




Milvus 2.4 presenta CAGRA: elevazione della ricerca vettoriale con indicizzazione GPU di nuova generazione
Che cos'è un indice basato su GPU?
La ricerca vettoriale è intrinsecamente ad alta intensità di calcolo. Milvus, in prima linea come database vettoriale più performante, alloca oltre l'80% delle risorse di calcolo ai propri database vettoriali e al motore di ricerca, Knowhere. Date le esigenze di calcolo ad alte prestazioni, le GPU si rivelano un elemento fondamentale della nostra piattaforma di database vettoriali, soprattutto nell'ambito della ricerca vettoriale.
Milvus ha creato un precedente diventando il primo database vettoriale a sfruttare l'accelerazione delle GPU con la sua Milvus versione 1.1 nel 2021. Nella versione 2.3, sfruttando la libreria RAFT di NVIDIA per la ricerca vettoriale, Milvus ha introdotto indici accelerati dalle GPU e l'integrazione con il framework di raccomandazione NVIDIA Merlin (usato per creare sistemi di raccomandazione). L'introduzione degli indici IVFFLAT e IVFPQ in questa versione ha mostrato notevoli miglioramenti delle prestazioni.
Nonostante questi progressi, persistono sfide come l'ottimizzazione delle prestazioni per le query in piccoli lotti e il miglioramento dell'efficienza dei costi degli indici basati su GPU, che spingono a cercare soluzioni innovative. Il passaggio del settore agli [algoritmi di ricerca vettoriale] basati su grafi (https://zilliz.com/learn/popular-machine-learning-algorithms-behind-vector-search), riconosciuti per le loro prestazioni superiori rispetto ai metodi basati su FIV, rappresenta un'evoluzione fondamentale. Tuttavia, l'adattamento di questi algoritmi alle GPU non è semplice a causa della loro esecuzione sequenziale e dei modelli di accesso casuale alla memoria, rendendo difficile un'implementazione efficiente su GPU per algoritmi come GGNN e SONG.
Per affrontare queste sfide, l'ultima innovazione di NVIDIA, l'indice di grafi basato su GPU CAGRA, rappresenta una pietra miliare significativa. Con l'assistenza di NVIDIA, Milvus ha integrato il supporto per CAGRA nella sua versione 2.4, segnando un passo significativo verso il superamento degli ostacoli all'implementazione efficiente delle GPU nella ricerca vettoriale.
Che cos'è CAGRA?
Costruire CAGRA
CAGRA (CUDA Anns GRAph-based) introduce un nuovo approccio alla costruzione dei grafi, che si discosta dal metodo iterativo di inserimento-aggiornamento utilizzato per i grafi hierarchical navigable small worlds (HNSW) sulle CPU. Questo cambiamento risponde alla sfida di sfruttare appieno le capacità di costruzione di grafi altamente paralleli delle GPU, che il processo di costruzione di HNSW basato su CPU non sfrutta. CAGRA inizia con la creazione di un grafo iniziale utilizzando IVFPQ o NN-DESCENT, dove ogni nodo è collegato a numerosi vicini. Le fasi successive prevedono l'ordinamento di queste connessioni in base all'importanza, la potatura degli spigoli meno critici e la fusione dei grafi diretti per finalizzare la struttura e costruire un grafo iniziale. Nel grafo iniziale, ogni nodo ha un gran numero di nodi vicini. CAGRA ordina quindi tutti gli spigoli adiacenti in base alla loro importanza, in base al grafo iniziale, e pota gli spigoli non importanti.
