




Como escolher o modo de implementação Milvus adequado para as suas aplicações de IA
A Milvus é uma base de dados de vectores de código aberto que armazena, indexa e recupera vetor embeddings à escala de mil milhões. É também um componente indispensável da geração aumentada de recuperação (RAG), uma técnica popular e eficaz para atenuar os problemas de alucinação em modelos de linguagem de grande dimensão (LLMs).
Ao contrário de outros projectos de pesquisa vetorial de código aberto, como Qdrant, Weaviate e Chroma, o Milvus oferece aos programadores três grandes opções de implementação para diferentes tamanhos de conjuntos de dados, casos de utilização e requisitos comerciais. Embora ter várias opções seja um benefício, também pode ser um pouco esmagador. Muitos desenvolvedores não têm certeza de como selecionar o melhor modo de implantação para seus aplicativos de IA específicos. Nesta postagem do blog, forneceremos um guia claro e detalhado para ajudá-lo a escolher a versão correta do Milvus para seus projetos.
Milvus Lite vs. Autónomo vs. Distribuído
Milvus oferece três opções de implementação: Milvus Lite, Standalone e Distributed.
Milvus Lite
Milvus Lite é uma biblioteca Python e uma versão ultra-leve do Milvus. É perfeita para prototipagem rápida em ambientes Python ou notebook e para experiências locais de pequena escala. Você pode instalá-la diretamente através do pacote pymilvus com uma simples linha de pip install pymilvus. Não há necessidade de executar um servidor separado, e ele lida com a persistência de dados usando arquivos locais, tornando-o fácil de configurar e usar.
Milvus Standalone
Milvus Standalone é a opção de implantação de nó único para Milvus, usando um modelo cliente-servidor. Você pode pensar nele como o equivalente Milvus do MySQL, enquanto o Milvus Lite é como o SQLite. Todos os componentes do Milvus Standalone vêm empacotados em uma imagem Docker, tornando a implantação do servidor simples. Executar uma única instância do Milvus Standalone em uma máquina com memória suficiente funcionará bem para a maioria dos projetos que não requerem escalonamento extensivo. Além disso, o Milvus Standalone oferece alta disponibilidade com um modo de backup primário, tornando-o uma escolha confiável para ambientes de produção.
Milvus Distribuído
O Milvus Distributed é o modo distribuído do Milvus, ideal para utilizadores empresariais que criam sistemas de bases de dados vetoriais em grande escala ou plataformas de dados vetoriais. Adota uma arquitetura nativa da nuvem com separação de leitura e escrita para otimizar o desempenho. Os principais componentes do Milvus Distributed estão equipados com cópias de segurança incorporadas e instâncias adicionais, pelo que, se uma parte falhar, outras podem assumir o controlo sem problemas, garantindo que o sistema permanece ininterrupto. Este nível de redundância aumenta a fiabilidade e garante [disponibilidade contínua] (https://zilliz.com/learn/ensuring-high-availability-of-vetor-databases). Das três opções de implementação, o Milvus Distributed oferece a maior escalabilidade e disponibilidade. Também fornece elasticidade ao nível dos componentes, permitindo-lhe escalar independentemente o Proxy, os nós de consulta e os nós de índice com base nos seus requisitos específicos de carga comercial.
A tabela abaixo resume e compara os principais recursos do Milvus Lite, Milvus Standalone e Milvus Distributed.
| Milvus Lite** | Milvus Standalone** | Milvus Distributed** | Capabilities | Python |
| Python | Python, Go, Java, Node.js, C#, RESTful | Python, Go, Java, Node.js, C#, RESTful | ||
| Vetores densos Vetores esparsos Vetores binários Vetores booleanos Escalares inteiros Escalares inteiros Escalares flutuantes Strings Arrays JSON Vetores densos Vetores esparsos Vetores binários Escalares booleanos Escalares inteiros Escalares flutuantes Strings Arrays JSON Vetores densos Vetores esparsos Vetores binários Escalares booleanos Escalares inteiros Escalares flutuantes Strings Arrays JSON | ||||
| Pesquisa vetorial (ANN search)Pesquisa vetorial filtrada Pesquisa por intervalo Pesquisa híbrida Consulta de expressão escalar Consulta de chave primária (get) | Pesquisa vetorial (ANN search)Pesquisa vetorial filtrada Pesquisa por intervalo Pesquisa híbrida Consulta de expressão escalar Consulta de chave primária (get) | Pesquisa vetorial (ANN search)Pesquisa vetorial filtrada Pesquisa por intervalo Pesquisa híbrida Consulta de expressão escalar Consulta de chave primária (get) | ||
| Capacidades básicas de CRUD | ✔️ | ✔️ | ✔️ | ✔️ |
| RBAC (controlo de acesso baseado em funções) | RBAC (controlo de acesso baseado em funções) Sharding Partição Chave de partição Agrupamento de recursos físicos | |||
| Consistência** | Forte | Forte Sessão de indisponibilidade limitada Eventualmente | Sessão de indisponibilidade limitada Forte Eventualmente |
Tabela: Comparação entre Milvus Lite, Milvus Standalone e Milvus Distributed_
Como selecionar a implantação correta do Milvus para cada estágio de desenvolvimento
A escolha da opção apropriada de implantação do Milvus depende do estágio de desenvolvimento do seu aplicativo. Esses estágios incluem Prototipagem rápida, Empreendimento de produção inicial e Empreendimento de produção em larga escala. Vamos explorar cada estágio em detalhes.
