




As 10 principais técnicas de Engenharia de Contexto que você deve conhecer para RAG em produção
Quando construímos pela primeira vez uma demonstração de RAG ou de agente, as coisas geralmente funcionam bem. Com um pequeno conjunto de dados, alguns prompts e recuperação simples, muitas vezes conseguimos colocar um protótipo em funcionamento em poucas horas.
O verdadeiro desafio aparece quando tentamos executar o sistema em produção. À medida que o uso cresce, os problemas aparecem rapidamente. A recuperação fica mais lenta, as respostas se tornam menos confiáveis, a latência aumenta e os custos sobem. O que funcionava em uma pequena demonstração muitas vezes quebra quando dados reais, usuários reais e contextos mais longos estão envolvidos.
Nesse ponto, geralmente percebemos que o problema não é apenas o modelo. Também se trata de como o contexto é preparado e passado ao modelo. É aqui que entra a engenharia de contexto. Ela se concentra em recuperar, organizar, refinar e gerenciar as informações que um modelo de linguagem usa para gerar respostas.
Neste artigo, explicamos como a engenharia de contexto funciona na prática. Analisamos abordagens recentes para construir contexto, processá-lo de forma eficiente e gerenciá-lo ao longo do tempo. Essas técnicas ajudam a transformar demonstrações simples em sistemas que podem ser executados de forma confiável em produção.
Observação: Este artigo é baseado principalmente no artigo https://arxiv.org/html/2507.13334v1.
O que é Engenharia de Contexto?
A engenharia de contexto se concentra em reunir as informações de que um grande modelo de linguagem precisa para responder bem a uma pergunta. Essas informações não se limitam ao prompt. Elas também incluem a consulta do usuário, documentos recuperados, histórico da conversa e outros dados relevantes. O objetivo é melhorar a precisão, reduzir o tempo de resposta e controlar os custos.
Esse trabalho é feito, em grande parte, automaticamente por meio de algoritmos. A engenharia de contexto combina engenharia de prompts, geração aumentada por recuperação (RAG) e técnicas multiagente em um único sistema, em vez de usá-las separadamente.
Na prática, uma configuração de engenharia de contexto tem duas partes. A primeira consiste em componentes fundamentais que lidam com recuperação, processamento e orquestração de dados. A segunda camada é composta por sistemas complexos que combinam esses componentes em aplicações completas. As equipes podem combinar e reutilizar essas partes para atender a diferentes cenários de produção.
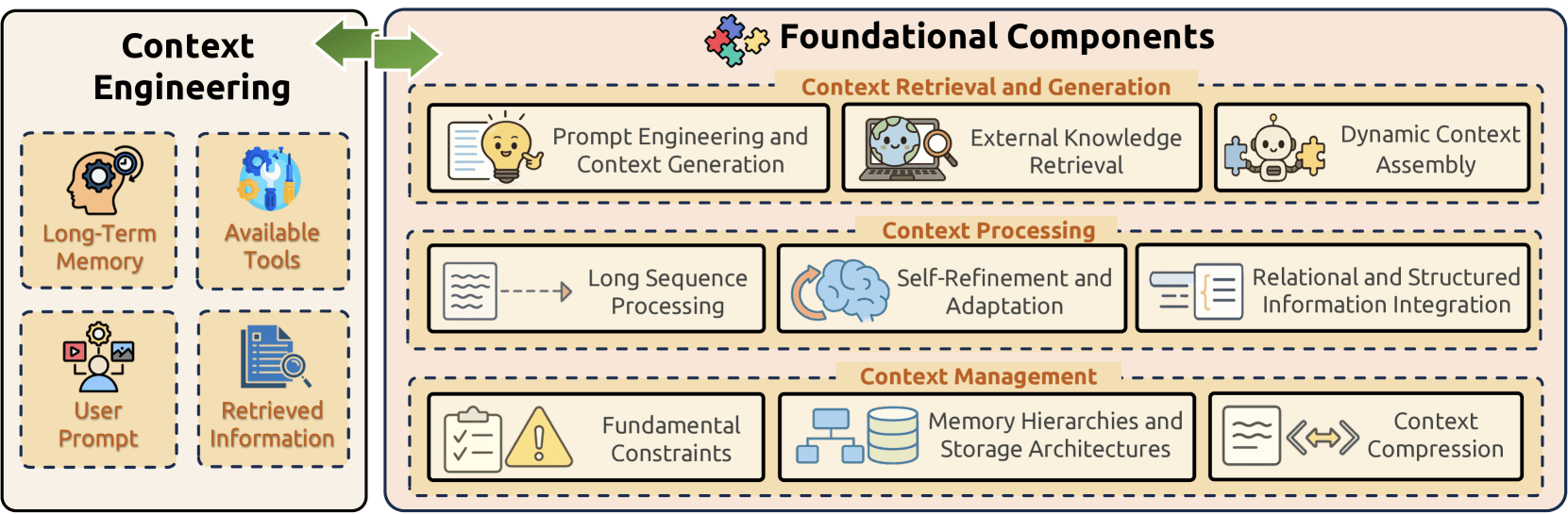
Componentes Fundamentais
A Engenharia de Contexto é construída sobre três componentes fundamentais que, em conjunto, abordam os principais desafios do gerenciamento de informações em grandes modelos de linguagem:
- Recuperação e Geração de Contexto obtém informações contextuais apropriadas por meio de engenharia de prompts, recuperação de conhecimento externo e montagem dinâmica de contexto;
- Processamento de Contexto transforma e otimiza as informações adquiridas por meio de processamento de sequências longas, mecanismos de autorrefinamento e integração de dados estruturados;
- Gerenciamento de Contexto enfrenta a organização e a utilização eficientes das informações contextuais ao abordar restrições fundamentais, implementar hierarquias de memória sofisticadas e desenvolver técnicas de compressão.
Sistemas Complexos na Prática
Além desses componentes fundamentais, a engenharia de contexto é aplicada por meio de vários tipos comuns de sistemas complexos.
Geração aumentada por recuperação (RAG) permite que um modelo consulte informações em uma base de conhecimento antes de responder a uma pergunta. Isso ajuda a garantir que a resposta seja baseada em dados reais e atuais, em vez de o modelo adivinhar. Na prática, RAG pode ser construído como pipelines modulares simples, conduzido por agentes que controlam a recuperação, ou combinado com grafos de conhecimento para um contexto mais rico.
Sistemas de memória permitem que os modelos acompanhem informações ao longo das interações. A memória de curto prazo guarda detalhes da conversa atual, enquanto a memória de longo prazo armazena conversas passadas e conhecimento aprendido. Isso torna conversas de múltiplos turnos mais consistentes e ajuda o sistema a melhorar ao longo do tempo.
Raciocínio integrado a ferramentas permite que modelos usem ferramentas externas, como calculadoras, mecanismos de busca ou APIs, em vez de depender apenas do raciocínio textual. Uma parte importante dessa configuração é inserir os resultados das ferramentas de volta no contexto no momento certo, para que o modelo possa usá-los de forma eficaz.
Sistemas multiagente usam múltiplos modelos que trabalham juntos para lidar com tarefas complexas. Cada agente tem uma função específica, e o sistema coordena como eles se comunicam, compartilham informações e permanecem sincronizados para produzir um resultado consistente.
Processamento de Contexto
Anteriormente, apresentamos as três principais partes da engenharia de contexto: recuperação e geração de contexto, processamento de contexto e gerenciamento de contexto. Elas formam os blocos básicos de construção de um sistema de contexto prático.
Processamento de contexto é especialmente importante. Ele pega informações brutas recuperadas e as limpa, remodela e organiza para que o modelo possa entendê-las e usá-las de forma mais eficiente.
Nesta seção, analisamos como o processamento de contexto é feito em sistemas reais e quais abordagens são comumente usadas.