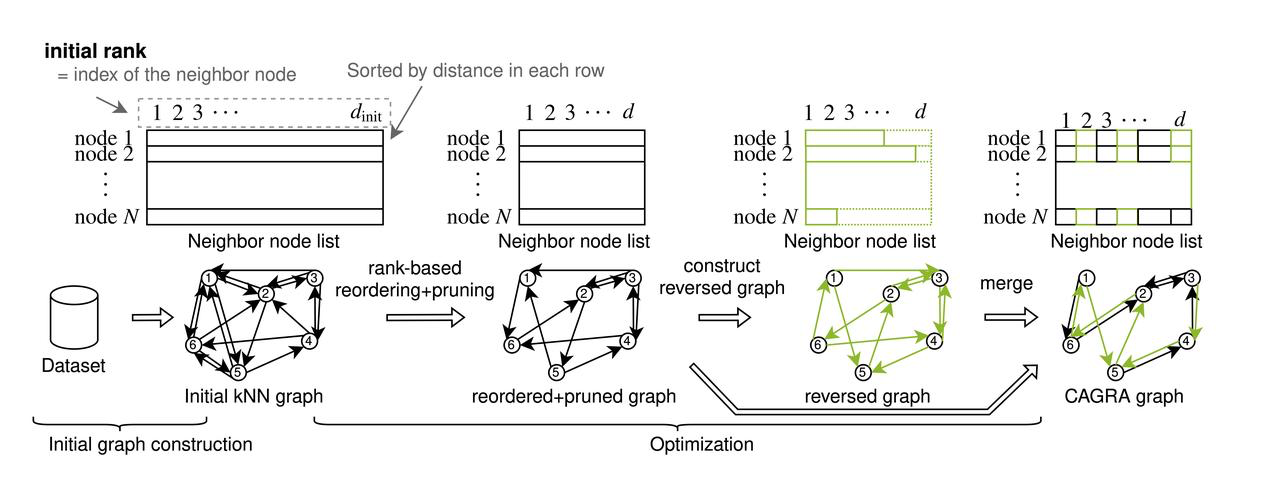 Il processo di costruzione di CAGRA
Il processo di costruzione di CAGRA
Costruzione iniziale del grafico
IVFPQ
In modalità IVFPQ, CAGRA sfrutta il set di dati per costruire un indice IVFPQ, utilizzando la funzione di quantizzazione dell'indice Product Quantization (PQ) per ridurre al minimo l'utilizzo della memoria video. Dopo la creazione di questo indice, CAGRA esegue una ricerca per ogni punto del set di dati, utilizzando i vicini approssimativi identificati dall'indice IVFPQ come ricerca dei vicini dei punti adiacenti. Questo processo costituisce la base per la costruzione del grafo iniziale, garantendo un'impostazione efficiente senza occupare troppa memoria.
NN-DESCENT
CAGRA impiega l'algoritmo NN-DESCENT per un altro approccio alla costruzione del grafo iniziale, che prevede le seguenti fasi dettagliate:
Inizializzazione: Selezionare casualmente k punti dal dataset v per creare l'elenco di adiacenze iniziale B[v].
Inversione e fusione: Prendere l'inverso di B[v] per generare l'elenco di adiacenze invertito R[v], quindi unire B e R per formare H[v].
Per qualsiasi nodo v nel dataset, identificare tutti i vicini dei vicini in base a H[v], selezionando i nodi topk** più vicini come nuovi vicini.
**Ripetere il processo di inversione e fusione e di espansione dei vicini finché B non si stabilizza e non cambia più o finché non viene raggiunta una soglia di iterazione predefinita.
Rispetto a HNSW, NN-Descent offre una parallelizzazione più semplice e una minore interazione dei dati tra i task, aumentando significativamente il tempo di costruzione del grafo e l'efficienza del grafo di adiacenza CAGRA sulle GPU. Tuttavia, va notato che la qualità iniziale del grafo in NN-DESCENT può essere leggermente inferiore a quella ottenuta con la modalità IVFPQ.
