




Implementação de um sistema RAG multimodal utilizando vLLM e Milvus
Imagine que passou meses a afinar a sua aplicação de IA em torno de um [LLM] específico (https://zilliz.com/glossary/large-language-models-(llms)) através de um fornecedor de API. Então, do nada, recebe um e-mail: "Estamos a descontinuar o modelo que está a utilizar em favor da nossa nova versão". Parece familiar? Embora os provedores de API em nuvem ofereçam a conveniência de recursos de IA poderosos e prontos para uso, confiar apenas neles também apresenta vários riscos significativos:
- Falta de controlo: Não tem controlo sobre as versões ou actualizações dos modelos.
- Imprevisibilidade**: Pode deparar-se com alterações súbitas no comportamento ou nas capacidades do modelo.
- Visão limitada**: A visibilidade do desempenho e dos padrões de utilização é frequentemente limitada.
- Preocupações com a privacidade**: A privacidade dos dados pode ser uma questão crítica, especialmente quando se lida com informações sensíveis.
Então, qual é a solução? Como é que pode recuperar o controlo? Como pode mitigar estes riscos enquanto melhora as capacidades do seu sistema? A resposta está na construção de um sistema mais robusto e independente utilizando soluções de código aberto.
Este blogue irá guiá-lo na criação de um Multimodal RAG com Milvus e vLLM. Tirando partido do poder de uma base de dados vetorial combinada com inferência LLM de código aberto, pode conceber um sistema capaz de processar e compreender vários tipos de dados - texto, imagens, áudio e até vídeos. Esta abordagem não só lhe dá o controlo total da tecnologia, como também garante um sistema que é simultaneamente poderoso e versátil, ultrapassando as soluções tradicionais baseadas em texto.
O que vamos construir: um RAG multimodal totalmente sob o seu controlo
Vamos construir um sistema Multimodal RAG usando Milvus e vLLM, ilustrando como pode auto-hospedar o seu LLM e ganhar controlo total sobre as suas aplicações de IA. O nosso tutorial irá guiá-lo através da criação de uma aplicação Streamlit que demonstra o poder da integração de vários tipos de dados. Veja o que abordaremos:
Processar a entrada de vídeo extraindo fotogramas e transcrevendo o áudio
Armazenar e indexar eficientemente dados multimodais utilizando Milvus
- Utilizamos o OpenAI CLIP para codificar as imagens em embeddings que podem depois ser pesquisados com o Milvus
- Usamos o modelo Mistral Embedding para codificar o texto em embeddings.
Recuperar o contexto relevante com base nas consultas do utilizador utilizando o Milvus
Gerar respostas utilizando o Pixtral em execução com o vLLM, tirando partido da compreensão visual e textual
No final deste tutorial, terá desenvolvido um sistema flexível e escalável totalmente sob o seu controlo - sem ter de se preocupar mais com as depreciações da API ou alterações inesperadas.
O que é Milvus?
Milvus é um banco de dados vetorial de código aberto, de alto desempenho e altamente escalável que pode armazenar, indexar e pesquisar dados não estruturados em escala de bilhões por meio de vetor embeddings de alta dimensão. É perfeita para criar aplicações modernas de IA, como a geração aumentada de recuperação (RAG), a pesquisa semântica, a pesquisa multimodal e os sistemas de recomendação. O Milvus funciona eficientemente em vários ambientes, desde computadores portáteis a sistemas distribuídos em grande escala.
O que é vLLM?
A ideia central do vLLM (Virtual Large Language Model) é otimizar o serviço e a execução de LLMs através da utilização de técnicas eficientes de gestão de memória. Aqui estão os principais aspectos:
- Gerenciamento de memória otimizado: O vLLM implementa técnicas avançadas de alocação e gerenciamento de memória para aproveitar ao máximo os recursos de hardware disponíveis. Essa otimização ajuda a executar grandes modelos de linguagem com eficiência, evitando gargalos de memória que podem prejudicar o desempenho.
- Lote dinâmico**: O vLLM adapta os tamanhos e as seqüências dos lotes com base na memória e nos recursos de computação do hardware subjacente. Esse ajuste dinâmico aumenta o rendimento do processamento e minimiza a latência durante a inferência do modelo.
- Projeto modular**: A arquitetura do vLLM é modular, facilitando a integração direta com vários aceleradores de hardware. Essa modularidade também permite o escalonamento fácil em vários dispositivos ou clusters, tornando-o altamente adaptável a diferentes cenários de implantação.
