




VDBBench adiciona benchmarking consciente de custos para bancos de dados vetoriais
No ano passado, lançamos o VectorDBBench 1.0 para tornar o benchmarking de bancos de dados vetoriais mais próximo das cargas de trabalho de produção. Em vez de testar apenas o QPS de pico em dados de benchmark fixos, o VectorDBBench (também conhecido como VDBBench) permite que as equipes avaliem bancos de dados vetoriais usando padrões de carga de trabalho que refletem mais de perto seus próprios sistemas de produção: ingestão, filtragem, recall, latência, concorrência e conjuntos de dados personalizados.
A versão mais recente do VDBBench adiciona uma nova dimensão: custo.
Equipes de produção raramente escolhem um banco de dados vetorial apenas pelo desempenho. Elas precisam saber quanto custa atingir um QPS-alvo, como o P99 se comporta sob esse modelo de custo, quando os dados inseridos se tornam pesquisáveis, quando estão totalmente indexados, como o tamanho do payload afeta a busca, como o sistema se comporta entre muitos tenants e o que acontece na primeira consulta após ficar ocioso. Essas perguntas agora fazem parte do VDBBench.
Para mostrar como esses novos benchmarks conscientes de custo funcionam na prática, testamos três produtos de banco de dados vetorial gerenciados comumente avaliados: Zilliz Cloud, Turbopuffer e Pinecone. Os resultados são publicados no novo VDBBench Cost Leaderboard, com gráficos e tabelas que comparam prontidão de inserção, busca com payload, busca multitenant, latência a frio e trade-offs de custo-desempenho.
O leaderboard é apenas uma forma de ler os resultados — é um retrato de três produtos em um determinado momento. Como o VDBBench é open source, as equipes também podem reproduzir esses casos, fazer benchmark de produtos que não estão no leaderboard ou adaptar as cargas de trabalho aos seus próprios dados semelhantes aos de produção.
O objetivo não é coroar um vencedor universal, mas ajudar as equipes a escolher o banco de dados vetorial que melhor se ajusta à sua carga de trabalho, metas de desempenho e orçamento.
- Referências: VectorDBBench GitHub | VDBBench Leaderboards
O que há de novo no VDBBench
Esta versão adiciona quatro casos de benchmark orientados à nuvem que medem comportamentos de produção que leaderboards de QPS de pico muitas vezes deixam passar.
| Caso | O que mede | Por que importa |
|---|---|---|
| CloudInsertCase | Conclusão da inserção, estado pesquisável, estado totalmente indexado e custo de escrita | Freshness e custo de backfill importam para RAG, catálogos e memória de agentes |
| CloudPayloadSearchCase | QPS, latência P99, recall e formato do payload de resposta | Retornar vetores ou metadados pode alterar a superfície de custo da busca |
| MultitenantSearchCase | Throughput entre muitos tenants ou namespaces | Cargas de trabalho SaaS estressam o roteamento e o comportamento de partições de forma diferente da busca single-tenant |
| CloudColdLatencyCase | Primeira consulta após ociosidade vs. caminho de consulta aquecido | O comportamento de cold-start importa para tenants de baixa frequência e memória de agentes |
Além desses casos, o Cost Leaderboard adiciona uma visão de custo-Pareto que modela os custos operacionais em níveis de QPS-alvo sob os limites de serviço medidos de cada produto — porque decisões de compra geralmente dependem de onde desempenho e custo se cruzam.
O VDBBench Cost Leaderboard usa esses casos para comparar publicamente produtos gerenciados. Como os casos são distribuídos no VDBBench open-source, as equipes podem reutilizá-los para sua própria avaliação, incluindo produtos e cargas de trabalho não mostrados no leaderboard.
Quem testamos: Zilliz Cloud vs. Turbopuffer vs. Pinecone
Para esta primeira execução consciente de custo, testamos três produtos de banco de dados vetorial gerenciados comumente avaliados. Todos os produtos foram benchmarkados em 10 de maio de 2026, na AWS US West (us-west-2). Seus modelos operacionais diferem, portanto os resultados devem ser interpretados em termos de adequação à carga de trabalho, e não como um ranking único.
| Produto | Papel neste benchmark |
|---|---|
| Zilliz Cloud | Banco de dados vetorial em nuvem gerenciado e lakebase vetorial dos criadores do Milvus, testado em suas configurações Tiered e Capacity |
| Turbopuffer | Banco de dados vetorial serverless testado em modos unpinned e pinned |
