




O que é um Vector Lakebase?
TL;DR
- Uma Vector Lakebase é uma arquitetura de dados unificada e nativa de lake para IA que combina atendimento de nível de banco de dados vetorial com armazenamento aberto em lake, índices reutilizáveis no nível do lake e uma camada semântica compartilhada.
- Ela permite que os mesmos dados não estruturados impulsionem o atendimento online (RAG, agentes, busca semântica) e a descoberta offline (clusterização, deduplicação, re-embedding, governança) — sem copiar dados entre sistemas.
- Zilliz Vector Lakebase é uma implementação dessa arquitetura: uma evolução do Zilliz Cloud de um banco de dados vetorial gerenciado para uma plataforma unificada de dados de IA.
O que é uma Vector Lakebase?
Uma Vector Lakebase é uma arquitetura de dados unificada e nativa de lake para IA. Ela combina atendimento de nível de banco de dados vetorial, armazenamento aberto em lake, índices reutilizáveis no nível do lake e uma camada semântica compartilhada, para que os mesmos dados não estruturados possam dar suporte a aplicações de IA online, descoberta interativa e análises offline — sem copiá-los entre sistemas. Ela responde a uma pergunta diferente da recuperação isolada: o que acontece quando equipes de IA em produção precisam dos mesmos dados para recuperação, descoberta, análises, governança, feedback e melhoria contínua?
Ela é melhor entendida como uma expansão do banco de dados vetorial, não como um substituto para ele. A busca vetorial continua sendo o caminho de atendimento de baixa latência; uma Vector Lakebase coloca esse caminho dentro de uma base mais ampla que também pode armazenar, indexar, governar e melhorar continuamente os dados ao seu redor.
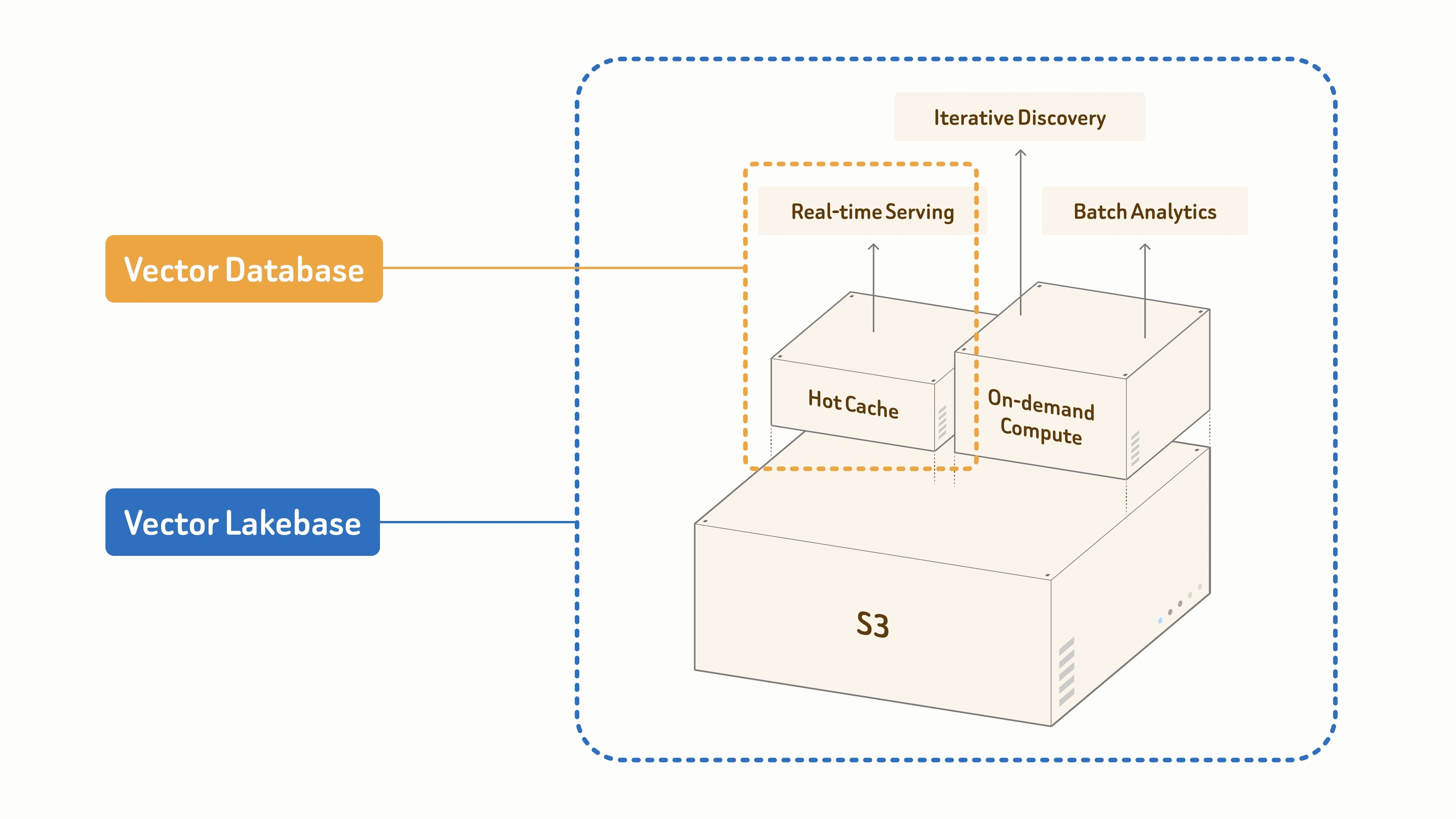
Por que as cargas de trabalho modernas de IA precisam de uma Vector Lakebase
Bancos de dados vetoriais resolveram o primeiro problema de dados da IA moderna: recuperação semântica rápida em escala, impulsionando RAG, agentes e busca semântica. Esse problema ainda importa — mais do que nunca, à medida que os sistemas de IA se espalham.
Mas equipes de IA em produção precisam cada vez mais de mais do que recuperação a partir dos mesmos dados — deduplicação e clusterização para conjuntos de treinamento, detecção de anomalias e deriva, re-embedding conforme os modelos mudam, governança e linhagem, e feedback do comportamento em produção.
