




Come Zilliz è finita al centro della storia dei dati non strutturati di NVIDIA al GTC 2026
Al NVIDIA GTC di quest’anno, in mezzo alla solita valanga di affermazioni su chip, sistemi e infrastrutture, Jensen Huang ha mostrato una slide che contava per un motivo diverso.
Non riguardava la prossima GPU. Non riguardava la dimensione dei modelli. Non riguardava nemmeno davvero l’inferenza.
Riguardava i dati.
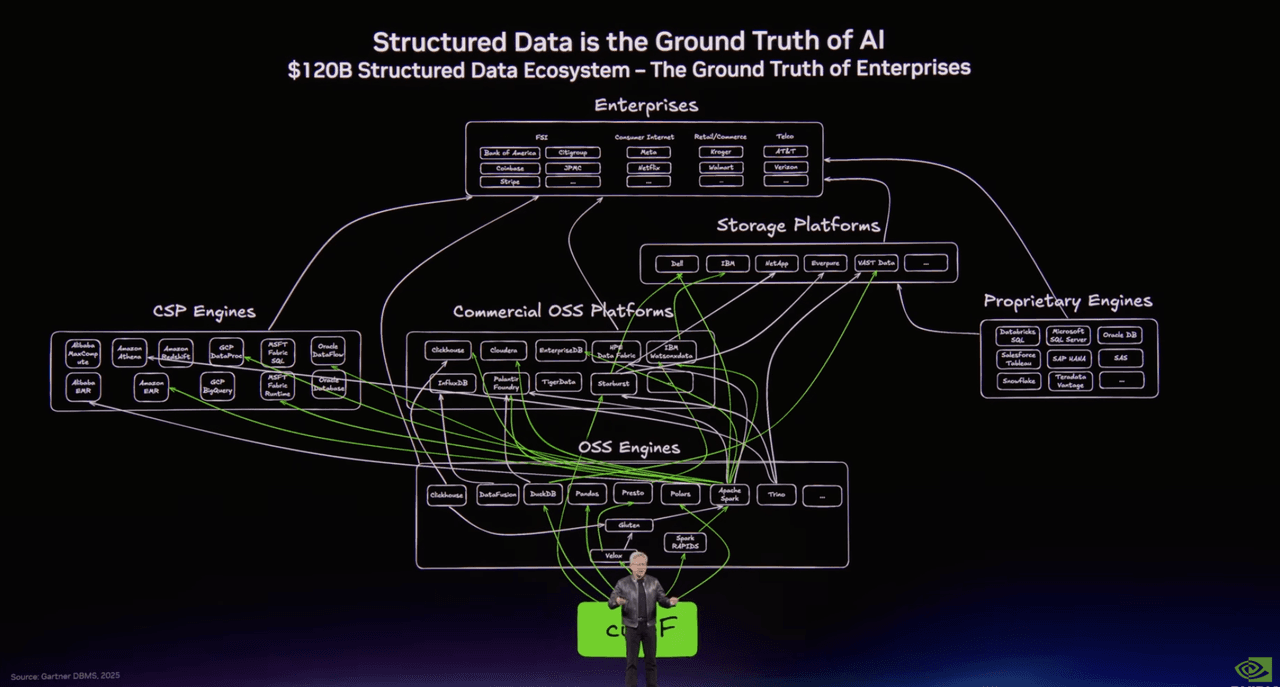
Una slide mappava il mondo dei dati strutturati: Spark, Presto, DuckDB, Polars, Snowflake, Databricks, BigQuery, i meccanismi familiari che alimentano analytics e data engineering da decenni.
Un’altra mappava lo stack emergente per i dati non strutturati. E lì, al centro di quella seconda immagine, c’erano Milvus nell’open source e Zilliz Cloud nel livello dei database enterprise.

Il titolo sulla slide diceva tutto: I dati non strutturati sono il contesto dell’AI.
