




Redução de Dimensionalidade: Simplificando dados complexos para facilitar a análise
TL;DR: A redução da dimensionalidade é um processo utilizado na ciência dos dados e na aprendizagem automática para reduzir o número de variáveis, ou "dimensões", num conjunto de dados, mantendo o máximo de informação relevante possível. Esta redução simplifica a análise, a visualização e o processamento de dados, especialmente em conjuntos de dados de elevada dimensão. Técnicas como a análise de componentes principais (PCA) e a incorporação de vizinhos estocásticos distribuídos t (t-SNE) identificam padrões e relações nos dados, projectando-os em menos dimensões. Ao descartar caraterísticas menos significativas, a redução da dimensionalidade ajuda a melhorar a eficiência computacional e atenua o sobreajuste, tornando-a essencial para a gestão de dados complexos, particularmente em domínios como a análise de imagens e de texto.
Redução de Dimensionalidade: Simplificando dados complexos para facilitar a análise
A redução da dimensionalidade simplifica um conjunto de dados, reduzindo o número de variáveis ou caraterísticas de entrada, mantendo as informações importantes. Desempenha um papel vital na ciência dos dados e na aprendizagem automática. Torna o trabalho com grandes conjuntos de dados mais fácil de gerir, melhora o desempenho do modelo e poupa recursos computacionais valiosos.
Imagine uma folha de cálculo grande e complexa com muitas colunas de dados. Se algumas dessas colunas não forem úteis ou precisarem de ser clarificadas para a análise, a redução da dimensionalidade corta-as para facilitar o reconhecimento de padrões.
A maldição da dimensionalidade
A maldição da dimensionalidade refere-se aos problemas que surgem quando se analisam e organizam dados em espaços de elevada dimensão. À medida que o número de caraterísticas (ou dimensões) aumenta, o volume do espaço expande-se tão rapidamente que os dados disponíveis se tornam esparsos. Esta esparsidade torna difícil para os algoritmos encontrarem padrões significativos, tornando a análise de dados ineficiente e pouco fiável.
Para compreender o impacto, imagine que está a tentar medir a distância entre pontos num espaço unidimensional, como uma linha reta. Os pontos estão suficientemente próximos para serem facilmente medidos. Se alargarmos este espaço para duas dimensões, como uma folha de papel plana, os pontos espalham-se mais. Quando se aumenta para três dimensões, como uma sala, os pontos espalham-se ainda mais. À medida que as dimensões aumentam, os pontos ficam tão afastados que parecem quase isolados, e o cálculo da distância torna-se menos útil. Isto acontece em dados de elevada dimensão, onde as técnicas comuns de análise de dados podem não funcionar eficazmente porque as relações entre os pontos de dados se diluem, como mostra a figura.
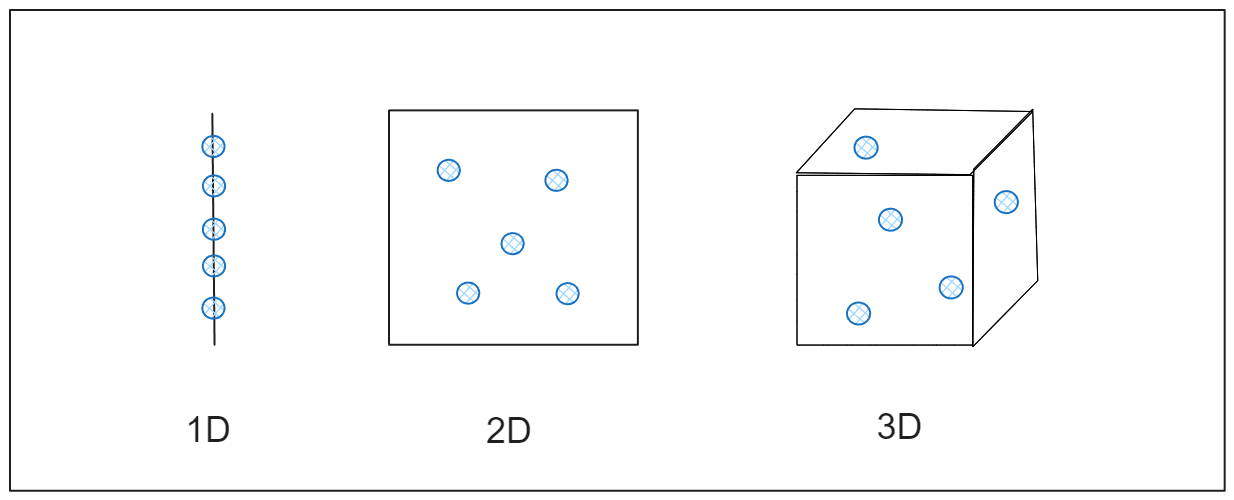 Figura- Como os dados se expandem através das dimensões.png
Figura- Como os dados se expandem através das dimensões.png
Figura: Como os dados se expandem através das dimensões
