




Frustriert über neue Daten? Unsere Vektordatenbank kann helfen
Welche Datenbanktechnologien und -anwendungen werden im Zeitalter von Big Data ins Rampenlicht rücken? Was wird der nächste Game-Changer sein?
Da unstrukturierte Daten etwa 80–90 % aller gespeicherten Daten ausmachen: Was sollen wir mit diesen wachsenden Data Lakes tun? Man könnte daran denken, traditionelle analytische Methoden einzusetzen, doch diese schaffen es nicht, nützliche Informationen herauszuziehen, wenn überhaupt Informationen. Um diese Frage zu beantworten, haben die „Drei Musketiere“ des Forschungs- und Entwicklungsteams von Zilliz, Dr. Rentong Guo, Herr Xiaofan Luan und Dr. Xiaomeng Yi, gemeinsam einen Artikel verfasst, um das Design und die Herausforderungen zu diskutieren, denen man beim Aufbau eines universellen Vektordatenbanksystems begegnet.
Dieser Artikel wurde in Programmer aufgenommen, einer von CSDN, der größten Softwareentwickler-Community in China, herausgegebenen Zeitschrift. Diese Ausgabe von Programmer enthält außerdem Artikel von Jeffrey Ullman, Träger des Turing Award 2020, Yann LeCun, Träger des Turing Award 2018, Mark Porter, CTO von MongoDB, Zhenkun Yang, Gründer von OceanBase, Dongxu Huang, Gründer von PingCAP, usw.
Im Folgenden teilen wir den vollständigen Artikel mit Ihnen:
Design und Praxis KI-orientierter universeller Vektordatenbanksysteme
Einführung
Moderne Datenanwendungen können problemlos mit strukturierten Daten umgehen, die etwa 20 % der heutigen Daten ausmachen. In ihrem Werkzeugkasten befinden sich Systeme wie relationale Datenbanken, NoSQL-Datenbanken usw.; im Gegensatz dazu gibt es für unstrukturierte Daten, die etwa 80 % aller Daten ausmachen, keine zuverlässigen Systeme. Um dieses Problem zu lösen, wird dieser Artikel die Schwachstellen diskutieren, die traditionelle Datenanalyse bei unstrukturierten Daten hat, und darüber hinaus die Architektur und Herausforderungen erörtern, denen wir beim Aufbau unseres eigenen universellen Vektordatenbanksystems gegenüberstanden.
Datenrevolution im KI-Zeitalter
Mit der rasanten Entwicklung von 5G- und IoT-Technologien versuchen Branchen, ihre Kanäle zur Datenerfassung zu vervielfachen und die reale Welt weiter in den digitalen Raum zu projizieren. Obwohl dies einige enorme Herausforderungen mit sich gebracht hat, hat es der wachsenden Branche auch enorme Vorteile gebracht. Eine dieser schwierigen Herausforderungen besteht darin, tiefere Einblicke in diese neu eintreffenden Daten zu gewinnen.
Laut IDC-Statistiken wurden allein im Jahr 2020 weltweit mehr als 40.000 Exabyte an neuen Daten erzeugt. Von der Gesamtmenge sind nur 20 % strukturierte Daten – Daten, die stark geordnet und über numerische Berechnungen und relationale Algebra leicht zu organisieren und zu analysieren sind. Im Gegensatz dazu sind unstrukturierte Daten (die die verbleibenden 80 % ausmachen) äußerst reich an Variationen von Datentypen, was es schwierig macht, die tiefe Semantik durch traditionelle Datenanalysemethoden aufzudecken.
Glücklicherweise erleben wir eine gleichzeitige, rasante Entwicklung bei unstrukturierten Daten und KI, wobei KI es uns ermöglicht, die Daten durch verschiedene Arten neuronaler Netze besser zu verstehen, wie in Abbildung 1 dargestellt.
