




Milvus 2.4 stellt CAGRA vor: Verbesserte Vektorsuche mit GPU-Indizierung der nächsten Generation
Was ist ein GPU-basierter Index?
Die Vektorsuche ist von Natur aus rechenintensiv. Milvus steht an der Spitze der leistungsfähigsten Vektordatenbanken und verwendet über 80 % seiner Rechenressourcen für seine Vektordatenbanken und seine Suchmaschine, Knowhere. In Anbetracht der Rechenanforderungen des High-Performance-Computing erweisen sich GPUs als ein zentrales Element unserer Vektordatenbankplattform, insbesondere im Bereich der Vektorsuche.
Milvus hat einen Präzedenzfall geschaffen, indem es 2021 mit Milvus Version 1.1 die erste Vektordatenbank wurde, die die GPU-Beschleunigung nutzte. In Version 2.3 führte Milvus durch die Nutzung von NVIDIAs RAFT-Bibliothek für die Vektorsuche GPU-beschleunigte Indizes und die Integration mit dem NVIDIA Merlin-Empfehlungsframework (das zum Aufbau von Empfehlungssystemen verwendet wird) ein. Die Einführung von IVFFLAT- und IVFPQ-Indizes in dieser Version führte zu bemerkenswerten Leistungsverbesserungen.
Trotz dieser Fortschritte gibt es nach wie vor Herausforderungen wie die Optimierung der Leistung bei Abfragen in kleinen Mengen und die Verbesserung der Kosteneffizienz von GPU-basierten Indizes, was eine kontinuierliche Suche nach innovativen Lösungen erforderlich macht. Die Verlagerung der Branche hin zu graphenbasierten [Vektorsuchalgorithmen] (https://zilliz.com/learn/popular-machine-learning-algorithms-behind-vector-search), die für ihre überlegene Leistung gegenüber IVF-basierten Methoden bekannt sind, stellt eine entscheidende Entwicklung dar. Die Anpassung dieser Algorithmen an GPUs ist jedoch aufgrund ihrer sequenziellen Ausführung und zufälligen Speicherzugriffsmuster nicht einfach, was eine effiziente GPU-Implementierung für Algorithmen wie GGNN und SONG schwierig macht.
Die jüngste Innovation von NVIDIA, der GPU-basierte Graphenindex CAGRA, ist ein wichtiger Meilenstein, um diese Herausforderungen zu bewältigen. Mit der Unterstützung von NVIDIA hat Milvus die Unterstützung für CAGRA in seine Version 2.4 integriert und damit einen bedeutenden Schritt zur Überwindung der Hindernisse einer effizienten GPU-Implementierung bei der Vektorsuche gemacht.
Was ist CAGRA?
CAGRA erstellen
CAGRA (CUDA Anns GRAph-based) führt einen neuen Ansatz zur Graphenkonstruktion ein, der von der iterativen Insert-Update-Methode abweicht, die von hierarchischen navigierbaren kleinen Welten (HNSW) Graphen auf CPUs verwendet wird. Mit dieser Änderung wird die Herausforderung angegangen, die hochparallelen Graphenkonstruktionsfähigkeiten von GPUs voll auszunutzen, die der CPU-basierte HNSW-Konstruktionsprozess nicht ausnutzen kann. CAGRA beginnt mit der Erstellung eines Ausgangsgraphen mit IVFPQ oder NN-DESCENT, wobei jeder Knoten mit zahlreichen Nachbarn verbunden ist. In den nächsten Schritten werden diese Verbindungen nach Wichtigkeit sortiert, weniger kritische Kanten beschnitten und gerichtete Graphen zusammengeführt, um die Struktur zu vervollständigen und einen Ausgangsgraphen zu erstellen. In diesem Ausgangsgraphen hat jeder Knoten eine große Anzahl von Nachbarknoten. CAGRA sortiert dann alle benachbarten Kanten nach ihrer Wichtigkeit auf der Grundlage des Ausgangsgraphen und beschneidet die unwichtigen Kanten.