Uma analogia simples é encontrar amigos num parque. Podem localizar-se rapidamente se vocês e os vossos amigos estiverem espalhados por um pequeno parque. Mas imagine que o parque cresce para o tamanho de uma grande cidade. Agora, mesmo com o mesmo número de amigos, encontrar um deles torna-se um desafio porque todos estão demasiado afastados. Da mesma forma, em espaços de elevada dimensão, os pontos de dados ficam dispersos, tornando difícil para os algoritmos organizá-los ou analisá-los de forma eficiente.
Principais técnicas de redução de dimensionalidade
Embora existam diferentes [estratégias para a redução da dimensionalidade] (https://zilliz.com/learn/streamlining-data-strategies-for-reducing-dimensionality), estas podem ser categorizadas em dois tipos principais: Seleção de caraterísticas e extração de caraterísticas. Ambos os métodos têm como objetivo simplificar os dados, mas de formas diferentes.
Seleção de caraterísticas
A seleção de caraterísticas reduz a dimensionalidade selecionando um subconjunto das caraterísticas mais relevantes do conjunto de dados original. Em vez de transformar os dados, esta abordagem mantém as caraterísticas tal como estão, mas elimina as que não contribuem significativamente para a análise ou para o desempenho do modelo. O objetivo é remover caraterísticas redundantes ou irrelevantes para tornar o conjunto de dados mais simples e mais fácil de trabalhar.
Existem três métodos comuns utilizados para a seleção de caraterísticas:
Métodos de filtro: Estes utilizam testes estatísticos para classificar as caraterísticas com base na sua importância. Os exemplos incluem pontuações de correlação, ganho de informação e testes de qui-quadrado. São simples e funcionam independentemente do modelo de aprendizagem automática.
Métodos de agrupamento**: Estes avaliam diferentes subconjuntos de caraterísticas e utilizam o desempenho do modelo para determinar a melhor combinação. Embora sejam mais exactos, podem ser computacionalmente dispendiosos. Técnicas como a eliminação recursiva de caraterísticas (RFE), a seleção progressiva e a eliminação regressiva pertencem a esta categoria.
Métodos incorporados**: Estas técnicas integram a seleção de caraterísticas no processo de treino do modelo. Modelos como árvores de decisão, regressão Lasso e regressão ridge identificam automaticamente caraterísticas importantes como parte do seu treino.
Extração de caraterísticas
A extração de caraterísticas transforma as caraterísticas originais num espaço de dimensão inferior, criando novas caraterísticas que ainda captam a informação essencial. Esta abordagem é útil quando se comprime os dados mantendo as relações significativas entre as caraterísticas. Ao contrário da seleção de caraterísticas, a extração de caraterísticas cria representações totalmente novas dos dados.
As técnicas mais amplamente adaptadas são a Análise de Componentes Principais (PCA), a Incorporação de Vizinhos Estocásticos Distribuídos t (t-SNE) e a Análise Discriminante Linear (LDA). Vamos discuti-las em pormenor.
Análise de componentes principais (PCA)
A análise de componentes principais (PCA) é uma técnica popular usada para redução de dimensionalidade. O seu principal objetivo é simplificar um grande conjunto de variáveis num conjunto mais pequeno que ainda capta a maior parte da informação nos dados originais.
