




Défis infrastructurels liés à la mise à l'échelle de RAG avec des modèles d'IA personnalisés
Les systèmes Retrieval Augmented Generation (RAG) ont considérablement amélioré les applications d'intelligence artificielle en fournissant des réponses plus précises et plus pertinentes sur le plan contextuel. Toutefois, la mise à l'échelle et le déploiement de ces systèmes en production ont présenté des défis considérables à mesure qu'ils devenaient plus sophistiqués et qu'ils incorporaient des modèles d'IA personnalisés.
Lors d'un récent Unstructured Data Meetup organisé par Zilliz, Chaoyu Yang, fondateur et PDG de BentoML, a partagé son point de vue sur les obstacles liés à l'infrastructure lors de la mise à l'échelle des systèmes RAG avec des modèles d'IA personnalisés et a souligné comment des outils tels que BentoML pouvaient simplifier le déploiement et la gestion de ces composants. Ce billet récapitule les points clés de Chaoyu Yang et explore les modèles d'inférence avancés et les techniques d'optimisation. Ces stratégies vous aideront à construire des systèmes RAG non seulement puissants, mais aussi efficaces et rentables.
Regardez la rediffusion de l'exposé de Chaoyu sur Youtube
Comment le RAG renforce les applications d'IA
Les systèmes RAG (Retrieval Augmented Generation) sont apparus pour résoudre le problème des hallucinations dans les applications GenAI. En intégrant les capacités de recherche de similarité vectorielle des bases de données vectorielles telles que Milvus et Zilliz Cloud à la puissance générative des grands modèles de langage (LLM), les systèmes RAG permettent aux modèles d'IA de produire des réponses qui sont :
plus précises
pertinentes sur le plan contextuel
Incroyablement informatif
Sans hallucinations
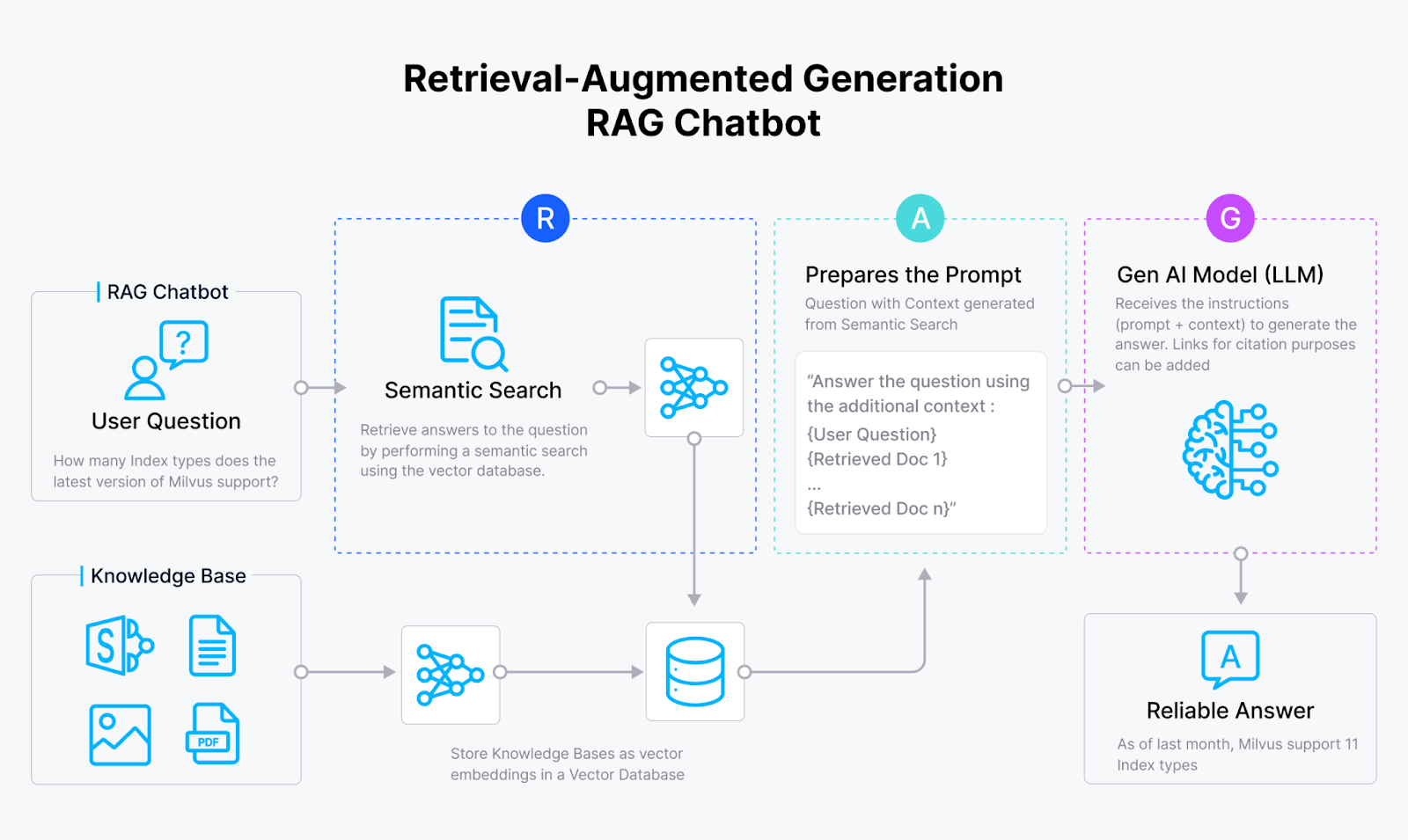
Comment fonctionne un chatbot RAG
Ces systèmes ont le potentiel de transformer un large éventail de domaines, y compris :
la réponse aux questions
le résumé de documents
Génération de contenu personnalisé
Et bien d'autres choses encore.