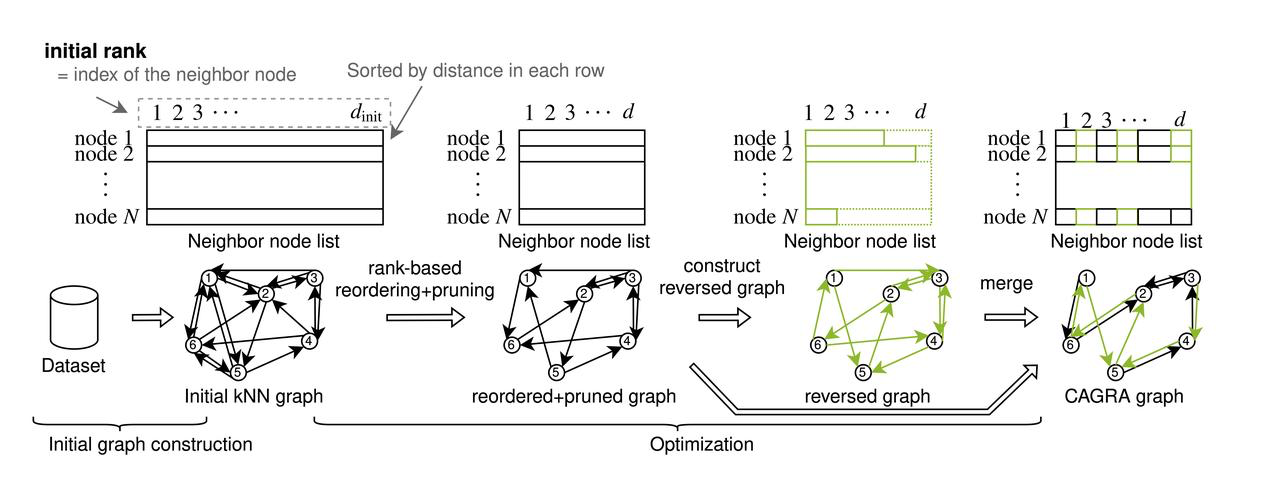 Der Erstellungsprozess von CAGRA
Der Erstellungsprozess von CAGRA
Anfängliche Konstruktion des Graphen
IVFPQ
Im IVFPQ-Modus nutzt CAGRA den Datensatz, um einen IVFPQ-Index zu erstellen, wobei die Quantisierungsfunktion des Product Quantization (PQ)-Index verwendet wird, um den Videospeicherverbrauch zu minimieren. Nach der Erstellung dieses Indexes führt CAGRA eine Suche für jeden Punkt im Datensatz durch, wobei die ungefähren nächsten Nachbarn, die durch den IVFPQ-Index identifiziert wurden, als nächstgelegene Punkte für die Suche verwendet werden. Dieser Prozess bildet die Grundlage für die Konstruktion des Ausgangsgraphen und gewährleistet eine effiziente Einrichtung, ohne zu viel Speicherplatz zu beanspruchen.
NN-DESCENT
CAGRA verwendet den NN-DESCENT-Algorithmus für einen anderen Ansatz zur Konstruktion des Ausgangsgraphen, der die folgenden detaillierten Schritte umfasst:
Initialisierung: Zufällige Auswahl von k Punkten aus dem Datensatz v zur Erstellung der anfänglichen Adjazenzliste B[v].
Umkehrung und Zusammenführung: Nehmen Sie die Umkehrung von B[v], um die umgekehrte Adjazenzliste R[v] zu erzeugen, und führen Sie dann B und R zusammen, um H[v] zu bilden.
Nachbarschaftsexpansion: Für jeden Knoten v im Datensatz werden alle Nachbarn von Nachbarn auf der Grundlage von H[v] identifiziert, wobei die nächstgelegenen Topk-Knoten als seine neuen Nachbarn ausgewählt werden.
Iteration: Wiederholen Sie den Prozess der Umkehr und Zusammenführung und der Nachbarschaftsexpansion, bis B sich stabilisiert und nicht mehr verändert oder bis ein voreingestellter Iterationsschwellenwert erreicht ist.
Im Vergleich zu HNSW bietet NN-Descent eine einfachere Parallelisierung und eine geringere Dateninteraktion zwischen den Aufgaben, was die Graphenerstellungszeit und die Effizienz des CAGRA-Adjazenzgraphen auf GPUs erheblich steigert. Es ist jedoch zu beachten, dass die anfängliche Qualität des Graphen im NN-DESCENT-Modus leicht hinter der im IVFPQ-Modus erreichten zurückbleiben kann.
