




Le Fuzz Testing expliqué : Découvrir les failles cachées dans les logiciels

TL ; DR : Le fuzz testing (ou fuzzing) est une technique de test de logiciels qui consiste à introduire de grandes quantités de données aléatoires ou inattendues ("fuzz") dans un programme afin d'identifier les bogues, les pannes ou les vulnérabilités. En exposant le comportement du système dans des conditions inattendues, les tests fuzz permettent de découvrir des cas limites, des failles de sécurité et des faiblesses que les tests traditionnels risquent de ne pas voir. Il est couramment utilisé pour améliorer la fiabilité et la sécurité des logiciels, en particulier dans les systèmes qui traitent des données complexes comme les services web, les analyseurs de fichiers et les API.
Le Fuzz Testing expliqué : Découvrir les failles cachées dans les logiciels
Qu'est-ce que le Fuzz Testing ?
Le Fuzz Testing est une méthode de test de logiciels qui permet de trouver des bogues cachés en introduisant des données inattendues ou aléatoires dans un programme pour voir comment il réagit. En provoquant délibérément des situations inhabituelles ou "floues", cette technique de test permet de découvrir des vulnérabilités que les tests habituels pourraient manquer, en particulier dans les logiciels complexes ou sensibles sur le plan de la sécurité.
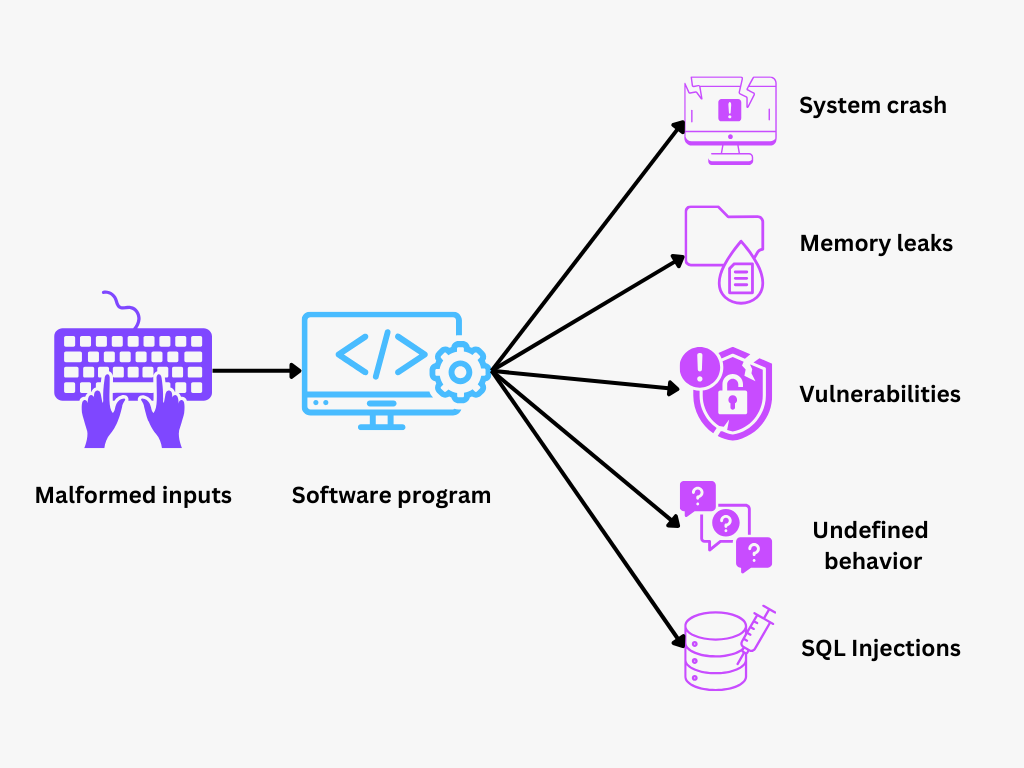 Figure- Fuzz Testing.png
Figure- Fuzz Testing.png
Figure: Fuzz Testing
Histoire du Fuzz Testing
Les tests Fuzz sont nés d'une découverte accidentelle à la fin des années 1980. Le professeur Barton Miller de l'université du Wisconsin expérimentait des programmes informatiques en réseau lorsqu'il a remarqué des pannes inattendues causées par un bruit d'entrée aléatoire. Cela l'a amené à approfondir ses recherches, en introduisant intentionnellement des données aléatoires dans divers programmes afin d'observer leurs réactions. Il a découvert que de nombreuses applications étaient vulnérables à ces entrées aléatoires, révélant des faiblesses en matière de sécurité et des problèmes de stabilité. Les travaux de Miller ont jeté les bases du fuzz testing, qui s'est imposé comme une méthode efficace pour découvrir les bogues et les vulnérabilités des logiciels.