A maioria das stacks trata esses fluxos de trabalho como sistemas separados: um data lake para arquivos brutos, um banco de dados vetorial para recuperação online, pipelines em lote para pré-processamento e jobs separados para embeddings e índices. Os dados são copiados entre eles, os índices são reconstruídos, e o atendimento online e a descoberta offline ficam fora de sincronia.
Uma Vector Lakebase remove essa fragmentação fornecendo uma base lógica única de dados para atendimento e descoberta. Ela mantém o caminho de recuperação de baixa latência para o qual os bancos de dados vetoriais foram criados, mas o conecta a uma base nativa de lake onde dados, vetores, índices, metadados e contexto semântico podem ser armazenados, governados, versionados, reutilizados e aprimorados ao longo do tempo. O objetivo não é substituir o banco de dados vetorial pelo lake; é integrar busca vetorial, contexto semântico e processamento de dados não estruturados em uma única arquitetura. (Para o contexto do setor e a engenharia por trás dessa mudança, veja Por que criamos a Vector Lakebase.)
Princípios centrais de design da Vector Lakebase: One Data, One Index, One Semantic Layer
Uma arquitetura Vector Lakebase se apoia em três princípios: One Data, One Index e One Semantic Layer. Eles descrevem onde vive o sistema de registro, como os índices são gerenciados e como o significado é organizado.

One Data: o lake como a base de dados compartilhada
One Data significa que o armazenamento aberto em lake se torna a base compartilhada para dados de IA não estruturados. Arquivos brutos, dados limpos, vetores, campos escalares, metadados, artefatos de índice, rótulos semânticos, linhagem e resultados de processamento offline residem todos dentro de uma única base lógica de dados.
Nesta arquitetura, o banco de dados vetorial não é um novo silo de dados. Ele se torna parte do caminho de serviço de baixa latência. Os dados autoritativos permanecem nativos do lake, enquanto os sistemas online armazenam em cache dados quentes e índices quando necessário. Isso reduz armazenamento duplicado, governança e migração entre sistemas, e permite que os mesmos dados deem suporte a aplicações online, processamento offline, treinamento de modelos, avaliação e governança.
Por exemplo, um documento usado em um sistema RAG também pode fazer parte de um trabalho de clustering offline, de um fluxo de trabalho de exploração de dados de treinamento, de uma revisão de conformidade e de um futuro processo de regeração de embeddings. Em uma arquitetura fragmentada, cada fluxo de trabalho cria sua própria cópia ou representação derivada. Em um Vector Lakebase, esses fluxos de trabalho operam sobre a mesma base lógica de dados.
