




ColPali: Recuperação melhorada de documentos com modelos de linguagem de visão e estratégia de incorporação ColBERT
A Retrieval Augmented Generation (RAG) é uma técnica que combina as capacidades dos modelos de linguagem de grande dimensão (LLMs com fontes de conhecimento externas para melhorar a precisão e a relevância das respostas. Uma aplicação comum do RAG é a extração de conteúdos de fontes como os PDF, uma vez que estes ficheiros contêm frequentemente dados valiosos mas são difíceis de pesquisar e indexar. A dificuldade reside no facto de informações importantes poderem ser ignoradas, dependendo da ferramenta utilizada para a extração. Por exemplo, o texto incorporado nas imagens pode não ser detectado durante a extração, tornando impossível a sua recuperação posterior.
ColPali, um modelo de recuperação de documentos, aborda esta questão com a sua nova arquitetura baseada em Modelos de Linguagem Visual (VLMs). Indexa documentos através das suas caraterísticas visuais, capturando elementos textuais e visuais. Ao gerar representações multi-vectoriais de texto e imagens ao estilo do ColBERT, o ColPali codifica imagens de documentos diretamente num espaço de incorporação unificado, eliminando a necessidade de extração e segmentação de texto tradicionais.
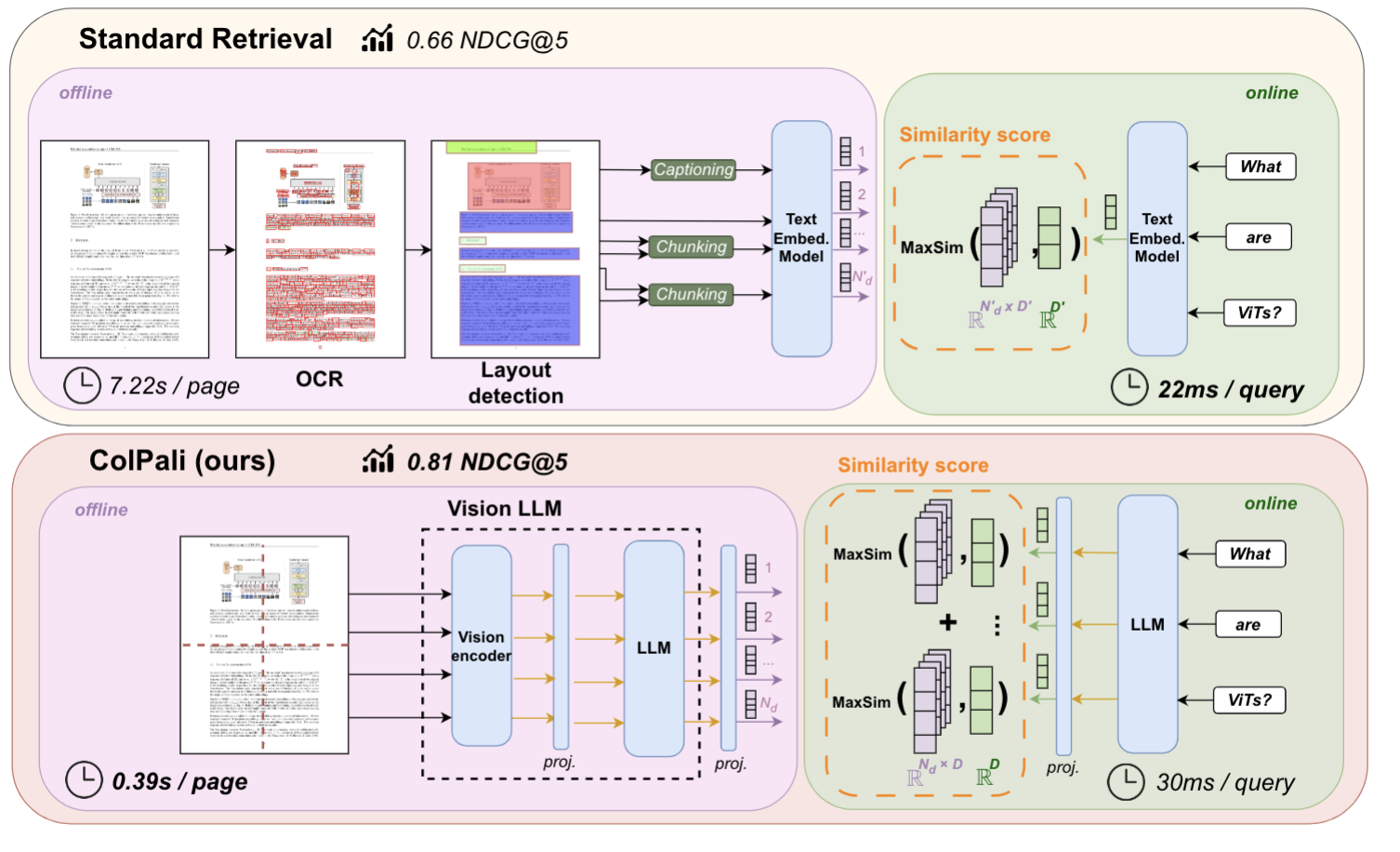 Figura: Pipeline de recuperação padrão vs. Pipeline ColPali para recuperação de PDF
Figura: Pipeline de recuperação padrão vs. Pipeline ColPali para recuperação de PDF
A imagem acima é do ColPali paper, onde os autores argumentam que um pipeline normal de recuperação de PDFs inclui normalmente várias etapas: extração de texto utilizando OCR, deteção de layout, chunking, e geração de embedding. O ColPali simplifica este processo utilizando um único modelo de visão linguística (VLM) que utiliza uma captura de ecrã da página como entrada.
