




Autoencoders Variacionais Condicionais (CVAEs): Modelos Generativos com Entradas Condicionais

Autoencoders Variacionais Condicionais (CVAEs): Modelos Generativos com Entradas Condicionais
Você já se perguntou como a IA pode gerar imagens ou dados específicos e realistas com base em uma condição, como criar uma imagem de um gato em um determinado estilo?
Autoencoders Variacionais (VAEs) são modelos generativos poderosos, mas não têm controle sobre os atributos dos dados. Autoencoders Variacionais Condicionais (CVAEs) superam essa limitação incorporando condições, como rótulos ou atributos, tanto no codificador quanto no decodificador. Isso permite que os CVAEs gerem dados adaptados a requisitos específicos, tornando-os ideais para tarefas como criação de imagens direcionadas ou geração de conteúdo personalizado, expandindo seu potencial em vários campos.
Vamos explorar como os Autoencoders Variacionais Condicionais (CVAEs) funcionam, suas vantagens e como eles mudam a forma como os dados são gerados em diversos domínios.
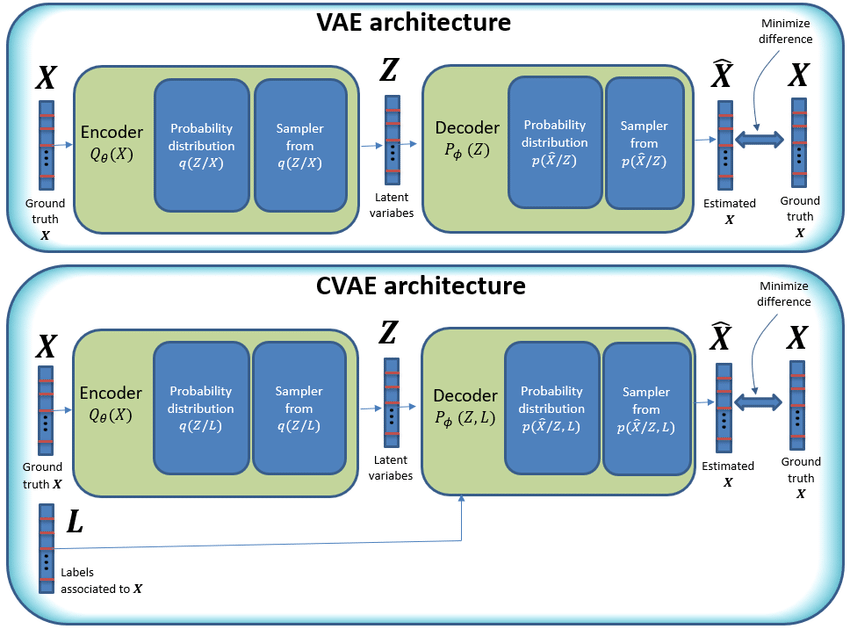