Processamento de Contexto Longo
Processar contextos muito longos é caro porque modelos transformer usam autoatenção, que escala mal à medida que o comprimento da entrada cresce. À medida que a sequência fica mais longa, o uso de computação e memória aumenta rapidamente, criando gargalos reais em sistemas de produção.
Por exemplo, expandir o comprimento de entrada do Mistral-7B de 4K para 128K tokens aumenta o custo computacional em cerca de 122×. O uso de memória também aumenta acentuadamente durante o preenchimento inicial e a decodificação. Na prática, modelos como Llama 3.1 8B podem exigir até 16 GB de memória para uma única solicitação de 128K tokens.
Para contornar esses limites, os pesquisadores usam principalmente três abordagens.
Uma delas é criar novas arquiteturas de modelo, como Mamba, que são mais baratas de executar por design. Outra é usar técnicas como interpolação posicional para permitir que modelos existentes lidem com entradas muito mais longas. A terceira abordagem melhora como a computação é feita, evitando trabalho redundante e usando a memória com mais eficiência, para que o processamento de contexto longo seja mais rápido e use menos recursos.
(1) Inovações Arquiteturais para Contexto Longo
Para lidar com o custo quadrático dos Transformers, pesquisadores desenvolveram novas arquiteturas de modelo que tornam o processamento de sequências longas mais barato e mais eficiente.
- Modelos de Espaço de Estados (SSMs) mantêm complexidade computacional linear e requisitos de memória constantes por meio de estados ocultos de tamanho fixo, com modelos como Mamba oferecendo mecanismos eficientes de computação recorrente que escalam de forma mais eficaz do que transformers tradicionais.
- Atenção dilatada abordagens como LongNet empregam campos atencionais que se expandem exponencialmente à medida que a distância entre tokens cresce, alcançando complexidade computacional linear enquanto mantêm dependência logarítmica entre tokens, tornando possível processar sequências com mais de um bilhão de tokens.
- Redes Neurais Toeplitz (TNNs) modelam sequências com matrizes Toeplitz codificadas por posição relativa, reduzindo a complexidade espaço-tempo para log-linear e permitindo extrapolação de 512 tokens de treinamento para 14.000 tokens de inferência.
- Atenção linear mecanismos reduzem a complexidade de O(N²) para O(N) ao expressar a autoatenção como produtos escalares lineares de mapas de características de kernel, alcançando até 4000× de aceleração ao processar sequências muito longas.
Abordagens alternativas, como LLMs sem atenção, quebram barreiras quadráticas ao empregar transformers de memória recursiva e outras inovações arquiteturais.
(2) Interpolação de Posição e Extensão de Contexto
Técnicas de interpolação de posição permitem que modelos processem sequências além das limitações da janela de contexto original ao redimensionar inteligentemente os índices de posição em vez de extrapolar para posições não vistas.
- As abordagens de Neural Tangent Kernel (NTK) fornecem estruturas matematicamente fundamentadas para extensão de contexto, com YaRN (Yet another RoPE-based Interpolation method) combinando interpolação NTK com interpolação linear e correção da distribuição de atenção.
- Abordagens em duas etapas: LongRoPE alcança janelas de contexto de 2048K tokens por meio de abordagens em duas etapas: primeiro ajustando modelos para comprimento de 256K, depois conduzindo interpolação posicional para atingir o comprimento máximo de contexto.
- Position Sequence Tuning (PoSE) demonstra extensões impressionantes de comprimento de sequência de até 128K tokens ao combinar múltiplas estratégias de interpolação posicional.
- Técnicas de Self-Extend permitem que LLMs processem contextos longos sem ajuste fino ao empregar estratégias de atenção em dois níveis — atenção agrupada e atenção vizinha — para capturar dependências entre tokens distantes e adjacentes.
(3) Técnicas de Otimização para Processamento Eficiente
Sem alterar a arquitetura central do modelo, pesquisadores também desenvolveram uma série de técnicas de otimização para tornar o processamento de contexto longo mais eficiente.