A ColPali integra ferramentas que vão para além dos sistemas RAG tradicionais, pelo que é importante compreender primeiro alguns destes conceitos. Antes de discutir os detalhes de ColPali, vamos aprender modelos de linguagem de visão e modelos de interação tardia.
O que são modelos de linguagem de visão (VLMs)?
Os Modelos de linguagem de visão (VLMs) são [modelos multimodais] (https://zilliz.com/learn/top-10-best-multimodal-ai-models-you-should-know) que aprendem simultaneamente com imagens e texto. Recebem entradas de imagem e texto e geram saídas de texto e fazem parte da categoria mais alargada de modelos generativos.
 Exemplo de um VLM
Exemplo de um VLM
O ColPali aproveita os VLMs para alinhar os embeddings de tokens de texto e imagem adquiridos durante o ajuste fino multimodal. Especificamente, utiliza uma versão alargada do modelo PaliGemma-3B para produzir representações multi-vectoriais ColBERT-style. Os autores escolheram este modelo porque tem uma variedade de pontos de controlo ajustados para diferentes resoluções de imagem e tarefas, incluindo OCR para leitura de texto a partir de imagens.
O ColPali foi construído com base no modelo PaliGemma-3B da Google, que foi lançado com pesos abertos. Este modelo foi treinado utilizando um conjunto de dados diversificado - 63% de dados académicos e 37% de dados sintéticos de páginas PDF recolhidas na Web, melhorados com pseudo-perguntas geradas pelo VLM.
O que são modelos de interação tardios?
Os modelos [Late Interaction] (https://zilliz.com/learn/explore-colbert-token-level-embedding-and-ranking-model-for-similarity-search#The-Late-Interaction-Mechanism) são concebidos para tarefas de recuperação. Concentram-se na semelhança ao nível dos tokens entre documentos, em vez de utilizarem uma única representação vetorial. Ao representar o texto como uma série de token embeddings, estes modelos oferecem o detalhe e a precisão dos codificadores cruzados, ao mesmo tempo que beneficiam da eficiência do armazenamento de documentos offline.
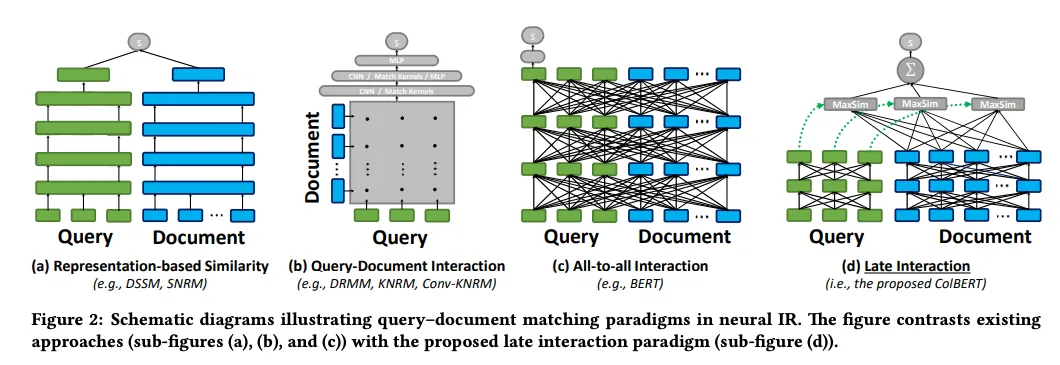 Figura 2: Diagramas esquemáticos que ilustram os paradigmas de correspondência consulta-documento na IR neural
Figura 2: Diagramas esquemáticos que ilustram os paradigmas de correspondência consulta-documento na IR neural
Figura 2: Diagramas esquemáticos que ilustram os paradigmas de correspondência consulta-documento na IR neural. | Fonte
Com esta compreensão dos Modelos de Interação Tardia e Modelos de Linguagem de Visão, podemos agora explorar o modo como o ColPali combina estes elementos para melhorar a recuperação de documentos.
