




Qu’est-ce qu’une Vector Lakebase ?
TL;DR
- Une Vector Lakebase est une architecture de données unifiée, native du lake, pour l’IA, qui combine une mise à disposition de niveau base de données vectorielle avec un stockage lake ouvert, des index réutilisables au niveau du lake et une couche sémantique partagée.
- Elle permet aux mêmes données non structurées d’alimenter la mise à disposition en ligne (RAG, agents, recherche sémantique) et la découverte hors ligne (clustering, déduplication, ré-embedding, gouvernance) — sans copier les données entre les systèmes.
- Zilliz Vector Lakebase est une implémentation de cette architecture : une évolution de Zilliz Cloud, passant d’une base de données vectorielle managée à une plateforme de données IA unifiée.
Qu’est-ce qu’une Vector Lakebase ?
Une Vector Lakebase est une architecture de données unifiée, native du lake, pour l’IA. Elle combine une mise à disposition de niveau base de données vectorielle, un stockage lake ouvert, des index réutilisables au niveau du lake et une couche sémantique partagée, afin que les mêmes données non structurées puissent prendre en charge des applications IA en ligne, la découverte interactive et l’analytique hors ligne — sans les copier entre les systèmes. Elle répond à une question différente de la simple récupération : que se passe-t-il lorsque les équipes IA en production ont besoin des mêmes données pour la récupération, la découverte, l’analytique, la gouvernance, le feedback et l’amélioration continue ?
Il est préférable de la comprendre comme une extension de la base de données vectorielle, et non comme un remplacement de celle-ci. La recherche vectorielle reste le chemin de mise à disposition à faible latence ; une Vector Lakebase place ce chemin au sein d’une fondation plus large qui peut également stocker, indexer, gouverner et améliorer en continu les données qui l’entourent.
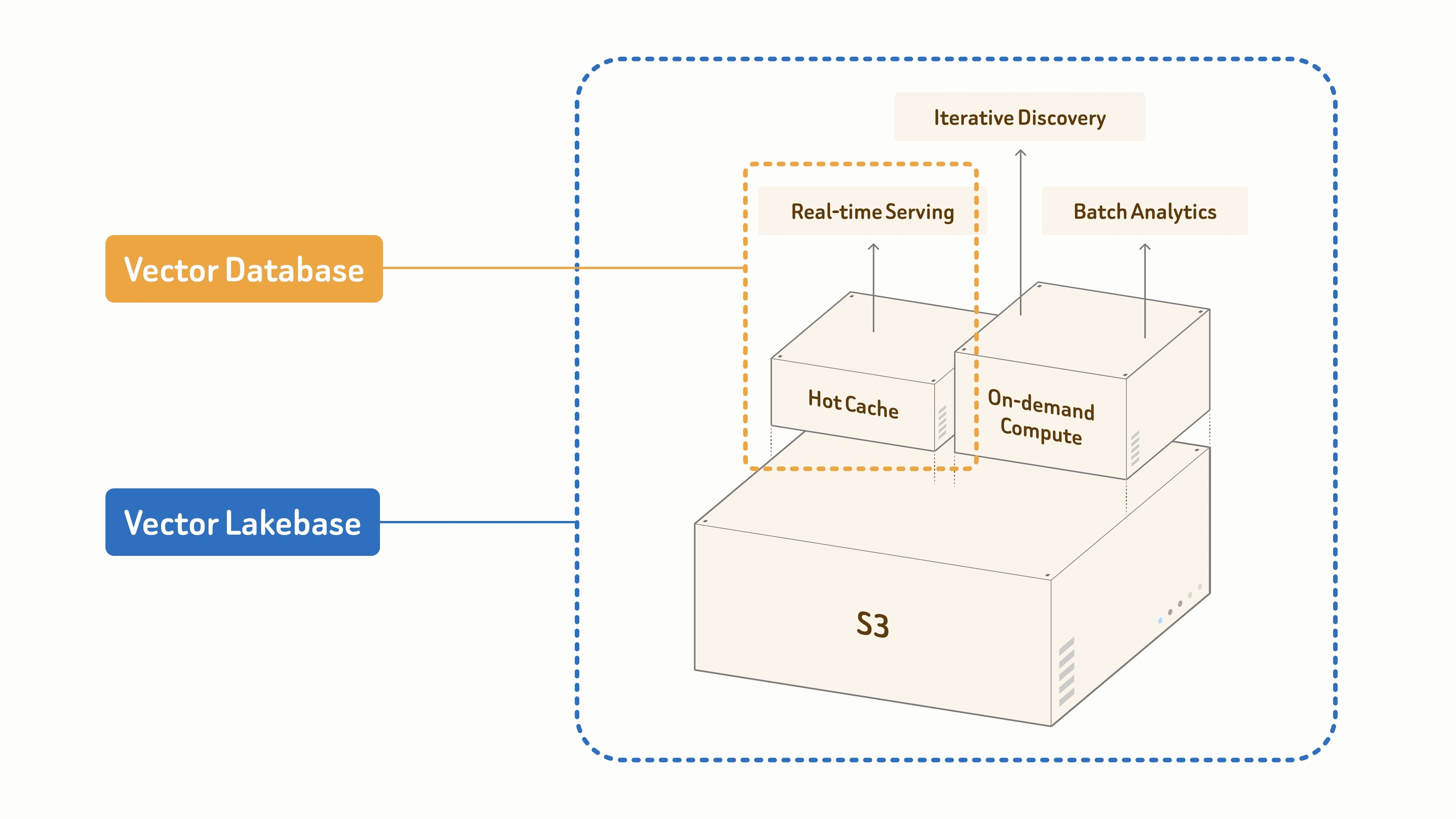
Pourquoi les workloads IA modernes ont besoin d’une Vector Lakebase
Les bases de données vectorielles ont résolu le premier problème de données de l’IA moderne : la récupération sémantique rapide à grande échelle, alimentant le RAG, les agents et la recherche sémantique. Ce problème reste important — plus que jamais, à mesure que les systèmes IA se diffusent.
Mais les équipes IA en production ont de plus en plus besoin de bien plus que la récupération à partir des mêmes données — déduplication et clustering pour les jeux d’entraînement, détection d’anomalies et de dérive, ré-embedding lorsque les modèles changent, gouvernance et lignage, ainsi que feedback issu du comportement en production.
