




Desnormalización de bases de datos: una guía completa

Desnormalización de bases de datos: una guía completa
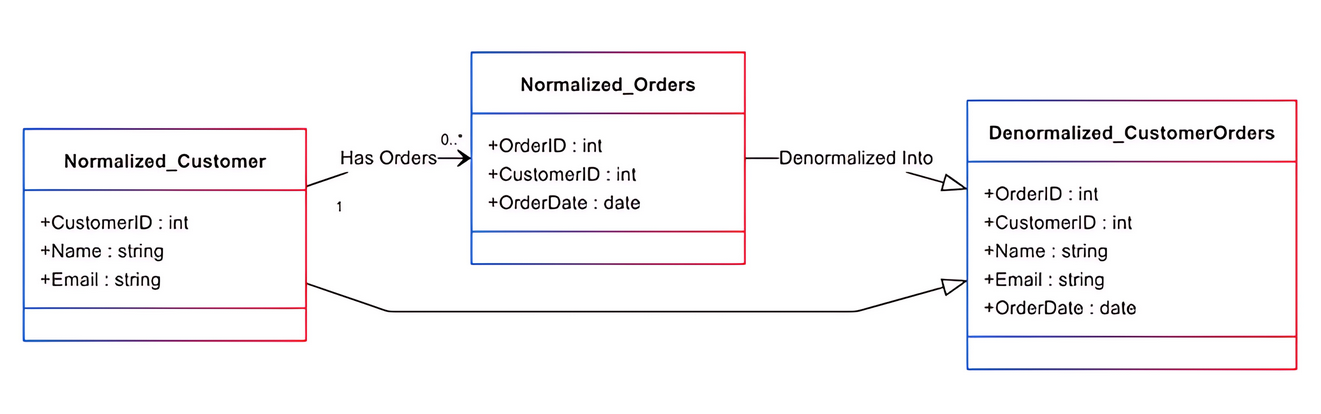
Figura 1: Ilustración de la desnormalización de bases de datos
¿Por qué algunas bases de datos procesan consultas más rápido que otras, incluso cuando manejan grandes cantidades de información? La respuesta radica en la indexación, la optimización de consultas y la arquitectura de almacenamiento de la base de datos. La recuperación rápida de datos es crucial, ya que mejora el rendimiento, la experiencia del usuario y la eficacia general.
La normalización tradicional de bases de datos mantiene la integridad de los datos organizándolos en tablas con relaciones bien definidas. Aunque la normalización mejora la precisión de los datos, tiende a provocar un cuello de botella en el rendimiento en sistemas que utilizan muchas uniones. Con tantas tablas y uniones, resulta más difícil recuperar los datos, lo que ralentiza la capacidad de respuesta de la aplicación.
Una técnica utilizada para optimizar el rendimiento de las bases de datos es la desnormalización. La desnormalización introduce datos redundantes en la base de datos para optimizar las cargas con muchas lecturas. Esto reduce la necesidad de uniones complejas, mejorando así el rendimiento de las consultas.
Esta guía explicará el concepto de desnormalización de bases de datos, lo comparará con la normalización y analizará sus beneficios. También descubriremos los casos de uso en los que la desnormalización de bases de datos resulta beneficiosa y los desafíos que las empresas podrían enfrentar al implementarla.
¿Qué es la desnormalización de bases de datos?
La desnormalización de bases de datos es una técnica de optimización que agrega datos duplicados a un esquema previamente normalizado. Esta técnica mejora el rendimiento de lectura al simplificar las consultas y reducir el número de uniones.
Las bases de datos normalizadas sufren por múltiples uniones para obtener datos entre varias tablas, lo que las vuelve lentas cuando trabajan con grandes conjuntos de datos. La técnica de desnormalización es útil en sistemas que realizan operaciones de lectura en lugar de operaciones de escritura.
Por ejemplo, supongamos que una base de datos normalizada contiene tres tablas separadas: clientes, pedidos y productos. Recuperar el historial de pedidos de un cliente con detalles de productos requiere que la base de datos una varias tablas, combinando datos de clientes, pedidos y productos. Un esquema desnormalizado combina datos relacionados, como los detalles de productos, en una sola tabla para minimizar las uniones y mejorar el rendimiento de lectura.