Les systèmes RAG atteignent cet objectif en puisant dans les vastes connaissances cachées dans les sources externes, à la manière d'un bibliothécaire de l'IA !
Défis liés au déploiement des systèmes RAG en production
Les systèmes RAG ont leurs propres défis à relever avant de pouvoir sauver la situation dans les environnements de production. L'un des plus grands obstacles consiste à garantir des performances de récupération de premier ordre, ce qui implique :
Optimiser le rappel: S'assurer que toutes les informations pertinentes sont récupérées.
L'optimisation de la précision : minimiser la quantité d'informations non pertinentes.
Pour rendre les choses encore plus intéressantes, les systèmes RAG doivent souvent traiter des sources de données complexes et non structurées. Imaginez que vous ayez à comprendre un PDF contenant plus de mises en page, de tableaux et d'images qu'une bande dessinée ! Ce problème nécessite des techniques de traitement et de compréhension des documents très sophistiquées.
Un autre défi auquel sont confrontés les systèmes RAG est de générer des réponses précises, adaptées au contexte et alignées sur l'intention de l'utilisateur. C'est comme écrire une histoire cohérente en utilisant uniquement des extraits de différents livres !
En outre, il est essentiel de garantir la sécurité et la fiabilité du contenu généré, en particulier lorsque les enjeux sont importants. Nous ne voulons pas que nos systèmes d'intelligence artificielle s'égarent et diffusent des informations erronées !
Les modèles d'IA personnalisés sont le fidèle acolyte de cette histoire. En affinant et en adaptant les modèles d'IA à des domaines et à des ensembles de données spécifiques, les développeurs peuvent donner à leurs systèmes RAG les superpouvoirs dont ils ont besoin pour relever ces défis.
Exploiter des modèles d'IA personnalisés pour améliorer les performances des systèmes RAG
Pour exploiter tout le potentiel des systèmes RAG, il est essentiel d'utiliser des modèles d'IA personnalisés, adaptés à notre cas d'utilisation spécifique. En affinant et en optimisant ces modèles, nous pouvons considérablement augmenter leurs performances. Examinons quelques domaines clés dans lesquels les modèles d'IA personnalisés peuvent avoir un impact significatif.
Modèles d'intégration de texte : La base du succès des RAG
Les modèles d'intégration de texte par défaut, comme "text-embedding-ada-002", ne parviennent souvent pas à saisir les nuances de notre domaine spécifique. Ce modèle est classé 57e sur le [MTEB leaderboard] (https://zilliz.com/glossary/massive-text-embedding-benchmark-(mteb)), ce qui indique une marge d'amélioration importante.
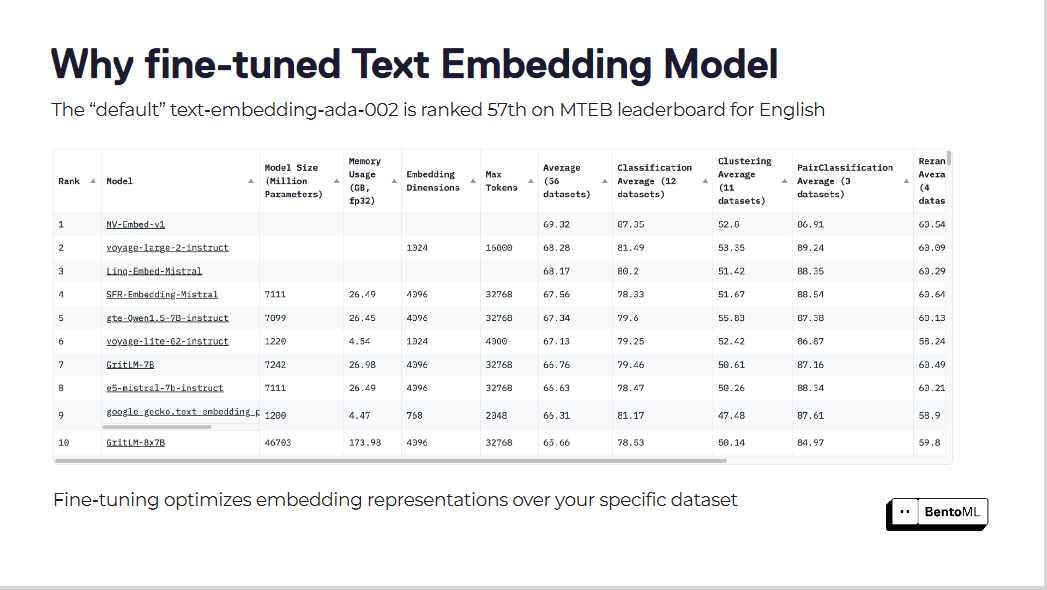
Le réglage fin optimise les représentations d'intégration sur votre ensemble de données spécifique.
Le réglage fin de ces modèles d'intégration peut conduire à des améliorations remarquables des scores de recherche. En optimisant les modèles d'intégration pour leurs ensembles de données spécifiques, les systèmes RAG ont enregistré des gains de performance substantiels.
Hébergement de nos LLM : Prendre le contrôle
Les LLM propriétaires sont pratiques mais ne répondent pas toujours à nos besoins ou à nos contraintes. Les LLM à source ouverte nous permettent de personnaliser et d'adapter les modèles à nos exigences. Lors de l'hébergement de nos LLM, nous devons prendre en compte les facteurs clés suivants :
Sécurité et confidentialité des données
Latence et performance
Capacités spécifiques nécessaires
Coût et évolutivité
Maintenance et assistance
Traitement et compréhension des documents : Extraire des informations de données non structurées
Les systèmes RAG doivent souvent traiter et comprendre des documents complexes et non structurés tels que des PDF, des images, etc. L'intégration de divers modèles et techniques peut aider à extraire des informations précieuses. Par exemple, nous pouvons effectuer :
Analyse de la mise en page avec LayoutLM
Détection des tableaux avec Table Transformers TATR
OCR avec EasyOCR ou Tesseract
Assurance qualité des documents visuels avec LayoutLM v3 ou Donut
L'adaptation de ces modèles à vos types de documents spécifiques peut grandement améliorer leurs performances.