Ottimizzazione CAGRA
La strategia di ottimizzazione del grafo di CAGRA si basa su due ipotesi principali:
**Per determinare l'importanza degli spigoli, si preferisce un ordinamento basato sui percorsi rispetto al tradizionale ordinamento basato sulla distanza. Questo metodo sostiene che la connettività del grafo non necessariamente trae vantaggio dall'ordinamento dell'importanza basato sulla distanza.
**Il principio secondo cui un nodo ritenuto importante per un altro può trovare importante anche quest'ultimo è alla base della strategia di fusione dei grafi inversi.
Il processo di ottimizzazione comprende due fasi principali:
- Inizialmente, ai bordi adiacenti di ciascun nodo vengono assegnati diversi pesi ('w')** in base alla distanza. CAGRA impiega una strategia di potatura in cui gli spigoli vengono tagliati se collegano i nodi più "svantaggiosi", in base alla condizione "max(w_{x a z},w_{z a y}) < w_{x a y}". Questo si concentra sull'eliminazione delle connessioni meno critiche per snellire il grafo.
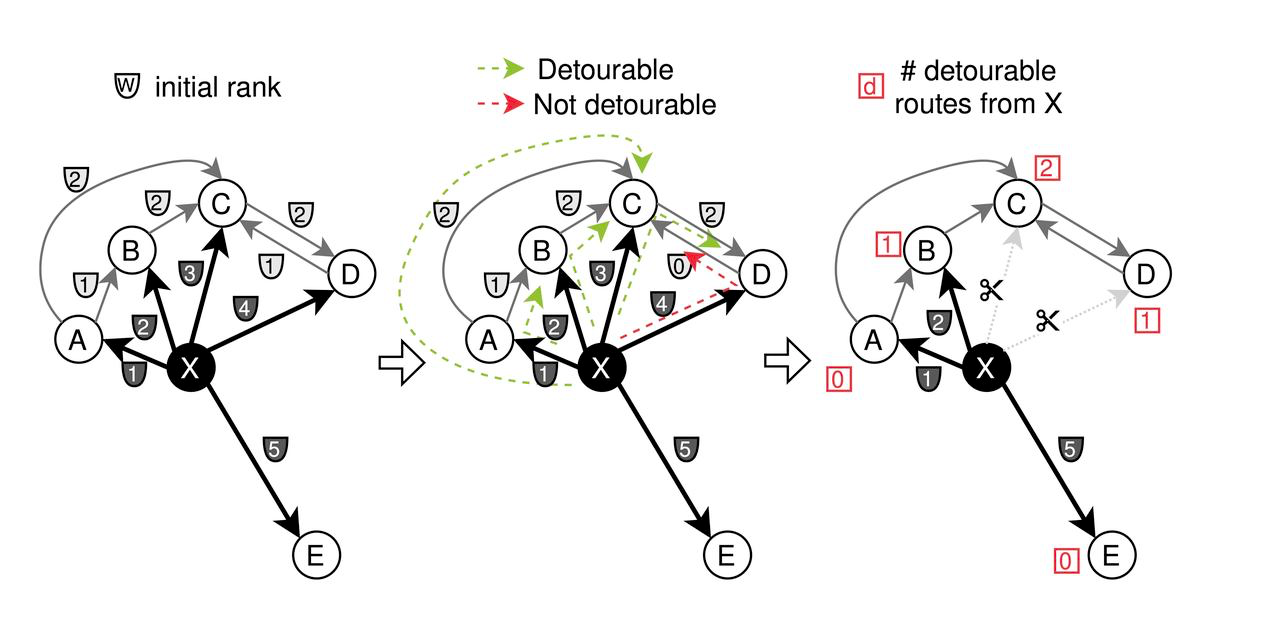 Processo di potatura per l'ottimizzazione di CAGRA
Processo di potatura per l'ottimizzazione di CAGRA
- **Dopo la potatura del grafo di andata in base alla significatività del percorso, i bordi vengono invertiti e uniti. In particolare, la metà dei bordi viene selezionata da entrambi i grafi forward e reverse per creare il grafo CAGRA finale ottimizzato.