One Index: índices se tornam ativos em nível de lake
One Index significa que os índices não ficam presos dentro de um único mecanismo de serviço online. Eles se tornam ativos de dados que podem ser criados, versionados, reutilizados e servidos em diferentes modos de computação. Isso importa porque os índices são caros e operacionalmente importantes — eles codificam como um sistema recupera e organiza dados. Se cada fluxo de trabalho precisa criar seu próprio índice, as equipes desperdiçam computação, criam comportamento de recuperação inconsistente e tornam a governança mais difícil.
Em um Vector Lakebase, um índice lógico pode mapear para diferentes formas de serviço com base no padrão de acesso e no custo. Índices quentes oferecem suporte à recuperação online em nível de milissegundos; dados mornos são servidos por meio de cache ou armazenamento em camadas; dados frios permanecem no lake para exploração, governança e análise offline. A mesma linhagem de índice pode dar suporte a serviço RAG, busca semântica, memória de agentes, exploração de dados e processamento em lote — permitindo que as equipes escolham o perfil certo de latência e custo sem quebrar o modelo de dados.
One Semantic Layer: o significado se torna uma camada compartilhada do sistema
One Semantic Layer significa que o sistema gerencia mais do que embeddings. Um embedding é apenas uma representação do ativo subjacente. Uma base de dados de IA útil também precisa de entidades, rótulos, resumos, tópicos, fragmentos de contexto, informações de origem, versões de modelo, políticas de acesso, linhagem e sinais de feedback. Essa camada semântica permite que as equipes organizem dados não estruturados por significado, em vez de apenas por caminho de arquivo, tabela, bucket ou coleção.
Um sistema RAG pode recuperar contexto confiável da camada semântica. Um agente de IA pode entender tarefas anteriores, memórias e resultados de chamadas de ferramentas. Um fluxo de trabalho de dados de treinamento pode descobrir lacunas de cobertura, duplicatas, outliers e viés. Um sistema de governança pode rastrear uma resposta, feature ou amostra até os dados de origem e a versão do modelo que a produziram.
A camada semântica também é o centro do flywheel de dados: aplicações online geram consultas, cliques, citações, correções e feedback; a descoberta offline transforma esses sinais em metadados melhores, conjuntos de dados mais limpos, índices aprimorados e contexto mais forte; e essas melhorias retornam ao serviço. Esse loop é onde um Vector Lakebase se torna mais do que armazenamento mais recuperação.
Como o Vector Lakebase funciona: o flywheel CS/CD, em quatro estágios