Grouped-Query Attention (GQA) particiona cabeças de consulta em grupos que compartilham cabeças de chave e valor, estabelecendo um equilíbrio entre atenção multi-query e atenção multi-head, ao mesmo tempo que reduz os requisitos de memória durante a decodificação.
FlashAttention explora a hierarquia assimétrica de memória da GPU para alcançar escalonamento linear de memória em vez de requisitos quadráticos, com FlashAttention-2 fornecendo aproximadamente o dobro da velocidade por meio de operações reduzidas que não envolvem multiplicação de matrizes e distribuição de trabalho otimizada.
Ring Attention com Blockwise Transformers permite lidar com sequências extremamente longas ao distribuir a computação por múltiplos dispositivos, aproveitando computação em blocos enquanto sobrepõe comunicação com computação de atenção.
Técnicas de atenção esparsa incluem Shifted sparse attention (S²-Attn) em LongLoRA e SinkLoRA com SF-Attn, que alcançam 92% da melhoria de perplexidade da atenção completa com economias significativas de computação.
Gerenciamento de memória e compressão de contexto reduzem o custo de entradas longas. Rolling Buffer Cache limita a janela de atenção para reduzir a memória do cache KV, enquanto StreamingLLM dá suporte a sequências longas mantendo apenas tokens-chave e contexto recente. Outros métodos como Infini-attention e H2O melhoram a eficiência por meio de memória compressiva e remoção de cache mais inteligente.
Autorrefinamento e Adaptação Contextuais
O autorrefinamento permite que LLMs melhorem saídas por meio de mecanismos cíclicos de feedback que espelham processos humanos de revisão, aproveitando a autoavaliação por meio de autointeração conversacional via engenharia de prompt distinta de abordagens de aprendizado por reforço.
A ideia é simples: para tarefas complexas, é mais fácil escrever uma primeira versão e depois corrigi-la do que acertar tudo de uma só vez. Quando os modelos aprendem a verificar o próprio trabalho e melhorá-lo passo a passo, eles apresentam melhor desempenho em raciocínio, escrita de código e tarefas criativas, e se adaptam mais facilmente a novas situações.
(1) Estruturas Fundamentais de Autorrefinamento
- A estrutura Self-Refine usa o mesmo modelo como gerador, provedor de feedback e refinador, demonstrando que identificar e corrigir erros muitas vezes é mais fácil do que produzir soluções iniciais perfeitas.
- Reflexion mantém texto reflexivo em buffers de memória episódica para tomada de decisões futuras por meio de feedback linguístico, enquanto a orientação estruturada se mostra essencial, pois prompts simplistas frequentemente falham em permitir autocorreção confiável.
- A estrutura N-CRITICS implementa avaliação baseada em ensemble na qual saídas iniciais são avaliadas tanto por LLMs geradores quanto por outros modelos, com feedback compilado orientando o refinamento até que critérios de parada específicos da tarefa sejam cumpridos.
(2) Meta-Aprendizado e Evolução Autônoma
Em um estágio mais avançado, o autoaperfeiçoamento de contexto concentra-se em meta-aprendizado e melhoria autônoma. O objetivo é ajudar o modelo não apenas a resolver tarefas, mas também a aprender como aprender melhor ao longo do tempo.
SELF ensina meta-habilidades a LLMs (auto-feedback, autoaperfeiçoamento) com exemplos limitados e, em seguida, faz com que o modelo evolua continuamente por conta própria, gerando e filtrando seus próprios dados de treinamento. Mecanismos de autorrecompensa permitem que os modelos melhorem autonomamente por meio de autojulgamento iterativo, em que um único modelo adota papéis duplos como executor e juiz, maximizando recompensas que atribui a si mesmo.
O framework Creator estende esse paradigma ao permitir que LLMs criem e usem suas próprias ferramentas por meio de um processo de quatro módulos que abrange criação, tomada de decisão, execução e reconhecimento.