La plupart des stacks gèrent ces workflows comme des systèmes distincts : un data lake pour les fichiers bruts, une base de données vectorielle pour la récupération en ligne, des pipelines batch pour le prétraitement, et des tâches séparées pour les embeddings et les index. Les données sont copiées entre eux, les index sont reconstruits, et la mise à disposition en ligne et la découverte hors ligne finissent par diverger.
Une Vector Lakebase supprime cette fragmentation en fournissant une fondation de données logique unique pour la mise à disposition et la découverte. Elle conserve le chemin de récupération à faible latence pour lequel les bases de données vectorielles sont conçues, mais le connecte à une fondation native du lake où les données, vecteurs, index, métadonnées et contexte sémantique peuvent être stockés, gouvernés, versionnés, réutilisés et améliorés au fil du temps. L’objectif n’est pas de remplacer la base de données vectorielle par le lake ; il s’agit d’intégrer la recherche vectorielle, le contexte sémantique et le traitement des données non structurées dans une architecture unique. (Pour le contexte sectoriel et l’ingénierie derrière cette évolution, voir Why We Built Vector Lakebase.)
Principes de conception fondamentaux de Vector Lakebase : One Data, One Index, One Semantic Layer
Une architecture Vector Lakebase repose sur trois principes : One Data, One Index et One Semantic Layer. Ils décrivent où vit le système d’enregistrement, comment les index sont gérés et comment la signification est organisée.

One Data : le lake comme fondation de données partagée
One Data signifie que le stockage lake ouvert devient la fondation partagée des données IA non structurées. Les fichiers bruts, les données nettoyées, les vecteurs, les champs scalaires, les métadonnées, les artefacts d’index, les labels sémantiques, le lignage et les résultats du traitement hors ligne résident tous au sein d’une fondation de données logique unique.
Dans cette architecture, la base de données vectorielle n’est pas un nouveau silo de données. Elle devient partie intégrante du chemin de service à faible latence. Les données faisant autorité restent natives du lac, tandis que les systèmes en ligne mettent en cache les données chaudes et les index lorsque nécessaire. Cela réduit le stockage dupliqué, la gouvernance et la migration entre systèmes, et permet aux mêmes données de prendre en charge les applications en ligne, le traitement hors ligne, l’entraînement de modèles, l’évaluation et la gouvernance.
Par exemple, un document utilisé dans un système RAG peut également faire partie d’une tâche de clustering hors ligne, d’un workflow d’exploration de données d’entraînement, d’une revue de conformité et d’un futur processus de ré-embedding. Dans une architecture fragmentée, chaque workflow crée sa propre copie ou représentation dérivée. Dans une Vector Lakebase, ces workflows opèrent sur la même fondation logique de données.
