




Apresentando o DeepSearcher: Uma pesquisa profunda local de código aberto
 deep researcher.gif
deep researcher.gif
No post anterior, "I Built a Deep Research with Open Source-and So Can You!", explicámos alguns dos princípios subjacentes aos agentes de investigação e construímos um protótipo simples que gera relatórios detalhados sobre um determinado tópico ou questão. O artigo e o bloco de notas correspondente demonstraram os conceitos fundamentais de utilização de ferramentas, decomposição de consultas, raciocínio e reflexão. O exemplo no nosso post anterior, em contraste com o Deep Research da OpenAI, foi executado localmente, usando apenas modelos e ferramentas de código aberto como Milvus e LangChain. (Aconselho-o a ler o artigo acima antes de continuar).
Nas semanas seguintes, houve uma explosão de interesse em compreender e reproduzir a Investigação Profunda da OpenAI. Veja, por exemplo, Perplexity Deep Research e Hugging Face's Open DeepResearch. Estas ferramentas diferem em termos de arquitetura e metodologia, embora partilhem um objetivo: pesquisar iterativamente um tópico ou questão navegando na Web ou em documentos internos e produzir um relatório detalhado, informado e bem estruturado. É importante notar que o agente subjacente automatiza o raciocínio sobre a ação a tomar em cada passo intermédio.
Neste post, baseamo-nos no nosso post anterior e apresentamos o projeto de código aberto [DeepSearcher] (https://github.com/zilliztech/deep-searcher) de Zilliz. O nosso agente demonstra conceitos adicionais: roteamento de consultas, fluxo de execução condicional e rastreamento da Web como uma ferramenta. É apresentado como uma biblioteca Python e uma ferramenta de linha de comando em vez de um bloco de notas Jupyter e tem mais funcionalidades do que o nosso post anterior. Por exemplo, pode introduzir vários documentos de origem e pode definir o modelo de incorporação e a base de dados vetorial utilizados através de um ficheiro de configuração. Embora ainda relativamente simples, o DeepSearcher é uma excelente demonstração do RAG agêntico e é mais um passo em direção a aplicações de IA de última geração.
Além disso, exploramos a necessidade de serviços de inferência mais rápidos e eficientes. Os modelos de raciocínio utilizam a "escala de inferência", ou seja, computação extra, para melhorar o seu resultado, e isso, combinado com o facto de um único relatório poder exigir centenas ou milhares de chamadas LLM, faz com que a largura de banda de inferência seja o principal estrangulamento. Usamos o [modelo de raciocínio DeepSeek-R1 no hardware personalizado da SambaNova] (https://sambanova.ai/press/fastest-deepseek-r1-671b-with-highest-efficiency), que é duas vezes mais rápido em tokens de saída por segundo do que o concorrente mais próximo (ver figura abaixo).