CAGRA-Optimierung
Die CAGRA-Graphenoptimierungsstrategie basiert auf zwei Hauptannahmen:
Bedeutungssortierung: Zur Bestimmung der Wichtigkeit von Kanten wird die pfadbasierte Sortierung gegenüber der traditionellen entfernungsbasierten Sortierung bevorzugt. Diese Methode argumentiert, dass die Konnektivität eines Graphen nicht unbedingt von einer distanzbasierten Wichtigkeitssortierung profitiert.
Zusammenführung umgekehrter Graphen: Die Strategie der Zusammenführung umgekehrter Graphen beruht auf dem Grundsatz, dass ein Knoten, der für einen wichtig ist, auch für den anderen wichtig sein kann.
Der Optimierungsprozess umfasst zwei Hauptschritte:
- Beschneidung: Zunächst werden den benachbarten Kanten jedes Knotens je nach Entfernung verschiedene Gewichte ('w') zugewiesen. CAGRA wendet eine Beschneidungsstrategie an, bei der Kanten abgeschnitten werden, wenn sie Knoten verbinden, die am "schädlichsten" sind, basierend auf der Bedingung "max(w_{x to z},w_{z to y}) < w_{x to y}". Dies konzentriert sich auf die Eliminierung weniger kritischer Verbindungen, um den Graphen zu straffen.
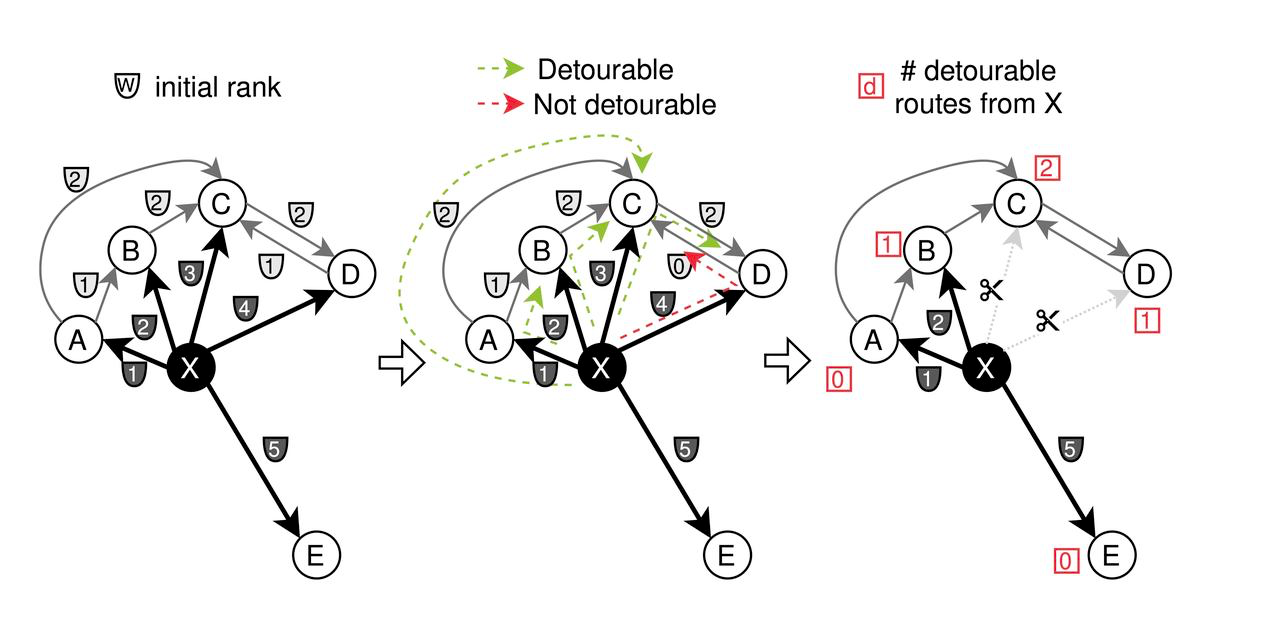 Pruning-Prozess für CAGRA-Optimierung
Pruning-Prozess für CAGRA-Optimierung
- Zusammenführung: Nach dem Pruning des Vorwärtsgraphen auf der Grundlage der Pfadbedeutung werden die Kanten invertiert und zusammengeführt. Konkret wird die Hälfte der Kanten sowohl aus dem Vorwärts- als auch aus dem Rückwärtsgraphen ausgewählt, um den endgültigen optimierten CAGRA-Graphen zu erstellen.