Milvus Lite para prototipagem rápida de aplicações de IA
Ao desenvolver e prototipar aplicações de IA como um assistente pessoal, um motor de pesquisa semântica, ou um RAG end-to-end, a velocidade e flexibilidade da aplicação são normalmente priorizadas em relação ao desempenho e estabilidade. Por conseguinte, o Milvus Lite é a escolha ideal nesta fase. Permite-lhe criar rapidamente uma funcionalidade de ponta a ponta num ambiente de notebook e realizar experiências ligeiras centradas no teste da eficácia.
Transição para o Milvus Standalone para validação em grandes conjuntos de dados
O Milvus Standalone é o próximo passo lógico se precisar de validar os seus resultados num grande conjunto de dados. O Milvus Lite e o Standalone foram concebidos para trabalhar em conjunto, oferecendo uma transição fácil da prototipagem local para a validação baseada no servidor. Uma vez que o Milvus Lite, Standalone e Distributed partilham a mesma interface de cliente, é possível reutilizar a mesma lógica de negócio para validações de dados locais e em grande escala. Adicionalmente, o Milvus Standalone suporta múltiplos utilizadores, tornando mais fácil para as equipas de desenvolvimento ágil colaborar ou partilhar dados utilizando uma única instância.
Milvus Standalone para implantação de produção inicial
Nas fases iniciais da produção de aplicações, quando o seu projeto é recém-lançado e ainda está a encontrar a sua adequação ao mercado do produto, os pedidos comerciais e os volumes de dados são relativamente baixos. A atenção deve centrar-se na eficácia e competitividade da empresa e não na infraestrutura. O Milvus Standalone é adequado para esta fase. Para os serviços online, a implementação do Milvus num modo de backup primário de alta disponibilidade garante a fiabilidade. Para ambientes de teste, uma implantação de um único nó é geralmente suficiente.
Nota: O Milvus Standalone não oferece isolamento de recursos físicos entre tabelas. Se você tiver dois aplicativos críticos e sensíveis ao desempenho, é melhor isolar seus dados usando instâncias separadas do Milvus Standalone. Embora isso possa levar a alguma ineficiência de recursos, continua a ser mais económico do que gerir uma configuração Milvus Distributed nesta fase.
Você pode continuar a usar o Milvus Lite para tarefas específicas de depuração, mas evite fazê-lo no ambiente de produção onde o Milvus Standalone está implantado, pois isso poderia introduzir riscos de desempenho e estabilidade.
Milvus Distributed para implantação de produção em larga escala
Quando os seus dados ultrapassam a capacidade de um único servidor ou estão a expandir-se rapidamente, é altura de se preparar para a escalabilidade futura. O Milvus Distributed torna-se essencial nesta fase.
Esta prática recomendada envolve a execução de instâncias do Milvus Standalone e do Milvus Distributed simultaneamente no início e a transferência gradual do tráfego de dados do Standalone para o Distributed. Certifique-se de que monitoriza o sistema durante pelo menos um mês até que o Milvus Distributed funcione de forma estável.
Durante esta fase, também terá de melhorar a sua gestão de operações. O Milvus Distributed suporta nativamente o Prometheus e oferece ferramentas de gerenciamento como Attu. Embora o Milvus forneça uma ampla gama de ferramentas operacionais dedicadas e integrações de ecossistema, a gestão de um grande sistema distribuído pode ser um desafio. Encorajamo-lo a juntar-se à aberta e ativa comunidade Milvus para pedir apoio, contribuir com código, participar em eventos e fazer muitas outras contribuições valiosas.