Comment fonctionne le Fuzz Testing ?
Les tests Fuzz introduisent des données aléatoires, inattendues ou invalides (entrées "fuzzées") dans un programme afin d'évaluer son comportement et de découvrir d'éventuels bogues. Cette approche force le programme dans des états imprévisibles, révélant souvent des bogues ou des vulnérabilités que les tests traditionnels pourraient manquer. L'idée est de voir comment un logiciel sain tient le coup sous le stress d'entrées inattendues sans se planter ou se comporter de manière inattendue.
Phases du Fuzz Testing
Le processus de fuzz testing se compose d'étapes qui permettent d'identifier, de tester et d'analyser les problèmes au sein d'un système cible.
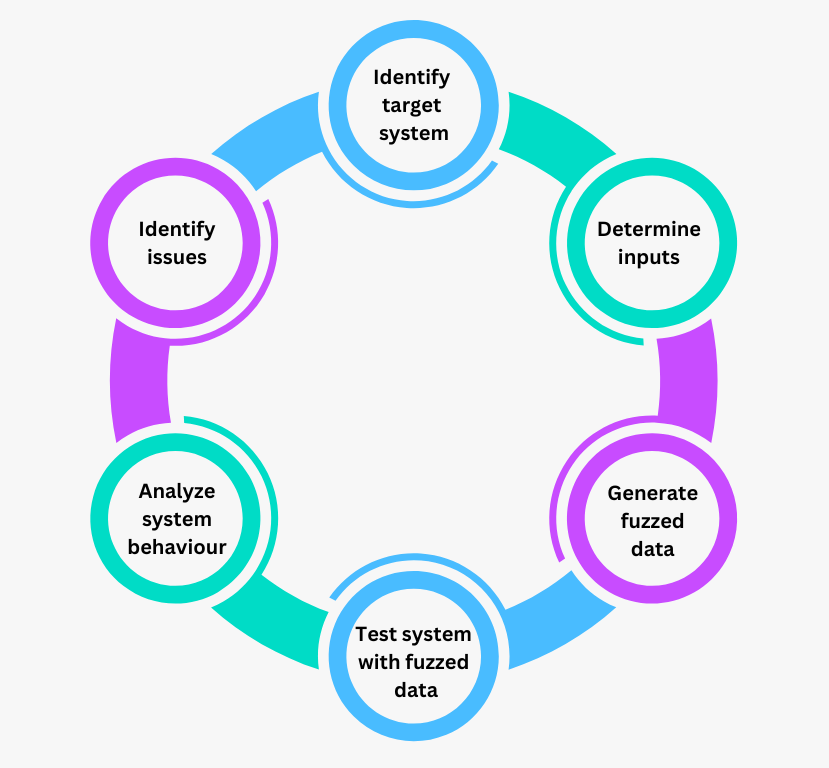 Figure- Phases du test Fuzz.png
Figure- Phases du test Fuzz.png
Figure: Phases du test Fuzz
Identifier le système cible
La première étape du fuzz testing est de choisir le programme ou le composant que vous voulez tester. Il peut s'agir d'une application, d'une fonction au sein d'un système plus étendu, ou même d'un champ de saisie spécifique.
