




Déploiement d'un système RAG multimodal utilisant vLLM et Milvus
Imaginez que vous ayez passé des mois à peaufiner votre application d'IA autour d'un [LLM] (https://zilliz.com/glossary/large-language-models-(llms)) spécifique par l'intermédiaire d'un fournisseur d'API. Puis, tout d'un coup, vous recevez un courriel : "Nous supprimons le modèle que vous utilisez au profit de notre nouvelle version". Cela vous rappelle quelque chose ? Si les fournisseurs d'API en nuage offrent la commodité de capacités d'IA puissantes et prêtes à l'emploi, le fait de s'en remettre uniquement à eux introduit également plusieurs risques importants :
- manque de contrôle : Vous n'avez aucun contrôle sur les versions ou les mises à jour des modèles.
- Imprévisibilité** : Vous pouvez être confronté à des changements soudains dans le comportement ou les capacités du modèle.
- Une visibilité limitée** : La visibilité sur les performances et les modèles d'utilisation est souvent limitée.
- Préoccupations en matière de protection de la vie privée** : La confidentialité des données peut être un problème critique, en particulier lorsqu'il s'agit de traiter des informations sensibles.
Quelle est donc la solution ? Comment reprendre le contrôle ? Comment atténuer ces risques tout en améliorant les capacités de votre système ? La réponse réside dans la construction d'un système plus robuste et indépendant à l'aide de solutions open-source.
Ce blog vous guidera dans la création d'un RAG multimodal avec Milvus et vLLM. En exploitant la puissance d'une [base de données vectorielle] (https://zilliz.com/learn/what-is-vector-database) open-source combinée à l'inférence LLM open-source, vous pouvez concevoir un système capable de traiter et de comprendre [plusieurs types de données] (https://zilliz.com/learn/introduction-to-unstructured-data) - texte, images, audio et même vidéos. Cette approche vous permet non seulement de contrôler entièrement la technologie, mais aussi de disposer d'un système à la fois puissant et polyvalent, surpassant les solutions traditionnelles basées sur le texte.
Ce que nous allons construire : un RAG multimodal entièrement sous votre contrôle
Nous allons construire un système RAG multimodal en utilisant Milvus et vLLM, illustrant comment vous pouvez auto-héberger votre LLM et obtenir un contrôle total sur vos applications d'IA. Notre tutoriel vous guidera dans la création d'une application Streamlit qui démontre la puissance de l'intégration de plusieurs types de données. Voici ce que nous allons couvrir :
Traiter les données vidéo en extrayant les images et en transcrivant l'audio
Stocker et indexer efficacement les données multimodales à l'aide de Milvus
- Nous utilisons [OpenAI CLIP] (https://zilliz.com/learn/exploring-openai-clip-the-future-of-multimodal-ai-learning) pour encoder les images dans des encastrements qui peuvent ensuite être recherchés avec Milvus.
- Nous utilisons le modèle Mistral Embedding pour encoder le texte dans des encastrements.
Récupérer le contexte pertinent en fonction des requêtes de l'utilisateur à l'aide de Milvus.
Générer des réponses à l'aide de Pixtral fonctionnant avec vLLM, en tirant parti de la compréhension visuelle et textuelle.
À la fin de ce tutoriel, vous aurez développé un système flexible et évolutif entièrement sous votre contrôle - vous n'aurez plus à vous soucier des dépréciations d'API ou des changements inattendus.
Qu'est-ce que Milvus ?
Milvus est une base de données vectorielle open-source, hautement performante et hautement évolutive qui peut stocker, indexer et rechercher des données non structurées à l'échelle du milliard par le biais d'embeddings vectoriels à haute dimension. Elle est parfaite pour construire des applications modernes d'IA telles que la génération augmentée de recherche (RAG), la recherche sémantique, la recherche multimodale et les systèmes de recommandation. Milvus fonctionne efficacement dans divers environnements, des ordinateurs portables aux systèmes distribués à grande échelle.
Qu'est-ce que vLLM ?
L'idée centrale de vLLM (Virtual Large Language Model) est d'optimiser le service et l'exécution des LLM en utilisant des techniques efficaces de gestion de la mémoire. En voici les principaux aspects :
- Gestion optimisée de la mémoire: vLLM met en œuvre des techniques avancées d'allocation et de gestion de la mémoire afin d'exploiter pleinement les ressources matérielles disponibles. Cette optimisation permet d'exécuter efficacement des modèles de langage volumineux, en évitant les goulets d'étranglement de la mémoire susceptibles d'entraver les performances.
- Mise en lots dynamique** : vLLM adapte la taille des lots et les séquences en fonction de la mémoire et des capacités de calcul du matériel sous-jacent. Cet ajustement dynamique améliore le débit de traitement et minimise la latence pendant l'inférence du modèle.
