




Effiziente Vektorähnlichkeitssuche in Empfehlungs-Workflows mit Milvus und NVIDIA Merlin
Dieser Beitrag wurde zuerst auf NVIDIA Merlins Medium-Kanal veröffentlicht und mit Genehmigung bearbeitet und hier erneut veröffentlicht. Er wurde gemeinsam von Burcin Bozkaya und William Hicks von NVIDIA sowie Filip Haltmayer und Li Liu von Zilliz verfasst.
Einführung
Moderne Empfehlungssysteme (Recsys) bestehen aus Trainings-/Inferenz-Pipelines, die mehrere Phasen der Datenaufnahme, Datenvorverarbeitung, des Modelltrainings und des Hyperparameter-Tunings für das Abrufen, Filtern, Ranking und Bewerten relevanter Elemente umfassen. Ein wesentlicher Bestandteil einer Pipeline für Empfehlungssysteme ist das Abrufen oder Entdecken von Dingen, die für einen Nutzer am relevantesten sind, insbesondere bei großen Artikelkatalogen. Dieser Schritt umfasst typischerweise eine Suche nach approximativen nächsten Nachbarn (ANN) in einer indizierten Datenbank niedrigdimensionaler Vektordarstellungen (d. h. Embeddings) von Produkt- und Nutzerattributen, die aus Deep-Learning-Modellen erstellt wurden, die mit Interaktionen zwischen Nutzern und Produkten/Dienstleistungen trainiert werden.
NVIDIA Merlin, ein Open-Source-Framework, das für das Training von End-to-End-Modellen zur Erstellung von Empfehlungen in jeder Größenordnung entwickelt wurde, integriert sich in ein effizientes Vektordatenbank-Index- und Such-Framework. Ein solches Framework, das in letzter Zeit viel Aufmerksamkeit erregt hat, ist Milvus, eine von Zilliz entwickelte Open-Source-Vektordatenbank. Sie bietet schnelle Index- und Abfragefunktionen. Milvus hat kürzlich Unterstützung für GPU-Beschleunigung hinzugefügt, die NVIDIA-GPUs nutzt, um KI-Workflows aufrechtzuerhalten. Die Unterstützung für GPU-Beschleunigung ist eine großartige Nachricht, denn eine beschleunigte Vektorsuchbibliothek ermöglicht schnelle gleichzeitige Abfragen und wirkt sich positiv auf die Latenzanforderungen heutiger Empfehlungssysteme aus, bei denen Entwickler viele gleichzeitige Anfragen erwarten. Milvus verzeichnet über 5 Mio. Docker-Pulls, ~23.000 Sterne auf GitHub (Stand September 2023), über 5.000 Unternehmenskunden und ist eine Kernkomponente vieler Anwendungen (siehe Anwendungsfälle).
Dieser Blog zeigt, wie Milvus zur Trainings- und Inferenzzeit mit dem Merlin Recsys-Framework zusammenarbeitet. Wir zeigen, wie Milvus Merlin in der Phase des Artikelabrufs mit einer hocheffizienten Top-k-Vektor-Embedding-Suche ergänzt und wie es zur Inferenzzeit mit NVIDIA Triton Inference Server (TIS) verwendet werden kann (siehe Abbildung 1). Unsere Benchmark-Ergebnisse zeigen eine beeindruckende 37- bis 91-fache Beschleunigung mit GPU-beschleunigtem Milvus, das NVIDIA RAFT mit den von Merlin Models generierten Vektor-Embeddings verwendet. Der Code, den wir zur Demonstration der Merlin-Milvus-Integration und der detaillierten Benchmark-Ergebnisse verwenden, sowie die Bibliothek, die unsere Benchmark-Studie ermöglicht hat, sind hier verfügbar.
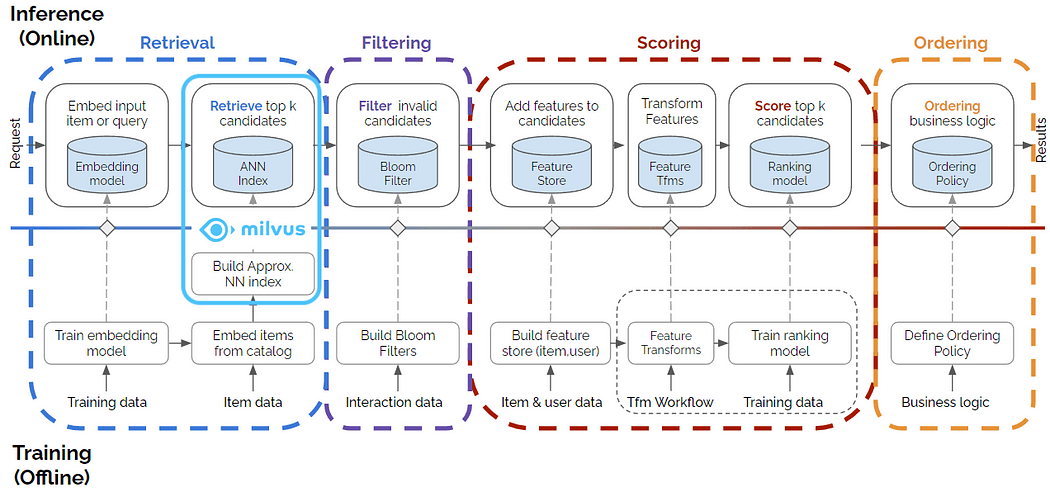
Abbildung 1. Mehrstufiges Empfehlungssystem mit Milvus-Framework, das zur Abrufphase beiträgt. Quelle der ursprünglichen mehrstufigen Abbildung: dieser Blogbeitrag.