Sin embargo, el aumento de rendimiento para las operaciones de lectura tiene un costo para las operaciones de escritura. Las actualizaciones de datos consistentes se vuelven más complejas porque la base de datos necesita mantener información redundante.
Cómo funciona
El proceso de desnormalización transforma las bases de datos normalizadas mediante la reestructuración para mejorar la velocidad y el rendimiento de las consultas y la recuperación de datos. Mientras que el proceso de normalización elimina duplicados manteniendo la consistencia de los datos, la desnormalización agrega datos duplicados específicamente para impulsar las operaciones de lectura en las aplicaciones.
Las bases de datos que necesitan informes en tiempo real, consultas de alta velocidad y análisis adoptan ampliamente esta técnica. A continuación, analizaremos los enfoques de desnormalización y su impacto en la eficacia de las bases de datos.
 Enfoques de desnormalización de bases de datos
Enfoques de desnormalización de bases de datos
Figura 2: Enfoques de desnormalización de bases de datos
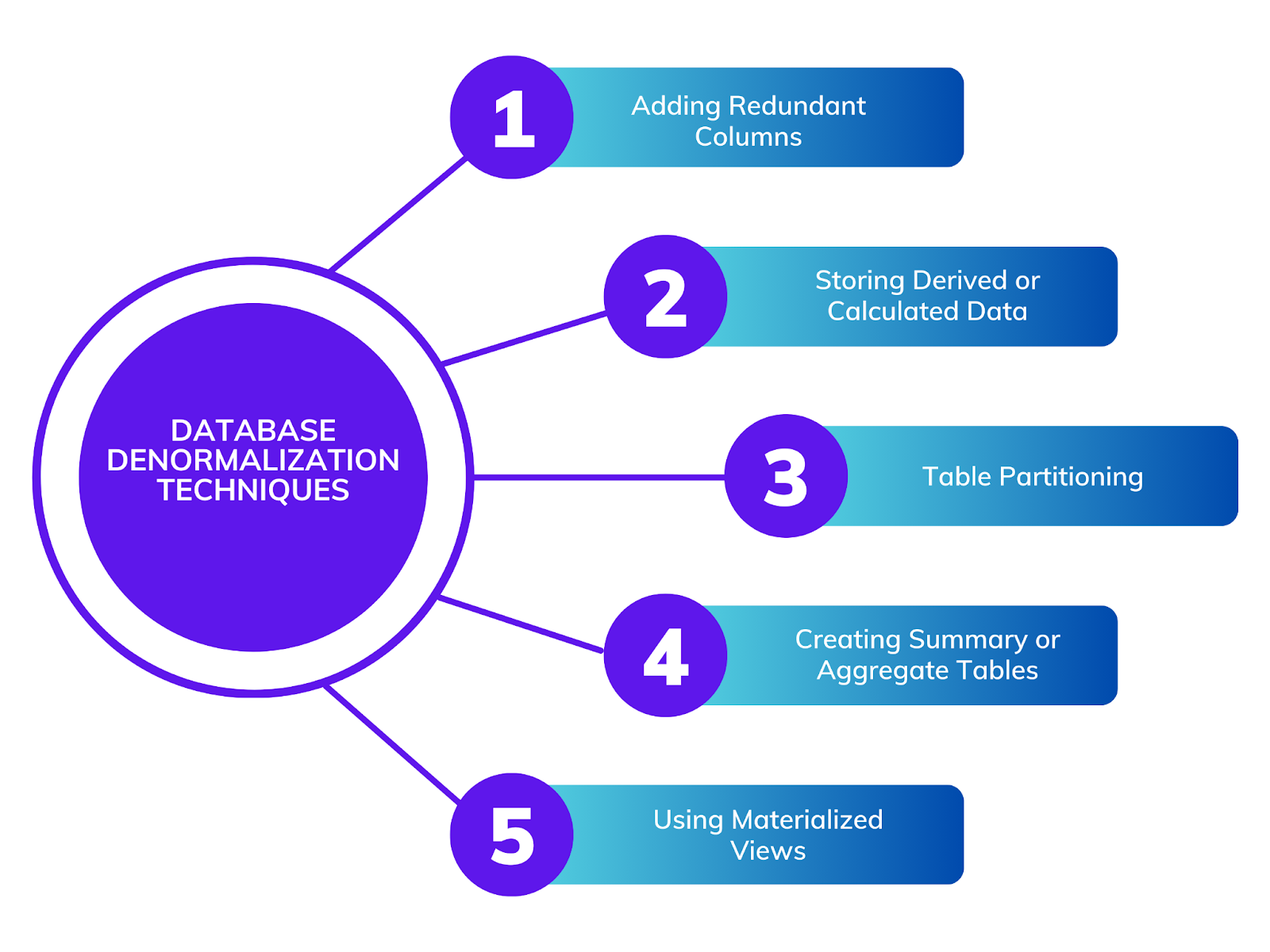
Agregar columnas redundantes
Agregar columnas redundantes es un método simple y estándar de desnormalización. Esto implica agregar datos en múltiples ubicaciones para reducir las operaciones de unión. Por ejemplo, la tabla de pedidos de una base de datos tiene una clave externa llamada ID que la conecta con la tabla de clientes. La tabla de clientes contiene detalles esenciales sobre cada cliente, como su nombre, ID e información de contacto.
