




Aufbau eines Shopping-Erlebnisses mit Bildersuche mit VOVA und Milvus
Springen zu:
- Wie funktioniert die Bildsuche?
- Zielerkennung mit dem YOLO-Modell
- Extraktion von Bildmerkmalsvektoren mit ResNet
- Vektorenähnlichkeitssuche mit Milvus
- VOVAs Shop-by-Image-Tool
Der Online-Einkauf nahm 2020 stark zu, um 44%, was zu einem großen Teil auf die Coronavirus-Pandemie zurückzuführen war. Da die Menschen soziale Distanz wahren und den Kontakt mit Fremden vermeiden wollten, wurde die kontaktlose Lieferung für viele Verbraucher zu einer äußerst attraktiven Option. Diese Beliebtheit hat auch dazu geführt, dass Menschen eine größere Vielfalt an Waren online kaufen, darunter Nischenartikel, die sich mit einer herkömmlichen Stichwortsuche nur schwer beschreiben lassen.
Um Nutzern zu helfen, die Grenzen stichwortbasierter Abfragen zu überwinden, können Unternehmen Bildsuchmaschinen entwickeln, die es Nutzern ermöglichen, Bilder statt Wörter für die Suche zu verwenden. Dies ermöglicht Nutzern nicht nur, schwer zu beschreibende Artikel zu finden, sondern hilft ihnen auch beim Einkauf von Dingen, denen sie im wirklichen Leben begegnen. Diese Funktionalität trägt dazu bei, ein einzigartiges Nutzererlebnis zu schaffen, und bietet allgemeinen Komfort, den Kunden schätzen.
VOVA ist eine aufstrebende E-Commerce-Plattform, die sich auf Erschwinglichkeit und ein positives Einkaufserlebnis für ihre Nutzer konzentriert, mit Angeboten, die Millionen von Produkten umfassen, sowie Unterstützung für 20 Sprachen und 35 wichtige Währungen. Um das Einkaufserlebnis für seine Nutzer zu verbessern, nutzte das Unternehmen Milvus, um eine Bildsuchfunktion in seine E-Commerce-Plattform zu integrieren. Der Artikel untersucht, wie VOVA erfolgreich eine Bildsuchmaschine mit Milvus aufgebaut hat.
Wie funktioniert die Bildsuche?
VOVAs Shop-by-Image-System durchsucht den Bestand des Unternehmens nach Produktbildern, die den Uploads der Nutzer ähnlich sind. Die folgende Grafik zeigt die zwei Phasen des Systemprozesses, die Datenimportphase (blau) und die Abfragephase (orange):
- Verwenden Sie das YOLO-Modell, um Ziele aus hochgeladenen Fotos zu erkennen;
- Verwenden Sie ResNet, um Merkmalsvektoren aus den erkannten Zielen zu extrahieren;
- Verwenden Sie Milvus für die Vektorenähnlichkeitssuche.
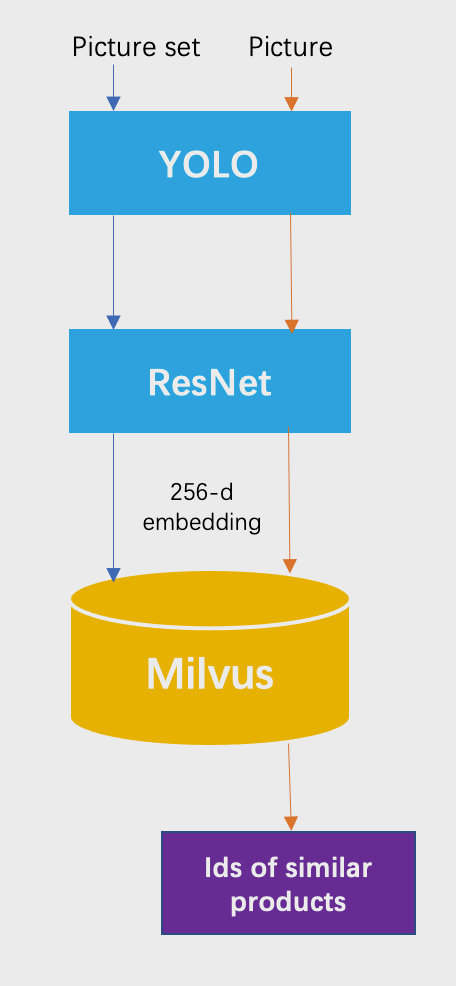 Systemprozess der Search-by-Image-Funktionalität von VOVA.
Systemprozess der Search-by-Image-Funktionalität von VOVA.
