




Making With Milvus: KI-gestützte Proptech für personalisierte Immobiliensuche
Künstliche Intelligenz (KI) hat leistungsstarke Anwendungen in der Immobilienbranche, die den Prozess der Immobiliensuche verändern. Technikaffine Immobilienfachleute nutzen KI seit Jahren und erkennen ihre Fähigkeit, Kunden dabei zu helfen, schneller die richtige Immobilie zu finden und den Prozess des Immobilienkaufs zu vereinfachen. Die Coronavirus-Pandemie hat das Interesse, die Akzeptanz und die Investitionen in Immobilientechnologie (oder Proptech) weltweit beschleunigt, was darauf hindeutet, dass sie künftig eine zunehmend größere Rolle in der Immobilienbranche spielen wird.
Dieser Artikel untersucht, wie Beike die Vektorähnlichkeitssuche nutzte, um eine Plattform für die Immobiliensuche aufzubauen, die personalisierte Ergebnisse liefert und Angebote nahezu in Echtzeit empfiehlt.
Direkt zu:
Was ist Vektorähnlichkeitssuche?
Vektorähnlichkeitssuche hat Anwendungen in einer Vielzahl von Szenarien der künstlichen Intelligenz, des Deep Learning und traditioneller Vektorberechnungen. Die Verbreitung von KI-Technologie ist teilweise der Vektorsuche und ihrer Fähigkeit zuzuschreiben, unstrukturierte Daten zu erschließen, zu denen Dinge wie Bilder, Videos, Audio, Verhaltensdaten, Dokumente und vieles mehr gehören.
Unstrukturierte Daten machen schätzungsweise 80–90 % aller Daten aus, und daraus Erkenntnisse zu gewinnen, wird schnell zu einer Voraussetzung für Unternehmen, die in einer sich ständig verändernden Welt wettbewerbsfähig bleiben wollen. Die steigende Nachfrage nach Analysen unstrukturierter Daten, zunehmende Rechenleistung und sinkende Rechenkosten haben KI-gestützte Vektorsuche zugänglicher gemacht als je zuvor.
 Den Unterschied zwischen strukturierten und unstrukturierten Daten verstehen.
Den Unterschied zwischen strukturierten und unstrukturierten Daten verstehen.
Traditionell waren unstrukturierte Daten schwer in großem Maßstab zu verarbeiten und zu analysieren, weil sie keinem vordefinierten Modell oder keiner organisatorischen Struktur folgen. Neuronale Netze (z. B. CNN, RNN und BERT) ermöglichen es, unstrukturierte Daten in Feature-Vektoren umzuwandeln, ein numerisches Datenformat, das von Computern leicht interpretiert werden kann. Anschließend werden Algorithmen verwendet, um die Ähnlichkeit zwischen Vektoren anhand von Metriken wie Kosinusähnlichkeit oder euklidischer Distanz zu berechnen.
Letztlich ist Vektorähnlichkeitssuche ein weit gefasster Begriff, der Techniken zur Identifizierung ähnlicher Dinge in riesigen Datensätzen beschreibt. Beike nutzt diese Technologie, um eine intelligente Immobiliensuchmaschine zu betreiben, die Angebote automatisch auf Grundlage individueller Nutzerpräferenzen, des Suchverlaufs und von Immobilienkriterien empfiehlt—und so den Such- und Kaufprozess in der Immobilienbranche beschleunigt. Milvus ist eine Open-Source-Vektordatenbank, die Informationen mit Algorithmen verbindet und Beike damit ermöglicht, seine KI-Immobilienplattform zu entwickeln und zu verwalten.
Wie verwaltet Milvus Vektordaten?