Déterminer les entrées
Une fois le système cible identifié, l'étape suivante consiste à déterminer le type d'entrées qui seront testées. Il s'agit de comprendre les formats de données ou les types d'entrées que le système traite habituellement. Par exemple, si le système cible traite des paquets réseau, les entrées peuvent consister en diverses structures de paquets. Les testeurs jettent les bases de la création de données floues pertinentes en définissant des entrées pertinentes.
Générer des données floues
Dans cette phase, le moteur de fuzzing crée une variété d'entrées inattendues ou invalides. Ces entrées peuvent être générées de manière aléatoire, des formes mutées de données valides ou des séquences élaborées qui simulent des cas limites. L'objectif est de produire des entrées qui peuvent mettre à l'épreuve les limites du système cible pour déceler d'éventuelles faiblesses dans son traitement des données inattendues.
Système de test avec des données floues
Les données floues générées sont ensuite introduites dans le système cible. Au cours de cette phase, le système interagit avec chaque entrée et répond aux données inhabituelles ou invalides. En raison de l'exposition répétée du système à diverses entrées, les tests fuzz révèlent les points où le système ne répond pas correctement ou tombe en panne.
Analyser le comportement du système
Au fur et à mesure que le système traite chaque entrée, son comportement est étroitement surveillé. Les testeurs recherchent des signes d'activité anormale, tels que des plantages, des comportements non réactifs ou des messages d'erreur inattendus. Cette phase permet d'identifier les vulnérabilités ou les faiblesses potentielles qui pourraient être exploitées dans un scénario réel.
Identifier les problèmes
Enfin, toutes les anomalies détectées au cours des tests sont examinées afin de déterminer si elles indiquent des problèmes réels. Les testeurs analysent le comportement observé à l'aide d'outils de débogage, afin d'identifier la cause première de chaque défaillance.
Types de tests Fuzz
Le fuzz testing se présente sous différentes formes, chacune avec des stratégies et des applications distinctes. Voici une décomposition des principaux types et catégories de fuzz testing :
1. Fuzzing basé sur les entrées
Ce type de fuzzing se concentre sur la génération de diverses entrées afin de tester la manière dont un programme traite différentes données. Il comprend deux approches principales :
Mutation-Based Fuzzing: Cette méthode altère les échantillons de données existants en y apportant des modifications aléatoires. Par exemple, le fuzzing basé sur la mutation peut ajouter des caractères inattendus, intervertir des sections ou changer des valeurs si l'entrée est un fichier texte. L'idée est de prendre des données d'entrée connues et valides et de créer de nouvelles versions légèrement "mutées", qui peuvent révéler des vulnérabilités tout en conservant une certaine ressemblance avec des données réalistes.
Fuzzing basé sur la génération:** Contrairement au fuzzing basé sur la mutation, le fuzzing basé sur la génération construit des entrées à partir de zéro. Il utilise des règles et des structures prédéfinies pour créer de nouvelles données qui imitent des formats ou des protocoles spécifiques. Par exemple, le fuzzing basé sur la génération peut construire des fichiers XML avec différentes structures, balises et valeurs d'attributs s'il s'agit de tester un analyseur XML.
2. Fuzzing conscient de la structure
Le fuzzing sensible à la structure comprend la structure sous-jacente des données testées. Au lieu de fournir des données aléatoires ou modifiées, il maintient le format correct ou la structure du protocole tout en faisant varier le contenu.
- Protocol Fuzzing: Une application typique du fuzzing structurel, le fuzzing de protocole est utilisé pour tester les protocoles de réseau en générant des entrées qui se conforment à des normes de communication spécifiques (comme HTTP ou TCP/IP).
