




Autoencoder Variazionali Condizionali (CVAE): Modelli generativi con input condizionali

Autoencoder Variazionali Condizionali (CVAE): Modelli generativi con input condizionali
Ti sei mai chiesto come l'IA possa generare immagini o dati specifici e realistici sulla base di una condizione, come creare l'immagine di un gatto in un certo stile?
Autoencoder Variazionali (VAE) sono potenti modelli generativi ma mancano di controllo sugli attributi dei dati. Gli Autoencoder Variazionali Condizionali (CVAE) superano questa limitazione incorporando condizioni, come etichette o attributi, sia nell'encoder sia nel decoder. Questo consente ai CVAE di generare dati su misura per requisiti specifici, rendendoli ideali per attività come la creazione mirata di immagini o la generazione di contenuti personalizzati, ampliando il loro potenziale in vari campi.
Esploriamo come funzionano gli Autoencoder Variazionali Condizionali (CVAE), i loro vantaggi e come cambiano il modo in cui i dati vengono generati in vari domini.
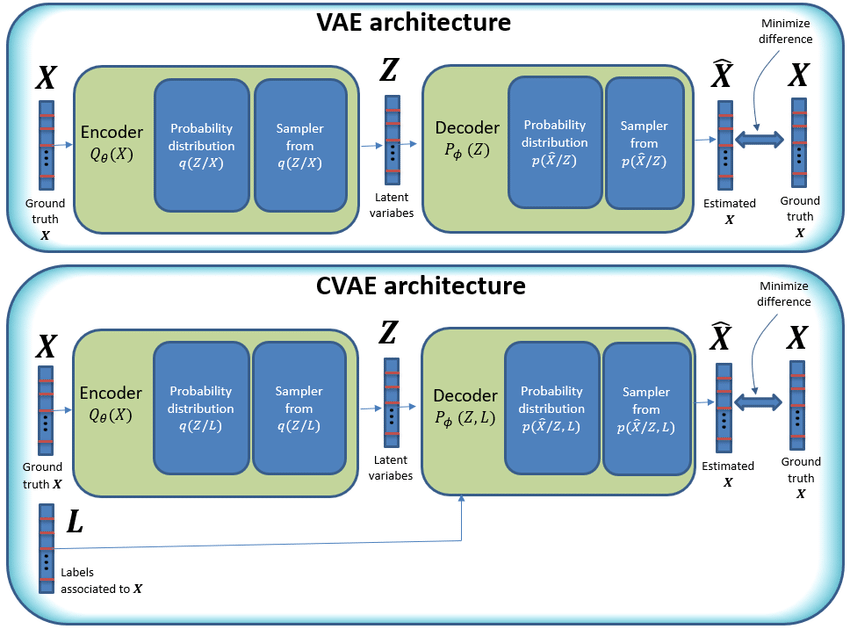
