




Beschleunigung der Kandidatengenerierung in Empfehlungssystemen mit Milvus in Kombination mit PaddlePaddle
Wenn Sie Erfahrung mit der Entwicklung eines Empfehlungssystems haben, sind Sie wahrscheinlich mindestens einem der folgenden Punkte zum Opfer gefallen:
- Das System ist bei der Rückgabe von Ergebnissen aufgrund der enormen Menge an Datensätzen extrem langsam.
- Neu eingefügte Daten können nicht in Echtzeit für Suche oder Abfrage verarbeitet werden.
- Die Bereitstellung des Empfehlungssystems ist entmutigend.
Dieser Artikel zielt darauf ab, die oben genannten Probleme anzugehen und Ihnen einige Einblicke zu geben, indem er ein Projekt für ein Produktempfehlungssystem vorstellt, das Milvus, eine Open-Source-Vektordatenbank, in Kombination mit PaddlePaddle, einer Deep-Learning-Plattform, verwendet.
Dieser Artikel beschreibt zunächst kurz den minimalen Workflow eines Empfehlungssystems. Anschließend werden die Hauptkomponenten und die Implementierungsdetails dieses Projekts vorgestellt.
Der grundlegende Workflow eines Empfehlungssystems
Bevor wir tief in das Projekt selbst eintauchen, werfen wir zunächst einen Blick auf den grundlegenden Workflow eines Empfehlungssystems. Ein Empfehlungssystem kann personalisierte Ergebnisse entsprechend den individuellen Interessen und Bedürfnissen der Nutzer zurückgeben. Um solche personalisierten Empfehlungen zu erstellen, durchläuft das System zwei Phasen: Kandidatengenerierung und Ranking.
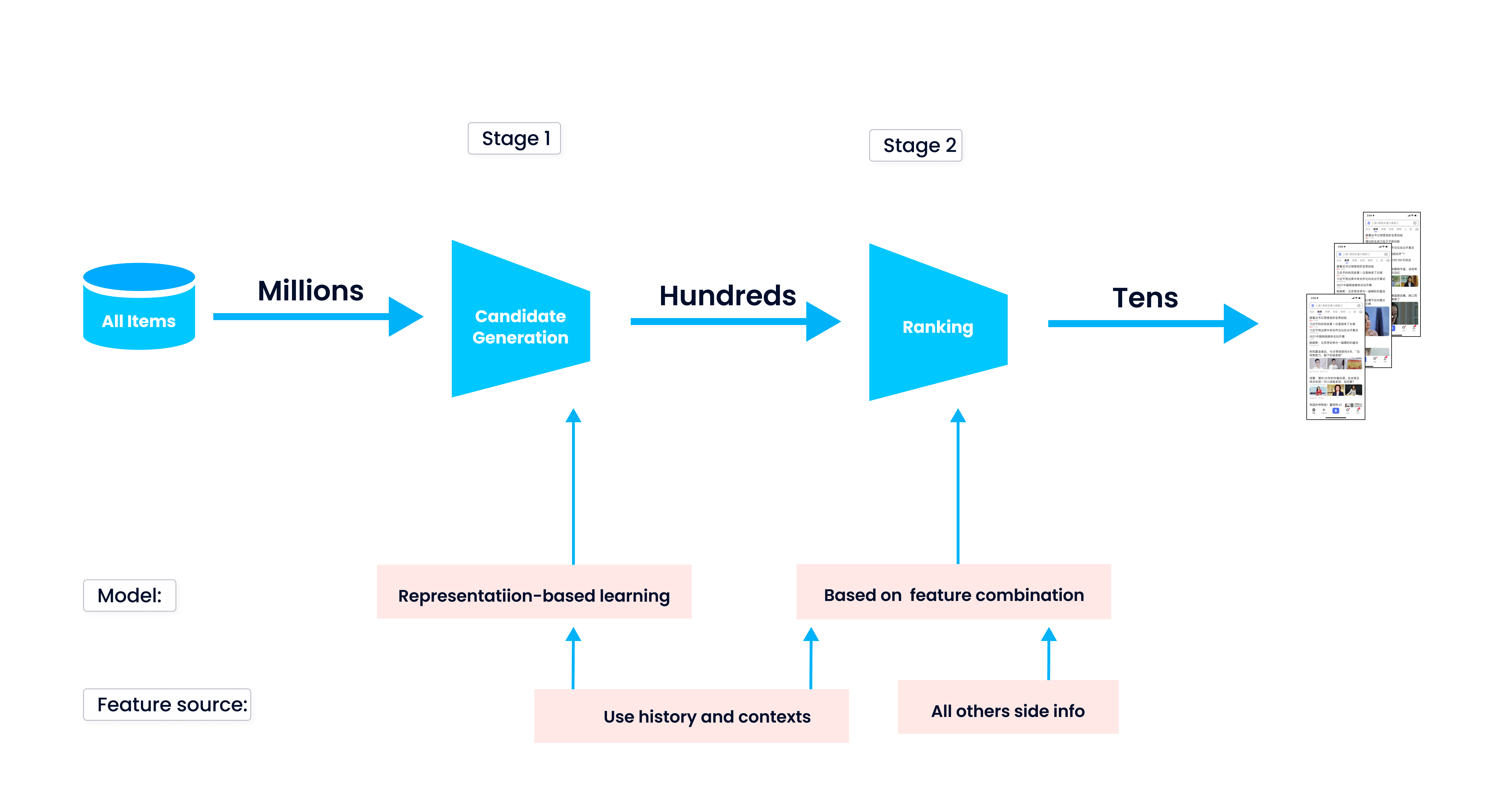 Figure 1.