Dieser detaillierte Ansatz für die Konstruktion und Optimierung des Graphen gewährleistet die Effizienz und Effektivität von CAGRA bei der Vektorsuche. Dabei werden die einzigartigen Fähigkeiten von Grafikprozessoren genutzt und gleichzeitig die Herausforderungen bewältigt, die mit graphenbasierten Suchalgorithmen verbunden sind.
Suchen mit CAGRA
Der CAGRA-Suchmechanismus verwendet einen methodischen Ansatz mit einer geordneten Prioritätswarteschlange fester Größe für eine effiziente Graphen-Navigation. Dieser detaillierte Prozess wird durch eine Reihe von Schritten innerhalb eines strukturierten Rahmens umrissen:
CAGRA-Suchrahmen
CAGRA arbeitet mit einem sequentiellen Speicherpuffer, der eine interne Top-M-Liste und eine Kandidatenliste umfasst. Die interne Top-M-Liste fungiert als Prioritäts-Warteschlange, deren Länge auf M (mit M ≥ k) eingestellt ist, um sicherzustellen, dass sie die relevantesten Ergebnisse bis zur gewünschten Anzahl der nächsten Nachbarn, k, speichern kann. Die Größe der Kandidatenliste wird durch p × d bestimmt, wobei p die Anzahl der in jeder Iteration untersuchten Quellknoten darstellt und d den Grad des Graphen angibt. Jedes Element innerhalb dieser Listen paart einen Knotenindex mit der Entfernung zur Anfrage, was eine effiziente Suchverwaltung ermöglicht.
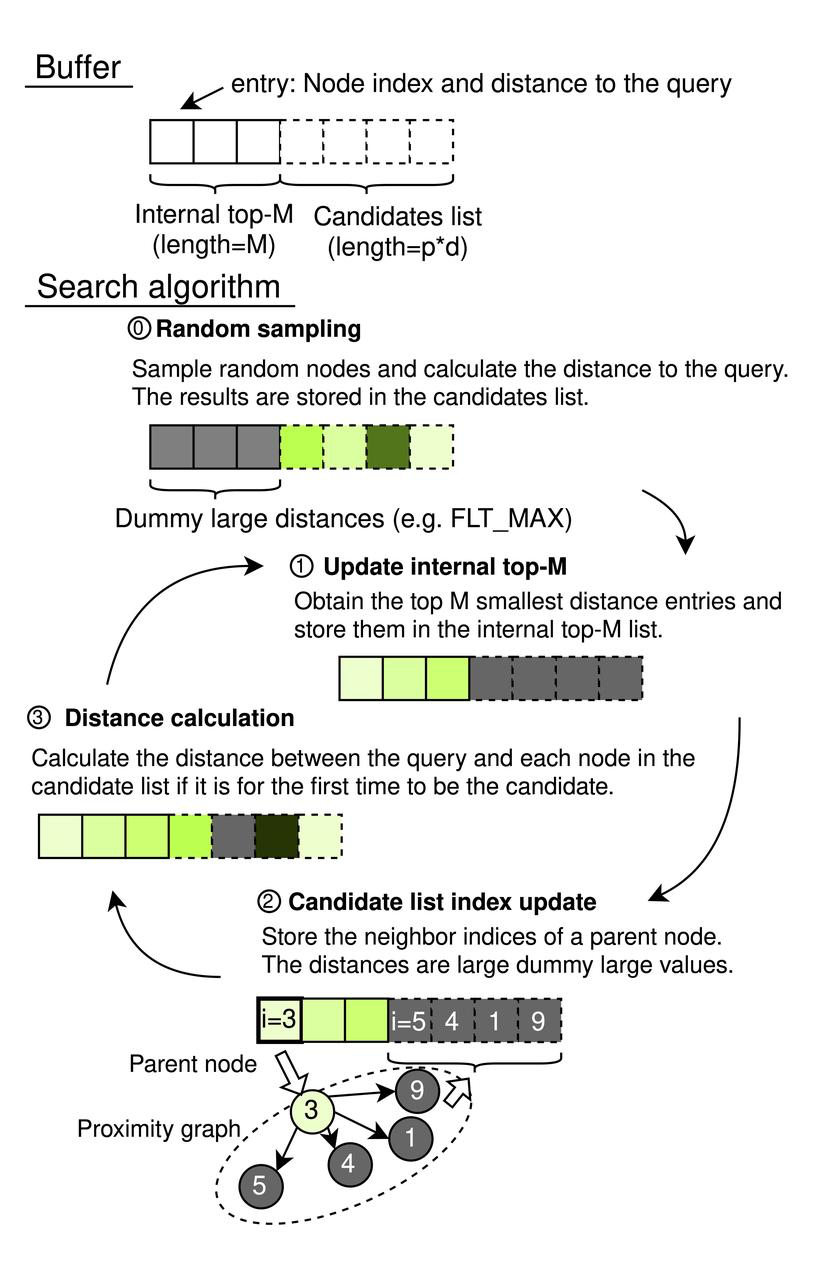 CAGRA-Suchprozess
CAGRA-Suchprozess
Schritte des Suchprozesses
- Zufallsstichprobe (Initialisierung)
- Verwendet einen Pseudo-Zufallsgenerator, um p × d zufällige Knotenindizes auszuwählen, wobei der Abstand zwischen jedem Knoten und der Abfrage berechnet wird.
- Die Ergebnisse füllen die Kandidatenliste, während die interne Top-M-Liste mit virtuellen Einträgen initialisiert wird (auf FLT_MAX gesetzt), um die anfänglichen Sortierergebnisse nicht zu beeinflussen.