È facile annuire davanti a quella frase. Certo, l’AI ha bisogno di contesto. Certo, la maggior parte dei dati aziendali è non strutturata. Certo, testo, immagini, video, audio, log, PDF e tutto il resto contano oggi più che mai. Ma una volta superato lo slogan, emerge una domanda più difficile: se i dati non strutturati stanno diventando il vero substrato dei sistemi di AI, che aspetto ha davvero l’infrastruttura per quel mondo?
Questa è la storia più interessante. Ed è il motivo per cui Milvus è passato dall’essere un database vettoriale specializzato a occupare una posizione molto più strategica nello stack dell’AI.
Perché Zilliz (Milvus) continua a comparire
Non era la prima volta che Zilliz compariva al GTC, e probabilmente non sarà l’ultima.
Molto prima che i database vettoriali diventassero un elemento costitutivo predefinito nei moderni sistemi di AI, Milvus è stato costruito attorno all’idea che la ricerca per similarità avrebbe dovuto operare a una scala molto diversa rispetto ai database tradizionali. L’accelerazione GPU non era un’aggiunta successiva. Faceva parte della logica progettuale fin dall’inizio.
Questo è diventato importante quando l’AI ha smesso di essere una storia di ricerca ed è diventata una storia di infrastruttura.
Al GTC 2023, Jensen Huang sottolineava già la maggiore integrazione tra le librerie di accelerazione di NVIDIA e sistemi come FAISS, Redis e Milvus. Un anno dopo, al GTC 2024, quella relazione è diventata più concreta con Milvus 2.4, che ha portato l’accelerazione GPU completa all’indicizzazione e alla ricerca vettoriale combinando le GPU NVIDIA con CAGRA di RAPIDS cuVS. Il risultato non è stato un’accelerazione cosmetica. In alcune configurazioni di benchmark, le prestazioni di ricerca sono migliorate fino a 50 volte rispetto a HNSW.
Quando è arrivato Milvus 2.6, la conversazione si era evoluta di nuovo. La domanda non era più se l’accelerazione GPU fosse importante. Era come usarla in modo efficiente dal punto di vista dei costi. Milvus 2.6 ha introdotto modelli di deployment più flessibili per CAGRA, incluse architetture ibride GPU-CPU che usano la GPU per la costruzione del grafo e la CPU per il recupero. Questo conta perché la maggior parte delle aziende non vuole il sistema più veloce possibile a qualsiasi prezzo. Vuole un sistema che resti abbastanza veloce pur rimanendo economicamente sensato.
Vale la pena soffermarsi su questo dettaglio, perché dice qualcosa di più ampio sul perché Milvus sia diventato importante. Non è solo una storia sulle prestazioni della ricerca vettoriale. È una storia su ciò che accade quando il recupero vettoriale smette di essere una funzionalità sperimentale e diventa parte dell’infrastruttura di produzione.
Cosa serve per far funzionare la ricerca vettoriale in produzione
La velocità da sola smette di essere la storia.
Ma quando il recupero vettoriale esce dalle demo ed entra nei sistemi reali, la velocità da sola smette di essere il punto centrale.
La domanda più difficile è che cosa serva per rendere il recupero pratico su scala enterprise, senza trasformare lo stack circostante in un groviglio di pipeline fragili, alta pressione sulla memoria e costi infrastrutturali crescenti.
Parte di questa sfida inizia a monte. Nel vecchio modello, trasformare un PDF, un'immagine o un documento in qualcosa di ricercabile significava di solito mettere insieme un livello di parsing separato, logiche di chunking, servizi di embedding e scritture nel database. Il sistema di recupero iniziava a funzionare solo dopo che una lunga catena di preprocessing aveva già completato il proprio lavoro. Milvus 2.6 ha iniziato a superare quel confine con un approccio Data-in, Data-out, consentendo di scrivere contenuti grezzi direttamente nel sistema e di generarne gli embedding all'interno del database stesso.