One Index : les index deviennent des actifs au niveau du lac
One Index signifie que les index ne sont pas verrouillés à l’intérieur d’un seul moteur de service en ligne. Ils deviennent des actifs de données qui peuvent être construits, versionnés, réutilisés et servis à travers différents modes de calcul. C’est important parce que les index sont coûteux et importants sur le plan opérationnel — ils encodent la manière dont un système récupère et organise les données. Si chaque workflow doit construire son propre index, les équipes gaspillent du calcul, créent un comportement de récupération incohérent et rendent la gouvernance plus difficile.
Dans une Vector Lakebase, un index logique peut correspondre à différentes formes de service selon le modèle d’accès et le coût. Les index chauds prennent en charge une récupération en ligne au niveau de la milliseconde ; les données tièdes sont servies via le cache ou le stockage hiérarchisé ; les données froides restent dans le lac pour l’exploration, la gouvernance et l’analyse hors ligne. La même lignée d’index peut prendre en charge le service RAG, la recherche sémantique, la mémoire d’agent, l’exploration de données et le traitement par lots — permettant aux équipes de choisir le bon profil de latence et de coût sans casser le modèle de données.
One Semantic Layer : le sens devient une couche système partagée
One Semantic Layer signifie que le système gère plus que des embeddings. Un embedding n’est qu’une représentation de l’actif sous-jacent. Une fondation de données IA utile a également besoin d’entités, de libellés, de résumés, de sujets, de fragments de contexte, d’informations de source, de versions de modèles, de politiques d’accès, de lignée et de signaux de feedback. Cette couche sémantique permet aux équipes d’organiser les données non structurées par le sens plutôt que seulement par chemin de fichier, table, compartiment ou collection.
Un système RAG peut récupérer un contexte fiable depuis la couche sémantique. Un agent IA peut comprendre les tâches précédentes, les souvenirs et les résultats d’appels d’outils. Un workflow de données d’entraînement peut découvrir des lacunes de couverture, des doublons, des valeurs aberrantes et des biais. Un système de gouvernance peut retracer une réponse, une fonctionnalité ou un échantillon jusqu’aux données sources et à la version du modèle qui l’ont produit.
La couche sémantique est également le centre du volant d’inertie des données : les applications en ligne génèrent des requêtes, des clics, des citations, des corrections et du feedback ; la découverte hors ligne transforme ces signaux en meilleures métadonnées, en jeux de données plus propres, en index améliorés et en contexte plus solide ; et ces améliorations retournent dans le service. Cette boucle est l’endroit où une Vector Lakebase devient plus que du stockage plus de la récupération.
Fonctionnement de Vector Lakebase : le volant d’inertie CS/CD, en quatre étapes