O que é o ColPali e como funciona?
O ColPali é um modelo avançado de recuperação de documentos concebido para indexar e recuperar informações diretamente a partir das caraterísticas visuais dos documentos, em particular dos PDFs. Ao contrário dos métodos tradicionais que se baseiam no OCR (reconhecimento ótico de caracteres) e na segmentação de texto, o ColPali captura capturas de ecrã de cada página e incorpora páginas inteiras de documentos num espaço vetorial unificado utilizando VLMs. Esta abordagem permite ao ColPali contornar processos de extração complexos, melhorando a precisão e a eficiência da recuperação.
Abaixo estão os principais passos durante o seu fluxo de trabalho:
Processamento de documentos
- Criação de imagens a partir de PDFs: Em vez de extrair texto, criar pedaços e depois incorporá-los, o ColPali incorpora diretamente a captura de ecrã de uma página PDF numa representação vetorial. Este passo é como tirar uma fotografia de cada página em vez de tentar extrair o seu conteúdo.
- Dividir as imagens em grelhas**: Cada página é então dividida numa grelha de peças uniformes denominadas patches. Por predefinição, é dividida numa grelha de 32x32, resultando em 1024 fragmentos por imagem. Cada fragmento é representado como um vetor de 128 dimensões. Pode pensar nisto como uma imagem com 1024 "palavras" que descrevem esses fragmentos.
Geração de incorporação
- Processamento de manchas de imagem: O ColPali transforma estes patches visuais em embeddings através de um Vision Transformer (ViT), que processa cada patch para criar uma representação vetorial detalhada.
- Alinhamento de embeddings visuais e de texto**: Para fazer corresponder a informação visual com a consulta de pesquisa, o ColPali converte o texto da consulta em embeddings no mesmo espaço vetorial que as manchas de imagem. Este alinhamento permite ao modelo comparar e fazer corresponder diretamente conteúdos visuais e textuais.
- Processamento da consulta**: O modelo tokeniza a consulta, atribuindo a cada token um vetor de 128 dimensões. Utiliza pedidos como "Descreva esta imagem
" para garantir que o modelo se concentra nos elementos visuais, permitindo uma integração perfeita de texto e dados visuais.
Mecanismo de recuperação
O ColPali usa um mecanismo de similaridade de interação tardia para comparar a consulta e os embeddings de documentos no momento da consulta. Esta abordagem permite uma interação detalhada entre todos os vectores de células da grelha de imagens e os vectores de símbolos de texto da consulta, garantindo uma comparação abrangente.
A semelhança é calculada utilizando uma abordagem de "soma das semelhanças máximas":
- Calcular as pontuações de semelhança entre cada símbolo de consulta e cada símbolo de correção na imagem.
- Agregar estas pontuações para gerar uma pontuação de relevância para cada documento.
- Ordenar os documentos pela pontuação em ordem decrescente, usando a pontuação como uma medida de relevância.
Este método permite que o ColPali faça corresponder eficazmente as consultas dos utilizadores aos documentos relevantes, concentrando-se nos fragmentos de imagem que melhor se alinham com o texto da consulta. Ao fazê-lo, destaca as partes mais relevantes do documento, combinando conteúdo textual e visual para uma recuperação precisa.
Processo de treinamento do modelo
O ColPali é construído sobre o modelo PaliGemma-3B, um modelo de linguagem de visão desenvolvido pelo Google. Na sua implementação, ColPali mantém os pesos do modelo congelados durante o treinamento para reter o conhecimento pré-treinado do VLM enquanto se concentra na otimização para tarefas de recuperação de documentos.
A chave para adaptar este VLM de uso geral para a recuperação de documentos está num componente pequeno mas crucial: **Este adaptador é colocado por cima do modelo PaliGemma-3B e é treinado para aprender representações adaptadas às tarefas de recuperação.
O processo de formação deste adaptador utiliza uma abordagem de aprendizagem tripla:
- Uma consulta de texto
- Uma imagem de uma página relevante para a consulta
- Uma imagem de uma página irrelevante para a consulta
Este método permite que o modelo aprenda distinções precisas entre conteúdo relevante e irrelevante, aumentando a sua precisão de recuperação.