Como escolher a implantação certa para seus conjuntos de dados vetoriais
O Milvus foi concebido para escalar com o seu projeto, oferecendo diferentes modos de implementação para corresponder às exigências evolutivas do seu conjunto de dados. Para clarificar as suas diferenças, vamos analisar como o Milvus Lite, Standalone e Distributed se comparam entre si e, mais importante, com outras bases de dados vectoriais de código aberto no mercado, como o Chroma, Weaviate, e Qdrant.
A Chroma tem ganho força entre os programadores desde o ano passado, especialmente para projectos de pequena escala. Tal como o Milvus Lite, o Chroma é uma base de dados vetorial leve. É mais adequado para aplicações que lidam com menos de centenas de milhares de vectores. O Chroma oferece funcionalidades básicas, como a inserção de dados vectoriais e a pesquisa de semelhanças, o que o torna uma opção leve para a criação rápida de protótipos. No entanto, o seu conjunto limitado de funcionalidades e a falta de preparação para a produção significam que até o Milvus Lite oferece capacidades mais robustas.
Para soluções prontas para produção, Milvus Standalone e Distributed, juntamente com Weaviate e Qdrant, são escolhas mais fortes. A Weaviate é conhecida pela sua integração com aplicações de IA, fornecendo suporte nativo para vários modelos a montante. O Qdrant, por outro lado, centra-se nas principais funcionalidades da base de dados vetorial, com ênfase no desempenho da pesquisa vetorial. No entanto, de acordo com o VectorDBBench, uma ferramenta de benchmarking de bases de dados vectoriais de código aberto, o Milvus continua a superar o Qdrant em desempenho de pesquisa, tornando-o um dos principais concorrentes neste espaço.
Eis uma análise das escalas de dados adequadas para cada base de dados vetorial:
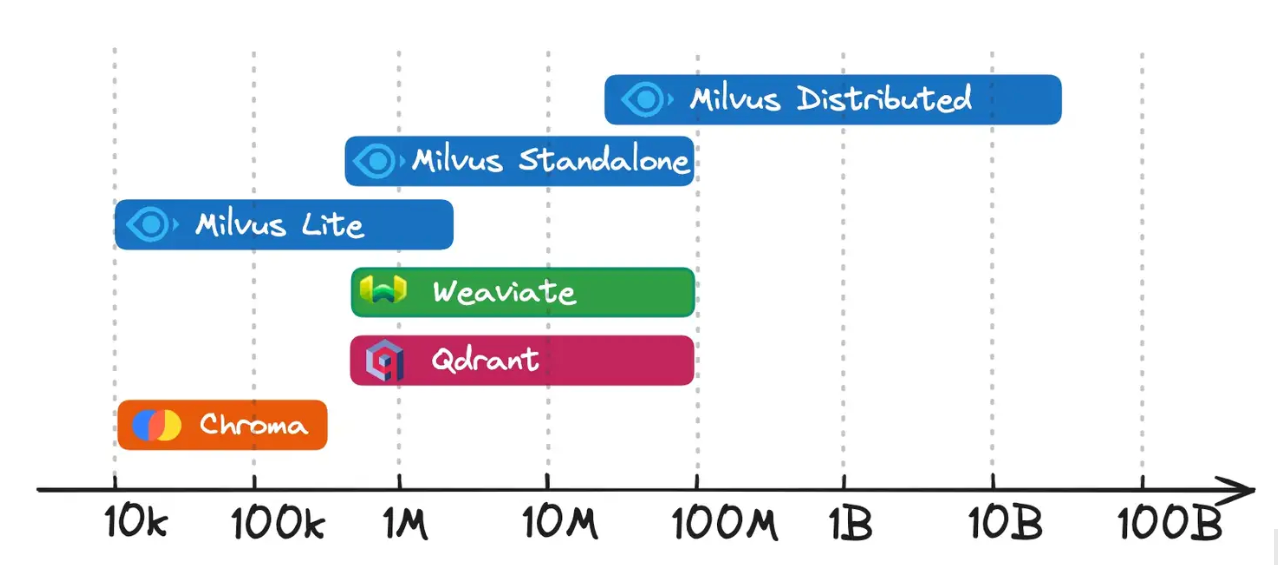 Figura 2- Milvus vs. Chroma vs. Qdrant vs. Weaviate para armazenamento e recuperação de vectores
Figura 2- Milvus vs. Chroma vs. Qdrant vs. Weaviate para armazenamento e recuperação de vectores
Milvus Lite e Chroma são ideais para escalas de dados até um milhão de vectores. Foram concebidos para serem fáceis de utilizar, sacrificando algumas capacidades do sistema em prol da simplicidade.