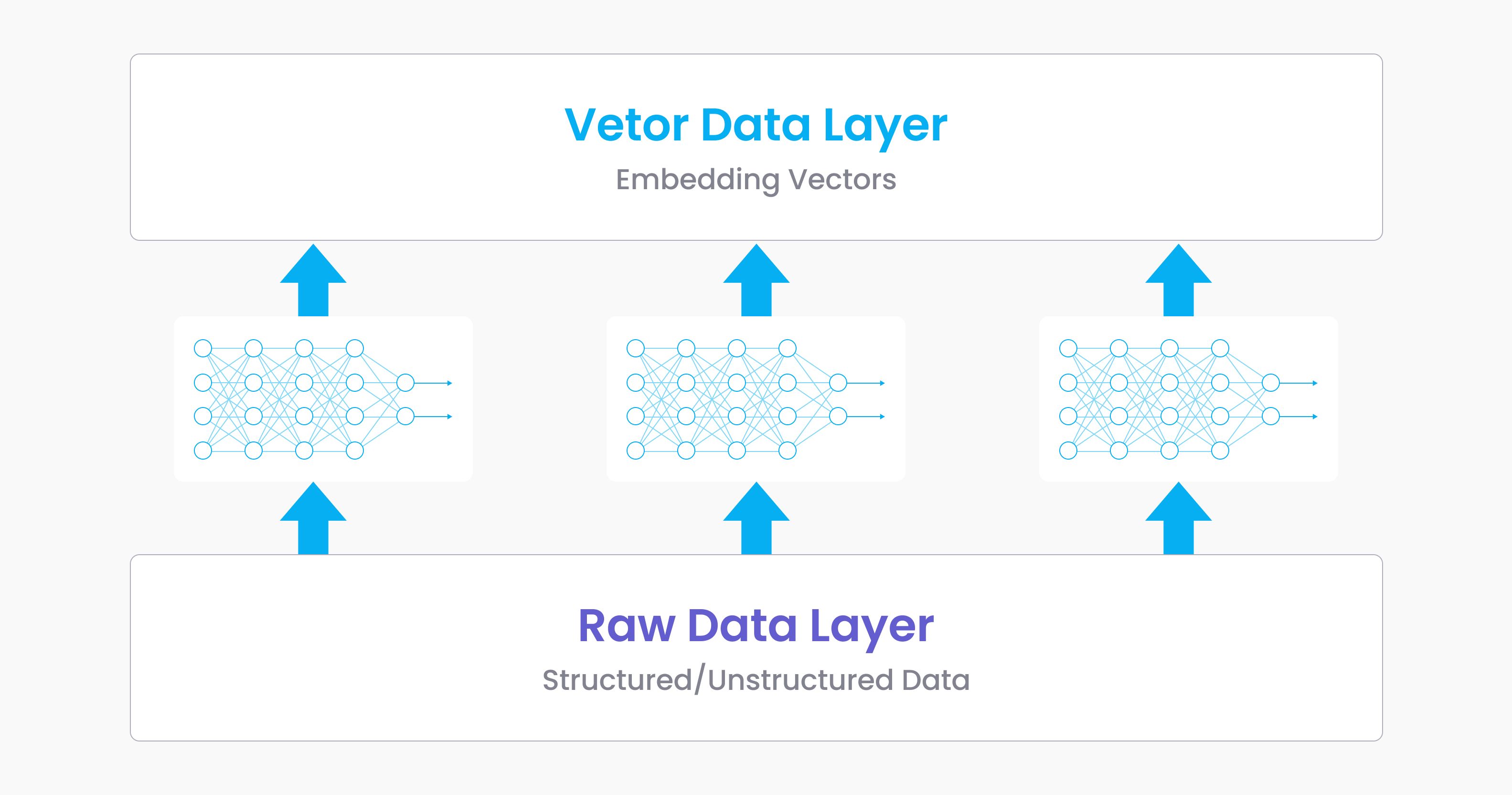 Abbildung 1: Embedding-Prozess
Abbildung 1: Embedding-Prozess
Die Embedding-Technologie hat nach dem Debüt von Word2vec schnell an Popularität gewonnen, wobei die Idee von „embed everything“ alle Bereiche des maschinellen Lernens erreicht hat. Dies führt zur Entstehung zweier großer Datenschichten: der Rohdatenschicht und der Vektordatenschicht. Die Rohdatenschicht besteht aus unstrukturierten Daten und bestimmten Arten strukturierter Daten; die Vektorschicht ist die Sammlung leicht analysierbarer Embeddings, die aus der Rohschicht hervorgehen, nachdem sie Machine-Learning-Modelle durchlaufen haben.
Im Vergleich zu Rohdaten weist vektorisierte Daten die folgenden Vorteile auf:
- Einbettungsvektoren sind ein abstrakter Datentyp, was bedeutet, dass wir ein einheitliches Algebrasystem aufbauen können, das darauf ausgerichtet ist, die Komplexität unstrukturierter Daten zu reduzieren.
- Einbettungsvektoren werden durch dichte Gleitkommavektoren ausgedrückt, wodurch Anwendungen SIMD nutzen können. Da SIMD von GPUs und nahezu allen modernen CPUs unterstützt wird, können Berechnungen über Vektoren hinweg eine hohe Leistung bei relativ geringen Kosten erzielen.
- Vektordaten, die über Modelle des maschinellen Lernens codiert werden, benötigen weniger Speicherplatz als die ursprünglichen unstrukturierten Daten und ermöglichen so einen höheren Durchsatz.
- Arithmetik kann auch über Einbettungsvektoren hinweg durchgeführt werden. Abbildung 2 zeigt ein Beispiel für cross-modales semantisches approximatives Matching – die in der Abbildung gezeigten Bilder sind das Ergebnis des Abgleichs von Worteinbettungen mit Bildeinbettungen.