Para compreender a ACP de uma forma simples, pense num conjunto de dados como um objeto multidimensional, como uma nuvem de pontos no espaço. A ACP encontra as direcções (ou eixos) onde os dados variam mais e projecta os dados nestes novos eixos. O primeiro eixo, designado por componente principal, capta a maior variância (ou dispersão) dos dados. O segundo eixo capta a maior variância seguinte, e assim por diante. Ao concentrar-se apenas nos primeiros componentes, a ACP reduz o número de dimensões, mantendo intacta a estrutura principal dos dados.
Os diagramas seguintes mostram como a ACP funciona para simplificar os dados. À esquerda, há um gráfico de dispersão de pontos espalhados em duas direcções. A ACP encontra a direção principal onde os dados variam mais, mostrada pela seta preta. O lado direito mostra os dados a serem achatados ao longo desta direção.
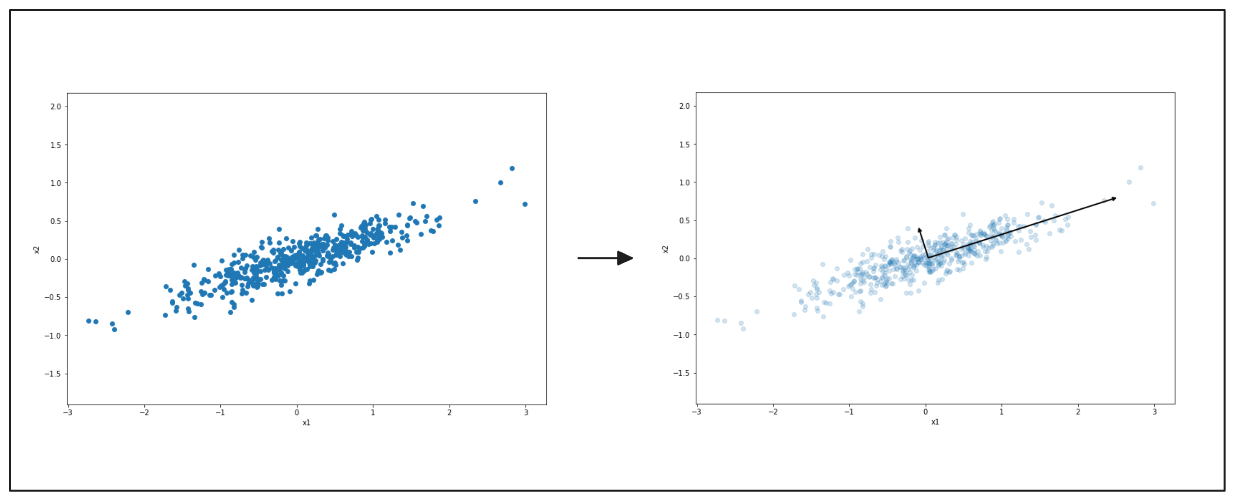 Figura- PCA destacando a direção principal da variação dos dados..png
Figura- PCA destacando a direção principal da variação dos dados..png
Figura: PCA destacando a direção principal da variação dos dados.
Mais uma vez, à esquerda, vêem-se dados espalhados em duas dimensões. A seta preta aponta para a principal direção de variação. À direita, os dados são comprimidos nesta linha, reduzindo-os a uma forma mais simples. Este processo torna os dados mais fáceis de trabalhar, mas mantém os padrões principais.