Milvus Standalone, Weaviate e Qdrant**: Melhores para escalas de dados que vão de um milhão a dezenas de milhões de vectores. Estas bases de dados atingem um equilíbrio entre as poderosas capacidades do sistema e a facilidade de utilização, tornando-as adequadas para a produção em fase inicial.
Milvus Distribuído**: Concebida para lidar com escalas de dados de dezenas de milhões e mais_. A comunidade Milvus validou o seu suporte para casos de utilização à escala de milhares de milhões, e está agora a ser implementado para situações que envolvem dezenas de milhares de milhões de vectores.
Embora outras bases de dados vectoriais como Chroma, Weaviate e Qdrant tenham os seus pontos fortes, muitas vezes não conseguem oferecer o mesmo nível de flexibilidade, escalabilidade e suporte a longo prazo que o Milvus proporciona. À medida que o seu projeto cresce, a mudança de bases de dados vectoriais pode tornar-se dispendiosa e complexa. O Milvus, com as suas opções de implementação versáteis, suporta fluxos de trabalho mistos em várias escalas de dados, assegurando que a sua solução de base de dados não fica ultrapassada.
Componentes subjacentes do Milvus Lite, autónomo e distribuído
O Milvus oferece uma experiência de utilizador consistente e uma evolução uniforme nos seus três modos de implementação graças aos componentes subjacentes partilhados. Este design garante que beneficia da mesma funcionalidade central, quer esteja a utilizar o Milvus Lite para tarefas ligeiras ou o Milvus Distributed para operações de grande escala.
O diagrama abaixo ilustra os componentes funcionais cobertos por cada um desses modos de implantação do Milvus:
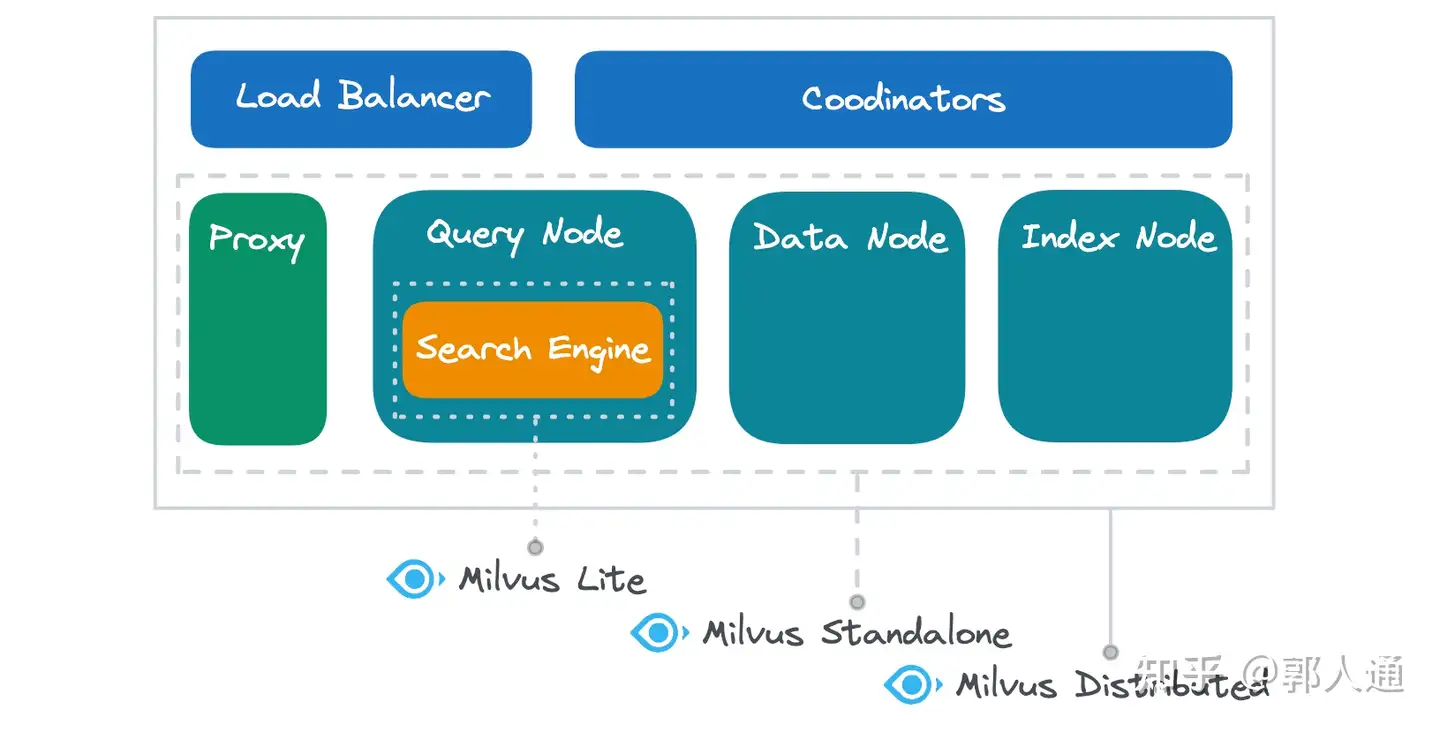 Figura 2- Milvus Lite vs. Standalone vs. Distributed em componentes subjacentes
Figura 2- Milvus Lite vs. Standalone vs. Distributed em componentes subjacentes
O Milvus Lite encapsula principalmente o motor de pesquisa, oferecendo também implementações locais para tarefas essenciais como a inserção de dados, a persistência, a criação de índices e a gestão de metadados. Pense no Milvus Lite como uma biblioteca poderosa em vez de uma simples ferramenta. Em comparação com bibliotecas mais básicas como a Chroma, o motor de busca do Milvus Lite oferece um desempenho e capacidades de consulta superiores, tornando-o ideal para incorporações vectoriais. Se procura uma alternativa à FAISS ou à HNSWLib, a Milvus Lite é uma forte candidata, uma vez que integra nativamente as principais bibliotecas de algoritmos vetor search e foi submetida a uma extensa otimização, tanto em termos de desempenho como de funcionalidade.