Techniques avancées pour améliorer la précision de la recherche
Pour améliorer encore la précision de la recherche, nous pouvons envisager de mettre en œuvre les techniques suivantes :
Context-aware chunking et global concept-aware chunking: Ces méthodes permettent d'identifier les informations les plus pertinentes pour la recherche en tenant compte du contexte et des concepts généraux dans les documents.
Extraction de métadonnées:** L'extraction de métadonnées à partir de documents peut fournir un contexte supplémentaire pour améliorer la recherche et la synthèse des réponses.
Modèles de reclassement:** La mise au point de modèles de reclassement sur des ensembles de données personnalisés peut permettre d'améliorer les performances de 10 à 30 % par rapport aux modèles génériques.
En exploitant des modèles d'IA personnalisés dans ces domaines clés, nous pouvons améliorer de manière significative les performances de notre système RAG.
Cependant, déployer et servir ces modèles de manière efficace comporte son lot de défis. Dans la section suivante, nous aborderons certains défis liés à l'infrastructure dans la mise à l'échelle de RAG avec des modèles personnalisés.
Défis d'infrastructure dans la mise à l'échelle de RAG avec des modèles personnalisés
À mesure que les systèmes RAG deviennent plus complexes et intègrent de multiples modèles personnalisés, la demande en ressources informatiques et la nécessité d'un déploiement et d'une gestion efficaces augmentent considérablement. La mise à l'échelle des systèmes RAG (Retrieval Augmented Generation) avec des modèles d'IA personnalisés devient une nécessité urgente, mais elle s'accompagne d'un ensemble unique de défis en matière d'infrastructure.
Service efficace des API d'inférence de modèles personnalisés
L'un des principaux défis consiste à servir efficacement les API d'inférence de modèles personnalisés. Les systèmes RAG nécessitent souvent l'intégration de plusieurs modèles, tels que :
Modèles d'intégration de texte
Modèles de langues étendues (LLM)
Modèles de traitement de documents
Chaque modèle peut avoir des exigences de calcul et des caractéristiques de performance différentes. Le déploiement de ces modèles en tant qu'API d'inférence capables de traiter des demandes en temps réel et de s'adapter à la demande est complexe.
Pour relever ce défi, il est essentiel de disposer d'une infrastructure robuste et évolutive pour servir les API d'inférence de modèles. Cette infrastructure doit être capable de gérer les exigences spécifiques de chaque modèle, telles que l'allocation de GPU, la gestion de la mémoire et les contraintes de latence. Les technologies de conteneurisation telles que Docker peuvent aider à encapsuler les dépendances des modèles et à fournir un environnement d'exécution cohérent sur différents systèmes.
Mécanismes de mise à l'échelle efficaces
Toutefois, il ne suffit pas de conteneuriser les modèles. L'infrastructure doit également prendre en charge des mécanismes de mise à l'échelle efficaces pour gérer des charges de travail variables. Il s'agit notamment d'adapter automatiquement le nombre d'instances de modèles en fonction du trafic de requêtes entrant, d'assurer une utilisation optimale des ressources et de réduire au minimum les temps de réponse.
Optimisation du service de modèle
L'optimisation du service de modèle en termes de performances et de rentabilité constitue un autre défi majeur. Les modèles d'IA personnalisés, en particulier les grands modèles de langage, peuvent être coûteux en termes de calcul. Des stratégies de déploiement naïves peuvent conduire à une utilisation sous-optimale des ressources et à une augmentation des coûts. Des techniques telles que la mise en lots dynamique, où plusieurs requêtes sont regroupées pour exploiter le parallélisme des GPU, peuvent améliorer de manière significative le débit et réduire les temps de réponse.
Outre la mise en lots dynamique, d'autres techniques d'optimisation, telles que la quantification, l'élagage et la distillation de modèles, peuvent être appliquées pour réduire l'empreinte mémoire et les besoins de calcul des modèles personnalisés. Toutefois, la mise en œuvre de ces optimisations nécessite un examen minutieux des compromis entre les performances du modèle et l'efficacité des ressources.
Allocation efficace des ressources et mise à l'échelle automatique
L'allocation efficace des ressources et la mise à l'échelle automatique sont également des aspects essentiels de la mise à l'échelle des systèmes RAG avec des modèles personnalisés. L'infrastructure doit être en mesure d'allouer dynamiquement les ressources en fonction des exigences de charge de travail de chaque modèle. Cette approche implique la surveillance de mesures clés telles que l'utilisation du GPU, l'utilisation de la mémoire et la latence des requêtes afin de prendre des décisions éclairées en matière de mise à l'échelle. Les mécanismes de mise à l'échelle automatique doivent être capables de gérer les pics soudains de trafic et d'adapter les ressources en conséquence pour maintenir des performances optimales.
Composition et orchestration de plusieurs modèles
En outre, l'infrastructure doit prendre en charge la composition et l'orchestration de plusieurs modèles au sein d'un système RAG. Les systèmes RAG impliquent souvent des pipelines complexes où la sortie d'un modèle sert d'entrée à un autre. L'infrastructure doit fournir des outils et des cadres pour définir et gérer ces pipelines, en assurant un flux de données transparent et une exécution efficace.