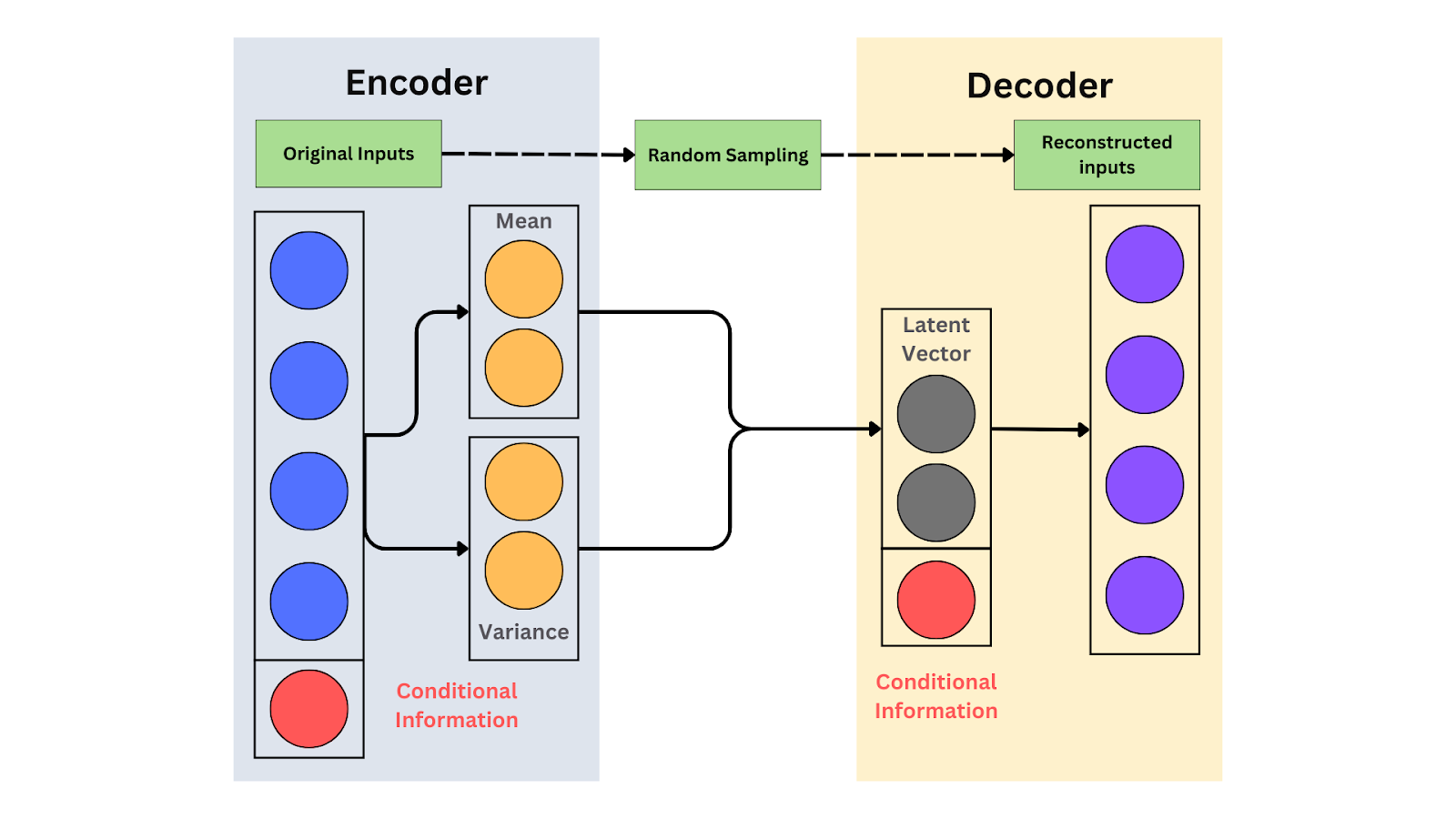 Lo schema di un CVAE.png
Lo schema di un CVAE.png
Lo schema di un CVAE
Cosa sono gli Autoencoder Variazionali Condizionali (CVAE) ?
Un Autoencoder Variazionale Condizionale (CVAE) è un'estensione dell'Autoencoder Variazionale (VAE) che incorpora input condizionali, come etichette o attributi, per guidare il processo di generazione dei dati. I dati generati soddisfano requisiti specifici condizionando il modello. Ad esempio, se vuoi creare immagini di gatti o cani, puoi fornire l'etichetta "cat" o "dog" per guidare la generazione. Questo consente al modello di produrre l'output desiderato in base alla condizione.
I CVAE sono importanti perché forniscono controllo sulla generazione dei dati. Gli input condizionali garantiscono che gli output corrispondano a caratteristiche predefinite. Questo li rende utili per attività come la generazione di immagini per il fashion design, dove i modelli possono creare capi di abbigliamento in diversi colori o stili, e nelle simulazioni mirate, dove scenari specifici devono essere generati in base a determinate condizioni.