Aktualisierung der internen Top-M-Liste: Auswahl der Top-M-Knoten auf der Grundlage der kleinsten Entfernungen im gesamten Puffer zur Aufnahme in die interne Top-M-Liste.
Kandidatenlisten-Indexaktualisierung (Graph Traversal):
- Identifiziert alle Nachbarknoten der Top-P-Knoten aus der internen Top-M-Liste, wobei zuvor verwendete Knoten über einen Hash-Tabellenfilter ausgeschlossen werden.
- Fügt diese Nachbarn zur Kandidatenliste hinzu, ohne die Abstände in diesem Stadium neu zu berechnen.
- Entfernungsberechnung:
- Führt Abstandsberechnungen für Knoten durch, die neu in der Kandidatenliste auftauchen, und vermeidet dabei redundante Berechnungen für Knoten, die in früheren Iterationen bewertet wurden.
- Stellt sicher, dass Knoten nur dann in die Top-M-Liste aufgenommen werden, wenn ihre Entfernungen ihre Relevanz rechtfertigen, basierend darauf, ob sie ausreichend klein sind, um dazuzugehören, oder zu groß, um berücksichtigt zu werden.
Der Algorithmus durchläuft diese Schritte iterativ, indem er alle Knoten in der internen Top-M-Liste durchläuft, bis sie alle als Startpunkte für die Suche gedient haben. Die Suche schließt mit der Extraktion der obersten k Einträge aus der internen Top-M-Liste ab und liefert die Ergebnisse der Approximate Nearest Neighbor-Suche (ANNS).
Leistung
Die Entscheidung, GPU-Indizes zu nutzen, wurde in erster Linie durch Leistungsüberlegungen motiviert. Wir haben eine umfassende Bewertung der Leistung von Milvus unter Verwendung eines Open-Source-Vektordatenbank Benchmark-Tools vorgenommen und uns dabei auf Vergleiche zwischen HNSW, GPU-basierten IVFFLAT- und CAGRA-Indizes konzentriert.