Figure 1.
Die erste Phase ist die Kandidatengenerierung, die die relevantesten oder ähnlichsten Daten zurückgibt, etwa ein Produkt oder ein Video, das zum Nutzerprofil passt. Während der Kandidatengenerierung vergleicht das System die Nutzereigenschaft mit den in seiner Datenbank gespeicherten Daten und ruft die ähnlichen ab. Anschließend bewertet das System während des Rankings die abgerufenen Daten und ordnet sie neu an. Schließlich werden den Nutzern die Ergebnisse ganz oben auf der Liste angezeigt.
In unserem Fall eines Produktempfehlungssystems vergleicht es zunächst das Nutzerprofil mit den Eigenschaften der Produkte im Bestand, um eine Liste von Produkten herauszufiltern, die den Bedürfnissen des Nutzers entsprechen. Dann bewertet das System die Produkte basierend auf ihrer Ähnlichkeit mit dem Nutzerprofil, ordnet sie ein und gibt schließlich die Top-10-Produkte an den Nutzer zurück.
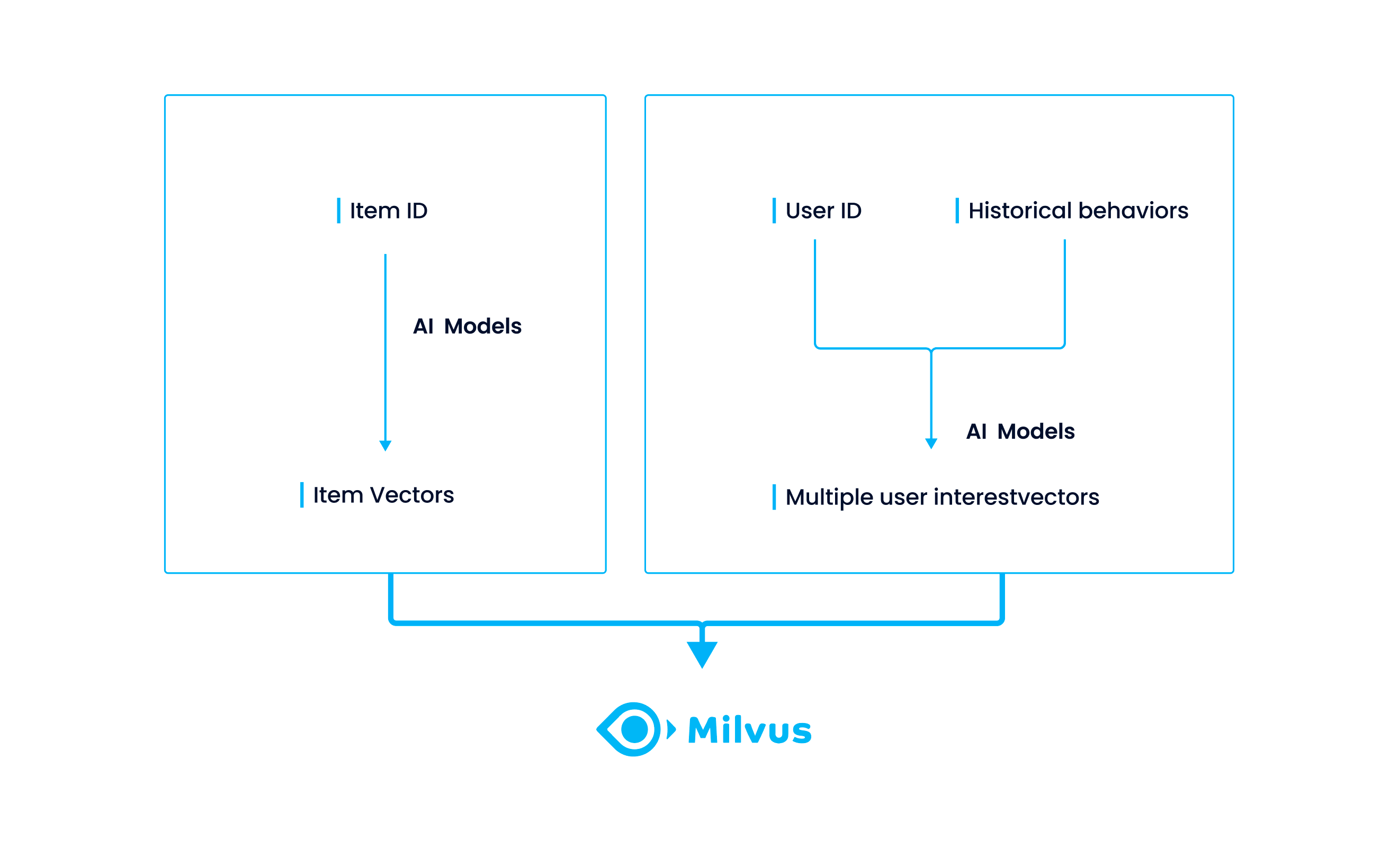 Figure 2.
