




Vector Lakebase : mettre fin au silo de données de l’IA
Toutes les équipes d’IA se heurtent au même mur — la gravité des données
Toute équipe data moderne a construit une variante de la même architecture. Une lakehouse — des tables Iceberg sur S3, un pipeline Spark et Delta Lake pour la gouvernance — se trouve au centre. Cela fonctionne bien. Puis les exigences de l’IA arrivent.
Votre pipeline RAG doit répondre à des questions portant sur 10 ans de documents d’entreprise, vous copiez donc tout dans une base de données vectorielle. Vos agents IA ont besoin d’un accès à faible latence aux embeddings du catalogue produit — un autre pipeline, une autre tâche de synchronisation. L’entraînement de votre modèle multimodal exige une déduplication quotidienne sur un milliard d’embeddings d’images — une tâche Spark qui ne peut pas voir l’index.
Six mois plus tard, vous avez cinq systèmes au lieu de deux. Votre équipe d’ingénierie des données passe plus de temps à maintenir des pipelines de synchronisation qu’à créer des fonctionnalités d’IA. Vous avez trois copies du même jeu de données sans aucune garantie qu’elles concordent. Chaque changement de schéma se répercute à quatre endroits différents.
Ce n’est pas un échec d’exécution. C’est un échec d’architecture — plus précisément, une architecture qui continue de lutter contre une propriété fondamentale des données : la gravité. Chaque système qui vous oblige d’abord à copier les données vous impose une taxe de gravité. Plus vous ajoutez de charges de travail d’IA — pipelines RAG, mémoire d’agents, entraînement de modèles, recommandations en temps réel — plus cette taxe augmente.
La bonne solution n’est pas un meilleur pipeline. Elle devrait être un nouveau paradigme architectural : Vector Lakebase.
Trois générations de solutions architecturales, deux impasses
Avant d’entrer dans les détails de Vector Lakebase, il vaut la peine d’examiner comment l’architecture de recherche vectorielle a évolué pour répondre au problème de la gravité des données. Globalement, il y a eu trois générations de solutions.
Génération 1 : bases de données vectorielles dédiées
Les bases de données vectorielles dédiées comme Milvus ont résolu un vrai problème pour les systèmes d’IA en production : la recherche sémantique avec une latence de l’ordre de la milliseconde, avec un rappel et des performances que les bases de données généralistes ne pouvaient égaler. En tant que créateurs de la base de données vectorielle open source Milvus, Zilliz se concentre depuis longtemps sur la construction d’un système fiable et performant pour stocker des embeddings, construire des index et servir une récupération à faible latence pour le RAG, les agents, les systèmes de recommandation, la recherche sémantique et les applications multimodales. Ce socle reste important. Les systèmes d’IA en production ont toujours besoin d’une récupération à la vitesse d’une base de données, et les bases de données vectorielles restent la bonne couche de service pour de nombreuses charges de travail sensibles à la latence.
Cependant, à mesure que les charges de travail d’IA gagnent en maturité, le défi s’étend de plus en plus au-delà du service en ligne. Une grande partie des données sources d’une organisation réside déjà dans du stockage objet, des data lakes, des lakehouses et des systèmes analytiques en aval. Pour utiliser ces données dans une base de données vectorielle dédiée, les équipes les copient généralement dans un système de service séparé, construisent des pipelines d’ingestion, maintiennent des tâches de synchronisation et gèrent la cohérence entre les données sources et l’index vectoriel. Lorsque les modèles d’embedding changent, comme c’est inévitable, les équipes doivent régénérer les embeddings, reconstruire les index et maintenir plusieurs systèmes alignés.
Ce n’est pas une limite des performances des bases de données vectorielles. C’est une frontière architecturale créée par le déplacement des données. À mesure que davantage d’équipes veulent utiliser les mêmes données pour la récupération en production, les expérimentations d’embeddings, l’évaluation hors ligne, la gouvernance, le lignage et l’analytique, la surface opérationnelle s’étend. Les bases de données vectorielles dédiées ont extrêmement bien résolu le problème de la récupération en ligne, mais à elles seules, elles n’éliminent pas le problème de la gravité des données.