Benchmarking-Setup
Für eine realistische Bewertung wurden unsere Benchmarks auf von AWS gehosteten Maschinen durchgeführt, die mit NVIDIA T4- und A10G-Grafikprozessoren ausgestattet waren, um sicherzustellen, dass die Testumgebungen den allgemein verfügbaren Ressourcen entsprachen. Die ausgewählten Rechner waren preislich vergleichbar und boten somit gleiche Voraussetzungen für die Leistungsbewertung. Alle Tests zielten darauf ab, top100@98 % Recall zu erreichen, wobei eine AWS m6i.4xlarge-Instanz (16C64G) als Client verwendet wurde.
Grundlegende Informationen zur ausgewählten Maschine (https://assets.zilliz.com/Basic_Info_for_Selected_Machine_2fb7d5556e.png)
Einblicke in die Leistung
Kleinserienleistung:
In Situationen mit kleinen Suchstapeln (Stapelgröße 1), in denen GPUs in der Regel nicht voll ausgelastet sind, übertraf CAGRA seine Konkurrenten deutlich. Unsere Tests ergaben, dass CAGRA unter diesen Bedingungen fast die 10-fache Leistung herkömmlicher Methoden erbringen kann.
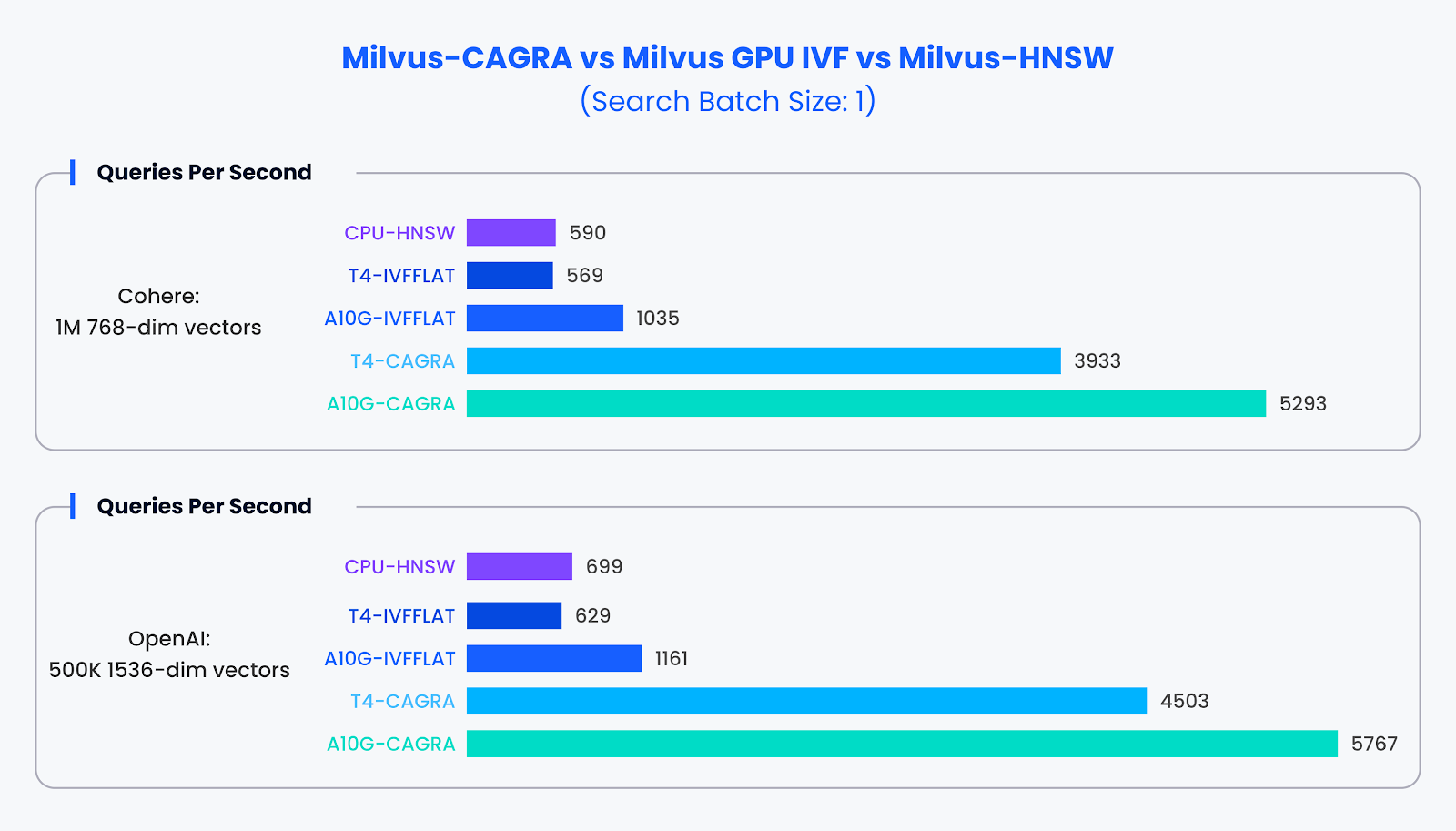 Leistungsvergleich für Small-Batch-Datensatz
Leistungsvergleich für Small-Batch-Datensatz
Large-Batch-Leistung:
Bei der Untersuchung größerer Suchstapel (Größen von 10 und 100) wurde der Vorteil von CAGRA noch deutlicher. Im Vergleich zu HNSW zeigte CAGRA eine dramatische Leistungssteigerung und verbesserte die Sucheffizienz um das Zehnfache.