- Utilização eficiente de recursos**: o vLLM otimiza o uso de recursos críticos, como CPUs, GPUs e memória. Essa eficiência permite que o sistema ofereça suporte a modelos maiores e lide com um número maior de solicitações simultâneas, o que é essencial em ambientes de produção em que tanto a escalabilidade quanto o desempenho são fundamentais.
- Integração perfeita**: Concebido para se integrar sem problemas com as estruturas e bibliotecas de aprendizagem automática existentes, o vLLM fornece uma interface fácil de utilizar. Isso garante que os desenvolvedores possam implantar e gerenciar facilmente grandes modelos de linguagem em uma variedade de aplicativos sem reconfiguração extensiva.
Componentes principais do nosso RAG multimodal
A aplicação RAG multimodal que estamos a construir é composta pelos seguintes componentes principais:
- vLLM é a biblioteca de inferência que utilizaremos para a inferência e o fornecimento do modelo multimodal Pixtral.
- Koyeb fornece a camada de infraestrutura para nossa implantação, oferecendo uma plataforma sem servidor especializada para cargas de trabalho de IA. Com integração vLLM nativa e gerenciamento automatizado de recursos de GPU, facilita a implantação do LLM, mantendo o desempenho e a escalabilidade de nível de produção.
- Pixtral da Mistral AI actua como o nosso cérebro multimodal, combinando um codificador de visão de 400M parâmetros com um descodificador multimodal de 12B parâmetros. Esta arquitetura permite-lhe processar imagens e texto na mesma [janela de contexto] (https://zilliz.com/glossary/context-window).
- O Milvus fornece a base de armazenamento de vectores, gerindo eficazmente os embeddings de diferentes modalidades. A sua capacidade para lidar com vários tipos de vectores e realizar rapidamente pesquisa de semelhanças torna-o perfeito para aplicações multimodais.
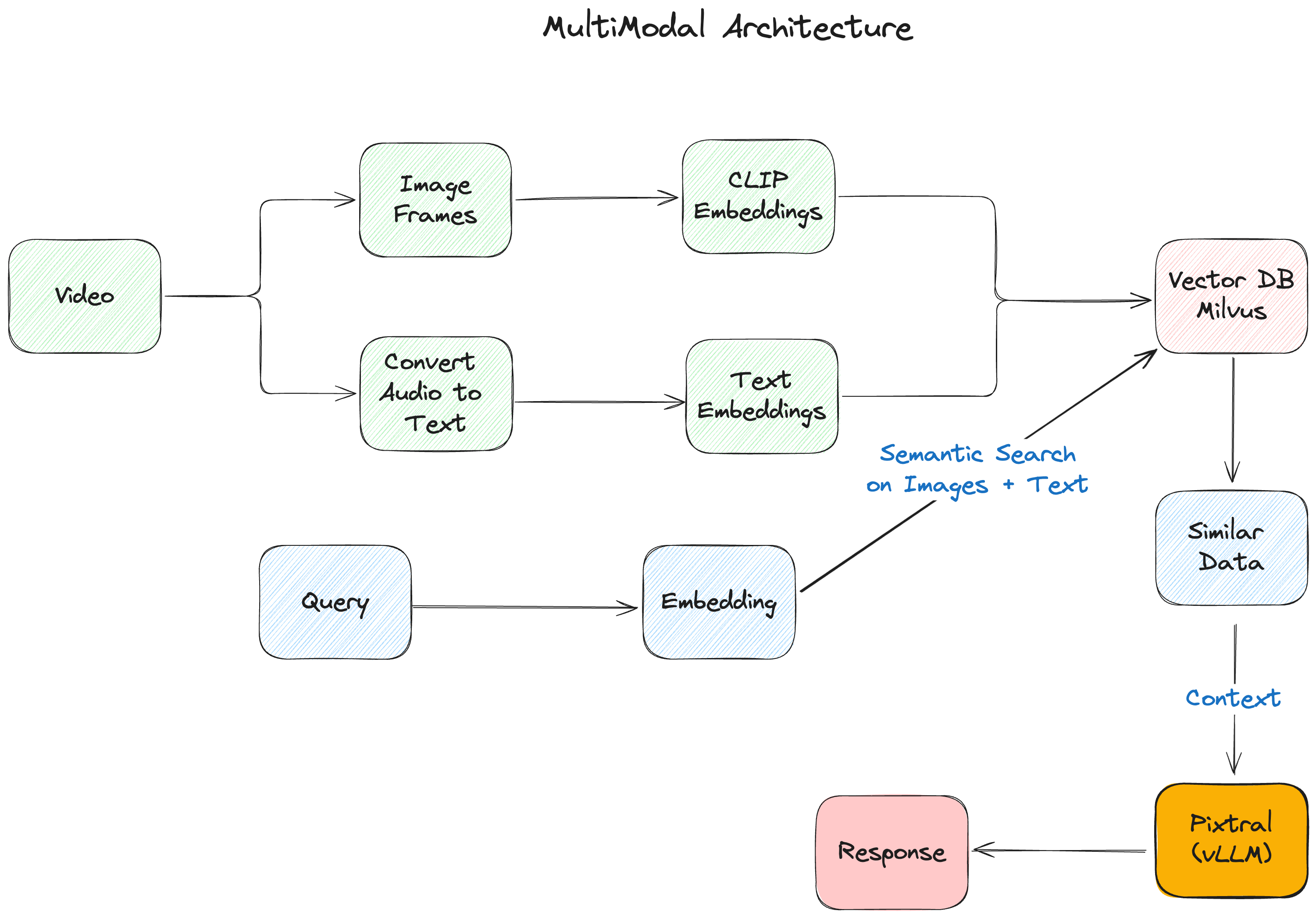 Figura - A arquitetura multimodal do RAG.png
Figura - A arquitetura multimodal do RAG.png
Figura: A arquitetura multimodal das RAG
Introdução
Primeiro, vamos instalar as nossas dependências:
# Pacotes principais do LlamaIndex
pip install -U llama-index-vetor-stores-milvus llama-index-multi-modal-llms-mistralai llama-index-embeddings-mistralai llama-index-multi-modal-llms-openai llama-index-embeddings-clip llama_index
# Processamento de vídeo e áudio
pip install moviepy pytube pydub SpeechRecognition openai-whisper ffmpeg-python soundfile
# Processamento e visualização de imagens
pip install torch torchvision matplotlib scikit-image git+https://github.com/openai/CLIP.git
# Utilitários e infra-estruturas
pip install pymilvus streamlit ftfy regex tqdm
Configurando o ambiente
Vamos começar configurando nosso ambiente e importando as bibliotecas necessárias:
import os
import base64
import json
from pathlib import Path