- Conception modulaire** : L'architecture de vLLM est modulaire, ce qui facilite l'intégration de divers accélérateurs matériels. Cette modularité permet également une mise à l'échelle aisée sur plusieurs appareils ou clusters, ce qui la rend très adaptable à différents scénarios de déploiement.
- Utilisation efficace des ressources** : vLLM optimise l'utilisation des ressources critiques telles que les CPU, les GPU et la mémoire. Cette efficacité permet au système de prendre en charge des modèles plus importants et de traiter un plus grand nombre de requêtes simultanées, ce qui est essentiel dans les environnements de production où l'évolutivité et les performances sont essentielles.
- Intégration transparente** : Conçu pour s'intégrer en douceur avec les cadres et les bibliothèques d'apprentissage automatique existants, vLLM offre une interface conviviale. Les développeurs peuvent ainsi facilement déployer et gérer de grands modèles de langage dans toute une série d'applications, sans avoir à procéder à une reconfiguration approfondie.
Composants essentiels de notre RAG multimodal
L'application RAG multimodale que nous construisons comprend les éléments clés suivants :
- vLLM est la bibliothèque d'inférence que nous utiliserons pour l'inférence et le service du modèle multimodal Pixtral.
- Koyeb fournit la couche d'infrastructure pour notre déploiement, offrant une plateforme sans serveur spécialisée pour les charges de travail d'IA. Avec l'intégration native de vLLM et la gestion automatisée des ressources GPU, elle facilite le déploiement de LLM tout en maintenant des performances et une évolutivité de niveau production.
- Pixtral de Mistral AI agit comme notre cerveau multimodal, combinant un encodeur de vision de 400M de paramètres avec un décodeur multimodal de 12B de paramètres. Cette architecture lui permet de traiter à la fois des images et du texte dans la même [fenêtre contextuelle] (https://zilliz.com/glossary/context-window).
- Milvus fournit la base de stockage des vecteurs, gérant efficacement les enregistrements de différentes modalités. Sa capacité à gérer plusieurs types de vecteurs et à effectuer une recherche de similarité rapide le rend parfait pour les applications multimodales.
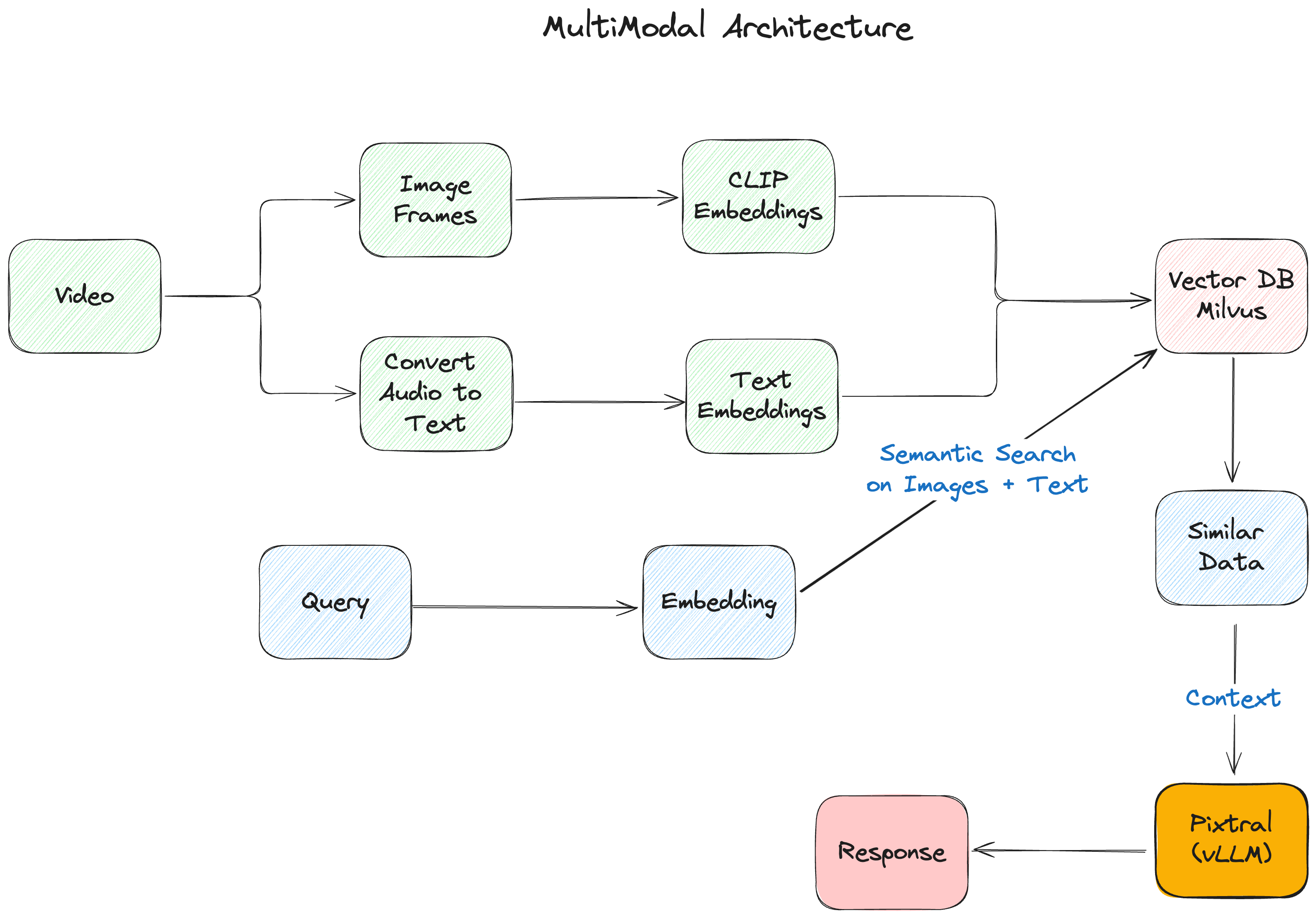 Figure- L'architecture multimodale de RAG.png
Figure- L'architecture multimodale de RAG.png
Figure : L'architecture multimodale de RAG
Pour commencer
Tout d'abord, installons nos dépendances :
# Paquets de base de LlamaIndex
pip install -U llama-index-vector-stores-milvus llama-index-multi-modal-llms-mistralai llama-index-embeddings-mistralai llama-index-multi-modal-llms-openai llama-index-embeddings-clip llama_index
# Traitement vidéo et audio
pip install moviepy pytube pydub SpeechRecognition openai-whisper ffmpeg-python soundfile