Génération 2 : Vector Lake
La réponse naturelle suivante a consisté à rapprocher la recherche vectorielle du lake : interroger les vecteurs directement depuis Iceberg, Delta Lake ou des fichiers Parquet sans d’abord les déplacer dans un système de service dédié. La motivation était juste. Si les données résident déjà dans du stockage objet ou une lakehouse, pourquoi les dupliquer ailleurs simplement pour les rendre consultables ?
Mais en pratique, les architectures de vector lake restent incomplètes pour les charges de travail d’IA en production, pour trois raisons.
Premièrement, elles ne sont pas conçues pour le service à faible latence. La plupart des approches de vector lake chargent les données ou les index depuis le stockage objet à la demande et sont optimisées davantage pour la flexibilité que pour le traitement de requêtes concurrentes sensibles à la latence. Cela peut être acceptable pour l’exploration hors ligne, mais ce n’est pas suffisant pour les applications RAG, les agents, la recommandation ou la recherche destinés aux utilisateurs. Lorsqu’un pipeline de récupération se trouve sur le chemin critique d’un appel LLM, les équipes ont besoin d’une latence prévisible inférieure à 100 ms avec une forte concurrence. Si la latence p99 dérive régulièrement vers l’ordre de quelques secondes, le système peut rester utile pour l’analyse, mais il ne peut pas servir de couche de récupération en production.
Deuxièmement, les systèmes de vector lake s’arrêtent généralement à l’étape de recherche. Ils permettent aux équipes d’interroger des données vectorielles dans le lac, mais ils ne fournissent pas d’environnement d’exécution plus large pour les workflows de données d’IA. Les systèmes d’IA modernes ont besoin de plus qu’une recherche de plus proches voisins. Ils doivent régénérer des embeddings, évaluer la qualité de la récupération, compresser la mémoire des agents, extraire des images de vidéos, traiter des données multimodales, gérer les métadonnées et préparer les données pour le fine-tuning ou les pipelines en aval. Un système qui se contente d’ajouter la recherche au-dessus de fichiers de lac ne répond pas à l’ensemble du cycle de vie des données vectorielles et multimodales.
Troisièmement, la couche de stockage sous-jacente n’a pas été conçue pour cette charge de travail. Iceberg et Delta Lake ont été conçus pour des données analytiques structurées — pas de types vectoriels natifs, pas de structures d’index, chaque requête est un scan complet. Les charges de travail d’IA ont besoin de recherches ponctuelles rapides (pas les scans séquentiels de groupes de lignes de Parquet — des formats comme Vortex et Lance existent pour cette raison), d’index intégrés cogérés avec les données, et d’une gestion des données non structurées basée sur des références, où les images, l’audio et la vidéo sont liés par référence plutôt qu’intégrés sous forme de blobs. Rien de tout cela n’existe aujourd’hui dans le lac. Un Vector Lake construit sur Iceberg lutte contre la couche de stockage à tous les niveaux.
Génération 3 : Vector Lakebase
Vector Lakebase est ce que l’on obtient lorsque l’on cesse de considérer le lac et la base de données vectorielle comme des systèmes distincts qui doivent être synchronisés, et que l’on commence à les construire comme deux modes de fonctionnement d’une seule couche unifiée. Pour être plus précis :
Un vector lakebase est une nouvelle architecture native de l’IA et native du lac, issue de l’évolution des systèmes de bases de données vectorielles. Il combine les capacités de service à haut QPS et faible latence des bases de données vectorielles avec l’ouverture, la scalabilité et l’efficacité économique des lacs de données multimodaux, tout en maintenant toutes les charges de travail sur la même source de vérité, sans migration de données. En séparant le calcul du stockage, un vector lakebase stocke les données multimodales, les vecteurs, les attributs, les index et les métadonnées directement dans un stockage objet à faible coût, en utilisant des formats ouverts. Les charges de travail de service, de découverte et d’analytics peuvent ensuite s’exécuter indépendamment au-dessus des mêmes données.
