




Pare de criar infraestrutura de dados de IA para a etapa errada
A maioria das decisões de infraestrutura de IA é tomada na primeira semana e lamentada quando você olha para trás no segundo ano.
O problema quase nunca é o modelo, e raramente é a lógica da aplicação. Ele volta sempre à mesma coisa: a infraestrutura de dados deve ser construída para o estágio em que a equipe está.
Em cada estágio, o modo de falha corta para os dois lados. Superengenheirar cedo demais desacelera você. Subestimar, e você reconstrói sob pressão. Ambos criam o mesmo resultado: sobrecarga de iteração que se acumula.
Estágio 1: O Protótipo — Apenas Faça Funcionar
No início, velocidade importa muito mais do que infraestrutura de dados — ou, na verdade, não há necessidade alguma de uma chamada "infraestrutura de dados".
O objetivo não é escalabilidade. O objetivo não é governança. O objetivo não é otimização.
O objetivo é simplesmente fazer a aplicação funcionar.
O erro mais comum neste estágio é confundir sofisticação com qualidade. Equipes adicionam pipelines de ingestão por streaming antes de terem documentos para ingerir. Elas configuram replicação em nível de produção antes de terem um único usuário real. Elas se preocupam com consistência de dados em vários sistemas antes de terem dados suficientes para que a consistência importe.
O resultado: semanas de trabalho de infraestrutura que poderiam ter sido entregues como uma simples mudança de ideia.
Quanto ao tópico em alta "banco de dados vetorial", ele mal importa. Milvus, Elasticsearch, pgvector, ou até mesmo uma biblioteca de busca leve — qualquer um deles fará o trabalho. A diferença de qualidade de recuperação entre as opções é insignificante em comparação com a diferença entre ter um protótipo funcional e não ter um.

O que você realmente precisa neste estágio:
- Seu sistema de arquivos local
- Qualquer banco de dados leve ou biblioteca de busca