# Traitement et visualisation d'images
pip install torch torchvision matplotlib scikit-image git+https://github.com/openai/CLIP.git
# Utilitaires et infrastructure
pip install pymilvus streamlit ftfy regex tqdm
Mise en place de l'environnement
Nous allons commencer par configurer notre environnement et importer les bibliothèques nécessaires :
import os
import base64
import json
from pathlib import Path
from dotenv import load_dotenv
from llama_index.core import Settings
from llama_index.embeddings.mistralai import MistralAIEmbedding
# Chargement des variables d'environnement
load_dotenv()
# Configurer le modèle d'intégration par défaut
Settings.embed_model = MistralAIEmbedding(
"mistral-embed",
api_key=os.getenv("MISTRAL_API_KEY")
)
Pipeline de traitement vidéo
Le cœur de notre système est le pipeline de traitement vidéo, qui transforme le contenu vidéo brut en données que notre système RAG peut comprendre et traiter efficacement.
def process_video(video_path : str, output_folder : str, output_audio_path : str) -> dict :
# Créer le répertoire de sortie s'il n'existe pas
Path(output_folder).mkdir(parents=True, exist_ok=True)
# Extraire les images de la vidéo
video_to_images(video_path, output_folder)
# Extraire et transcrire l'audio
video_to_audio(video_path, output_audio_path)
text_data = audio_to_text(output_audio_path)
# Sauvegarde de la transcription
with open(os.path.join(output_folder, "output_text.txt"), "w") as file :
file.write(text_data)
os.remove(chemin_audio sortie)
return {"Auteur" : "Exemple d'auteur", "Titre" : "Exemple de titre", "Vues" : "1000000"}
Ce pipeline décompose les vidéos en
- Images (extraites à 0,2 FPS)
- Transcription audio à l'aide de Whisper
- Métadonnées sur la vidéo
Construction de l'index vectoriel
Nous utilisons Milvus pour stocker nos embeddings multimodaux. Voici comment nous créons notre index :
def create_index(output_folder : str) :
# Créer des collections différentes pour le texte et les images
text_store = MilvusVectorStore(
uri="milvus_local.db",
collection_name="text_collection",
overwrite=True,
dim=1024
)
image_store = MilvusVectorStore(
uri="milvus_local.db",
collection_name="image_collection",
overwrite=True,
dim=512
)
storage_context = StorageContext.from_defaults(
vector_store=text_store,
image_store=image_store
)
# Chargement et indexation des documents
documents = SimpleDirectoryReader(output_folder).load_data()
return MultiModalVectorStoreIndex.from_documents(
documents,
contexte_de_stockage=contexte_de_stockage
)
Traitement des requêtes avec Pixtral
Lorsqu'un utilisateur pose une question, nous devons.. :
- Récupérer le contexte pertinent dans notre base de données vectorielles
- Traiter la requête avec Pixtral en utilisant à la fois du texte et des images.