| Pinecone Serverless | Banco de dados vetorial serverless maduro e de baixa operação usado como ponto de referência comum de produção |
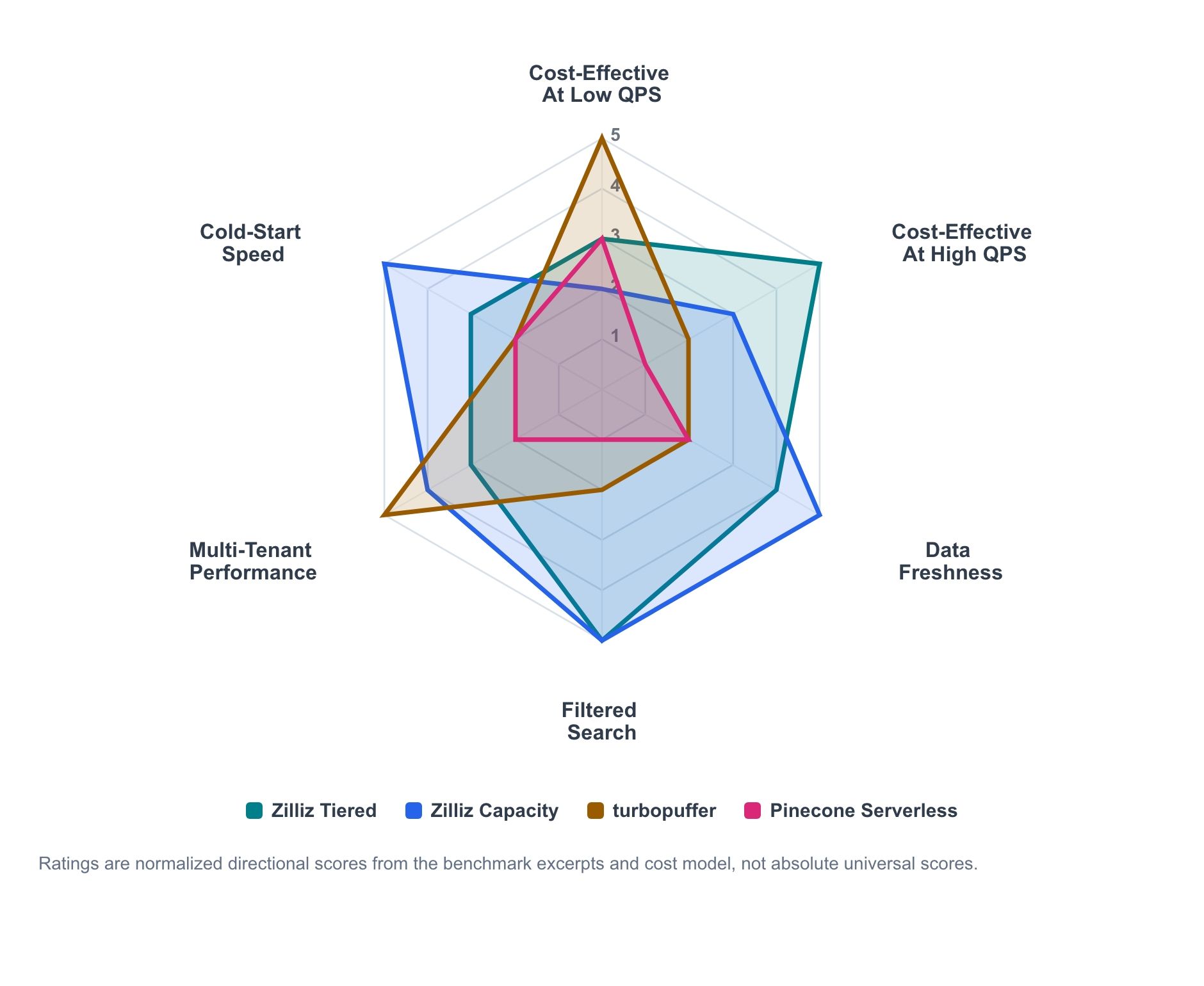
Figura 1. Resumo direcional de adequação à carga de trabalho com base em trechos do benchmark e modelagem de custos. As pontuações são normalizadas para comparação entre dimensões de carga de trabalho e não devem ser lidas como classificações absolutas universais.
O gráfico de radar resume o sinal direcional dos trechos do benchmark e do modelo de custos. Ele não é um placar absoluto; é um mapa de onde cada produto tende a ser mais forte.
- Zilliz Cloud Tiered é a linha econômica de serviço ativo que escala conforme a utilização aumenta.
- Zilliz Cloud Capacity é o perfil de maior controle para serviço previsível, frescor e comportamento a frio.
- Turbopuffer é mais forte onde a economia serverless medida por uso e a vazão orientada a namespaces correspondem à carga de trabalho.
- Pinecone continua sendo uma linha de base serverless útil e de baixa operação, mesmo quando não está na fronteira de custo-desempenho em um teste específico.
O padrão principal é claro. A economia serverless pode ser atraente em QPS sustentado baixo. A capacidade provisionada se torna mais competitiva conforme a utilização aumenta. Frescor, busca filtrada, tamanho do payload, contagem de tenants e comportamento a frio podem todos influenciar a decisão.
Conjuntos de dados e cargas de trabalho
Os casos com consciência de custo usam dois formatos de carga de trabalho.
- LAION 100M de tenant único: 100 milhões de vetores densos de 768 dimensões. Isso representa uma grande coleção de produção em que tamanho do payload, filtros, recall e QPS sustentado importam.
- Cohere 10M multitenant: 10 milhões de vetores densos de 768 dimensões, divididos aleatoriamente entre 1.000 tenants — aproximadamente 10K vetores por tenant. Isso representa cargas de trabalho no estilo SaaS, nas quais cada tenant tem um conjunto de dados menor, mas o sistema precisa rotear e atender eficientemente muitos namespaces ou partições de tenants.
Os trechos abaixo mostram o formato das descobertas. O Cost Leaderboard e o repositório VectorDBBench continuam sendo a fonte para as matrizes completas, definições de clientes e detalhes de reprodução.
CloudInsertCase: Inserido nem sempre está pronto
O desempenho de inserção não é um único número. Um banco de dados vetorial gerenciado pode aceitar dados do cliente antes que esses dados estejam seguros para busca pelo caminho de índice pretendido. Para cargas de trabalho de produção, as equipes precisam saber quando a operação de inserção está concluída, quando os dados se tornam pesquisáveis e quando a indexação em segundo plano está totalmente atualizada.
CloudInsertCase mede o ciclo de vida de gravação para serviço. Isso importa para atualizações de corpus de RAG, atualizações de catálogos de produtos, gravações de memória de agentes e backfills de dados. Nesses sistemas, "inserção aceita" não é suficiente. A pergunta operacional é quando os dados recém-gravados podem ser pesquisados de forma confiável com desempenho de produção.
| Produto / modo | Tamanho do lote | Tempo de inserção | Espera até pesquisável | Espera até totalmente indexado | Custo de gravação |
|---|---|---|---|---|---|
| Zilliz Cloud Capacity 12CU | 10,000 | 3.2 h | 0 ms | 1.9 min | $9.50 |
| Zilliz Cloud Tiered 4CU | 10,000 | 4.1 h | 0 ms | 10.9 min | $6.34 |
| Turbopuffer (backpressure desativado) | 10,000 | 1.8 h | 6.4 h | 2.0 min | $302 |
| Pinecone Serverless | 10,000 | 72.4 h | 0 ms | 127 ms | $1,180 |
Tabela 1. Trecho de inserção em lote de 10k do LAION 100M. Custos e tempos são da execução atual do leaderboard. Para as configurações provisionadas da Zilliz, o custo de gravação é o custo em CU-hora consumido durante a janela de carregamento e indexação; para Turbopuffer e Pinecone, é a cobrança de gravação medida. Leia os tempos com as definições do cliente para os estados inserido, pesquisável e totalmente indexado (definidos por cliente no código-fonte do VDBBench).
Mudanças no tamanho do lote alteram os números para diferentes produtos.
- O Turbopuffer mostra forte ingestão bruta em lotes grandes, especialmente com backpressure desativado — seu modo de ingestão mais agressivo. No caminho batch-10k, ele conclui a inserção rapidamente, mas a espera pela capacidade de busca domina a janela completa de prontidão.