Zielerkennung mit dem YOLO-Modell
VOVAs mobile Apps auf Android und iOS unterstützen derzeit die Bildsuche. Das Unternehmen verwendet ein hochmodernes Echtzeit-Objekterkennungssystem namens YOLO (You only look once), um Objekte in von Nutzern hochgeladenen Bildern zu erkennen. Das YOLO-Modell befindet sich derzeit in seiner fünften Iteration.
YOLO ist ein einstufiges Modell, das nur ein einziges Convolutional Neural Network (CNN) verwendet, um Kategorien und Positionen verschiedener Ziele vorherzusagen. Es ist klein, kompakt und gut für den mobilen Einsatz geeignet.
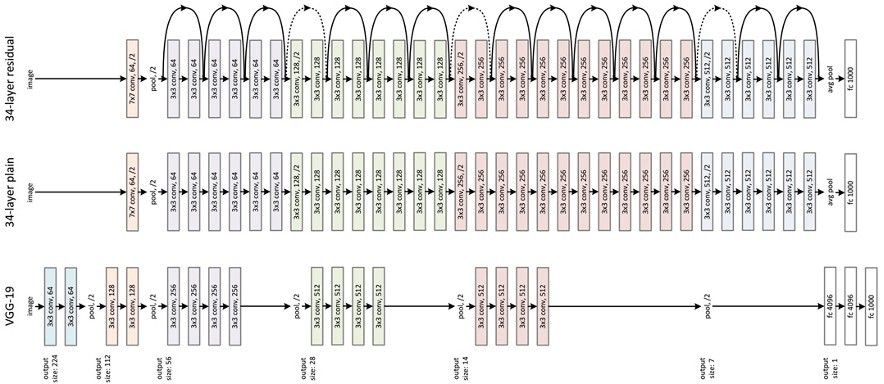
YOLO verwendet Convolutional Layers, um Merkmale zu extrahieren, und Fully-Connected Layers, um vorhergesagte Werte zu erhalten. Inspiriert vom GooLeNet-Modell umfasst YOLOs CNN 24 Convolutional Layers und zwei Fully-Connected Layers.
Wie die folgende Abbildung zeigt, wird ein 448 × 448-Eingabebild durch eine Reihe von Convolutional Layers und Pooling Layers in einen 7 × 7 × 1024-dimensionalen Tensor umgewandelt (im drittletzten Würfel unten dargestellt) und anschließend durch zwei Fully-Connected Layers in eine 7 × 7 × 30-dimensionale Tensor-Ausgabe umgewandelt.
Die vorhergesagte Ausgabe von YOLO P ist ein zweidimensionaler Tensor, dessen Form [batch,7 ×7 ×30] ist. Mithilfe von Slicing ist P[:,0:7×7×20] die Kategorienwahrscheinlichkeit, P[:,7×7×20:7×7×(20+2)] die Konfidenz, und P[:,7×7×(20+2)]:] ist das vorhergesagte Ergebnis der Bounding Box.
 YOLO-Netzwerkarchitektur.
YOLO-Netzwerkarchitektur.
Extraktion von Bildmerkmalsvektoren mit ResNet
VOVA nutzte das Residual Neural Network (ResNet)-Modell, um Merkmalsvektoren aus einer umfangreichen Produktbildbibliothek und von Nutzern hochgeladenen Fotos zu extrahieren. ResNet ist eingeschränkt, da mit zunehmender Tiefe eines lernenden Netzwerks die Genauigkeit des Netzwerks abnimmt. Das folgende Bild zeigt ResNet beim Ausführen des VGG19-Modells (einer Variante des VGG-Modells), das so modifiziert wurde, dass es durch den Kurzschlussmechanismus eine Residualeinheit enthält. VGG wurde 2014 vorgeschlagen und umfasst nur 14 Schichten, während ResNet ein Jahr später erschien und bis zu 152 haben kann.
Die ResNet-Struktur lässt sich leicht modifizieren und skalieren. Durch Ändern der Anzahl der Kanäle im Block und der Anzahl der gestapelten Blöcke können Breite und Tiefe des Netzwerks einfach angepasst werden, um Netzwerke mit unterschiedlichen Ausdrucksfähigkeiten zu erhalten. Dies löst effektiv den Effekt der Netzwerkdegeneration, bei dem die Genauigkeit mit zunehmender Lerntiefe abnimmt. Mit ausreichenden Trainingsdaten kann ein Modell mit verbesserter Ausdrucksleistung erhalten werden, während das Netzwerk schrittweise vertieft wird. Durch Modelltraining werden Merkmale für jedes Bild extrahiert und in 256-dimensionale Gleitkommavektoren umgewandelt.