Questo approccio dettagliato alla costruzione e all'ottimizzazione del grafo garantisce l'efficienza e l'efficacia di CAGRA nelle operazioni di ricerca vettoriale, sfruttando le capacità uniche delle GPU e affrontando le sfide inerenti agli algoritmi di ricerca basati sui grafi.
Ricerca con CAGRA
Il meccanismo di ricerca di CAGRA impiega un approccio metodico che utilizza una coda di priorità ordinata di dimensioni fisse per una navigazione efficiente nel grafo. Questo processo dettagliato è delineato da una serie di passi all'interno di un quadro strutturato:
Struttura di ricerca CAGRA
CAGRA opera con un buffer di memoria sequenziale che comprende un elenco interno di top-M e un elenco di candidati. L'elenco interno top-M agisce come una coda di priorità, la cui lunghezza è impostata su M (dove M ≥ k), assicurando che possa memorizzare i risultati più rilevanti fino al numero desiderato di vicini, k. La dimensione dell'elenco dei candidati è determinata da p × d, con p che rappresenta il numero di nodi sorgente esplorati in ogni iterazione e d che indica il grado del grafo. Ogni elemento di queste liste accoppia un indice di nodo con la distanza dall'interrogazione, consentendo una gestione efficiente della ricerca.
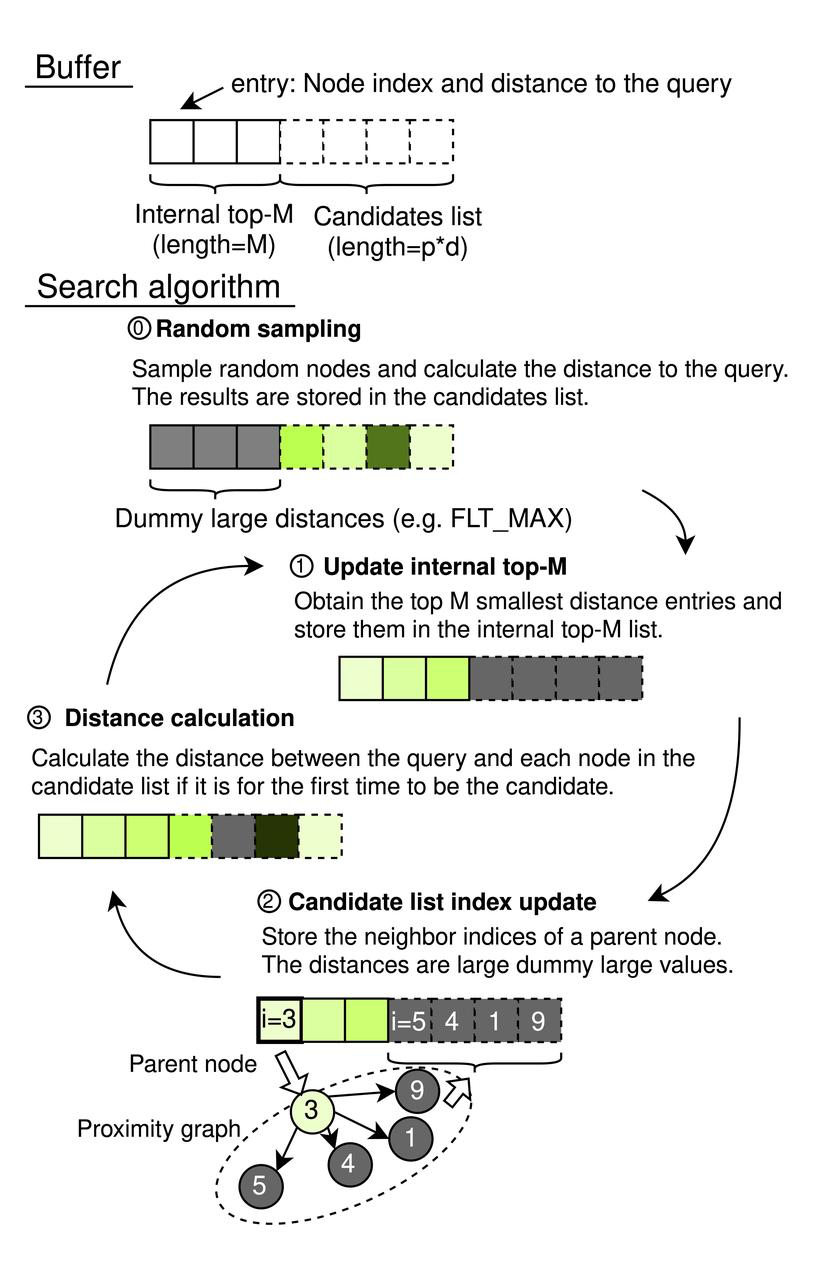 Processo di ricerca CAGRA
Processo di ricerca CAGRA
Fasi del processo di ricerca
- Campionamento casuale (inizializzazione)
- Utilizza un generatore pseudocasuale per selezionare indici di nodi casuali p × d, calcolando la distanza tra ciascun nodo e la query.
- I risultati popolano l'elenco dei candidati, mentre l'elenco top-M interno si inizializza con voci virtuali (impostate su FLT_MAX) per evitare di influenzare i risultati dell'ordinamento iniziale.
Aggiornamento dell'elenco Top-M interno: Selezionare i nodi Top-M in base alle distanze più piccole nell'intero buffer per includerli nell'elenco Top-M interno.