Parte di essa si colloca all'interno del livello di recupero. Carichi di lavoro diversi richiedono compromessi diversi, quindi è necessario supportare più tipi di indice invece di imporre un'unica strategia di recupero a ogni caso d'uso. Anche la compressione entra nell'equazione. Funzionalità come Int8 e RaBitQ non sono aggiunte appariscenti, ma affrontano un obiettivo più importante: ridurre la pressione sulla memoria e i costi senza sacrificare la qualità del recupero.
E parte di essa è semplicemente operativa. Milvus ha introdotto un'architettura di write-ahead logging riprogettata che ha eliminato la necessità di Kafka e Pulsar dallo stack, riducendo sia la complessità sia l'overhead. Questo tipo di ingegneria raramente finisce nei titoli, ma è esattamente quello che determina se un'infrastruttura resta interessante in teoria o diventa utilizzabile nella pratica.
Lo storage si rivela un'altra linea di frattura.
Man mano che i sistemi di IA crescono, cresce anche il costo di fingere che tutti i dati debbano essere trattati allo stesso modo, sempre. Su una grande piattaforma multi-tenant, solo una piccola parte dei dati può essere effettivamente attiva in un dato giorno. La maggior parte resta fredda. Ma le architetture tradizionali a caricamento completo continuano a trattare tutto come se meritasse la stessa residenza locale, lo stesso profilo prestazionale e la stessa impronta di costo.
Su piccola scala, questo appare inefficiente. Su scala enterprise, diventa difficile da giustificare.
Milvus 2.6 ha affrontato questo problema con lo storage a livelli. I dati caldi restano locali, dove la latenza conta. I dati freddi vengono caricati su richiesta da object storage a costo inferiore. E il confine tra i due si sposta dinamicamente in base all'utilizzo effettivo del sistema. Sembra una modesta ottimizzazione di sistema. In pratica, cambia l'economia del recupero. Quando i dati giusti risiedono nel livello giusto, i costi di storage possono diminuire di oltre il 70 percento.
Niente di tutto questo è particolarmente glamour. Ma di solito è così che l'infrastruttura matura: non attraverso una singola svolta spettacolare, ma tramite una serie di decisioni progettuali che rendono il sistema più veloce, più economico e più facile da gestire.
E tutte queste funzionalità sono disponibili in Zilliz Cloud, il servizio completamente gestito di Milvus.
Il vero problema dei dati non strutturati
Il cambiamento più grande, però, non riguarda davvero solo Milvus. Riguarda il tipo di dati da cui ora dipendono i sistemi di IA.
I dati strutturati si sono evoluti in modo lungo e ordinato. Righe, colonne, schemi, indici, warehouse, motori di query. Gli strumenti sono maturati nel corso di decenni perché i dati stessi si adattavano alle ipotesi su cui quei sistemi erano stati costruiti. Sapevi com'era fatto un record. Sapevi quali campi interrogare. Sapevi come indicizzarli.
I dati non strutturati rompono questo modello.
Un contratto non è una riga. Né lo è un'immagine medica, una trascrizione di supporto, un repository di codice o un feed di sorveglianza. Questi oggetti possono essere archiviati, ma archiviarli è la parte facile. La parte difficile è renderli ricercabili in un modo che comprenda il significato anziché corrispondenze esatte tra campi.
Ecco perché gli embedding hanno cambiato tutto. Una volta che testo, immagini, audio e altre forme di contenuto potevano essere mappati in uno spazio vettoriale ad alta dimensionalità, il recupero non doveva più dipendere da corrispondenze simboliche esatte. I sistemi potevano recuperare per similarità, intento e contesto.
Quella è stata la svolta.
È stata anche l'inizio di un nuovo problema infrastrutturale.
Una volta che i dati non strutturati diventano interrogabili, le aziende si trovano immediatamente ad affrontare l'economia della scala. Milioni di documenti diventano centinaia di milioni di embedding. Un aggiornamento del modello significa re-incorporare il corpus storico. La qualità del recupero dipende dalla qualità dell'indice. La latenza conta in produzione. Così come il costo dello storage. Così come l'onere operativo di mantenere tutto questo sincronizzato.