O framework Self-Developing representa a abordagem mais autônoma, permitindo que LLMs descubram, implementem e refinem seus próprios algoritmos de melhoria por meio de ciclos iterativos que geram candidatos algorítmicos como código executável.
Contexto Multimodal
Modelos de linguagem grandes multimodais (MLLMs) vão além do texto ao trabalhar com entradas como imagens, áudio e dados 3D. Eles combinam esses diferentes tipos de informação em um único contexto sobre o qual o modelo pode raciocinar.
Isso torna possíveis aplicações mais avançadas, mas também traz novos desafios, como integrar diferentes modalidades, raciocinar entre elas e lidar com entradas longas e complexas.
(1) Integração de Contexto Multimodal
A integração de contexto é o núcleo do processamento de contexto multimodal. Ela visa combinar informações de diferentes modalidades, como imagens, texto e áudio, em uma única representação com a qual um modelo pode raciocinar.
Uma abordagem básica transforma imagens em tokens usando encoders como CLIP e depois os acrescenta aos tokens de texto antes de enviar tudo ao modelo de linguagem. Isso é fácil de implementar, mas as diferentes modalidades muitas vezes permanecem frouxamente conectadas.
Métodos mais avançados melhoram a integração. A atenção cross-modal permite que o modelo aprenda relações diretas entre tokens visuais e textuais dentro do modelo, o que é importante para tarefas como edição de imagens e raciocínio visual.
Para escalar para entradas longas ou complexas, designs hierárquicos processam cada modalidade em etapas. Alguns sistemas também mesclam informações de várias imagens ou entradas antes de passá-las ao modelo, em vez de lidar com cada uma separadamente.
Outros trabalhos evitam adaptar modelos exclusivamente textuais treinando desde o início com dados multimodais e texto em conjunto. O raciocínio cross-modal se baseia nisso, exigindo que o modelo compreenda não apenas cada modalidade isoladamente, mas também o significado que emerge quando elas são combinadas, como sarcasmo expresso tanto por uma imagem quanto por texto.
(2) Encoders Multimodais Externos e Módulos de Alinhamento
A integração de contexto multimodal é construída sobre duas partes principais: encoders multimodais externos e os módulos de alinhamento que os conectam ao modelo de linguagem.
Na maioria dos sistemas atuais, cada tipo de dado é tratado por um encoder dedicado. Por exemplo, imagens são processadas por modelos como CLIP, e áudio é tratado por modelos como CLAP. Esses encoders transformam entradas brutas, como pixels ou ondas sonoras, em vetores de características.
Os módulos de alinhamento então convertem essas características para o espaço de embeddings do modelo de linguagem, de modo que possam trabalhar em conjunto com tokens de texto. Alguns sistemas usam mapeamentos simples como MLPs, enquanto outros usam Q-Former, que seleciona as características visuais mais relevantes para o texto usando tokens de consulta aprendíveis.
Essa configuração modular torna os sistemas mais fáceis de manter. Encoders podem ser atualizados ou substituídos sem retreinar todo o modelo de linguagem, o que é importante para implantação no mundo real.
Contexto Relacional e Estruturado
Modelos de linguagem grandes enfrentam restrições fundamentais ao processar dados relacionais e estruturados, incluindo tabelas, bancos de dados e grafos de conhecimento, devido aos requisitos de entrada baseados em texto e às limitações da arquitetura sequencial.
A linearização frequentemente falha em preservar relações complexas e propriedades estruturais, com o desempenho se degradando quando a informação está dispersa ao longo dos contextos.
Para resolver esse problema, pesquisadores têm buscado formas de representar dados estruturados em um formato que os modelos de linguagem possam usar. O objetivo é ajudar os modelos a ter melhor desempenho em tarefas que envolvem raciocínio complexo e verificação de fatos.
(1) Embeddings de Grafos de Conhecimento e Integração Neural
Estratégias avançadas de codificação abordam limitações estruturais por meio de embeddings de grafos de conhecimento que transformam entidades e relações em vetores numéricos, permitindo processamento eficiente dentro de arquiteturas de modelos de linguagem.