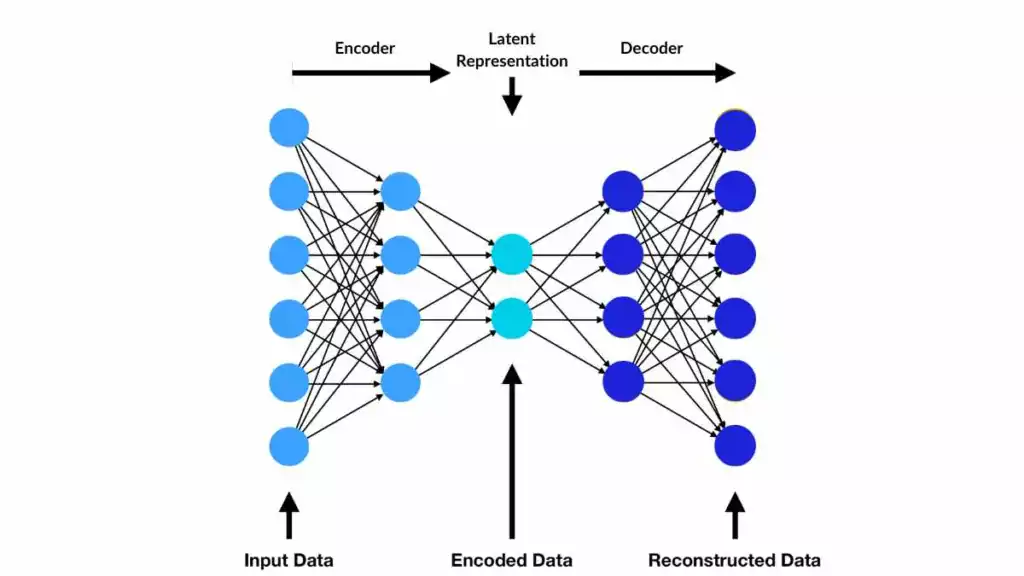 La struttura dell'autoencoder è alla base di VAE e CVAE.png
La struttura dell'autoencoder è alla base di VAE e CVAE.png
La struttura dell'autoencoder è alla base di VAE e CVAE | Fonte
Comprendere gli Autoencoder Variazionali (VAE)
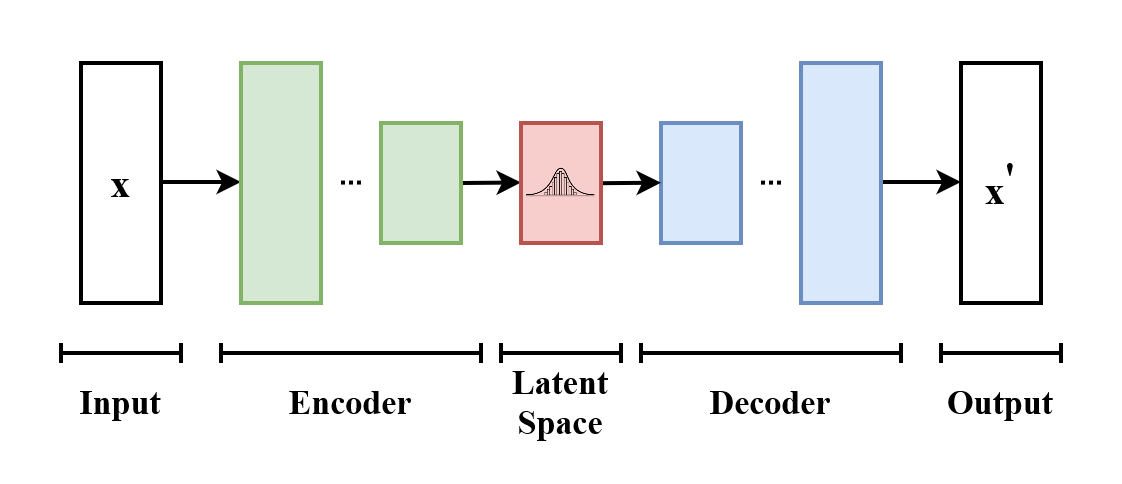
Prima di approfondire i CVAE, parliamo del concetto di Autoencoder Variazionali (VAE). I VAE sono modelli generativi che imparano a rappresentare distribuzioni di dati complesse in uno spazio latente continuo per generare nuovi campioni di dati.
I VAE contengono due componenti principali: un encoder e un decoder. L'encoder comprime i dati di input in uno spazio latente, catturandone le caratteristiche chiave. Il decoder ricostruisce l'input o genera nuovi campioni da questa rappresentazione latente. Una funzione di perdita svolge un ruolo chiave nell'addestramento bilanciando l'accuratezza della ricostruzione e la regolarità dello spazio latente. La Regolarizzazione assicura che lo spazio latente sia liscio e strutturato, consentendo una generazione coerente dei dati.
Funzione di perdita
La funzione di perdita negli Autoencoder Variazionali (VAE) consiste in due componenti principali: perdita di ricostruzione e divergenza KL.