In altre parole, il recupero semantico ha risolto il problema dell'accesso, ma ha esposto il problema dei sistemi.
Questo è il contesto in cui Milvus ha senso.
Perché un database vettoriale non era sufficiente
Per la prima ondata di aziende AI-native, la risposta era semplice: usare un database vettoriale come livello di recupero, collegarlo a un modello e costruire l'applicazione da lì. Quel modello funzionava, e funziona ancora, soprattutto quando la ricerca semantica è il nucleo del prodotto.
Ma le grandi imprese tendono a scontrarsi con un muro diverso.
Il problema non è se riescono a far funzionare la ricerca vettoriale. Il problema è ciò che accade dopo.
I file grezzi vivono nell'object storage o nei data lake. Gli embedding vivono in un database vettoriale. I metadati vivono in un sistema relazionale. L'elaborazione offline avviene altrove. I log di ricerca si accumulano in un'altra pipeline. Poi il modello di embedding cambia, o cambia la logica di ranking, o la knowledge base ha bisogno di curazione, o qualcuno vuole tracciare perché un sistema di recupero continua a fallire sui casi limite. All'improvviso, il sistema non è più un unico sistema. È un mosaico.
Quel mosaico crea tre problemi familiari.
- Il primo sono i silos di dati. I dati necessari per eseguire una funzione AI sono distribuiti su più sistemi, ciascuno con il proprio formato, ciclo di vita e modello operativo.
- Il secondo è il costo dell'iterazione. Quando un modello di embedding cambia, la riscrittura non è incrementale per impostazione predefinita. Può diventare uno sforzo di reindicizzazione e migrazione lungo mesi.
- Il terzo è il ciclo interrotto tra servizio online e miglioramento offline. Il sistema serve query in produzione, ma i segnali che potrebbero migliorarlo, output di deduplicazione, etichette di clustering, punteggi di qualità e analisi dei fallimenti, spesso vivono in ambienti separati e non rifluiscono mai in modo pulito nel livello di recupero.
È a quel punto che acquistare un database vettoriale smette di sembrare la risposta e inizia a sembrare l'inizio di una questione architetturale più ampia.
Se il vero problema è il miglioramento continuo su larga scala, allora l'architettura deve cambiare.
Da database vettoriale ad AI Lakebase
Prima del boom dell'AI, Databricks ha contribuito a rendere popolare il modello Lakehouse, eliminando la scomoda separazione tra data lake e data warehouse. Invece di mantenere sistemi separati per storage, analytics ed elaborazione su larga scala, le aziende potevano lavorare da una base più unificata.
L'era dell'AI sta imponendo un ripensamento simile, ma intorno ai dati non strutturati.
Se osservi attentamente i diagrammi infrastrutturali che Jensen Huang sta usando, il baricentro si sta spostando. Nell'era dei dati strutturati, framework come Spark erano al cuore della pipeline. Nell'era dei dati non strutturati, infrastrutture vettoriali come Milvus stanno iniziando a ricoprire quel ruolo. Non perché la ricerca vettoriale sia l'unica cosa che conta, ma perché si trova sempre più spesso all'incrocio tra dati grezzi, embedding, indici e recupero applicativo.
Questo apre una possibilità più ampia: e se il recupero vettoriale non fosse trattato come un livello di serving separato, aggiunto lateralmente allo stack? E se fosse integrato direttamente con il data lake aziendale e con i workflow di dati circostanti?
Architettura AI Lakebase
Questa è l’idea alla base di AI Lakebase.
Lo scopo di AI Lakebase non è aggiungere un’ennesima categoria di prodotto a un mercato già affollato. Lo scopo è sostituire un modello frammentato con uno più coerente.