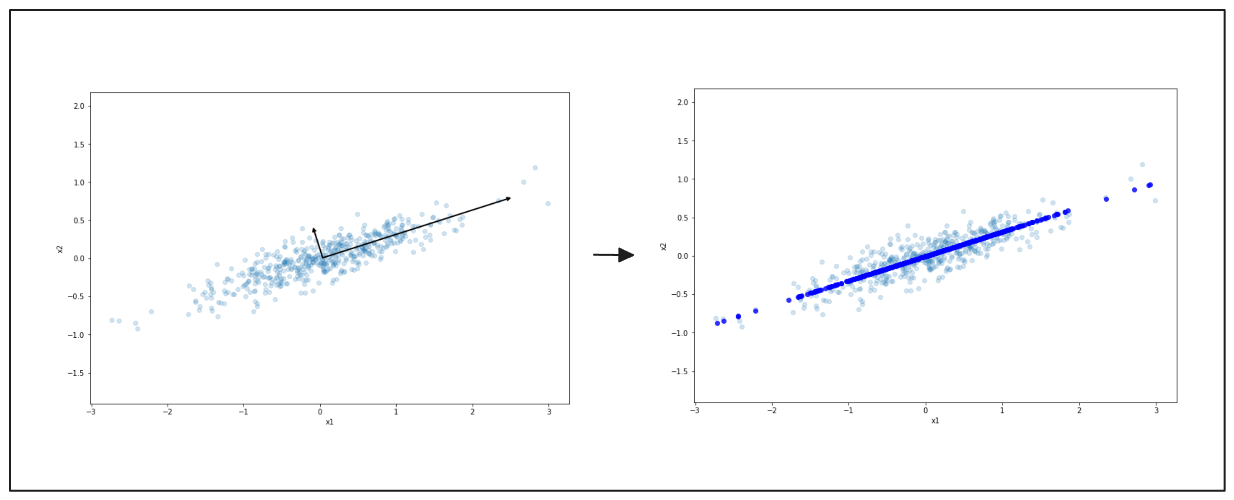 Figura - Representação simplificada de dados com PCA.png
Figura - Representação simplificada de dados com PCA.png
Figura: Representação simplificada de dados com PCA
**Vantagens da utilização da PCA
Reduz a complexidade: A simplificação de conjuntos de dados com muitas variáveis torna a análise mais rápida e eficiente.
Remove o ruído: A PCA filtra o ruído e a informação irrelevante, mantendo os componentes com maior variância.
Melhora a visualização**: A PCA ajuda a visualizar dados de alta dimensão em duas ou três dimensões, revelando padrões que, de outra forma, poderiam estar ocultos.
**Contras da utilização da PCA
Perda de informação**: Alguns dados podem ser perdidos durante a redução da dimensionalidade, afectando o desempenho do modelo.
Interpretabilidade mais difícil**: As novas caraterísticas criadas pela PCA são combinações das caraterísticas originais, o que as torna difíceis de interpretar de uma forma significativa.
Pressupõe linearidade**: A PCA funciona melhor quando as relações entre as variáveis são lineares, o que pode nem sempre ser verdade.
**Aplicações práticas
Compressão de imagens**: Reduz o tamanho do ficheiro de imagem, mantendo as principais caraterísticas visuais.
Finanças**: Simplifica conjuntos de dados complexos para identificar padrões em movimentos de preços de acções.
Genética**: Analisa grandes conjuntos de dados genómicos para descobrir estruturas de dados significativas.
Versatilidade**: Útil para simplificar e interpretar dados altamente dimensionais em vários domínios.
Incorporação de vizinho estocástico distribuído t (t-SNE)
O t-Distributed Stochastic Neighbor Embedding (t-SNE) visualiza dados de alta dimensão. O t-SNE é amplamente valorizado pela sua capacidade de manter as relações locais entre os pontos de dados, o que ajuda a revelar a estrutura subjacente do conjunto de dados. Este método é mais adequado para conjuntos de dados no espaço 3D.