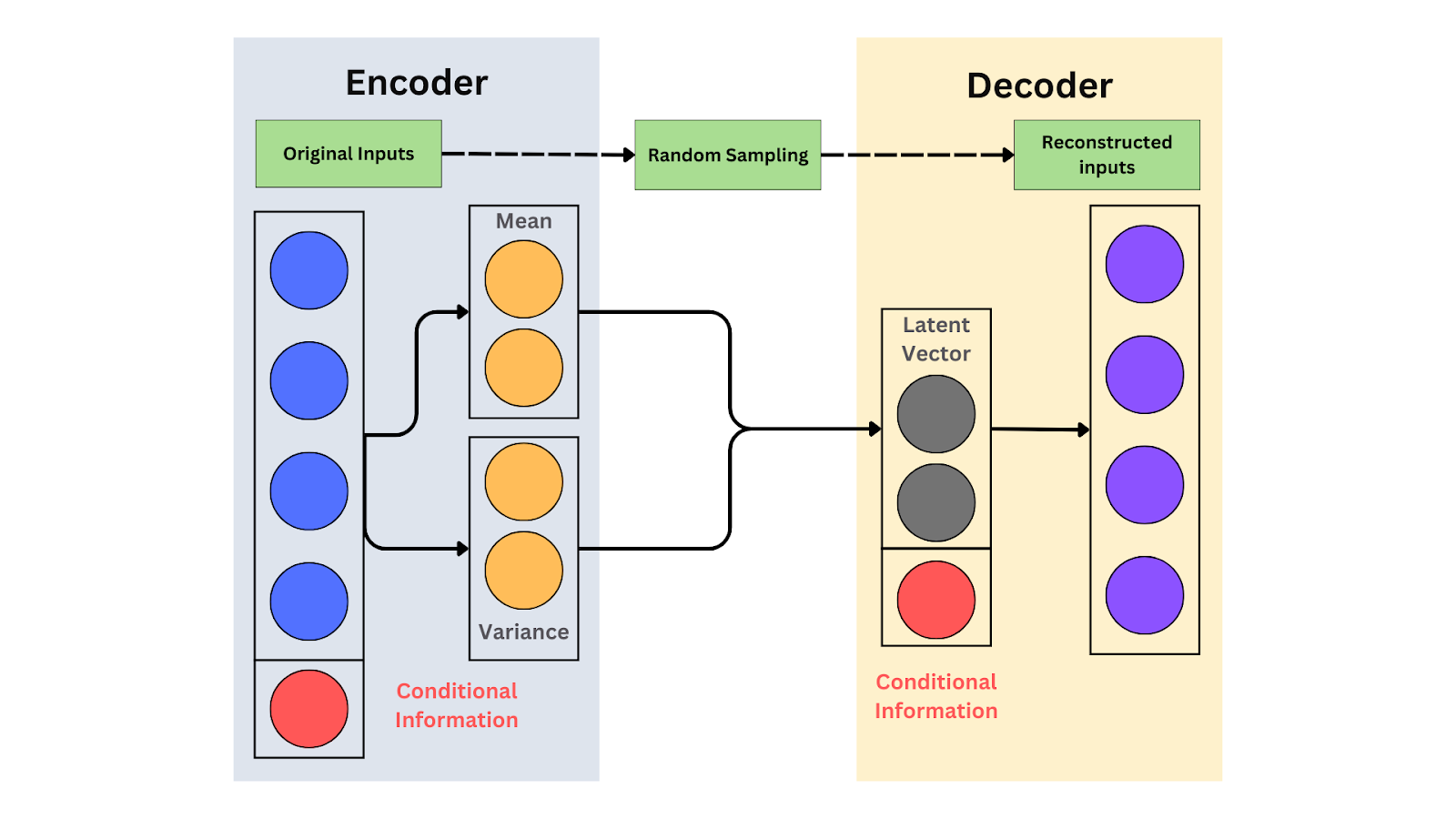 The schematic of a CVAE.png
The schematic of a CVAE.png
O esquema de um CVAE
O que são Autoencoders Variacionais Condicionais (CVAE) ?
Um Autoencoder Variacional Condicional (CVAE) é uma extensão do Autoencoder Variacional (VAE) que incorpora entradas condicionais, como rótulos ou atributos, para orientar o processo de geração de dados. Os dados gerados atendem a requisitos específicos ao condicionar o modelo. Por exemplo, se você quiser criar imagens de gatos ou cães, pode fornecer o rótulo "cat" ou "dog" para orientar a geração. Isso permite que o modelo produza a saída desejada com base na condição.
Os CVAEs são importantes porque fornecem controle sobre a geração de dados. As entradas condicionais garantem que as saídas correspondam a características predefinidas. Isso os torna úteis para tarefas como geração de imagens para design de moda, em que os modelos podem criar peças de roupa em diferentes cores ou estilos, e em simulações direcionadas, em que cenários específicos precisam ser gerados com base em determinadas condições.
