




Anatomie eines Cloud-nativen Vektordatenbank-Managementsystems
Es ist mir eine Ehre, dass unser neuestes Paper, "Manu: A Cloud Native Vector Database Management System", von VLDB'22 akzeptiert wurde, einer führenden internationalen Konferenz in der Datenbankforschung. In diesem Artikel werde ich die zentrale Designphilosophie und die Prinzipien hinter Manu (Projektname für Milvus 2.0) erläutern, einer cloudnativen Datenbank, die speziell für das Management von Vektordaten entwickelt wurde. Weitere Informationen finden Sie in unseren früheren Papers und in unserem GitHub-Repository.
Hintergrund
Als wir Milvus 1.0 entwickelten, war unser Hauptziel schlicht, Vektormanagement zu unterstützen und die Leistung der Vektorsuche zu optimieren. Doch als wir im Laufe der Jahre mit immer mehr Nutzern in Kontakt kamen, stellten wir fest, dass es einige gemeinsame geschäftliche Anforderungen an Vektordatenbanken gibt, die im ursprünglichen Framework nur schwer zu erfüllen waren.
Diese Anforderungen lassen sich in die folgenden Kategorien einteilen: sich ständig ändernde Anforderungen, eine flexiblere Konsistenzrichtlinie, Elastizität auf Komponentenebene und ein einfacheres, effizienteres Modell für die Transaktionsverarbeitung.
Sich ständig ändernde Anforderungen
Geschäftliche Anforderungen sind im Bereich der Vektordatenverarbeitung noch immer nicht vollständig definiert.
In den frühesten Tagen war die Suche nach den K nächsten Nachbarn am gefragtesten. Doch dann tauchten immer mehr Anforderungen auf, darunter Bereichssuche, Unterstützung verschiedener benutzerdefinierter Distanzmetriken, hybride Suche, multimodale Abfragen und andere zunehmend vielfältige Abfragesemantiken.
Dies erfordert, dass die Architektur einer Vektordatenbank flexibel genug ist, um neue Anforderungen schnell und agil zu unterstützen.
Eine flexiblere Konsistenzrichtlinie
Nehmen wir Content-Empfehlungen als Beispiel: Dieses Szenario stellt hohe Anforderungen an die Aktualität. Neue Inhalte müssen den Nutzern innerhalb weniger Minuten oder sogar Sekunden empfohlen werden, sodass das System nicht einen Tag oder länger benötigen darf, um seine Empfehlung zu aktualisieren. In diesen Szenarien ist es schwierig, Geschäftsergebnisse zu garantieren, wenn nur eventual consistency bereitgestellt wird, während ein großer System-Overhead entsteht, wenn wir auf strong consistency bestehen.
Um dieses Problem zu lösen, schlagen wir die folgende Lösung vor: Entsprechend den geschäftlichen Anforderungen können Nutzer die maximale Verzögerung angeben, die toleriert werden kann, bevor die eingefügten Daten abgefragt werden können. Das System passt wiederum bestimmte Datenverarbeitungsmechanismen an, um das endgültige Ergebnis für das Geschäft zu gewährleisten.
Elastizität auf Komponentenebene
Ressourcenanforderungen und Lastintensität variieren bei den einzelnen Komponenten einer Vektordatenbank in unterschiedlichen Anwendungen stark. Beispielsweise benötigen Vektorsuche- und Abfragekomponenten große Rechen- und Speicherressourcen, um ihre Leistung sicherzustellen, während Datenarchivierung und Metadatenmanagement nur wenige Ressourcen benötigen, um zu funktionieren.
Bei Anwendungen ist die kritischste Anforderung für Empfehlungssysteme die Fähigkeit, parallele Abfragen in großem Maßstab durchzuführen, und daher trägt in diesen Systemen nur die Abfragekomponente eine höhere Last. Analyseanwendungen hingegen müssen häufig eine große Menge an Offline-Daten importieren, sodass der Lastdruck auf die Dateneinfügung und den Indexaufbau fällt, zwei miteinander verbundene Komponenten.
Um die Ressourcennutzung zu verbessern, ist es notwendig, dass jedes Funktionsmodul über eine unabhängige und elastische Skalierbarkeit verfügt, damit die Ressourcenzuweisung des Systems enger an die tatsächlichen Anforderungen einer Anwendung angepasst werden kann.
Ein einfacheres, effizienteres Modell für die Transaktionsverarbeitung
Streng genommen ist das Transaktionsmodell eher ein Optimierungsspielraum, der im Systemdesign genutzt werden kann, als eine geschäftliche Anforderung.
Da sich maschinelles Lernen in seiner deskriptiven Leistungsfähigkeit weiterentwickelt, neigen Unternehmen dazu, Daten aus mehreren Dimensionen einer einzelnen Entität zusammenzuführen, um sie als einen einzigen, einheitlichen Vektor darzustellen. Beispielsweise werden beim User Profiling Informationen wie persönliche Profile, Präferenzen und soziale Beziehungen zusammengeführt. Infolgedessen können Vektordatenbanken mit nur einer einzigen Tabelle verwaltet werden, ohne JOIN-ähnliche Operationen implementieren zu müssen, die in traditionellen Datenbanken üblich sind. Auf diese Weise muss das System nur ACID auf Zeilenebene für eine einzelne Tabelle unterstützen und kann auf komplexe Transaktionen verzichten, die mehrere Tabellen umfassen, wodurch im System großer Spielraum für Komponentenentkopplung und Leistungsoptimierung bleibt.