Aggiornamento dell'indice dell'elenco dei candidati (attraversamento del grafico):
- Identifica tutti i nodi vicini dei nodi top p dell'elenco top-M interno, escludendo i nodi usati in precedenza tramite un filtro a tabella hash.
- Aggiunge questi vicini all'elenco dei candidati senza ricalcolare le distanze in questa fase.
- Calcolo della distanza:
- Esegue il calcolo della distanza per i nodi che compaiono di recente nell'elenco dei candidati, evitando calcoli ridondanti per i nodi valutati nelle iterazioni precedenti.
- Assicura che i nodi vengano aggiunti all'elenco top-M solo se le loro distanze ne giustificano la rilevanza, in base al fatto che siano sufficientemente piccoli per appartenere o troppo grandi per essere considerati.
L'algoritmo esegue queste fasi in modo iterativo, passando in rassegna tutti i nodi dell'elenco top-M interno fino a quando non sono tutti serviti come punti di partenza per la ricerca. La ricerca si conclude con l'estrazione delle prime k voci dall'elenco top-M interno, fornendo i risultati della Approximate Nearest Neighbor Search (ANNS).
Prestazioni
La decisione di sfruttare gli indici su GPU è stata motivata principalmente da considerazioni sulle prestazioni. Abbiamo intrapreso una valutazione completa delle prestazioni di Milvus utilizzando uno strumento di benchmark open-source vector database, concentrandoci sul confronto tra gli indici HNSW, IVFFLAT basato su GPU e CAGRA.
Setup di benchmarking
Per una valutazione realistica, i nostri benchmark sono stati condotti su macchine ospitate da AWS e dotate di GPU NVIDIA T4 e A10G, garantendo che gli ambienti di test riflettessero le risorse comunemente disponibili. Le macchine selezionate avevano prezzi comparabili, in modo da fornire un campo di gioco uniforme per la valutazione delle prestazioni. Tutti i test miravano a raggiungere il top100@98% di richiamo, utilizzando come client un'istanza AWS m6i.4xlarge (16C64G).