Estágio 2: Ajuste Produto-Mercado — Mais Bancos de Dados, Piores Problemas
Quando usuários reais começam a interagir com o sistema, o foco muda de construir uma demonstração para melhorar continuamente o produto, mas uma armadilha diferente aparece.
O equívoco parece razoável: tipos de bancos de dados mais especializados levam a uma melhor qualidade de recuperação.
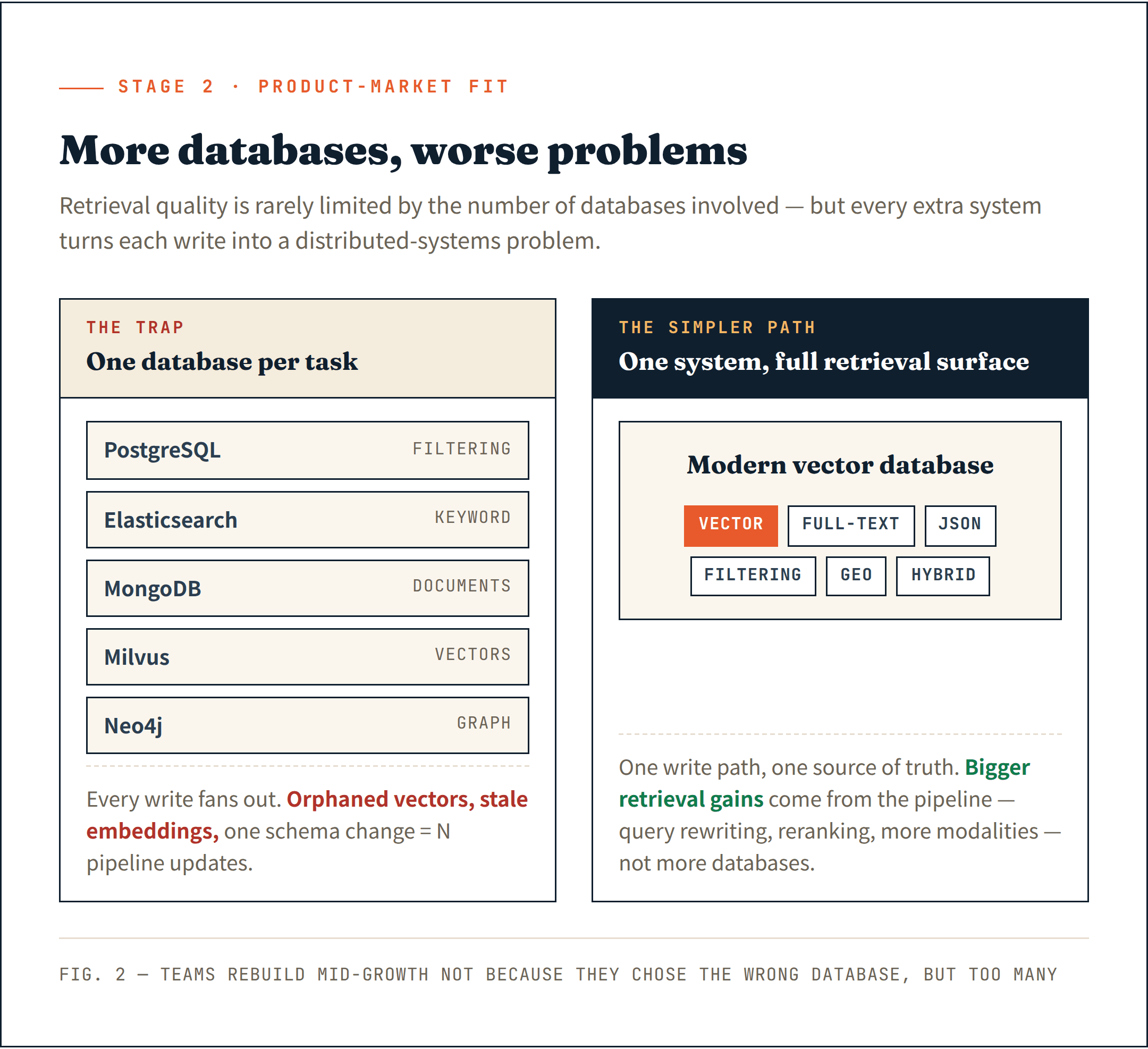
Algumas equipes começam a montar um sistema por tarefa de recuperação — PostgreSQL para filtragem, Elasticsearch para busca por palavras-chave, MongoDB para documentos, Milvus para vetores e Neo4j para relacionamentos em grafo. A stack de recuperação cresce mais rápido do que o próprio produto.
Então chega o problema de sincronização.
Documentos vivem em um sistema. Embeddings em outro. Metadados em um terceiro. Cada operação de escrita se torna um problema de sistemas distribuídos. Uma exclusão com falha deixa vetores órfãos. Uma inserção parcial cria embeddings obsoletos. Uma mudança de schema exige atualizar vários pipelines ao mesmo tempo.
A lição difícil: a qualidade de recuperação raramente é limitada pelo número de bancos de dados envolvidos.
Os maiores ganhos vêm do próprio pipeline de recuperação — reescrita dinâmica de consultas, busca iterativa, divulgação progressiva, reranking melhor. Do lado dos dados, adicionar outro campo de embedding ou outra modalidade frequentemente melhora mais a qualidade de recuperação do que adicionar outro banco de dados especializado.
Bancos de dados vetoriais modernos se expandiram silenciosamente muito além de vetores. Busca full-text, filtragem JSON, busca geoespacial e recuperação híbrida — a maioria dos sistemas maduros agora oferece suporte nativo a isso. A suposição de um banco de dados especializado por tarefa está cada vez mais ultrapassada.
Um único sistema que lida com toda a superfície de recuperação é mais simples de operar e fornece uma base mais limpa para o que vem a seguir.