3. Fuzzing guidé par la couverture
Le fuzzing guidé par la couverture utilise le retour d'information de l'exécution du programme pour générer de nouvelles entrées. Il suit les mesures de couverture du code pour identifier les parties du code qui ont été exécutées avec chaque entrée, puis crée des entrées qui visent à couvrir les chemins de code non testés. Cette approche est très efficace pour réaliser des tests approfondis, car elle maximise la couverture du code, ce qui augmente les chances de découvrir des bogues et des vulnérabilités cachés.
4. Fuzzing boîte noire, boîte blanche et boîte grise
Ces catégories diffèrent en fonction de la quantité d'informations dont dispose le testeur sur le logiciel cible :
Black-Box Fuzzing: Dans le cas du black-box fuzzing, le testeur n'a aucune connaissance interne du programme. Les entrées sont générées de manière aléatoire et introduites dans le logiciel sans tenir compte de la structure ou du code du programme. Le black-box fuzzing est simple à mettre en place et ne nécessite pas de code source. Il permet de tester les applications à code source fermé, même s'il ne permet pas de découvrir autant de problèmes que d'autres méthodes.
White-Box Fuzzing: Le testeur a un accès complet au code source du programme dans le cas du white-box fuzzing. Cela permet au processus de fuzzing de cibler des parties spécifiques du code, en utilisant des techniques telles que l'analyse statique et le suivi du flux de contrôle pour guider la génération d'entrées. Le fuzzing en boîte blanche est plus précis et permet de découvrir des bogues complexes, mais il nécessite une connaissance détaillée du code, ce qui le rend plus gourmand en ressources.
Fuzzing en boîte grise:** Le fuzzing en boîte grise est un équilibre entre les approches en boîte noire et en boîte blanche. Les testeurs ont un accès partiel au fonctionnement interne du programme, généralement par le biais d'instruments qui fournissent des informations sur la couverture du code. Cette approche bénéficie de l'efficacité du fuzzing boîte noire avec l'aide supplémentaire de la couverture du code.
5. Fuzzing hybride
Le fuzzing hybride combine plusieurs stratégies de fuzzing pour améliorer la profondeur et l'efficacité des tests. Par exemple, il peut combiner le fuzzing basé sur la mutation avec des techniques guidées par la couverture pour maximiser la couverture du code tout en explorant une gamme plus large de variations d'entrée. Ainsi, les testeurs peuvent cibler des logiciels complexes avec une plus grande précision pour trouver des vulnérabilités qui pourraient être manquées par une seule méthode de fuzzing.
Cas d'utilisation du Fuzz Testing
Les tests fuzz ont des applications diverses dans tous les secteurs, en particulier lorsque la sécurité, la stabilité et la résilience sont essentielles. Voici quelques-uns des principaux cas d'utilisation des tests Fuzz :
1. Tests de sécurité
L'une des applications les plus courantes des tests fuzz est le test de sécurité. En introduisant des entrées aléatoires ou mal formées dans un programme, les tests fuzz peuvent révéler des vulnérabilités que les pirates pourraient exploiter, telles que des débordements de mémoire tampon, des défauts de validation des entrées et des vulnérabilités d'injection.
2. Robustesse des logiciels
Les tests Fuzz améliorent également la robustesse des logiciels en s'assurant que les applications peuvent traiter des données inattendues ou malformées sans tomber en panne. De nombreux programmes sont conçus en fonction d'attentes spécifiques en matière d'entrées, mais les données du monde réel ne sont pas toujours prévisibles. En testant avec diverses entrées inattendues, les tests fuzz peuvent mettre en évidence les zones où le logiciel pourrait échouer sous contrainte, en particulier pour les applications qui s'exécutent dans des environnements imprévisibles ou qui traitent des données diverses.
3. Test de protocole
Le fuzzing de protocole est largement utilisé pour tester la résilience des protocoles de réseau. Les protocoles de réseau définissent les règles d'échange de données entre les appareils, et toute faiblesse dans ces protocoles peut entraîner des failles de sécurité ou des perturbations. En testant les protocoles réseau par fuzzing, les testeurs peuvent évaluer la façon dont ces protocoles traitent les paquets inattendus ou malformés afin d'identifier les vulnérabilités qui pourraient affecter l'intégrité des données, la sécurité ou la fiabilité de la communication.