Die Herausforderungen für Empfehlungssysteme
Angesichts der mehrstufigen Natur von Empfehlungssystemen und der Verfügbarkeit verschiedener Komponenten und Bibliotheken, die sie integriert haben, besteht eine erhebliche Herausforderung darin, alle Komponenten nahtlos in eine End-to-End-Pipeline zu integrieren. Wir möchten in unseren Beispiel-Notebooks zeigen, dass die Integration mit weniger Aufwand durchgeführt werden kann.
Eine weitere Herausforderung von Recommender-Workflows ist die Beschleunigung bestimmter Pipeline-Teile. Während GPUs bekanntermaßen eine enorme Rolle beim Training großer neuronaler Netzwerke spielen, sind sie erst seit Kurzem Bestandteil von Vektordatenbanken und ANN-Suche. Mit der zunehmenden Größe von E-Commerce-Produktbeständen oder Streaming-Media-Datenbanken und der Anzahl der Nutzer, die diese Dienste verwenden, müssen CPUs die erforderliche Leistung bereitstellen, um Millionen von Nutzern in performanten RecSys-Workflows zu bedienen. GPU-Beschleunigung in anderen Pipeline-Teilen ist notwendig geworden, um diese Herausforderung zu bewältigen. Die Lösung in diesem Blog adressiert diese Herausforderung, indem sie zeigt, dass ANN-Suche bei der Verwendung von GPUs effizient ist.
Tech-Stacks für die Lösung
Beginnen wir zunächst damit, einige der Grundlagen zu überprüfen, die für die Durchführung unserer Arbeit erforderlich sind.
NVIDIA Merlin: eine Open-Source-Bibliothek mit High-Level-APIs zur Beschleunigung von Empfehlungssystemen auf NVIDIA-GPUs.
NVTabular: für die Vorverarbeitung der tabellarischen Eingabedaten und Feature Engineering.
Merlin Models: zum Trainieren von Deep-Learning-Modellen und, in diesem Fall, zum Lernen von Nutzer- und Item-Embedding-Vektoren aus Nutzerinteraktionsdaten.
Merlin Systems: zum Kombinieren eines TensorFlow-basierten Empfehlungsmodells mit anderen Elementen (z. B. Feature Store, ANN-Suche mit Milvus), um es mit TIS bereitzustellen.
Triton Inference Server: für die Inferenzphase, in der ein Nutzer-Feature-Vektor übergeben und Produktempfehlungen generiert werden.
Containerisierung: All das oben Genannte ist über Container verfügbar, die NVIDIA im NGC catalog bereitstellt. Wir haben den Merlin TensorFlow 23.06 container verwendet.
Milvus 2.3: zur Durchführung GPU-beschleunigter Vektorindexierung und Abfragen.
Milvus 2.2.11: wie oben, aber für die Ausführung auf CPU.
Pymilvus SDK: zum Verbinden mit dem Milvus-Server, Erstellen von Vektordatenbank-Indizes und Ausführen von Abfragen über eine Python-Schnittstelle.
Feast: zum Speichern und Abrufen von Nutzer- und Item-Attributen in einem (Open-Source-)Feature Store als Teil unserer End-to-End-RecSys-Pipeline.
Mehrere zugrunde liegende Bibliotheken und Frameworks werden ebenfalls im Hintergrund verwendet. Beispielsweise stützt sich Merlin auf andere NVIDIA-Bibliotheken wie cuDF und Dask, die beide unter RAPIDS cuDF verfügbar sind. Ebenso stützt sich Milvus auf NVIDIA RAFT für Primitive zur GPU-Beschleunigung sowie auf modifizierte Bibliotheken wie HNSW und FAISS für die Suche.
Vektordatenbanken und Milvus verstehen
Approximate Nearest Neighbor (ANN) ist eine Funktionalität, die relationale Datenbanken nicht bewältigen können. Relationale DBs sind darauf ausgelegt, tabellarische Daten mit vordefinierten Strukturen und direkt vergleichbaren Werten zu verarbeiten. Indizes relationaler Datenbanken stützen sich darauf, um Daten zu vergleichen und Strukturen zu erstellen, die den Vorteil nutzen, zu wissen, ob jeder Wert kleiner oder größer als der andere ist. Embedding-Vektoren können auf diese Weise nicht direkt miteinander verglichen werden, da wir wissen müssen, wofür jeder Wert im Vektor steht. Sie können nicht aussagen, ob ein Vektor notwendigerweise kleiner ist als der andere. Das Einzige, was wir tun können, ist, die Distanz zwischen den beiden Vektoren zu berechnen. Wenn die Distanz zwischen zwei Vektoren klein ist, können wir davon ausgehen, dass die Merkmale, die sie repräsentieren, ähnlich sind, und wenn sie groß ist, können wir davon ausgehen, dass die Daten, die sie repräsentieren, unterschiedlicher sind. Diese effizienten Indizes haben jedoch ihren Preis; die Berechnung der Distanz zwischen zwei Vektoren ist rechenintensiv, und Vektorindizes sind nicht ohne Weiteres anpassbar und manchmal nicht modifizierbar. Aufgrund dieser beiden Einschränkungen ist die Integration dieser Indizes in relationale Datenbanken komplexer, weshalb speziell entwickelte Vektordatenbanken benötigt werden.