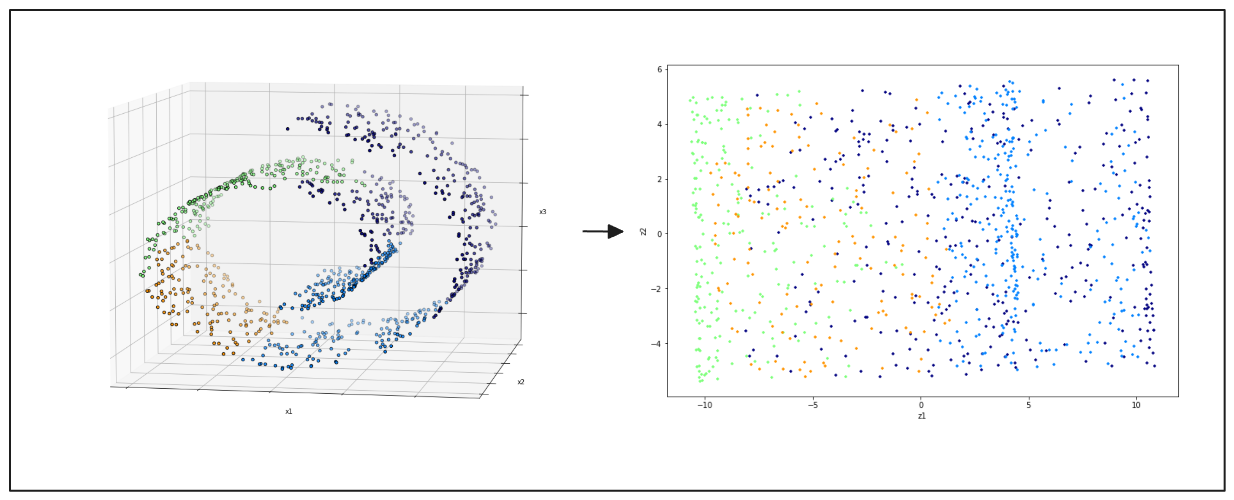 Figura- esquerda- pontos de dados 3D do swiss roll, direita- resultado da projeção 2D do PCA.png
Figura- esquerda- pontos de dados 3D do swiss roll, direita- resultado da projeção 2D do PCA.png
Figura: esquerda: pontos de dados 3D do rolo suíço, direita: resultado da projeção 2D da PCA
Vantagens da utilização de t-SNE
Preservar estrutura local**: t-SNE é excelente em manter pontos de dados próximos no espaço de dimensão inferior, tornando-o eficaz para visualizar clusters.
Útil para dados complexos**: É particularmente bom a lidar com relações não lineares e a explorar padrões intrincados nos dados.
Ótimo para visualização**: O t-SNE produz gráficos de dispersão visualmente intuitivos e apelativos que ajudam a compreender a disposição dos dados.
Contras de usar o t-SNE
Intensivo em termos de computação**: A execução do t-SNE pode ser lenta e exigir muitos recursos, especialmente para grandes conjuntos de dados.
Requer ajuste de parâmetros**: Parâmetros como perplexidade e taxa de aprendizagem devem ser cuidadosamente definidos, e os resultados podem variar significativamente com base nessas configurações.
Distorce a estrutura global**: Embora o t-SNE preserve bem as relações locais, ele pode distorcer a estrutura global dos dados e torná-lo menos útil para entender as relações em grande escala.
**Aplicações práticas
Visualização de dados de alta dimensão**: Útil para explorar estruturas de clusters.
Reconhecimento de imagens**: Visualiza a distribuição das caraterísticas da imagem.
Processamento de Linguagem Natural (NLP): Explora a incorporação de palavras.
Genómica: Identifica grupos de dados genéticos significativos.
Popularidade**: Amplamente utilizado por cientistas de dados para obter informações visuais, apesar das limitações.
Análise Discriminante Linear (LDA)
Ao contrário da PCA, a LDA tem como objetivo maximizar a separação entre diferentes classes nos dados. Fá-lo projectando os dados num espaço de dimensão inferior que melhor separa as categorias com base nas suas etiquetas.
A LDA é normalmente utilizada em cenários em que a classificação de dados é o objetivo principal. É especialmente útil quando se lida com conjuntos de dados que têm limites de classe claros. Algumas aplicações práticas incluem o reconhecimento facial, o diagnóstico médico e a classificação de texto.
Qual a diferença entre LDA e PCA?
Objetivo**: A LDA concentra-se em maximizar a separabilidade das classes, enquanto a PCA tem como objetivo capturar a maior variância nos dados sem considerar as etiquetas das classes.
Supervisionado vs. Não-supervisionado**: A LDA é uma técnica supervisionada que utiliza etiquetas de classe nos seus cálculos. A PCA, por outro lado, não é supervisionada e não utiliza qualquer informação de etiquetas.
Variância de dados**: A LDA reduz as dimensões ao encontrar os eixos que maximizam a distância entre as médias de diferentes classes, minimizando a dispersão dentro de cada classe. A PCA não tem em conta a informação sobre as classes e o seu único objetivo é reduzir a redundância nos dados.