Redes neurais em grafos capturam relações complexas entre entidades, facilitando o raciocínio de múltiplos saltos em estruturas de grafos de conhecimento por meio de arquiteturas especializadas como GraphFormers, que aninham componentes de GNN junto a blocos transformer.
(2) Verbalização
Uma abordagem comum é transformar dados estruturados — como grafos de conhecimento, tabelas ou registros de bancos de dados — em texto em linguagem natural, para que possam ser usados diretamente por modelos de linguagem existentes sem alterar sua arquitetura. Outros métodos reorganizam o texto de entrada em camadas estruturadas com base em relações linguísticas, ou extraem informações-chave e as representam explicitamente como grafos, tabelas ou esquemas relacionais.
Em alguns casos, representar dados estruturados usando linguagens de programação funciona melhor do que linguagem natural. Por exemplo, usar código Python para grafos de conhecimento ou SQL para bancos de dados muitas vezes leva a um desempenho mais forte em tarefas de raciocínio complexo, porque esses formatos preservam a estrutura com mais clareza. Também há abordagens eficientes em termos de recursos que usam representações matriciais compactas para lidar com dados estruturados com menos parâmetros, mantendo um bom desempenho.
(3) Arquiteturas Híbridas
Para lidar com dados estruturados com relações complexas, como tabelas e grafos de conhecimento, pesquisadores têm explorado arquiteturas híbridas que combinam grandes modelos de linguagem com componentes projetados para dados estruturados em grafos, como redes neurais em grafos.
Várias abordagens práticas são usadas. GraphToken torna as relações explícitas adicionando tokens especiais, o que ajuda os modelos a raciocinar sobre grafos. Heterformer processa texto e estrutura de grafo juntos em uma única estrutura, mantendo as informações de relacionamento enquanto controla o custo computacional.
Outros métodos integram conhecimento de maneiras diferentes. K-BERT adiciona informações de grafos de conhecimento durante o treinamento, para que o modelo aprenda essas relações antecipadamente. KAPING recupera conhecimento relevante no momento da inferência, sem retreinamento. Projetos mais avançados usam adaptadores e atenção para combinar informações de grafos diretamente no modelo, levando a uma integração mais estreita.
Conclusão
A engenharia de contexto oferece uma forma útil de entender como sistemas de LLM funcionam em produção. Em geral, ela envolve três processos principais: recuperação e geração de contexto, processamento de contexto e gerenciamento de contexto. Juntas, essas etapas determinam como as informações são coletadas, preparadas e passadas ao modelo.
Entre elas, o processamento de contexto é especialmente importante porque decide como as informações recuperadas são limpas, organizadas e comprimidas antes de chegarem ao modelo. Devido aos limites de espaço, este artigo se concentrou principalmente nessa parte e revisou várias abordagens usadas em sistemas reais. A recuperação e o gerenciamento de contexto também são áreas importantes e podem ser explorados mais a fundo em discussões futuras.
Se você está criando sistemas RAG ou de agentes e enfrentando problemas em produção com contexto, custo ou latência, participe do nosso Slack Channel para discutir engenharia de contexto com outros engenheiros. Você também pode agendar uma breve sessão individual para obter orientações práticas sobre como passar de demonstrações para sistemas prontos para produção por meio do Milvus Office Hours.
Continue lendo

Zilliz Cloud On-Demand Compute: Pay Only for What You Use
The customer case behind Zilliz Cloud On-Demand: how a $10K vector search bill came down to under $500, and the engineering changes that made it possible.

Zilliz Cloud Delivers Better Performance and Lower Costs with Arm Neoverse-based AWS Graviton
Zilliz Cloud adopts Arm-based AWS Graviton3 CPUs to cut costs, speed up AI vector search, and power billion-scale RAG and semantic search workloads.

Selecting the Right ETL Tools for Unstructured Data to Prepare for AI
Learn the right ETL tools for unstructured data to power AI. Explore key challenges, tool comparisons, and integrations with Milvus for vector search.