 Abbildung 2: Visualisierung semantischer Einbettung basierend auf einem cross-modalen neuronalen Sprachmodell
Abbildung 2: Visualisierung semantischer Einbettung basierend auf einem cross-modalen neuronalen Sprachmodell
Wie in Abbildung 3 gezeigt, kann die Kombination von Bild- und Wortsemantik durch einfache Vektoraddition und -subtraktion über ihre entsprechenden Einbettungen hinweg erfolgen.
 Abbildung 3: Einheitliche Visualisierung semantischer Einbettung basierend auf einem cross-modalen neuronalen Sprachmodell
Abbildung 3: Einheitliche Visualisierung semantischer Einbettung basierend auf einem cross-modalen neuronalen Sprachmodell
Abgesehen von den oben genannten Funktionen unterstützen diese Operatoren in praktischen Szenarien komplexere Abfrageanweisungen. Inhaltsempfehlung ist ein bekanntes Beispiel. Im Allgemeinen bettet das System sowohl die Inhalte als auch die Sehpräferenzen der Nutzer ein. Anschließend gleicht das System die eingebetteten Präferenzen des Nutzers mit den ähnlichsten eingebetteten Inhalten mittels semantischer Ähnlichkeitsanalyse ab, was zu neuen Inhalten führt, die den Präferenzen der Nutzer ähneln. Diese Vektordatenschicht ist nicht nur auf Empfehlungssysteme beschränkt; Anwendungsfälle umfassen E-Commerce, Malware-Analyse, Datenanalyse, biometrische Verifizierung, Analyse chemischer Formeln, Finanzen, Versicherungen usw.
Unstrukturierte Daten erfordern einen vollständigen grundlegenden Software-Stack
Systemsoftware bildet die Grundlage aller datenorientierten Anwendungen, aber die Daten-Systemsoftware, die in den vergangenen Jahrzehnten aufgebaut wurde, z. B. Datenbanken, Datenanalyse-Engines usw., ist für den Umgang mit strukturierten Daten gedacht. Moderne Datenanwendungen stützen sich fast ausschließlich auf unstrukturierte Daten und profitieren nicht von traditionellen Datenbankmanagementsystemen.
Um dieses Problem anzugehen, haben wir ein KI-orientiertes, universell einsetzbares Vektordatenbanksystem namens Milvus entwickelt und als Open Source veröffentlicht (Referenz Nr. 1~2). Im Vergleich zu traditionellen Datenbanksystemen arbeitet Milvus auf einer anderen Datenschicht. Traditionelle Datenbanken, wie relationale Datenbanken, KV-Datenbanken, Textdatenbanken, Bild-/Videodatenbanken usw... arbeiten auf der Rohdatenschicht, während Milvus auf der Vektordatenschicht arbeitet.
In den folgenden Kapiteln werden wir die neuartigen Funktionen, das architektonische Design und die technischen Herausforderungen erörtern, denen wir beim Aufbau von Milvus begegnet sind.
Wichtige Eigenschaften einer Vektordatenbank
Vektordatenbanken speichern, abrufen und analysieren Vektoren und stellen, wie jede andere Datenbank auch, eine Standardschnittstelle für CRUD-Operationen bereit. Zusätzlich zu diesen „Standard“-Funktionen sind die unten aufgeführten Eigenschaften ebenfalls wichtige Qualitäten für eine Vektordatenbank:
- Unterstützung für hocheffiziente Vektoroperatoren
Die Unterstützung von Vektoroperatoren in einer Analyse-Engine konzentriert sich auf zwei Ebenen. Erstens sollte die Vektordatenbank verschiedene Arten von Operatoren unterstützen, zum Beispiel das oben erwähnte semantische Ähnlichkeitsmatching und die semantische Arithmetik. Darüber hinaus sollte sie eine Vielzahl von Ähnlichkeitsmetriken für die zugrunde liegenden Ähnlichkeitsberechnungen unterstützen. Eine solche Ähnlichkeit wird üblicherweise als räumlicher Abstand zwischen Vektoren quantifiziert, wobei gängige Metriken der euklidische Abstand, der Kosinusabstand und der Skalarproduktabstand sind.
- Unterstützung für Vektorindizierung
Im Vergleich zu B-Tree- oder LSM-Tree-basierten Indizes in traditionellen Datenbanken verbrauchen hochdimensionale Vektorindizes in der Regel deutlich mehr Rechenressourcen. Wir empfehlen die Verwendung von Clustering- und Graph-Indexalgorithmen sowie die Priorisierung von Matrix- und Vektoroperationen, um die zuvor erwähnten Fähigkeiten der Hardware zur Beschleunigung von Vektorberechnungen voll auszuschöpfen.