Milvus wurde entwickelt, um die Probleme zu lösen, auf die relationale Datenbanken bei Vektoren stoßen, und wurde von Grund auf dafür konzipiert, diese Embedding-Vektoren und ihre Indizes in großem Maßstab zu verarbeiten. Um dem Cloud-native-Anspruch gerecht zu werden, trennt Milvus Rechenleistung und Speicher sowie verschiedene Rechenaufgaben — Abfragen, Datenaufbereitung und Indexierung. Benutzer können jeden Datenbankteil skalieren, um andere Anwendungsfälle zu bewältigen, unabhängig davon, ob sie dateninsertionslastig oder suchlastig sind. Wenn es einen großen Zustrom von Insertionsanfragen gibt, kann der Benutzer die Indexknoten vorübergehend horizontal und vertikal skalieren, um die Aufnahme zu bewältigen. Ebenso kann der Benutzer, wenn keine Daten aufgenommen werden, es aber viele Suchanfragen gibt, die Indexknoten reduzieren und stattdessen die Abfrageknoten für mehr Durchsatz hochskalieren. Dieses Systemdesign (siehe Abbildung 2) erforderte von uns, in einer Denkweise des parallelen Rechnens zu denken, was zu einem rechenoptimierten System mit vielen offenen Türen für weitere Optimierungen führte.
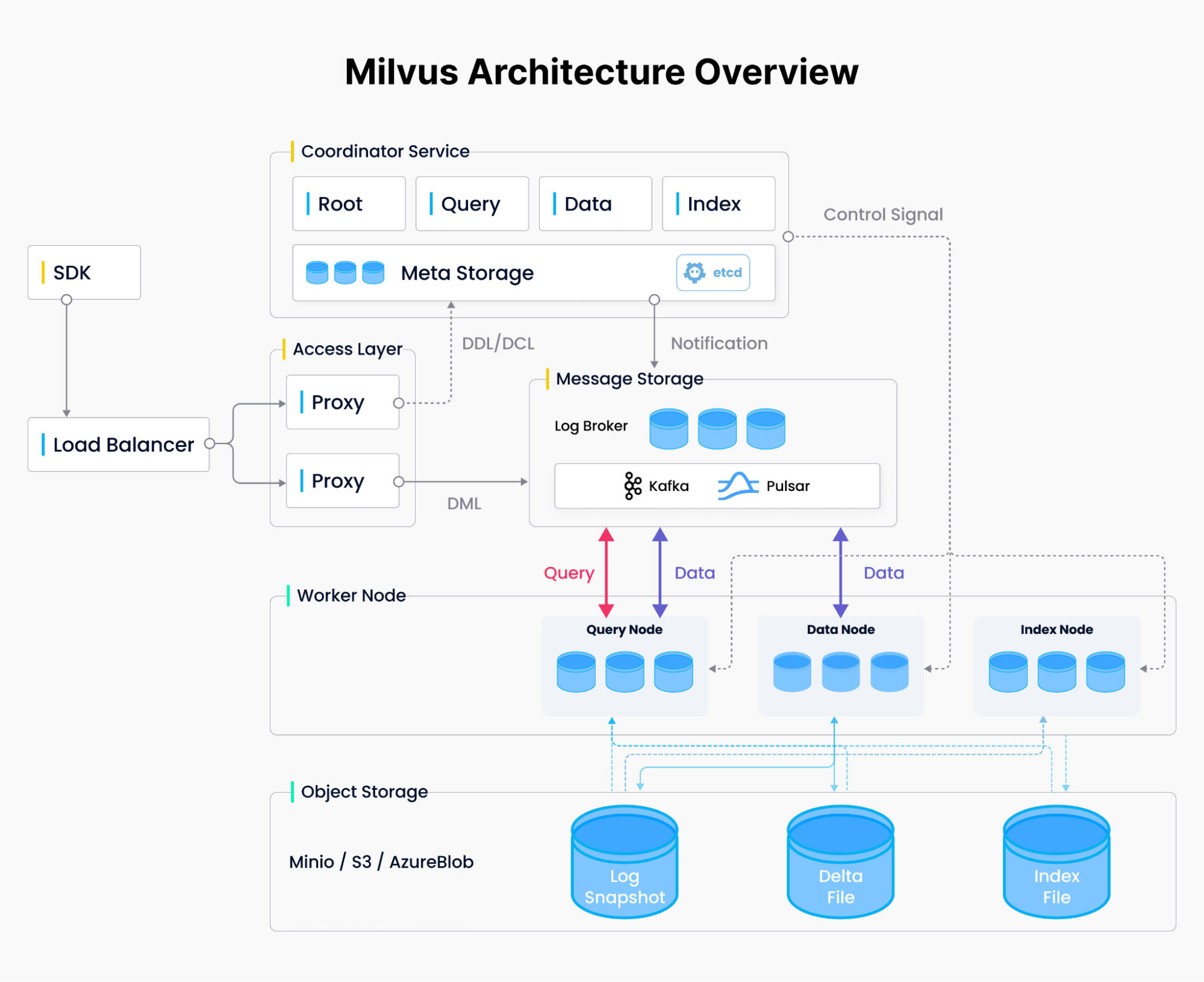
Abbildung 2. Milvus-Systemdesign
Milvus verwendet außerdem viele hochmoderne Indexierungsbibliotheken, um Benutzern so viel Anpassungsfähigkeit für ihr System wie möglich zu bieten. Es verbessert sie, indem es die Fähigkeit hinzufügt, CRUD-Operationen, gestreamte Daten und Filterung zu verarbeiten. Später werden wir besprechen, wie sich diese Indizes unterscheiden und welche Vor- und Nachteile die einzelnen haben.