- O Zilliz Cloud é mais estável entre tamanhos de lote. Nas configurações Capacity e Tiered testadas, os dados se tornam pesquisáveis imediatamente após a conclusão da inserção, e a espera restante até estarem totalmente indexados é medida em minutos.
- O Pinecone Serverless é a linha de base de ingestão em massa mais lenta neste teste. Depois que os dados são aceitos, a espera adicional para ficarem pesquisáveis e totalmente indexados é efetivamente zero nessas execuções, mas a etapa de inserção em si leva muito mais tempo.
A leitura do produto é moldada pela carga de trabalho.
- O Zilliz se encaixa em fluxos de trabalho nos quais dados recentes precisam se tornar rapidamente pesquisáveis e indexados a um custo previsível.
- O Turbopuffer se encaixa em grandes backfills aceitos quando a carga de trabalho pode tolerar uma janela de prontidão mais longa.
- O Pinecone se encaixa em padrões de ingestão serverless de menor volume, nos quais a simplicidade operacional importa mais do que a velocidade ou o custo de carga em massa.
O carregamento em massa também é um evento de custo. Neste caso de inserção LAION 100M, as configurações do Zilliz mantêm o custo do lado da escrita na faixa de um dígito em dólares para o caminho batch-10k testado. O Turbopuffer é modelado em torno de $302. O Pinecone Serverless é modelado em torno de $1,180. Isso não torna um modelo de preços universalmente melhor. Significa que a economia da inserção depende da frequência com que a carga de trabalho executa esse caminho.
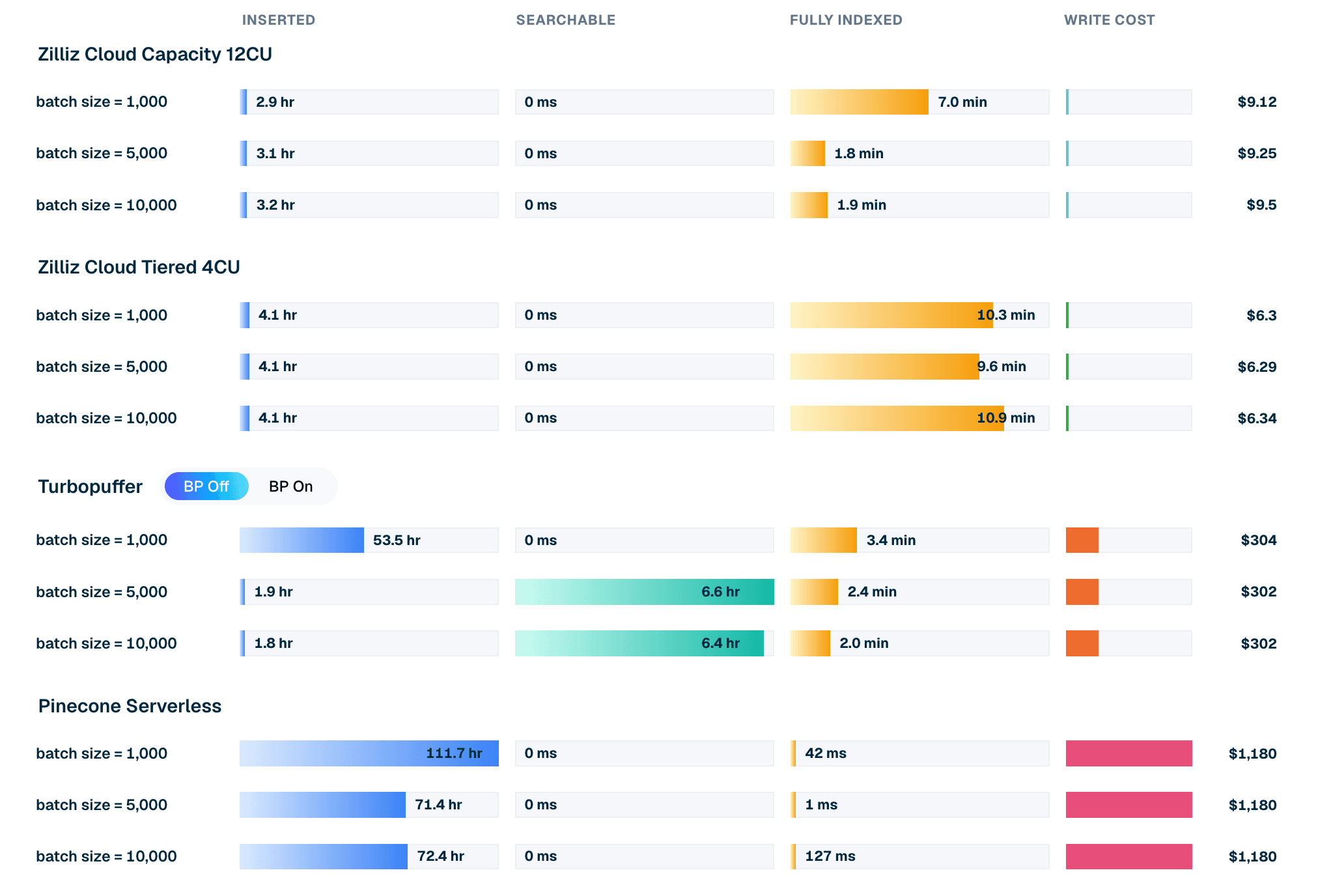
Figura 2. Ciclo de vida de inserção para LAION 100M com lote 10k: tempo de inserção, espera até ficar pesquisável, espera até ficar totalmente indexado e custo de escrita modelado por produto.
CloudPayloadSearchCase: O payload altera a superfície de busca
Depois que os dados estão pesquisáveis, a próxima pergunta não é apenas quantas consultas por segundo o banco de dados consegue processar. O formato da resposta importa. Retornar apenas IDs é muito diferente de retornar metadados ou vetores brutos. Um vetor de 768 dimensões pode adicionar milhares de bytes a cada resultado. Em topK=100, o tamanho do payload pode se tornar um fator importante no custo e na latência da consulta.
O CloudPayloadSearchCase testa LAION 100M de tenant único sob diferentes payloads de resposta e formatos de filtro. A leitura combina QPS concorrente máximo, latência P99 nessa concorrência, tipo de payload e recall, quando disponível.