Ziele
Als zweite Hauptversion von Milvus ist Manu als cloud-natives, verteiltes Vektordatenbanksystem positioniert.
Als wir mit dem Design von Manu begannen, berücksichtigten wir die verschiedenen oben genannten Geschäftsanforderungen und kombinierten sie mit den allgemeinen Anforderungen an ein verteiltes System. Das Ergebnis sind fünf übergeordnete Ziele für Manu: langfristige Weiterentwickelbarkeit, abstimmbare Konsistenz, gute Elastizität, hohe Verfügbarkeit und hohe Leistung.
Langfristige Weiterentwickelbarkeit
Um die Komplexität des Systems auf einem beherrschbaren Niveau zu halten, während sich die Funktionalitäten weiterentwickeln, müssen wir das System gut entkoppeln, um sicherzustellen, dass einzelne Komponenten unabhängig weiterentwickelt, hinzugefügt oder ersetzt werden können, mit minimaler Beeinträchtigung anderer Komponenten.
Abstimmbare Konsistenz
Das System muss Delta-Konsistenz unterstützen, damit Benutzer die Sichtbarkeitsverzögerung von Abfragen für neu eingefügte Daten festlegen können. Delta-Konsistenz erfordert, dass alle Abfragen alle relevanten Daten mindestens bis zur Delta-Zeiteinheit zurückgeben können, die von der Benutzeranwendung basierend auf Geschäftsanforderungen festgelegt werden kann.
Gute Elastizität
Um die Effizienz der Ressourcennutzung zu verbessern, muss das System feingranulare Elastizität auf Komponentenebene erreichen sowie eine Ressourcenzuweisungsrichtlinie bieten, die verschiedene Hardware-Abhängigkeiten der Komponenten berücksichtigt.
Hohe Verfügbarkeit und Leistung
Hohe Verfügbarkeit ist die grundlegende Anforderung aller Cloud-Datenbanken, die verlangt, dass bei Ausfall einiger Service-Knoten oder Komponenten andere Dienste nicht betroffen sind und dass das System zu effektiver Fehlerbehebung fähig ist.
Hohe Leistung ist ein Klischee für Vektordatenbanken. Im Designprozess müssen wir den auf System-Framework-Ebene entstehenden Overhead streng kontrollieren, um gute Leistung sicherzustellen.
Manu-Architektur
Manu verwendet eine Vier-Schichten-Architektur, die die Entkopplung von Lesen und Schreiben, zustandslos und zustandsbehaftet sowie Speicherung und Computing ermöglicht.
Wie in der folgenden Abbildung gezeigt, hat Manu von oben nach unten vier Schichten, d. h. Zugriffsschicht, Koordinatorenschicht, Worker-Schicht und Speicherschicht. Manu verwendet außerdem ein Log-System als Rückgrat, das die entkoppelten Komponenten verbindet.
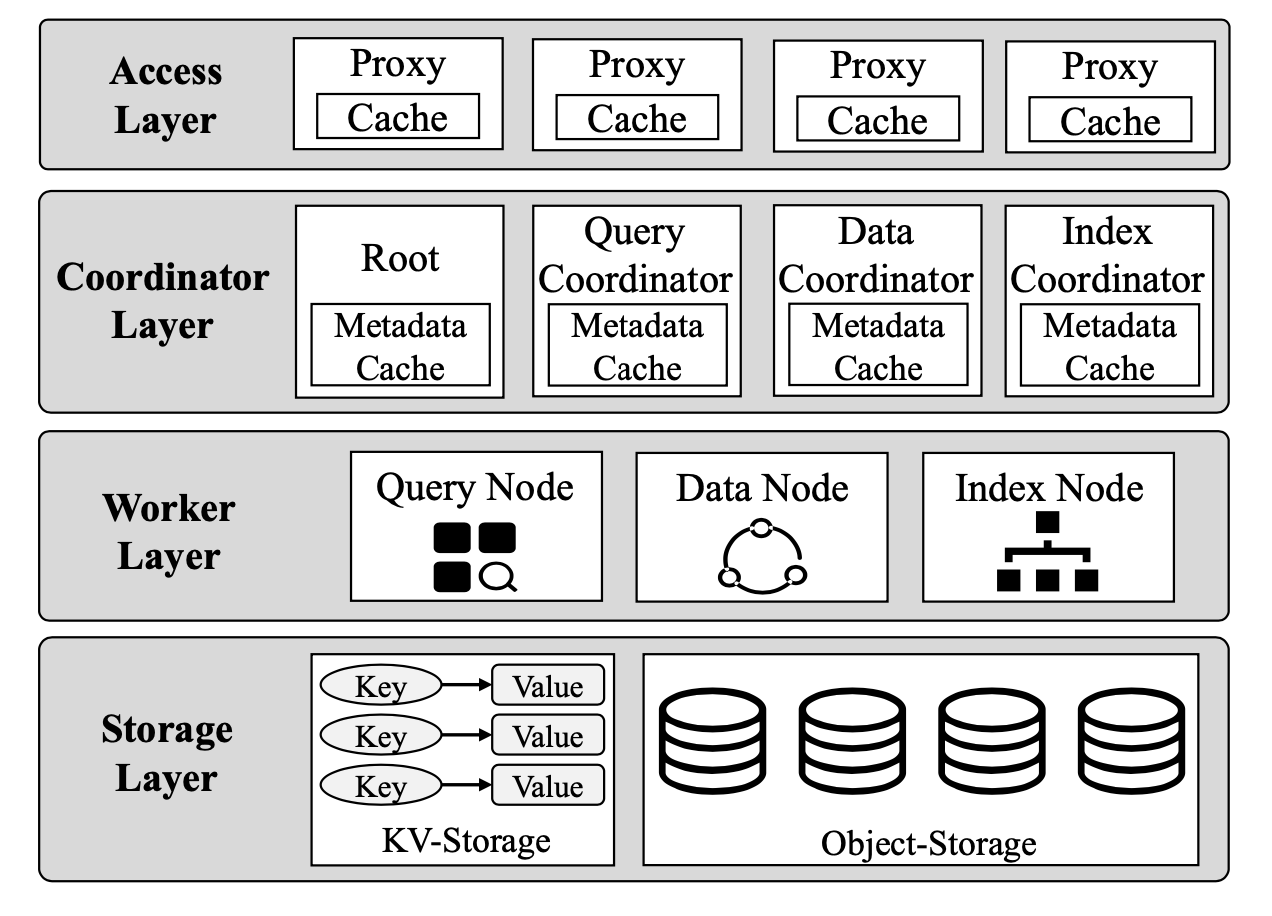 Manu-Architektur.