Um Vector Lakebase opera como um loop contínuo entre serviço e descoberta — chamamos isso de CS/CD (Continuous Serving e Continuous Discovery). O serviço gera feedback e novos dados, a descoberta os transforma em dados mais limpos e índices melhores, e essas melhorias retornam ao serviço.
Operacionalmente, o mesmo loop passa por quatro estágios: ingestão de dados, vetorização e enriquecimento, serviço de consultas e processamento offline.
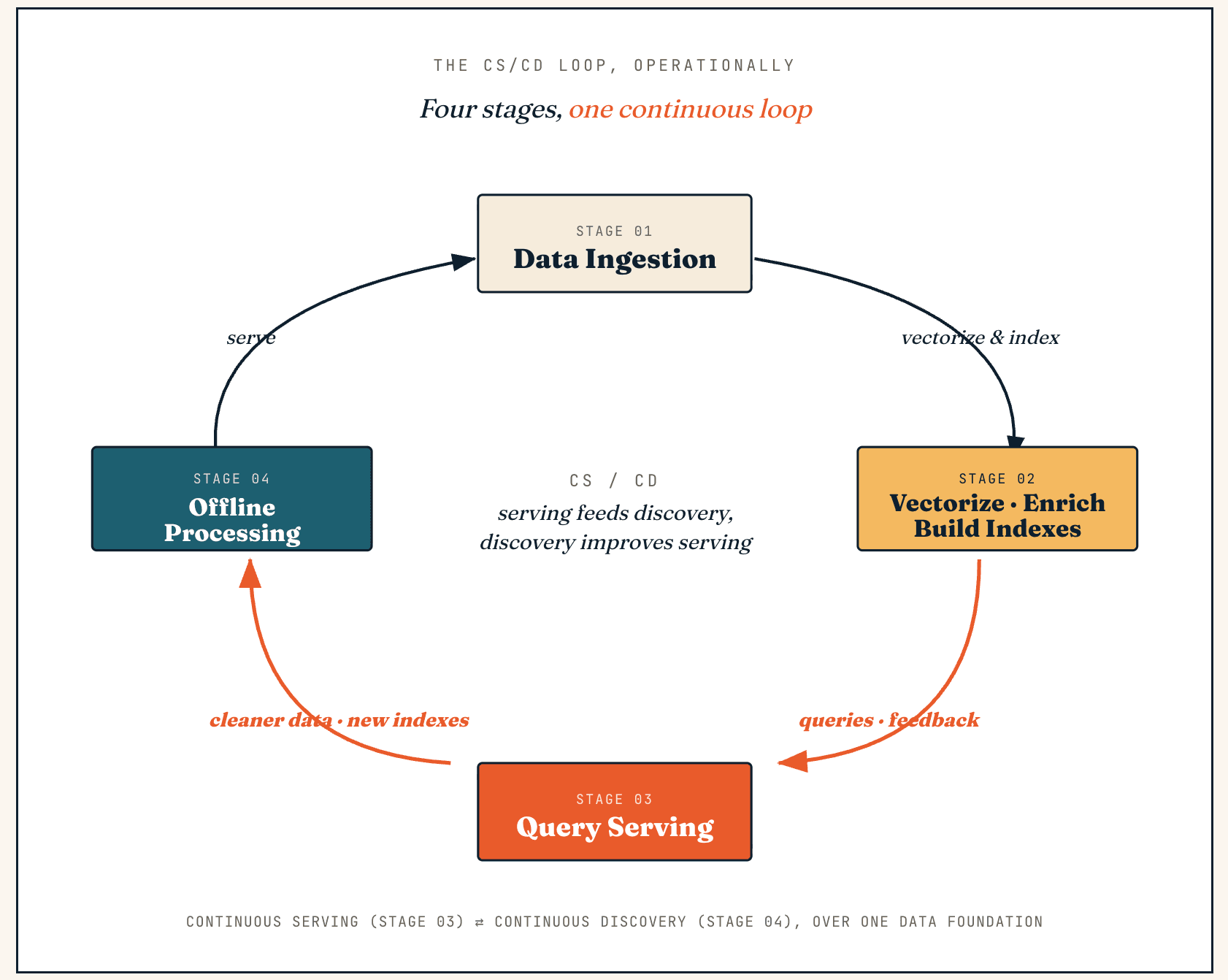
Ingestão de dados
Os dados podem entrar no sistema por meio de uma API de banco de dados vetorial, um pipeline de documentos, armazenamento de objetos ou um formato de lake aberto existente. Os dados podem incluir documentos, vetores, campos escalares, metadados de negócios, imagens, áudio, vídeo, código, logs, conversas, tickets de suporte ou traces de agentes.
À medida que os dados não estruturados crescem, a ingestão também deve oferecer suporte a limpeza, normalização, controle de acesso, rastreamento de origem e linhagem. O sistema precisa saber não apenas o que os dados são, mas de onde vieram, qual modelo os processou, quem pode acessá-los e como podem ser usados. Isso é especialmente importante para IA empresarial. Um sistema RAG ou agente não pode tratar cada parte dos dados recuperados como igualmente confiável. O contexto precisa de consciência da origem, consciência de permissões, atualização e, às vezes, regras de governança específicas do negócio.
Vetorização, enriquecimento e construção de índices
Após a ingestão, o sistema gera representações vetoriais usando modelos de embedding e tarefas de processamento de dados. Ele também enriquece os dados com metadados — entidades, rótulos, resumos, tópicos, informações de origem, permissões, carimbos de data/hora e versões de modelo. Em seguida, cria estruturas de consulta sobre os dados do lake: índices vetoriais, índices de palavras-chave, índices de texto completo, índices JSON, índices escalares e outras estruturas necessárias para recuperação híbrida.
Arquiteturalmente, este é o ponto-chave: os índices não estão vinculados a nenhum mecanismo de serving específico. Eles podem ser versionados, publicados, reutilizados e rastreados até o snapshot dos dados a partir do qual foram construídos — o que torna o gerenciamento do ciclo de vida dos índices parte da base de dados, não um detalhe de implementação enterrado dentro de uma aplicação.
Serving de consultas
Um Vector Lakebase fornece caminhos de recuperação para RAG, busca agentica, busca semântica, recuperação multimodal, memória de IA, recomendação e outras cargas de trabalho de aplicações de IA. O caminho de consulta pode usar um banco de dados vetorial ou camada de cache para dados quentes que precisam de baixa latência, e acessar dados e índices nativos do lake para cargas de trabalho mais frias ou menos frequentes.