- La Perdita di ricostruzione misura quanto bene il modello riproduce i dati di input. È tipicamente calcolata usando l'Errore Quadratico Medio (MSE) o l'Entropia Incrociata Binaria. L'equazione per la perdita di ricostruzione è:
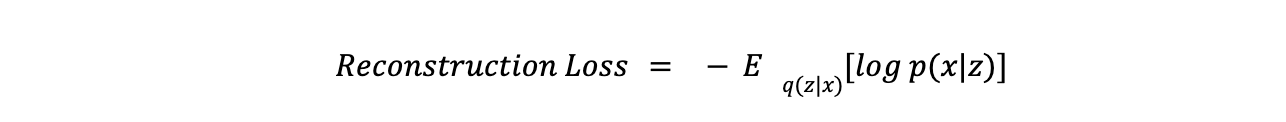
- La Divergenza KL, abbreviazione di divergenza di Kullback-Leibler, è una misura statistica di quanto una distribuzione di probabilità differisca. Nel contesto dei VAE, assicura che la distribuzione latente 𝒒(𝔃∣𝔁) (appresa dall'encoder) rimanga vicina alla prior 𝒑(𝔃), che è tipicamente una distribuzione gaussiana standard. L'equazione per la divergenza KL è:
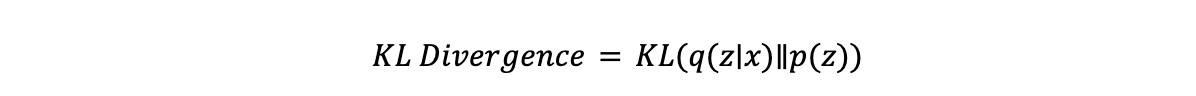
La funzione di perdita complessiva è una somma ponderata di questi due termini:
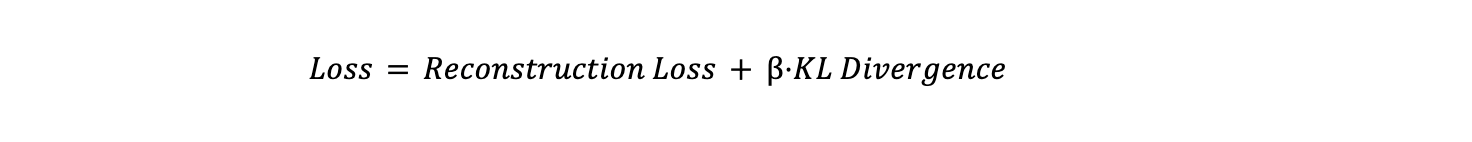
Dove β è un iperparametro che controlla il compromesso tra la perdita di ricostruzione e la divergenza KL. Un β più alto dà maggiore importanza alla regolarizzazione dello spazio latente, mentre un valore più basso consente al modello di concentrarsi maggiormente su una ricostruzione accurata. Questo equilibrio è fondamentale per garantire che il modello generi dati accurati e apprenda uno spazio latente significativo e ben strutturato.
Regolarizzazione
La regolarizzazione utilizza la divergenza di Kullback-Leibler per allineare lo spazio latente con la distribuzione a priori, assicurando che le variabili latenti seguano una distribuzione gaussiana. Questo rende più uniforme lo spazio latente, consentendo l’interpolazione e un campionamento significativo. Punti vicini tra loro nello spazio latente generano output simili. La regolarizzazione migliora anche la generalizzazione impedendo al modello di adattarsi eccessivamente ai dati di addestramento. Ad esempio, nel design della moda, la regolarizzazione garantisce che vengano generati design di abbigliamento diversificati mantenendo al contempo modelli e stili realistici. Aiuta a creare variazioni nei tipi di abbigliamento, nei colori e nelle texture, senza produrre output irrealistici. Mantenendo strutturato lo spazio latente, genera design che si allineano alle tendenze attuali ma sono diversi a modo loro.
 Struttura di un Variational Autoencoder (VAE) |.png
Struttura di un Variational Autoencoder (VAE) |.png
Struttura di un Variational Autoencoder (VAE) | Fonte
{kind=link}
In che modo il CVAE migliora il VAE con input condizionali?