Outras técnicas e métodos emergentes
Além das técnicas tradicionais de redução de dimensionalidade, como PCA, t-SNE e LDA, vários outros métodos e tendências emergentes estão a ganhar força na análise de dados.
Autoencodificadores
Os autoencoders são [redes neuronais] (https://zilliz.com/glossary/neural-networks) utilizadas para a aprendizagem não supervisionada que têm como objetivo comprimir os dados numa representação de dimensão inferior e depois reconstruí-los de volta à sua forma original. A rede é constituída por um codificador que reduz a dimensionalidade e um descodificador que reconstrói a entrada a partir da representação comprimida. Os auto-codificadores são úteis para tratar relações não lineares nos dados e podem aprender representações de caraterísticas complexas.
Análise de componentes independentes (ICA)
A Análise de Componentes Independentes (ICA) é uma técnica computacional para separar um sinal multivariado em componentes aditivos e independentes. Ao contrário do PCA, que se concentra na variância, o ICA procura fontes estatisticamente independentes. Este método é frequentemente utilizado em aplicações como a separação cega de fontes, como o isolamento de diferentes fontes de áudio de uma gravação mista.
Aproximação e Projeção Uniforme de Manifold (UMAP)
A Aproximação e Projeção Uniforme de Manifolds (UMAP) é uma técnica relativamente nova para a redução da dimensionalidade que preserva as estruturas locais e globais dos dados. Baseia-se na aprendizagem de variedades e tem por objetivo manter as relações entre os pontos de dados durante o processo de redução. A UMAP é mais rápida e produz frequentemente melhores visualizações em comparação com a t-SNE.
Benefícios da redução de dimensionalidade
A redução da dimensionalidade oferece várias vantagens importantes que melhoram a análise de conjuntos de dados complexos:
Modelos simplificados: Menos caraterísticas conduzem a modelos mais simples que são mais fáceis de treinar e analisar, o que pode ser crucial para aplicações sensíveis ao tempo.
Reduz os requisitos de armazenamento e computacionais**: O tratamento de dados de menor dimensão resulta em menos armazenamento e tempos de processamento mais rápidos, o que pode reduzir os custos operacionais, especialmente com grandes conjuntos de dados.
Melhora o desempenho do modelo**: Ao considerar as caraterísticas mais significativas, os modelos podem tornar-se mais precisos e robustos, uma vez que é menos provável que sejam afectados por dados irrelevantes.
Melhora a interpretabilidade**: A redução das dimensões pode ajudar a destacar relações essenciais nos dados que ajudam as partes interessadas a compreender as decisões do modelo e os padrões subjacentes.
Facilita a visualização de dados**: A transformação de dados de alta dimensão em duas ou três dimensões permite representações visuais mais claras, ajudando a descobrir informações que podem não ser evidentes em dimensões mais elevadas.
Ajuda na redução do ruído**: Ao remover dimensões menos importantes, a redução da dimensionalidade pode diminuir a quantidade de ruído, resultando em conjuntos de dados mais limpos que contribuem para análises mais fiáveis.
Apoia a melhoria da engenharia de caraterísticas**: O processo pode ajudar a identificar as caraterísticas de maior impacto, proporcionando oportunidades para a criação de caraterísticas melhoradas que podem levar a um melhor desempenho do modelo.
Permite uma prototipagem mais rápida**: Com menos dimensões a considerar, os cientistas de dados podem iterar rapidamente no desenvolvimento de modelos para testes rápidos e refinamento de modelos.
Desafios na redução da dimensionalidade
As técnicas de redução da dimensionalidade apresentam vários desafios que devem ser cuidadosamente considerados:
Risco de perda de informações importantes: A redução de dimensões pode inadvertidamente descartar caraterísticas essenciais, o que pode afetar negativamente o desempenho do modelo e levar a uma má interpretação dos resultados.
Escolher a técnica correta**: A eficácia dos métodos de redução da dimensionalidade varia consoante a natureza do conjunto de dados e os objectivos analíticos específicos. Esta variabilidade faz com que seja crucial compreender os pontos fortes e as limitações de cada técnica para evitar resultados ineficazes.
Custo computacional**: Técnicas como a t-SNE podem consumir muitos recursos e ser menos viáveis para grandes conjuntos de dados. Os requisitos de tempo e memória podem limitar significativamente a sua aplicabilidade em cenários sensíveis ao tempo.