Beispiellösung: Integration von Milvus und Merlin
Die hier vorgestellte Beispiellösung demonstriert die Integration von Milvus mit Merlin in der Phase des Item Retrievals (wenn die k relevantesten Items durch eine ANN-Suche abgerufen werden). Wir verwenden einen realen Datensatz aus einer RecSys Challenge, die unten beschrieben wird. Wir trainieren ein Two-Tower-Deep-Learning-Modell, das Vektor-Embeddings für Benutzer und Items lernt. Dieser Abschnitt bietet außerdem den Blueprint unserer Benchmarking-Arbeit, einschließlich der Metriken, die wir erfassen, und des Parameterbereichs, den wir verwenden.
Unser Ansatz umfasst:
Datenaufnahme und Vorverarbeitung
Training des Two-Tower-Deep-Learning-Modells
Aufbau des Milvus-Index
Milvus-Ähnlichkeitssuche
Wir beschreiben jeden Schritt kurz und verweisen den Leser für Details auf unsere Notebooks.
Datensatz
YOOCHOOSE GmbH stellt den Datensatz bereit, den wir in dieser Integrations- und Benchmark-Studie für die RecSys 2015 Challenge verwenden und der auf Kaggle verfügbar ist. Er enthält Nutzer-Klick-/Kaufereignisse eines europäischen Online-Händlers mit Attributen wie einer Session-ID, einem Zeitstempel, einer mit dem Klick/Kauf verknüpften Artikel-ID und einer Artikelkategorie, verfügbar in der Datei yoochoose-clicks.dat. Die Sessions sind unabhängig, und es gibt keinen Hinweis auf wiederkehrende Nutzer, daher behandeln wir jede Session als zu einem einzelnen Nutzer gehörig. Der Datensatz umfasst 9.249.729 eindeutige Sessions (Nutzer) und 52.739 eindeutige Artikel.
Datenaufnahme und Vorverarbeitung
Das Tool, das wir für die Datenvorverarbeitung verwenden, ist NVTabular, eine GPU-beschleunigte, hochskalierbare Komponente von Merlin für Feature Engineering und Vorverarbeitung. Wir verwenden NVTabular, um Daten in den GPU-Speicher einzulesen, Features nach Bedarf neu anzuordnen, in Parquet-Dateien zu exportieren und einen Train-Validation-Split für das Training zu erstellen. Daraus ergeben sich 7.305.761 eindeutige Nutzer und 49.008 eindeutige Artikel für das Training. Außerdem kategorisieren wir jede Spalte und ihre Werte in Integer-Werte. Der Datensatz ist nun bereit für das Training mit dem Two-Tower-Modell.
Modelltraining
Wir verwenden das Two-Tower-Deep-Learning-Modell, um Nutzer- und Artikel-Embeddings zu trainieren und zu erzeugen, die später bei der Vektorindexierung und -abfrage verwendet werden. Nach dem Training des Modells können wir die gelernten Nutzer- und Artikel-Embeddings extrahieren.
Die folgenden zwei Schritte sind optional: ein DLRM-Modell, das darauf trainiert wurde, die abgerufenen Artikel für Empfehlungen zu ranken, und ein Feature Store (in diesem Fall Feast), der zum Speichern und Abrufen von Nutzer- und Artikel-Features verwendet wird. Wir beziehen sie der Vollständigkeit des mehrstufigen Workflows halber ein.
Abschließend exportieren wir die Nutzer- und Artikel-Embeddings in Parquet-Dateien, die später erneut geladen werden können, um einen Milvus-Vektorindex zu erstellen.
Aufbau und Abfrage des Milvus-Index
Milvus erleichtert Vektorindexierung und Ähnlichkeitssuche über einen „Server“, der auf der Inferenzmaschine gestartet wird. In unserem Notebook #2 richten wir dies ein, indem wir den Milvus-Server und Pymilvus per pip installieren und anschließend den Server mit seinem standardmäßigen Listening-Port starten. Als Nächstes demonstrieren wir den Aufbau eines einfachen Index (IVF_FLAT) und die Abfrage dagegen mithilfe der Funktionen setup_milvus bzw. query_milvus.
Benchmarking
Wir haben zwei Benchmarks entwickelt, um den Anwendungsfall für die Nutzung einer schnellen und effizienten Bibliothek für Vektorindexierung/-suche wie Milvus zu demonstrieren.
Verwendung von Milvus zum Aufbau von Vektorindizes mit den zwei von uns erzeugten Embedding-Sätzen: 1) Nutzer-Embeddings für 7,3 Mio. eindeutige Nutzer, aufgeteilt in 85 % Trainingssatz (für die Indexierung) und 15 % Testsatz (für die Abfrage), und 2) Artikel-Embeddings für 49.000 Produkte (mit einem 50-50-Train-Test-Split). Dieser Benchmark wird unabhängig für jeden Vektordatensatz durchgeführt, und die Ergebnisse werden separat berichtet.