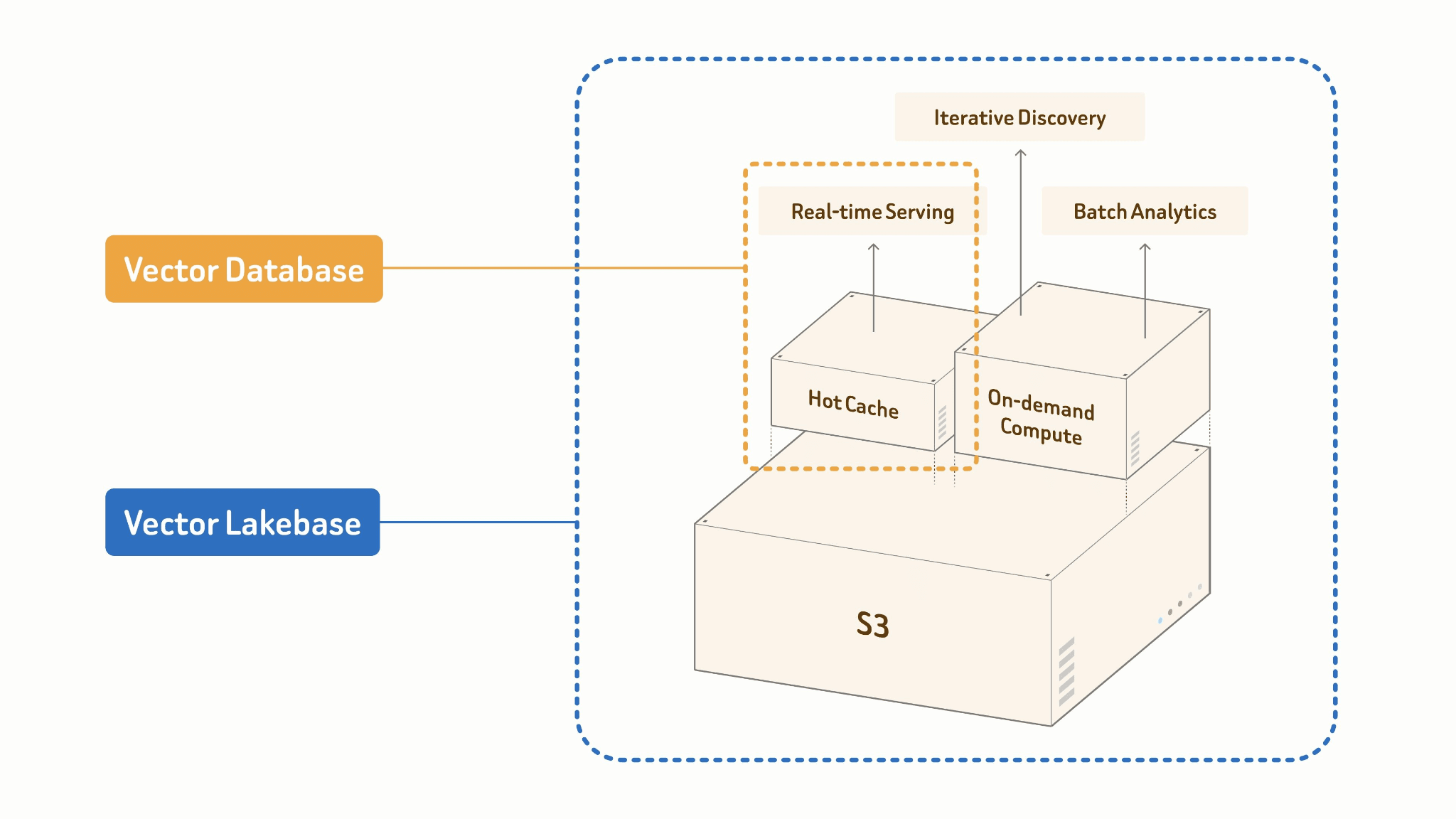
Le principe fondamental : Une seule source de vérité.
Votre table de lac est la source unique de vérité. Le service en ligne et le traitement batch hors ligne partagent les mêmes données, index et schéma. Il n’y a pas de pipeline entre eux parce qu’il n’y a pas de frontière entre eux.