 Informazioni di base sulla macchina selezionata
Informazioni di base sulla macchina selezionata
Approfondimenti sulle prestazioni
Prestazioni di piccoli lotti:
In situazioni di piccoli lotti di ricerca (dimensione del lotto di 1), in cui le GPU sono generalmente sottoutilizzate, CAGRA ha superato in modo significativo le sue controparti. I nostri test hanno rivelato che CAGRA è in grado di fornire prestazioni quasi 10 volte superiori a quelle dei metodi tradizionali in queste condizioni.
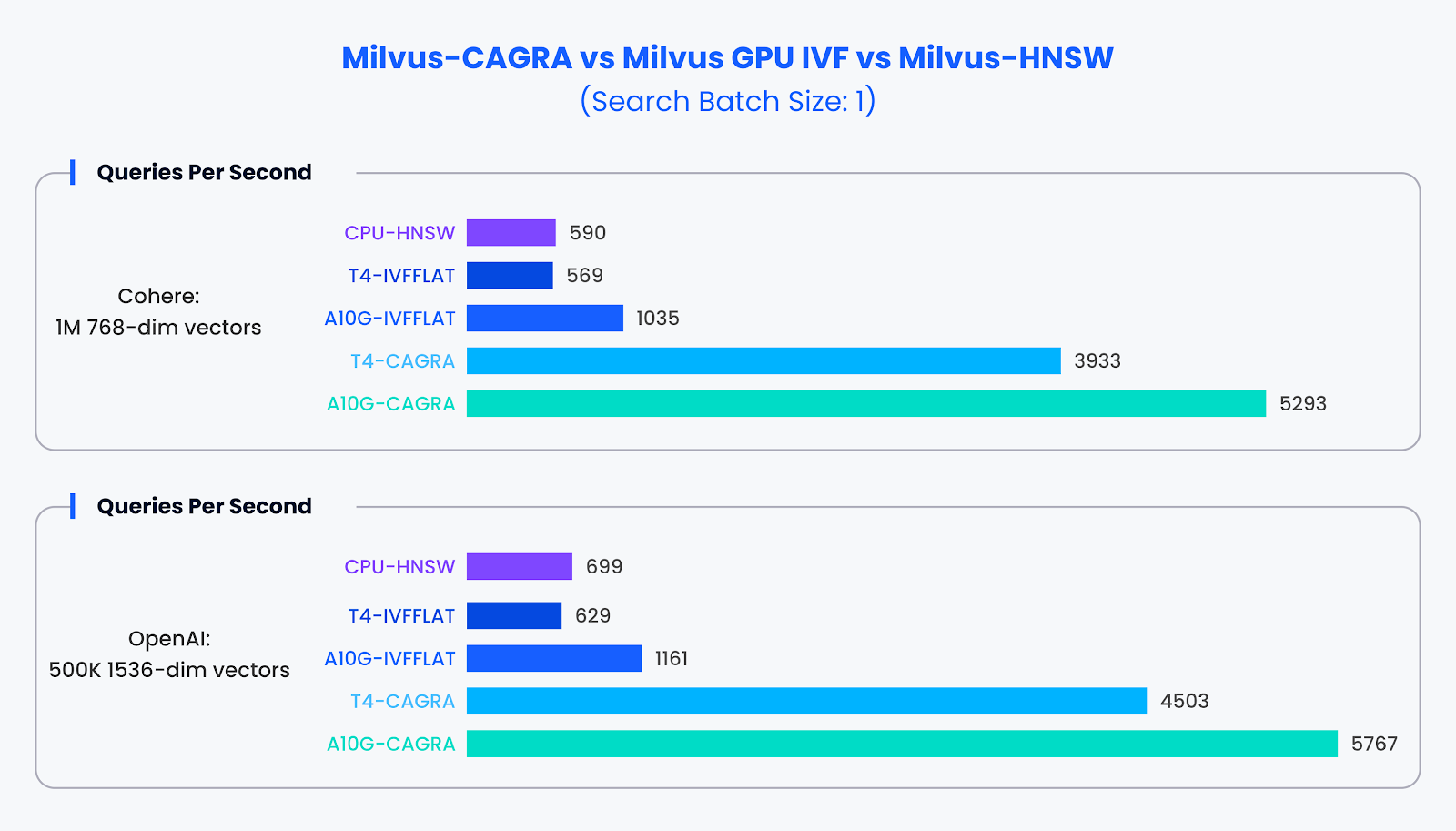 Confronto delle prestazioni per un set di dati di piccole dimensioni
Confronto delle prestazioni per un set di dati di piccole dimensioni
Prestazioni per grandi lotti:
Esaminando lotti di ricerca più grandi (dimensioni di 10 e 100), il vantaggio di CAGRA è diventato ancora più pronunciato. Rispetto a HNSW, CAGRA ha mostrato un notevole aumento delle prestazioni, migliorando l'efficienza della ricerca di decine di volte.