O SambaNova Cloud também fornece inferência como serviço para outros modelos de código aberto, incluindo Llama 3.x, Qwen2.5 e QwQ. O serviço de inferência é executado no chip personalizado da SambaNova chamado unidade de fluxo de dados reconfigurável (RDU), que é especialmente concebido para inferência eficiente em modelos de IA generativa, reduzindo o custo e aumentando a velocidade de inferência. Para mais informações, consulte o sítio Web
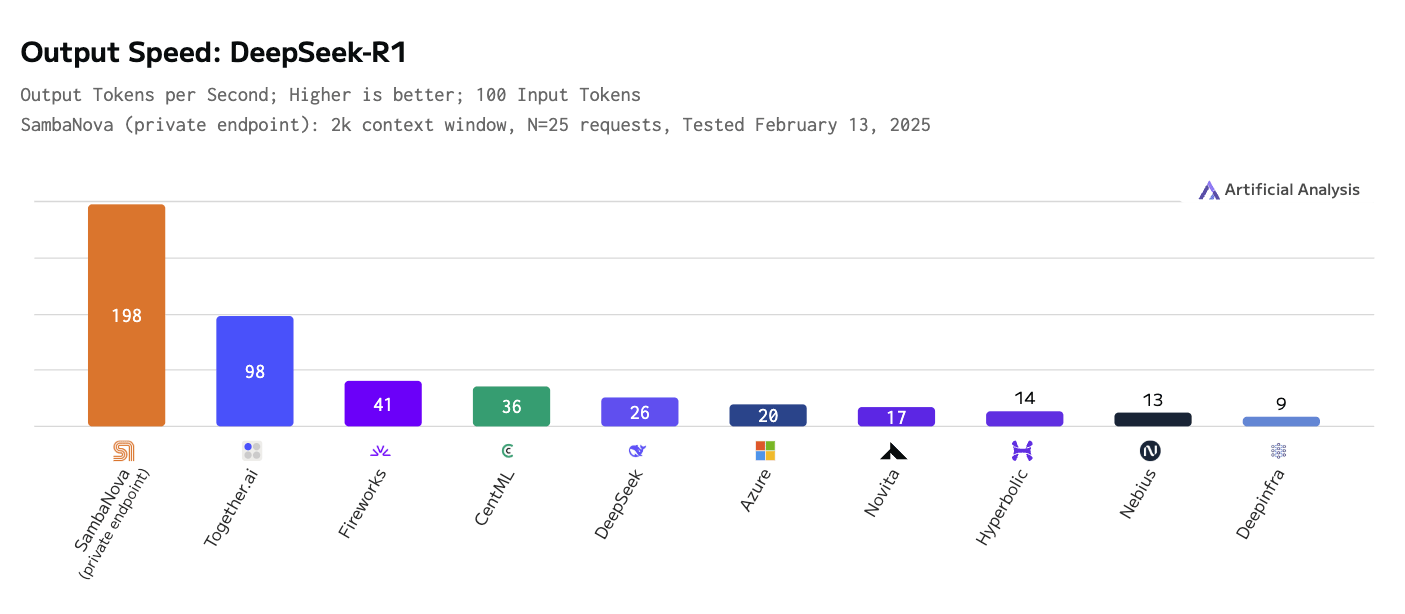 Velocidade de saída - deepseek r1.png
Velocidade de saída - deepseek r1.png
Arquitetura do DeepSearcher
A arquitetura do DeepSearcher segue o nosso post anterior, dividindo o problema em quatro passos - definir/refinar a questão, investigar, analisar, sintetizar - embora desta vez com alguma sobreposição. Passamos por cada passo, destacando as melhorias do DeepSearcher.
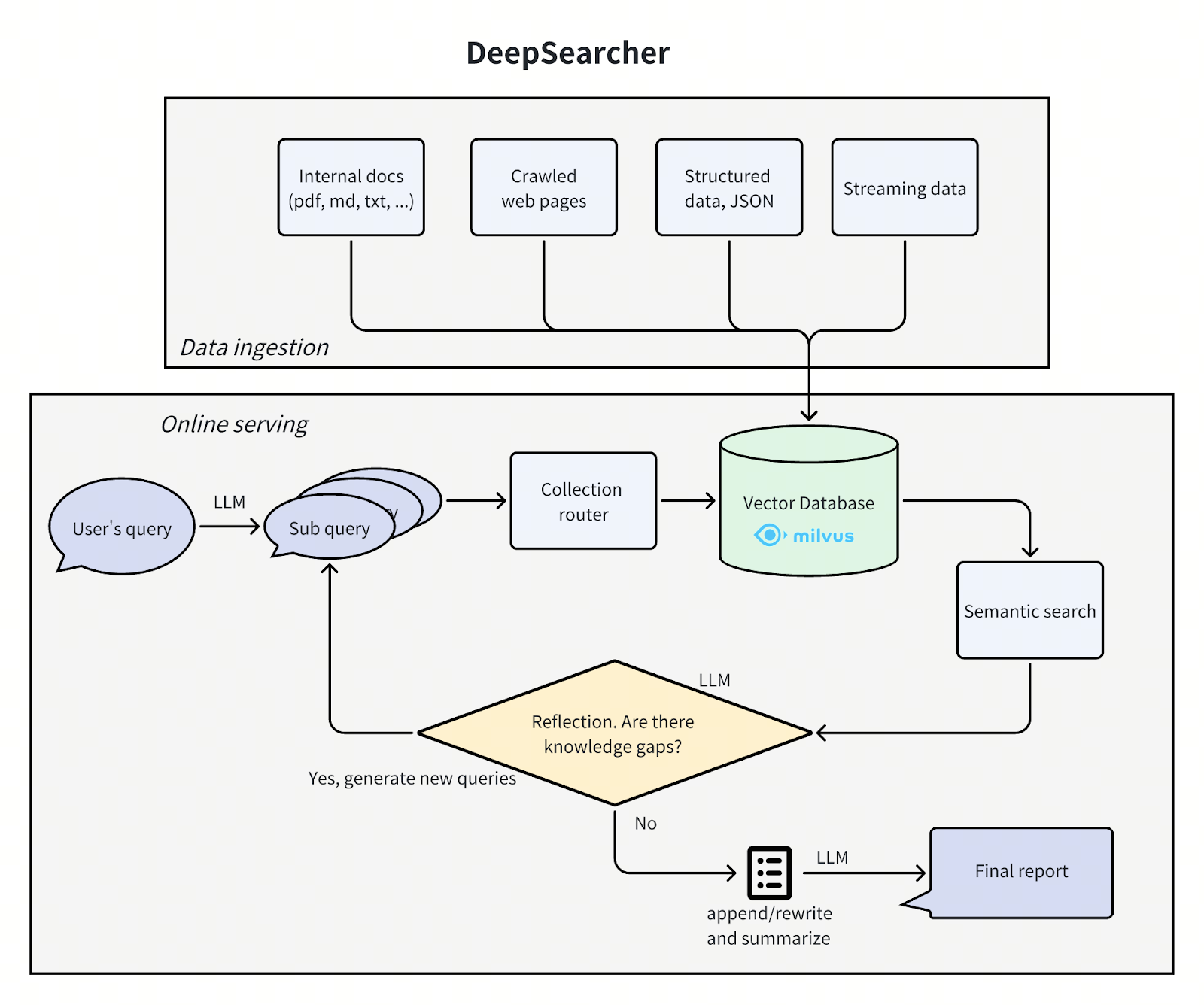 deepsearcher architecture.png
deepsearcher architecture.png
Definir e refinar a pergunta
Dividir a consulta original em novas subconsultas: [
'Como é que o impacto cultural e a relevância social de Os Simpsons evoluíram desde a sua estreia até ao presente?