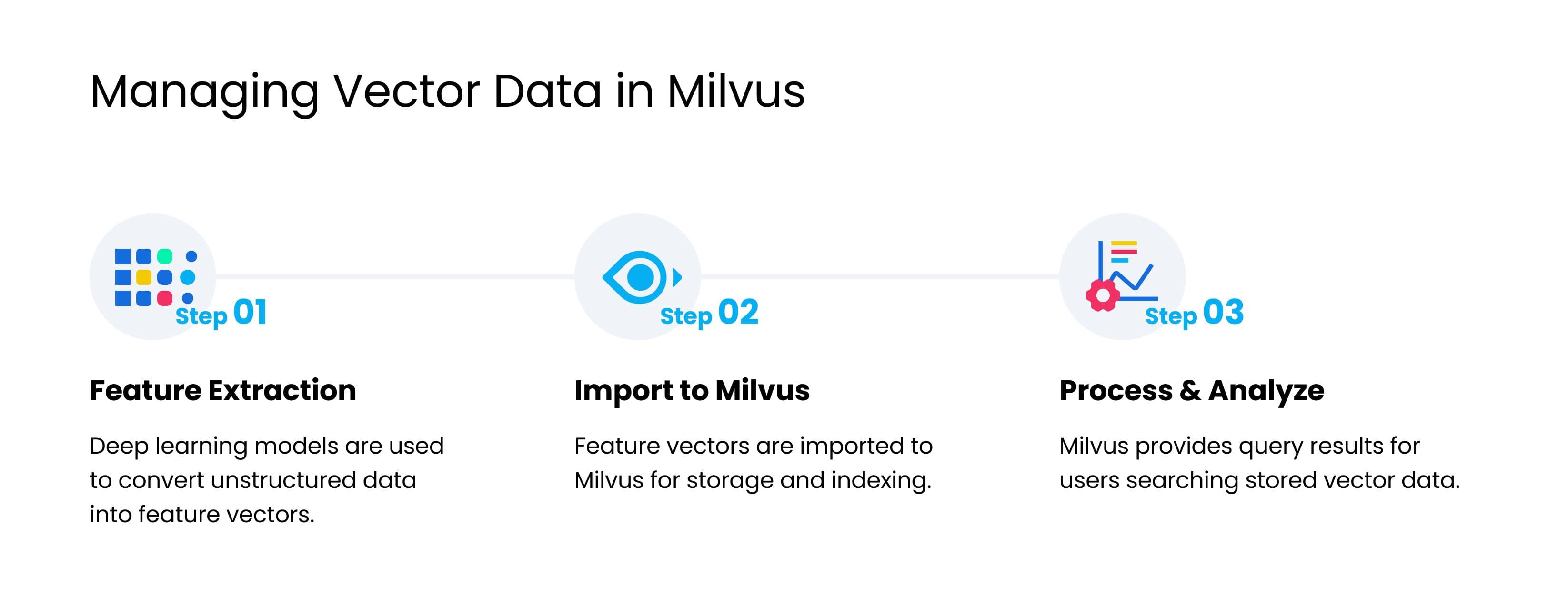
Milvus wurde speziell für die Verwaltung großer Mengen an Vektordaten entwickelt und hat Anwendungen in der Bild- und Videosuche, chemischen Ähnlichkeitsanalyse, personalisierten Empfehlungssystemen, Conversational AI und vielem mehr. In Milvus gespeicherte Vektordatensätze können effizient abgefragt werden, wobei die meisten Implementierungen diesem allgemeinen Prozess folgen:
 Wie verwaltet Milvus Vektordaten?
Wie verwaltet Milvus Vektordaten?
Wie nutzt Beike Milvus, um die Immobiliensuche intelligenter zu machen?
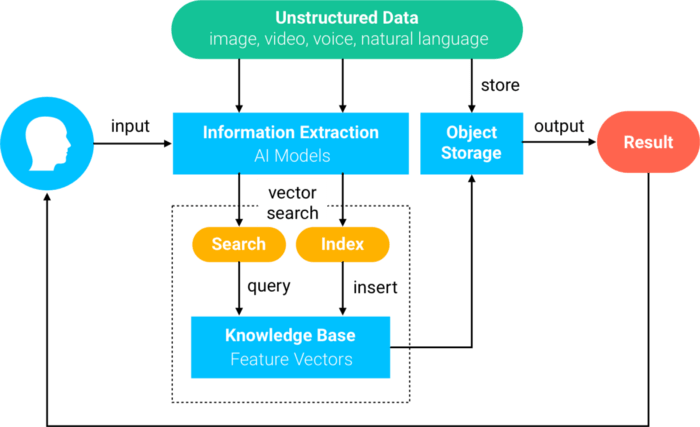
Oft als Chinas Antwort auf Zillow beschrieben, ist Beike eine Online-Plattform, die es Immobilienmaklern ermöglicht, Immobilien zur Miete oder zum Verkauf einzustellen. Um die Erfahrung bei der Haussuche für Wohnungssuchende zu verbessern und Maklern zu helfen, Abschlüsse schneller zu erzielen, entwickelte das Unternehmen eine KI-gestützte Suchmaschine für seine Inseratsdatenbank. Beikes Immobilien-Inseratsdatenbank wurde in Feature-Vektoren umgewandelt und anschließend zur Indizierung und Speicherung in Milvus eingespeist. Milvus wird dann verwendet, um eine Ähnlichkeitssuche auf Basis eines eingegebenen Inserats, von Suchkriterien, eines Nutzerprofils oder anderer Kriterien durchzuführen.