Voici notre fonction de traitement des requêtes :
def process_query_with_image(query_str, context_str, metadata_str, image_document) :
client = OpenAI(
base_url=os.getenv("KOYEB_ENDPOINT"),
api_key=os.getenv("KOYEB_TOKEN")
)
with open(image_document.image_path, "rb") as image_file :
image_base64 = base64.b64encode(image_file.read()).decode("utf-8")
qa_tmpl_str = """
Compte tenu des informations fournies, y compris les images pertinentes et le contexte récupéré
de la vidéo, répondez de manière précise et exacte à la requête sans aucune
connaissances préalables supplémentaires.
---------------------
Contexte : {context_str}
Metadata : {metadata_str}
---------------------
Query : {query_str}
Answer : """
# Préparer les messages pour Pixtral
messages = [
{
"role" : "utilisateur",
"content" : [
{
"type" : "texte",
"text" : qa_tmpl_str.format(
context_str=context_str,
query_str=query_str,
metadata_str=metadata_str
)
},
{
"type" : "image_url",
"image_url" : {
"url" : f "data:image/jpeg;base64,{image_base64}"
}
},
],
}
]
completion = client.chat.completions.create(
model="mistralai/Pixtral-12B-2409",
messages=messages,
max_tokens=300
)
return completion.choices[0].message.content
Construction de l'interface Streamlit
Enfin, nous créons une interface conviviale avec Streamlit :
def main() :
st.title("RAG multimodal avec Pixtral et Milvus")
# Initialisation de l'état de la session
if 'index' not in st.session_state :
st.session_state.index = None
st.session_state.retriever_engine = None
st.session_state.metadata = None
# Entrée vidéo
video_path = st.text_input("Enter video path :")
if video_path and not st.session_state.index :
with st.spinner("Processing video...") :
# Traite la vidéo et crée un index
[... code de traitement ...]
if st.session_state.index :
st.subheader("Chat avec la vidéo")
query = st.text_input("Posez une question sur la vidéo :")
if query :
with st.spinner("Generating response...") :
# Génère et affiche la réponse
[... code de traitement de la requête ...]
if __name__ == "__main__" :
main()
Exécution de l'application
Avant de lancer l'application, assurez-vous d'avoir
- Configurer vos variables d'environnement dans
.env - Installé toutes les dépendances nécessaires
Lancez ensuite l'application :
``Bash streamlit run app.py
Vous verrez la page d'accueil où vous pourrez :
- Charger des vidéos pour les traiter
- Poser des questions sur le contenu de la vidéo
- Lire les réponses de Pixtral avec les images vidéo pertinentes
Figure : L'interface de votre application RAG multimodale construite avec Milvus et Pixtral
Désormais, vous pouvez interagir avec la vidéo et, par exemple, en apprendre davantage sur la distribution gaussienne.

Figure : Recherche multimodale
## Conclusion
Dans cet article de blog, nous avons démontré comment construire un puissant système RAG multimodal à l'aide de Milvus, Pixtral et vLLM. En combinant les capacités de stockage vectoriel efficaces de Milvus et la compréhension multimodale avancée de Pixtral, nous avons créé un système capable de traiter, de comprendre et de répondre aux requêtes sur le contenu vidéo. Et ce système est entièrement sous votre contrôle.
## Nous aimerions savoir ce que vous en pensez !
Si vous avez aimé cet article de blog, pensez à.. :
- ⭐ De nous donner une étoile sur [GitHub](https://github.com/milvus-io/milvus)
- 💬 Rejoindre notre [communauté Milvus Discord](https://discord.gg/FG6hMJStWu) pour partager vos expériences
- 🔍 Explorer notre [référentiel Bootcamp](https://github.com/milvus-io/bootcamp) pour plus d'exemples d'applications multimodales avec Milvus

Continuer à lire

From Vector Database to Vector Lakebase
Zilliz offers a fully managed Vector Lakebase powered by Milvus, unifying real-time vector search, lake-scale discovery, and Al data operations.

Milvus 2.6.x Now Generally Available on Zilliz Cloud, Making Vector Search Faster, Smarter, and More Cost-Efficient for Production AI
Milvus 2.6.x is now GA on Zilliz Cloud, delivering faster vector search, smarter hybrid queries, and lower costs for production RAG and AI applications.

Our Journey to 35K+ GitHub Stars: The Real Story of Building Milvus from Scratch
Join us in celebrating Milvus, the vector database that hit 35.5K stars on GitHub. Discover our story and how we’re making AI solutions easier for developers.