from dotenv import load_dotenv
from llama_index.core import Settings
from llama_index.embeddings.mistralai import MistralAIEmbedding
# Carregar variáveis de ambiente
load_dotenv()
# Configurar o modelo padrão de embedding
Settings.embed_model = MistralAIEmbedding(
"mistral-embed",
api_key=os.getenv("MISTRAL_API_KEY")
)
Pipeline de processamento de vídeo
O coração do nosso sistema é o pipeline de processamento de vídeo, que transforma o conteúdo bruto de vídeo em dados que o nosso sistema RAG pode compreender e processar de forma eficiente.
def process_video(video_path: str, output_folder: str, output_audio_path: str) -> dict:
# Cria o diretório de saída se ele não existir
Path(pasta_de_saída).mkdir(parents=True, exist_ok=True)
# Extrair fotogramas do vídeo
video_to_images(video_path, output_folder)
# Extrair e transcrever o áudio
video_to_audio(video_path, output_audio_path)
dados_de_texto = audio_to_text(output_audio_path)
# Guardar a transcrição
com open(os.path.join(pasta_de_saída, "texto_de_saída.txt"), "w") as file:
file.write(text_data)
os.remove(output_audio_path)
return {"Autor": "Exemplo de Autor", "Título": "Exemplo de título", "Visualizações": "1000000"}
Esse pipeline divide os vídeos em:
- Quadros de imagem (extraídos a 0,2 FPS)
- Transcrição de áudio usando o Whisper
- Metadados sobre o vídeo
Construir o índice vetorial
Usamos o Milvus para armazenar nossos embeddings multimodais. Aqui está como criamos nosso índice:
def create_index(pasta_de_saída: str):
# Criar colecções diferentes para texto e imagens
text_store = MilvusVectorStore(
uri="milvus_local.db",
nome_da_colecção="colecção_de_texto",
overwrite=True,
dim=1024
)
image_store = MilvusVectorStore(
uri="milvus_local.db",
nome_da_colecção="colecção_de_imagens",
overwrite=True,
dim=512
)
storage_context = StorageContext.from_defaults(
vector_store=text_store,
image_store=image_store
)
# Carregar e indexar documentos
documents = SimpleDirectoryReader(output_folder).load_data()
return MultiModalVectorStoreIndex.from_documents(
documentos,
storage_context=storage_context
)
Processamento de consulta com Pixtral
Quando um utilizador faz uma pergunta, precisamos de:
- Recuperar o contexto relevante da nossa loja de vectores
- Processar a consulta com o Pixtral usando texto e imagens
Aqui está a nossa função de processamento de consultas:
def process_query_with_image(query_str, context_str, metadata_str, image_document):
client = OpenAI(
base_url=os.getenv("KOYEB_ENDPOINT"),
api_key=os.getenv("KOYEB_TOKEN")
)
com open(image_document.image_path, "rb") as image_file:
image_base64 = base64.b64encode(image_file.read()).decode("utf-8")
qa_tmpl_str = """
Com base nas informações fornecidas, incluindo imagens relevantes e contexto recuperado
do vídeo, responder com exatidão e precisão à consulta sem qualquer
conhecimento prévio adicional.