- Konsistente Benutzererfahrung über verschiedene Bereitstellungsumgebungen hinweg
Vektordatenbanken werden in der Regel in unterschiedlichen Umgebungen entwickelt und bereitgestellt. In der Vorphase arbeiten Data Scientists und Algorithmus-Ingenieure meist auf ihren Laptops und Workstations, da sie mehr Wert auf Verifikationseffizienz und Iterationsgeschwindigkeit legen. Wenn die Verifikation abgeschlossen ist, können sie die Datenbank in voller Größe auf einem privaten Cluster oder in der Cloud bereitstellen. Daher sollte ein geeignetes Vektordatenbanksystem über verschiedene Bereitstellungsumgebungen hinweg eine konsistente Leistung und Benutzererfahrung bieten.
- Unterstützung für hybride Suche
Neue Anwendungen entstehen, da Vektordatenbanken allgegenwärtig werden. Unter all diesen Anforderungen wird die hybride Suche über Vektoren und andere Datentypen am häufigsten genannt. Einige Beispiele hierfür sind die Approximate Nearest Neighbor Search (ANNS) nach skalarer Filterung, Multi-Channel-Recall aus Volltextsuche und Vektorsuche sowie die hybride Suche von raumzeitlichen Daten und Vektordaten. Solche Herausforderungen erfordern elastische Skalierbarkeit und Abfrageoptimierung, um Vektorsuchmaschinen effektiv mit KV-, Text- und anderen Suchmaschinen zu verbinden.
- Cloud-native Architektur
Das Volumen von Vektordaten wächst explosionsartig mit dem exponentiellen Wachstum der Datenerfassung. Hochdimensionale Vektordaten im Billionenmaßstab entsprechen Tausenden von TB Speicher, was weit über die Grenze eines einzelnen Knotens hinausgeht. Daher ist horizontale Erweiterbarkeit eine Schlüsselfähigkeit für eine Vektordatenbank und sollte die Anforderungen der Nutzer an Elastizität und Bereitstellungsagilität erfüllen. Darüber hinaus sollte sie auch die Komplexität von Systembetrieb und -wartung senken und zugleich die Beobachtbarkeit mithilfe von Cloud-Infrastruktur verbessern. Einige dieser Anforderungen treten in Form von mandantenfähiger Isolation, Daten-Snapshots und -Backups, Datenverschlüsselung und Datenvisualisierung auf, die in traditionellen Datenbanken üblich sind.