Vantagens do ColPali
- Eliminação de pré-processamento complexo**: O ColPali substitui o pipeline tradicional de extração de texto, OCR, deteção de layout e fragmentação por um único VLM que utiliza uma captura de ecrã da página como entrada.
- Captura de informações visuais e textuais**: Ao trabalhar diretamente com imagens de páginas, o ColPali pode incorporar tanto o conteúdo textual como a disposição visual na sua compreensão dos documentos.
- Recuperação eficiente de documentos visualmente ricos**: O mecanismo de interação tardia permite uma correspondência fina entre as consultas e o conteúdo do documento, possibilitando a recuperação eficiente de informações relevantes de documentos complexos e visualmente ricos.
- Preservação do contexto: Ao operar em imagens de páginas inteiras, o ColPali mantém o contexto completo do documento, que pode ser perdido nas abordagens tradicionais de fragmentação de texto.
Desafios do ColPali
Tal como acontece com qualquer sistema de recuperação em grande escala, o ColPali enfrenta desafios significativos em termos de complexidade computacional e requisitos de armazenamento.
Complexidade computacional: Os requisitos de computação do ColPali crescem quadraticamente com o número de tokens de consulta e vectores de correção. Isto significa que, à medida que a complexidade das consultas ou a resolução das imagens dos documentos aumenta, a procura computacional cresce rapidamente.
Requisitos de armazenamento: O custo de armazenamento das abordagens do tipo ColBERT é 10x a 100x superior ao da incorporação de vectores densos, uma vez que requer um vetor para cada token. As necessidades de armazenamento do sistema aumentam linearmente com três factores:
Número de documentos
Número de patches por documento
Dimensionalidade das representações vectoriais.
Este escalonamento pode levar a requisitos de armazenamento substanciais para grandes colecções de documentos.
Estratégia de otimização - Redução da precisão
Para resolver esses desafios de escalonamento, sugerimos o uso da estratégia de redução de precisão.
- Redução de precisão: Passar de representações de maior precisão (por exemplo, floats de 32 bits) para formatos de menor precisão (por exemplo, números inteiros de 8 bits) pode reduzir drasticamente os requisitos de armazenamento com um impacto mínimo na qualidade da recuperação.
Resumo
O ColPali tem um potencial significativo para transformar a forma como recuperamos conteúdo visualmente rico com contexto textual em sistemas RAG. Ao tirar partido dos modelos de linguagem visual, permite a recuperação de documentos com base não só no texto, mas também em elementos visuais.
No entanto, apesar dos seus resultados impressionantes, o ColPali enfrenta desafios devido às suas elevadas exigências de armazenamento e complexidade computacional, o que pode impedir a sua adoção generalizada. Futuras optimizações poderão resolver estas limitações, tornando-o mais prático. medida que os métodos RAG continuam a desenvolver-se, métodos de recuperação como o ColPali, que integram a compreensão visual e textual, são susceptíveis de desempenhar um papel cada vez mais importante na [recuperação de informação] (https://zilliz.com/learn/what-is-information-retrieval) em diversos tipos de documentos.
Gostaríamos de saber a sua opinião!
Se gostou desta publicação no blogue, agradecíamos que nos desse uma estrela no GitHub! Também é bem-vindo a juntar-se à nossa comunidade Milvus no Discord para partilhar as suas experiências. Se estiver interessado em saber mais, consulte o nosso Bootcamp repository no GitHub ou os nossos notebooks. Também gostaríamos de saber se está a planear experimentar o ColPali no futuro!
Leitura adicional
- Papel de ColPali: [2407.01449] ColPali: Efficient Document Retrieval with Vision Language Models
- ColPali GitHub: https://github.com/illuin-tech/colpali
- ColBERT: Um modelo de classificação e incorporação ao nível dos tokens
- ColPali: Recuperação de documentos com modelos de linguagem de visão
- O que é RAG?
- O que são bases de dados vectoriais e como funcionam?

Continue lendo

How to Improve Retrieval Quality for Japanese Text with Sudachi, Milvus/Zilliz, and AWS Bedrock
Learn how Sudachi normalization and Milvus/Zilliz hybrid search improve Japanese RAG accuracy with BM25 + vector fusion, AWS Bedrock embeddings, and practical code examples.

Zilliz Cloud Now Available in Azure North Europe: Bringing AI-Powered Vector Search Closer to European Customers
The addition of the Azure North Europe (Ireland) region further expands our global footprint to better serve our European customers.

Vector Databases vs. Document Databases
Use a vector database for similarity search and AI-powered applications; use a document database for flexible schema and JSON-like data storage.