 Leistungsvergleich für Large-Batch-Datensatz
Leistungsvergleich für Large-Batch-Datensatz
Index Gebäude-Effizienz:
Über die Suchfunktionen hinaus erstreckt sich die Leistungsfähigkeit von CAGRA auch auf die Indexerstellung. Mit GPU-Beschleunigung demonstrierte CAGRA die Fähigkeit, Indizes etwa 10-mal schneller als alternative Methoden zu erstellen.
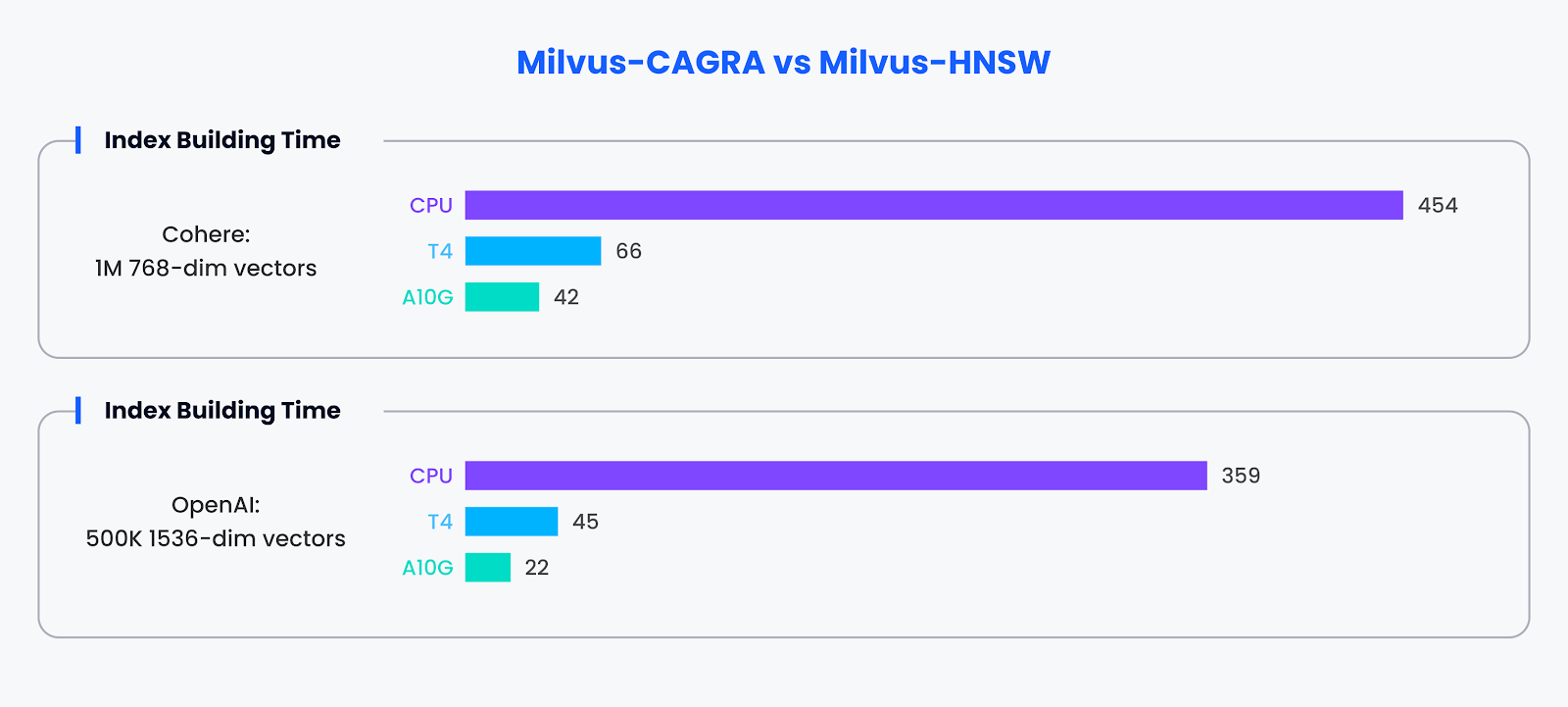 Leistungsvergleich für Indexaufbau
Leistungsvergleich für Indexaufbau
Die Benchmark-Ergebnisse unterstreichen die erheblichen Leistungsvorteile, die der Einsatz von GPU-beschleunigten Indizes wie CAGRA in Milvus bietet. Es zeichnet sich nicht nur durch die Beschleunigung von Suchaufgaben über Stapelgrößen hinweg aus, sondern verbessert auch die Geschwindigkeit der Indexerstellung erheblich, was den Wert von GPUs bei der Optimierung der Leistung von Vektordatenbanken unterstreicht.
Was kommt als Nächstes?
CAGRA ist ein bedeutender Schritt nach vorn in unserem Bestreben, die Grenzen der Vektorsuche neu zu definieren und das Potenzial der GPU-basierten Suche bei der Bewältigung der anspruchsvollsten Produktionsanforderungen zu demonstrieren. Im weiteren Verlauf wird Milvus die Aspekte [hoher Rückruf] (https://zilliz.com/blog/diskann-a-disk-based-anns-solution-with-high-recall-and-high-qps-on-billion-scale-dataset), niedrige Latenz, Kosteneffizienz und Skalierbarkeit bei der Vektorsuche weiter erforschen. Unser Engagement geht über die aktuellen Errungenschaften hinaus und umfasst eine flexiblere Datenverwaltung, erweiterte Suchfunktionen und bahnbrechende Leistungsoptimierungen.