Figure 2.
Systemarchitektur
Das Produktempfehlungssystem in diesem Projekt verwendet drei Komponenten: MIND, PaddleRec und Milvus.
MIND
MIND, kurz für „Multi-Interest Network with Dynamic Routing for Recommendation at Tmall“, ist ein von der Alibaba Group entwickelter Algorithmus. Bevor MIND vorgeschlagen wurde, verwendeten die meisten verbreiteten KI-Modelle für Empfehlungen einen einzelnen Vektor, um die vielfältigen Interessen eines Nutzers darzustellen. Ein einzelner Vektor reicht jedoch bei weitem nicht aus, um die genauen Interessen eines Nutzers darzustellen. Daher wurde der MIND-Algorithmus vorgeschlagen, um die mehrfachen Interessen eines Nutzers in mehrere Vektoren umzuwandeln.
Konkret nutzt MIND ein multi-interest network mit dynamischem Routing, um während der Kandidatengenerierungsphase mehrere Interessen eines Nutzers zu verarbeiten. Das Multi-Interest Network ist eine Schicht eines Multi-Interest-Extraktors, der auf einem Capsule-Routing-Mechanismus basiert. Es kann verwendet werden, um vergangene Verhaltensweisen eines Nutzers mit seinen oder ihren mehrfachen Interessen zu kombinieren, um ein genaues Nutzerprofil bereitzustellen.
Das folgende Diagramm veranschaulicht die Netzwerkstruktur von MIND.
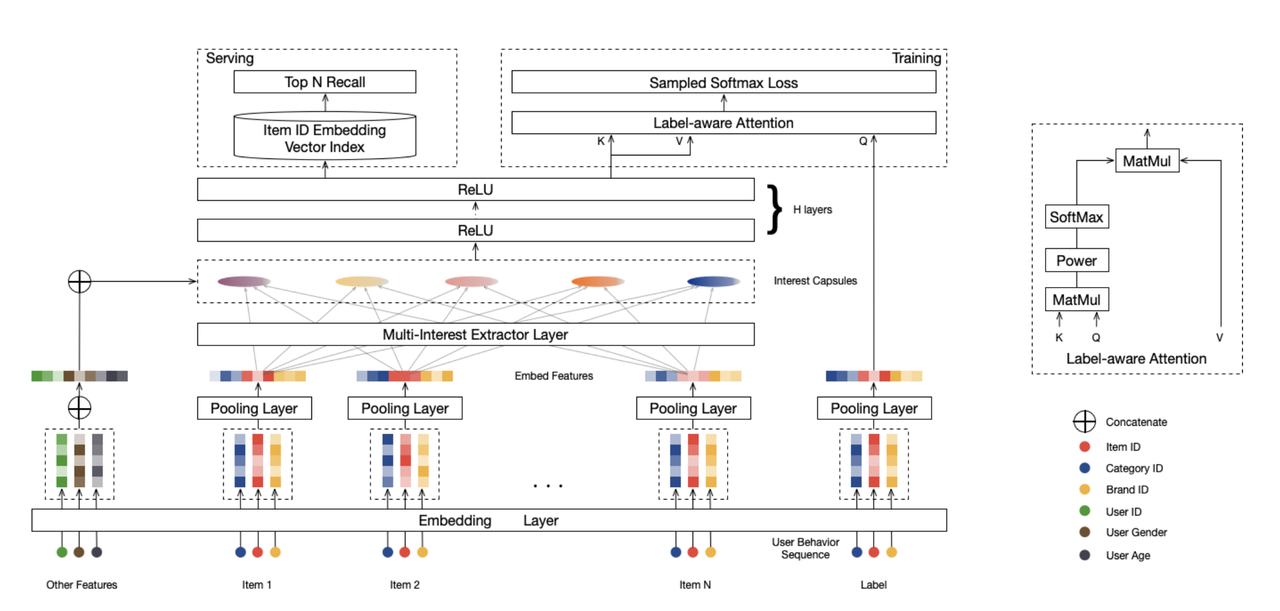 Figure 3.