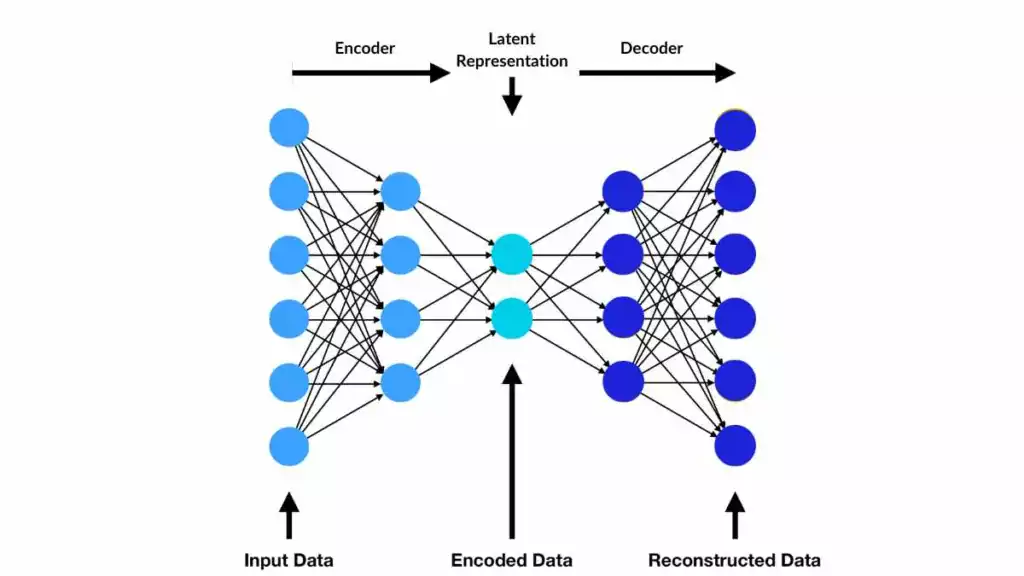 Autoencoder structure underlies VAEs and CVAEs.png
Autoencoder structure underlies VAEs and CVAEs.png
A estrutura do autoencoder fundamenta VAEs e CVAEs | Fonte
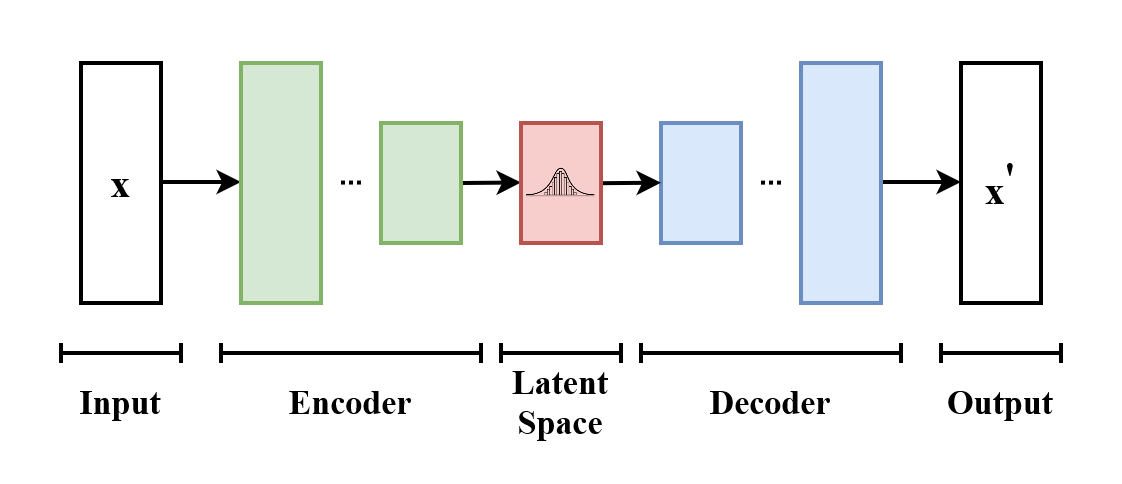
Entendendo os Autoencoders Variacionais (VAEs)
Antes de nos aprofundarmos nos CVAEs, vamos discutir o conceito de Autoencoders Variacionais (VAEs). VAEs são modelos generativos que aprendem a representar distribuições de dados complexas em um espaço latente contínuo para gerar novas amostras de dados.
VAEs contêm dois componentes principais: um codificador e um decodificador. O codificador comprime os dados de entrada em um espaço latente, capturando suas principais características. O decodificador reconstrói a entrada ou gera novas amostras a partir dessa representação latente. Uma função de perda desempenha um papel fundamental no treinamento ao equilibrar a precisão da reconstrução e a regularidade do espaço latente. A Regularização garante que o espaço latente seja suave e estruturado, permitindo a geração coerente de dados.