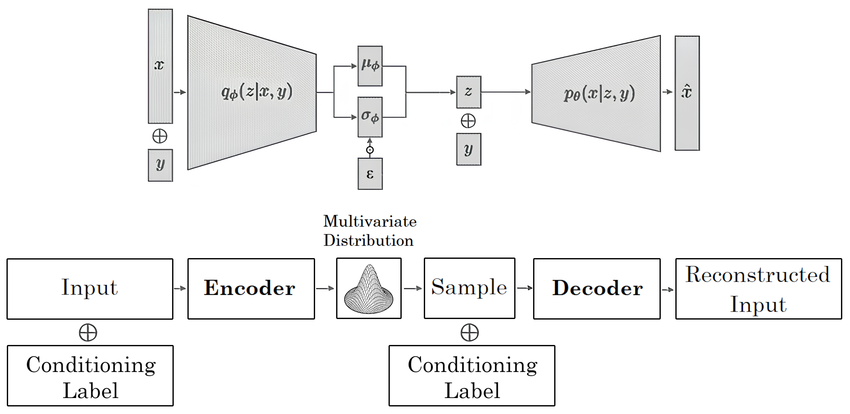
I CVAE estendono i VAE aggiungendo input condizionali, come etichette di classe, per guidare la generazione dei dati. L’encoder elabora sia i dati di input sia la condizione. Li mappa in uno spazio latente congiunto, catturando i dati e la condizione combinati. Il decoder utilizza quindi questa rappresentazione latente, una versione compressa dei dati, insieme alla condizione per generare nuovi campioni.
Ad esempio, se la condizione è "sneaker rosse," il decoder genera un’immagine di sneaker rosse. La condizione garantisce che l’output corrisponda a requisiti specifici. Come i VAE, i CVAE utilizzano la divergenza KL per regolarizzare lo spazio latente e creare una distribuzione uniforme.
I VAE si basano solo sulle variazioni dei dati di input, limitando il controllo sull’output. I CVAE utilizzano etichette o attributi per guidare il processo di generazione. Questo consente output mirati e specifici. Ad esempio, in un CVAE addestrato su MNIST, la condizione potrebbe essere un’etichetta di cifra come "5." Data l’etichetta e un input, il modello genera uno specifico "5." Un VAE, al contrario, potrebbe generare qualsiasi cifra casuale a seconda dello spazio latente.
I CVAE sono ideali per attività come la generazione di immagini con caratteristiche specifiche o la personalizzazione dei contenuti. Ad esempio, un CVAE può generare un design di sneaker basato sulle preferenze dell’utente in termini di colore, taglia e stile, migliorando la personalizzazione e l’esperienza utente.
 Architettura del Conditional Variational Autoencoder (CVAE).png
Architettura del Conditional Variational Autoencoder (CVAE).png
Architettura del Conditional Variational Autoencoder (CVAE) | Fonte
Termini chiave:
Spazio latente: Lo spazio latente è una rappresentazione compressa e ad alta dimensionalità dei dati. Cattura le caratteristiche essenziali dei dati di input, come posa o colore, in una forma compatta. Ad esempio, un’immagine di un volto potrebbe essere compressa in un vettore che rappresenta età o espressione. Lo spazio segue tipicamente una distribuzione nota (ad esempio, gaussiana), consentendo la generazione di nuovi punti dati simili campionando da questa distribuzione. Questa rappresentazione consente al modello di manipolare o interpolare efficacemente tra punti dati.
Codificatore: Il codificatore converte i dati di input in una rappresentazione latente probabilistica. Mappa l'input 𝔁 (come un'immagine) a una distribuzione (media 𝜇, varianza 𝝈2) nello spazio latente. Ad esempio, per un'immagine di un gatto, il codificatore produce una distribuzione di caratteristiche come colore e razza. Un vettore latente viene campionato da questa distribuzione. Il codificatore apprende come comprimere i dati in modo efficiente preservando le caratteristiche essenziali.
Decodificatore: Il decodificatore prende una variabile latente 𝔃 e ricostruisce o genera dati. Mappa il vettore latente, una versione compressa dei dati, di nuovo nello spazio dei dati originale. Ad esempio, il decodificatore genera un'immagine di un gatto da un vettore latente che rappresenta caratteristiche di gatto. La funzione è indicata come 𝒑(𝔁∣𝔃), dove 𝔁 sono i dati generati. Il decodificatore può creare output diversi apprendendo dalle variabili latenti, anche per dati mai visti.