Manu-Architektur.
Zugriffsschicht
Die Zugriffsschicht besteht aus zustandslosen Proxys, die als Benutzer-Endpunkte dienen.
Diese Proxys empfangen Anfragen von Clients, verteilen die Anfragen an die entsprechenden Komponenten und sammeln die Ergebnisse, bevor sie sie an die Clients zurückgeben. Außerdem cachen die Proxys eine Kopie der Metadaten, um die Legitimität der Suchanfragen zu überprüfen (z. B. ob die zu durchsuchende Collection existiert).
Koordinatorenschicht
Die Koordinatorenschicht verwaltet den Systemstatus, pflegt Metadaten und koordiniert die Systemkomponenten zur Verarbeitung von Aufgaben.
Es gibt vier Arten von Koordinatoren, die jeweils unabhängig für unterschiedliche Funktionalitäten entwickelt wurden. Auf diese Weise können Systemausfälle isoliert und die Komponenten separat weiterentwickelt werden. Aus Zuverlässigkeitsgründen kann jeder Koordinator mehrere Instanzen haben (z. B. eine Hauptinstanz und zwei Backups).
Root Coordinator
Root-Koordinator verarbeitet Daten-Definitionsanfragen, wie das Erstellen/Löschen von Collections, und verwaltet die Meta-Informationen der Collections (z. B. die Eigenschaften der Collections, den Datentyp jeder Eigenschaft).
Datenkoordinator
Datenkoordinator befasst sich mit der Persistenz von Daten. Er koordiniert die Datenknoten, um Anfragen zur Aktualisierung von Daten in Binlogs umzuwandeln, und zeichnet die detaillierten Informationen der Collections auf (z. B. die Liste der Segmente jeder Collection, den Speicherpfad jedes Segments).
Index-Koordinator
Index-Koordinator verwaltet die Datenindizierung. Er koordiniert Indexknoten für Indizierungsaufgaben und zeichnet die Indexinformationen jeder Collection auf (z. B. Indextyp, zugehörige Parameter, Speicherpfad usw.).
Abfragekoordinator
Abfragekoordinator überwacht den Status der Abfrageknoten und passt die Zuweisung von Segmenten (zusammen mit zugehörigen Indizes) zu Abfrageknoten für den Lastausgleich an.
Worker-Schicht
Die Worker-Schicht führt die mehreren Aufgaben im System aus.
Alle Worker-Knoten sind zustandslos - sie rufen schreibgeschützte Kopien von Daten ab, um Aufgaben auszuführen, und müssen sich nicht miteinander koordinieren. Daher kann die Anzahl der Worker-Knoten flexibel entsprechend der Last angepasst werden. Außerdem verwendet Manu verschiedene Worker-Knoten für verschiedene Aufgaben, sodass jeder Knotentyp unabhängig entsprechend der tatsächlichen Last und den QoS-Anforderungen skaliert werden kann.
Speicherschicht
Die Speicherschicht speichert Systemstatusinformationen, Metadaten, Collections und zugehörige Indizes persistent.
Manu verwendet hochverfügbare verteilte KV-Speicher (Key-Value) wie etcd, um Systemstatusinformationen und Metadaten zu speichern. Wenn Metadaten aktualisiert werden, werden die Daten zuerst in den KV-Speicher geschrieben und dann mit den relevanten Koordinatoren synchronisiert. Daten mit großem Volumen, wie die von Collections und Indizes, werden mit Objektspeicherdiensten wie AWS S3 verwaltet. Die hohe Latenz, die mit Objektspeicher einhergeht, ist kein Leistungsengpass, da die Worker-Knoten schreibgeschützte Kopien der Daten aus dem Objektspeicher abrufen und sie vor der Verarbeitung der Daten lokal zwischenspeichern, sodass die meiste Datenverarbeitung lokal erfolgt.