Wenn beispielsweise nach weiteren Häusern gesucht wird, die einem bestimmten Inserat ähneln, werden Merkmale wie Grundriss, Größe, Ausrichtung, Innenausstattung, Wandfarben und mehr extrahiert. Da die ursprüngliche Datenbank mit Immobilieninseratsdaten indiziert wurde, können Suchvorgänge in nur wenigen Millisekunden durchgeführt werden. Beikes Endprodukt hatte eine durchschnittliche Abfragezeit von 113 Millisekunden bei einem Datensatz mit über 3 Millionen Vektoren. Milvus ist jedoch in der Lage, auch bei Datensätzen im Billionenmaßstab effiziente Geschwindigkeiten aufrechtzuerhalten – wodurch diese relativ kleine Immobiliendatenbank mühelos bewältigt wird. Im Allgemeinen folgt das System dem folgenden Prozess:
Deep-Learning-Modelle (z. B. CNN, RNN oder BERT) wandeln unstrukturierte Daten in Feature-Vektoren um, die anschließend in Milvus importiert werden.
Milvus speichert und indiziert die Feature-Vektoren.
Milvus gibt Ähnlichkeitssuchergebnisse basierend auf Nutzerabfragen zurück.
 Ein Überblick über Milvus.
Ein Überblick über Milvus.
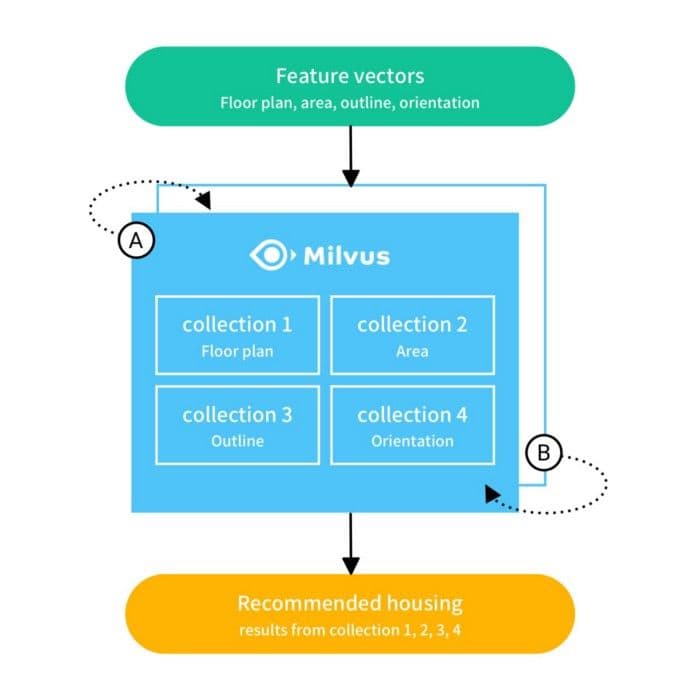
Beikes intelligente Immobiliensuchplattform wird von einem Empfehlungsalgorithmus angetrieben, der Vektorähnlichkeit mithilfe der Kosinusdistanz berechnet. Das System findet ähnliche Häuser basierend auf favorisierten Inseraten und Suchkriterien. Auf hoher Ebene funktioniert es wie folgt:
Basierend auf einem eingegebenen Inserat werden Merkmale wie Grundriss, Größe und Ausrichtung verwendet, um 4 Sammlungen von Feature-Vektoren zu extrahieren.
Die extrahierten Feature-Sammlungen werden verwendet, um eine Ähnlichkeitssuche in Milvus durchzuführen. Die Ergebnisse der Abfrage für jede Vektorsammlung sind ein Maß für die Ähnlichkeit zwischen dem eingegebenen Inserat und anderen ähnlichen Inseraten.
Die Suchergebnisse aus jeder der 4 Vektorsammlungen werden verglichen und anschließend verwendet, um ähnliche Häuser zu empfehlen.
 Ein Überblick über Beikes intelligente Plattform für die Haussuche.
Ein Überblick über Beikes intelligente Plattform für die Haussuche.
Wie die obige Abbildung zeigt, implementiert das System einen A/B-Tabellenwechselmechanismus zur Aktualisierung von Daten. Milvus speichert die Daten der ersten T Tage in Tabelle A, an Tag T+1 beginnt es, Daten in Tabelle B zu speichern, an Tag 2T+1 beginnt es, Tabelle A neu zu schreiben, und so weiter.
Um mehr darüber zu erfahren, wie man Dinge mit Milvus erstellt, sehen Sie sich die folgenden Ressourcen an:
Weiterlesen

Zilliz Cloud On-Demand Compute: Pay Only for What You Use
The customer case behind Zilliz Cloud On-Demand: how a $10K vector search bill came down to under $500, and the engineering changes that made it possible.

Notion's Vector Search Is Excellent. Their Next Problem Is Harder.
Notion solved vector search scaling in two years. The next bottleneck — offline context engineering, unified data, and the real-time/offline gap — is harder.

Why Deepseek is Waking up AI Giants Like OpenAI And Why You Should Care
Discover how DeepSeek R1's open-source AI model with superior reasoning capabilities and lower costs is disrupting the AI landscape and challenging tech giants like OpenAI.