




FARFETCH의 대화형 AI 최적화

15x
더 빠른 인덱싱 시간
5x
쿼리 시간 단축
전환율 향상
보다 관련성 높은 제품 추천을 통해
여러 메트릭 유형
다양한 사용 사례를 지원하기 위해
Milvus consistently outperformed Weaviate, emphasizing the indexing time for scenario S9, closely resembling the FARFETCH product catalog's dimensions.
PEDRO MOREIRA COSTA
파페치 소개
온라인 패션 리테일의 선두주자인 FARFETCH는 최신 혁신 기술인 iFetch를 통해 디지털 쇼핑의 경계를 넓히고 있습니다. 이 대화형 AI 시스템은 일반적으로 고급 오프라인 매장에서 볼 수 있는 개인화된 고급 서비스를 디지털 영역으로 가져올 수 있도록 설계되었습니다. 이 이니셔티브의 일환으로 아이페치 채팅 R&D는 특화된 대화형 추천 시스템을 개발하고 있습니다. iFetch에 통합된 이 챗봇을 통해 사용자는 자연어와 이미지를 통해 FARFETCH 제품 카탈로그와 상호작용할 수 있습니다. 예를 들어 사용자가 마음에 드는 재킷 사진을 업로드하면 챗봇이 비슷한 재킷을 엄선하여 추천해 줍니다. 사용자 경험에 중점을 둔 고급 AI 기술을 완벽하게 결합함으로써 FARFETCH는 고객이 온라인 쇼핑에서 기대할 수 있는 것을 재정의하는 것을 목표로 합니다.
파페치 채팅에서 유사한 쇼케이스 보기](https://assets.zilliz.com/FARFETCH_Chat_show_similar_showcase_4d268c1bc0.jpg)
하지만 메타데이터가 제한적인 기존 제품 카탈로그는 광범위한 제품들의 복잡한 관계와 미묘한 속성을 포착하는 데 어려움을 겪었습니다. 이 문제를 해결하기 위해 머신 러닝 알고리즘을 사용하여 AI 시스템의 강력한 언어 역할을 하는 고차원 데이터 포인트인 제품 임베딩을 개발했습니다. 이를 통해 챗봇은 전례 없는 정확도로 제품을 이해하고 추천할 수 있게 되었습니다. 하지만 이러한 임베딩을 실시간으로 저장하고 검색하는 데는 또 다른 장애물이 있었으며, 고차원 데이터를 효율적으로 처리할 수 있는 전문 스토리지 솔루션이 필요했습니다.
벡터 데이터베이스의 중요성 ## 벡터 데이터베이스의 중요성
벡터 유사성 엔진(VSE)이라고도 하는 벡터 데이터베이스는 벡터 임베딩이라는 복잡한 고차원 데이터를 처리하도록 설계된 특수 데이터베이스입니다. 이러한 데이터베이스는 빠르고 정확한 데이터 검색을 위해 필수적인 근사 이웃(ANN) 알고리즘을 사용합니다. 이 기능은 즉각적인 제품 추천을 제공하고 고객의 질문에 답변하기 위해 실시간 고객 상호 작용이 필요한 iFetch에 특히 중요합니다. 벡터 데이터베이스의 선택은 단순한 기술적인 문제가 아니라 iFetch의 성능, 견고성, 효율성에 직접적인 영향을 미치는 전략적 결정입니다. 이들은 가장 적합한 VSE를 선택하기 위해 포괄적인 벤치마킹 연구를 수행했습니다. 이 벤치마크에는 인덱싱 속도, 쿼리 속도, 확장성 등 다양한 기준에 따라 Vespa, Milvus, Qdrant, Weaviate, Vald, Pinecone을 비롯한 다양한 데이터베이스를 평가하는 작업이 포함되었습니다. 벤치마킹에는 각 VSE가 최대 부하에서 어떻게 작동하는지 평가하는 스트레스 테스트와 복원력을 평가하기 위한 장애 조치 및 복구 시나리오도 포함되었습니다.