Diese Vision treibt uns zu ständiger Innovation an und stellt sicher, dass Milvus die Zukunft der beschleunigten Suche für unstrukturierte Daten anführt und bahnbrechend ist. Indem wir die Grenzen dessen, was heute möglich ist, erweitern, wollen wir neue Möglichkeiten für die Zukunft erschließen und die Vektorsuche leistungsfähiger, effizienter und zugänglicher machen.
 Praktische Tipps und Tricks für Entwickler, die Vektordatenbanken verwenden.png
Sind Sie nicht sicher, welchen Index Sie für Ihre Lösung wählen sollen? Wir haben einen Blog, der Ihnen hilft, die richtige Wahl zu treffen!
Praktische Tipps und Tricks für Entwickler, die Vektordatenbanken verwenden.png
Sind Sie nicht sicher, welchen Index Sie für Ihre Lösung wählen sollen? Wir haben einen Blog, der Ihnen hilft, die richtige Wahl zu treffen!

Weiterlesen

Zilliz Cloud Update: Smarter Autoscaling for Cost Savings, Stronger Compliance with Audit Logs, and More
What's new in Zilliz Cloud? Smarter autoscaling with scale-down, audit logs GA, enhanced SSO, and Milvus 2.6 in Private Preview.

Vector Databases vs. Key-Value Databases
Use a vector database for AI-powered similarity search; use a key-value database for high-throughput, low-latency simple data lookups.

AI Integration in Video Surveillance Tools: Transforming the Industry with Vector Databases
Discover how AI and vector databases are revolutionizing video surveillance with real-time analysis, faster threat detection, and intelligent search capabilities for enhanced security.