Uma consulta pode combinar busca vetorial, busca por palavras-chave, busca de texto completo, filtragem por metadados, predicados escalares, permissões e ranqueamento híbrido — porque a recuperação de IA em produção raramente se baseia apenas em similaridade vetorial. Um bom resultado geralmente depende de relevância semântica, atualização, direitos de acesso, qualidade da origem, metadados de negócio e intenção do usuário.
Processamento offline
O processamento offline inclui clustering, deduplicação, detecção de anomalias, análise de qualidade de dados, exploração de dados de treinamento, evolução de esquema, re-embedding, avaliação e reconstrução de índices. Esses fluxos de trabalho são executados em grandes lotes de dados e nem sempre exigem latência de milissegundos, mas precisam de acesso aos mesmos vetores, metadados, índices e contexto semântico usados por aplicações online.
Sua saída é gravada de volta no lake, no sistema de índices e na camada semântica — datasets mais limpos, rótulos melhores, fragmentos de contexto aprimorados, novas versões de índice ou sinais de feedback atualizados — e publicada como um snapshot atômico para que a produção nunca leia índices parcialmente construídos. Este é o ciclo operacional central: o serving gera feedback, a descoberta melhora os dados, e os dados melhorados retornam ao serving.
Três formatos de carga de trabalho para Vector Lakebases
As cargas de trabalho de dados de IA não têm um único formato. Algumas precisam de serving em nível de milissegundos durante todo o dia. Algumas precisam de uma busca interativa para uma sessão curta de análise. Algumas precisam de grandes tarefas de processamento offline que são executadas, publicam resultados e desaparecem. Um único modelo de armazenamento online sempre ativo não consegue cobrir tudo isso de forma eficiente.
Um banco de dados vetorial tradicional é otimizado principalmente para o primeiro formato de carga de trabalho. Um Vector Lakebase é projetado para todos os três sobre um único dataset lógico.
No Zilliz Vector Lakebase, essas cargas de trabalho se mapeiam para três modos de computação — long-running (residente, serving em milissegundos), on-demand (interativo, cobrado por minuto, a ponte entre serving e descoberta) e offline batch (grandes tarefas que liberam sua computação quando terminam).
| Tipo de carga de trabalho | Exemplos típicos | Padrão de computação |
|---|---|---|
| Atendimento em tempo real | RAG em produção, memória de agentes, busca semântica, recomendação, personalização, busca com IA | Clusters de atendimento de longa duração com índices quentes, caches aquecidos e latência previsível |
| Descoberta interativa | Análise de feedback, inspeção de rastros de agentes, busca de anomalias, recuperação de dados frios, exploração semântica | Computação sob demanda que inicia quando necessário e libera recursos quando a sessão termina |
| Análises em lote | Deduplicação de corpus, clustering, re-embedding completo, preparação de dados de treinamento, reconstrução de índices | Computação em lote para grandes trabalhos que são executados, publicam resultados e desaparecem |
Casos de uso comuns de Vector Lakebases
Como um Vector Lakebase unifica atendimento e descoberta em uma única base, seus casos de uso se dividem em dois grupos.
 图片12
图片12
Casos de uso de recuperação (compartilhados com um banco de dados vetorial, agora em uma base governada):
- RAG — documentos, bases de conhecimento, código e logs como contexto pesquisável, mantidos atualizados, com permissões e reindexáveis conforme os modelos mudam.
- Memória de agentes de IA e uso de ferramentas — armazene e recupere memória de agentes, depois analise-a offline e realimente as descobertas.
- Busca agêntica e multimodal — busca vetorial, por palavra-chave, de texto completo e por metadados em textos, imagens, áudio, vídeo e entidades.
- Sistemas de recomendação e mais.
Casos de uso do ciclo de vida dos dados (além do que um banco de dados vetorial sozinho cobre):
- Engenharia de features e contexto — derive entidades, resumos, tópicos, rótulos e clusters, armazenados junto aos dados dos quais vieram.
- Exploração de dados de treinamento — agrupe amostras em clusters, encontre quase duplicatas, inspecione outliers e rastreie exemplos até a origem.
- Pré-processamento de dados não estruturados — deduplicação, detecção de anomalias, enriquecimento e filtragem de qualidade, gravados de volta no lake.