Log-Backbone
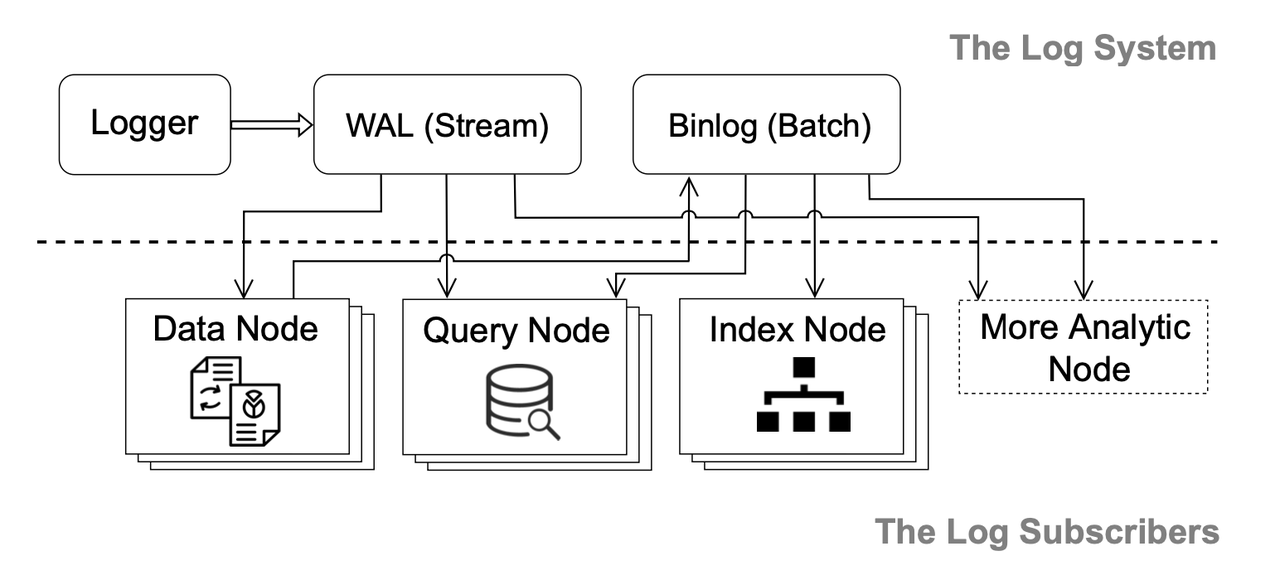 Log-Backbone.
Log-Backbone.
Um die Systemkomponenten (z. B. WAL, Binlog, Datenknoten, Indexknoten und Abfrageknoten) besser zu entkoppeln, sodass sie jeweils unabhängig skaliert und weiterentwickelt werden können, folgt Manu dem Paradigma "log as data" und verwendet ein Log-System als Backbone, das die entkoppelten Systemkomponenten verbindet. In Manu können Logs dauerhaft von verschiedenen Systemkomponenten abonniert werden, die daher als Abonnenten der Logs bezeichnet werden.
Die Logs in Manu können in das Write-Ahead Log (WAL) und Binlog unterteilt werden. Das WAL ist der inkrementelle Teil des Systemlogs, während das Binlog der Basisteil ist. Sie ergänzen sich gegenseitig hinsichtlich Verzögerung, Kapazität und Kosten.
Wie in der obigen Abbildung gezeigt, sind Logger die Einstiegspunkte des Log-Systems und veröffentlichen Daten auf dem WAL. Datenknoten abonnieren das WAL und wandeln die zeilenbasierten WALs in spaltenbasierte Binlogs um. Alle schreibgeschützten Komponenten wie Indexknoten und Abfrageknoten sind unabhängige Abonnenten des Log-Dienstes, um sich auf dem neuesten Stand zu halten.
Das Log-System dient auch dazu, Nachrichten zwischen Komponenten zu übermitteln. Mit anderen Worten, Komponenten können Systemereignisse über Logs übertragen. Beispielsweise können Datenknoten andere Komponenten darüber informieren, welche Segmente in den Objektspeicher geschrieben wurden, und Indexknoten können alle Abfragekoordinatoren informieren, sobald neue Indizes erstellt wurden. Darüber hinaus werden verschiedene Arten von Nachrichten auf verschiedenen Kanälen organisiert. Jede Komponente muss nur ihren entsprechenden Kanal abonnieren, anstatt alle Broadcast-Logs abzuhören.
Datenverarbeitungs-Workflow
Dieser Abschnitt erläutert den Datenverarbeitungs-Workflow innerhalb von Manu und stellt den Prozess der Dateneinfügung, Indexerstellung und Abfrageausführung vor.
Dateneinfügung
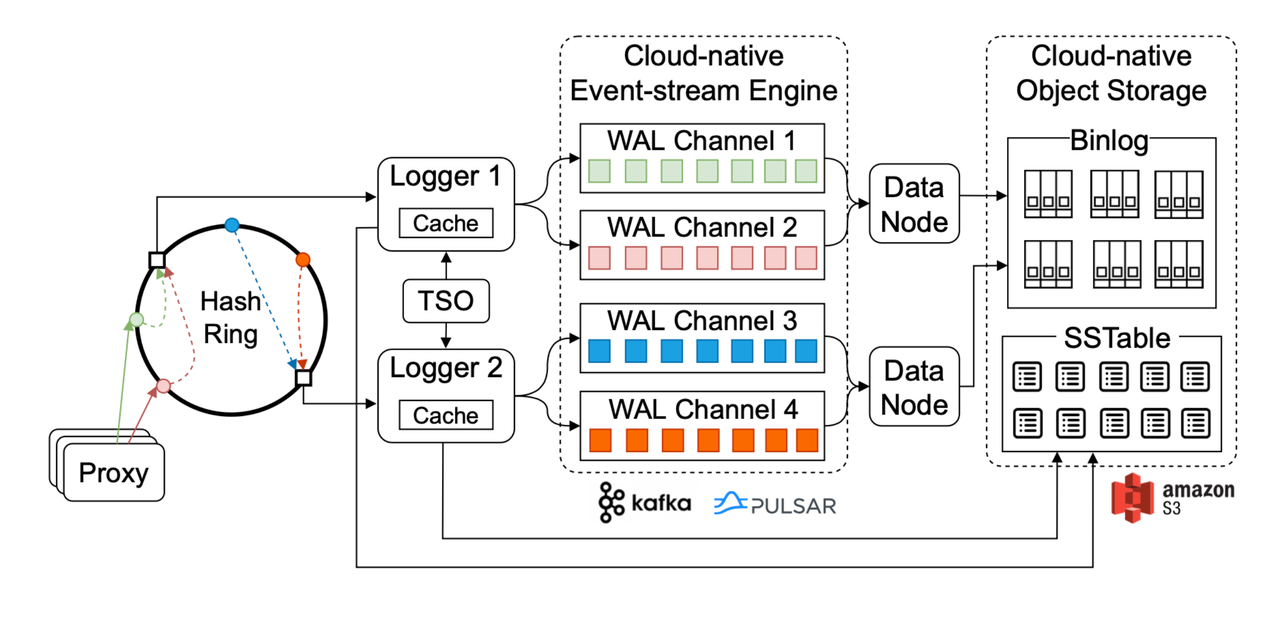 Workflow der Dateneinfügung.