Função de Perda
A função de perda em Autoencoders Variacionais (VAEs) consiste em dois componentes principais: perda de reconstrução e divergência KL.
- Perda de Reconstrução mede quão bem o modelo reproduz os dados de entrada. Ela é normalmente calculada usando Erro Quadrático Médio (MSE) ou Entropia Cruzada Binária. A equação para a perda de reconstrução é:
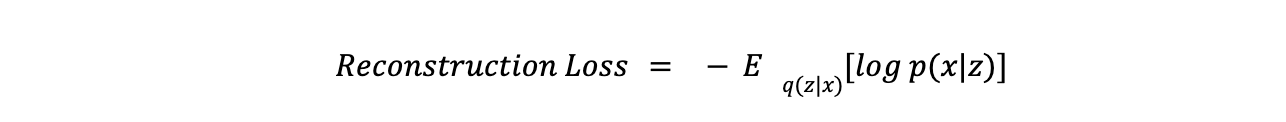
- Divergência KL, abreviação de divergência de Kullback-Leibler, é uma medida estatística de como uma distribuição de probabilidade difere. No contexto dos VAEs, ela garante que a distribuição latente 𝒒(𝔃∣𝔁) (aprendida pelo codificador) permaneça próxima da distribuição a priori 𝒑(𝔃), que normalmente é uma distribuição gaussiana padrão. A equação para a divergência KL é:
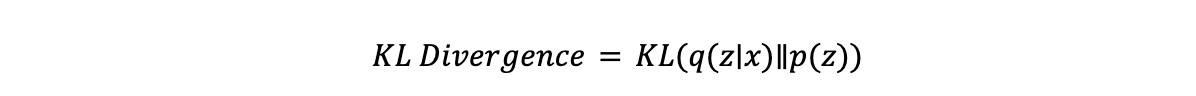
A função de perda geral é uma soma ponderada desses dois termos:
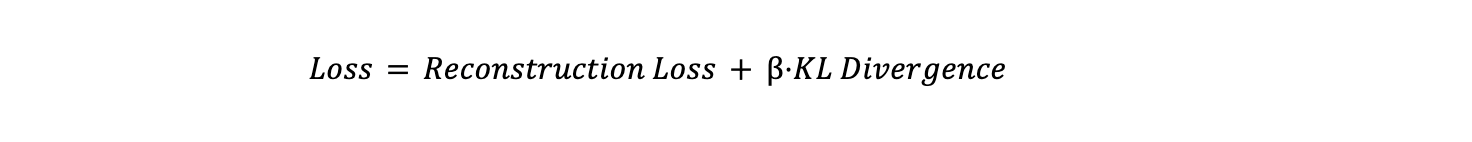
Onde β é um hiperparâmetro que controla o equilíbrio entre a perda de reconstrução e a divergência KL. Um β mais alto dá mais importância à regularização do espaço latente, enquanto um valor mais baixo permite que o modelo se concentre mais na reconstrução precisa. Esse equilíbrio é crucial para garantir que o modelo gere dados precisos e aprenda um espaço latente significativo e bem-comportado.
Regularização
A regularização usa a divergência de Kullback-Leibler para alinhar o espaço latente com a distribuição prévia, garantindo que as variáveis latentes sigam uma distribuição gaussiana. Isso suaviza o espaço latente, permitindo interpolação e amostragem significativa. Pontos próximos uns dos outros no espaço latente geram saídas semelhantes. A regularização também melhora a generalização ao impedir que o modelo se ajuste excessivamente aos dados de treinamento. Por exemplo, no design de moda, a regularização garante que diversos designs de roupas sejam gerados mantendo padrões e estilos realistas. Ela ajuda a criar variações em tipos de roupas, cores e texturas, sem produzir saídas irreais. Ao manter o espaço latente estruturado, ela gera designs que se alinham às tendências atuais, mas são diferentes à sua própria maneira.
 Structure of a Variational Autoencoder (VAE) |.png
Structure of a Variational Autoencoder (VAE) |.png
Estrutura de um Autoencoder Variacional (VAE) | Fonte
{kind=link}
Como o CVAE melhora o VAE com entradas condicionais?