- Alla base si trova un livello di storage unificato. Una parte di quei dati risiede in collection native di Zilliz ottimizzate per il recupero vettoriale ad alte prestazioni. Un’altra parte rimane nei formati aperti che l’azienda già utilizza, Iceberg, Lance, Paimon e file grezzi in object storage. La parte importante è che i dati non devono essere copiati in cinque sistemi diversi solo per diventare utilizzabili.
- Sopra questo si trova il livello di serving di produzione, progettato per il recupero in tempo reale. In Zilliz Cloud, ciò significa cluster di serving basati su Cardinal, ottimizzati per una latenza nell’ordine dei millisecondi, con diverse modalità per prestazioni, capacità e posizionamento dei dati hot-cold a livelli. In pratica, ciò significa che i dati consultati di frequente restano locali mentre i dati freddi vengono caricati su richiesta da storage meno costoso. Il risultato non è solo una migliore progettazione del sistema. È controllo dei costi.
- Poi c’è il livello di calcolo elastico: cluster on-demand per ETL, deduplicazione, clustering, analisi della qualità dei dati, re-embedding, valutazione e indagine interattiva. Non sono sistemi laterali incollati successivamente. Fanno parte della stessa base.
Tutti e tre i livelli condividono gli stessi dati invece di mantenere più copie disconnesse.
Sembra una storia di razionalizzazione architetturale, e lo è. Ma è più di questo.
Ma il punto più importante è ciò che quell’architettura rende possibile.
AI Lakebase è più di una razionalizzazione architetturale
La maggior parte dei sistemi di AI oggi è in grado di servire. Molti meno sono in grado di migliorare sistematicamente.
Di solito non è perché il modello è sbagliato. È perché l’infrastruttura intorno a esso rende il feedback costoso.
Un sistema di produzione genera segnali costantemente. Ogni query ti dice qualcosa. Ogni recupero fallito ti dice qualcosa. Ogni risposta di bassa qualità, ogni risultato ripetuto, ogni interazione senza sbocco, ogni cluster di documenti simili, ogni chunk rumoroso nel corpus, sono tutte informazioni che potrebbero essere usate per migliorare il sistema.
Ma nella maggior parte degli stack, questi segnali sono dispersi tra log di serving, pipeline offline, notebook, dashboard e script una tantum. Il sistema funziona, ma non impara davvero dalla propria esperienza.
Il framework di AI Lakebase per risolvere questo problema è Continuous Serving/Continuous Discovery (AI CS/CD).
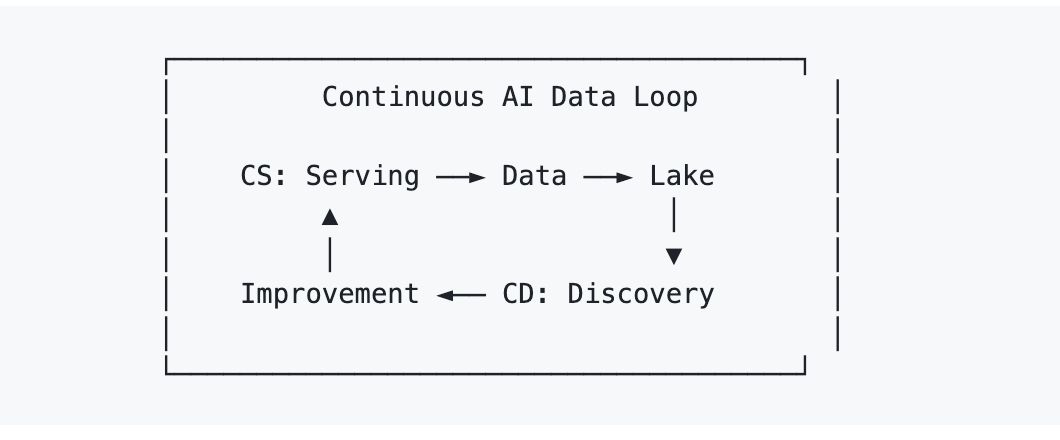
- Continuous Serving è la parte ovvia: il sistema live gestisce recupero e generazione in produzione.