 Confronto delle prestazioni per set di dati di grandi dimensioni
Confronto delle prestazioni per set di dati di grandi dimensioni
Efficienza dell'edificio dell'indice:
Oltre alle capacità di ricerca, la competenza di CAGRA si estende alla costruzione di indici. Con l'accelerazione delle GPU, CAGRA ha dimostrato di essere in grado di costruire indici circa 10 volte più velocemente rispetto ai metodi alternativi.
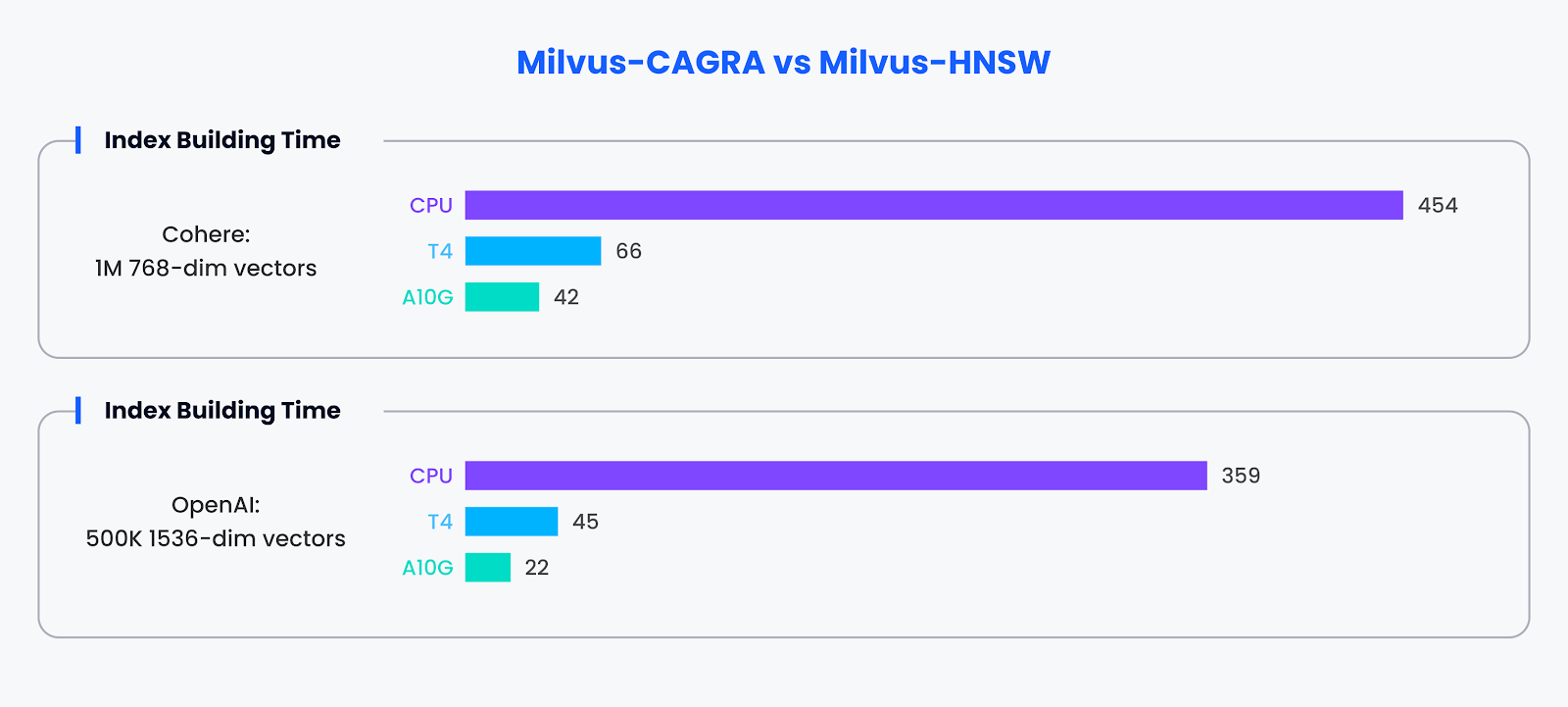 Confronto delle prestazioni per la costruzione di indici
Confronto delle prestazioni per la costruzione di indici
I risultati dei benchmark sottolineano i notevoli vantaggi in termini di prestazioni derivanti dall'adozione di indici accelerati dalle GPU come CAGRA in Milvus. Non solo è in grado di accelerare le attività di ricerca per tutte le dimensioni dei batch, ma migliora anche in modo significativo la velocità di costruzione degli indici, affermando il valore delle GPU nell'ottimizzazione delle prestazioni dei database vettoriali.
Cosa ci aspetta?
CAGRA segna un significativo balzo in avanti nel nostro tentativo di ridefinire i confini della ricerca vettoriale, mostrando il potenziale della ricerca basata su GPU per affrontare le sfide di produzione più impegnative. Per il futuro, Milvus intende approfondire gli aspetti di high recall, bassa latenza, efficienza dei costi e scalabilità della ricerca vettoriale. Il nostro impegno si estende oltre i risultati attuali per abbracciare una gestione dei dati più flessibile, funzionalità di ricerca arricchite e ottimizzazioni delle prestazioni rivoluzionarie.