---------------------
Contexto: {context_str}
Metadados: {metadata_str}
---------------------
Consulta: {query_str}
Resposta: """
# Preparar as mensagens para o Pixtral
mensagens = [
{
"role": "utilizador",
"content": [
{
"tipo": "text",
"texto": qa_tmpl_str.format(
context_str=context_str,
query_str=query_str,
metadata_str=metadata_str
)
},
{
"type": "image_url",
"image_url": {
"url": f "data:image/jpeg;base64,{image_base64}"
}
},
],
}
]
conclusão = client.chat.completions.create(
model="mistralai/Pixtral-12B-2409",
messages=messages,
max_tokens=300
)
return completion.choices[0].message.content
Construindo a interface do Streamlit
Finalmente, criamos uma interface amigável com o Streamlit:
def main():
st.title("RAG MultiModal com Pixtral & Milvus")
# Inicializar o estado da sessão
if 'index' not in st.session_state:
st.session_state.index = None
st.session_state.retriever_engine = None
st.session_state.metadata = None
# Entrada de vídeo
video_path = st.text_input("Introduza o caminho do vídeo:")
if video_path and not st.session_state.index:
with st.spinner("Processing video..."):
# Processa o vídeo e cria um índice
[... código de processamento ...]
if st.session_state.index:
st.subheader("Conversar com o vídeo")
consulta = st.text_input("Fazer uma pergunta sobre o vídeo:")
if consulta:
com st.spinner("Gerando resposta..."):
# Gerar e apresentar a resposta
[... código de processamento da pergunta ...]
se __name__ == "__main__":
main()
Executando a aplicação
Antes de iniciar a aplicação, certifique-se de que tem:
- Configurado suas variáveis de ambiente em
.env - Instalou todas as dependências necessárias
Em seguida, inicie o aplicativo:
streamlit run app.py
Verá a página inicial onde pode:
- Carregar vídeos para processamento
- Fazer perguntas sobre o conteúdo do vídeo
- Ler as respostas de Pixtral com os quadros de vídeo pertinentes
 Figura - A interface da sua aplicação RAG multimodal construída com Milvus e Pixtral.png
Figura - A interface da sua aplicação RAG multimodal construída com Milvus e Pixtral.png
Figura: A interface da sua aplicação RAG multimodal criada com Milvus e Pixtral
A partir de agora, pode interagir com o vídeo e, por exemplo, aprender mais sobre a distribuição Gaussiana.
 Figura - Realização da pesquisa multimodal.png
Figura - Realização da pesquisa multimodal.png
Figura: Realização da pesquisa multimodal
Conclusão
Nesta postagem do blog, demonstramos como construir um poderoso sistema RAG multimodal usando Milvus, Pixtral e vLLM. Através da combinação das capacidades eficientes de armazenamento vetorial do Milvus e da compreensão multimodal avançada do Pixtral, criámos um sistema que pode processar, compreender e responder a consultas sobre conteúdos de vídeo. E este sistema está totalmente sob o seu controlo.
Gostaríamos de ouvir a sua opinião!
Se gostou deste post, por favor considere:
- ⭐ Dar-nos uma estrela no GitHub
- Juntar-se à nossa comunidade Milvus Discord para partilhar as suas experiências
- Explorar o nosso repositório Bootcamp para mais exemplos de aplicações multimodais com Milvus

Continue lendo

Stop Building AI Data Infra for the Wrong Stage
Learn how AI data infrastructure should evolve from prototype to enterprise scale, and when Vector Lakebase becomes the right architecture for AI apps.

Introducing Business Critical Plan: Enterprise-Grade Security and Compliance for Mission-Critical AI Applications
Discover Zilliz Cloud’s Business Critical Plan—offering advanced security, compliance, and uptime for mission-critical AI and vector database workloads.

Announcing the General Availability of Single Sign-On (SSO) on Zilliz Cloud
SSO is GA on Zilliz Cloud, delivering the enterprise-grade identity management capabilities your teams need to deploy vectorDB with confidence.