Une Vector Lakebase fonctionne comme une boucle continue entre service et découverte — nous appelons cela CS/CD (Continuous Serving and Continuous Discovery). Le service génère du feedback et de nouvelles données, la découverte les transforme en données plus propres et en meilleurs index, et ces améliorations retournent dans le service.
Sur le plan opérationnel, la même boucle passe par quatre étapes : ingestion des données, vectorisation et enrichissement, service de requêtes et traitement hors ligne.
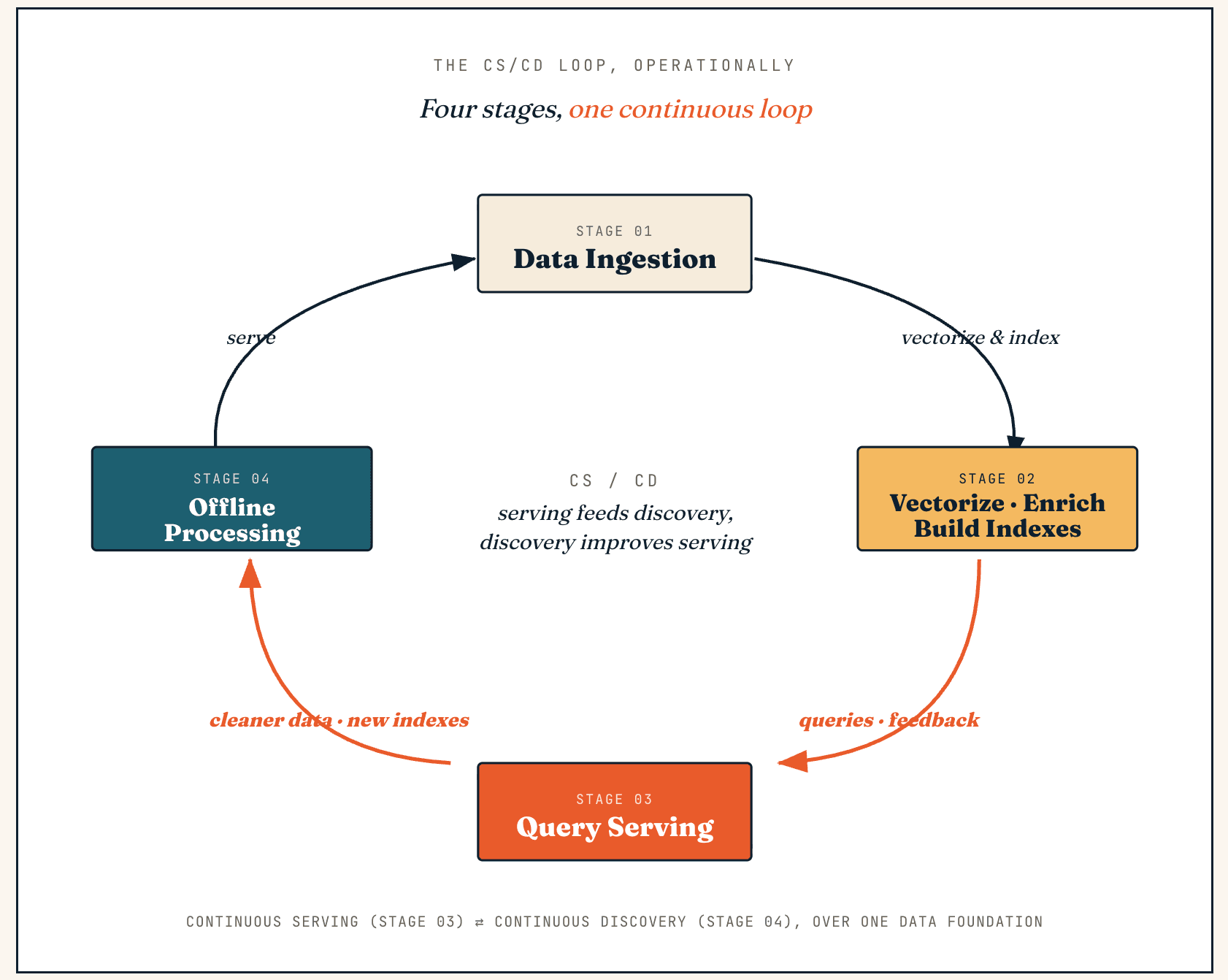
Ingestion des données
Les données peuvent entrer dans le système via une API de base de données vectorielle, un pipeline de documents, un stockage objet ou un format de lac ouvert existant. Les données peuvent inclure des documents, des vecteurs, des champs scalaires, des métadonnées métier, des images, de l’audio, de la vidéo, du code, des journaux, des conversations, des tickets de support ou des traces d’agents.
À mesure que les données non structurées augmentent, l’ingestion doit également prendre en charge le nettoyage, la normalisation, le contrôle d’accès, le suivi des sources et la traçabilité. Le système doit savoir non seulement ce que sont les données, mais aussi d’où elles proviennent, quel modèle les a traitées, qui peut y accéder et comment elles peuvent être utilisées. C’est particulièrement important pour l’IA d’entreprise. Un système RAG ou un agent ne peut pas traiter chaque élément de données récupéré comme étant également fiable. Le contexte nécessite une connaissance des sources, des autorisations, de la fraîcheur et parfois des règles de gouvernance propres à l’entreprise.
Vectorisation, enrichissement et construction d’index
Après l’ingestion, le système génère des représentations vectorielles à l’aide de modèles d’embedding et de tâches de traitement des données. Il enrichit également les données avec des métadonnées — entités, libellés, résumés, sujets, informations de source, autorisations, horodatages et versions de modèles. Il construit ensuite des structures de requête sur les données du lake : index vectoriels, index de mots-clés, index plein texte, index JSON, index scalaires et autres structures nécessaires à la recherche hybride.
Sur le plan architectural, voici le point clé : les index ne sont liés à aucun moteur de service unique. Ils peuvent être versionnés, publiés, réutilisés et retracés jusqu’à l’instantané de données à partir duquel ils ont été construits — ce qui fait de la gestion du cycle de vie des index une partie du socle de données, et non un détail d’implémentation enfoui dans une application.
Service des requêtes
Une Vector Lakebase fournit des chemins de récupération pour le RAG, la recherche agentique, la recherche sémantique, la récupération multimodale, la mémoire IA, la recommandation et d’autres charges de travail d’applications IA. Le chemin de requête peut utiliser une base de données vectorielle ou une couche de cache pour les données chaudes nécessitant une faible latence, et accéder aux données et aux index natifs du lake pour les charges de travail plus froides ou moins fréquentes.