Cuando se analizan los detalles de los pedidos de los clientes, se necesita una operación de unión para extraer los datos del cliente. Unir tablas puede ser particularmente costoso y ralentizar el rendimiento general. Si la información del cliente se almacena en la tabla de pedidos, se elimina la necesidad de una unión y se consigue una recuperación de datos eficiente.
Aunque este método mejora considerablemente la velocidad de las consultas, aumenta los costes de redundancia de datos. Cuando los datos del cliente cambian, todas las copias redundantes deben actualizarse para mantener la consistencia. Esto exige optimizar el rendimiento y gestionar la integridad de los datos mediante actualizaciones o triggers. Equilibrar este problema puede llevarse a cabo mediante procesos de actualización bien definidos.
Almacenar datos derivados o calculados
Otro método de desnormalización es almacenar y precalcular cálculos frecuentes. En un sistema de base de datos normalizado, los cálculos se realizan dinámicamente en el momento de la consulta. Si bien esto garantiza que los valores estén actualizados, también afecta negativamente la carga de cómputo.
El rendimiento del sistema se resiente al tratar con grandes conjuntos de datos o numerosas solicitudes de consulta. Sin embargo, el rendimiento puede mejorarse añadiendo estos valores como columnas adicionales dentro de las filas de las tablas existentes.
Por ejemplo, la base de datos puede almacenar previamente los importes totales de los pedidos en la tabla de pedidos, de modo que los usuarios no necesiten recalcular esta información al solicitar su historial de pedidos. El sistema de base de datos puede entregar el valor sin procesamiento adicional porque estos valores ya están almacenados.
Esta técnica es beneficiosa en el sector financiero, el comercio electrónico y los sistemas de BI, que tienen un alto volumen de datos que requiere cálculos agregados y complejos. Sin embargo, mantener la integridad de los valores precalculados es vital. Esto, posteriormente, requiere actualizaciones periódicas o activaciones de triggers basadas en cambios en los datos.
Particionamiento de tablas
El particionamiento de tablas es un enfoque clave de desnormalización que divide tablas grandes en particiones para mejorar el procesamiento de consultas y la velocidad de recuperación de datos. Proporciona resultados excepcionales al procesar bases de datos extensas que contienen registros de transacciones, registros de auditoría y conjuntos de datos históricos. Además, se divide en dos partes:
Particionamiento horizontal: La técnica de particionamiento divide una tabla en particiones más pequeñas según criterios como parámetros de fecha, áreas geográficas y divisiones de usuarios. Por ejemplo, un minorista en línea con millones de transacciones de ventas puede dividir su tabla de pedidos según particiones anuales. El rendimiento mejora cuando las consultas necesitan transacciones recientes porque requieren escanear un subconjunto de datos reducido en lugar de la tabla completa.
Particionamiento vertical: El particionamiento vertical funciona de manera diferente al particionamiento horizontal porque separa las tablas en secciones distintas basadas en columnas. Divide las tablas en dos partes colocando las columnas a las que se accede con frecuencia junto a las de acceso menos frecuente, de modo que las consultas solo necesiten recuperar los datos necesarios. El enfoque resulta beneficioso para tablas anchas que contienen numerosos atributos porque permite que las consultas accedan solo a los campos esenciales.