벡터 유사성 시어크가 적용된 iFetch 시스템 아키텍처의 전체적인 모습](https://assets.zilliz.com/Holistic_representation_of_the_i_Fetch_system_architecture_with_Vector_Similarity_Search_10948cc2e7.png)
벤치마크 기준 및 선택
Farfetch 팀이 수행한 벤치마킹 프로세스는 철저하고 체계적으로 진행되었으며, iFetch의 장기적인 성공에 중요한 다양한 요소들을 포괄했습니다. 여기에는 인덱스 유형, 메트릭 유형, 모델 서비스 기능, 커뮤니티 채택의 다양성 등이 포함되었습니다. 또한 구현의 용이성과 지속적인 유지 관리에 영향을 미칠 수 있는 문서의 품질과 지원의 가용성도 고려했습니다.
| 기능 | Qdrant | Milvus | Weaviate | Vespa | Vald | Pinecone | ||||
|---|---|---|---|---|---|---|---|---|---|---|
| 일관성 모델 | 해당 없음 | 강력한 일관성 | 최종 일관성 | 최종 일관성 | 해당 없음 | 최종 일관성 | 해당 없음 | 최종 일관성 | ||
| 그래프QL 지원 | N/A | N/A | 예 | N/A | N/A | N/A | N/A | N/A | N/A | N/A |
| 샤딩 | 아니요(해결 예정 날짜 미정) | 예 | 예 | 예 | N/A | N/A | N/A | |||
| 페이지 매김 | 아니요(2022.3 버전 2.2에서 예상됨) | 예 | 예 | 예 | 아니요 | 아니요 | 아니요 | 아니요 | ||
| 메트릭 유형 | 내적 곱 코사인 유사도 유클리드(L2) | L2 내적 곱 해밍 자카드 타니모토 상부 구조 하부 구조 | 코사인 | 유클리드 각도 내적 곱 방위각 해밍 | L1 L2 각도 해밍 코사인 정규화 각도 정규화 코사인 Jaccard | 유클리드 코사인 내적 곱 | ||||
| 최대 벡터 차원 | N/A | N/A | 32 768 | N/A | max.MaxInt64 | N/A | ||||
| 최대 인덱스 크기 | N/A | N/A | 무제한 | N/A | N/A | N/A | N/A | N/A | N/A | |
| 인덱스 유형 | HNSW | ANNOY HNSW IVF_PQ IVF_SQ8 IVF_FLAT FLAT IVF_SQ8_H RNSG | NHSW | HNSW BM25 | N/A | 독점적 | ||||
| 제공 모델 | N/A | N/A | text2vec-contextionary Weaviate의 자체 언어 벡터화기; fastText 및 GloVe와 같은 인기 모델에서 작동하는 WMOWE(Weighted Mean of Word Embeddings) 벡터화기 모듈입니다. 가장 최근의 text2vec - 문맥은 Wiki 및 CommonCrawl 데이터의 fastText를 사용하여 학습됩니다. text2vec- transformers 트랜스포머 모델은 사용 사례에 맞게 미리 훈련된 NLP 모듈을 연결할 수 있다는 점에서 문맥형과 다릅니다. 즉, BERT, DilstBERT, RoBERTa, DilstilROBERTa 등과 같은 모델을 Weaviate에서 바로 사용할 수 있습니다. 사용자 정의 모델 | N/A | N/A | N/A | N/A |
엄격한 분석 끝에 심층적인 벤치마킹을 위해 Milvus와 Weaviate라는 두 개의 VSE가 선정되었습니다. 이 플랫폼들은 엄격한 견고성, 효율성 및 확장성 요구 사항에 가장 부합했습니다. 플랫폼의 로드맵도 최종 선택에 영향을 미쳤는데, 증가하는 요구사항에 맞춰 지속적으로 발전하고 적응할 수 있는 솔루션이 필요했기 때문입니다.
실험 설정
공정하고 포괄적인 평가를 위해 표준화된 하드웨어 및 소프트웨어 설정을 사용했습니다.
- 하드웨어: 인텔 제온 E5-2690 v4 CPU, 112GB RAM, 1024GB HDD
- 소프트웨어: Linux 16.04-LTS, Anaconda 4.8.3 및 Python 3.8.12
- 데이터 세트: Farfetch 팀은 40,474개의 레코드로 구성된 startups-list.com의 공개 데이터 세트를 사용했습니다. 이 데이터 세트에는 회사 설명을 위해 미리 계산된 임베딩이 포함되어 있었습니다.