Une requête peut combiner recherche vectorielle, recherche par mots-clés, recherche plein texte, filtrage par métadonnées, prédicats scalaires, autorisations et classement hybride — car la récupération IA en production repose rarement sur la seule similarité vectorielle. Un bon résultat dépend souvent de la pertinence sémantique, de la fraîcheur, des droits d’accès, de la qualité des sources, des métadonnées métier et de l’intention de l’utilisateur.
Traitement hors ligne
Le traitement hors ligne comprend le clustering, la déduplication, la détection d’anomalies, l’analyse de la qualité des données, l’exploration des données d’entraînement, l’évolution des schémas, le ré-embedding, l’évaluation et la reconstruction d’index. Ces workflows s’exécutent sur de grands lots de données et ne nécessitent pas toujours une latence de l’ordre de la milliseconde, mais ils doivent accéder aux mêmes vecteurs, métadonnées, index et contexte sémantique que ceux utilisés par les applications en ligne.
Leur sortie est réécrite dans le lake, le système d’index et la couche sémantique — jeux de données plus propres, meilleurs libellés, fragments de contexte améliorés, nouvelles versions d’index ou signaux de feedback mis à jour — puis publiée sous forme d’instantané atomique afin que la production ne lise jamais des index à moitié construits. C’est la boucle opérationnelle centrale : le service génère du feedback, la découverte améliore les données, et les données améliorées reviennent au service.
Trois formes de charges de travail pour les Vector Lakebases
Les charges de travail de données IA n’ont pas une forme unique. Certaines nécessitent un service au niveau de la milliseconde toute la journée. Certaines nécessitent une recherche interactive pour une courte session d’analyse. Certaines nécessitent de grands traitements hors ligne qui s’exécutent, publient des résultats puis disparaissent. Un modèle unique de stockage en ligne toujours actif ne peut pas couvrir efficacement tous ces cas.
Une base de données vectorielle traditionnelle est principalement optimisée pour la première forme de charge de travail. Une Vector Lakebase est conçue pour les trois sur un seul jeu de données logique.
Dans Zilliz Vector Lakebase, ces charges de travail correspondent à trois modes de calcul — long-running (résident, service à la milliseconde), on-demand (interactif, facturé à la minute, le pont entre service et découverte) et offline batch (grands traitements qui libèrent leurs ressources de calcul une fois terminés).
| Type de charge de travail | Exemples typiques | Modèle de calcul |
|---|---|---|
| Service en temps réel | RAG de production, mémoire d’agent, recherche sémantique, recommandation, personnalisation, recherche IA | Clusters de service longue durée avec index chauds, caches tièdes et latence prévisible |
| Découverte interactive | Analyse des retours, inspection des traces d’agent, recherche d’anomalies, récupération de données froides, exploration sémantique | Calcul à la demande qui démarre lorsque nécessaire et libère les ressources à la fin de la session |
| Analytique par lots | Déduplication de corpus, clustering, réintégration complète, préparation des données d’entraînement, reconstruction d’index | Calcul par lots pour de grands traitements qui s’exécutent, publient les résultats, puis disparaissent |
Cas d’utilisation courants des Vector Lakebases
Parce qu’une Vector Lakebase unifie le service et la découverte sur une fondation unique, ses cas d’utilisation se répartissent en deux groupes.
 图片12
图片12
Cas d’utilisation de récupération (partagés avec une base de données vectorielle, désormais sur une fondation gouvernée) :
- RAG — documents, bases de connaissances, code et journaux comme contexte consultable, maintenus à jour, soumis à des autorisations et réindexables à mesure que les modèles évoluent.
- Mémoire d’agent IA et utilisation d’outils — stocker et récupérer la mémoire d’agent, puis l’analyser hors ligne et réinjecter les enseignements.
- Recherche agentique et multimodale — recherche vectorielle, par mots-clés, plein texte et par métadonnées à travers textes, images, audio, vidéo et entités.
- Systèmes de recommandation, et plus encore.
Cas d’utilisation du cycle de vie des données (au-delà de ce qu’une base de données vectorielle seule couvre) :
- Ingénierie des caractéristiques et du contexte — dériver entités, résumés, sujets, étiquettes et clusters, stockés à côté des données dont ils proviennent.
- Exploration des données d’entraînement — regrouper des échantillons, trouver des quasi-doublons, inspecter les valeurs aberrantes et retracer les exemples jusqu’à leur source.
- Prétraitement des données non structurées — déduplication, détection d’anomalies, enrichissement et filtrage de qualité, réécrits dans le lac.