Surveillance et observabilité
La surveillance et l'observabilité sont cruciales pour maintenir la santé et la performance des systèmes RAG avec des modèles personnalisés. L'infrastructure doit fournir des capacités de surveillance complètes pour suivre les mesures clés, les journaux et les traces dans tous les composants du système. Cela permet de détecter et de diagnostiquer rapidement les problèmes et d'optimiser et d'affiner le système sur la base de données de performance réelles.
Intégration et déploiement continus (CI/CD)
Enfin, l'infrastructure doit prendre en charge l'intégration et le déploiement continus des modèles personnalisés (CI/CD). Au fur et à mesure que les modèles sont mis à jour et affinés, un processus rationalisé de déploiement des nouvelles versions doit être mis en place sans perturber le système dans son ensemble. Cela nécessite de solides mécanismes de versionnement, de test et de retour en arrière afin de garantir la stabilité et la fiabilité du système RAG.
Pour relever ces défis en matière d'infrastructure, il faut une combinaison d'outils, de cadres et de bonnes pratiques. Dans la section suivante, nous verrons comment BentoML, une plateforme pour servir et déployer des modèles d'apprentissage automatique, peut aider à relever ces défis et à simplifier la mise à l'échelle des systèmes RAG avec des modèles d'IA personnalisés.
Construire des API d'inférence pour des modèles personnalisés avec BentoML
BentoML simplifie le processus de construction et de déploiement des API d'inférence pour les modèles personnalisés dans les systèmes RAG. Il assure une transition transparente entre le développement de modèles et les API prêtes pour la production, ce qui permet une itération plus rapide et une intégration plus facile avec les systèmes existants. Voyons comment il peut nous aider à surmonter les défis liés à l'infrastructure pour la mise à l'échelle de RAG.
Du script d'inférence au point final de service
Avec seulement quelques lignes de code, vous pouvez facilement convertir votre script d'inférence en un point final de service à l'aide de BentoML. Examinons un exemple de création d'un service BentoML pour un modèle d'intégration de texte affiné :
import torch
from sentence_transformers import SentenceTransformer, models
classe SentenceTransformers :
def __init__(self) :
self.model = SentenceTransformer(
"bentoml/my-fine-tuned-model",
device="cuda"
)
def encode(
self,
sentences : t.List[str],
) -> np.ndarray :
return self.model.encode(sentences)
Cet extrait de code définit la classe SentenceTransformers pour encapsuler le modèle d'encapsulation et ses méthodes associées. Dans la méthode __init__` `, le modèle SentenceTransformer est initialisé avec un modèle finement ajusté et configuré pour fonctionner sur le périphérique "cuda". La méthode ``encode prend une liste de phrases en entrée et retourne leurs embeddings sous la forme d'un tableau NumPy.
Pour transformer ceci en un service BentoML, vous pouvez ajouter les décorateurs @bentoml.service` ` et @bentoml.api :
import bentoml
@bentoml.service
classe SentenceTransformers :
def __init__(self) :
self.model = SentenceTransformer(
"bentoml/my-fine-tuned-model",
device="cuda"
)
@bentoml.api
def encode(
self,
sentences : t.List[str],
) -> np.ndarray :
return self.model.encode(sentences)
Pour servir le modèle, vous pouvez utiliser le CLI de BentoML :
bentoml serve .
Cette commande démarre le serveur BentoML et sert le modèle défini dans le répertoire courant. La sortie CLI montre que le service écoute sur [http://localhost:3000](http://localhost:3000).
Vous pouvez alors faire des requêtes au modèle servi en utilisant le client BentoML :
import bentoml
with bentoml.SyncHTTPClient("http://localhost:3000") as client :
result : np.NDArray = client.encode(
sentences=["sample input sentence"],
)
Optimisation du service
BentoML fournit plusieurs optimisations de service prêtes à l'emploi. L'une des optimisations les plus puissantes est la mise en lots dynamique. En ajoutant le paramètre ```batchable=True` `` à votre définition d'API, BentoML met automatiquement en lots les requêtes entrantes, optimisant l'utilisation du GPU et améliorant le débit pour le service du modèle.
@bentoml.api(batchable=True)
def encode(self, sentences : t.List[str]) -> np.ndarray :
return self.model.encode(sentences)
La mise en lots dynamique forme intelligemment de petits lots en regroupant les requêtes entrantes, en décomposant les gros lots et en ajustant automatiquement la taille du lot. Cette optimisation peut apporter un temps de réponse trois fois plus rapide et une amélioration d'environ 200 % du débit pour le service d'encodage.
Infrastructure de déploiement et de service
BentoML offre un déploiement et une infrastructure flexibles et évolutifs pour le service. Il prend en charge diverses options de déploiement, notamment la conteneurisation avec Docker et l'orchestration avec Kubernetes. Vous pouvez facilement spécifier les besoins en ressources, tels que le nombre et le type de GPU, et configurer les paramètres de trafic tels que la concurrence et les files d'attente externes.
import bentoml
@bentoml.service(
resources={
"gpu" : 1,
"gpu_type" : "nvidia-tesla-t4",
},
traffic={
"concurrency" : 512,
"external_queue" : True
}
)
classe SentenceTransformers :
def __init__(self) :
...
@bentoml.api(batchable=True)
def encode(
...
) :
...
Les capacités de micro-batching adaptatif et de mise à l'échelle élastique de BentoML garantissent une utilisation optimale des ressources et une mise à l'échelle automatique en fonction du trafic entrant. Il fournit également un tableau de bord de déploiement convivial qui donne un aperçu du taux de requête, du temps de réponse et de l'utilisation des ressources. Voyons maintenant comment mettre à l'échelle l'inférence LLM avec BentoML.
Mise à l'échelle des services d'inférence LLM avec BentoML
BentoML fournit des fonctionnalités et des optimisations complètes pour vous aider à mettre à l'échelle vos services d'inférence LLM de manière efficace.