Uma observação sobre a leitura das tabelas: P99 aqui é medido na concorrência máxima — o ponto de saturação que produz o pico de QPS de cada produto — não em um ponto operacional confortável de nível de serviço. Ele mostra como uma configuração se comporta em seu limite medido.
| Produto | Latência P99 @ concorrência máxima | QPS máximo | recall@10 |
|---|---|---|---|
| Zilliz Cloud Capacity 32CU | 158 ms | 786.1 | 0.9728 |
| turbopuffer | 2.34 s | 395.7 | 0.9321 |
| Zilliz Cloud Capacity 12CU | 299 ms | 376.0 | 0.9723 |
| Turbopuffer pinned | 3.30 s | 68.2 | 0.9321 |
| Zilliz Cloud Tiered 4CU | 5.57 s | 49.2 | 0.9510 |
| Pinecone Serverless | 4.85 s | 4.6 | 0.9609 |
Tabela 2. LAION 100M de tenant único, sem filtro, apenas IDs, topK 100. Observação sobre o Pinecone: sua vazão neste caso de tenant único é limitada por throttling de unidades de leitura no lado do servidor, então a execução chega ao máximo com concorrência 4–5, em comparação com 80 para os outros produtos. Leia suas linhas como uma linha de base serverless cadenciada, e não como um resultado de saturação.
A configuração importa. Em 12CU, o Zilliz Capacity e o Turbopuffer ficam próximos em QPS bruto neste caso amplo de apenas IDs, enquanto o Zilliz está à frente em recall e latência P99. Em 32CU, o Zilliz Capacity excede o resultado testado do Turbopuffer para esta carga de trabalho de tenant único.
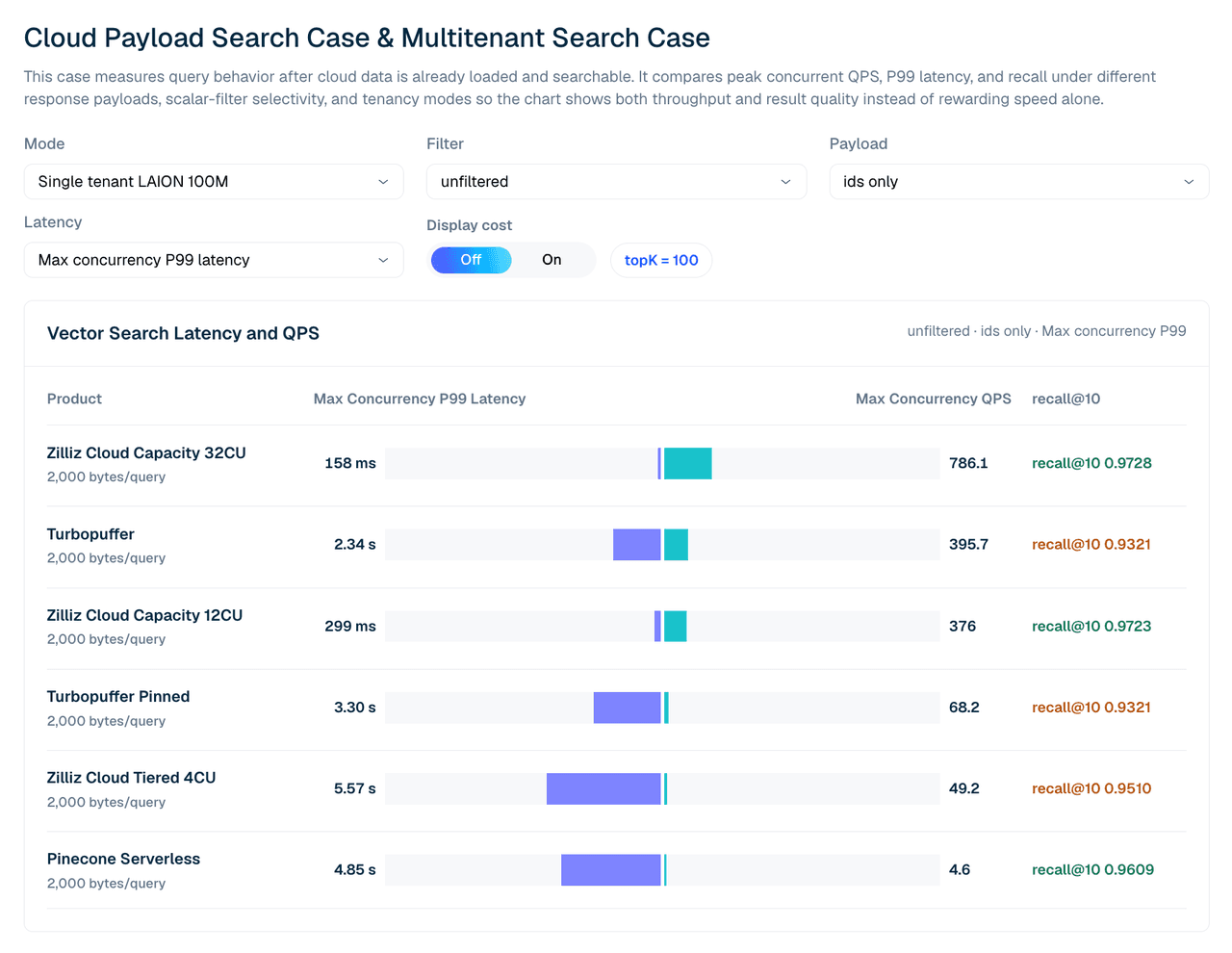
Figura 3. Busca em LAION 100M de tenant único com respostas apenas de IDs. Esta visualização compara QPS concorrente máximo, latência P99 e recall@10 entre as configurações gerenciadas testadas.
A questão não é apenas qual produto é mais rápido em uma configuração. É como o desempenho muda quando uma equipe compra mais capacidade, altera o formato do payload ou precisa de uma meta de recall. Quando a consulta retorna payloads vetoriais brutos, a vazão pode mudar de forma significativa.
| Produto | QPS somente IDs | QPS com payload vetorial | Recall |
|---|---|---|---|
| Zilliz Cloud Tiered 4CU | 49.2 | 44.0 | 0.9510 |
| Zilliz Cloud Capacity 12CU | 376.0 | 229.4 | 0.9723 |
| Zilliz Cloud Capacity 32CU | 786.1 | 531.4 | 0.9728 |
| turbopuffer | 395.7 | 382.2 | 0.9321 |
| Pinecone Serverless | 4.6 | 4.5 | 0.9609 |
Tabela 3. Trecho de payload para recuperação ampla sem filtros. As equipes devem avaliar com benchmark o formato de payload que sua aplicação realmente retorna, não apenas a busca somente com IDs.