Comment une Vector Lakebase se rapporte aux bases de données vectorielles et aux Lakebases
Une Vector Lakebase est liée à deux architectures : les bases de données vectorielles et Lakebase. Elle ne remplace ni l’une ni l’autre. Le tableau ci-dessous donne un aperçu rapide ; les sections qui suivent expliquent chaque relation.
| Base de données vectorielle | Vector Lakebase | Lakebase | |
|---|---|---|---|
| Données principales | Embeddings vectoriels + données non structurées associées | Données non structurées et multimodales, ainsi que tout le cycle de vie qui les entoure | Données applicatives structurées / transactionnelles |
| Fonction principale | Récupération sémantique à faible latence | Unifier le service en ligne et la découverte hors ligne sur une même fondation | Apporter des capacités de base de données (OLTP) au stockage de lac ouvert |
| Index | Construits et conservés dans le moteur de service | Actifs au niveau du lac : construits, versionnés, réutilisés dans différents modes de calcul | Index de table / SQL |
| Calcul | Service toujours actif | Longue durée + à la demande + lots hors ligne | Transactionnel |
| Stockage de référence | Souvent couplé au moteur | Stockage de lac ouvert | Stockage de lac ouvert |
| Meilleur cas d’usage | Recherche vectorielle rapide pour application en ligne | Servir et améliorer en continu les données non structurées à grande échelle | Données applicatives transactionnelles sur le lac |
| Relation avec Vector Lakebase | Devient le moteur de service au sein d’une Vector Lakebase | - | Le pendant données structurées de la même idée native du lac |
Vector Lakebase vs bases de données vectorielles
Une Vector Lakebase ne remplace pas les bases de données vectorielles. Si une organisation a seulement besoin d’une recherche vectorielle à faible latence pour une seule application, une base de données vectorielle peut suffire — elle demeure le bon système pour la récupération en production lorsque la latence, l’échelle, le filtrage et la fiabilité opérationnelle comptent. Milvus, par exemple, est conçu pour ce type de recherche vectorielle en production.
Le calcul change lorsqu’une organisation doit réutiliser les mêmes données non structurées, embeddings, index et contexte sémantique à travers de nombreuses équipes, modèles, applications et workflows de traitement.
Dans ce monde, la base de données vectorielle ne devrait pas être le seul endroit où résident les données et les index ; elle devient le moteur de service au sein d’une architecture plus large de données non structurées. Son rôle devient plus spécifique et plus important — elle fournit le chemin de service dont les applications d’IA ont besoin, tandis que le Vector Lakebase fournit la fondation de données plus large autour de ce chemin. Le résultat n’est pas moins de recherche vectorielle ; c’est une recherche vectorielle connectée au cycle de vie complet des données non structurées.
Si je n’ai besoin que d’une base de données vectorielle, Vector Lakebase est-il toujours un bon choix ?
C’est un excellent point de départ — car la base de données vectorielle fait déjà partie d’un Vector Lakebase. Vous pouvez utiliser la couche de cluster de service exactement comme une base de données vectorielle autonome (recherche ANN à faible latence, recherche hybride, filtrage de métadonnées, recherche en texte intégral, filtrage JSON, gestion des index, fiabilité en production) et ne jamais toucher à la découverte interactive ni à l’analytique batch le premier jour. La différence est que vous n’êtes pas enfermé dans une architecture uniquement orientée récupération : si la charge de travail s’étend ensuite à la recherche dans les données froides, à la déduplication à grande échelle, au ré-embedding, à la préparation des données d’entraînement ou à la gouvernance sémantique, l’architecture plus large est déjà en place — sans reconstruction, sans données dupliquées.