Questa visione ci spinge a innovare continuamente, garantendo che Milvus sia leader e pioniere del futuro della ricerca accelerata per [dati non strutturati] (https://zilliz.com/glossary/unstructured-data). Spingendo i limiti di ciò che è possibile oggi, miriamo a sbloccare nuove possibilità per il domani, rendendo la ricerca vettoriale più potente, efficiente e accessibile.
 Consigli e trucchi pratici per gli sviluppatori che usano i database vettoriali.png
Non siete sicuri di quale indice scegliere per la vostra soluzione? Abbiamo un blog che vi aiuta a fare la scelta giusta!
Consigli e trucchi pratici per gli sviluppatori che usano i database vettoriali.png
Non siete sicuri di quale indice scegliere per la vostra soluzione? Abbiamo un blog che vi aiuta a fare la scelta giusta!

Continua a leggere

My Wife Wanted Dior. I Spent $600 on Claude Code to Vibe-Code a 2M-Line Database Instead.
Write tests, not code reviews. How a test-first workflow with 6 parallel Claude Code sessions turns a 2M-line C++ codebase into a daily shipping pipeline.

Migrating from S3 Vectors to Zilliz Cloud: Unlocking the Power of Tiered Storage
Learn how Zilliz Cloud bridges cost and performance with tiered storage and enterprise-grade features, and how to migrate data from AWS S3 Vectors to Zilliz Cloud.

Will Amazon S3 Vectors Kill Vector Databases—or Save Them?
AWS S3 Vectors aims for 90% cost savings for vector storage. But will it kill vectordbs like Milvus? A deep dive into costs, limits, and the future of tiered storage.