4. Tests automobiles et IoT
Dans les systèmes automobiles, les tests fuzz peuvent révéler des vulnérabilités dans la communication entre les sous-systèmes de la voiture, afin de s'assurer qu'ils restent opérationnels et sûrs. De même, pour les appareils IoT, les tests fuzz sont essentiels pour confirmer que ces appareils peuvent gérer une gamme de conditions de réseau et d'entrées de données sans compromettre la fonctionnalité ou la sécurité.
Avantages du Fuzz Testing
Découverte précoce de bogues et de vulnérabilités cachés: Les tests Fuzz révèlent des bogues que les méthodes de test traditionnelles peuvent manquer, en particulier ceux qui sont déclenchés par des scénarios d'entrée rares ou inattendus.
**En exposant le logiciel à diverses entrées, y compris des données malformées ou inattendues, les tests fuzz aident les développeurs à identifier les points faibles et à renforcer le logiciel contre les conditions du monde réel.
Mesures de sécurité renforcées: Les tests fuzz permettent de détecter les vulnérabilités susceptibles d'être exploitées pour des attaques, telles que les débordements de mémoire tampon, les fuites de mémoire et les failles d'injection. Il permet donc aux équipes de sécurité de remédier de manière proactive à ces faiblesses afin de protéger le logiciel contre les cyberattaques potentielles et les accès non autorisés.
**Le fuzzing guidé par la couverture garantit que même les parties du code les moins fréquemment utilisées sont testées, ce qui permet de découvrir des bogues dans les chemins rarement exécutés. Cette approche de test étendue améliore la qualité et la stabilité globales du logiciel en explorant des chemins de code qui pourraient autrement être négligés.
Défis et limites du Fuzz Testing
Complexité dans la manipulation de données complexes: Les tests Fuzz ont des difficultés avec les programmes complexes, avec état, qui s'appuient sur des formats de données complexes, ce qui rend difficile la génération d'entrées adéquates sans casser la structure des données. Par exemple, dans les tests de protocoles ou de formats de fichiers, le fuzzing nécessite la connaissance de la structure, ce qui ajoute de la complexité et requiert des techniques de fuzzing avancées.
Contraintes de ressources et de temps : Le fuzzing à grande échelle peut consommer une puissance de traitement et une mémoire importantes, ce qui le rend gourmand en ressources. De longues durées d'exécution sont souvent nécessaires pour produire des résultats significatifs, en particulier pour les applications complexes, ce qui peut retarder le processus de test et de développement.
Limites de la génération d'entrées aléatoires: Le test Fuzz repose sur des entrées aléatoires ou semi-aléatoires, qui n'atteignent pas toujours les parties les plus profondes du code, en particulier dans les programmes complexes avec une logique ou des dépendances compliquées. En outre, le fuzzing purement aléatoire ne permet pas de cibler des vulnérabilités spécifiques, de sorte que des bogues dans certains chemins de code peuvent ne pas être détectés.
Difficulté à reproduire les problèmes: Les tests fuzz peuvent révéler des bogues obscurs, mais il peut être difficile de reproduire les conditions exactes qui ont déclenché ces bogues. Le débogage devient plus compliqué lorsque l'entrée spécifique ou la séquence d'événements qui a causé le problème ne peut pas être facilement reproduite.
Les faux positifs et le bruit dans les résultats: Les tests Fuzz peuvent produire un grand volume de données, avec certains résultats indiquant des problèmes qui ne sont pas des vulnérabilités réelles, connus sous le nom de faux positifs. Filtrer les faux positifs et se concentrer sur les véritables vulnérabilités peut prendre du temps et nécessiter une certaine expertise.