Figure 3.
Um die Eigenschaften von Nutzern darzustellen, nimmt MIND Nutzerverhalten und Nutzerinteressen als Eingaben und speist sie dann in die Embedding-Schicht ein, um Nutzervektoren zu erzeugen, einschließlich Nutzerinteressenvektoren und Nutzerverhaltensvektoren. Dann werden Nutzerverhaltensvektoren in die Multi-Interest-Extractor-Schicht eingespeist, um Nutzerinteressenkapseln zu erzeugen. Nachdem die Nutzerinteressenkapseln mit Nutzerverhaltens-Embeddings verkettet und mit mehreren ReLU-Schichten transformiert wurden, gibt MIND mehrere Nutzerrepräsentationsvektoren aus. Dieses Projekt hat festgelegt, dass MIND letztendlich vier Nutzerrepräsentationsvektoren ausgeben wird.
Andererseits durchlaufen Produktmerkmale die Embedding-Schicht und werden in dünn besetzte Artikelvektoren umgewandelt. Anschließend durchläuft jeder Artikelvektor eine Pooling-Schicht, um zu einem dichten Vektor zu werden.
Wenn alle Daten in Vektoren umgewandelt sind, wird eine zusätzliche label-aware Attention-Schicht eingeführt, um den Trainingsprozess zu steuern.
PaddleRec
PaddleRec ist eine groß angelegte Suchmodellbibliothek für Empfehlungen. Sie ist Teil des Baidu-PaddlePaddle-Ökosystems. PaddleRec zielt darauf ab, Entwicklern eine integrierte Lösung bereitzustellen, um auf einfache und schnelle Weise ein Empfehlungssystem aufzubauen.
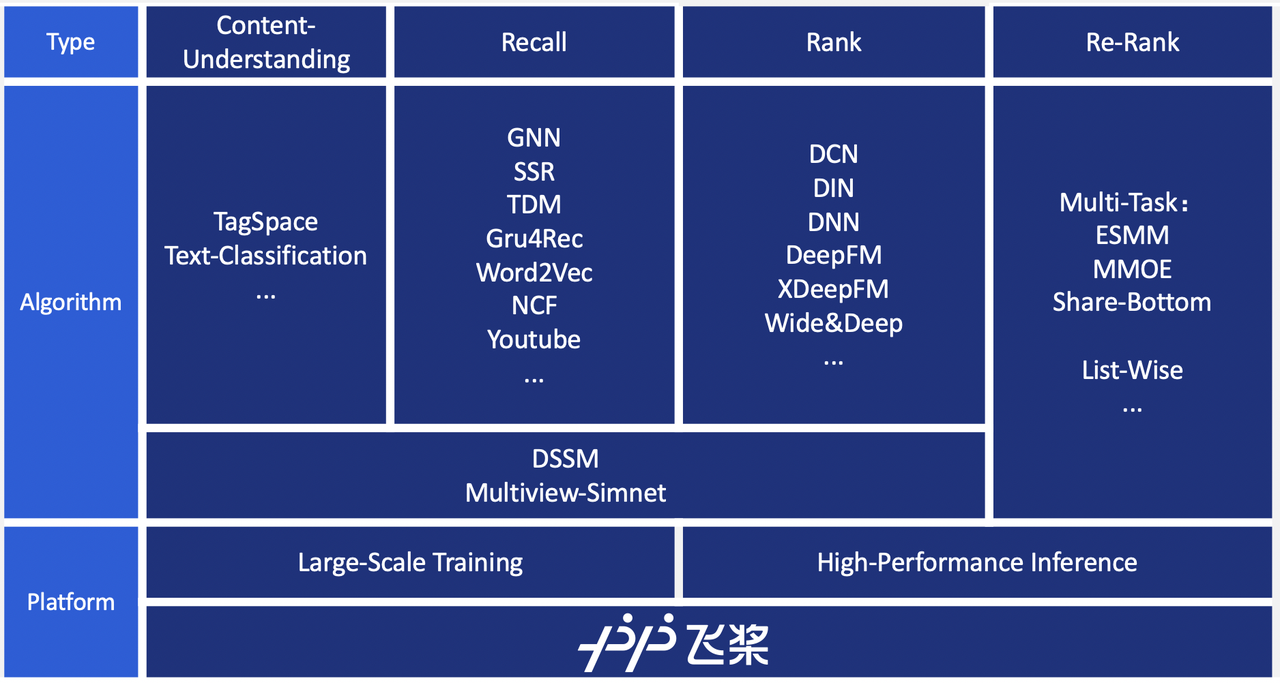 Abbildung 4.
Abbildung 4.