- Continuous Discovery è la parte meno ovvia: il sistema analizza continuamente ciò che ha accumulato, gap di copertura, modalità di errore, struttura dei cluster, problemi di qualità dei dati, e scrive i miglioramenti risultanti nello stesso ambiente operativo.
Questo è importante perché, una volta che serving e discovery condividono la stessa base dati, i miglioramenti smettono di sembrare migrazioni e iniziano a sembrare iterazioni. I risultati della deduplicazione possono confluire nel recupero live. I punteggi di qualità possono influenzare il ranking in produzione. Le etichette dei cluster possono diventare segnali di recupero. Il re-embedding può avvenire in modo incrementale tramite calcolo elastico invece che come un enorme evento tutto in una volta.
L’architettura inizia a comportarsi meno come un database statico e più come un ciclo vivente di miglioramento.
Questo è un cambiamento molto più rilevante di “database vettoriale, ma più veloce.”
Scalare rapidamente e iterare rapidamente con AI Lakebase
Molte aziende infrastrutturali possono affermare di offrire scalabilità. Molte possono affermare di offrire velocità. Meno possono affermare in modo plausibile di offrire sia scalabilità sia iterazione continua nello stesso sistema.
Zilliz sostiene che la prossima fase dell’infrastruttura AI enterprise richiede entrambe.
- Scale Fast significa infrastruttura multi-regione e multi-cloud in grado di supportare carichi di lavoro di produzione su scala molto ampia, non solo esecuzioni di benchmark o ambienti demo.
- Iterate Fast significa che il sistema è progettato in modo che la scoperta offline e il serving online facciano parte dello stesso ciclo operativo. Il miglioramento è integrato, non aggiunto a posteriori.
Questa distinzione è importante perché l’AI in produzione fallisce in due modi opposti. Alcuni sistemi scalano ma ristagnano. Diventano grandi, costosi e sempre più difficili da migliorare. Altri iterano rapidamente in ambienti piccoli ma non diventano mai sistemi di produzione solidi. Il vero obiettivo non è nessuno dei due. È un sistema che possa crescere e imparare simultaneamente.
Questa è la promessa alla base del passaggio dal database vettoriale all’AI Lakebase.
Il database vettoriale non scompare in questa transizione. Conta ancora. È ancora il motore di serving per il retrieval in tempo reale. Ma smette di essere il punto di arrivo dell’architettura. Diventa un livello in un sistema più ampio, proprio come i database relazionali esistono ancora in un mondo Lakehouse senza definire da soli l’intera architettura.
E questo potrebbe essere il modo più utile per interpretare la frase di Jensen Huang al GTC.
Se i dati non strutturati sono il contesto dell’AI, allora il limite massimo delle applicazioni AI sarà determinato non solo dai modelli, ma da quanto matura diventerà l’infrastruttura per i dati non strutturati.
Quell’infrastruttura è ancora incompleta. Il mercato è ancora agli inizi. Ma il profilo sta iniziando a delinearsi.
E sempre più spesso, Milvus si trova proprio al centro di tutto questo.
Restate sintonizzati!
AI Lakebase sarà l’aggiornamento architetturale alla base di Milvus 3.0 e una grande evoluzione di Zilliz Cloud. Se volete dare uno sguardo in anteprima alla direzione che sta prendendo, contattateci per l’accesso anticipato.
Continua a leggere

Our Journey to 35K+ GitHub Stars: The Real Story of Building Milvus from Scratch
Join us in celebrating Milvus, the vector database that hit 35.5K stars on GitHub. Discover our story and how we’re making AI solutions easier for developers.

Why Not All VectorDBs Are Agent-Ready
Explore why choosing the right vector database is critical for scaling AI agents, and why traditional solutions fall short in production.

Bringing AI to Legal Tech: The Role of Vector Databases in Enhancing LLM Guardrails
Discover how vector databases enhance AI reliability in legal tech, ensuring accurate, compliant, and trustworthy AI-powered legal solutions.