Verwendung von Milvus zum Aufbau eines Vektorindex für den Datensatz mit 49.000 Artikel-Embeddings und Abfrage der 7,3 Mio. eindeutigen Nutzer gegen diesen Index für die Ähnlichkeitssuche.
In diesen Benchmarks haben wir IVFPQ- und HNSW-Indexierungsalgorithmen verwendet, die auf GPU und CPU ausgeführt wurden, zusammen mit verschiedenen Parameterkombinationen. Details sind auf unserer GitHub-Seite verfügbar.
Der Kompromiss zwischen Suchqualität und Durchsatz ist ein wichtiger Leistungsaspekt, insbesondere in einer Produktionsumgebung. Milvus ermöglicht die vollständige Kontrolle über Indexierungsparameter, um diesen Kompromiss für einen bestimmten Anwendungsfall zu untersuchen und bessere Suchergebnisse mit Ground Truth zu erzielen. Dies kann höhere Rechenkosten in Form einer reduzierten Durchsatzrate oder von weniger Abfragen pro Sekunde (QPS) bedeuten. Wir messen die Qualität der ANN-Suche mit einer Recall-Metrik und stellen QPS-Recall-Kurven bereit, die den Kompromiss veranschaulichen. Man kann dann ein akzeptables Niveau der Suchqualität angesichts der Rechenressourcen oder der Latenz-/Durchsatzanforderungen des Geschäftsanwendungsfalls festlegen.
Beachten Sie auch die in unseren Benchmarks verwendete Abfrage-Batchgröße (nq). Dies ist nützlich in Workflows, in denen mehrere gleichzeitige Anfragen an die Inferenz gesendet werden (z. B. Offline-Empfehlungen, die angefordert und an eine Liste von E-Mail-Empfängern gesendet werden, oder Online-Empfehlungen, die durch Bündelung gleichzeitig eingehender Anfragen erstellt und auf einmal verarbeitet werden). Je nach Anwendungsfall kann TIS auch dabei helfen, diese Anfragen in Batches zu verarbeiten.
Ergebnisse
Wir berichten nun die Ergebnisse für die drei Benchmark-Sets sowohl auf CPU als auch auf GPU, unter Verwendung der von Milvus implementierten Indextypen HNSW (nur CPU) und IVF_PQ (CPU und GPU).
Vektorähnlichkeitssuche Items vs. Items
Bei diesem kleinsten Datensatz verwendet jeder Lauf für eine gegebene Parameterkombination 50% der Item-Vektoren als Abfragevektoren und fragt die 100 ähnlichsten Vektoren aus dem Rest ab. HNSW und IVF_PQ erzielen mit den getesteten Parametereinstellungen einen hohen Recall im Bereich von 0,958–1,0 bzw. 0,665–0,997. Dieses Ergebnis legt nahe, dass HNSW hinsichtlich Recall besser abschneidet, IVF_PQ mit kleinen nlist-Einstellungen jedoch einen sehr vergleichbaren Recall erzielt. Wir sollten auch beachten, dass die Recall-Werte je nach Indexierungs- und Abfrageparametern stark variieren können. Die von uns berichteten Werte wurden nach vorläufigen Experimenten mit allgemeinen Parameterbereichen und einer weiteren Fokussierung auf eine ausgewählte Teilmenge erzielt.
Die Gesamtzeit zur Ausführung aller Abfragen auf CPU mit HNSW für eine gegebene Parameterkombination liegt zwischen 5,22 und 5,33 Sek. (schneller, wenn m größer wird, relativ unverändert mit ef) und mit IVF_PQ zwischen 13,67 und 14,67 Sek. (langsamer, wenn nlist und nprobe größer werden). GPU-Beschleunigung hat einen merklichen Effekt, wie in Abbildung 3 zu sehen ist.
Abbildung 3 zeigt den Recall-Durchsatz-Kompromiss über alle auf CPU und GPU mit diesem kleinen Datensatz unter Verwendung von IVF_PQ abgeschlossenen Läufe hinweg. Wir stellen fest, dass GPU über alle getesteten Parameterkombinationen hinweg eine Beschleunigung von 4x bis 15x bietet (größere Beschleunigung, wenn nprobe größer wird). Dies wird berechnet, indem das Verhältnis von QPS aus GPU-Läufen zu QPS aus CPU-Läufen für jede Parameterkombination gebildet wird. Insgesamt stellt dieses Set CPU oder GPU vor geringe Herausforderungen und zeigt Aussichten auf weitere Beschleunigung mit den größeren Datensätzen, wie unten besprochen.