Systemarchitektur von Vektordatenbanken
Milvus 2.0 folgt den Designprinzipien „Log as data“, „unified batch and stream processing“, „stateless“ und „micro-services“. Abbildung 4 zeigt die Gesamtarchitektur von Milvus 2.0.
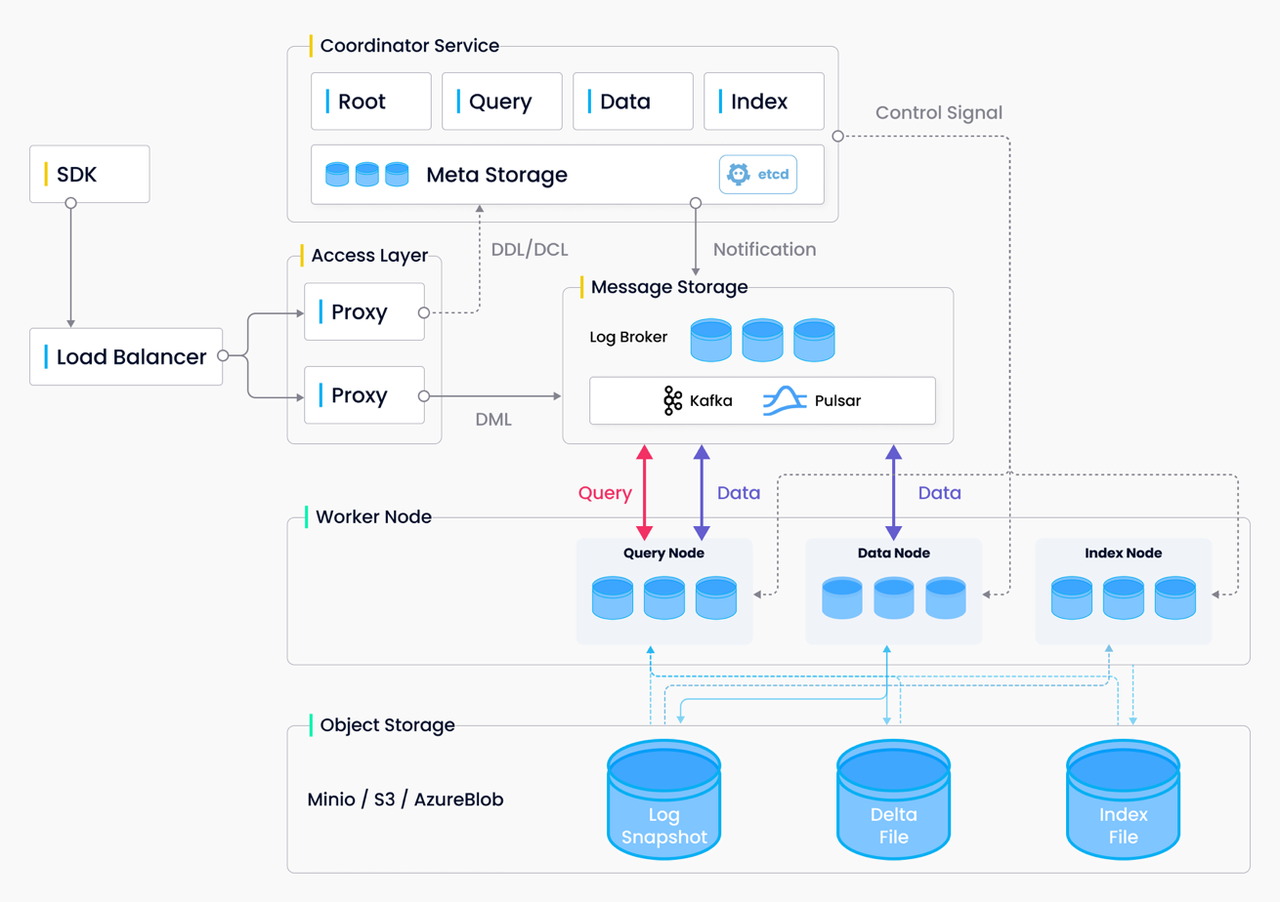 Abbildung 4: Gesamtarchitektur von Milvus 2.0
Abbildung 4: Gesamtarchitektur von Milvus 2.0
Log as data: Milvus 2.0 verwaltet keine physischen Tabellen. Stattdessen stellt es die Datenzuverlässigkeit durch Log-Persistenz und Log-Snapshots sicher. Der Log-Broker (das Rückgrat des Systems) speichert Logs und entkoppelt Komponenten und Dienste über den Log-Publication-Subscription-Mechanismus (Pub/Sub). Wie in Abbildung 5 gezeigt, besteht der Log-Broker aus „log sequence“ und „log subscriber“. Die Log-Sequenz zeichnet alle Operationen auf, die den Zustand einer Collection ändern (entspricht einer Tabelle in einer relationalen Datenbank ); der Log-Subscriber abonniert die Log-Sequenz, um seine lokalen Daten zu aktualisieren und Dienste in Form von schreibgeschützten Kopien bereitzustellen. Der Pub/Sub-Mechanismus schafft außerdem Raum für Systemerweiterbarkeit in Bezug auf Change Data Capture (CDC) und global verteilte Bereitstellung.
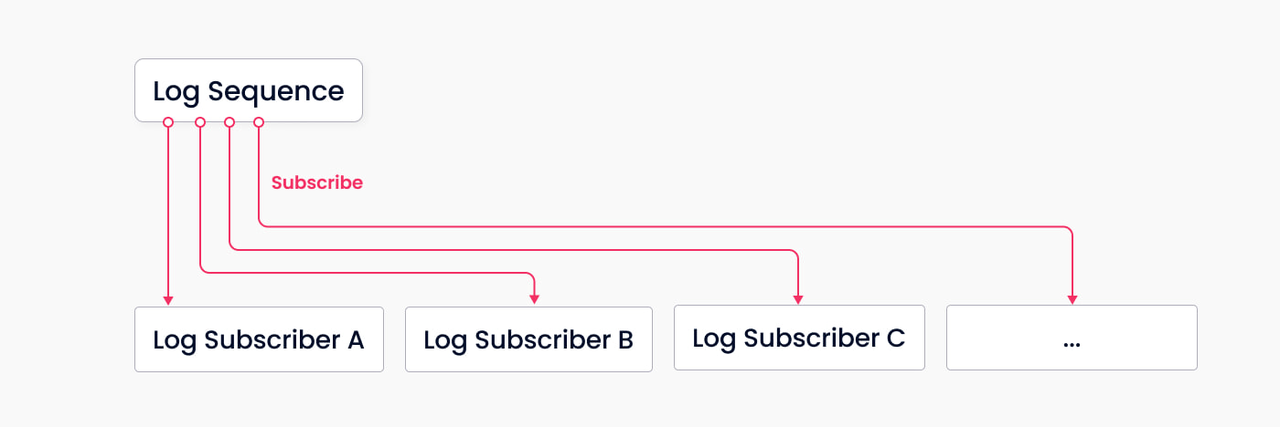 Abbildung 5: Ein vereinfachtes Modell für Log-Speicherung
Abbildung 5: Ein vereinfachtes Modell für Log-Speicherung
Einheitliche Batch- und Stream-Verarbeitung: Log-Streaming ermöglicht es Milvus, Daten in Echtzeit zu aktualisieren und dadurch die Echtzeit-Lieferbarkeit sicherzustellen. Darüber hinaus kann Milvus durch die Umwandlung von Daten-Batches in Log-Snapshots und den Aufbau von Indizes auf Snapshots eine höhere Abfrageeffizienz erzielen. Während einer Abfrage führt Milvus die Abfrageergebnisse aus sowohl inkrementellen Daten als auch historischen Daten zusammen, um die Vollständigkeit der zurückgegebenen Daten zu gewährleisten. Ein solches Design balanciert Echtzeitleistung und Effizienz besser aus und verringert im Vergleich zur traditionellen Lambda-Architektur den Wartungsaufwand sowohl für Online- als auch für Offline-Systeme.