Stratégies de mise à l'échelle automatique
L'autoscaling garantit que vos services d'inférence LLM peuvent gérer des charges de travail variables et maintenir des performances optimales. Cependant, les mesures traditionnelles d'autoscaling telles que l'utilisation du GPU et les requêtes par seconde (QPS) peuvent ne pas refléter avec précision le nombre de répliques souhaité pour les services LLM.
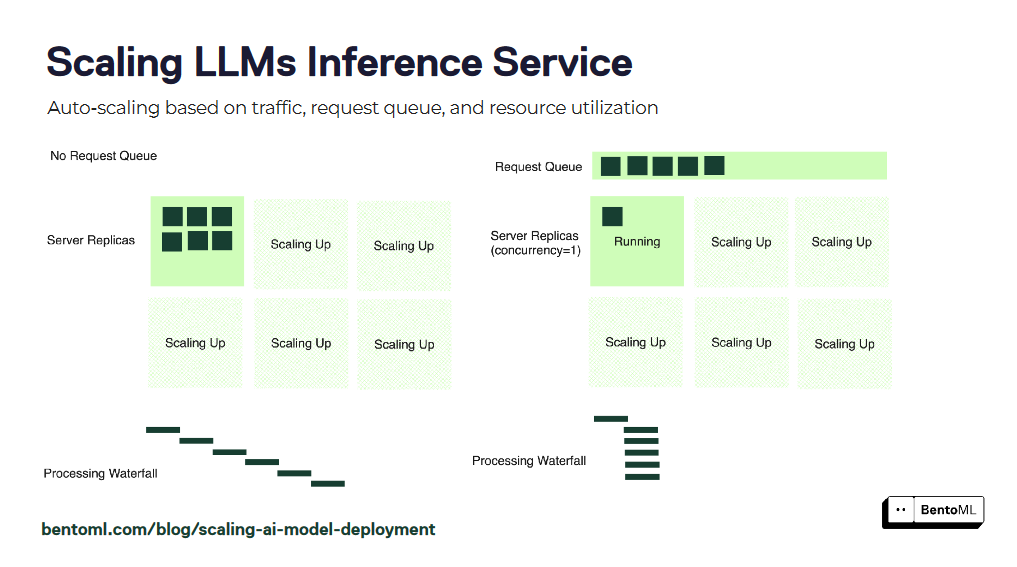
BentoML introduit l'autoscaling basé sur la concurrence, une approche plus efficace pour la mise à l'échelle des services d'inférence LLM. L'autoscaling basé sur la concurrence considère le nombre de requêtes concurrentes que chaque réplique de modèle peut gérer, fournissant une représentation plus précise de la capacité du service.
Optimisation du démarrage à froid
Les démarrages à froid peuvent représenter un défi important lors de la mise à l'échelle des services d'inférence LLM, en particulier avec des images de conteneur et des fichiers de modèle volumineux. BentoML propose plusieurs techniques d'optimisation pour réduire la latence des démarrages à froid.
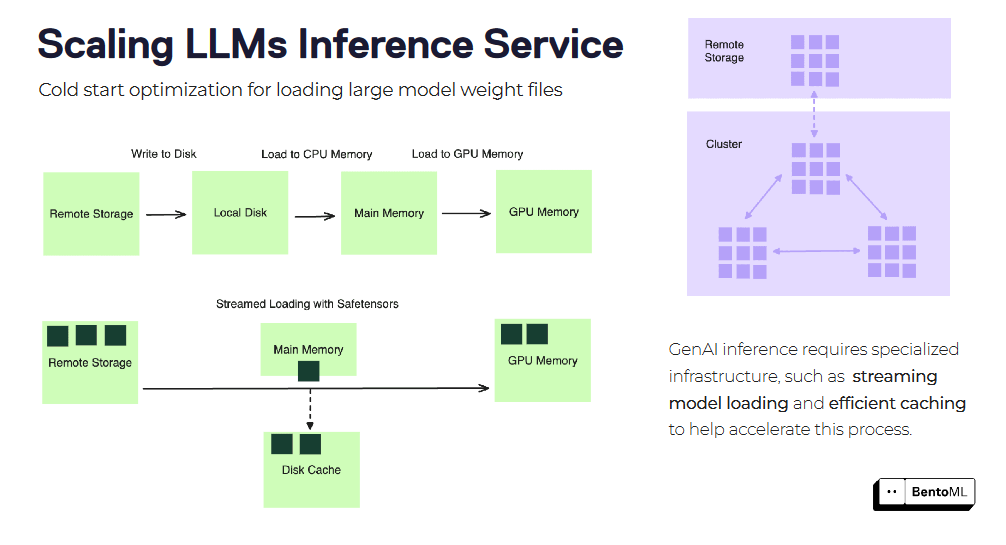
L'une de ces techniques est le chargement en continu des images de conteneurs. Au lieu de télécharger l'intégralité de l'image du conteneur avant de démarrer le service, BentoML peut charger l'image en continu, en récupérant uniquement les fichiers nécessaires à la demande. Cela permet de réduire considérablement le temps de démarrage des nouvelles répliques.
Une autre optimisation est le chargement et la mise en cache efficaces des fichiers de poids de modèle. BentoML peut mettre en cache les poids de modèle chargés dans les répliques, réduisant ainsi le temps nécessaire au chargement du modèle pour chaque nouvelle requête. Ceci est particulièrement bénéfique pour les modèles de langage de grande taille avec des fichiers de poids étendus.
En tirant parti des stratégies de mise à l'échelle automatique et des optimisations de démarrage à froid de BentoML, vous pouvez efficacement mettre à l'échelle vos services d'inférence LLM pour gérer les demandes de votre système RAG. BentoML fait abstraction des complexités de la gestion de l'infrastructure, ce qui vous permet de vous concentrer sur le développement et l'itération de vos modèles tout en garantissant des performances et une évolutivité optimales.