CVAEs estendem VAEs adicionando entradas condicionais, como rótulos de classe, para orientar a geração de dados. O codificador processa tanto os dados de entrada quanto a condição. Ele os mapeia em um espaço latente conjunto, capturando os dados e a condição combinados. O decodificador então usa essa representação latente, uma versão comprimida dos dados, junto com a condição para gerar novas amostras.
Por exemplo, se a condição for "tênis vermelhos", o decodificador gera uma imagem de tênis vermelhos. A condição garante que a saída corresponda a requisitos específicos. Assim como os VAEs, os CVAEs usam a divergência KL para regularizar o espaço latente e criar uma distribuição suave.
VAEs dependem apenas das variações dos dados de entrada, limitando o controle sobre a saída. CVAEs usam rótulos ou atributos para orientar o processo de geração. Isso permite saídas direcionadas e específicas. Por exemplo, em um CVAE treinado no MNIST, a condição poderia ser um rótulo de dígito como "5." Dado o rótulo e uma entrada, o modelo gera um "5" específico. Um VAE, em contraste, poderia gerar qualquer dígito aleatório dependendo do espaço latente.
CVAEs são ideais para tarefas como gerar imagens com características específicas ou personalizar conteúdo. Por exemplo, um CVAE pode gerar um design de tênis com base nas preferências de cor, tamanho e estilo de um usuário, melhorando a personalização e a experiência do usuário.
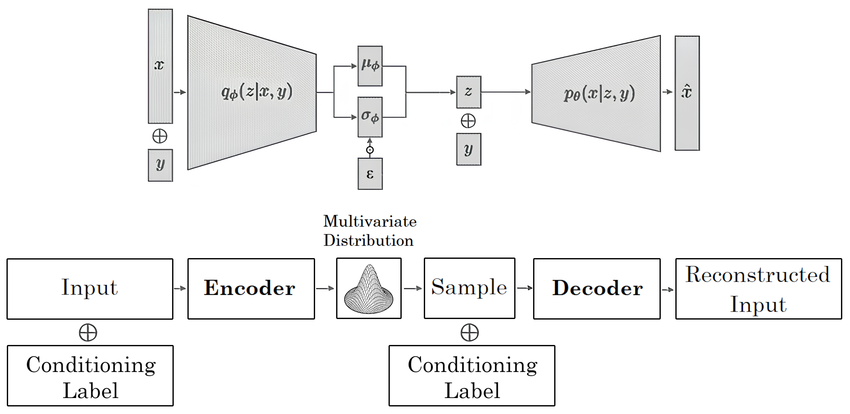 Conditional Variational Autoencoder (CVAE) Architecture.png
Conditional Variational Autoencoder (CVAE) Architecture.png
Arquitetura de Autoencoder Variacional Condicional (CVAE) | Fonte
Termos-chave:
Espaço latente: O espaço latente é uma representação comprimida e de alta dimensionalidade dos dados. Ele captura características essenciais dos dados de entrada, como pose ou cor, em uma forma compacta. Por exemplo, uma imagem de um rosto poderia ser comprimida em um vetor que representa idade ou expressão. O espaço normalmente segue uma distribuição conhecida (por exemplo, gaussiana), permitindo a geração de novos pontos de dados semelhantes por meio de amostragem dessa distribuição. Essa representação permite que o modelo manipule ou interpole entre pontos de dados de forma eficaz.
Codificador: O codificador converte dados de entrada em uma representação latente probabilística. Ele mapeia a entrada 𝔁 (como uma imagem) para uma distribuição (média 𝜇, variância 𝝈2) sobre o espaço latente. Por exemplo, para uma imagem de gato, o codificador gera uma distribuição de características como cor e raça. Um vetor latente é amostrado dessa distribuição. O codificador aprende a comprimir dados de forma eficiente, preservando as características essenciais.
Decodificador: O decodificador recebe uma variável latente 𝔃 e reconstrói ou gera dados. Ele mapeia o vetor latente, uma versão comprimida dos dados, de volta para o espaço dos dados originais. Por exemplo, o decodificador gera uma imagem de um gato a partir de um vetor latente que representa características de gato. A função é denotada como 𝒑(𝔁∣𝔃), onde 𝔁 são os dados gerados. O decodificador pode criar saídas diversas ao aprender com as variáveis latentes, mesmo para dados não vistos.