Workflow der Dateneinfügung.
Die obige Abbildung veranschaulicht den Workflow der Dateneinfügung in Manu und die relevanten beteiligten Komponenten.
Nachdem sie vom Proxy verarbeitet wurden, werden Dateneinfügungsanforderungen auf der Grundlage von Hash-Algorithmen auf mehrere Buckets verteilt. Im Allgemeinen gibt es im Manu-System mehrere Logger, die die Entitäten in jedem Hash-Bucket auf der Grundlage von Consistent Hashing verarbeiten. Entitäten in jedem Hash-Bucket werden in einen Write-Ahead-Log-(WAL-)Kanal geschrieben, der nur diesem Bucket zugeordnet ist. Wenn ein Logger eine Dateneinfügungsanforderung erhält, weist er dieser Anforderung eine global eindeutige Log Sequence Number (LSN) zu und schreibt sie in den entsprechenden WAL-Kanal. Die LSN wird vom zentralen Zeitdienst-Oracle (TSO) generiert. Jeder Logger muss in regelmäßigen Abständen eine LSN vom TSO empfangen und die LSN lokal speichern.
Um sicherzustellen, dass Log-Pub/Sub eine geringe Verzögerung aufweist und feingranular ist, werden Entitäten in Manu zeilenbasiert im WAL gespeichert, und jede Komponente, die den WAL abonniert, liest Daten daraus auf Streaming-Weise. In den meisten Fällen kann WAL über eine cloudbasierte Message Queue wie Kafka oder Pulsar implementiert werden. Datenknoten abonnieren die WALs und wandeln die zeilenbasierten WALs in spaltenbasierte Binlogs um. Die spaltenbasierte Natur von Binlog erleichtert das Komprimieren und den Zugriff auf Daten. Ein Beispiel für diese Effizienz zeigt sich bei den Indexknoten. Indexknoten lesen nur die erforderliche Vektorspalte aus dem Binlog für den Indexaufbau und sind somit frei von Leseverstärkungen.
Indexaufbau
Es gibt zwei Szenarien für den Indexaufbau in Manu – Batch-Indexierung und Stream-Indexierung. Batch-Indexierung erfolgt, wenn der Benutzer einen Index für eine gesamte Collection erstellt (z. B. wenn alle Vektoren mit einem neuen Embedding-Modell aktualisiert werden). In diesem Fall erhält der Indexkoordinator die Pfade aller Segmente in der Collection vom Datenkoordinator und weist Indexknoten an, für jedes Segment einen Index zu erstellen. Stream-Indexierung findet statt, wenn Benutzer kontinuierlich neue Entitäten einfügen und Indizes asynchron on-the-fly erstellt werden, ohne Suchdienste zu unterbrechen.
Wenn der Datenknoten ein neues Segment in den Binlog schreibt, benachrichtigt der Datenkoordinator den Indexkoordinator, eine Aufgabe für einen Indexknoten zu erstellen, um einen Index auf dem neuen Segment zu erstellen. Sowohl in Batch- als auch in Stream-Indexierungsszenarien speichert der Indexknoten, nachdem der erforderliche Index für ein Segment erstellt wurde, diesen im Objektspeicher und sendet den Speicherpfad an den Indexkoordinator, wobei er den Abfragekoordinator benachrichtigt, damit Abfrageknoten den Index zur Verarbeitung von Abfragen laden können.
Abfrageausführung
Manu partitioniert eine Collection in Segmente und verteilt die Segmente auf Abfrageknoten, um Abfrageanforderungen parallel auszuführen. Die Proxys cachen eine Kopie der Verteilung der Segmente auf Abfrageknoten, indem sie den Abfragekoordinator anfragen, und leiten Suchanforderungen an Abfrageknoten weiter, die Segmente der durchsuchten Collection halten. Die Abfrageknoten führen Vektorabfragen auf ihren lokalen Segmenten aus, führen die Ergebnisse zusammen und geben sie an den Proxy zurück. Der Proxy aggregiert die Ergebnisse jedes Abfrageknotens weiter und gibt die endgültigen Ergebnisse an den Client zurück.