Zustandslos: Cloud-Infrastruktur und Open-Source-Speicherkomponenten befreien Milvus davon, Daten innerhalb seiner eigenen Komponenten persistent zu speichern. Milvus 2.0 persistiert Daten mit drei Arten von Speicher: Metadatenspeicher, Log-Speicher und Objektspeicher. Der Metadatenspeicher speichert nicht nur die Metadaten, sondern übernimmt auch Service Discovery und Knotenverwaltung. Der Log-Speicher führt die Persistenz inkrementeller Daten und die Daten-Publish-Subscription aus. Der Objektspeicher speichert Log-Snapshots, Indizes und einige Zwischenergebnisse von Berechnungen.
Microservices: Milvus folgt den Prinzipien der Entkopplung von Data Plane und Control Plane, der Trennung von Lesen/Schreiben und der Trennung von Online-/Offline-Aufgaben. Es besteht aus vier Dienstschichten: der Zugriffsschicht, der Koordinator-Schicht, der Worker-Schicht und der Speicherschicht. Diese Schichten sind in Bezug auf Skalierung und Disaster Recovery voneinander unabhängig. Als nach außen gerichtete Schicht und Benutzer-Endpunkt verarbeitet die Zugriffsschicht Client-Verbindungen, validiert Client-Anfragen und kombiniert Abfrageergebnisse. Als „Gehirn“ des Systems übernimmt die Koordinator-Schicht die Aufgaben des Cluster-Topologie-Managements, des Lastausgleichs, der Datendeklaration und des Datenmanagements. Die Worker-Schicht enthält die „Gliedmaßen“ des Systems und führt Datenaktualisierungen, Abfragen und Indexaufbau-Operationen aus. Schließlich ist die Speicherschicht für Datenpersistenz und Replikation verantwortlich. Insgesamt gewährleistet dieses auf Microservices basierende Design eine kontrollierbare Systemkomplexität, wobei jede Komponente für ihre entsprechende Funktion verantwortlich ist. Milvus klärt die Service-Grenzen durch klar definierte Schnittstellen und entkoppelt die Dienste auf Basis feinerer Granularität, was die elastische Skalierbarkeit und Ressourcenverteilung weiter optimiert.
Technische Herausforderungen für Vektordatenbanken
Frühe Forschung zu Vektordatenbanken konzentrierte sich hauptsächlich auf den Entwurf hocheffizienter Indexstrukturen und Abfragemethoden – dies führte zu einer Vielzahl von Bibliotheken für Vektorsuchalgorithmen (Referenz Nr. 3~5). In den letzten Jahren haben immer mehr akademische und Engineering-Teams Vektorsuchprobleme aus der Perspektive des Systemdesigns neu betrachtet und einige systematische Lösungen vorgeschlagen. Durch die Zusammenfassung bestehender Studien und der Nutzernachfrage kategorisieren wir die wichtigsten technischen Herausforderungen für Vektordatenbanken wie folgt:
- Optimierung des Kosten-Leistungs-Verhältnisses relativ zur Last
Im Vergleich zu traditionellen Datentypen erfordert die Analyse von Vektordaten aufgrund ihrer hohen Dimensionalität deutlich mehr Speicher- und Rechenressourcen. Darüber hinaus haben Nutzer unterschiedliche Präferenzen hinsichtlich Lasteigenschaften und Kosten-Leistungs-Optimierung bei Vektorsuchlösungen gezeigt. Beispielsweise würden Nutzer, die mit extrem großen Datensätzen (Dutzenden oder Hunderten von Milliarden Vektoren) arbeiten, Lösungen mit geringeren Datenspeicherkosten und geringerer Varianz der Suchlatenz bevorzugen, während andere eine höhere Suchleistung und eine nicht variierende durchschnittliche Latenz verlangen können. Um solche unterschiedlichen Präferenzen zu erfüllen, muss die Kernindexkomponente der Vektordatenbank in der Lage sein, Indexstrukturen und Suchalgorithmen mit verschiedenen Arten von Speicher- und Rechenhardware zu unterstützen.