Wie im einleitenden Absatz erwähnt, müssen Ingenieure, die Empfehlungssysteme entwickeln, häufig die Herausforderungen schlechter Benutzerfreundlichkeit und komplizierter Bereitstellung des Systems bewältigen. PaddleRec kann Entwicklern jedoch in den folgenden Aspekten helfen:
Benutzerfreundlichkeit: PaddleRec ist eine Open-Source-Bibliothek, die verschiedene in der Branche beliebte Modelle kapselt, darunter Modelle für Kandidatengenerierung, Ranking, Reranking, Multitasking und mehr. Mit PaddleRec können Sie die Effektivität des Modells sofort testen und seine Effizienz durch Iteration verbessern. PaddleRec bietet Ihnen eine einfache Möglichkeit, Modelle für verteilte Systeme mit ausgezeichneter Leistung zu trainieren. Es ist für die Verarbeitung großer Datenmengen dünn besetzter Vektoren optimiert. Sie können PaddleRec problemlos horizontal skalieren und seine Rechengeschwindigkeit beschleunigen. Daher können Sie mit PaddleRec schnell Trainingsumgebungen auf Kubernetes erstellen.
Unterstützung für Bereitstellung: PaddleRec bietet Online-Bereitstellungslösungen für seine Modelle. Die Modelle sind nach dem Training sofort einsatzbereit und zeichnen sich durch Flexibilität und hohe Verfügbarkeit aus.
Milvus
Milvus ist eine Vektordatenbank mit einer cloudnativen Architektur. Sie ist auf GitHub quelloffen verfügbar und kann verwendet werden, um massive Embedding-Vektoren zu speichern, zu indizieren und zu verwalten, die von tiefen neuronalen Netzen und anderen Machine-Learning-(ML-)Modellen erzeugt werden. Milvus kapselt mehrere erstklassige Bibliotheken für Approximate-Nearest-Neighbor-(ANN-)Suche, darunter Faiss, NMSLIB und Annoy. Sie können Milvus außerdem je nach Bedarf skalieren. Der Milvus-Dienst ist hochverfügbar und unterstützt einheitliche Batch- und Stream-Verarbeitung. Milvus hat sich zum Ziel gesetzt, den Prozess der Verwaltung unstrukturierter Daten zu vereinfachen und eine konsistente Benutzererfahrung in verschiedenen Bereitstellungsumgebungen zu bieten. Es verfügt über die folgenden Funktionen:
Hohe Leistung bei der Durchführung von Vektorsuchen auf riesigen Datensätzen.
Eine entwicklerorientierte Community, die Mehrsprachenunterstützung und Toolchain bietet.
Cloud-Skalierbarkeit und hohe Zuverlässigkeit selbst im Falle einer Störung.
Hybride Suche, die durch die Kombination von skalarer Filterung mit Vektorähnlichkeitssuche erreicht wird.
Milvus wird in diesem Projekt für die Vektorähnlichkeitssuche und Vektorverwaltung verwendet, da es das Problem häufiger Datenaktualisierungen lösen kann und gleichzeitig die Systemstabilität aufrechterhält.
Systemimplementierung
Um das Produktempfehlungssystem in diesem Projekt aufzubauen, müssen Sie die folgenden Schritte durchlaufen:
- Datenverarbeitung
- Modelltraining
- Modelltests
- Generieren von Produktartikel-Kandidaten
- Datenspeicherung: Artikelvektoren werden über das trainierte Modell gewonnen und in Milvus gespeichert.
- Datensuche: vier von MIND generierte Benutzervektoren werden für die Vektorähnlichkeitssuche in Milvus eingespeist.
- Datenranking: jeder der vier Vektoren hat seine eigenen
top_kähnlichen Artikelvektoren, und vier Sätze vontop_k-Vektoren werden gerankt, um eine endgültige Liste dertop_kähnlichsten Vektoren zurückzugeben.
Der Quellcode dieses Projekts wird auf der Plattform Baidu AI Studio gehostet. Der folgende Abschnitt ist eine detaillierte Erklärung des Quellcodes für dieses Projekt.
Schritt 1. Datenverarbeitung
Der ursprüngliche Datensatz stammt aus dem von ComiRec bereitgestellten Amazon-Buchdatensatz. Dieses Projekt verwendet jedoch die Daten, die von PaddleRec heruntergeladen und verarbeitet werden. Weitere Informationen finden Sie im AmazonBook-Datensatz im PaddleRec-Projekt.
Der Datensatz für das Training wird im folgenden Format erwartet, wobei jede Spalte Folgendes darstellt:
Uid: Benutzer-ID.item_id: ID des Produktartikels, der vom Benutzer angeklickt wurde.Time: Der Zeitstempel oder die Reihenfolge des Klicks.
Der Datensatz für das Testen wird im folgenden Format erwartet, wobei jede Spalte Folgendes darstellt:
Uid: Benutzer-ID.hist_item: ID des Produktartikels im historischen Klickverhalten des Benutzers. Wenn es mehrerehist_itemgibt, werden sie nach dem Zeitstempel sortiert.eval_item: Die tatsächliche Reihenfolge, in der der Benutzer die Produkte anklickt.