Modèles d'inférence avancés pour les systèmes RAG
Les systèmes RAG nécessitent souvent des modèles d'inférence avancés pour gérer des flux de travail complexes et optimiser les performances. BentoML fournit un cadre flexible et extensible pour prendre en charge ces modèles, ce qui permet de créer facilement des systèmes RAG sophistiqués.
Les pipelines de traitement de documents peuvent être construits en combinant plusieurs modèles et étapes de traitement, tels que l'analyse de la mise en page, l'extraction de tableaux et l'OCR.
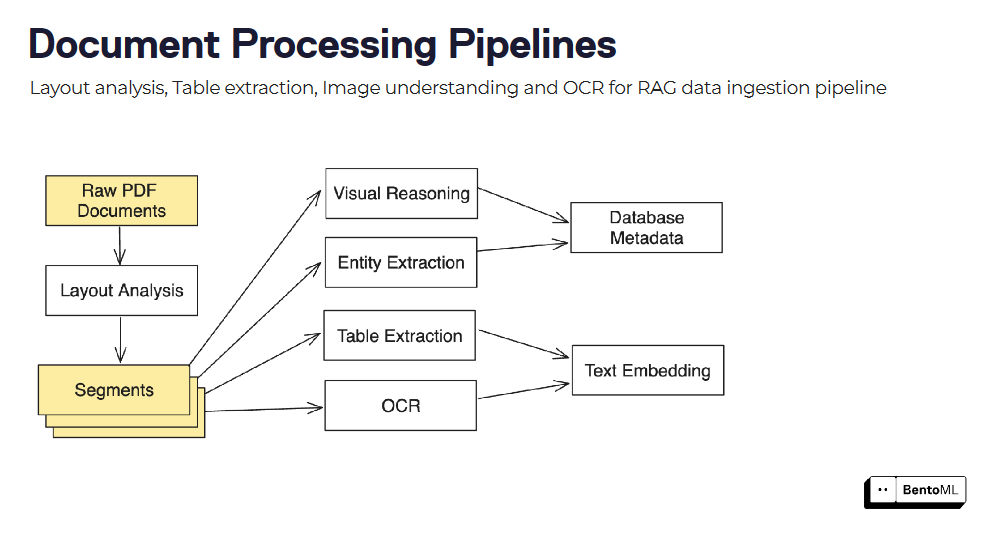
L'interface d'inférence asynchrone de BentoML gère efficacement les tâches de longue durée, tandis que son support d'inférence par lots permet de traiter de grands ensembles de données en tirant parti du parallélisme et des optimisations.
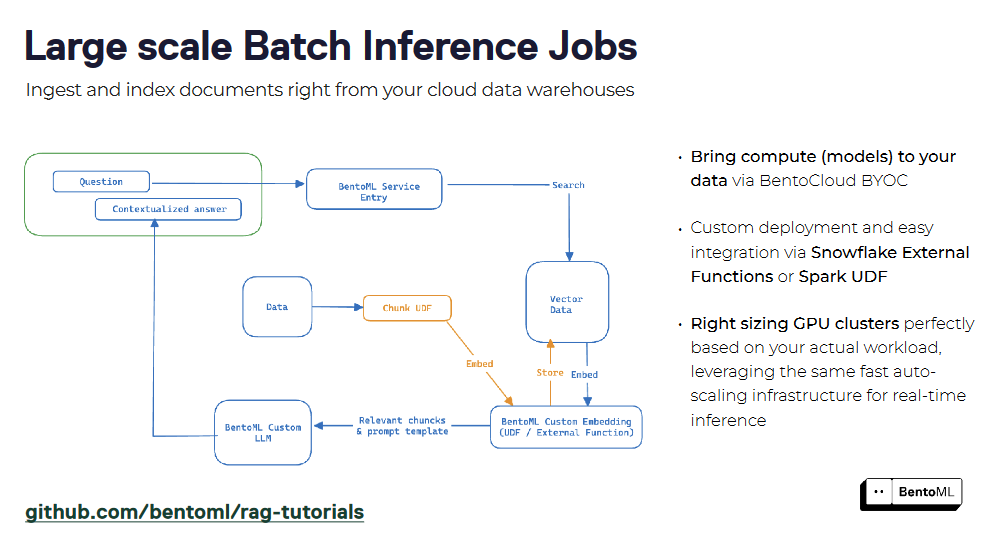
Les systèmes RAG peuvent être présentés comme un service à l'aide de BentoML, créant ainsi une interface unifiée pour l'interrogation et l'interaction. En encapsulant les composants du récupérateur et du générateur, vous pouvez déployer facilement un service RAG et l'intégrer à d'autres applications. La prise en charge de la conteneurisation et de l'orchestration par BentoML simplifie la mise à l'échelle et la gestion des services RAG dans les environnements de production.
Ces modèles d'inférence avancés illustrent la flexibilité et l'extensibilité de BentoML dans la construction de services RAG puissants et efficaces qui gèrent diverses tâches et charges de travail.
Outre l'infrastructure pour servir les LLM, nous avons également besoin d'une base de données vectorielle robuste pour stocker nos embeddings vectoriels et effectuer une recherche de similarité. C'est là que la base de données vectorielles Milvus nous aide. Dans la section suivante, nous verrons comment construire une application RAG simple en utilisant BentoML et Milvus.
Intégration de BentoML et de la base de données vectorielles Milvus
Milvus est une base de données vectorielles open-source conçue pour la recherche de similarités à haute performance et constitue un composant d'infrastructure essentiel pour la construction de Retrieval Augmented Generation (RAG).