Entradas condicionais: Entradas condicionais fornecem informações extras (por exemplo, rótulos) que orientam a geração de dados. Em CVAE, rótulos como "gato" ajudam a gerar saídas específicas, como imagens de gatos. O codificador e o decodificador usam essas entradas para criar saídas controladas. Por exemplo, o codificador se torna 𝒒(𝔃∣𝔁,𝔂), e o decodificador é 𝒑(𝔁∣𝔃,𝔂). Essas entradas garantem que o modelo gere dados adaptados às condições fornecidas, aumentando a flexibilidade.
- Divergência KL: Divergência KL mede quão diferente é a distribuição aprendida pelo codificador em relação à distribuição a priori (geralmente uma gaussiana). Ela incentiva o codificador a gerar variáveis latentes próximas da distribuição a priori, garantindo um espaço latente estruturado. A fórmula é:
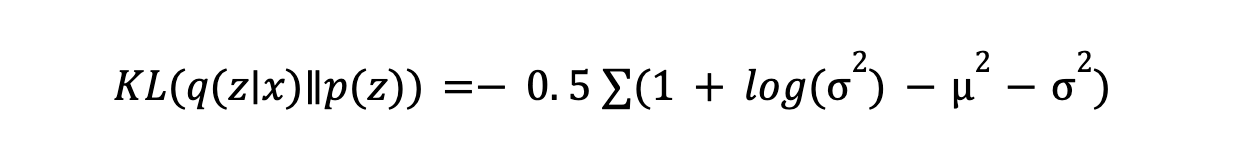
Minimizar a divergência KL ajuda a manter um espaço latente bem-comportado para a geração de dados. Essa técnica de regularização garante que as variáveis latentes sejam distribuídas de uma forma que torne a amostragem e a geração de novos pontos de dados confiáveis.
CVAEs vs. VAEs vs. GANs
Esta seção compara Autoencoders Variacionais (VAEs) com Autoencoders Variacionais Condicionais (CVAEs) e Redes Generativas Adversariais (GANs). Todos são modelos generativos, mas têm várias diferenças importantes.
A tabela a seguir destaca as diferenças em seus mecanismos, flexibilidade e casos de uso.
| Aspecto | VAE (Variational Autoencoder) | CVAE (Conditional Variational Autoencoder) | GANs (Generative Adversarial Networks) |
| Mecanismo central | Codifica os dados de entrada em um espaço latente comprimido e gera novos dados. | Semelhante ao VAE, incorpora entradas condicionais (por exemplo, rótulos) para orientar a geração. | Composto por duas redes: um gerador cria dados, e um discriminador os avalia. |
| Dados de entrada | Apenas os próprios dados são inseridos no codificador. | Dados condicionais (por exemplo, rótulos de classe e atributos) também são usados no codificador. | Usa ruído aleatório como entrada para o gerador, enquanto o discriminador avalia os dados gerados. |
| Representação latente | Representa toda a distribuição dos dados, fornecendo um espaço latente suave e contínuo. | O espaço latente é condicionado aos dados de entrada, proporcionando mais controle sobre a saída gerada. | O espaço latente é aprendido durante o treinamento, sem controle explícito sobre características específicas. |
| Controle da geração | A geração é baseada puramente no espaço latente, sem controles externos. | Dados condicionais permitem a geração de dados com base em atributos específicos (por exemplo, gerar imagens de categorias específicas como “gato” ou “cachorro”). | O gerador “compete” com o discriminador, melhorando os dados gerados ao “enganar” o discriminador. |
| Flexibilidade | Bom para geração de dados de propósito geral e detecção de anomalias. | Ideal para cenários em que é necessária geração controlada com base em atributos específicos. | Muito flexível na geração de amostras realistas, mas com menos controle sobre saídas específicas. |
| Dados de treinamento | Pode ser treinado em um conjunto de dados amplo sem condições explícitas. | Dados rotulados ou condicionais adicionais são necessários para orientar o processo de geração. | Requer treinamento adversarial com gerador e discriminador competindo. |
| Casos de uso | Geração de dados (por exemplo, geração de rostos), detecção de anomalias e interpolação de pontos de dados. | Geração controlada de imagens (por exemplo, geração de objetos ou condições específicas como cor ou estilo), aprendizado semissupervisionado. | Geração de imagens de alta qualidade, tradução imagem-para-imagem, transferência de estilo e aumento de dados. |
| Principais vantagens | Mais simples de treinar, sem necessidade de condições externas. | Permite a geração de saídas altamente específicas, oferecendo melhor controle sobre os dados gerados. | Gera imagens altamente realistas e dados diversos, sem necessidade de rótulos explícitos. |