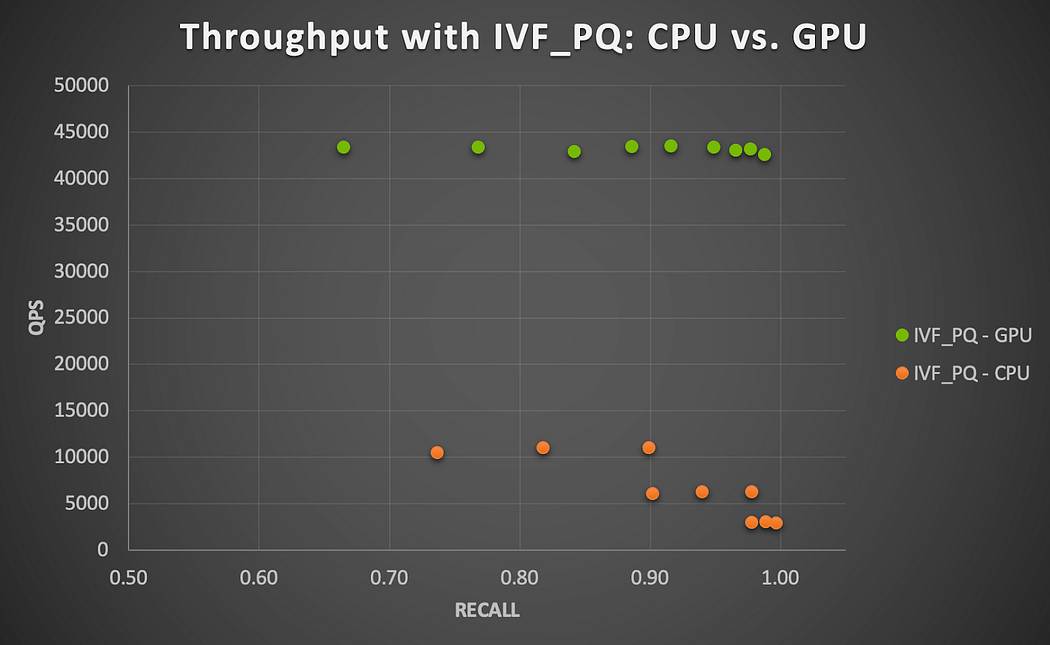
Abbildung 3. GPU-Beschleunigung mit dem Milvus IVF_PQ-Algorithmus auf NVIDIA A100 GPU (Item-Item-Ähnlichkeitssuche)
Vektorähnlichkeitssuche Users vs. Users
Mit dem deutlich größeren zweiten Datensatz (7,3 Mio. Nutzer) legen wir 85% (~6,2 Mio.) der Vektoren als „Train“ (die Menge der zu indexierenden Vektoren) beiseite und die verbleibenden 15% (~1,1 Mio.) als „Test“- bzw. Abfragevektorsatz. HNSW und IVF_PQ schneiden in diesem Fall außergewöhnlich gut ab, mit Recall-Werten von 0,884–1,0 bzw. 0,922–0,999. Sie sind jedoch rechnerisch deutlich anspruchsvoller, insbesondere IVF_PQ auf der CPU. Die Gesamtzeit zur Ausführung aller Abfragen auf CPU mit HNSW reicht von 279,89 bis 295,56 Sek. und mit IVF_PQ von 3082,67 bis 10932,33 Sek. Beachten Sie, dass diese Abfragezeiten kumulativ für 1,1 Mio. abgefragte Vektoren sind, sodass man sagen kann, dass eine einzelne Abfrage gegen den Index immer noch sehr schnell ist.
CPU-basierte Abfragen sind jedoch möglicherweise nicht praktikabel, wenn der Inferenzserver erwartet, dass viele Tausend gleichzeitige Anfragen Abfragen gegen ein Inventar von Millionen von Items ausführen.
Die A100-GPU liefert mit IVF_PQ über alle Parameterkombinationen hinweg eine rasante Beschleunigung um den Faktor 37 bis 91 (durchschnittlich 76,1) in Bezug auf den Durchsatz (QPS), wie in Abbildung 4 gezeigt. Dies stimmt mit dem überein, was wir bei dem kleinen Datensatz beobachtet haben, was darauf hindeutet, dass die GPU-Leistung bei der Verwendung von Milvus mit Millionen von Einbettungsvektoren recht gut skaliert.
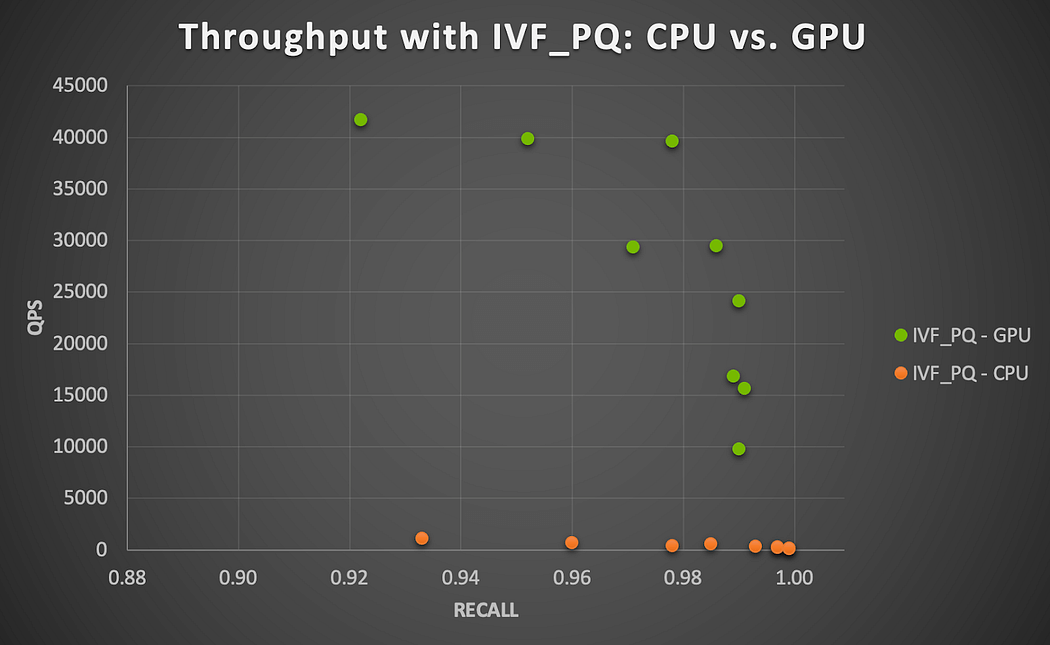
Abbildung 4. GPU-Beschleunigung mit dem Milvus-IVF_PQ-Algorithmus auf einer NVIDIA-A100-GPU (User-User-Ähnlichkeitssuche)
Die folgende detaillierte Abbildung 5 zeigt den Recall-QPS-Kompromiss für alle auf CPU und GPU mit IVF_PQ getesteten Parameterkombinationen. Jede Punktmenge (oben für GPU, unten für CPU) in diesem Diagramm veranschaulicht den Kompromiss, der entsteht, wenn Vektorindexierungs-/Abfrageparameter geändert werden, um einen höheren Recall auf Kosten eines geringeren Durchsatzes zu erreichen. Beachten Sie den erheblichen Verlust an QPS im GPU-Fall, wenn man versucht, höhere Recall-Werte zu erreichen.