Que mudanças no desenvolvimento das personagens, no humor e no estilo de contar histórias ocorreram nas diferentes temporadas de Os Simpsons?
Como é que o estilo de animação e a tecnologia de produção de Os Simpsons mudaram ao longo do tempo?
'Como é que a demografia, a receção e as audiências de Os Simpsons se alteraram ao longo da sua duração?]
Na conceção do DeepSearcher, as fronteiras entre a pesquisa e o refinamento da pergunta são pouco nítidas. A consulta inicial do utilizador é decomposta em subconsultas, tal como no post anterior. Veja acima as subconsultas iniciais produzidas a partir da consulta "Como Os Simpsons mudaram ao longo do tempo?". No entanto, a etapa de pesquisa a seguir continuará a refinar a pergunta conforme necessário.
Pesquisa e análise
Depois de dividir a pergunta em subperguntas, a parte de pesquisa do agente começa. Tem, grosso modo, quatro passos: encaminhamento, pesquisa, _reflexão, e repetição condicional.
Encaminhamento
A nossa base de dados contém várias tabelas ou colecções de diferentes fontes. Seria mais eficiente se pudéssemos restringir a nossa pesquisa semântica apenas às fontes que são relevantes para a consulta em causa. Um encaminhador de consultas pede a um LLM que decida a partir de que colecções a informação deve ser recuperada.