Vi equipes demais forçadas a reconstruir sua infraestrutura de dados no meio do crescimento — não porque escolheram o banco de dados errado, mas porque escolheram bancos de dados demais.
O que você realmente precisa neste estágio:
- Um serviço de banco de dados gerenciado — deixe o fornecedor cuidar da confiabilidade enquanto você se concentra no produto
- Um único sistema com amplo suporte semântico: vetor, texto completo, JSON, filtragem, híbrido — não um banco de dados por tarefa
- Margem suficiente para crescer até a próxima ordem de magnitude sem reconstruir
Estágio 3: Crescimento em Escala — Nem Toda Carga de Trabalho Deve Compartilhar a Mesma Computação
Este é o estágio em que a pressão de custos se torna inegável. O motivo é simples: os dados sempre crescem mais rápido do que sua receita.
O erro mais comum: presumir que a solução tradicional de banco de dados que trouxe você até aqui o levará mais longe.
Ao contrário do Estágio 2, neste ponto não há espaço fácil para reconstruir. Uma migração de infraestrutura em larga escala sob pressão de crescimento é extremamente cara, extremamente arriscada, ou ambos.
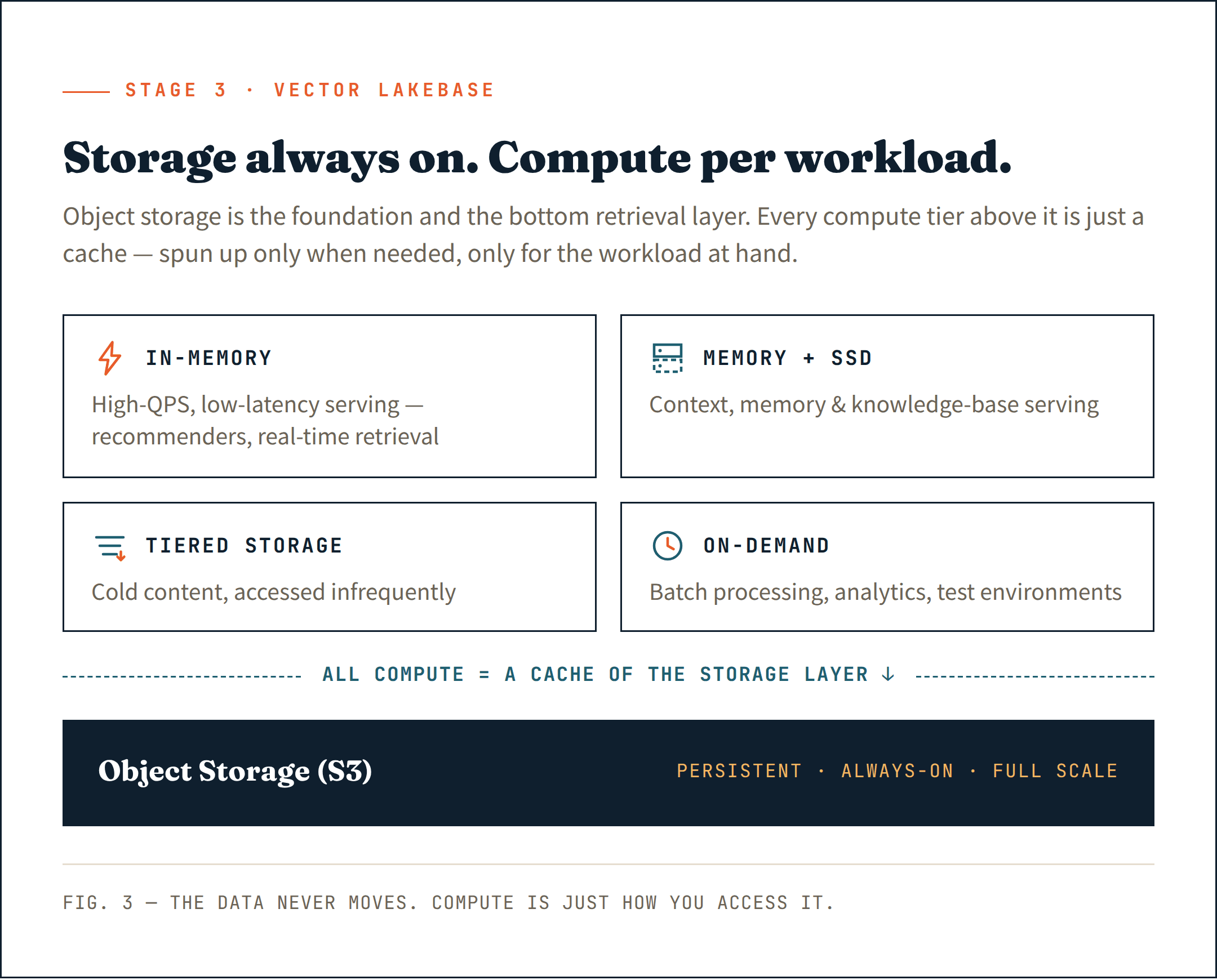
O movimento certo é colocar tudo em armazenamento de objetos (como S3) — não apenas como um armazenamento persistente, mas como a camada base da sua arquitetura de recuperação. É a opção mais barata, mais durável e mais escalável que existe. Trate-a como a fundação, não como algo secundário.
Acima dessa camada, traga computação apenas onde ela é realmente necessária. Clusters de longa duração para atendimento sensível à latência. Recursos de computação efêmeros para ingestão e indexação. Computação sob demanda para análises e trabalhos em lote. Cada carga de trabalho recebe a computação de que precisa — e nada mais.
Essa é a essência de uma Vector Lakebase: armazenamento que está sempre ativo em escala total, computação que não está — ativada apenas quando necessário, apenas para a carga de trabalho em questão.