Schritt 2. Modelltraining
Das Modelltraining verwendet die im vorherigen Schritt verarbeiteten Daten und übernimmt das auf PaddleRec aufgebaute Kandidatengenerierungsmodell MIND.
1. Modell Eingabe
Führen Sie in dygraph_model.py den folgenden Code aus, um die Daten zu verarbeiten und in Modelleingaben umzuwandeln. Dieser Prozess sortiert die vom selben Benutzer in den ursprünglichen Daten angeklickten Artikel nach dem Zeitstempel und kombiniert sie zu einer Sequenz. Wählen Sie dann zufällig eine item``_``id aus der Sequenz als target_item aus und extrahieren Sie die 10 Artikel vor target_item als hist_item für die Modelleingabe. Wenn die Sequenz nicht lang genug ist, kann sie auf 0 gesetzt werden. seq_len sollte die tatsächliche Länge der hist_item-Sequenz sein.
def create_feeds_train(self, batch_data):
hist_item = paddle.to_tensor(batch_data[0], dtype="int64")
target_item = paddle.to_tensor(batch_data[1], dtype="int64")
seq_len = paddle.to_tensor(batch_data[2], dtype="int64")
return [hist_item, target_item, seq_len]
Den Code zum Lesen des ursprünglichen Datensatzes finden Sie im Skript /home/aistudio/recommend/model/mind/mind_reader.py.
2. Modellvernetzung
Der folgende Code ist ein Auszug aus net.py. class Mind_Capsual_Layer definiert die Multi-Interest-Extractor-Schicht, die auf dem Interest-Capsule-Routing-Mechanismus basiert. Die Funktion label_aware_attention() implementiert die label-aware Attention-Technik im MIND-Algorithmus. Die Funktion forward() in der class MindLayer modelliert die Benutzereigenschaften und generiert entsprechende Gewichtsvektoren.
class Mind_Capsual_Layer(nn.Layer):
def __init__(self):
super(Mind_Capsual_Layer, self).__init__()
self.iters = iters
self.input_units = input_units
self.output_units = output_units
self.maxlen = maxlen
self.init_std = init_std
self.k_max = k_max
self.batch_size = batch_size
# B2I routing
self.routing_logits = self.create_parameter(
shape=[1, self.k_max, self.maxlen],
attr=paddle.ParamAttr(
name="routing_logits", trainable=False),
default_initializer=nn.initializer.Normal(
mean=0.0, std=self.init_std))
# bilinear mapping
self.bilinear_mapping_matrix = self.create_parameter(
shape=[self.input_units, self.output_units],
attr=paddle.ParamAttr(
name="bilinear_mapping_matrix", trainable=True),
default_initializer=nn.initializer.Normal(
mean=0.0, std=self.init_std))
class MindLayer(nn.Layer):
def label_aware_attention(self, keys, query):
weight = paddle.sum(keys * query, axis=-1, keepdim=True)
weight = paddle.pow(weight, self.pow_p) # [x,k_max,1]
weight = F.softmax(weight, axis=1)
output = paddle.sum(keys * weight, axis=1)
return output, weight
def forward(self, hist_item, seqlen, labels=None):
hit_item_emb = self.item_emb(hist_item) # [B, seqlen, embed_dim]
user_cap, cap_weights, cap_mask = self.capsual_layer(hit_item_emb, seqlen)
if not self.training:
return user_cap, cap_weights
target_emb = self.item_emb(labels)
user_emb, W = self.label_aware_attention(user_cap, target_emb)
return self.sampled_softmax(
user_emb, labels, self.item_emb.weight,
self.embedding_bias), W, user_cap, cap_weights, cap_mask
Beziehen Sie sich auf das Skript /home/aistudio/recommend/model/mind/net.py für die spezifische Netzwerkstruktur von MIND.
3. Modelloptimierung
Dieses Projekt verwendet den Adam-Algorithmus als Modelloptimierer.
def create_optimizer(self, dy_model, config):
lr = config.get("hyper_parameters.optimizer.learning_rate", 0.001)
optimizer = paddle.optimizer.Adam(
learning_rate=lr, parameters=dy_model.parameters())
return optimizer
Darüber hinaus schreibt PaddleRec Hyperparameter in config.yaml, sodass Sie nur diese Datei ändern müssen, um einen klaren Vergleich zwischen der Wirksamkeit der beiden Modelle zu sehen und die Modelleffizienz zu verbessern. Beim Trainieren des Modells kann eine schlechte Modellwirkung auf Underfitting oder Overfitting zurückzuführen sein. Sie können sie daher verbessern, indem Sie die Anzahl der Trainingsrunden ändern. In diesem Projekt müssen Sie lediglich den Parameter epochs in config.yaml ändern, um die perfekte Anzahl von Trainingsrunden zu finden. Darüber hinaus können Sie zum Debuggen auch den Modelloptimierer, optimizer.class,oder learning_rate ändern. Im Folgenden wird ein Teil der Parameter in config.yaml gezeigt.
runner:
use_gpu: True
use_auc: False
train_batch_size: 128
epochs: 20
print_interval: 10
model_save_path: "output_model_mind"
# hyper parameters of user-defined network
hyper_parameters:
# optimizer config
optimizer:
class: Adam
learning_rate: 0.005
Beziehen Sie sich auf das Skript /home/aistudio/recommend/model/mind/dygraph_model.py für die detaillierte Implementierung.