Eis o método para formar o pedido de encaminhamento de consultas:
def get_vector_db_search_prompt(
pergunta: str,
nomes_da_colecção: List[str],
descrição_das_colecções: List[str],
contexto: List[str] = None,
):
sections = []
# prompt comum
prompt_comum = f"""És um analista avançado de problemas de IA. Utiliza a tua capacidade de raciocínio e a informação histórica das conversas, com base em todos os conjuntos de dados existentes, para obteres respostas absolutamente exactas às seguintes perguntas e gerares uma pergunta adequada para cada conjunto de dados, de acordo com a descrição do conjunto de dados que pode estar relacionada com a pergunta.
Pergunta: {pergunta}
"""
secções.append(common_prompt)
# prompt do conjunto de dados
conjunto_de_dados = []
for i, collection_name in enumerate(collection_names):
data_set.append(f"{nome_da_colecção}: {descrições_da_colecção[i]}")
data_set_prompt = f"""O seguinte é toda a informação do conjunto de dados. O formato das informações do conjunto de dados é nome do conjunto de dados: descrição do conjunto de dados.
Conjuntos de dados e descrições:
"""
secções.append(data_set_prompt + "\n".join(data_set))
# prompt de contexto
if context:
context_prompt = f"""O que se segue é uma versão condensada da conversa histórica. Esta informação precisa de ser combinada nesta análise para gerar perguntas que estejam mais próximas da resposta. Não pode gerar as mesmas perguntas ou perguntas semelhantes para o mesmo conjunto de dados, nem pode gerar novamente perguntas para conjuntos de dados que foram determinados como não relacionados.
Conversa histórica:
"""
secções.append(context_prompt + "\n".join(context))
# prompt de resposta
response_prompt = f"""Com base no que precede, só pode selecionar alguns conjuntos de dados da seguinte lista de conjuntos de dados para gerar perguntas relacionadas adequadas para os conjuntos de dados selecionados, a fim de resolver os problemas acima referidos. O formato de saída é json, em que a chave é o nome do conjunto de dados e o valor é a pergunta gerada correspondente.
Conjuntos de dados:
"""
secções.append(response_prompt + "\n".join(collection_names))
rodapé = """Responder exclusivamente em formato JSON válido que corresponda ao esquema JSON exato.
Requisitos críticos:
- Incluir APENAS UM tipo de ação
- Nunca adicionar chaves não suportadas
- Excluir todo o texto não JSON, markdown ou explicações
- Manter uma sintaxe JSON rigorosa"""
secções.append(rodapé)
return "\n\n".join(sections)
Fazemos com que o LLM retorne uma saída estruturada como JSON para converter facilmente sua saída em uma decisão sobre o que fazer a seguir.
Pesquisa
Tendo selecionado várias colecções de bases de dados através do passo anterior, o passo de pesquisa efectua uma pesquisa de semelhanças com Milvus. Tal como no post anterior, os dados de origem foram especificados antecipadamente, divididos em pedaços, incorporados e armazenados na base de dados vetorial. Para o DeepSearcher, as fontes de dados, tanto locais como online, devem ser especificadas manualmente. Deixamos a pesquisa online para trabalhos futuros.
Reflexão
Ao contrário do post anterior, o DeepSearcher ilustra uma verdadeira forma de reflexão agêntica, introduzindo os resultados anteriores como contexto num prompt que "reflecte" sobre se as perguntas feitas até agora e os pedaços recuperados relevantes contêm quaisquer lacunas informativas. Isto pode ser visto como uma etapa de análise.
Aqui está o método para criar o prompt:
def get_reflect_prompt(
pergunta: str,
mini_perguntas: List[str],
mini_perguntas: List[str],
):
mini_chunk_str = ""
for i, chunk in enumerate(mini_chuncks):
mini_chunk_str += f"""<chunk_{i}>\n{chunk}\n</chunk_{i}>\n"""
reflect_prompt = f"""Determine se são necessárias consultas de pesquisa adicionais com base na consulta original, nas subconsultas anteriores e em todos os pedaços de documentos recuperados. Se for necessária mais investigação, forneça uma lista Python com um máximo de 3 consultas de pesquisa. Se não for necessária mais investigação, devolve uma lista vazia.