Como um Vector Lakebase se relaciona com bancos de dados vetoriais e Lakebases
Um Vector Lakebase está relacionado a duas arquiteturas: bancos de dados vetoriais e Lakebase. Ele não substitui nenhuma delas. A tabela abaixo é uma visão rápida; as seções seguintes explicam cada relação.
| Banco de dados vetorial | Vector Lakebase | Lakebase | |
|---|---|---|---|
| Dados primários | Embeddings vetoriais + dados não estruturados associados | Dados não estruturados e multimodais, além de todo o ciclo de vida ao redor deles | Dados de aplicações estruturados / transacionais |
| Função principal | Recuperação semântica de baixa latência | Unificar atendimento online e descoberta offline sobre uma única base | Trazer capacidades de banco de dados (OLTP) para armazenamento aberto em lake |
| Índices | Criados e mantidos dentro do mecanismo de atendimento | Ativos no nível do lake: criados, versionados, reutilizados entre modos de computação | Índices de tabela / SQL |
| Computação | Atendimento sempre ativo | De longa duração + sob demanda + lote offline | Transacional |
| Armazenamento de registro | Frequentemente acoplado ao mecanismo | Armazenamento aberto em lake | Armazenamento aberto em lake |
| Melhor adequação | Busca vetorial rápida para aplicação online | Atendimento e melhoria contínua de dados não estruturados em escala | Dados transacionais de aplicações no lake |
| Relação com vector lakebase | Torna-se o mecanismo de atendimento dentro de um Vector Lakebase | - | A contraparte de dados estruturados da mesma ideia nativa de lake |
Vector Lakebase vs. bancos de dados vetoriais
Um Vector Lakebase não substitui bancos de dados vetoriais. Se uma organização precisa apenas de busca vetorial de baixa latência para uma única aplicação, um banco de dados vetorial pode ser suficiente — ele continua sendo o sistema certo para recuperação em produção quando latência, escala, filtragem e confiabilidade operacional importam. Milvus, por exemplo, é criado para esse tipo de busca vetorial em produção.
O cálculo muda quando uma organização precisa reutilizar os mesmos dados não estruturados, embeddings, índices e contexto semântico entre muitas equipes, modelos, aplicações e fluxos de trabalho de processamento.
Nesse mundo, o banco de dados vetorial não deve ser o único lugar onde dados e índices residem; ele se torna o mecanismo de serving dentro de uma arquitetura mais ampla de dados não estruturados. Seu papel se torna mais específico e mais importante — ele fornece o caminho de serving de que as aplicações de IA precisam, enquanto o Vector Lakebase fornece a base de dados mais ampla em torno desse caminho. O resultado não é menos busca vetorial; é busca vetorial conectada ao ciclo de vida completo dos dados não estruturados.
Se eu só preciso de um banco de dados vetorial, o Vector Lakebase ainda é uma boa opção?
Esse é um ponto de partida perfeitamente válido — porque o banco de dados vetorial já faz parte de um Vector Lakebase. Você pode usar a camada de cluster de serving exatamente como um banco de dados vetorial independente (busca ANN de baixa latência, busca híbrida, filtragem por metadados, recuperação de texto completo, filtragem JSON, gerenciamento de índices, confiabilidade em produção) e nunca tocar em descoberta interativa ou análises em lote no primeiro dia. A diferença é que você não fica preso a uma arquitetura apenas de recuperação: se a carga de trabalho mais tarde se expandir para busca em dados frios, deduplicação em larga escala, re-embedding, preparação de dados de treinamento ou governança semântica, a arquitetura mais ampla já está pronta — sem reconstrução, sem dados duplicados.