Mais importante ainda, toda computação — seja de longa duração ou sob demanda — atua como um cache da camada de armazenamento de objetos. Os dados sempre residem no armazenamento. A computação é apenas como você os acessa.
Combine cada carga de trabalho com o nível de computação correto:
- Em memória para cargas de trabalho de alto QPS e baixa latência — sistemas de recomendação de IA, recuperação em tempo real
- Memória + SSD para servir contexto, memória e bases de conhecimento
- Armazenamento em camadas para conteúdo frio acessado com pouca frequência
- Computação sob demanda para processamento em lote, análises internas e ambientes de teste
Feita corretamente, essa abordagem reduz os custos de infraestrutura em 50% ou mais em comparação com um design unificado — ao mesmo tempo em que oferece uma qualidade de serviço muito melhor para cada carga de trabalho.
Soluções serverless frequentemente deixam de funcionar bem neste estágio — não tecnicamente, mas economicamente. Quando seus dados chegam aos terabytes, os custos de inserção e armazenamento começam a dominar. O motivo é estrutural: arquiteturas serverless incorporam a sobrecarga de pooling, indexação e custos de dados persistentes aos acréscimos de escrita e armazenamento. Você não está mais pagando pelo que usa. Está pagando pela abstração.
O primeiro princípio para infraestrutura de dados neste estágio é simples: sua fundação precisa escalar com seus dados, não contra eles. Uma arquitetura forçada a atender igualmente bem a todas as cargas de trabalho acaba não atendendo bem a nenhuma — e o custo desse compromisso se acumula a cada gigabyte que você adiciona.
Do que você realmente precisa neste estágio:
- Armazenamento de objetos (S3) como fundação e camada inferior de recuperação — persistente, sempre ativo em escala total, a camada da qual toda computação lê
- Uma Vector Lakebase: dados que nunca se movem, computação que é ativada por carga de trabalho e nada mais
- O nível de computação correto para cada tipo de carga de trabalho
Estágio 4: Escala Empresarial — A Confiança Torna-se Parte do Produto
Neste estágio, a maioria das equipes acredita que a parte difícil ficou para trás. Não ficou.