| Exemplo de aplicação | Geração de imagens aleatórias de rostos. | Geração de imagens de rostos com atributos específicos como idade, gênero ou expressão. | Geração de imagens realistas de rostos humanos, geração de arte ou tradução de imagens de um estilo para outro. |
 Comparison of CVAE with a typical VAE architecture.png
Comparison of CVAE with a typical VAE architecture.png
Comparação do CVAE com uma arquitetura VAE típica | Fonte
 Comparison of the architectures of (A) VAEs and (B) GANs.png
Comparison of the architectures of (A) VAEs and (B) GANs.png
Comparação das arquiteturas de (A) VAEs e (B) GANs | Fonte
Benefícios e Desafios dos Autoencoders Variacionais (VAEs)
Os Autoencoders Variacionais (VAEs) oferecem vantagens significativas na modelagem generativa, mas também apresentam desafios que precisam ser abordados. Vamos primeiro discutir os benefícios de usar VAEs.
Geração Condicional: CVAEs podem gerar novas amostras com base em condições específicas, tornando-os úteis para tarefas como gerar imagens com certas características ou criar conteúdo personalizado. Isso adiciona flexibilidade e versatilidade a várias aplicações.
Representações Significativas: VAEs Condicionais (CVAEs) aprendem representações latentes significativas a partir da entrada, possibilitando uma melhor compreensão e manipulação das estruturas de dados. Isso é particularmente benéfico para tarefas como extração e análise de características.
Personalização: CVAEs podem produzir dados adaptados a necessidades específicas, possibilitando recomendações personalizadas e conteúdo direcionado. Isso os torna altamente valiosos em áreas como publicidade e aplicações personalizadas para usuários.
Aumento de Dados: CVAEs podem ser usados para aumentar conjuntos de dados gerando dados sintéticos diversos e realistas. Essa capacidade ajuda a melhorar o desempenho dos modelos de aprendizado de máquina, especialmente em cenários com conjuntos de dados limitados ou desequilibrados.
Agora, vamos discutir os desafios enfrentados ao usar VAEs.
Colapso de Modos: Ocorre quando o modelo gera apenas alguns tipos de amostras, levando a saídas repetitivas em vez de diversas. O sobreajuste pode piorar esse problema ao fazer com que o modelo memorize padrões específicos em vez de aprender representações latentes significativas. Isso geralmente acontece devido à exploração inadequada do espaço latente ou a dados de treinamento insuficientes e não representativos. Para resolver isso, técnicas de regularização como dropout e normalização em lote podem ser usadas, juntamente com algoritmos de treinamento avançados como Importance-Weighted Autoencoders (IWAE).
Geração de Imagens em Alta Resolução: CVAEs têm dificuldade para gerar imagens em alta resolução de forma eficaz. O espaço latente do modelo pode não conseguir capturar detalhes suficientemente refinados, resultando em saídas borradas ou distorcidas. Essa limitação surge da capacidade restrita do espaço latente e da perda de qualidade em saídas de alta resolução. Mitigar esse desafio envolve usar espaços latentes mais complexos ou VAEs hierárquicos, combinar CVAEs com modelos como GANs ou empregar técnicas de treinamento progressivo que aumentam gradualmente a resolução durante o treinamento.
Casos de Uso de Autoencoders Variacionais Condicionais (CVAEs)
Autoencoders Variacionais Condicionais (CVAEs) são ferramentas versáteis em deep learning, com aplicações em uma variedade de domínios. Aqui estão alguns casos de uso principais:
Geração de Imagens: CVAEs geram imagens condicionadas a atributos como estilo, pose ou iluminação. Em design e moda, são usados para visualizar vestuário em diferentes estilos ou cores. Desenvolvedores de jogos os utilizam para criar aparências diversas de personagens, enquanto fabricantes automotivos os usam para renderizar veículos com várias personalizações para clientes.