Surveillance et analyse permanentes: Le test de fuzz n'est pas un processus ponctuel ; il nécessite une surveillance permanente. De plus, un fuzzing efficace nécessite l'interprétation de journaux et de résultats détaillés, ce qui requiert un personnel qualifié pour analyser et traiter les problèmes détectés.
Outils et cadres de test de fuzz
AFL (American Fuzzy Lop): Connu pour son efficacité dans le fuzzing basé sur la mutation, AFL utilise une combinaison de mutation d'entrée intelligente et de retour d'information sur la couverture du code pour découvrir les vulnérabilités.
libFuzzer: Un fuzzer guidé par la couverture conçu pour les bibliothèques et les applications, libFuzzer génère des entrées qui visent la couverture du code pour découvrir les bogues cachés dans les logiciels complexes.
OSS-Fuzz: Plate-forme de fuzzing à grande échelle conçue pour les projets open-source, OSS-Fuzz fournit des tests fuzz continus et automatisés afin d'améliorer la sécurité et la stabilité des logiciels open-source largement utilisés.
Peach: Un cadre complet de fuzzing qui prend en charge une gamme de protocoles et de formats de données pour tester des logiciels complexes et des protocoles de communication, y compris les tests générationnels et basés sur la mutation.
Sulley: Principalement utilisé pour le fuzzing de protocoles réseau, Sulley est apprécié pour sa capacité à simuler une grande variété d'entrées réseau et est souvent utilisé dans la recherche sur la sécurité.
Radamsa: Un fuzzer léger basé sur la mutation qui est simple à utiliser et efficace pour générer des entrées inattendues afin de tester la résilience et la robustesse des logiciels.
Fuzz Testing pour les bases de données vectorielles et les applications d'intelligence artificielle
Les tests Fuzz sont très pertinents dans les bases de données vectorielles comme Milvus (créé par Zilliz) et les applications GenAI, car ces technologies gèrent de grands volumes de données diverses et complexes. Dans les solutions basées sur l'IA, telles que Retrieval-Augmented Generation (RAG) et d'autres modèles d'apprentissage automatique, les tests fuzz sont essentiels pour maintenir l'intégrité des données, la stabilité du système et la sécurité, en particulier lorsqu'il s'agit de données non structurées. Voici comment les tests fuzz sont bénéfiques :
Comme les bases de données vectorielles supportent souvent des requêtes et des filtrages complexes, les tests fuzz peuvent révéler la façon dont elles gèrent les cas limites dans les entrées de requêtes. Par conséquent, il identifie les défaillances potentielles ou les inefficacités dans l'indexation et la récupération.
Test de résilience dans les applications alimentées par l'IA comme RAG:** RAG et les modèles d'IA similaires s'appuient sur la récupération d'informations pertinentes à partir de bases de données externes pour générer des réponses ou effectuer des tâches spécifiques. Ces modèles sont sensibles à la qualité et à la structure des données récupérées. Les tests Fuzz permettent de simuler des entrées de données corrompues ou inattendues afin de voir comment le modèle réagit à des extractions inhabituelles.
Sécuriser les bases de données vectorielles et les pipelines d'IA contre les attaques potentielles:** Les tests Fuzz peuvent simuler des entrées de données hostiles, comme des exemples adverses conçus pour manipuler le comportement du modèle d'IA. Cela permet d'identifier les points faibles que les attaquants pourraient exploiter, ce qui permet aux développeurs de renforcer la sécurité.
Amélioration de la fiabilité dans les architectures d'IA distribuées:** De nombreuses applications d'IA, en particulier celles alimentées par des [Grands modèles de langage (LLM)] (https://zilliz.com/glossary/large-language-models-(llms)) ou des systèmes de reconnaissance d'images, sont distribuées sur plusieurs nœuds et systèmes. Les tests Fuzz peuvent révéler des problèmes dans le processus de synchronisation des données entre les nœuds d'une base de données vectorielle distribuée afin de vérifier si toutes les instances de la base de données peuvent gérer sans problème des entrées incohérentes ou inattendues.