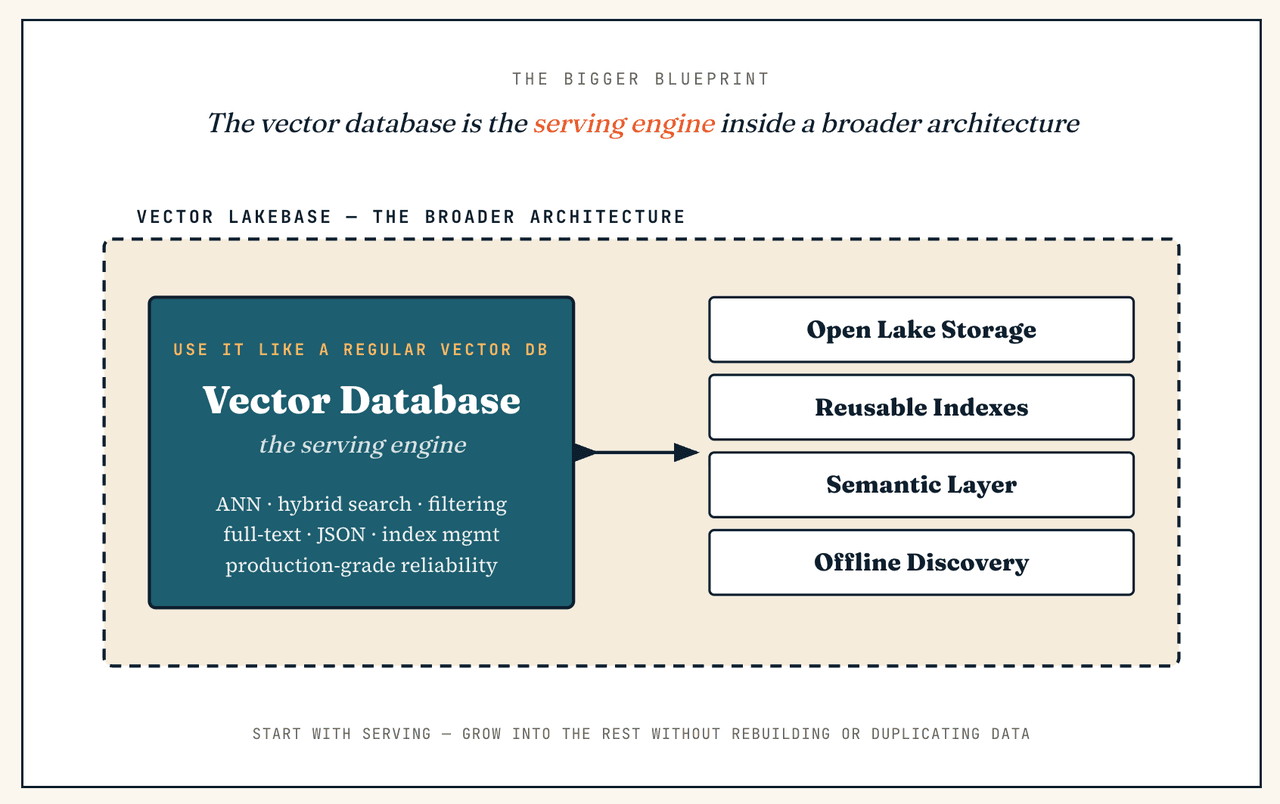
Vector Lakebase vs. Lakebase
Um Vector Lakebase está relacionado a um Lakebase, mas não é apenas "Lakebase com vetores."

Uma arquitetura no estilo Lakebase traz capacidades semelhantes às de banco de dados para armazenamento aberto em lake voltado a dados estruturados de aplicações — registros estruturados, transações, esquemas, computação elástica e governança unificada, consultados por meio de campos e relações conhecidos.
Um Vector Lakebase aborda um centro de gravidade diferente: dados não estruturados e multimodais para IA. O problema não é como armazenar o estado da aplicação em um lake; é como gerenciar representações semânticas, índices vetoriais, metadados, contexto, feedback e fluxos de trabalho de descoberta offline sobre dados não estruturados — o que exige interpretação semântica, recuperação, refinamento e feedback, em vez de buscas sobre campos conhecidos. Ele é melhor descrito não como um substituto do Lakebase, mas como a ideia de Lakebase estendida para a era de vetores, índices e contexto semântico.
| Dimensão | Lakebase | Vector Lakebase |
|---|---|---|
| Dados primários | Dados estruturados de aplicações, registros transacionais, estado da aplicação | Documentos, imagens, áudio, vídeo, logs, código, conversas, vetores, metadados e contexto semântico |
| Abstrações principais | Tabelas, transações, esquemas, branches, clones | Vetores, índices, chunks, entidades, rótulos, resumos, permissões, feedback e relações semânticas |
| Principais cargas de trabalho | Leituras e escritas de aplicações, transações, análises em tempo real | RAG, memória de agentes, busca agentic, recuperação multimodal, descoberta, engenharia de contexto, fluxos de trabalho de dados de treinamento |
| Modelo de consulta | SQL, consultas transacionais, consultas analíticas | Busca vetorial, busca híbrida, busca de texto completo, filtragem JSON, recuperação multimodal, descoberta semântica |
| Modelo semântico | Significado de negócio expresso principalmente por meio do esquema | Significado expresso por meio de embeddings, metadados, entidades, resumos, versões de modelos, linhagem e feedback |
| Valor para IA | Traz capacidades semelhantes às de banco de dados para armazenamento aberto em lake | Traz contexto de IA, indexação vetorial, recuperação semântica e descoberta offline para dados não estruturados nativos de lake |
O que um Vector Lakebase não é
Como Vector Lakebase é um novo padrão de arquitetura, vale a pena deixar claro o que ele não é.