4. Modelltraining
Führen Sie den folgenden Befehl aus, um das Modelltraining zu starten.
python -u trainer.py -m mind/config.yaml
Beziehen Sie sich auf /home/aistudio/recommend/model/trainer.py für das Modelltrainingsprojekt.
Schritt 3. Modelltest
Dieser Schritt verwendet den Testdatensatz, um die Leistung zu überprüfen, z. B. die Recall-Rate des trainierten Modells.
Während des Modelltests werden alle Item-Vektoren aus dem Modell geladen und anschließend in Milvus, die Open-Source-Vektordatenbank, importiert. Lesen Sie den Testdatensatz über das Skript /home/aistudio/recommend/model/mind/mind_infer_reader.py. Laden Sie das Modell aus dem vorherigen Schritt und geben Sie den Testdatensatz in das Modell ein, um vier Interessenvektoren des Benutzers zu erhalten. Suchen Sie in Milvus nach den 50 ähnlichsten Item-Vektoren zu den vier Interessenvektoren. Sie können die zurückgegebenen Ergebnisse den Benutzern empfehlen.
Führen Sie den folgenden Befehl aus, um das Modell zu testen.
python -u infer.py -m mind/config.yaml -top_n 50
Während des Modelltests stellt das System mehrere Indikatoren zur Bewertung der Modellwirksamkeit bereit, z. B. Recall@50, NDCG@50 und HitRate@50. Dieser Artikel stellt nur die Änderung eines Parameters vor. In Ihrem eigenen Anwendungsszenario müssen Sie jedoch mehr epochs trainieren, um eine bessere Modellwirkung zu erzielen. Sie können die Modellwirksamkeit auch verbessern, indem Sie verschiedene Optimierer verwenden, unterschiedliche Lernraten festlegen und die Anzahl der Testrunden erhöhen. Es wird empfohlen, mehrere Modelle mit unterschiedlichen Wirkungen zu speichern und dann dasjenige auszuwählen, das die beste Leistung aufweist und am besten zu Ihrer Anwendung passt.
Schritt 4. Generieren von Produkt-Item-Kandidaten
Um den Dienst zur Generierung von Produktkandidaten aufzubauen, verwendet dieses Projekt das in den vorherigen Schritten trainierte Modell in Kombination mit Milvus. Während der Kandidatengenerierung wird FASTAPI verwendet, um die Schnittstelle bereitzustellen. Wenn der Dienst startet, können Sie Befehle direkt im Terminal über curl ausführen.
Führen Sie den folgenden Befehl aus, um vorläufige Kandidaten zu generieren.
uvicorn main:app
Der Dienst stellt vier Arten von Schnittstellen bereit:
- Einfügen : Führen Sie den folgenden Befehl aus, um die Item-Vektoren aus Ihrem Modell zu lesen und sie in eine Collection in Milvus einzufügen.
curl -X 'POST' \
'http://127.0.0.1:8000/rec/insert_data' \
-H 'accept: application/json' \
-d ''
- Vorläufige Kandidaten generieren: Geben Sie die Reihenfolge ein, in der Produkte vom Benutzer angeklickt werden, und finden Sie das nächste Produkt heraus, das der Benutzer möglicherweise anklickt. Sie können Produkt-Item-Kandidaten auch stapelweise für mehrere Benutzer auf einmal generieren.
hist_itemim folgenden Befehl ist ein zweidimensionaler Vektor, und jede Zeile stellt eine Sequenz der Produkte dar, die der Benutzer in der Vergangenheit angeklickt hat. Sie können die Länge der Sequenz definieren. Die zurückgegebenen Ergebnisse sind ebenfalls Mengen zweidimensionaler Vektoren, wobei jede Zeile die zurückgegebenenitem ids für Benutzer darstellt.
curl -X 'POST' \
'http://127.0.0.1:8000/rec/recall' \
-H 'accept: application/json' \
-H 'Content-Type: application/json' \
-d '{
"top_k": 50,
"hist_item": [[43,23,65,675,3456,8654,123454,54367,234561],[675,3456,8654,123454,76543,1234,9769,5670,65443,123098,34219,234098]]
}'
- Gesamtzahl der Produkt-Items abfragen: Führen Sie den folgenden Befehl aus, um die Gesamtzahl der in der Milvus-Datenbank gespeicherten Item-Vektoren zurückzugeben.