Abfrageknoten beziehen Daten aus drei Quellen – dem WAL, den Indexdateien und dem Binlog. Für historische Daten lesen Abfrageknoten die entsprechenden Binlogs oder Indexdateien aus dem Objektspeicher. Für inkrementelle Daten hingegen lesen Abfrageknoten direkt aus dem WAL auf Streaming-Weise. Das Beziehen inkrementeller Daten aus dem Binlog führt zu Latenz bei der Datensichtbarkeit, was insbesondere bei großen Suchanforderungen zutrifft. Mit anderen Worten: Neu eingefügte Daten stehen erst nach langer Zeit für Abfragen zur Verfügung, was in manchen Szenarien den Bedarf an hoher Konsistenz nicht erfüllt.
Wie bereits erwähnt, verwendet Manu ein Delta-Konsistenzmodell, um Benutzern eine flexiblere Abstimmung der Konsistenzstufen zu ermöglichen. Delta-Konsistenz stellt sicher, dass die aktualisierten Daten (einschließlich eingefügter und gelöschter Daten) bis zu delta-Zeiteinheiten nach Eingang der Datenaktualisierungsanforderung bei Manu abgefragt und gesucht werden können.
Manu erreicht Delta-Konsistenz, indem allen Dateneinfügungs- und Abfrageanforderungen LSNs mit Zeitstempeln hinzugefügt werden. Bei der Ausführung von Abfrageanforderungen prüft der Abfrageknoten den Zeitstempel der Anforderung (Lr) und den Zeitstempel der neuesten Datenaktualisierungsanforderung, die vom Abfrageknoten verarbeitet wurde (Ls). Die Abfrageanforderung wird nur ausgeführt, wenn das Intervall zwischen Lr und Ls kleiner als delta ist. Andernfalls wartet die Abfrageanforderung auf die Ausführung, bis die in WAL aufgezeichneten Datenaktualisierungen verarbeitet wurden. Wenn jedoch über einen langen Zeitraum keine Datenaktualisierung erfolgt, wird das Zeitintervall zwischen Ls und der aktuellen Systemzeit so klein, dass Abfragen blockiert werden. Um ein solches Problem zu verhindern, fügt Manu regelmäßig Kontrollinformationen in das WAL ein und zwingt den Abfrageknoten so, seinen Zeitstempel zu aktualisieren.
Leistungsbewertung
In der Arbeit haben wir Manu außerdem in reale Anwendungen integriert und eine Gesamtbewertung der Systemleistung durchgeführt. Im Folgenden sind einige der Bewertungsergebnisse aufgeführt.
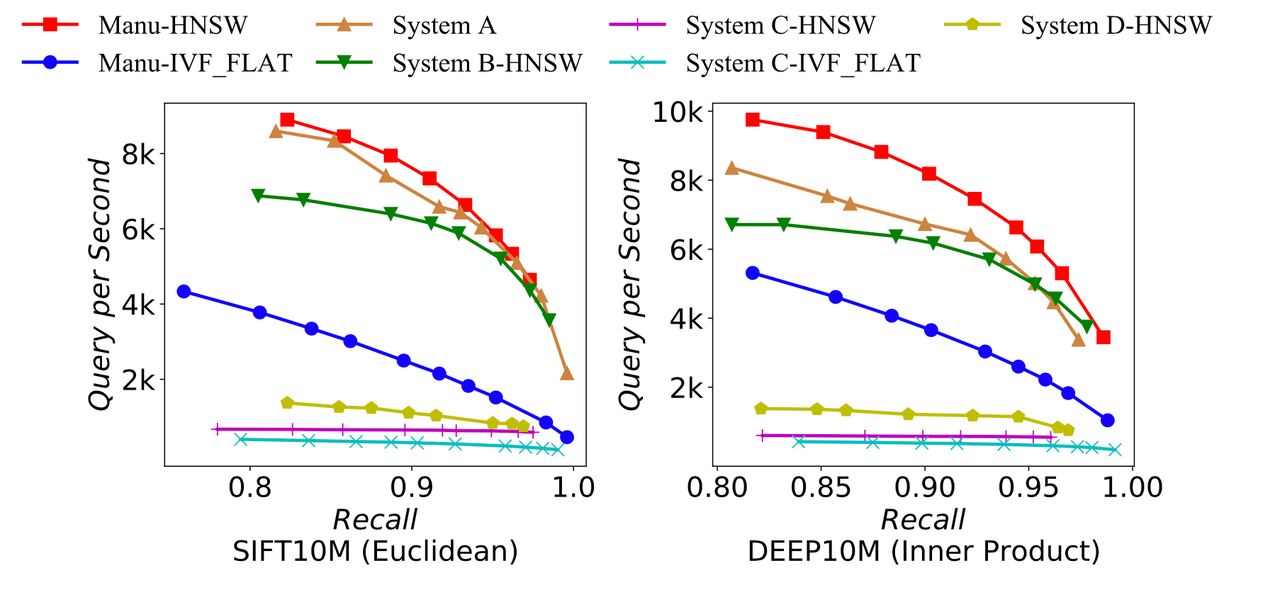 Abfrageleistung von Manu und anderen Vektorsuchsystemen.
Abfrageleistung von Manu und anderen Vektorsuchsystemen.
Die obige Abbildung vergleicht Manu mit vier anderen anonymen Open-Source-Vektorsuchsystemen hinsichtlich der Abfrageleistung. Wir können sehen, dass Manu andere Vektorsuchsysteme bei der Durchführung von Abfragen auf SIFT- und DEEP-Datensätzen deutlich übertrifft.