시나리오 및 색인 알고리즘
연구팀은 다양한 조건에서 이러한 VSE의 성능을 평가하기 위해 여러 테스트 시나리오를 설계했습니다. 이러한 시나리오에서는 엔티티당 레코드 수와 인코딩 수가 다양했습니다. 색인에는 고차원 데이터 공간에서 효율적인 것으로 알려진 계층적 탐색 가능한 작은 세계(HNSW) 알고리즘을 사용했습니다.
최종 시나리오 목록은 다음과 같습니다.
| 시나리오 | 엔티티 수 | 엔티티당 인코딩 수 | |
|---|---|---|---|
| 시나리오 #1(S1) | 1.000 | 1 | 1 |
| 시나리오 #2 (S2) | 10.000 | 1 | |
| 시나리오 #3(S3) | 40.474 | 1 | |
| 시나리오 #4 (S4) | 1.000 | 2 | |
| 시나리오 #5 (S5) | 10.000 | 2 | |
| 시나리오 #6 (S6) | 40.474 | 2 | |
| 시나리오 #7 (S7) | 1.000 | 5 | |
| 시나리오 #8 (S8) | 10.000 | 5 | |
| 시나리오 #9 (S9) | 40.474 | 5 |
성능 분석
인덱싱
위베이트: 클래스 스키마를 생성하는 동안 인덱스 매개변수를 명시적으로 선언할 수 있습니다. 그러나 숫자나 특수 문자를 허용하지 않는 등 클래스 이름 지정이 제한됩니다.
Milvus: 더 광범위한 인덱싱 알고리즘과 메트릭 유형을 제공합니다. 또한 인덱스 파일 크기를 정의할 수 있어 배치 작업을 최적화할 수 있습니다.
결과: Milvus는 모든 시나리오에서 평균 인덱싱 시간 면에서 우위를 점했습니다. 가장 리소스 집약적인 시나리오인 S9에서 특히 더 빨랐습니다.