Se a consulta original for para escrever um relatório e preferir gerar mais algumas consultas, devolva uma lista vazia.
Consulta original: {question}
Subconsultas anteriores: {mini_questions}
Fragmentos relacionados:
{mini_chunk_str}
"""
rodapé = """Responder exclusivamente no formato válido Lista de str sem qualquer outro texto."""
return reflect_prompt + rodapé
Mais uma vez, fazemos com que o LLM retorne uma saída estruturada, desta vez como dados interpretáveis em Python.
Aqui está um exemplo de novas subconsultas "descobertas" por reflexão depois de responder às subconsultas iniciais acima:
Novas consultas de pesquisa para a próxima iteração: [
"Como é que as mudanças no elenco de vozes e na equipa de produção de Os Simpsons influenciaram a evolução do programa ao longo das diferentes temporadas?",
"Que papel desempenharam a sátira e o comentário social de Os Simpsons na sua adaptação a questões contemporâneas ao longo das décadas?",
Como é que Os Simpsons abordaram e incorporaram as mudanças no consumo dos media, como os serviços de streaming, nas suas estratégias de distribuição e conteúdo?]
Repetição condicional
Ao contrário do nosso post anterior, o DeepSearcher ilustra o fluxo de execução condicional. Depois de refletir sobre se as perguntas e respostas até agora estão completas, se houver perguntas adicionais a fazer, o agente repete os passos acima. É importante notar que o fluxo de execução (um ciclo "while") é uma função da saída LLM em vez de ser codificado. Neste caso, existe apenas uma escolha binária: repetir a pesquisa ou gerar um relatório. Em agentes mais complexos, pode haver várias opções, tais como: seguir hiperligação, recuperar pedaços, guardar na memória, reflectir etc. Desta forma, a pergunta continua a ser refinada à medida que o agente considera adequado até decidir sair do ciclo e gerar o relatório. No nosso exemplo dos Simpsons, o DeepSearcher executa mais duas rodadas de preenchimento das lacunas com subconsultas extras.
Sintetizar
Finalmente, a pergunta totalmente decomposta e os pedaços recuperados são sintetizados em um relatório com um único prompt. Aqui está o código para criar o prompt:
def get_final_answer_prompt(
pergunta: str,
mini_perguntas: List[str],
mini_perguntas: List[str],
):
mini_chunk_str = ""
for i, chunk in enumerate(mini_chuncks):
mini_chunk_str += f"""<chunk_{i}>\n{chunk}\n</chunk_{i}>\n"""
summary_prompt = f"""Você é um especialista em análise de conteúdo de IA, bom em resumir conteúdo. Resuma uma resposta ou relatório específico e detalhado com base nas consultas anteriores e nos pedaços de documentos recuperados.
Consulta original: {question}
Subconsultas anteriores: {mini_questions}
Fragmentos relacionados:
{mini_chunk_str}
"""
return summary_prompt
Esta abordagem tem a vantagem, em relação ao nosso protótipo, que analisou cada pergunta separadamente e simplesmente concatenou o resultado, de produzir um relatório em que todas as secções são consistentes entre si, ou seja, não contém informação repetida ou contraditória. Um sistema mais complexo poderia combinar aspectos de ambos, utilizando um fluxo de execução condicional para estruturar o relatório, resumir, reescrever, refletir e dinamizar, etc., o que deixamos para trabalho futuro.