Input condizionali: Gli input condizionali forniscono informazioni extra (ad es., etichette) che guidano la generazione dei dati. Nei CVAE, etichette come "gatto" aiutano a generare output specifici, come immagini di gatti. Il codificatore e il decodificatore usano questi input per creare output controllati. Ad esempio, il codificatore diventa 𝒒(𝔃∣𝔁,𝔂), e il decodificatore è 𝒑(𝔁∣𝔃,𝔂). Questi input garantiscono che il modello generi dati adattati alle condizioni date, aumentando la flessibilità.
- Divergenza KL: La Divergenza KL misura quanto la distribuzione appresa dal codificatore sia diversa dalla distribuzione a priori (di solito una gaussiana). Incoraggia il codificatore a generare variabili latenti vicine alla distribuzione a priori, garantendo uno spazio latente strutturato. La formula è:
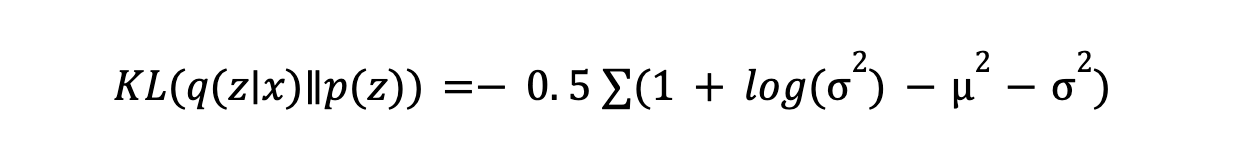
Minimizzare la divergenza KL aiuta a mantenere uno spazio latente ben comportato per la generazione dei dati. Questa tecnica di regolarizzazione garantisce che le variabili latenti siano distribuite in un modo che renda affidabili il campionamento e la generazione di nuovi punti dati.
CVAE vs. VAE vs. GAN
Questa sezione confronta i Variational Autoencoders (VAE) con i Conditional Variational Autoencoders (CVAE) e le Generative Adversarial Networks (GAN). Sono tutti modelli generativi, ma presentano diverse differenze chiave.
La seguente tabella evidenzia le differenze nei loro meccanismi, nella flessibilità e nei casi d'uso.
| Aspetto | VAE (Variational Autoencoder) | CVAE (Conditional Variational Autoencoder) | GANs (Generative Adversarial Networks) |
| Meccanismo di base | Codifica i dati di input in uno spazio latente compresso e genera nuovi dati. | Simile al VAE, incorpora input condizionali (ad es., etichette) per guidare la generazione. | Composto da due reti: un generatore crea dati e un discriminatore li valuta. |
| Dati di input | Solo i dati stessi vengono forniti all’encoder. | I dati condizionali (ad es., etichette di classe e attributi) vengono utilizzati anche nell’encoder. | Usa rumore casuale come input per il generatore, mentre il discriminatore valuta i dati generati. |
| Rappresentazione latente | Rappresenta l’intera distribuzione dei dati, fornendo uno spazio latente fluido e continuo. | Lo spazio latente è condizionato sui dati di input, offrendo un maggiore controllo sull’output generato. | Lo spazio latente viene appreso durante l’addestramento, senza controllo esplicito su caratteristiche specifiche. |
| Controllo della generazione | La generazione si basa esclusivamente sullo spazio latente, senza controlli esterni. | I dati condizionali consentono la generazione di dati basati su attributi specifici (ad es., generare immagini di categorie specifiche come “gatto” o “cane”). | Il generatore “compete” con il discriminatore, migliorando i dati generati “ingannando” il discriminatore. |
| Flessibilità | Adatto alla generazione di dati per scopi generali e al rilevamento di anomalie. | Ideale per scenari in cui è richiesta una generazione controllata basata su attributi specifici. | Molto flessibile nel generare campioni realistici, ma con minore controllo sugli output specifici. |
| Dati di addestramento | Può essere addestrato su un dataset ampio senza condizioni esplicite. | Sono necessari dati etichettati o condizionali aggiuntivi per guidare il processo di generazione. | Richiede un addestramento avversario in cui generatore e discriminatore competono. |
| Casi d’uso | Generazione di dati (ad es., generare volti), rilevamento di anomalie e interpolazione di punti dati. | Generazione controllata di immagini (ad es., generare oggetti o condizioni specifiche come colore o stile), apprendimento semi-supervisionato. | Generazione di immagini di alta qualità, traduzione da immagine a immagine, trasferimento di stile e aumento dei dati. |
| Vantaggi principali | Più semplice da addestrare, senza necessità di condizioni esterne. | Consente la generazione di output altamente specifici, offrendo un miglior controllo sui dati generati. | Genera immagini altamente realistiche e dati diversificati, senza necessità di etichette esplicite. |