Equilíbrio entre redução e precisão**: Conseguir o nível correto de redução da dimensionalidade e, ao mesmo tempo, garantir que o modelo retém informações suficientes para previsões precisas é um desafio constante. Uma redução excessiva pode simplificar demasiado os dados, afectando a capacidade do modelo para captar a complexidade necessária.
Aplicações da redução de dimensionalidade em vários sectores
As técnicas de redução da dimensionalidade encontram aplicações em vários domínios, melhorando a análise de dados e o desempenho do modelo. Eis alguns cenários práticos em que estes métodos são normalmente utilizados:
Processamento de imagens: Em domínios como a visão por computador, a redução da dimensionalidade ajuda a comprimir os dados de imagem, preservando simultaneamente as caraterísticas essenciais. Por exemplo, no reconhecimento facial, o PCA pode reduzir milhares de valores de pixéis a caraterísticas mais pequenas, acelerando o processamento sem perder detalhes críticos. Do mesmo modo, na imagiologia médica, a redução da dimensionalidade destaca áreas importantes em exames de ressonância magnética para uma análise mais rápida.
Processamento de linguagem natural**: A redução da dimensionalidade é utilizada para simplificar dados de texto de elevada dimensão, tais como a incorporação de palavras. Métodos como o t-SNE ajudam a visualizar as relações e os grupos de palavras, auxiliando a análise de sentimentos e a modelação de tópicos.
Genómica**: Na bioinformática, as técnicas de redução da dimensionalidade são essenciais para analisar dados genéticos, em que o número de variáveis (genes) pode ser extremamente elevado. A redução de dimensões ajuda a identificar marcadores genéticos chave relacionados com doenças.
Finanças**: A redução da dimensionalidade ajuda na gestão de riscos e na otimização de carteiras, simplificando grandes conjuntos de dados de indicadores financeiros. Os analistas podem selecionar as caraterísticas mais relevantes que influenciam o comportamento do mercado.
[Recommendation Systems] (https://zilliz.com/learn/Introduction-to-Recommendation-systems): Na filtragem colaborativa e baseada em conteúdos, a redução da dimensionalidade ajuda a criar algoritmos de recomendação mais eficientes, identificando padrões subjacentes nas preferências dos utilizadores e nas caraterísticas dos itens.
Cuidados de saúde**: A análise de dados de pacientes envolve frequentemente conjuntos de dados de elevada dimensão. A redução da dimensionalidade ajuda a identificar factores significativos que afectam os resultados dos pacientes, melhorando a modelação preditiva da progressão da doença.
Análise de marketing**: No marketing, é crucial compreender o comportamento dos clientes. A redução da dimensionalidade permite às empresas segmentar facilmente os clientes, reduzindo a complexidade dos dados dos clientes, o que conduz a estratégias de marketing direcionadas.
Fabrico e controlo de qualidade**: Nas aplicações industriais, a redução da dimensionalidade ajuda a analisar os dados dos sensores das máquinas para identificar padrões e anomalias, conduzindo a um melhor controlo da qualidade e à manutenção preditiva.
Como a redução de dimensionalidade melhora o desempenho do banco de dados vetorial?
A redução da dimensionalidade melhora significativamente o desempenho de bases de dados vectoriais como a Milvus (criada por engenheiros da Zilliz), que foi concebida para gerir dados não estruturados em grande escala e as suas representações vectoriais de elevada dimensão. Eis como estão interligados:
Armazenamento eficiente de dados: O Milvus pode armazenar dados vectoriais de elevada dimensão gerados por modelos de aprendizagem automática. A aplicação de técnicas de redução da dimensionalidade, como o PCA ou o t-SNE, ajuda a comprimir estes vectores, reduzindo os requisitos de armazenamento e melhorando a velocidade de recuperação.
Desempenho de consulta melhorado**: A pesquisa em dados de elevada dimensão pode ser computacionalmente intensiva numa base de dados de vectores. A redução da dimensionalidade minimiza a dimensionalidade dos vectores, o que acelera as [pesquisas de semelhança] (https://zilliz.com/blog/similarity-metrics-for-vetor-search) e as [consultas ao vizinho mais próximo] (https://zilliz.com/glossary/anns).