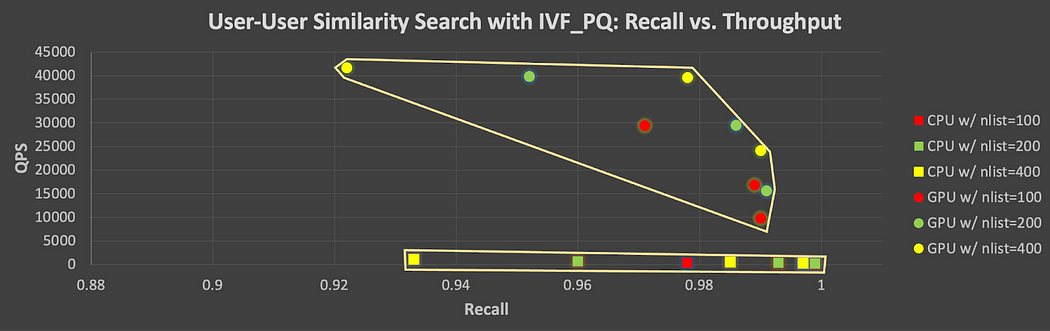
Abbildung 5. Recall-Durchsatz-Kompromiss für alle auf CPU und GPU mit IVF_PQ getesteten Parameterkombinationen (Users vs. Users)
Vektor-Ähnlichkeitssuche Users vs. Items
Schließlich betrachten wir einen weiteren realistischen Anwendungsfall, bei dem User-Vektoren gegen Item-Vektoren abgefragt werden (wie oben in Notebook 01 demonstriert). In diesem Fall werden 49K Item-Vektoren indiziert, und 7,3M User-Vektoren werden jeweils nach den Top 100 ähnlichsten Items abgefragt.
Hier wird es interessant, denn die Abfrage von 7,3M in Batches von 1000 gegen einen Index von 49K Items scheint auf der CPU sowohl für HNSW als auch für IVF_PQ zeitaufwendig zu sein. Die GPU scheint diesen Fall besser zu bewältigen (siehe Abbildung 6). Die höchsten Genauigkeitsstufen von IVF_PQ auf der CPU bei nlist = 100 werden im Durchschnitt in etwa 86 Minuten berechnet, variieren jedoch erheblich, wenn der nprobe-Wert steigt (51 Min. bei nprobe = 5 gegenüber 128 Min. bei nprobe = 20). Die NVIDIA-A100-GPU beschleunigt die Leistung erheblich um den Faktor 4 bis 17 (höhere Beschleunigungen bei größerem nprobe). Denken Sie daran, dass der IVF_PQ-Algorithmus durch seine Quantisierungstechnik auch den Speicherbedarf reduziert und in Kombination mit der GPU-Beschleunigung eine rechnerisch tragfähige ANN-Suchlösung bietet.