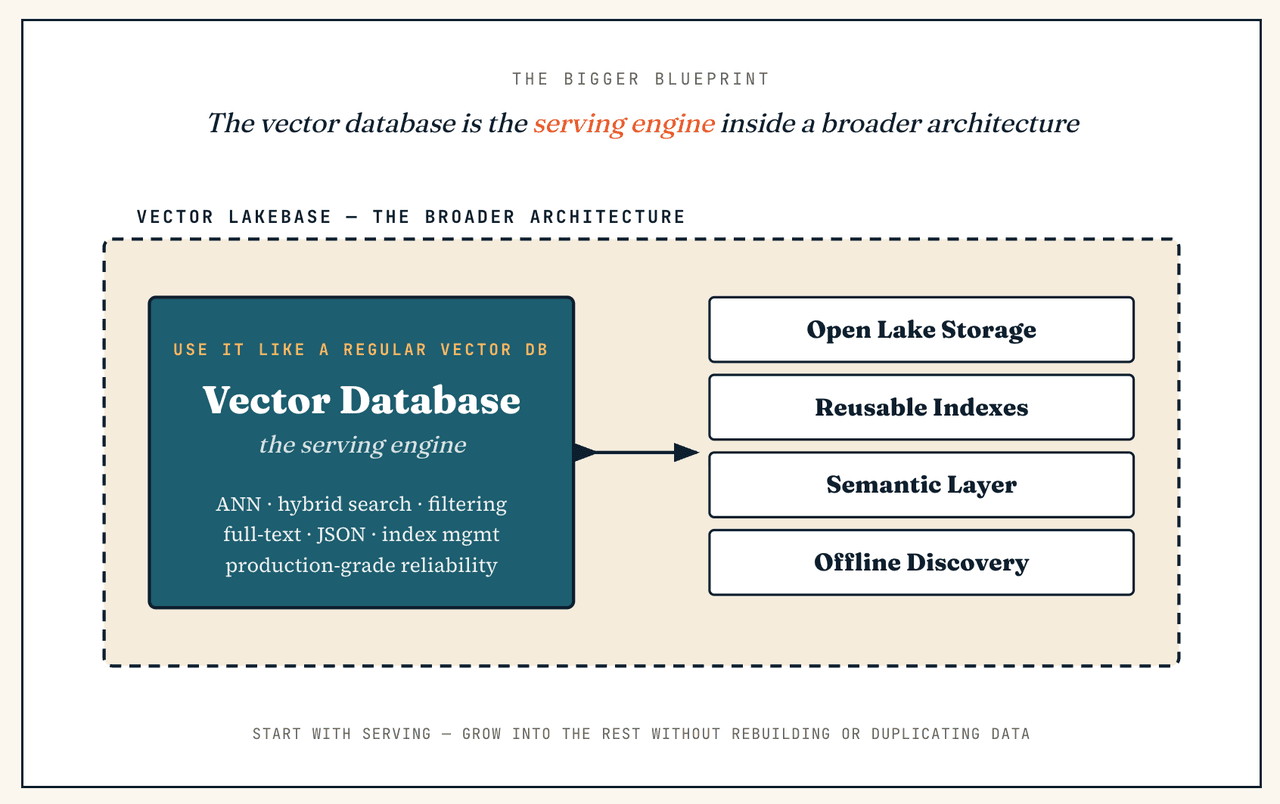
Vector Lakebase vs. Lakebase
Un Vector Lakebase est lié à un Lakebase, mais ce n’est pas simplement « Lakebase plus des vecteurs ».

Une architecture de type Lakebase apporte des capacités proches de celles d’une base de données au stockage ouvert de type lake pour les données applicatives structurées — enregistrements structurés, transactions, schémas, calcul élastique et gouvernance unifiée, interrogés via des champs et relations connus.
Un Vector Lakebase répond à un autre centre de gravité : les données non structurées et multimodales pour l’IA. Le problème n’est pas de savoir comment stocker l’état applicatif dans un lake ; il est de savoir comment gérer les représentations sémantiques, les index vectoriels, les métadonnées, le contexte, les retours et les workflows de découverte hors ligne sur des données non structurées — ce qui nécessite une interprétation sémantique, une récupération, un affinage et des retours plutôt que des recherches sur des champs connus. Il se décrit mieux non pas comme un remplacement du Lakebase, mais comme l’idée du Lakebase étendue à l’ère des vecteurs, des index et du contexte sémantique.
| Dimension | Lakebase | Vector Lakebase |
|---|---|---|
| Données principales | Données applicatives structurées, enregistrements transactionnels, état applicatif | Documents, images, audio, vidéo, journaux, code, conversations, vecteurs, métadonnées et contexte sémantique |
| Abstractions clés | Tables, transactions, schémas, branches, clones | Vecteurs, index, fragments, entités, labels, résumés, permissions, retours et relations sémantiques |
| Charges de travail principales | Lectures et écritures applicatives, transactions, analytique en temps réel | RAG, mémoire d’agent, recherche agentique, récupération multimodale, découverte, ingénierie du contexte, workflows de données d’entraînement |
| Modèle de requête | SQL, requêtes transactionnelles, requêtes analytiques | Recherche vectorielle, recherche hybride, recherche en texte intégral, filtrage JSON, récupération multimodale, découverte sémantique |
| Modèle sémantique | Signification métier exprimée principalement par le schéma | Signification exprimée par les embeddings, les métadonnées, les entités, les résumés, les versions de modèles, la lignée et les retours |
| Valeur pour l’IA | Apporte des capacités proches de celles d’une base de données au stockage ouvert de type lake | Apporte le contexte d’IA, l’indexation vectorielle, la récupération sémantique et la découverte hors ligne aux données non structurées natives du lake |
Ce qu’un Vector Lakebase n’est pas
Parce que Vector Lakebase est un nouveau modèle d’architecture, il convient de clarifier ce qu’il n’est pas.