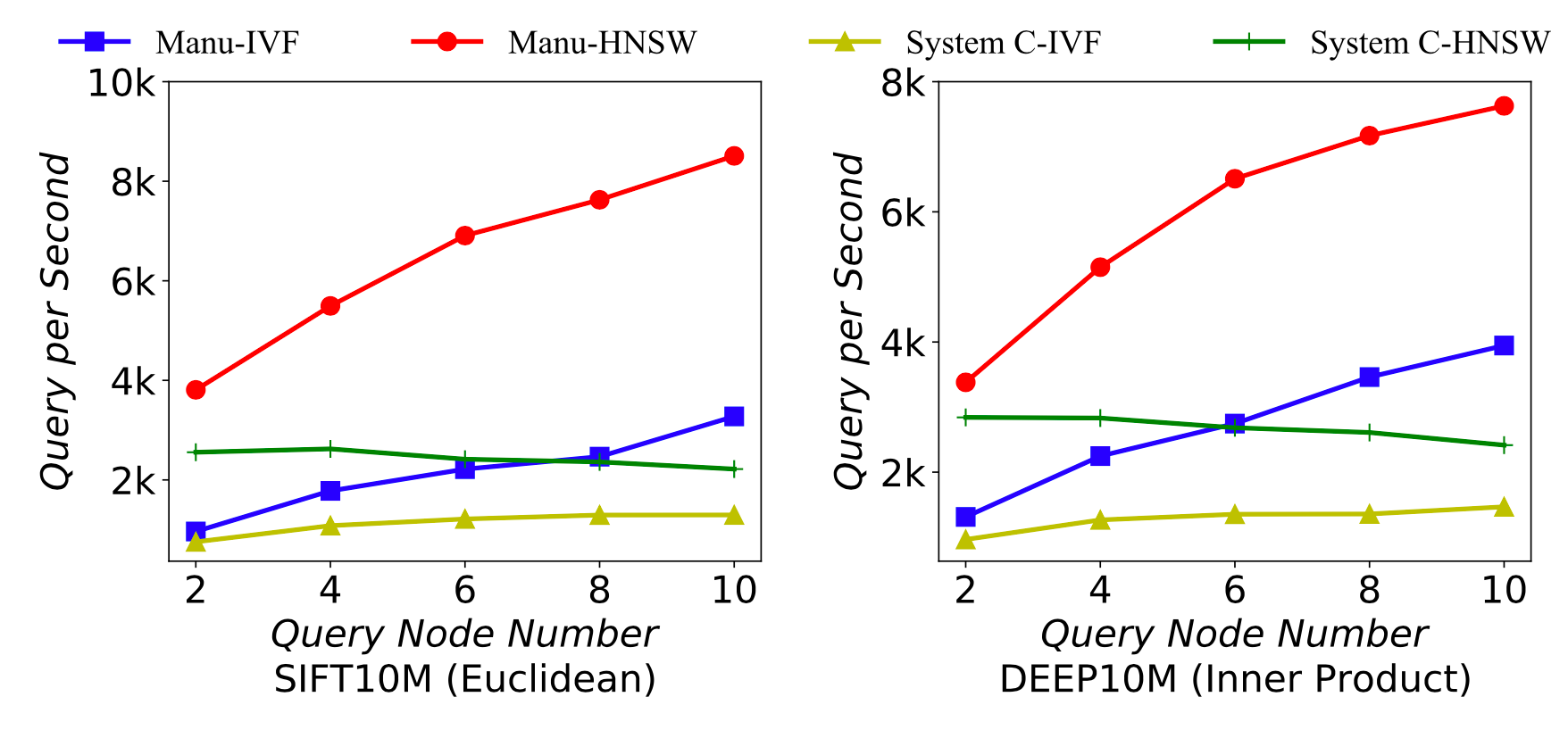 Abfrageleistung von Manu bei unterschiedlicher Anzahl von Knoten.
Abfrageleistung von Manu bei unterschiedlicher Anzahl von Knoten.
Die obige Abbildung zeigt die Abfrageleistung von Manu, wenn die Anzahl der Abfrageknoten variiert. Wir können sehen, dass bei der Abfrage verschiedener Datensätze mit unterschiedlichen Ähnlichkeitsmetriken die Abfrageleistung von Manu eine annähernd lineare Beziehung zur Anzahl der Abfrageknoten aufweist.
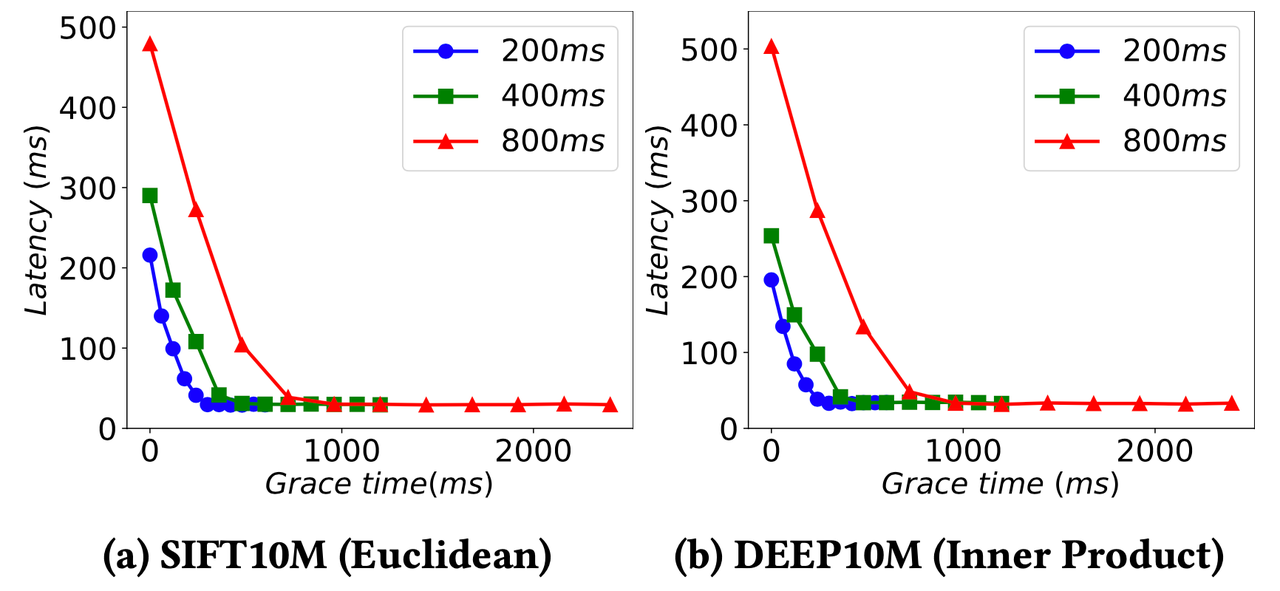 Abfrageleistung von Manu unter verschiedenen Konsistenzstufen.