Milvus s'est intégré à BentoML, ce qui facilite la création d'applications RAG évolutives. Cette section vous guidera dans la construction d'une application RAG avec BentoML et la base de données vectorielles Milvus. Dans cet exemple, nous utiliserons Milvus Lite, la version allégée de Milvus, pour un prototypage rapide.
Le jeu de données que nous utilisons est disponible ici : City data.
Étape 1 : Mise en place de l'environnement
Tout d'abord, installez les bibliothèques nécessaires comme indiqué ci-dessous :
# Installer les bibliothèques nécessaires
pip install -U pymilvus bentoml
Étape 2 : Préparer vos données
Nous allons télécharger et traiter les [données de la ville] (https://github.com/ytang07/bento_octo_milvus_RAG/tree/main/data).
import os
import requests
import urllib.request
# Configurer la source de données
repo = "ytang07/bento_octo_milvus_RAG"
directory = "data"
save_dir = "./city_data"
api_url = f "https://api.github.com/repos/{repo}/contents/{directory}"
# Télécharger les fichiers depuis GitHub
response = requests.get(api_url)
data = response.json()
if not os.path.exists(save_dir) :
os.makedirs(save_dir)
for item in data :
if item["type"] == "file" :
file_url = item["download_url"]
file_path = os.path.join(save_dir, item["name"])
urllib.request.urlretrieve(file_url, file_path)
# Traiter les données téléchargées
def chunk_text(filename) :
with open(filename, "r") as f :
text = f.read()
sentences = text.split("\n")
return [s for s in sentences if len(s) > 7]
villes = os.listdir("city_data")
city_chunks = []
pour ville dans villes :
chunked = chunk_text(f "city_data/{city}")
city_chunks.append({
"nom_de_ville" : ville.split(".")[0],
"chunks" : chunked
})
Étape 3 : Configurer les clients BentoML
Nous allons maintenant configurer les clients BentoML pour le modèle d'intégration et le LLM comme indiqué ci-dessous.
import bentoml
# Configurer les points de terminaison et le jeton API
EMBEDDING_ENDPOINT = "YOUR_EMBEDDING_MODEL_ENDPOINT" (POINT DE TERMINAISON DE L'INTÉGRATION)
LLM_ENDPOINT = "VOTRE_LLM_ENDPOINT"
API_TOKEN = "YOUR_API_TOKEN"
# Initialisation des clients BentoML
embedding_client = bentoml.SyncHTTPClient(EMBEDDING_ENDPOINT, token=API_TOKEN)
llm_client = bentoml.SyncHTTPClient(LLM_ENDPOINT, token=API_TOKEN)
Remplacez les points de terminaison et le jeton par les points de terminaison et le jeton de l'API de votre déploiement BentoML. Ces clients nous permettront de générer des embeddings et d'utiliser le modèle de langage pour la génération de texte.
Etape 4 : Générer des Embeddings
Avant de générer des embeddings, créons une fonction d'embedding comme indiqué ci-dessous :
Créer une fonction d'intégration
def get_embeddings(texts) :
# Traite les gros lots de textes
if len(texts) > 25 :
splits = [texts[x : x + 25] for x in range(0, len(texts), 25)]
embeddings = []
pour split dans splits :
embedding_split = embedding_client.encode(sentences=split)
embeddings += embedding_split
return embeddings
# Traiter directement les petits lots
return embedding_client.encode(sentences=textes)
Cette fonction gère les lots pour les grands ensembles de textes, car le modèle d'encodage peut avoir des limites de taille d'entrée.
Générer des embeddings pour tous les chunks.
entrées = []
pour city_dict dans city_chunks :
# Obtenir des embeddings pour les morceaux de texte de chaque ville
embedding_list = get_embeddings(city_dict["chunks"])
# Créer des entrées avec des embeddings et des métadonnées
pour i, embedding dans enumerate(embedding_list) :
entrée = {
"embedding" : embedding,
"sentence" : city_dict["chunks"][i],
"ville" : city_dict["nom_de_ville"],
}
entries.append(entry)
Ici, nous créons une liste d'entrées, chacune contenant l'intégration, la phrase originale et le nom de la ville. Cette structure sera utile lorsque vous insérerez des données dans Milvus.
Étape 5 : configuration de Milvus
Nous allons maintenant initialiser une base de données vectorielle en utilisant Milvus pour ajouter les embeddings.
Initialiser le client Milvus et créer le schéma
from pymilvus import MilvusClient, DataType
COLLECTION_NAME = "Bento_Milvus_RAG" (nom de la collection)
DIMENSION = 384 # Cela devrait correspondre à la dimension de sortie de votre modèle d'intégration
# Initialisation du client Milvus
milvus_client = MilvusClient("milvus_demo.db")
# Créer un schéma
schema = MilvusClient.create_schema(auto_id=True, enable_dynamic_field=True)
schema.add_field("id", DataType.INT64, is_primary=True)
schema.add_field("embedding", DataType.FLOAT_VECTOR, dim=DIMENSION)
Nous utilisons ici Milvus lite, qui est intégré dans l'application. Le schéma définit notre structure de données dans Milvus, y compris un identifiant auto-généré et le vecteur d'intégration.
Préparez les paramètres de l'index et créez une collection
# Préparer les paramètres de l'index
index_params = milvus_client.prepare_index_params()
index_params.add_index(
field_name="embedding",
index_type="AUTOINDEX",
metric_type="COSINE",
)
# Créer ou recréer une collection
if milvus_client.has_collection(collection_name=COLLECTION_NAME) :
milvus_client.drop_collection(collection_name=COLLECTION_NAME)
milvus_client.create_collection(
nom_de_la_collection=nom_de_la_collection, schema=schema, index_params=index_params
)
Nous utilisons AUTOINDEX, qui sélectionne automatiquement le meilleur type d'index en fonction des données. La [similarité cosinusienne] (https://zilliz.com/blog/similarity-metrics-for-vector-search#Cosine-Similarity) est utilisée comme métrique de distance pour les comparaisons de vecteurs.