| Esempio di applicazione | Generare immagini casuali di volti. | Generare immagini di volti con attributi specifici come età, genere o espressione. | Generare immagini realistiche di volti umani, generare arte o tradurre immagini da uno stile a un altro. |
 Confronto tra CVAE e una tipica architettura VAE.png
Confronto tra CVAE e una tipica architettura VAE.png
Confronto tra CVAE e una tipica architettura VAE | Fonte
 Confronto tra le architetture di (A) VAE e (B) GAN.png
Confronto tra le architetture di (A) VAE e (B) GAN.png
Confronto tra le architetture di (A) VAE e (B) GAN | Fonte
Vantaggi e sfide degli autoencoder variazionali (VAE)
Gli autoencoder variazionali (VAE) offrono vantaggi significativi nella modellazione generativa, ma presentano anche sfide che devono essere affrontate. Discutiamo prima i vantaggi dell'utilizzo dei VAE.
Generazione condizionale: I CVAE possono generare nuovi campioni in base a condizioni specifiche, rendendoli utili per attività come la generazione di immagini con determinate caratteristiche o la creazione di contenuti personalizzati. Ciò aggiunge flessibilità e versatilità a varie applicazioni.
Rappresentazioni significative: Gli VAE condizionali (CVAE) apprendono rappresentazioni latenti significative dall'input, consentendo una migliore comprensione e manipolazione delle strutture dei dati. Ciò è particolarmente vantaggioso per attività come l'estrazione e l'analisi delle caratteristiche.
Personalizzazione: I CVAE possono produrre dati adattati a esigenze specifiche, consentendo raccomandazioni personalizzate e contenuti mirati. Questo li rende estremamente preziosi in ambiti come la pubblicità e le applicazioni utente personalizzate.
Aumento dei dati: I CVAE possono essere utilizzati per aumentare i dataset generando dati sintetici diversificati e realistici. Questa capacità aiuta a migliorare le prestazioni dei modelli di machine learning, soprattutto in scenari con dataset limitati o sbilanciati.
Ora discutiamo le sfide affrontate nell'utilizzo dei VAE.
Collasso delle modalità: Si verifica quando il modello genera solo pochi tipi di campioni, portando a output ripetitivi invece che diversificati. L'overfitting può peggiorare questo problema inducendo il modello a memorizzare pattern specifici invece di apprendere rappresentazioni latenti significative. Ciò accade spesso a causa di una scarsa esplorazione dello spazio latente o di dati di training insufficienti e non rappresentativi. Per affrontare questo problema, si possono utilizzare tecniche di regolarizzazione come dropout e batch normalization, insieme ad algoritmi di training avanzati come gli Importance-Weighted Autoencoders (IWAE).
Generazione di immagini ad alta risoluzione: I CVAE faticano a generare efficacemente immagini ad alta risoluzione. Lo spazio latente del modello potrebbe non riuscire a catturare dettagli sufficientemente fini, producendo output sfocati o distorti. Questa limitazione deriva dalla capacità limitata dello spazio latente e dalla perdita di qualità negli output ad alta risoluzione. Per mitigare questa sfida, si possono utilizzare spazi latenti più complessi o VAE gerarchici, combinare i CVAE con modelli come le GAN, oppure impiegare tecniche di training progressivo che aumentano gradualmente la risoluzione durante il training.
Casi d'uso degli autoencoder variazionali condizionali (CVAE)
Gli autoencoder variazionali condizionali (CVAE) sono strumenti versatili nel deep learning, con applicazioni in una varietà di domini. Ecco alcuni casi d'uso principali:
Generazione di immagini: I CVAE generano immagini condizionate da attributi come stile, posa o illuminazione. Nel design e nella moda, vengono utilizzati per visualizzare capi di abbigliamento in diversi stili o colori. Gli sviluppatori di videogiochi li sfruttano per creare aspetti dei personaggi diversificati, mentre i produttori automobilistici li usano per renderizzare veicoli con varie personalizzazioni per i clienti.