O erro comum: as equipes ainda pensam que o problema é técnico.
Elas otimizaram a infraestrutura. Controlaram os custos. Presumem que escalar para o nível empresarial é uma questão de adicionar capacidade e marcar uma caixa de segurança.
Não é.
As perguntas que bloqueiam negócios empresariais não têm nada a ver com desempenho:
Como nossos dados são isolados dos de outros clientes?
Quem tem acesso a quê, e vocês conseguem provar isso?
Vocês conseguem nos atender em nossa região?
Podemos implantar isso dentro da nossa própria conta de nuvem?
Mas os requisitos individuais de cada negociação são apenas parte do problema. No Estágio 3, a heterogeneidade era técnica — diferentes cargas de trabalho, diferentes camadas de computação. Neste estágio, ela é estrutural: sua base de clientes exige uma infraestrutura de dados em nível de plataforma para lidar com isso.
Você tem usuários gratuitos que precisam de atendimento compartilhado e eficiente em custos. Você tem clientes individuais pagos que esperam melhor disponibilidade. Você tem clientes empresariais que exigem isolamento total de dados, computação dedicada e a capacidade de auditar tudo. Atender todos os três a partir da mesma arquitetura significa que você está gastando demais no seu nível gratuito, atendendo mal seus clientes empresariais, ou ambos.
A resposta certa é uma infraestrutura em camadas alinhada a cada segmento de clientes:
- Clusters compartilhados para usuários gratuitos e individuais — agrupados, otimizados para custo
- Clusters isolados por cliente empresarial — computação dedicada, armazenamento dedicado, controles de acesso dedicados
- BYOC para clientes que exigem implantação dentro da própria conta de nuvem

O ponto do BYOC é onde a maioria das equipes comete um erro crítico. SaaS e BYOC parecem dois produtos. Se eles se bifurcam no nível da arquitetura, você passa a manter duas bases de código, dois pipelines de implantação e dois runbooks operacionais — indefinidamente. As equipes que acertaram trataram BYOC como um modelo de implantação, e não como um produto separado. Mesmo plano de dados, mesma interface de controle, alvo de implantação diferente.
A confiabilidade global é a outra parte que é adiada por tempo demais. Em escala empresarial, multi-regiões não são um recurso premium — são uma expectativa básica. Clientes empresariais em diferentes geografias não tolerarão uma implantação em uma única região, nem aceitarão seus compromissos de SLA. Sem uma interface unificada de infraestrutura de dados entre nuvens e regiões, você acaba operando diferentes camadas de dados em diferentes ambientes — a sincronização de dados em tempo real se torna seu próprio problema de sistemas distribuídos, e a complexidade operacional se multiplica a cada nova região que você adiciona.
As equipes com quem conversei que haviam chegado a negociações empresariais sérias descreveram a mesma descoberta dolorosa: nada disso havia sido projetado desde o início. Foi acrescentado depois, sob pressão de um ciclo de vendas em andamento. Uma equipe passou quatro meses adaptando isolamento em nível de dados a uma arquitetura que não havia sido construída para isso. Eles entregaram. Mas sabiam exatamente por que aquilo era frágil.
Prontidão empresarial não é uma checklist. É uma consequência de decisões arquiteturais tomadas muito antes.
O que você realmente precisa neste estágio:
- Uma interface unificada de infraestrutura de dados — consistente entre nuvens, consistente entre regiões
- Clusters globais projetados para alta confiabilidade e atendimento multi-região
- Atendimento em camadas: clusters compartilhados para usuários gratuitos, clusters isolados por cliente empresarial
- SaaS e BYOC na mesma arquitetura — um plano de dados, diferentes alvos de implantação
- Padrões abertos e código aberto na base — sem aprisionamento a fornecedor em escala empresarial
O Que as Equipes Que Escalaram Bem Têm em Comum
O padrão é consistente.