Meilleures pratiques pour les tests Fuzz
La mise en œuvre efficace des tests fuzz nécessite une planification minutieuse et le respect des meilleures pratiques. Voici quelques conseils essentiels pour optimiser les tests fuzz :
Optimiser la génération d'entrées
Utilisez le fuzzing basé sur la mutation et la génération pour garantir une large gamme d'entrées, couvrant les cas courants et rares.
Adapter la génération d'entrée pour qu'elle corresponde aux formats de données ou aux protocoles attendus du logiciel cible afin d'éviter les erreurs non pertinentes et de se concentrer sur les problèmes significatifs.
Utiliser le fuzzing orienté structure ou couverture pour les types de données complexes afin de maximiser la couverture du code et de trouver des bogues plus profonds.
Mettre en place une surveillance et un retour d'information complets
Mettre en place une journalisation détaillée pour capturer le comportement du programme pendant les tests, y compris les plantages, les fuites de mémoire et les sorties anormales.
Des outils de surveillance tels que Prometheus peuvent être utilisés pour suivre l'utilisation de la mémoire, la charge du processeur et les chemins d'exécution afin d'obtenir des informations sur les performances du logiciel en cas d'intrants floutés.
Activer les outils de rapport de crash et de débogage pour aider à tracer la cause première de tout problème détecté, facilitant ainsi la reproduction et la correction des bogues.
Choisir les bons outils
Choisissez les outils de fuzzing en fonction des exigences spécifiques du projet. Par exemple, AFL peut être utilisé pour le fuzzing basé sur la mutation, libFuzzer peut être utilisé pour les bibliothèques, et OSS-Fuzz peut être utilisé pour les projets open-source.
Assurez-vous que l'outil s'intègre bien à votre environnement de développement et de test, permettant une incorporation transparente dans les pipelines CI/CD.
Expérimentez avec plusieurs outils et combinez différentes stratégies de fuzzing pour obtenir une meilleure couverture et de meilleurs résultats.
Concevoir un environnement de test efficace
Créer un environnement de test contrôlé qui isole le logiciel fuzzé des systèmes critiques afin d'éviter tout dommage accidentel ou toute perte de données.
Allouer des ressources informatiques suffisantes, car les tests de fuzz peuvent être gourmands en ressources. Envisager d'exécuter les tests dans une machine virtuelle ou un conteneur afin de gérer efficacement l'allocation des ressources.
Mettez régulièrement à jour votre environnement de test pour y inclure les dernières dépendances et les derniers correctifs, car les composants obsolètes peuvent introduire des problèmes involontaires.
Éviter les pièges courants
Le piège : s'appuyer uniquement sur des entrées aléatoires sans cibler des domaines spécifiques. Solution: Utiliser le fuzzing guidé par la couverture ou la structure pour orienter le test vers les chemins de code les plus importants.
Piège:** Ignorer les faux positifs, qui peuvent écraser les résultats. Solution: Examiner et filtrer régulièrement les résultats pour se concentrer sur les problèmes réels, en utilisant des outils ou des scripts pour aider à trier les résultats.
Piège:** Ne pas reproduire les problèmes trouvés pendant les tests fuzz. Solution: Enregistrer toutes les entrées fuzzées et les chemins d'exécution afin que les problèmes détectés puissent être reproduits et corrigés avec précision.
Rendre les tests fuzz continus
Intégrez le fuzz testing dans votre pipeline CI/CD pour vous assurer que les nouveaux changements de code sont systématiquement testés pour détecter les vulnérabilités potentielles.
Planifiez des tests fuzz réguliers, en particulier pour les composants logiciels critiques, dans le cadre du processus de développement continu. Les tests fuzz continus augmentent la probabilité de détecter les problèmes à un stade précoce.