O Milvus Standalone inclui todos os componentes funcionais do sistema Milvus, exceto o balanceamento de carga e a gestão de vários nós (coordenadores). Esses componentes operam no mesmo ambiente Docker, facilitando a comunicação local eficiente e minimizando a latência do servidor.
O Milvus Distributed possui uma gama completa de componentes funcionais. Enquanto os modos Standalone e Distributed contêm um Proxy, Query Node, Data Node e Index Node com funcionalidades idênticas, o Milvus Distributed oferece uma maior flexibilidade de implementação. Cada componente funcional pode ser implementado várias vezes para lidar com cargas mais elevadas, e vários componentes podem ser implementados no mesmo nó físico para partilhar recursos ou em nós diferentes para garantir o isolamento de recursos. Além disso, o modo Distribuído permite o escalonamento independente de cada componente, permitindo-lhe adaptar-se a caraterísticas de carga variáveis e melhorar a utilização de recursos de forma eficaz.
Resumo
Neste post, exploramos as três opções de implantação que o Milvus oferece: Milvus Lite, Standalone e Distributed. Cada modo de implantação é adaptado para atender a diferentes estágios de desenvolvimento, tamanhos de dados e [casos de uso] (https://zilliz.com/vetor-database-use-cases), garantindo que o Milvus possa escalar junto com seu projeto.
O Milvus Lite** é ideal para prototipagem rápida e experiências de pequena escala em ambientes Python. É fácil de configurar e utilizar, o que o torna perfeito para os programadores que necessitam de uma solução leve mas poderosa para testes e desenvolvimento.
O Milvus Standalone** é o próximo passo para aqueles que estão prontos para passar da prototipagem para a produção. Esta opção de implementação de nó único fornece todos os componentes necessários para ambientes de produção iniciais, equilibrando o desempenho e a eficiência de recursos. É adequada para projectos com tamanhos de dados moderados e exigências crescentes dos utilizadores.
O Milvus Distributed** foi concebido para implementações de produção em grande escala que requerem elevada disponibilidade, escalabilidade e flexibilidade. É a escolha ideal para empresas e aplicações que lidam com grandes quantidades de dados, garantindo que a sua base de dados vetorial pode crescer com as suas necessidades comerciais.
Recursos adicionais
O que é Retrieval Augmented Generation (RAG)](https://zilliz.com/learn/Retrieval-Augmented-Generation)
Modelos de IA com melhor desempenho para as suas aplicações GenAI | Zilliz

Continue lendo

Zilliz Cloud Now Available in AWS Asia Pacific (Seoul)
Zilliz Cloud is now available in AWS Seoul — low-latency vector search, in-country data residency, and one-step migration for Korean AI teams. 31 regions across 5 clouds.

Data Deduplication at Trillion Scale: How to Solve the Biggest Bottleneck of LLM Training
Explore how MinHash LSH and Milvus handle data deduplication at the trillion-scale level, solving key bottlenecks in LLM training for improved AI model performance.

Zilliz Named "Highest Performer" and "Easiest to Use" in G2's Summer 2025 Grid® Report for Vector Databases
Zilliz shines in G2's Summer 2025 Grid® Report as both "Highest Performer" and "Easiest to Use," solving the performance-usability dilemma.