Sistemas de Recomendação de Conteúdo: CVAEs aprimoram a personalização ao aprender as preferências dos usuários para sugerir recomendações relevantes. Eles também se adaptam dinamicamente às interações dos usuários, melhorando o engajamento ao longo do tempo.
Descoberta de Fármacos: CVAEs aceleram a inovação médica ao gerar novas estruturas moleculares com base em propriedades desejadas. Eles também otimizam compostos existentes para melhores resultados terapêuticos.
Detecção de Anomalias: CVAEs identificam padrões incomuns em sistemas críticos. Eles sinalizam desvios em relação aos parâmetros operacionais normais e aprimoram a cibersegurança ao detectar atividades de rede incomuns.
Processamento de Linguagem Natural (NLP): CVAEs contribuem para tarefas como gerar texto coerente condicionado ao contexto, estilo ou tom. Eles também facilitam traduções linguísticas sutis adaptadas a requisitos estilísticos.
Arte e Criatividade: CVAEs capacitam artistas e criadores ao possibilitar a transferência de estilo para reimaginar obras de arte em diferentes estéticas. Eles também auxiliam na geração de novas criações artísticas com base em temas ou motivos específicos.
Ética e Responsabilidade em IA: CVAEs apoiam o desenvolvimento responsável de IA ao melhorar a interpretabilidade do modelo por meio da geração controlada de dados. Eles garantem que os sistemas de IA estejam alinhados com padrões éticos ao possibilitar resultados controláveis.
Ferramentas
Agora, exploraremos algumas das ferramentas e frameworks populares que facilitam a implementação e o treinamento de Autoencoders Variacionais Condicionais (CVAEs).
TensorFlow: É um framework poderoso para projetar CVAEs. Ele simplifica a implementação de arquiteturas codificador-decodificador e oferece suporte ao cálculo do termo de divergência KL por meio do TensorFlow Probability. Seu suporte a GPU/TPU garante treinamento eficiente para grandes conjuntos de dados.
PyTorch: É amplamente utilizado por sua flexibilidade e grafo de computação dinâmico, tornando-o ideal para implementações personalizadas de CVAE. Ele permite controle preciso sobre os componentes do modelo, e bibliotecas como Pyro adicionam recursos avançados de modelagem probabilística para funções de perda de CVAE.
JAX e Flax: JAX, combinado com sua biblioteca de redes neurais Flax, oferece computação eficiente para CVAEs. Ele fornece flexibilidade para personalizar cálculos de gradiente e oferece suporte a arquiteturas escaláveis para tarefas complexas de CVAE.
Perguntas Frequentes
O que distingue CVAEs de VAEs padrão? CVAEs usam entradas condicionais para controlar características da saída. VAEs padrão geram dados com base apenas na distribuição de entrada.
Como o condicionamento influencia o processo generativo em CVAEs? O condicionamento orienta o modelo na geração de dados que correspondem a atributos específicos. Ele adiciona controle e precisão à saída.
Quais são as aplicações comuns de CVAEs? CVAEs criam imagens personalizadas, texto personalizado e conjuntos de dados aumentados. Eles funcionam bem em tarefas que precisam de geração de características específicas.
Quais desafios alguém pode encontrar ao treinar CVAEs? O treinamento requer dados rotulados e ajuste cuidadoso. Ele também pode enfrentar problemas de estabilidade e complexidade.
Quais são as limitações dos CVAEs em comparação com GANs? CVAEs podem produzir saídas menos realistas. GANs frequentemente alcançam resultados mais nítidos e detalhados, mas não têm o mesmo controle.
- O que são Autoencoders Variacionais Condicionais (CVAE) ?
- Entendendo os Autoencoders Variacionais (VAEs)
- Como o CVAE melhora o VAE com entradas condicionais?
- CVAEs vs. VAEs vs. GANs
- Benefícios e Desafios dos Autoencoders Variacionais (VAEs)
- Casos de Uso de Autoencoders Variacionais Condicionais (CVAEs)
- Ferramentas
- Perguntas Frequentes
Conteúdo
Comece grátis, escale facilmente
Experimente o banco de dados totalmente gerenciado, construído para seus aplicativos GenAI.
Experimente o Zilliz Cloud grátis