Sistemi di raccomandazione dei contenuti: I CVAE migliorano la personalizzazione apprendendo le preferenze degli utenti per suggerire raccomandazioni pertinenti. Si adattano inoltre dinamicamente alle interazioni degli utenti, migliorando il coinvolgimento nel tempo.
Scoperta di farmaci: I CVAE accelerano l'innovazione medica generando nuove strutture molecolari basate su proprietà desiderate. Ottimizzano inoltre i composti esistenti per migliorare gli esiti terapeutici.
Rilevamento delle anomalie: I CVAE identificano schemi insoliti nei sistemi critici. Segnalano deviazioni dai normali parametri operativi e rafforzano la cybersecurity rilevando attività di rete insolite.
Elaborazione del linguaggio naturale (NLP): I CVAE contribuiscono a compiti come la generazione di testo coerente condizionata da contesto, stile o tono. Facilitano inoltre traduzioni linguistiche sfumate adattate a requisiti stilistici.
Arte e creatività: I CVAE danno potere ad artisti e creatori consentendo il trasferimento di stile per reinventare opere d'arte con estetiche diverse. Assistono inoltre nella generazione di nuove creazioni artistiche basate su temi o motivi specifici.
Etica e responsabilità dell'AI: I CVAE supportano lo sviluppo responsabile dell'AI migliorando l'interpretabilità dei modelli attraverso la generazione controllata di dati. Garantiscono che i sistemi di AI siano allineati agli standard etici consentendo risultati controllabili.
Strumenti
Ora esploreremo alcuni degli strumenti e framework più diffusi che facilitano l'implementazione e l'addestramento degli Autoencoder Variazionali Condizionali (CVAE).
TensorFlow: È un potente framework per progettare CVAE. Semplifica l'implementazione di architetture encoder-decoder e supporta il calcolo del termine di divergenza KL tramite TensorFlow Probability. Il suo supporto GPU/TPU garantisce un addestramento efficiente per dataset di grandi dimensioni.
PyTorch: È ampiamente utilizzato per la sua flessibilità e il grafo di computazione dinamico, che lo rendono ideale per implementazioni CVAE personalizzate. Consente un controllo preciso sui componenti del modello, e librerie come Pyro aggiungono funzionalità avanzate di modellazione probabilistica per le funzioni di perdita dei CVAE.
JAX e Flax: JAX, combinato con la sua libreria di reti neurali Flax, offre computazione efficiente per i CVAE. Fornisce flessibilità per personalizzare i calcoli dei gradienti e supporta architetture scalabili per compiti CVAE complessi.
FAQ
Cosa distingue i CVAE dai VAE standard? I CVAE utilizzano input condizionali per controllare le caratteristiche dell'output. I VAE standard generano dati basandosi solo sulla distribuzione di input.
In che modo il condizionamento influenza il processo generativo nei CVAE? Il condizionamento guida il modello nella generazione di dati che corrispondono ad attributi specifici. Aggiunge controllo e precisione all'output.
Quali sono le applicazioni comuni dei CVAE? I CVAE creano immagini personalizzate, testo personalizzato e dataset aumentati. Funzionano bene in compiti che richiedono la generazione di caratteristiche specifiche.
Quali sfide si possono incontrare durante l'addestramento dei CVAE? L'addestramento richiede dati etichettati e un'attenta messa a punto. Può anche incontrare problemi di stabilità e complessità.
Quali sono i limiti dei CVAE rispetto alle GAN? I CVAE possono produrre output meno realistici. Le GAN spesso ottengono risultati più nitidi e dettagliati, ma non hanno lo stesso controllo.
- Cosa sono gli Autoencoder Variazionali Condizionali (CVAE) ?
- Comprendere gli Autoencoder Variazionali (VAE)
- In che modo il CVAE migliora il VAE con input condizionali?
- CVAE vs. VAE vs. GAN
- Vantaggi e sfide degli autoencoder variazionali (VAE)
- Casi d'uso degli autoencoder variazionali condizionali (CVAE)
- Strumenti
- FAQ
Contenuto
Inizia gratis, scala facilmente
Prova il database vettoriale completamente gestito progettato per le tue applicazioni GenAI.
Prova Zilliz Cloud gratuitamente