




질리즈 x 컨플루언트: 환각 없이 실시간 RAG 애플리케이션 구축하기
Kafka는 애플리케이션이 데이터 스트림을 효율적으로 게시(쓰기)하고 구독(읽기)할 수 있게 해주는 오픈 소스 실시간 데이터 스트리밍 플랫폼이자 메시지 브로커입니다. 개발자는 Kafka를 사용하여 벡터 데이터베이스에 공급할 수 있는 확장 가능하고 내결함성 있는 데이터 파이프라인을 구축하여 검색 증강 생성(RAG) 애플리케이션을 향상시킬 수 있습니다. Confluent는 이벤트 기반 애플리케이션과 스트리밍 데이터 아키텍처에 대한 사용을 간소화하기 위해 Kafka를 중심으로 구축된 상용 솔루션과 도구를 제공하는 회사입니다.
생성적 AI(LLM, 확산 모델, GAN 등)는 다양한 산업과 업종에 광범위하게 적용될 수 있습니다. RAG를 통해 이러한 모델에 도메인 데이터를 주입하는 것은 애플리케이션 수준에서 점점 더 보편화되고 있습니다. CVP (ChatGPT, 벡터 데이터베이스, 프롬프트) 프레임워크는 벡터 데이터베이스를 활용하여 시맨틱 검색을 수행하는 자주 사용되는 RAG의 인스턴스화입니다.
Confluent 통합은 질리즈 클라우드(호스팅 밀버스) 및 Confluent Kafka를 활용하여 데이터의 실시간 수집, 구문 분석 및 처리를 수행하여 사용자 경험을 향상시키는 데 도움이 되는 최신의 맥락 관련 정보를 제공함으로써 대규모 언어 모델(LLM)의 환상을 줄입니다.
챗봇, 실시간 감성 분석, 고객 지원 등 이 통합의 이점을 누릴 수 있는 사용 사례는 무수히 많습니다.
GenAI 외에도 이 통합을 사용하여 실시간 추천 시스템을 구축하고, 이상 징후를 감지하고, 실시간 AI의 이점을 활용할 수 있는 다양한 애플리케이션을 개발할 수도 있습니다.
Confluent와 Zilliz Cloud 통합의 작동 방식
통합 작동 방식
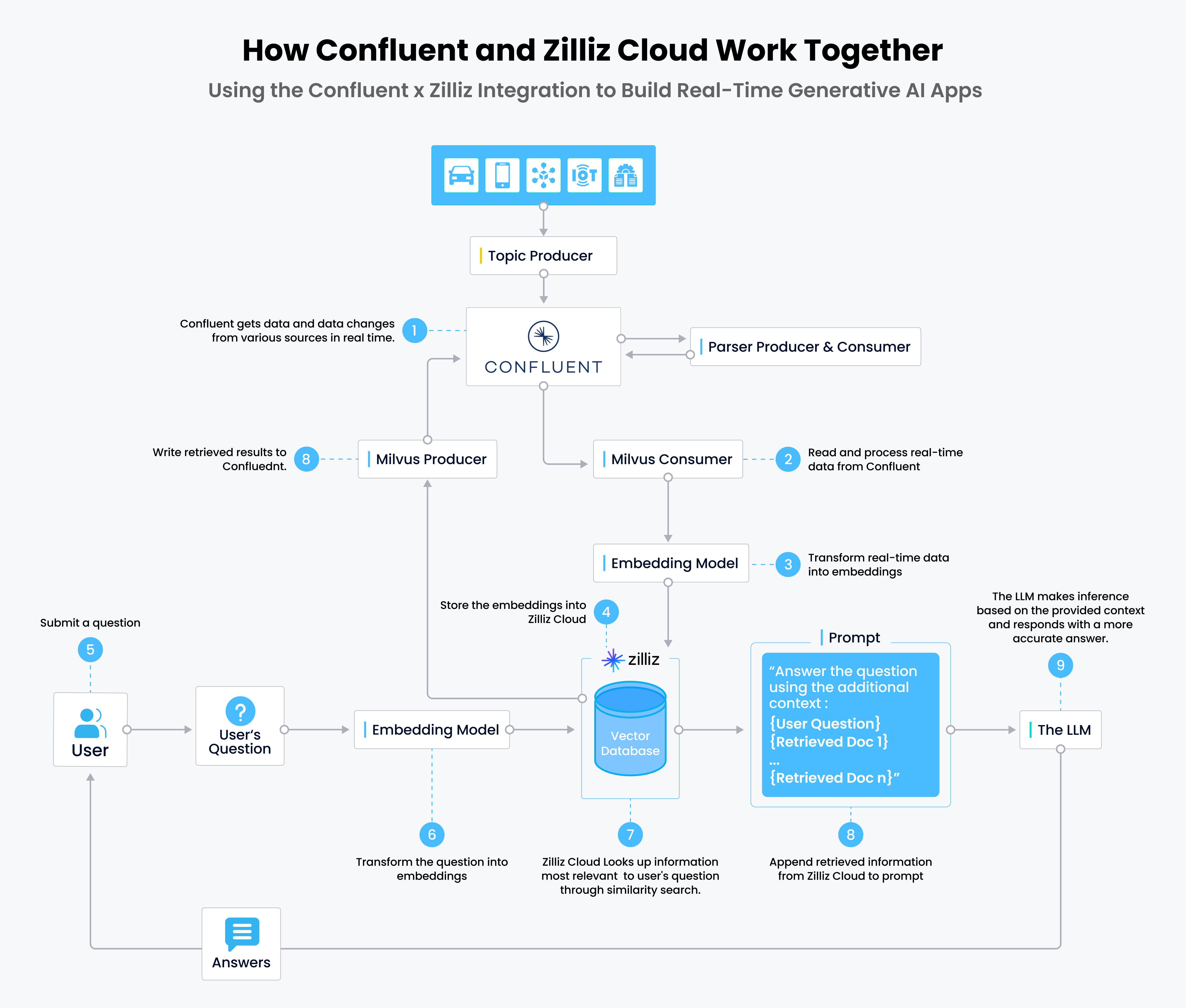
- 토픽 프로듀서를 통해 실시간 데이터가 Confluent에 기록되고, 이 데이터는 파싱되어 다시 Confluent로 전송됩니다.
- 밀버스 소비자는 Confluent에서 실시간 데이터를 읽고 처리합니다.
- 실시간 데이터는 임베딩 모델을 통해 벡터 임베딩으로 변환됩니다.
- 벡터 임베딩은 질리즈 클라우드에 저장됩니다.
- 사용자가 챗봇(또는 RAG 앱)에 질문을 제출합니다.
- 질문이 벡터 임베딩으로 변환되어 질의에 응답합니다.
- 질리즈 클라우드가 유사도 검색을 통해 질문과 가장 연관성이 높은 상위 k개의 결과를 찾아냅니다.
- 질리즈 클라우드에서 검색된 결과를 프롬프트에 추가하여 LLM으로 전송합니다.
- LLM은 답변을 생성하여 챗봇을 통해 사용자에게 전송합니다.
방법 알아보기
이 튜토리얼을 확인하여 Confluent 통합 사용 방법을 알아보세요.