Vector DB: [Lake] ──ETL──▶ [Vector DB] # duplication + staleness
Vector Lake: [Lake + Index] ◀── batch query only # no serving, no processing
Vector Lakebase: [Lake + Index + Compute]
├── Online: Cache + High-performance Index
│ → ANN query, <100ms p99 serving
└── Offline: Batch Processing + Cost-efficient Index Build
→ embed, cluster, dedup, feature engineering
Les deux modes sont conçus différemment par nécessité. Le service en ligne s’exécute sur un cache chaud et un index en mémoire haute performance — optimisés pour la concurrence et la latence de queue. Les tâches batch hors ligne construisent des index de manière rentable à grande échelle : scans colonnaires, construction accélérée par GPU, écritures échelonnées vers le lake. Mêmes données, même format d’index, profils de calcul radicalement différents.
À quoi cela ressemble-t-il en pratique ? Sur une table Iceberg de 1 milliard de vecteurs :
| Mode | Latence | Contexte |
|---|---|---|
| Scan Spark brute-force (sans index) | Heures | Valeur par défaut actuelle pour la recherche vectorielle basée sur le lake |
| Vector Lakebase — froid (index tout juste construit) | ~30 secondes | L’index se construit depuis Iceberg en ~20 minutes |
| Vector Lakebase — tiède (cache disque) | Dizaines de ms | Index mis en cache sur SSD local |
| Vector Lakebase — chaud (en mémoire) | Quelques ms | RAG de production et service d’agents |
| Vector Lakebase — clustering / déduplication | Heures | KMeans sur 1 milliard de vecteurs ou détection de quasi-doublons, entièrement distribuée |
Vous passez de plusieurs heures à quelques millisecondes — et vous ne copiez jamais les données hors du lake.
Ce n’est pas un choix de produit. C’est la direction vers laquelle l’architecture des données IA converge. Tout système qui exige que les données existent à deux endroits vous impose une taxe permanente — en stockage, en heures d’ingénierie, en obsolescence. Les systèmes qui séparent le stockage des opérations IA paraîtront transitoires avec le recul.
Ce qu’une Vector Lakebase permet réellement
Au moins trois classes de charges de travail qui nécessitaient auparavant des systèmes séparés peuvent désormais être traitées avec une vector lakebase.
Collections externes : rendez votre lake consultable sans rien déplacer
Vous avez des pétaoctets d’embeddings dans des fichiers Parquet sur S3. Les rendre consultables pour une nouvelle application RAG aujourd’hui signifie les charger dans une base de données vectorielle — une migration qui se compte en jours ou en semaines, plus une obligation de synchronisation continue.
Les collections externes de Vector Lakebase travaillent avec la gravité des données plutôt que contre elle. Vous pointez vers le bucket, définissez un mappage de schéma sur vos colonnes existantes, et construisez un index vectoriel sur place. Les données restent dans S3. L’index persiste dans S3. Lorsque les données sources sont mises à jour, vous actualisez de manière incrémentale — seuls les fichiers modifiés sont retraités.
# 1. Register your existing lake data as an external collection
client.create_external_collection(
collection_name="enterprise_docs",
src="s3://my-lake/docs/*.parquet", # point at your existing data
schema={"text": String, "embedding": FloatVector(768)},
)
# 2. Build a vector index — data stays in S3, index persists back to S3
client.create_index("enterprise_docs", field="embedding", index_type="HNSW")
# ~20 min for 1B vectors. Data never moves.
# 3. Search — single-digit ms with in-memory cache
results = client.search(
collection_name="enterprise_docs",
data=[query_embedding],
top_k=10,
output_fields=["text"],
)
Pas de migration, pas de pipeline, pas de nouveau coût de stockage. Votre système RAG interroge les mêmes données que votre équipe d’analytique gouverne déjà — via Spark, Ray, LangChain, PyMilvus ou une API REST. L’index devient une propriété de premier ordre de la table, et non un système étranger greffé à côté.
ETL, ingénierie des features et ingénierie du contexte
C’est la charge de travail que Vector Database et Vector Lake ignorent toutes deux — et elle devient la partie la plus importante de la stack de données IA.