Resultados
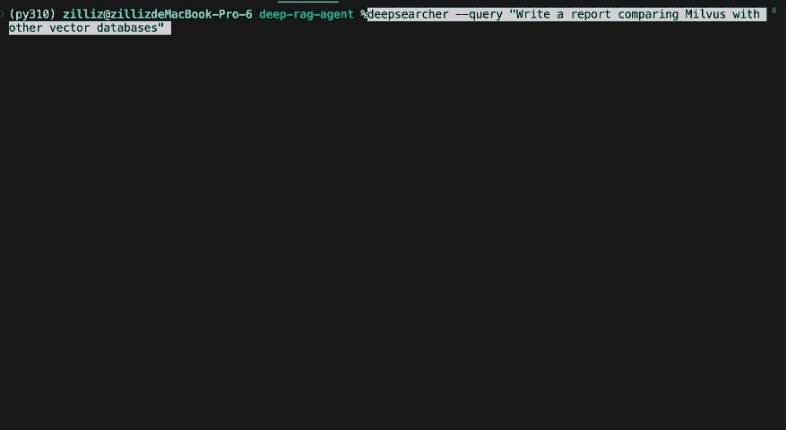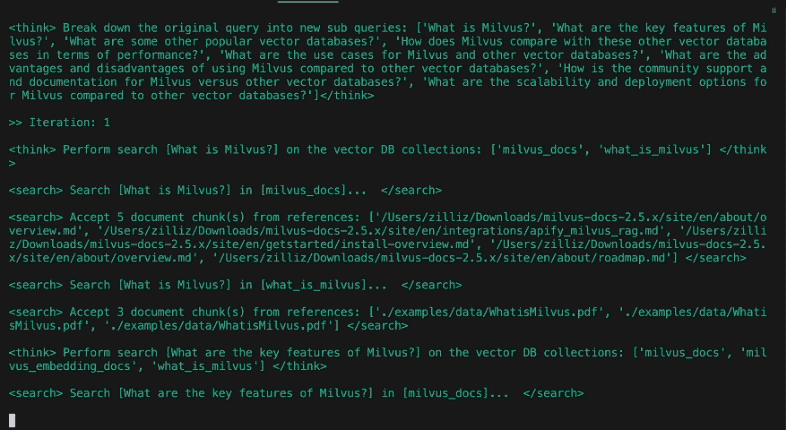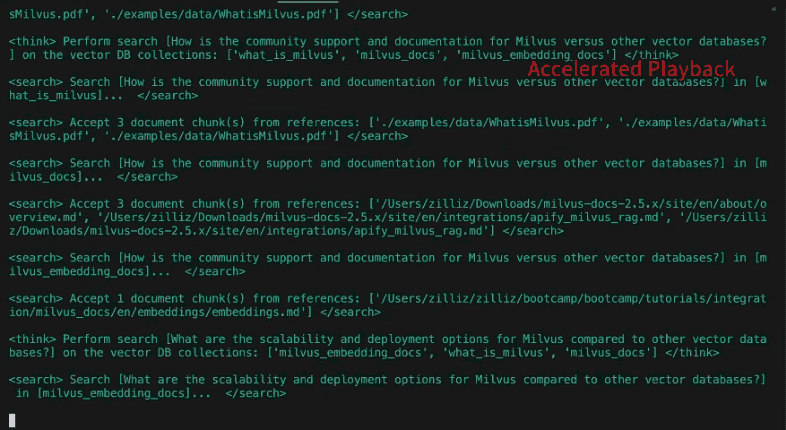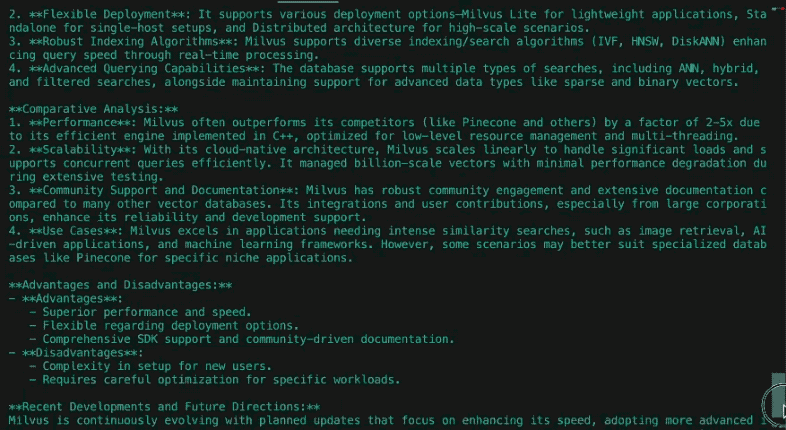
Aqui está um exemplo do relatório gerado pela consulta "Como Os Simpsons mudaram ao longo do tempo?" com o DeepSeek-R1 passando a página da Wikipedia sobre Os Simpsons como material de origem:
Relatório: A evolução de Os Simpsons (1989-presente)
1. Impacto cultural e relevância social
Os Simpsons estreou como uma crítica subversiva da vida da classe média americana, ganhando notoriedade pela sua sátira ousada na década de 1990. Inicialmente um fenómeno contracultural, desafiava as normas com episódios que abordavam a religião, a política e o consumismo. Com o passar do tempo, o seu domínio cultural foi diminuindo à medida que concorrentes como South Park e Family Guy foram ultrapassando os limites. Na década de 2010, o programa passou de criador de tendências a instituição nostálgica, equilibrando o apelo do legado com tentativas de abordar questões modernas como as alterações climáticas e os direitos LGBTQ+, embora com menos ressonância social.
...
Conclusão
Os Simpsons evoluíram de uma sátira radical para uma instituição televisiva, navegando nas mudanças tecnológicas, políticas e nas expectativas do público. Embora o seu brilhantismo da era dourada permaneça inigualável, a sua adaptabilidade - através de streaming, humor atualizado e alcance global - assegura o seu lugar como pedra de toque cultural. A longevidade do programa reflecte tanto a nostalgia como a aceitação pragmática da mudança, mesmo quando enfrenta os desafios da relevância num panorama mediático fragmentado.
Encontrar o relatório completo aqui, e um relatório produzido pelo DeepSearcher com o GPT-4o mini para comparação.
Discussão