Beispielsweise sollte die Speicherung von Vektordaten und den entsprechenden Indexdaten in günstigeren Speichermedien (wie NVM und SSD) in Betracht gezogen werden, wenn Speicherkosten gesenkt werden sollen. Die meisten bestehenden Vektorsuchalgorithmen arbeiten jedoch mit Daten, die direkt aus dem Arbeitsspeicher gelesen werden. Um Leistungsverluste durch die Verwendung von Festplattenlaufwerken zu vermeiden, sollte die Vektordatenbank in der Lage sein, die Lokalität des Datenzugriffs in Kombination mit Suchalgorithmen auszunutzen, zusätzlich dazu, sich an Speicherlösungen für Vektordaten und Indexstrukturen anpassen zu können (Referenz Nr. 6~8). Zur Leistungsverbesserung konzentriert sich die aktuelle Forschung auf Hardware-Beschleunigungstechnologien mit GPU, NPU, FPGA usw. (Referenz Nr. 9). Beschleunigungsspezifische Hardware und Chips unterscheiden sich jedoch im Architekturdesign, und das Problem der effizientesten Ausführung über verschiedene Hardware-Beschleuniger hinweg ist noch nicht gelöst.
- Automatisierte Systemkonfiguration und -abstimmung
Die meisten bestehenden Studien zu Vektorsuchalgorithmen streben ein flexibles Gleichgewicht zwischen Speicherkosten, Rechenleistung und Suchgenauigkeit an. Im Allgemeinen beeinflussen sowohl Algorithmusparameter als auch Datenmerkmale die tatsächliche Leistung eines Algorithmus. Da sich die Anforderungen der Nutzer hinsichtlich Kosten und Leistung unterscheiden, stellt die Auswahl einer Vektorabfragemethode, die ihren Anforderungen und Datenmerkmalen entspricht, eine erhebliche Herausforderung dar.
Dennoch sind manuelle Methoden zur Analyse der Auswirkungen der Datenverteilung auf Suchalgorithmen aufgrund der hohen Dimensionalität der Vektordaten nicht effektiv. Um dieses Problem zu lösen, suchen Wissenschaft und Industrie nach Lösungen zur Algorithmusempfehlung auf Basis von maschinellem Lernen (Referenz Nr. 10).
Das Design eines ML-gestützten intelligenten Vektorsuchalgorithmus ist ebenfalls ein Forschungsschwerpunkt. Allgemein gesprochen werden bestehende Vektorsuchalgorithmen universell für Vektordaten mit unterschiedlicher Dimensionalität und unterschiedlichen Verteilungsmustern entwickelt. Infolgedessen unterstützen sie keine spezifischen Indexstrukturen entsprechend den Datenmerkmalen und bieten daher wenig Raum für Optimierung. Künftige Studien sollten auch wirksame Technologien des maschinellen Lernens untersuchen, die Indexstrukturen für unterschiedliche Datenmerkmale maßschneidern können (Referenz Nr. 11-12).
- Unterstützung für erweiterte Abfragesemantik
Moderne Anwendungen stützen sich häufig auf fortgeschrittenere Abfragen über Vektoren hinweg - traditionelle Semantik der Suche nach nächsten Nachbarn ist für die Suche in Vektordaten nicht mehr anwendbar. Darüber hinaus entsteht Nachfrage nach kombinierter Suche über mehrere Vektordatenbanken hinweg oder auf Vektor- und Nicht-Vektordaten (Referenz Nr. 13).
Konkret nehmen Varianten von Distanzmetriken für Vektorähnlichkeit schnell zu. Traditionelle Ähnlichkeitswerte wie euklidische Distanz, Skalarproduktdistanz und Kosinusdistanz können nicht alle Anwendungsanforderungen erfüllen. Mit der Verbreitung der Technologie der künstlichen Intelligenz entwickeln viele Branchen ihre eigenen feldspezifischen Metriken für Vektorähnlichkeit, wie Tanimoto-Distanz, Mahalanobis-Distanz, Superstructure und Substructure. Die Integration dieser Bewertungsmetriken in bestehende Suchalgorithmen und das Design neuartiger Algorithmen, die diese Metriken nutzen, sind beides anspruchsvolle Forschungsprobleme.
Mit zunehmender Komplexität der Nutzerdienste werden Anwendungen sowohl Vektordaten als auch Nicht-Vektordaten durchsuchen müssen. Beispielsweise analysiert ein Content-Recommender die Präferenzen und sozialen Beziehungen der Nutzer und gleicht sie mit aktuellen Trendthemen ab, um den Nutzern passende Inhalte bereitzustellen. Solche Suchen umfassen normalerweise Abfragen über mehrere Datentypen oder über mehrere Datenverarbeitungssysteme hinweg. Solche hybriden Suchen effizient und flexibel zu unterstützen, ist eine weitere Herausforderung im Systemdesign.
