




WhyHow
Build more controlled retrieval workflows within your RAG pipeline with WhyHow and Milvus or Zilliz Cloud
Utilice esta integración de forma gratuita¿Qué es WhyHow?
WhyHow es una plataforma que proporciona a los desarrolladores los bloques de construcción para organizar, contextualizar y recuperar de forma fiable datos no estructurados para llevar a cabo la compleja Retrieval Augmented Generation (RAG). El Rule-based Retrieval Package es un paquete Python desarrollado por WhyHow que ayuda a los desarrolladores a construir flujos de trabajo de recuperación más precisos dentro de RAG añadiendo capacidades de filtrado avanzadas. Este paquete se integra con OpenAI para la generación de texto y con Milvus y Zilliz Cloud (Milvus totalmente gestionado) para el almacenamiento eficiente de vectores y la búsqueda de similitudes.
¿Por qué integrar WhyHow y Milvus/Zilliz?
La Generación Aumentada de Recuperación (RAG) es una tecnología avanzada que mejora los grandes modelos lingüísticos (LLMs) proporcionando información contextual de la consulta para obtener respuestas más precisas. Sin embargo, en ocasiones, un proceso RAG simple puede no recuperar de forma coherente los fragmentos de datos correctos. Este problema puede deberse a la naturaleza de "caja negra" de la recuperación y la generación de respuestas LLM, a consultas de usuario mal formuladas que arrojan resultados subóptimos a partir de una base de datos vectorial, o a la necesidad de incluir datos contextualmente relevantes pero semánticamente disímiles en las respuestas.
Para superar estos retos, necesitamos tener un mayor control sobre la recuperación de trozos de datos sin procesar. Al integrar WhyHow y Milvus/Zilliz, podemos construir una solución de recuperación basada en reglas. Este enfoque permite definir y asignar reglas específicas a trozos de datos relevantes antes de realizar una búsqueda por similitud, lo que mejora el control sobre el flujo de trabajo de recuperación. La aplicación de estas reglas reduce el alcance de las consultas a un conjunto más específico de fragmentos, lo que aumenta las posibilidades de recuperar datos relevantes para generar respuestas precisas. La calidad de los resultados puede mejorarse continuamente con nuevos ajustes de las consultas.
Funcionamiento de la integración WhyHow y Milvus/Zilliz
La solución de recuperación basada en reglas creada con WhyHow y Milvus/Zilliz realiza las siguientes tareas:
Creación del almacén de vectores: Esta integración crea una colección Milvus para almacenar las incrustaciones de trozos.
División, fragmentación e incrustación**: Cuando carga sus documentos, la integración divide, fragmenta y crea automáticamente incrustaciones de los documentos antes de ingestarlos en Milvus o Zilliz Cloud. Este paquete de recuperación basado en reglas es compatible actualmente con PyPDFLoader y RecursiveCharacterTextSplitter de LangChain para el procesamiento de PDF, la extracción de metadatos y la fragmentación. Para la incrustación, es compatible con OpenAI text-embedding-3-small model.
Inserción de datos:** Sube las incrustaciones y los metadatos a Milvus o Zilliz Cloud.
Auto-filtrado: Usando reglas definidas por el usuario, la integración construye automáticamente un filtro de metadatos para restringir la consulta contra el almacén de vectores.