Busca Filtrada: Onde a Seletividade Importa
Muitas cargas de trabalho de busca vetorial em produção são permissionadas ou filtradas. Um copiloto de suporte pode buscar apenas documentos que o usuário tem permissão para ver. Um sistema de recomendação pode filtrar por região, categoria, vendedor ou disponibilidade. Um aplicativo de busca corporativa pode aplicar restrições de tenant, controle de acesso, atualização e tipo de documento antes de ranquear os resultados.
Esses filtros não são cosméticos. Eles mudam o caminho de execução. No ponto de estresse com filtro inteiro de 99.9% mais payload vetorial, o comportamento do produto muda drasticamente.
| Produto | QPS máximo | Recall | Latência P99 |
|---|---|---|---|
| Zilliz Cloud Tiered 4CU | 955.7 | 0.9423 | 0.16 s |
| Zilliz Cloud Capacity 12CU | 933.0 | 0.9781 | 0.12 s |
| turbopuffer | 45.1 | 0.9436 | 7.03 s |
| Pinecone Serverless | 4.8 | —* | 3.30 s |
Tabela 4. Ponto de estresse de filtro seletivo de tenant único: filtro inteiro de 99.9% com payload vetorial. O recall da execução do Pinecone Serverless nesse ponto de estresse ainda não estava disponível no momento da publicação; seu QPS e sua latência vêm da execução medida.
Este é um dos exemplos mais claros de por que a avaliação com consciência de custo precisa de múltiplos formatos de carga de trabalho. Um produto que tem bom desempenho em recuperação ampla sem filtros pode não ser a melhor opção para busca filtrada seletiva. Para busca permissionada, RAG com controle de acesso intenso ou cargas de trabalho com alta seletividade de filtro, as linhas filtradas podem importar mais do que as linhas não filtradas.
MultitenantSearchCase: Muitos Pequenos Tenants se Comportam de Forma Diferente
Benchmarks de tenant único não capturam todas as cargas de trabalho em nuvem.
Muitas aplicações de IA têm formato SaaS. Um produto pode atender milhares de tenants, cada um com um conjunto de dados menor. O desafio operacional não é apenas a busca vetorial dentro de uma única coleção grande. É roteamento, isolamento, gerenciamento de namespaces e manutenção de vazão em muitas pequenas partições.
O caso multitenant usa o conjunto de dados Cohere 10M dividido entre 1,000 tenants. O formato da consulta usa topK 50 e compara linhas somente com IDs, payload vetorial e filtradas.
Duas observações de configuração moldam como ler esta tabela.
Primeiro, as configurações da Zilliz aqui são intencionalmente pequenas — Tiered 1CU e Capacity 2CU, apenas o suficiente para conter o conjunto de dados Cohere 10M. O caso de tenant único acima já mostra que o QPS da Zilliz escala com a contagem de CUs; a pergunta que este caso faz é sobre custo-benefício em uma configuração dimensionada para os dados, não sobre vazão de pico.
Segundo, a coluna da Pinecone é uma execução destacada de baixa concorrência (concorrência 4), não normalizada em relação às linhas de maior concorrência, portanto trate-a como contexto em vez de uma comparação direta.
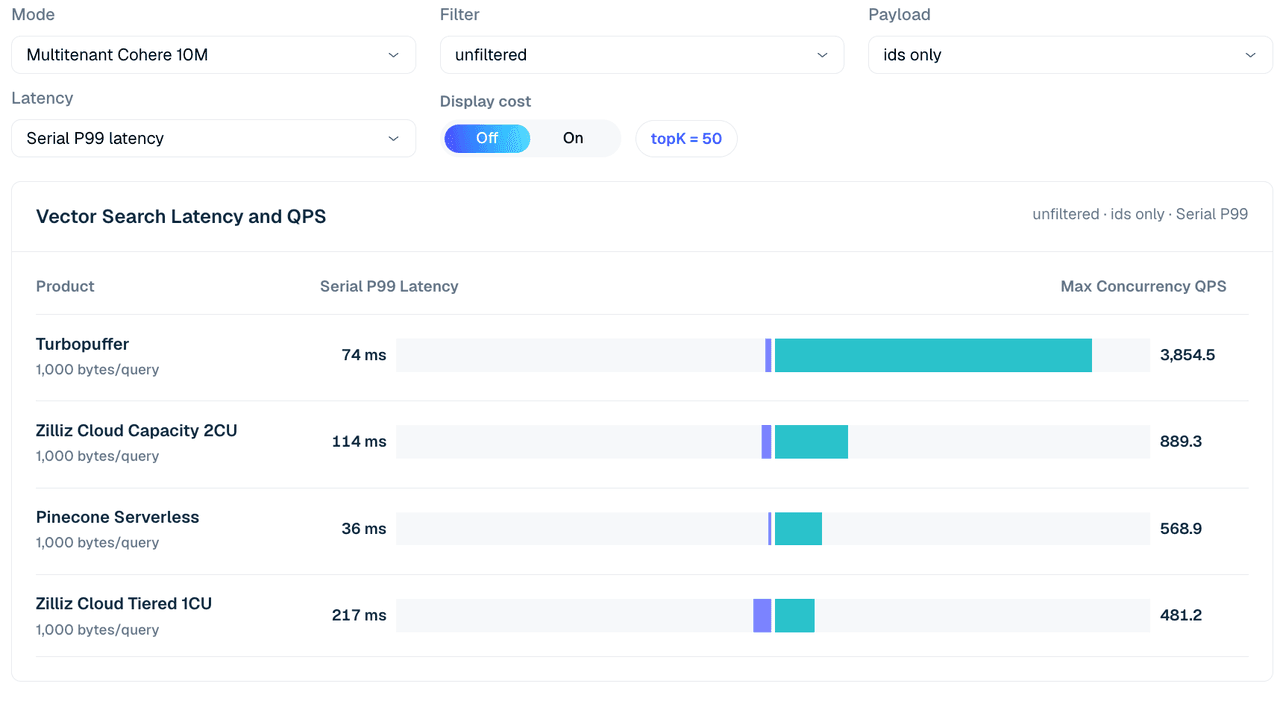
Figura 4. Busca multitenant Cohere 10M em 1,000 tenants, sem filtros, somente IDs, topK 50. A visualização compara a latência P99 serial e o QPS concorrente máximo entre as configurações testadas; a tabela abaixo adiciona variações de payload e filtro.