- Não é apenas um data lake com embeddings armazenados em uma coluna. Armazenar embeddings em uma tabela de lake preserva os vetores, mas não fornece nenhum dos recursos de indexação, serving, metadados semânticos, recuperação híbrida, ciclo de feedback ou caminho de recuperação de baixa latência de que os sistemas de IA em produção precisam. Vetores são úteis quando podem ser pesquisados, governados, versionados, filtrados, conectados aos dados de origem e aprimorados ao longo do tempo — não meramente armazenados.
- Não é apenas um banco de dados vetorial conectado a object storage. Colocar object storage por trás de um banco de dados vetorial pode reduzir o custo de armazenamento, mas não resolve a reutilização de índices, a descoberta offline, a governança, o versionamento ou a consistência entre dados processados e servidos. A parte difícil não é onde os bytes ficam; é como dados, índices, metadados, sinais semânticos e modos de computação funcionam juntos como um único sistema operacional.
- Não é um sistema de analytics offline. A descoberta offline é apenas um lado da arquitetura. Um Vector Lakebase também atende ao tráfego de produção, suporta caminhos de recuperação quentes, gerencia índices, aplica controle de acesso e retorna contexto relevante para aplicações e agentes. O objetivo não é escolher entre serving e analytics — é conectá-los.
- Não é um afastamento dos bancos de dados vetoriais. Este talvez seja o ponto mais importante que mencionamos repetidamente. Vector Lakebase não torna os bancos de dados vetoriais menos relevantes. Ele lhes dá uma arquitetura mais ampla na qual operar.
Zilliz Vector Lakebase está disponível em public preview
Lançamos o public preview do Zilliz Vector Lakebase — uma grande evolução do Zilliz Cloud, de um banco de dados vetorial gerenciado puro para uma plataforma unificada de dados semânticos que combina serving vetorial de baixa latência com a abertura, escalabilidade e economia de um data lake.
Principais capacidades do Zilliz Vector Lakebase:
- Serving em camadas otimizado para diferentes trade-offs de desempenho-custo em tempo real
- Busca sob demanda para cargas de trabalho em grande escala ou exploratórias sem computação sempre ativa
- Busca em data lake externo — indexe e pesquise diretamente sobre seus dados de lake existentes
- Busca de IA de espectro completo em vetores, texto, JSON e dados geoespaciais com recuperação híbrida e reranking
- Armazenamento unificado nativo de lake criado sobre Vortex, um formato aberto com leituras aleatórias mais rápidas e baratas do que Lance ou Parquet
Se sua stack atual divide serving e descoberta em sistemas separados, vale a pena dar uma olhada no Vector Lakebase. Experimente no Zilliz Cloud — novos cadastros com e-mail profissional recebem $100 em créditos gratuitos — ou fale conosco sobre seu caso de uso.
Saiba mais sobre Vector Lakebases
- De Vector Database a Vector Lakebase
- Passamos 8 anos tornando a busca vetorial mais rápida. Então a IA mudou o modelo de computação
- Por que criamos o Vector Lakebase: repensando a arquitetura de dados não estruturados para IA
- Vector Lakebase: acabe com o silo de dados de IA
- Zilliz Cloud On-Demand Compute: pague apenas pelo que usar
- A busca vetorial do Notion é excelente. O próximo problema deles é mais difícil.
Continue lendo

Zilliz Cloud BYOC Now Available Across AWS, GCP, and Azure
Zilliz Cloud BYOC is now generally available on all three major clouds. Deploy fully managed vector search in your own AWS, GCP, or Azure account — your data never leaves your VPC.

Zilliz Cloud Update: Tiered Storage, Business Critical Plan, Cross-Region Backup, and Pricing Changes
This release offers a rebuilt tiered storage with lower costs, a new Business Critical plan for enhanced security, and pricing updates, among other features.

Milvus WebUI: A Visual Management Tool for Your Vector Database
Explore Milvus WebUI to monitor, manage, and optimize your vector database with real-time insights, performance tracking, and system health monitoring.