Conclusion
En résumé, le fuzz testing est une méthode puissante pour découvrir des bogues et des vulnérabilités cachés dans diverses applications logicielles, y compris les bases de données vectorielles et les systèmes d'intelligence artificielle. Le fuzz testing permet d'améliorer la robustesse, la sécurité et la fiabilité en introduisant des données aléatoires ou malformées dans un programme. Bien qu'il comporte des défis, l'adoption de bonnes pratiques et l'utilisation des bons outils peuvent maximiser son efficacité.
FAQ sur le Fuzz Testing
- Qu'est-ce que le fuzz testing et pourquoi est-il important ?
Le fuzz testing est une méthode de test de logiciels qui consiste à introduire des données aléatoires ou inattendues dans un programme afin de trouver des bogues et des vulnérabilités. Il améliore la sécurité, la robustesse et la fiabilité des logiciels en découvrant des problèmes que les méthodes de test traditionnelles pourraient manquer.
- Comment les tests fuzz fonctionnent-ils en pratique ?
Les tests fuzz comportent plusieurs phases : l'identification du système cible, la détermination des types d'entrées à tester, la génération de données fuzzées, l'exécution du programme avec ces données, l'analyse du comportement du programme et l'identification des problèmes. Ce processus permet de déterminer dans quelle mesure le logiciel gère les entrées inattendues ou mal formées.
- Quels sont les types de tests fuzz les plus courants ?
Les types les plus courants sont le fuzzing basé sur la mutation (modification des données existantes), le fuzzing basé sur la génération (création d'entrées à partir de zéro), le fuzzing guidé par la couverture (maximisation de la couverture du code) et le fuzzing de protocole (test de formats de données spécifiques ou de normes de communication).
- Les tests fuzz peuvent-ils être appliqués aux applications d'intelligence artificielle et aux bases de données vectorielles ?
Oui, les tests fuzz sont très pertinents pour les applications d'intelligence artificielle et les bases de données vectorielles. Il aide ces systèmes à gérer les entrées imprévisibles, à améliorer l'intégrité des données et à maintenir la sécurité, en particulier dans des applications telles que [Retrieval-Augmented Generation (RAG)] (https://zilliz.com/vector-database-use-cases/llm-retrieval-augmented-generation) et le traitement de données complexes dans les pipelines d'IA.
- Quels sont les principaux défis du fuzz testing ?
Les principaux défis comprennent la manipulation de structures de données complexes, la nature intensive en ressources du fuzzing à grande échelle, les limites de la génération d'entrées aléatoires et la difficulté à reproduire les problèmes. Le respect des meilleures pratiques et le choix des bons outils peuvent aider à relever ces défis.
Ressources connexes
Comment évaluer les applications RAG](https://zilliz.com/learn/How-To-Evaluate-RAG-Applications)
[Optimisation des applications RAG : Guide des méthodologies, des mesures et des outils d'évaluation pour une meilleure fiabilité] (https://zilliz.com/blog/how-to-evaluate-retrieval-augmented-generation-rag-applications)
[Introduction d'une surveillance et d'une observabilité complètes dans le nuage Zilliz] (https://zilliz.com/blog/introducing-monitoring-and-observability-in-zilliz-cloud)
[Prometheus Metrics : surveiller les performances de votre application] (https://zilliz.com/glossary/prometheus-metrics)
Observability : Tracking Beyond Monitoring](https://zilliz.com/glossary/observability)
- Qu'est-ce que le Fuzz Testing ?
- Histoire du Fuzz Testing
- Comment fonctionne le Fuzz Testing ?
- Types de tests Fuzz
- Cas d'utilisation du Fuzz Testing
- Avantages du Fuzz Testing
- Défis et limites du Fuzz Testing
- Outils et cadres de test de fuzz
- Fuzz Testing pour les bases de données vectorielles et les applications d'intelligence artificielle
- Meilleures pratiques pour les tests Fuzz
- Conclusion
- FAQ sur le Fuzz Testing
- Ressources connexes
Contenu
Commencez gratuitement, évoluez facilement
Essayez la base de données vectorielle entièrement managée conçue pour vos applications GenAI.
Essayer Zilliz Cloud gratuitement