Les opérations de données natives pour l’IA ne se contentent pas de déplacer les données entre des systèmes — elles les enrichissent avec une signification sémantique, sur place, à grande échelle :
- Ajouter une colonne d’embeddings à une table existante : inférence par lots sur 100 M de lignes, écriture des résultats dans la même table.
- Découper un corpus de documents pour le RAG, en conservant les documents bruts et les chunks versionnés ensemble.
- Passer de text-embedding-3-small à un modèle plus récent — réindexer les 500 M de vecteurs en place, avec coexistence des anciens et des nouveaux embeddings jusqu’au basculement.
- Construire et versionner les packages de contexte que vos agents IA récupèrent à l’exécution — ce qui est récupéré, comment c’est structuré, comment c’est compressé pour une fenêtre de contexte.
À mesure que les modèles se banalisent, la qualité de ce que vous leur fournissez compte davantage que le modèle que vous choisissez. Cette discipline émergente — Context Engineering — a sa place dans le lake : au plus près des données, versionnée avec elles, reproductible de bout en bout. Vector Lakebase en fait une opération de premier ordre, et non des scripts ad hoc assemblés avec des tâches cron.
Clustering, déduplication et découverte d’anomalies
Essentiel pour toute équipe entraînant ou affinant ses propres modèles — et totalement absent du paradigme des bases de données vectorielles :
- Déduplication : Les exemples quasi dupliqués dans votre jeu de données de fine-tuning LLM gonflent la perte d’entraînement et biaisent le comportement du modèle. Identifiez les quasi-doublons, produisez un ensemble canonique, réécrivez les étiquettes de déduplication sous forme de colonne.
- Clustering : Comprendre ce que contient réellement votre jeu de données avant l’entraînement. Regroupez votre espace d’embeddings — vous découvrirez souvent que 40 % d’un jeu de données « diversifié » n’est constitué que de variations mineures sur les mêmes quelques sujets.
- Découverte d’anomalies : Pour les véhicules autonomes, la robotique ou tout modèle critique pour la sécurité — trouver les 0,1 % d’échantillons qui ne ressemblent en rien au reste. Les signaler, les prioriser pour l’annotation et les inclure dans l’entraînement. Vous ne pouvez pas les trouver sans index ; vous ne pouvez pas agir dessus sans réécrire les résultats dans le lake.
Vector Lakebase traite ces opérations comme des opérations distribuées de premier ordre : conscientes des index, parallélisées au plus près des données, avec écriture des résultats dans des formats ouverts. Le résultat d’une exécution de déduplication devient une colonne dans la même table.
Qui construit déjà là-dessus
Les premiers partenaires de conception de Vector Lakebase couvrent deux des problèmes de données IA à grande échelle les plus difficiles.
Des leaders de la conduite autonome et des véhicules électriques l’utilisent pour extraire des cas limites de milliards d’embeddings de scènes de conduite — les rares scénarios routiers qui déterminent si un système autonome est sûr. Une entreprise de premier plan dans les modèles de fondation l’utilise pour la détection de quasi-doublons dans des corpus de pré-entraînement — dédupliquant des milliards d’exemples afin d’améliorer la qualité du modèle avant qu’une seule heure GPU ne soit dépensée en entraînement.
Nous avons déjà Databricks Lakebase. En faut-il un autre ?
C’est une question légitime, et la réponse exige de comprendre ce qu’est réellement Databricks Lakebase.
Databricks Lakebase — construit sur leur acquisition de Neon — intègre un moteur PostgreSQL serverless à la plateforme Databricks. Le problème qu’il résout : OLTP et OLAP ont toujours été des systèmes séparés. Databricks est en train d’effacer cette frontière. C’est un vrai problème qui mérite d’être résolu. Mais c’est un problème fondamentalement différent.