 ResNet-Struktur.
ResNet-Struktur.
Vektorähnlichkeitssuche powered by Milvus
Die Produktbilddatenbank von VOVA umfasst 30 Millionen Bilder und wächst schnell. Um die ähnlichsten Produktbilder aus diesem riesigen Datensatz schnell abzurufen, wird Milvus verwendet, um eine Vektorähnlichkeitssuche durchzuführen. Dank einer Reihe von Optimierungen bietet Milvus einen schnellen und optimierten Ansatz zur Verwaltung von Vektordaten und zum Erstellen von Machine-Learning-Anwendungen. Milvus bietet Integration mit beliebten Indexbibliotheken (z. B. Faiss, Annoy), unterstützt mehrere Indextypen und Distanzmetriken, verfügt über SDKs in mehreren Sprachen und stellt umfangreiche APIs zur Verwaltung von Vektordaten bereit.
Milvus kann Ähnlichkeitssuchen auf Datensätzen mit Billionen von Vektoren in Millisekunden durchführen, mit einer Abfragezeit von unter 1,5 Sekunden bei nq=1 und einer durchschnittlichen Batch-Abfragezeit von unter 0,08 Sekunden. Zum Aufbau seiner Bildsuchmaschine orientierte sich VOVA am Design von Mishards, Milvus' Sharding-Middleware-Lösung (siehe Diagramm unten für das Systemdesign), um einen hochverfügbaren Servercluster zu implementieren. Durch Nutzung der horizontalen Skalierbarkeit eines Milvus-Clusters wurde die Projektanforderung an eine hohe Abfrageleistung auf riesigen Datensätzen erfüllt.
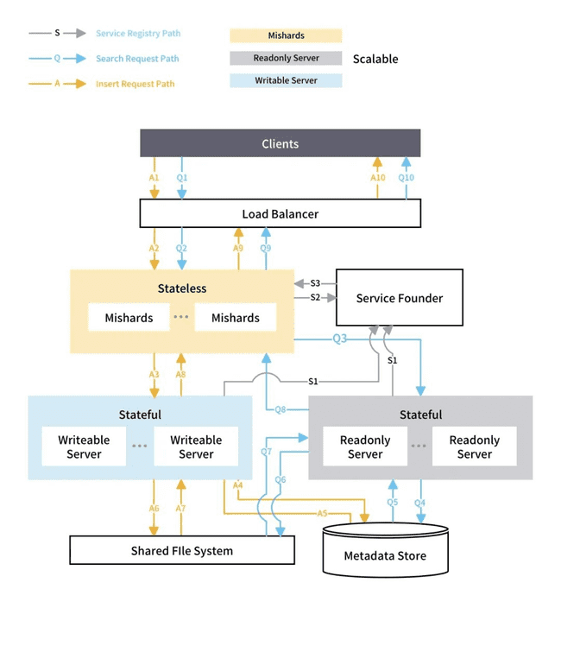 Mishards-Architektur in Milvus.
Mishards-Architektur in Milvus.
VOVAs Shop-by-Image-Tool
Die folgenden Screenshots zeigen das VOVA-Shopping-Tool für die Suche per Bild in der Android-App des Unternehmens.
 Screenshots von VOVAs Shopping-Tool für die Suche per Bild.
Screenshots von VOVAs Shopping-Tool für die Suche per Bild.
Da immer mehr Nutzer nach Produkten suchen und Fotos hochladen, wird VOVA die Modelle, die das System antreiben, weiter optimieren. Darüber hinaus wird das Unternehmen neue Milvus-Funktionen integrieren, die das Online-Shopping-Erlebnis seiner Nutzer weiter verbessern können.
Referenz
YOLO:
https://arxiv.org/pdf/1506.02640.pdf
https://arxiv.org/pdf/1612.08242.pdf
ResNet:
https://arxiv.org/abs/1512.03385
Milvus:
https://milvus.io/docs/overview.md
Weiterlesen

Build Multimodal Search for 3D Assets with Tripo and Zilliz Cloud
Generate 3D assets with Tripo, then search them by text, image, and metadata with multimodal embeddings and Zilliz Cloud.

How to Choose the Best Embedding Model for RAG in 2026: 10 Models Benchmarked
We benchmarked 10 embedding models on cross-modal, cross-lingual, long-document, and dimension compression tasks. See which one fits your RAG pipeline.

Zilliz Cloud Just Landed in Claude Code
The Zilliz Cloud Plugin brings the full power of Zilliz Cloud directly into your Claude Code terminal as natural-language conversations.