El flujo de trabajo de esta integración es el siguiente:
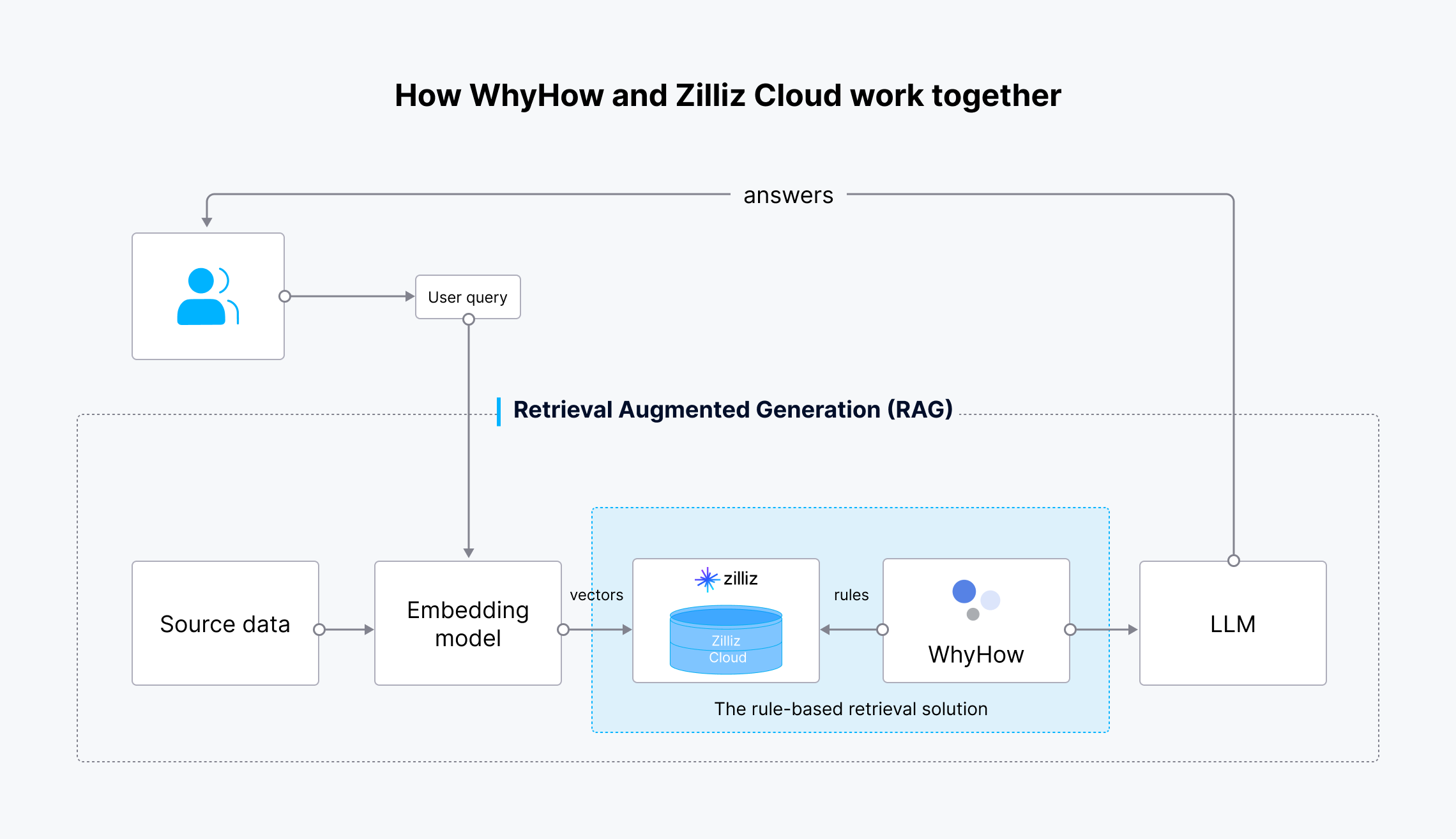 Cómo funcionan juntos WhyHow y Zilliz Cloud.png
Cómo funcionan juntos WhyHow y Zilliz Cloud.png
- Los datos de origen se transforman en incrustaciones vectoriales utilizando el modelo de incrustación de OpenAI.
- Las incrustaciones vectoriales se introducen en Milvus o Zilliz Cloud para su almacenamiento y recuperación.
- La consulta del usuario también se transforma en incrustaciones vectoriales y se envía a Milvus o Zilliz Cloud para buscar los resultados más relevantes.
- WhyHow establece reglas y añade filtros a la búsqueda vectorial.
- Los resultados recuperados y la consulta original del usuario se envían al LLM.
- El LLM genera resultados más precisos y los envía al usuario.
Cómo utilizar WhyHow y Milvus/Zilliz Cloud