| Databricks Lakebase | Vector Lakebase | |
|---|---|---|
| Utilisateur principal | Ingénieurs backend, ingénieurs data | Ingénieurs ML, équipes plateforme IA |
| Données principales | Lignes, comptes, transactions | Embeddings, documents, multimodal |
| Modèle de stockage | Stockage Postgres + Delta Lake (séparés) | Table lake unique, unifiée |
| Embedding par lots / dédup | Hors périmètre | Opération de premier ordre |
| Context Engineering | Hors périmètre | Capacité centrale |
| S’appuie sur le lake existant | Partiel | Oui — zéro migration |
| Optimisation des formats | Delta Lake, Parquet | Parquet, Vortex, Lance, Apache Iceberg, données non structurées natives |
| OLTP (transactions) | ✓ | N/A |
Databricks Lakebase efface la frontière OLTP/OLAP. Vector Lakebase efface la frontière entre l’endroit où vivent vos données IA et l’endroit où s’exécutent vos opérations IA. Ils sont complémentaires, pas concurrents. De nombreuses équipes utiliseront les deux.
Le pari architectural
En 2013, Databricks a posé la question : Et si l’analytique SQL vivait dans le lake ? Cette question valait 40 milliards de dollars.
La prochaine question est : Et si les opérations de données AI-native — récupération RAG, mémoire d’agent, embedding par lots, curation des données d’entraînement des modèles, context engineering — vivaient aussi dans le lake ?
C’est le pari derrière Vector Lakebase. Pas une nouvelle base de données vers laquelle migrer. Pas une couche de requête greffée sur votre lake existant. Une fondation unifiée où vos données résident une seule fois, sont indexées une seule fois, et servent chaque charge de travail d’IA — sans duplication, sans surcharge d’ETL, sans lutter contre la gravité.
La course à l’IA récompense la vitesse. Chaque semaine que votre équipe passe à construire des pipelines de synchronisation, à déboguer des données obsolètes ou à migrer entre des systèmes est une semaine que vos concurrents passent à livrer des fonctionnalités d’IA. L’infrastructure devrait être un accélérateur, pas un goulot d’étranglement. Les équipes qui gagnent ne sont pas celles qui ont les meilleurs modèles — ce sont celles qui ont supprimé les frictions entre leurs données et leur IA.
Construisez sur vos tables Iceberg existantes ou votre data lake. Pas de migration. Pas de duplication. Avancez vite — vos données restent là où elles sont, et deviennent consultables, traitables et prêtes pour l’IA en quelques minutes.
C’est Vector Lakebase.
Zilliz Vector Lakebase est disponible en aperçu public
Nous avons lancé l’aperçu public de Zilliz Vector Lakebase — une évolution majeure de Zilliz Cloud, passant d’une base de données vectorielle managée à une plateforme de données sémantique unifiée, combinant le service vectoriel à faible latence avec l’ouverture, la scalabilité et l’économie d’un data lake.
Capacités principales de Zilliz Vector Lakebase :
- Service en niveaux optimisé pour différents compromis performance-coût en temps réel
- Recherche à la demande pour les charges de travail à grande échelle ou exploratoires sans calcul toujours actif
- Recherche dans un data lake externe — indexez et recherchez directement sur vos données de lake existantes
- Recherche sur tout le spectre à travers les vecteurs, le texte, JSON et les données géospatiales avec récupération hybride et reranking
- Stockage unifié lake-native basé sur Vortex, un format ouvert avec des lectures aléatoires plus rapides et moins coûteuses que Lance ou Parquet
Si votre stack actuelle sépare le service et la découverte en systèmes distincts, Vector Lakebase mérite peut-être votre attention. Essayez-le sur Zilliz Cloud — les nouvelles inscriptions avec un e-mail professionnel obtiennent 100 $ de crédits gratuits — ou contactez-nous pour discuter de votre cas d’usage.

Continuer à lire

Zilliz Cloud BYOC Now Available Across AWS, GCP, and Azure
Zilliz Cloud BYOC is now generally available on all three major clouds. Deploy fully managed vector search in your own AWS, GCP, or Azure account — your data never leaves your VPC.

Optimizing Embedding Model Selection with TDA Clustering: A Strategic Guide for Vector Databases
Discover how Topological Data Analysis (TDA) reveals hidden embedding model weaknesses and helps optimize vector database performance.

Selecting the Right ETL Tools for Unstructured Data to Prepare for AI
Learn the right ETL tools for unstructured data to power AI. Explore key challenges, tool comparisons, and integrations with Milvus for vector search.