Cada estágio introduz uma classe de problema completamente diferente. O Estágio 1 é um problema de velocidade. O Estágio 2 é um problema de complexidade. O Estágio 3 é um problema de custo e arquitetura. O Estágio 4 é um problema de confiança e plataforma.

As equipes que navegaram por todos os estágios sem uma reconstrução dolorosa entenderam isso cedo. Elas pararam de perguntar "de qual banco de dados eu preciso agora?" e começaram a perguntar "o que o próximo estágio exigirá — e minha decisão atual fecha essa porta?"
No Estágio 1, um banco de dados vetorial é exatamente a ferramenta certa. Digo isso sem ressalvas.
No Estágio 3 e além, o que se torna necessário é algo diferente em natureza — um Vector Lakebase. Armazenamento sempre ativo em escala total. Computação ajustada a cada carga de trabalho. Uma plataforma que pode atender um usuário gratuito, um cliente pagante e uma conta corporativa a partir da mesma arquitetura, sem bifurcação.
As equipes que chegaram lá mais rápido não eram mais inteligentes nem mais bem financiadas.
Elas apenas entenderam, mais cedo, que a decisão de infraestrutura não era uma escolha temporária.
Era a base sobre a qual todo o restante seria construído.
Zilliz Vector Lakebase está disponível em prévia pública
Lançamos a prévia pública do Zilliz Vector Lakebase — uma grande evolução do Zilliz Cloud, de um banco de dados vetorial gerenciado para uma plataforma unificada de dados semânticos que combina o banco de dados vetorial de produção com uma base de dados compartilhada e nativa de lake.
Principais recursos do Zilliz Vector Lakebase:
- Atendimento em camadas otimizado para diferentes compensações de desempenho-custo em tempo real
- Busca sob demanda para cargas de trabalho em larga escala ou exploratórias sem computação sempre ativa
- Busca em data lake externo — indexe e pesquise diretamente sobre seus dados de lake existentes
- Busca de espectro completo em vetores, texto, JSON e dados geoespaciais com recuperação híbrida e reranking
- Armazenamento unificado nativo de lake construído sobre Vortex, um formato aberto com leituras aleatórias mais rápidas e mais baratas do que Lance ou Parquet
Se sua stack atual divide atendimento e descoberta em sistemas separados, talvez valha a pena dar uma olhada no Vector Lakebase. Experimente no Zilliz Cloud — novos cadastros com e-mail profissional recebem US$ 100 em créditos gratuitos — ou fale conosco sobre seu caso de uso.
Saiba mais sobre Vector Lakebases
- De Banco de Dados Vetorial a Vector Lakebase
- Passamos 8 anos tornando bancos de dados vetoriais mais rápidos. Então paramos.
- Por que criamos o Vector Lakebase: Repensando a arquitetura de dados não estruturados para IA
- Vector Lakebase: Acabe com o silo de dados de IA
- Zilliz Cloud On-Demand Compute: Pague apenas pelo que usar
- A busca vetorial do Notion é excelente. O próximo problema deles é mais difícil.

Continue lendo

Announcing the General Availability of Zilliz Cloud BYOC on Google Cloud Platform
Zilliz Cloud BYOC on GCP offers enterprise vector search with full data sovereignty and seamless integration.

Vector Databases vs. Object-Relational Databases
Use a vector database for AI-powered similarity search; use an object-relational database for complex data modeling with both relational integrity and object-oriented features.

Legal Document Analysis: Harnessing Zilliz Cloud's Semantic Search and RAG for Legal Insights
Enhance legal document analysis with Zilliz Cloud’s Semantic Search and RAG. Improve accuracy, efficiency, and scalability for contracts, case law, and compliance.