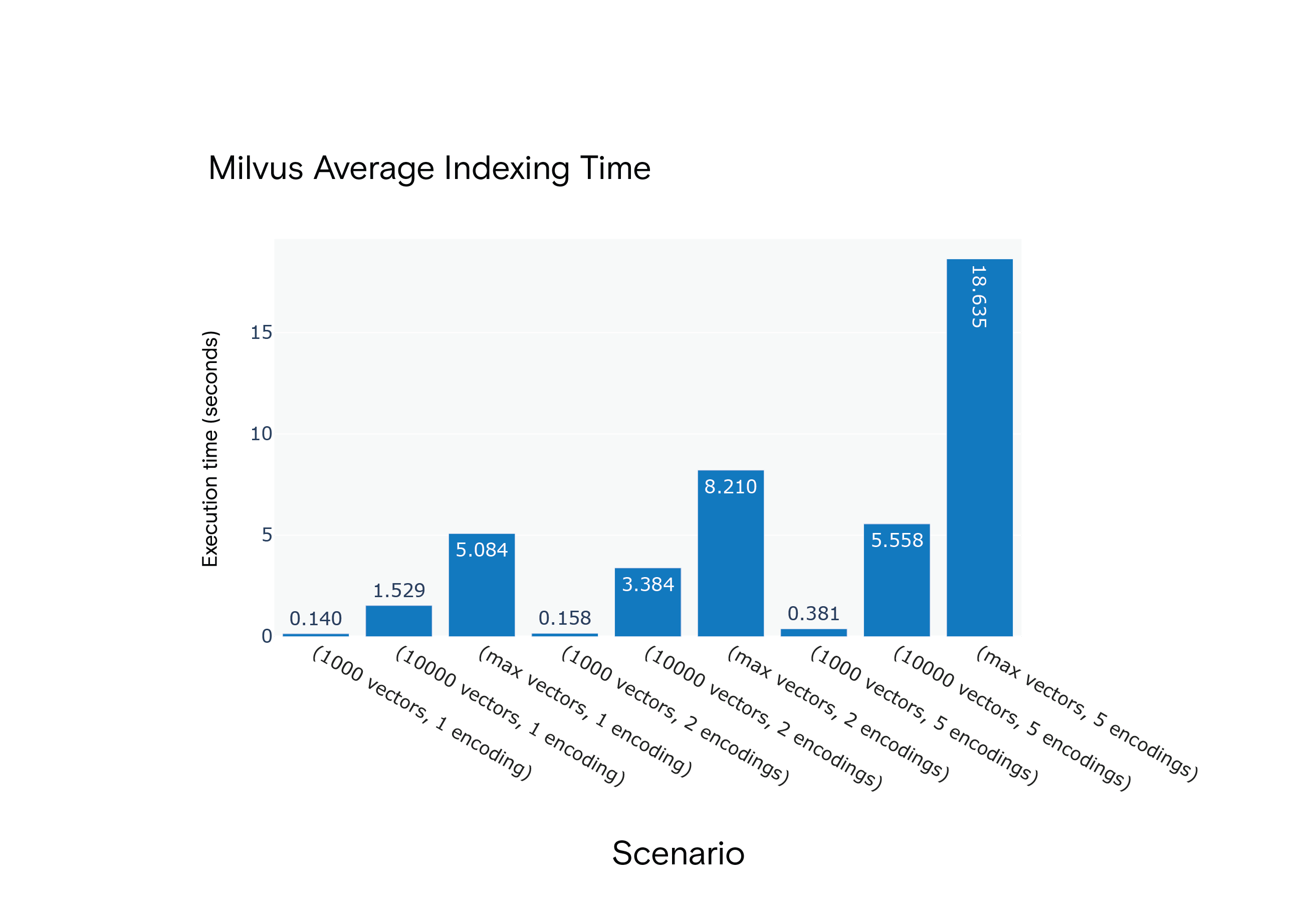 Milvus 1.1.1 시나리오 S1~S9의 평균 인덱싱 시간
Milvus 1.1.1 시나리오 S1~S9의 평균 인덱싱 시간
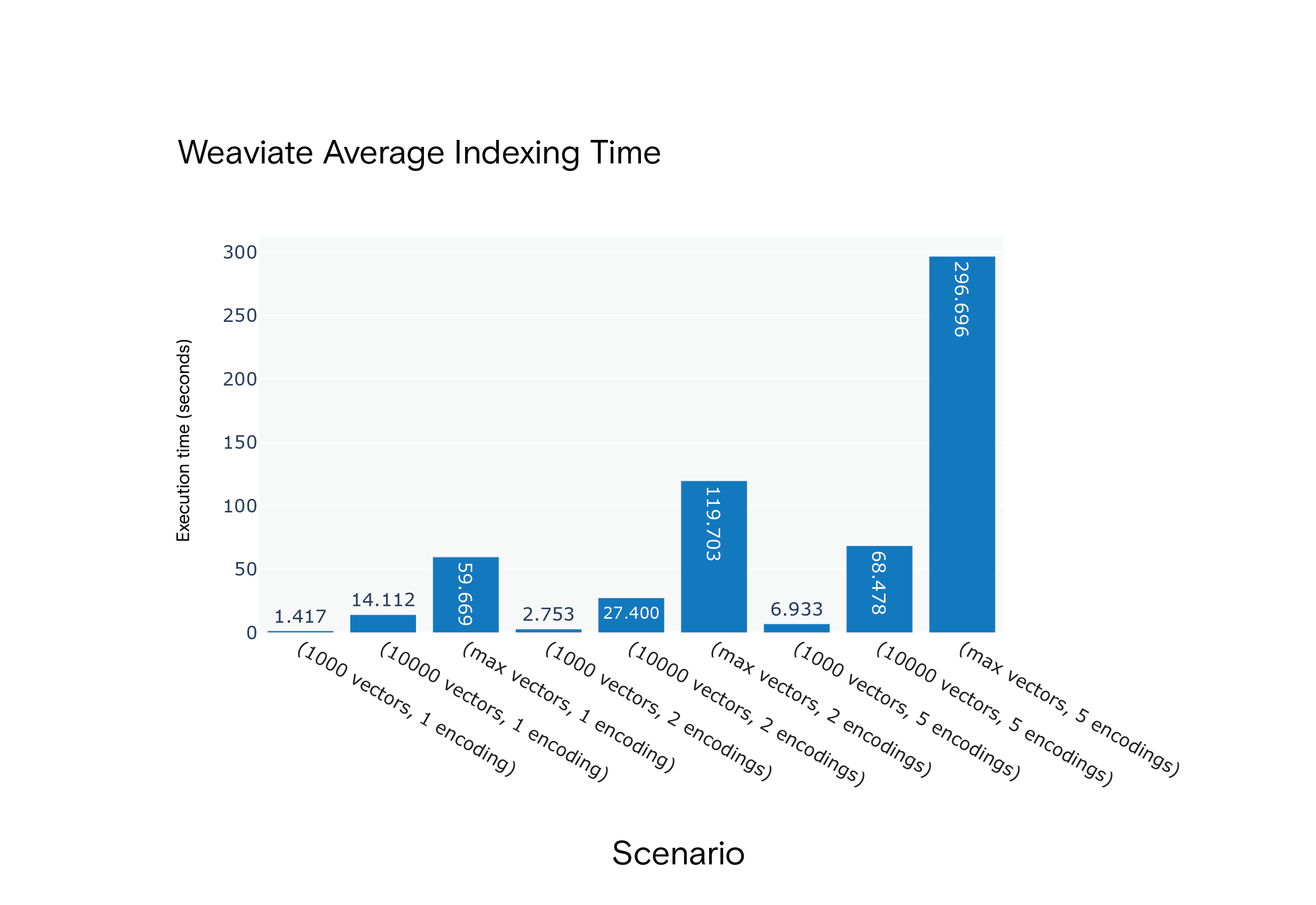 시나리오 S1~S9의 Weaviate 평균 인덱싱 시간
시나리오 S1~S9의 Weaviate 평균 인덱싱 시간
쿼리
Weaviate: Python 클라이언트는 벡터 검색을 지원하지만 한 번에 하나의 벡터에 대해서만 지원합니다.
밀버스: 벡터 목록을 처리할 수 있는 보다 유연한 검색 방법을 제공하여 다중 벡터 쿼리를 용이하게 합니다.
결과: Milvus는 모든 시나리오에서 평균 쿼리 시간이 더 짧았지만, 최적의 성능에 도달하기 위해 "워밍업" 단계가 필요했습니다.