| Caso | Zilliz Tiered 1CU | Zilliz Capacity 2CU | turbopuffer | Pinecone (c4 run) |
|---|---|---|---|---|
| Sem filtro, apenas IDs | 481 | 889 | 3,855 | 569 |
| Sem filtro, vetor | 34 | 371 | 1,775 | 542 |
| Filtro de inteiro 99,9%, vetor | 625 | 1,307 | 3,835 | 526 |
| Rótulo escalar 1%, vetor | 152 | 588 | 1,767 | 600 |
| Rótulo escalar 50%, vetor | 29 | 317 | 1,760 | 562 |
Tabela 5. Trecho de busca multitenant em 1.000 tenants, topK 50.
Nesse modo, o Turbopuffer é forte em todos os aspectos. Ele atinge 3,855 QPS em uma busca sem filtro apenas por IDs e 3,835 QPS na linha seletiva de filtro de inteiro/vetor. O Zilliz Cloud Capacity 2CU continua sendo o perfil Zilliz mais forte neste trecho, atingindo 889 QPS sem filtro apenas por IDs e 1,307 QPS na linha de filtro de inteiro 99,9%/vetor.
A leitura do produto é novamente moldada pela carga de trabalho. O Turbopuffer é uma boa opção para muitos tenants leves e throughput orientado a namespaces. O Zilliz é mais forte quando as cargas de trabalho são filtradas, permissionadas, sensíveis a recall ou mais pesadas por tenant, especialmente quando as equipes podem escolher uma configuração Zilliz Capacity que corresponda ao objetivo de serving.
CloudColdLatencyCase: A primeira consulta após inatividade
Loops de benchmark aquecidos podem ocultar o comportamento frio. Para muitas aplicações de IA em produção, especialmente memória de agentes, RAG de cauda longa e cargas de trabalho de tenants de baixa frequência, a primeira consulta após inatividade importa. Um sistema pode parecer rápido após o aquecimento, mas adiciona segundos de latência quando uma collection, namespace ou caminho de cache frio é acessado novamente.
CloudColdLatencyCase isola esse comportamento. Ele mede a primeira consulta contra uma collection que ficou inativa por pelo menos 24 horas — tempo suficiente para que caches e caminhos de serving fiquem tão frios quanto realisticamente possível — e a compara com a primeira consulta no caminho aquecido da mesma execução.
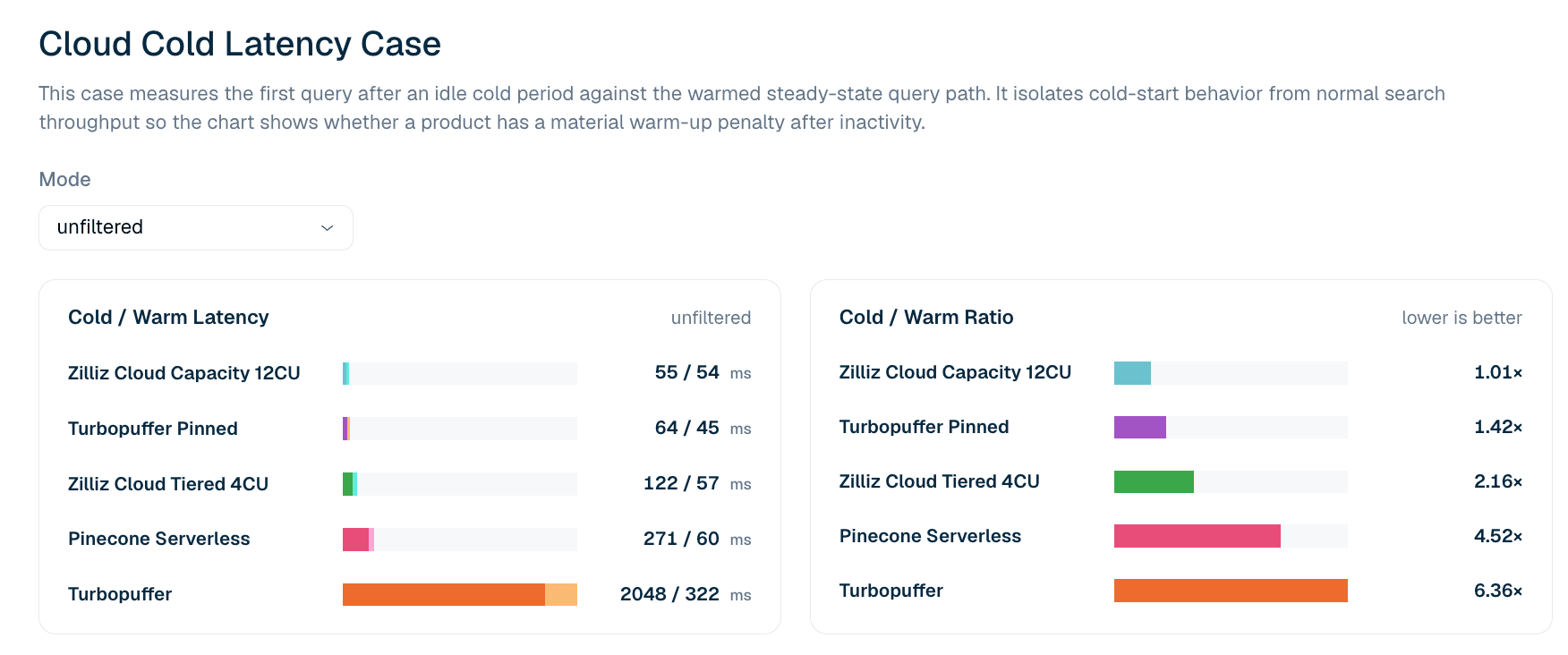
Figura 5. Latência da primeira consulta após inatividade vs. o caminho de consulta aquecido para busca LAION 100M sem filtro. A razão frio/quente destaca se um produto tem uma penalidade material na primeira consulta após inatividade.
| Produto | Primeira consulta após inatividade | Primeira consulta quente | Razão frio/quente |
|---|---|---|---|
| Zilliz Cloud Capacity 12CU | 55 ms | 54 ms | 1.01x |
| Turbopuffer pinned | 64 ms | 45 ms | 1.42x |
| Zilliz Cloud Tiered 4CU | 122 ms | 57 ms | 2.16x |
| Pinecone Serverless | 271 ms | 60 ms | 4.52x |
| turbopuffer | 2,048 ms | 322 ms | 6.36x |
Tabela 6. Trecho de latência da primeira consulta fria e quente para LAION 100M sem filtro. O caso relata a latência da primeira consulta em vez de percentis de cauda: razões frio/quente no P99 tendem a capturar ruído de rede em consultas posteriores que não se reproduz de forma confiável, portanto o leaderboard usa a definição mais rigorosa de primeira consulta.