Apresentámos o DeepSearcher, um agente para fazer pesquisa e escrever relatórios. O nosso sistema foi construído com base na ideia do nosso artigo anterior, acrescentando caraterísticas como o fluxo de execução condicional, o encaminhamento de consultas e uma interface melhorada. Passámos da inferência local com um pequeno modelo de raciocínio quantizado de 4 bits para um serviço de inferência online para o modelo massivo DeepSeek-R1, melhorando qualitativamente o nosso relatório de resultados. O DeepSearcher funciona com a maioria dos serviços de inferência, como OpenAI, Gemini, DeepSeek e Grok 3 (em breve!).
Os modelos de raciocínio, especialmente os usados em agentes de pesquisa, são pesados em termos de inferência, e tivemos a sorte de poder usar a oferta mais rápida do DeepSeek-R1 da SambaNova em execução em seu hardware personalizado. Para nossa consulta de demonstração, fizemos sessenta e cinco chamadas para o serviço de inferência DeepSeek-R1 da SambaNova, inserindo cerca de 25 mil tokens, produzindo 22 mil tokens e custando US$ 0,30. Ficámos impressionados com a velocidade da inferência, dado que o modelo contém 671 mil milhões de parâmetros e tem 3/4 de um terabyte de tamanho. Saiba mais detalhes aqui!
Continuaremos a repetir este trabalho em posts futuros, examinando conceitos agênticos adicionais e o espaço de design dos agentes de investigação. Entretanto, convidamos todos a experimentar o DeepSearcher, star us on GitHub, e a partilhar o seu feedback!
Recursos

Continue lendo

Why AI Databases Don't Need SQL
Whether you like it or not, here's the truth: SQL is destined for decline in the era of AI.

Vector Databases vs. Graph Databases
Use a vector database for AI-powered similarity search; use a graph database for complex relationship-based queries and network analysis.

DeepRAG: Thinking to Retrieval Step by Step for Large Language Models
Discover DeepRAG, an advanced retrieval-augmented generation (RAG) model that improves LLM accuracy by retrieving only essential data through step-by-step reasoning.