- Ce n’est pas simplement un lac de données avec des embeddings stockés dans une colonne. Stocker des embeddings dans une table de lac préserve les vecteurs, mais ne fournit aucun des éléments d’indexation, de service, de métadonnées sémantiques, de recherche hybride, de boucle de rétroaction ou de chemin de récupération à faible latence dont les systèmes d’IA en production ont besoin. Les vecteurs sont utiles lorsqu’ils peuvent être recherchés, gouvernés, versionnés, filtrés, connectés aux données sources et améliorés au fil du temps — pas simplement stockés.
- Ce n’est pas simplement une base de données vectorielle connectée à du stockage objet. Placer du stockage objet derrière une base de données vectorielle peut réduire les coûts de stockage, mais cela ne répond pas aux enjeux de réutilisation des index, de découverte hors ligne, de gouvernance, de versioning ou de cohérence entre les données traitées et servies. La difficulté n’est pas de savoir où résident les octets ; elle réside dans la manière dont les données, les index, les métadonnées, les signaux sémantiques et les modes de calcul fonctionnent ensemble comme un seul système opérationnel.
- Ce n’est pas un système d’analytique hors ligne. La découverte hors ligne n’est qu’un aspect de l’architecture. Un Vector Lakebase sert également le trafic de production, prend en charge les chemins de récupération à chaud, gère les index, applique le contrôle d’accès et renvoie le contexte pertinent aux applications et aux agents. L’objectif n’est pas de choisir entre service et analytique — c’est de les connecter.
- Ce n’est pas une rupture avec les bases de données vectorielles. C’est peut-être le point le plus important que nous avons mentionné à plusieurs reprises. Vector Lakebase ne rend pas les bases de données vectorielles moins pertinentes. Il leur donne une architecture plus large dans laquelle fonctionner.
Zilliz Vector Lakebase est disponible en aperçu public
Nous avons lancé l’aperçu public de Zilliz Vector Lakebase — une évolution majeure de Zilliz Cloud, passant d’une base de données vectorielle managée pure à une plateforme de données sémantiques unifiée qui combine le service vectoriel à faible latence avec l’ouverture, la scalabilité et l’économie d’un lac de données.
Capacités principales de Zilliz Vector Lakebase :
- Service par niveaux optimisé pour différents compromis performance-coût en temps réel
- Recherche à la demande pour les charges de travail à grande échelle ou exploratoires sans calcul toujours actif
- Recherche dans des lacs de données externes — indexez et recherchez directement dans vos données de lac existantes
- Recherche IA complète sur les vecteurs, le texte, JSON et les données géospatiales avec recherche hybride et reranking
- Stockage unifié natif du lac basé sur Vortex, un format ouvert avec des lectures aléatoires plus rapides et moins coûteuses que Lance ou Parquet
Si votre pile actuelle sépare le service et la découverte dans des systèmes distincts, Vector Lakebase pourrait mériter votre attention. Essayez-le sur Zilliz Cloud — les nouvelles inscriptions avec une adresse e-mail professionnelle obtiennent $100 de crédits gratuits — ou contactez-nous pour parler de votre cas d’utilisation.
En savoir plus sur les Vector Lakebases
- De la base de données vectorielle au Vector Lakebase
- Nous avons passé 8 ans à accélérer la recherche vectorielle. Puis l’IA a changé le modèle de calcul
- Pourquoi nous avons construit Vector Lakebase : repenser l’architecture des données non structurées pour l’IA
- Vector Lakebase : mettre fin au silo de données IA
- Zilliz Cloud On-Demand Compute : ne payez que ce que vous utilisez
- La recherche vectorielle de Notion est excellente. Leur prochain problème est plus difficile.
Continuer à lire

Zilliz Cloud Just Landed in Claude Code
The Zilliz Cloud Plugin brings the full power of Zilliz Cloud directly into your Claude Code terminal as natural-language conversations.

Zilliz Cloud Enterprise Vector Search Powers High-Performance AI on AWS
Zilliz Cloud on AWS powers secure, scalable, ultra-fast vector search for enterprise AI apps, with BYOC, sub-10ms latency, and zero-DevOps simplicity.

Legal Document Analysis: Harnessing Zilliz Cloud's Semantic Search and RAG for Legal Insights
Enhance legal document analysis with Zilliz Cloud’s Semantic Search and RAG. Improve accuracy, efficiency, and scalability for contracts, case law, and compliance.