No caso atual de latência fria sem filtro, o Zilliz Cloud Capacity 12CU mostra o perfil frio-quente mais estreito: 55 ms frio e 54 ms quente, ou uma razão de 1.01x. O Turbopuffer pinned também tem um perfil forte, com 64 ms frio e 45 ms quente. O Turbopuffer não fixado mostra uma penalidade fria maior: 2,048 ms frio e 322 ms quente, ou uma razão de 6.36x.
A latência fria deve sempre ser lida junto com o custo. Réplicas fixadas e capacidade provisionada podem reduzir penalidades de primeiro toque, mas alteram o modelo econômico. Um produto pode exibir excelente comportamento frio porque retém mais calor. Esse pode ser o tradeoff certo para aplicações interativas, mas não deve ser separado do custo de manter esse caminho.
Linhas de Pareto de custo: onde os modelos de precificação se cruzam
Uma tabela de preços não é suficiente. Um preço unitário baixo não ajuda se o produto não consegue atingir o QPS-alvo. Uma configuração de alto throughput não é atraente se custa mais do que outro produto que satisfaz os mesmos requisitos de latência, recall e payload.
A visualização de Pareto de Custo combina limites de benchmark medidos com modelos de precificação. Para a configuração somente consulta do LAION 100M, cada linha de produto para no QPS máximo observado no benchmark. O gráfico então estima o custo operacional em níveis-alvo de QPS e marca as escolhas Pareto-ótimas sob essas restrições medidas.
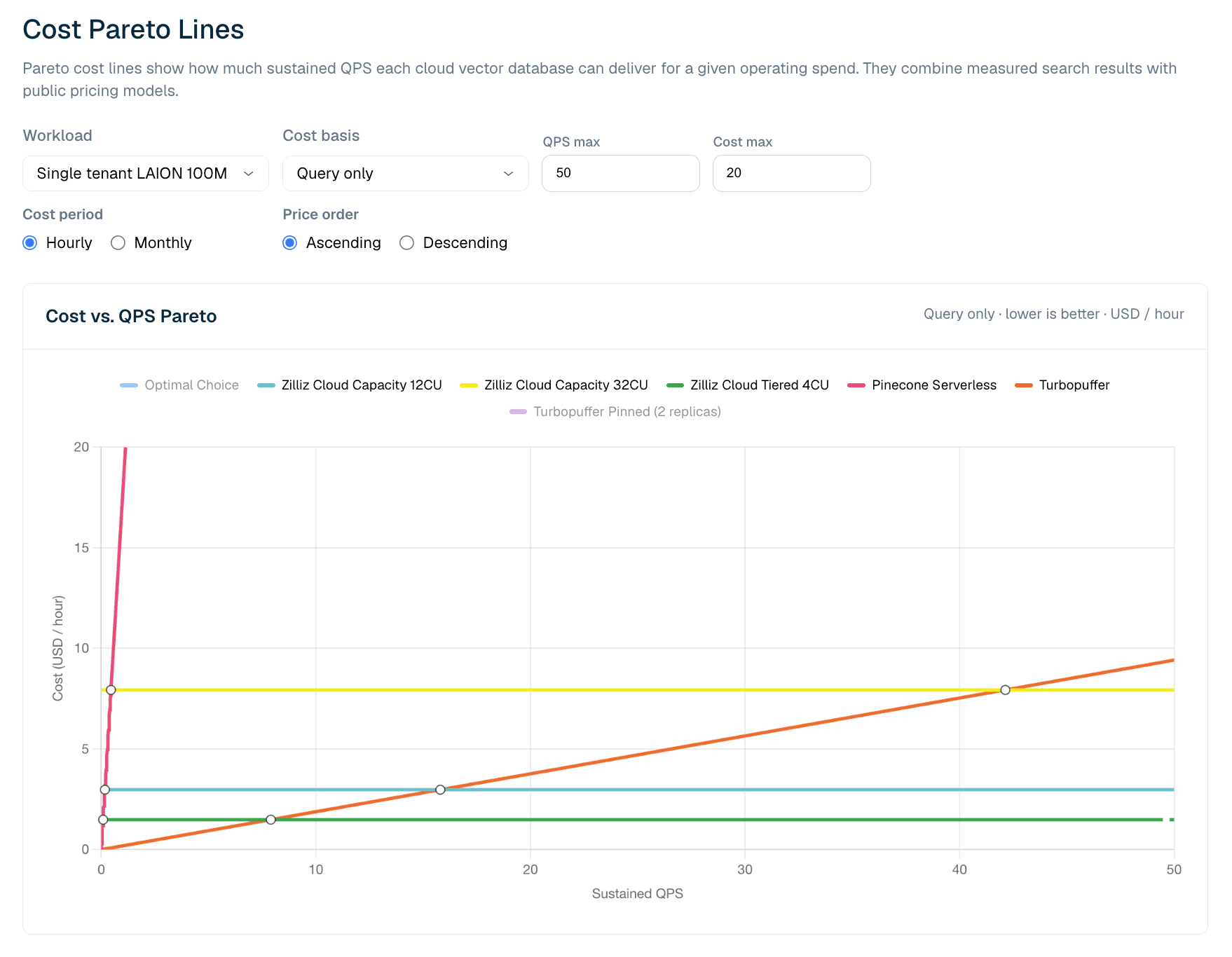
Figura 6. Custo vs. QPS sustentado para cargas de trabalho somente consulta do LAION 100M. A visualização de Pareto mostra onde a precificação serverless é mais eficiente em baixo QPS e onde as configurações provisionadas da Zilliz se tornam mais econômicas à medida que a utilização aumenta.