curl -X 'POST' \
'http://127.0.0.1:8000/rec/count' \
-H 'accept: application/json' \
-d ''
- Löschen: Führen Sie den folgenden Befehl aus, um alle in der Milvus-Datenbank gespeicherten Daten zu löschen .
curl -X 'POST' \
'http://127.0.0.1:8000/qa/drop' \
-H 'accept: application/json' \
-d ''
Wenn Sie den Dienst zur Kandidatengenerierung auf Ihrem lokalen Server ausführen, können Sie auch unter 127.0.0.1:8000/docs auf die oben genannten Schnittstellen zugreifen. Sie können damit experimentieren, indem Sie auf die vier Schnittstellen klicken und den Wert für die Parameter eingeben. Klicken Sie anschließend auf "Try it out", um das Empfehlungsergebnis zu erhalten.
 Abbildung 5.
Abbildung 5.
 Abbildung 6.
Abbildung 6.
Zusammenfassung
Dieser Artikel konzentriert sich hauptsächlich auf die erste Phase der Kandidatengenerierung beim Aufbau eines Empfehlungssystems. Er bietet außerdem eine Lösung zur Beschleunigung dieses Prozesses, indem Milvus mit dem MIND-Algorithmus und PaddleRec kombiniert wird, und behandelt damit das im einleitenden Absatz aufgeworfene Problem.
Was ist, wenn das System aufgrund der enormen Datenmengen beim Zurückgeben von Ergebnissen extrem langsam ist? Milvus, die Open-Source-Vektordatenbank, ist für blitzschnelle Ähnlichkeitssuchen auf dichten Vektordatensätzen ausgelegt, die Millionen, Milliarden oder sogar Billionen von Vektoren enthalten.
Was ist, wenn neu eingefügte Daten nicht in Echtzeit für Suche oder Abfrage verarbeitet werden können? Sie können Milvus verwenden, da es eine einheitliche Batch- und Stream-Verarbeitung unterstützt und Ihnen ermöglicht, neu eingefügte Daten in Echtzeit zu suchen und abzufragen. Außerdem ist das MIND-Modell in der Lage, neues Benutzerverhalten in Echtzeit umzuwandeln und die Benutzervektoren sofort in Milvus einzufügen.
Was ist, wenn die komplizierte Bereitstellung zu einschüchternd ist? PaddleRec, eine leistungsstarke Bibliothek, die zum PaddlePaddle-Ökosystem gehört, kann Ihnen eine integrierte Lösung bieten, um Ihr Empfehlungssystem oder andere Anwendungen auf einfache und schnelle Weise bereitzustellen.
Über die Autorin
Yunmei Li, Zilliz Data Engineer, hat an der Huazhong University of Science and Technology einen Abschluss in Informatik erworben. Seit ihrem Eintritt bei Zilliz arbeitet sie daran, Lösungen für das Open-Source-Projekt Milvus zu erkunden und Benutzern dabei zu helfen, Milvus in realen Szenarien einzusetzen. Ihr Hauptfokus liegt auf NLP und Empfehlungssystemen, und sie möchte ihren Schwerpunkt in diesen beiden Bereichen weiter vertiefen. Sie verbringt gerne Zeit allein und liest.
Suchen Sie nach weiteren Ressourcen?
- Weitere Anwendungsfälle für den Aufbau eines Empfehlungssystems:
- Aufbau eines personalisierten Produktempfehlungssystems mit Vipshop mit Milvus
- Aufbau einer App zur Kleiderschrank- und Outfit-Planung mit Milvus
- Aufbau eines intelligenten Nachrichtenempfehlungssystems innerhalb der Sohu News App
- Item-basiertes kollaboratives Filtern für ein Musikempfehlungssystem
- Making with Milvus: KI-gestützte Nachrichtenempfehlungen im mobilen Browser von Xiaomi
- Weitere Milvus-Projekte in Zusammenarbeit mit anderen Communities:
- Engagieren Sie sich in unserer Open-Source-Community:
Weiterlesen

Introducing Functions and Model Inference on Zilliz Cloud: Automatic Embedding and Reranking with Hosted Models
Zilliz Cloud Functions auto-generate embeddings via OpenAI, Voyage AI, Cohere, or Zilliz Hosted Models. Built-in reranking — just insert text and search.

Top 10 Context Engineering Techniques You Should Know for Production RAG
A practical guide to context engineering for production LLM systems, covering RAG, context processing, memory, agents, and multimodal context.

Milvus 2.6.x Now Generally Available on Zilliz Cloud, Making Vector Search Faster, Smarter, and More Cost-Efficient for Production AI
Milvus 2.6.x is now GA on Zilliz Cloud, delivering faster vector search, smarter hybrid queries, and lower costs for production RAG and AI applications.