Insérer les données dans Milvus
Nous allons maintenant insérer les données dans Milvus comme indiqué ci-dessous
# Insérer les données prétraitées dans Milvus
milvus_client.insert(collection_name=COLLECTION_NAME, data=entries)
Cette étape insère toutes nos données prétraitées (embeddings et métadonnées) dans la collection Milvus.
Etape 6 : Implémenter RAG
Pour mettre en œuvre efficacement le RAG, nous allons créer trois fonctions pour générer la réponse RAG, récupérer le contexte pertinent dans la collection et générer la réponse, comme indiqué ci-dessous :
Créer une fonction pour le LLM afin de générer des réponses
def generate_rag_response(question, context) :
# Préparer l'invite pour le LLM
prompt = (
f "Vous êtes un assistant utile. Répondez à la question de l'utilisateur en vous basant uniquement sur le contexte : {contexte}. \n"
f "La question de l'utilisateur est {question}"
)
# Générer la réponse à l'aide du LLM
results = llm_client.generate(max_tokens=1024, prompt=prompt)
return "".join(results)
Cette fonction construit une invite en utilisant le contexte récupéré et la question de l'utilisateur, puis utilise le LLM pour générer une réponse.
Créer une fonction pour récupérer le contexte pertinent
def retrieve_context(question) :
# Génère l'intégration pour la question
embeddings = get_embeddings([question])
# Recherche de vecteurs similaires dans Milvus
res = milvus_client.search(
collection_name=COLLECTION_NAME,
data=embeddings,
anns_field="embedding",
limit=5,
output_fields=["phrase"],
)
# Extraire et combiner les phrases pertinentes
sentences = [hit["entity"]["sentence"] for hits in res for hit in hits]
return ". ".join(sentences)
Cette fonction intègre la question de l'utilisateur, recherche des vecteurs similaires dans Milvus et récupère les morceaux de texte correspondants pour le contexte.
Combinez les fonctions ci-dessus pour créer le pipeline RAG
def ask_question(question) :
# Récupère le contexte pertinent
context = retrieve_context(question)
# Génère une réponse basée sur le contexte et la question
return generate_rag_response(question, context)
Cette fonction lie le tout, créant notre pipeline RAG.
Étape 7 : Utiliser votre système RAG
Nous pouvons maintenant utiliser notre système RAG pour répondre aux questions, comme indiqué ci-dessous :
# Exemple d'utilisation
question = "Dans quel état se trouve Cambridge ?"
answer = ask_question(question)
print(f "Question : {question}")
print(f "Réponse : {réponse}")
Cet exemple montre comment utiliser le système RAG pour répondre à une question spécifique sur une ville.
Remarques importantes :
Avant d'exécuter ce code, assurez-vous que vos modèles d'intégration et de langage étendu sont correctement déployés sur BentoML.
La dimension de vos embeddings (384 dans cet exemple) doit correspondre à la sortie de votre modèle d'embedding.
Cette configuration utilise Milvus Lite, qui convient aux petits ensembles de données. Envisagez d'utiliser un déploiement Milvus complet sur Docker ou K8s pour les applications à plus grande échelle.
L'efficacité du système RAG dépend de la qualité et de la couverture de vos données urbaines initiales. Assurez-vous que votre jeu de données est complet et précis pour obtenir les meilleurs résultats.
L'intégration de BentoML et de Milvus crée un puissant système RAG capable de répondre à des questions basées sur les informations fournies sur les villes. Vous pouvez étendre ce système en ajoutant des données supplémentaires ou en l'adaptant à des cas d'utilisation spécifiques.
Conclusion
La construction et la mise à l'échelle de systèmes Retrieval Augmented Generation (RAG) avec des modèles d'IA personnalisés présentent des défis uniques. Les développeurs peuvent créer des systèmes RAG très performants et évolutifs en exploitant la puissance des modèles personnalisés, en optimisant le déploiement et l'infrastructure de service, et en adoptant des modèles d'inférence avancés.
BentoML est un outil précieux dans ce parcours. Il simplifie le processus de construction et de déploiement des API d'inférence, optimise les performances de service et permet une mise à l'échelle transparente.
En intégrant BentoML à la base de données vectorielles Milvus, les organisations peuvent construire des systèmes RAG plus puissants et évolutifs. Cette combinaison permet de récupérer efficacement les informations pertinentes et de générer des réponses adaptées au contexte, ce qui ouvre la voie à des applications d'IA avancées dans divers domaines et secteurs d'activité.
Pour en savoir plus sur BentoML et RAG, consultez les ressources suivantes
Comment améliorer la performance de votre pipeline RAG - Zilliz blog
Maîtriser les défis du LLM : une exploration de RAG - Zilliz blog
Ingérer le chaos : The MLOps Behind Handling Unstructured Data Reliably at Scale for RAG (milvus.io)
Pourquoi Milvus rend la construction de RAG plus facile, plus rapide et plus rentable - Zilliz blog
Continuer à lire

Zilliz Cloud On-Demand Compute: Pay Only for What You Use
The customer case behind Zilliz Cloud On-Demand: how a $10K vector search bill came down to under $500, and the engineering changes that made it possible.

AI Agents Are Quietly Transforming E-Commerce — Here’s How
Discover how AI agents transform e-commerce with autonomous decision-making, enhanced product discovery, and vector search capabilities for today's retailers.

DeepSeek Always Busy? Deploy It Locally with Milvus in Just 10 Minutes—No More Waiting!
Learn how to set up DeepSeek-R1 on your local machine using Ollama, AnythingLLM, and Milvus in just 10 minutes. Bypass busy servers and enhance AI responses with custom data.