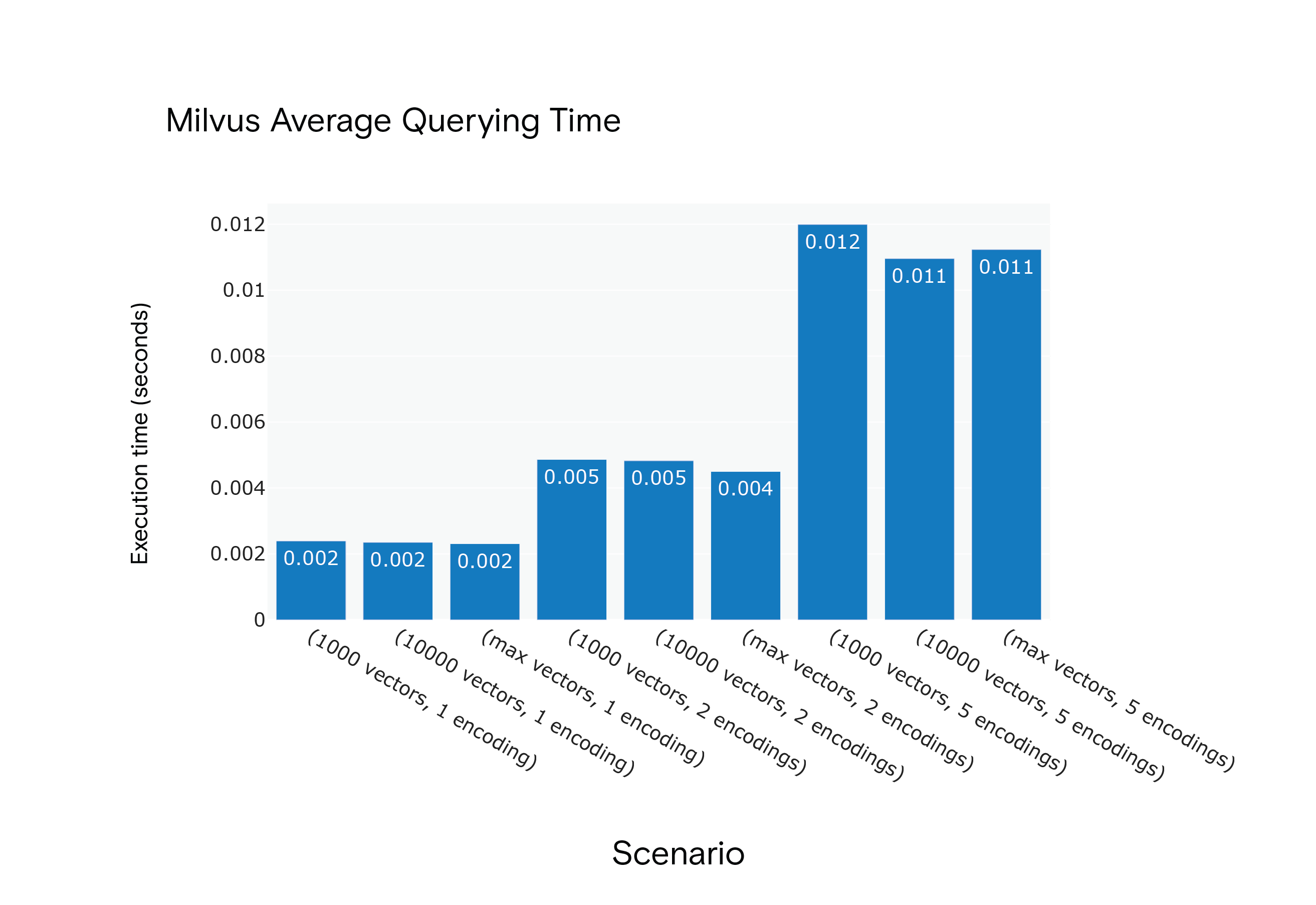 Milvus 1.1.1 시나리오 S1~S9의 평균 쿼리 시간
Milvus 1.1.1 시나리오 S1~S9의 평균 쿼리 시간
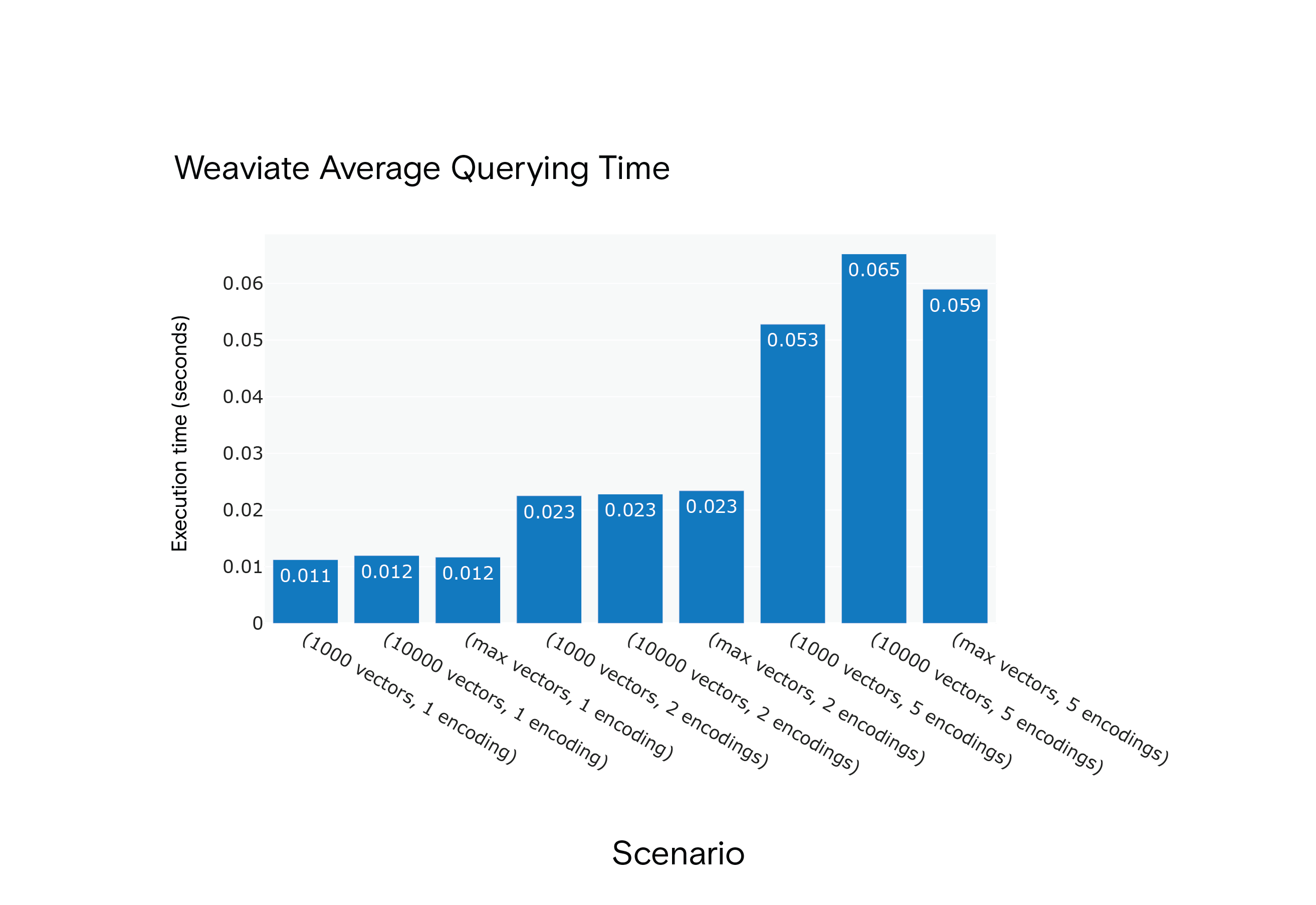 시나리오 S1~S9의 Weaviate 평균 쿼리 시간
시나리오 S1~S9의 Weaviate 평균 쿼리 시간
Farfetch 팀은 Milvus와 Weaviate가 가능성을 보였지만 아직 진화 중이라고 느꼈습니다. 수평적 확장, 샤딩, GPU 지원과 같은 기능은 로드맵에 포함되어 있습니다. 30만 개에서 500만 개에 이르는 제품 카탈로그를 처리하는 것을 목표로 하는 파페치에게 이상적인 VSE는 다음과 같은 기능을 제공해야 합니다:
- 고품질의 정확한 결과
- 효율적인 인덱싱 기능
- 빠른 쿼리 실행
- 로드 밸런싱 및 데이터 복제와 같은 확장성 기능
실험 결과, Milvus는 인덱싱 및 쿼리 시간에서 Weaviate보다 지속적으로 더 나은 성능을 보였습니다. 그러나 두 플랫폼 모두 다중 인코딩을 지원하지 않는 등의 특정 제한 사항이 있다는 점은 주목할 필요가 있습니다. 앞으로 이 두 플랫폼의 개발을 면밀히 모니터링하고 새로운 기능을 도입할 때 재평가할 가능성이 있습니다.
*이 사례 연구는 원래 Farfetch의 페드로 모레라 코스타(PEDRO MOREIRA COSTA)가 게시한 심층적인 벡터 데이터베이스 벤치마킹 블로그의 요약본입니다. 더 자세한 분석과 인사이트를 원하시면 원본 블로그 게시물을 참조하시기 바랍니다: 벡터 데이터베이스로 AI 강화하기: 벤치마크 - 1부 및 벡터 데이터베이스로 AI 강화하기: 벤치마크 - 2부를 참조하세요.
사용 사례
산업
전자상거래