No modelo atual somente consulta do LAION 100M, a Turbopuffer tem vantagem em QPS sustentado muito baixo. O ponto de cruzamento medido fica em aproximadamente 8 QPS: abaixo dele, a precificação de consultas medida por uso da turbopuffer é a linha mais barata; acima dele, o Zilliz Cloud Tiered 4CU se torna mais barato, porque seu custo de atendimento por CU-hora é em grande parte fixo uma vez provisionado. À medida que o QPS aumenta, a utilização melhora e a capacidade provisionada se torna mais econômica.
Isso não significa que serverless seja pior. Significa que as economias de serverless e provisionado se cruzam. Para cargas de trabalho baixas, com picos ou imprevisíveis, serverless medido por uso pode ser a melhor opção. Para tráfego de produção sustentado, um modelo fixo de CU-hora pode se tornar mais barato quando a utilização passa do ponto de cruzamento. Para equipes que precisam de envelopes de atendimento mais robustos, comportamento a frio ou controle operacional, Zilliz Capacity pode ser o perfil certo mesmo quando Tiered é a linha de menor custo.
Zilliz Cloud vs. Turbopuffer vs. Pinecone: Melhor adequação por carga de trabalho
| Formato da carga de trabalho | Sinal mais forte | Por quê |
|---|---|---|
| QPS sustentado muito baixo | turbopuffer | A economia serverless medida por uso é atraente antes do cruzamento de baixo QPS |
| QPS sustentado acima do cruzamento (~8 QPS neste modelo) | Zilliz Cloud Tiered | A economia fixa de CU-hora melhora à medida que a utilização aumenta |
| Dados recentes ou atualização frequente | Zilliz Cloud Capacity / Tiered | Inserção até busca e prontidão totalmente indexada são fortes no caso de inserção do LAION 100M |
| Sensibilidade ao custo de carregamento completo grande | Zilliz Cloud Capacity / Tiered | O custo do lado de gravação é muito menor no caminho de carregamento em massa do LAION 100M testado |
| Busca ampla de payload sem filtro | Turbopuffer e Zilliz Capacity 32CU | Turbopuffer é forte em recuperação ampla; Zilliz escala com mais capacidade |
| Filtros seletivos ou busca com permissões | Zilliz Cloud Capacity / Tiered | Zilliz mostra QPS muito mais alto e menor latência P99 no ponto de estresse de filtro de 99,9% |
| Muitos tenants leves | turbopuffer | Maior QPS bruto no trecho de 1.000 tenants |
| Aplicativos interativos sensíveis a cold start | Zilliz Cloud Capacity; Turbopuffer pinned | Ambos reduzem penalidades da primeira consulta, com modelos de custo diferentes |
| Linha de base serverless de baixa operação | Pinecone Serverless | Ponto de referência serverless maduro, mesmo quando não é a fronteira nesta carga de trabalho |
Como usar estes resultados de benchmarking
O VDBBench e seu Cost Leaderboard foram projetados para fazer com que a avaliação de bancos de dados vetoriais reflita mais de perto como as equipes realmente compram e operam produtos de nuvem gerenciados. O QPS de pico ainda importa, mas já não é suficiente por si só. A pergunta mais útil é se um produto consegue atender simultaneamente aos requisitos da carga de trabalho para latência, recall, frescor, payload, tenancy e custo.
Um fluxo de avaliação prático é assim:
- Use o Performance Leaderboard para entender a capacidade bruta de atendimento sob condições controladas de benchmark.
- Use o Cost Leaderboard para entender as compensações de custo-desempenho entre produtos de nuvem gerenciados e formatos de carga de trabalho.
- Use o próprio VDBBench para reproduzir os casos, testar outros produtos ou executar o benchmark contra dados e distribuições de consulta semelhantes aos de produção.
Os resultados atuais devem ser lidos com várias ressalvas.
- Os produtos foram avaliados em 10 de maio de 2026, e o modelo de custo usa os preços da AWS us-west-2 nessa data. Os preços podem mudar conforme a data e a região.
- Escolhas de configuração, como modos fixados, capacidade provisionada, controles de escalabilidade e limitação serverless, podem afetar os resultados.
- Os estados de prontidão nem sempre são expostos da mesma forma, portanto as definições de inserido, pesquisável e totalmente indexado precisam ser verificadas para cada cliente.
- Por fim, as cargas de trabalho são específicas por design. Os resultados de Pareto de custo devem sempre ser lidos em conjunto com latência, recall, formato do payload e limites de serving medidos.
Faça Benchmark das Suas Próprias Cargas de Trabalho
O Cost Leaderboard é um snapshot público dos resultados atuais, mas a mudança mais importante está no próprio VDBBench. Agora ele permite que as equipes avaliem desempenho e custo em conjunto em relação a restrições específicas da carga de trabalho: frescor, tamanho do payload, formato do tenant, comportamento a frio e modelo operacional.
Um produto serverless pode ser uma boa opção para QPS sustentado baixo. A capacidade provisionada pode se tornar mais econômica quando a utilização aumenta. Um sistema pode liderar em recuperação ampla, enquanto outro pode ter desempenho melhor sob filtros seletivos, atualizações frequentes ou cargas de trabalho sensíveis a cold-start.
O objetivo não é o melhor número de destaque. É o melhor ajuste para a sua carga de trabalho.
- Veja os resultados atuais: VDBBench Cost Leaderboard
- Reproduza esses casos ou faça benchmark dos seus próprios candidatos: VectorDBBench on GitHub
- Perguntas ou resultados para compartilhar? Abra uma issue no GitHub ou participe da conversa no Discord

Continue lendo

AI Agents Are Quietly Transforming E-Commerce — Here’s How
Discover how AI agents transform e-commerce with autonomous decision-making, enhanced product discovery, and vector search capabilities for today's retailers.

How to Build RAG with Milvus, QwQ-32B and Ollama
Hands-on tutorial on how to create a streamlined, powerful RAG pipeline that balances efficiency, accuracy, and scalability using the QwQ-32B and Milvus.

Legal Document Analysis: Harnessing Zilliz Cloud's Semantic Search and RAG for Legal Insights
Enhance legal document analysis with Zilliz Cloud’s Semantic Search and RAG. Improve accuracy, efficiency, and scalability for contracts, case law, and compliance.