Visualização de dados aprimorada: Ao utilizar o Zilliz ou o Milvus para análise de dados, as técnicas de redução de dimensionalidade podem facilitar a visualização de conjuntos de dados complexos. Isto permite aos utilizadores compreender melhor as distribuições de dados, as relações e os padrões nos dados de elevada dimensão armazenados na base de dados.
Facilitar os fluxos de trabalho de aprendizagem automática**: Nos pipelines de aprendizagem automática, a redução da dimensionalidade pode ajudar a otimizar o pré-processamento de dados. A redução da complexidade das caraterísticas de entrada melhora a formação de modelos de aprendizagem automática, conduzindo a um melhor desempenho e interpretabilidade.
Conclusão
A redução da dimensionalidade é uma técnica importante na ciência dos dados e na aprendizagem automática que simplifica conjuntos de dados complexos, preservando a informação essencial. A redução do número de caraterísticas melhora o desempenho do modelo, facilita a visualização e ajuda a facilitar a análise de dados em vários domínios. Apesar dos seus desafios, como o risco de perder informações importantes e a necessidade de uma seleção cuidadosa da técnica, os benefícios da redução da dimensionalidade tornam-na inestimável para descobrir informações e melhorar a eficiência dos processos analíticos.
FAQs sobre redução de dimensionalidade
- O que é a redução da dimensionalidade?
A redução da dimensionalidade é uma técnica utilizada para reduzir o número de caraterísticas ou dimensões num conjunto de dados, preservando o máximo possível de informações relevantes. Essa simplificação facilita a análise, a visualização e a modelagem de dados complexos.
- Porque é que a redução da dimensionalidade é importante na ciência dos dados?
Ajuda a melhorar o desempenho do modelo, reduz os requisitos de armazenamento e computacionais, melhora a visualização dos dados e simplifica a interpretação do modelo, tornando-a essencial para uma análise de dados eficiente em várias aplicações.
- Quais são algumas técnicas comuns para a redução da dimensionalidade?
As técnicas comuns incluem a análise de componentes principais (PCA), a incorporação de vizinhos estocásticos distribuídos em t (t-SNE), a análise discriminante linear (LDA), métodos de seleção de caraterísticas e técnicas emergentes como autoencoders e UMAP.
- Quais são os desafios associados à redução da dimensionalidade?
Os desafios incluem o risco de perder informações importantes, a dificuldade de escolher a técnica correta para conjuntos de dados específicos, os custos computacionais de determinados métodos e o equilíbrio entre a redução da dimensionalidade e a precisão do modelo.
- Como é que a redução da dimensionalidade beneficia as bases de dados vectoriais como o Milvus?
A redução da dimensionalidade melhora o desempenho das bases de dados vectoriais, optimizando o armazenamento de dados, melhorando o desempenho das consultas, facilitando a visualização de dados e simplificando os fluxos de trabalho de aprendizagem automática.
Recursos relacionados
Técnicas avançadas de consulta em bancos de dados vetoriais](https://zilliz.com/learn/advanced-querying-techniques-in-vetor-databases)
Racionalização de dados: estratégias eficazes para reduzir a dimensionalidade
A Maldição da Dimensionalidade na Aprendizagem Automática](https://zilliz.com/glossary/curse-of-dimensionality-in-machine-learning)
Normalização de lote versus normalização de camada - desbloqueando a eficiência em redes neurais
- A maldição da dimensionalidade
- Principais técnicas de redução de dimensionalidade
- Outras técnicas e métodos emergentes
- Benefícios da redução de dimensionalidade
- Desafios na redução da dimensionalidade
- Aplicações da redução de dimensionalidade em vários sectores
- Como a redução de dimensionalidade melhora o desempenho do banco de dados vetorial?
- Conclusão
- FAQs sobre redução de dimensionalidade
- Recursos relacionados
Conteúdo
Comece grátis, escale facilmente
Experimente o banco de dados totalmente gerenciado, construído para seus aplicativos GenAI.
Experimente o Zilliz Cloud grátis