Autoren
Dr. Rentong Guo (Ph.D. in Computersoftware und -theorie, Huazhong University of Science and Technology), Partner und R&D Director von Zilliz. Er ist Mitglied des China Computer Federation Technical Committee on Distributed Computing and Processing (CCF TCDCP). Seine Forschung konzentriert sich auf Datenbanken, verteilte Systeme, Caching-Systeme und heterogenes Rechnen. Seine Forschungsarbeiten wurden auf mehreren erstklassigen Konferenzen und in Fachzeitschriften veröffentlicht, darunter Usenix ATC, ICS, DATE, TPDS. Als Architekt von Milvus sucht Dr. Guo nach Lösungen zur Entwicklung hochskalierbarer und kosteneffizienter KI-basierter Datenanalysesysteme.
Xiaofan Luan, Partner und Engineering Director von Zilliz sowie Mitglied des Technical Advisory Committee der LF AI & Data Foundation. Er arbeitete nacheinander in der US-Zentrale von Oracle und bei Hedvig, einem Startup für softwaredefinierten Speicher. Er trat dem Alibaba Cloud Database Team bei und war für die Entwicklung der NoSQL-Datenbank HBase und Lindorm verantwortlich. Luan erwarb seinen Master-Abschluss in Electronic Computer Engineering an der Cornell University.
Dr. Xiaomeng Yi (Ph.D. in Computerarchitektur, Huazhong University of Science and Technology), Senior Researcher und Leiter des Forschungsteams von Zilliz. Seine Forschung konzentriert sich auf das Management hochdimensionaler Daten, großskalige Informationssuche und Ressourcenallokation in verteilten Systemen. Dr. Yis Forschungsarbeiten wurden in führenden Fachzeitschriften und auf internationalen Konferenzen veröffentlicht, darunter IEEE Network Magazine, IEEE/ACM TON, ACM SIGMOD, IEEE ICDCS und ACM TOMPECS.
Filip Haltmayer, ein Zilliz Data Engineer, schloss sein Studium an der University of California, Santa Cruz mit einem BS in Computer Science ab. Seit seinem Eintritt bei Zilliz verbringt Filip den Großteil seiner Zeit mit Cloud-Bereitstellungen, Kundeninteraktionen, technischen Vorträgen und der Entwicklung von KI-Anwendungen.
Referenzen
- Milvus Project: https://github.com/milvus-io/milvus
- Milvus: Ein speziell entwickeltes Vektordatenmanagementsystem, SIGMOD'21
- Faiss Project: https://github.com/facebookresearch/faiss
- Annoy Project: https://github.com/spotify/annoy
- SPTAG Project: https://github.com/microsoft/SPTAG
- GRIP: Multi-Store-kapazitätsoptimierte Hochleistungs-Nächste-Nachbarn-Suche für Vektorsuchmaschinen, CIKM'19
- DiskANN: Schnelle, genaue Milliarden-Punkte-Nächste-Nachbarn-Suche auf einem einzelnen Knoten, NIPS'19
- HM-ANN: Effiziente Milliarden-Punkte-Nächste-Nachbarn-Suche auf heterogenem Speicher, NIPS'20
- SONG: Approximative Nächste-Nachbarn-Suche auf GPU, ICDE'20
- Eine Demonstration des Tuning-Dienstes des automatischen Datenbankmanagementsystems ottertune, VLDB'18
- Der Fall für Learned Index Structures, SIGMOD'18
- Verbesserung der approximativen Nächste-Nachbarn-Suche durch gelernte adaptive frühzeitige Beendigung, SIGMOD'20
- AnalyticDB-V: Eine hybride Analyse-Engine zur Query Fusion für strukturierte und unstrukturierte Daten, VLDB'20
Engagieren Sie sich in unserer Open-Source-Community:
Weiterlesen

Zilliz Skills Breakdown: How AI Agents Master Vector Databases
Zilliz's Milvus Skill (pymilvus, 7 files) and Zilliz Cloud Skill (zilliz-cli, 14 modules) bring vector-DB dev and ops into one Claude Code session.

Smarter Autoscaling in Zilliz Cloud: Always Optimized for Every Workload
With the latest upgrade, Zilliz Cloud introduces smarter autoscaling—a fully automated, more streamlined, elastic resource management system.

Data Deduplication at Trillion Scale: How to Solve the Biggest Bottleneck of LLM Training
Explore how MinHash LSH and Milvus handle data deduplication at the trillion-scale level, solving key bottlenecks in LLM training for improved AI model performance.