Abfrageleistung von Manu unter verschiedenen Konsistenzstufen.
Die obigen Abbildungen zeigen die Abfrageleistung von Manu unter verschiedenen Konsistenzstufen. Die horizontalen Koordinaten stellen die Werte von delta wie bei der Delta-Konsistenz dar. Jede Abbildung spiegelt die Häufigkeit wider, mit der Kontrollinformationen an WAL gesendet werden, die Abfrageknoten zur Zeitsynchronisierung zwingen. Aus der Abbildung können wir sehen, dass die Abfragelatenz von Manu drastisch abnimmt, wenn der Wert von delta steigt. Daher müssen Manu-Benutzer den geeigneten delta-Wert entsprechend ihrem Bedarf an Leistung und Konsistenz wählen.
Fazit
In dieser Arbeit haben wir auf der Grundlage realer Anforderungen an Vektordatenbanken die Entwürfe von Manu und die Workflows seiner Hauptfunktionen vorgestellt. Kurz gesagt sind die zwei Hauptmerkmale von Manu wie folgt:
Manu verwendet das Log-Backbone, um die Systemkomponenten zu verbinden, was die unabhängige Skalierung und Weiterentwicklung jeder Komponente ermöglicht und die Ressourcenzuweisung sowie die Fehlerisolation erleichtert.
Mit dem Log-System und der LSN verwendet Manu ein Delta-Konsistenzmodell, um einen flexiblen Kompromiss zwischen Konsistenz, Kosten und Leistung zu ermöglichen.
Zusammenfassend lässt sich sagen, dass der Hauptbeitrag unserer VLDB Arbeit in der Einführung des realen Bedarfs an Vektordatenbanken und dem Entwurf der grundlegenden Architektur einer cloud-nativen Vektordatenbank liegt. Derzeit ist die Architektur noch weit davon entfernt, perfekt zu sein, und einige unserer zukünftigen Richtungen umfassen:
Wie man Vektoren abruft, die aus multimodalen Inhalten extrahiert wurden;
Wie man Cloud-Speicherdienste, einschließlich lokaler Festplatten, Cloud-Laufwerke und anderer Speicherdienste, besser nutzen kann, um den Datenabruf effizienter zu gestalten;
Wie man die Indexierungs- und Suchleistung mithilfe neuer Computing-, Speicher- oder Kommunikationshardware wie FPGA、GPU、RDMA、NVM 、RDMA maximieren kann.
Endnote
Vor einem Jahr nahm ich mit Charles Xie, CEO von Zilliz, an der ACM SIGMOD 2021 in Xi'an teil. Die Idee, dieses Paper zu schreiben, kam mir, als wir auf dem Rückweg nach Shanghai für das GA-Release von Milvus 2.0 (Manu) waren. Sowohl Charles als auch ich nahmen wahr, dass Cloud-native-Datenbanken in der Wissenschaft zum neuen Trendthema wurden. Es war ein solcher Zufall, dass Manu genau ein Cloud-natives und zweckgebundenes Datenbanksystem für massive Vektoren ist. Daher beschlossen wir, dieses Paper über Manu und das Cloud-native-Datenbankmanagementsystem zu schreiben.
Wir hoffen, dass unser Paper etwas Licht ins Dunkel bringen und mehr Wissenschaftler und Kolleginnen und Kollegen aus der Branche dazu bewegen kann, sich uns bei der Erforschung und Untersuchung von Cloud-native-Vektordatenbankmanagementsystemen anzuschließen.
Wir möchten auch Assistant Professor Bo Tang, Research Assistant Professor Xiao Yan und Long Xiang unseren Dank für ihren Beitrag aussprechen. Dieses Paper wurde gemeinsam vom Zilliz-Team und der Database Group der Southern University of Science and Technology verfasst.
Weiterlesen

Vector Lakebase: End the AI Data Silo
Learn how Vector Lakebase unifies vector search, data lakes, and AI data operations so teams can serve RAG and agents without copy-and-sync pipelines.

Zilliz Cloud Delivers Better Performance and Lower Costs with Arm Neoverse-based AWS Graviton
Zilliz Cloud adopts Arm-based AWS Graviton3 CPUs to cut costs, speed up AI vector search, and power billion-scale RAG and semantic search workloads.

Democratizing AI: Making Vector Search Powerful and Affordable
Zilliz democratizes AI vector search with Milvus 2.6 and Zilliz Cloud for powerful, affordable scalability, cutting costs in infrastructure, operations, and development.