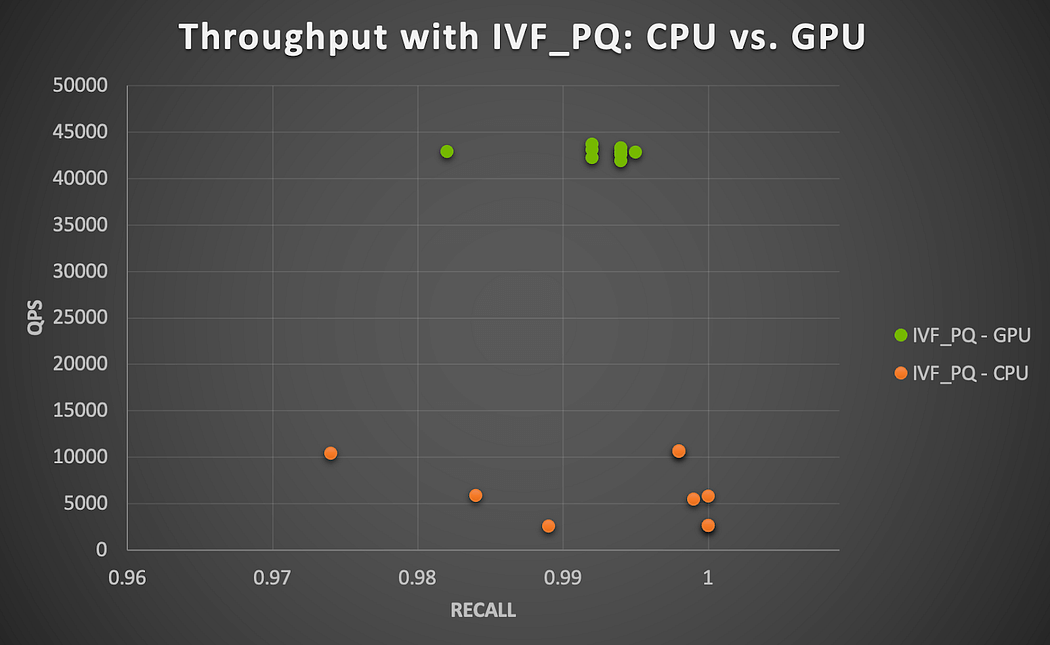
Abbildung 6. GPU-Beschleunigung mit dem Milvus-IVF_PQ-Algorithmus auf einer NVIDIA-A100-GPU (User-Item-Ähnlichkeitssuche)
Ähnlich wie Abbildung 5 zeigt Abbildung 7 den Recall-Durchsatz-Kompromiss für alle mit IVF_PQ getesteten Parameterkombinationen. Hier kann man weiterhin erkennen, dass man bei der ANN-Suche möglicherweise etwas Genauigkeit zugunsten eines höheren Durchsatzes aufgeben muss, obwohl die Unterschiede deutlich weniger auffallen, insbesondere bei GPU-Läufen. Dies deutet darauf hin, dass man mit der GPU relativ konstant hohe Rechenleistungsniveaus erwarten kann und dennoch einen hohen Recall erreicht.
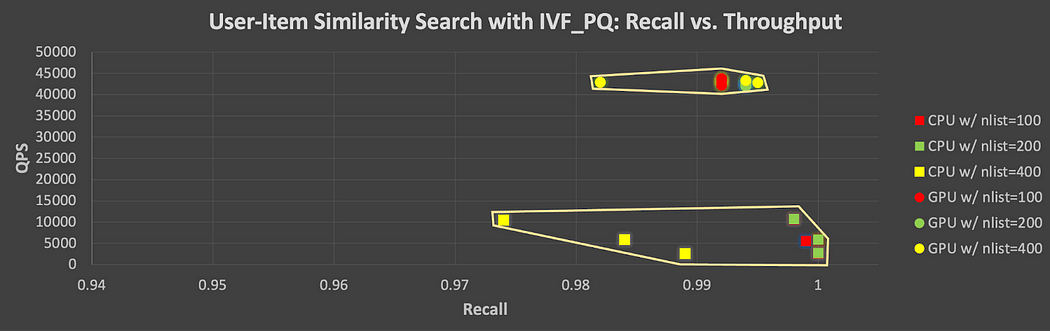
Abbildung 7. Recall-Durchsatz-Kompromiss für alle auf CPU und GPU mit IVF_PQ getesteten Parameterkombinationen (Users vs. Items)
Fazit
Wir teilen gern ein paar abschließende Bemerkungen, wenn Sie bis hierhin gelesen haben. Wir möchten Sie daran erinnern, dass die Komplexität und die mehrstufige Natur moderner Recsys Leistung und Effizienz in jedem Schritt erfordern. Hoffentlich hat Ihnen dieser Blog überzeugende Gründe geliefert, zwei wichtige Funktionen in Ihren RecSys-Pipelines in Betracht zu ziehen:
Die Merlin Systems-Bibliothek von NVIDIA Merlin ermöglicht es Ihnen, Milvus, eine effiziente GPU-beschleunigte Vektorsuchmaschine, einfach zu integrieren.
Verwenden Sie die GPU, um Berechnungen für die Indexierung von Vektordatenbanken und die ANN-Suche mit Technologien wie RAPIDS RAFT zu beschleunigen.

Diese Ergebnisse deuten darauf hin, dass die vorgestellte Merlin-Milvus-Integration hochperformant und deutlich weniger komplex ist als andere Optionen für Training und Inferenz. Außerdem werden beide Frameworks aktiv weiterentwickelt, und in jedem Release werden viele neue Funktionen (z. B. neue GPU-beschleunigte Vektordatenbank-Indizes von Milvus) hinzugefügt. Die Tatsache, dass die Vektorähnlichkeitssuche eine entscheidende Komponente in verschiedenen Workflows ist, etwa in Computer Vision, Large Language Modeling und Empfehlungssystemen, macht diesen Aufwand umso lohnender.
Abschließend möchten wir allen von Zilliz/Milvus sowie den Merlin- und RAFT-Teams danken, die zu den Bemühungen beigetragen haben, diese Arbeit und den Blogbeitrag zu erstellen. Wir freuen uns darauf, von Ihnen zu hören, falls Sie die Gelegenheit haben, Merlin und Milvus in Ihren Recsys- oder anderen Workflows zu implementieren.

Weiterlesen

AI Agents Are Quietly Transforming E-Commerce — Here’s How
Discover how AI agents transform e-commerce with autonomous decision-making, enhanced product discovery, and vector search capabilities for today's retailers.

How to Use Anthropic MCP Server with Milvus
MCP + Milvus: Streamline AI agent development with standardized data access, eliminating integration hassles while enhancing context and flexibility.

VidTok: Rethinking Video Processing with Compact Tokenization
VidTok tokenizes videos to reduce redundancy while preserving spatial and temporal details for efficient processing.