Ambos métodos de particionamiento mejoran la optimización del almacenamiento y reducen el tiempo de ejecución de las consultas, añadiendo un valor significativo a las bases de datos de alto rendimiento. Sin embargo, los métodos aumentan la complejidad de la indexación y el particionamiento y pueden dar lugar a ineficiencias en las consultas si no se aplican estrategias adecuadas.
Crear tablas de resumen o agregadas
Las aplicaciones de generación de informes y procesamiento de análisis de datos a menudo extraen estadísticas resumidas en tiempo real a partir de datos de entrada sin procesar. Esto normalmente requiere una potencia de procesamiento significativa. Por lo tanto, un enfoque consiste en agregar tablas. En lugar de recalcular, una tabla de resumen puede utilizarse como punto de almacenamiento, permitiendo el acceso instantáneo a datos preagregados.
Consideremos una empresa minorista que analiza el rendimiento de ventas en múltiples regiones. Crear una tabla de resumen con las ventas totales agregadas por mes para cada región facilitaría la comprensión de información de alto nivel.
Esta tabla podría actualizarse en tiempo real, mediante triggers, o con actualizaciones por lotes programadas. La tabla de resumen ofrece una ejecución de consultas más rápida porque contiene menos filas que la tabla de transacciones original, lo que mejora la capacidad de respuesta de dashboards e informes.
Si bien este método mejora la información de alto nivel, también requiere un mecanismo sólido de actualización de datos. El procesamiento por lotes o las pipelines ETL pueden garantizar la conservación de datos de resumen actualizados.
Uso de vistas materializadas
Las vistas materializadas son una función avanzada de optimización que crea objetos físicos de base de datos que contienen resultados de ejecución de consultas. Las vistas estándar requieren la ejecución dinámica de consultas con cada acceso. Sin embargo, las vistas materializadas almacenan sus datos en disco para que los usuarios puedan recuperar información al instante sin procesamiento adicional.
Tomemos el ejemplo de un sitio web de comercio electrónico que supervisa las compras de los clientes. Los propietarios del sitio pueden crear una vista materializada que haga un seguimiento del gasto total por cliente dentro de varias categorías de productos. La base de datos recupera resultados precalculados en lugar de realizar cálculos en tiempo real porque este enfoque ofrece respuestas de consulta más rápidas.
Las vistas materializadas pueden actualizarse periódicamente o actualizarse de forma incremental según los requisitos del sistema. La técnica ofrece beneficios excepcionales a las bases de datos que requieren joins, agregaciones y transformaciones de varios pasos.
Comparación: desnormalización vs. normalización
La elección entre normalización y desnormalización para el diseño de bases de datos depende de la velocidad de rendimiento, la eficiencia de almacenamiento y los requisitos de consistencia de datos. Esta tabla muestra las diferencias entre desnormalización y normalización.
| Aspecto | Normalización | Desnormalización |
| Propósito | Reducir la redundancia | Mejorar el rendimiento de lectura |
| Estructura de datos | Múltiples tablas relacionadas | Menos tablas, datos redundantes |
| Complejidad de consulta | Joins complejos | Consultas simplificadas |
| Ideal para | Aplicaciones con muchas escrituras | Aplicaciones con muchas lecturas |
| Integridad de datos | Alta | Potencialmente comprometida |
| Uso de almacenamiento | Eficiente | Aumentado |
| Mantenimiento | Simplificado | Más complejo |
| Anomalías de actualización | Minimizadas | Mayor riesgo |
El proceso de selección de una base de datos exige analizar los patrones de recuperación de datos, los requisitos de velocidad de actualización y las especificaciones de rendimiento del sistema. Una base de datos adecuadamente equilibrada mantiene la eficiencia operativa y la escalabilidad.
Beneficios y desafíos
La desnormalización es un método de optimización que añade datos redundantes para impulsar las operaciones de lectura y la velocidad de ejecución de consultas. Sin embargo, las mejoras de rendimiento pueden crear problemas con el almacenamiento y anomalías. Los beneficios de la desnormalización requieren una implementación equilibrada que evite que surjan riesgos potenciales. Estos son algunos de los beneficios y desafíos:
Beneficios de la desnormalización
Complejidad reducida de la aplicación: La desnormalización simplifica la lógica de la aplicación al eliminar la necesidad de joins complejos y consultas de múltiples tablas. Esto mejora la legibilidad y simplicidad de las consultas, lo que conduce a una mayor productividad de los desarrolladores.
Rendimiento mejorado en sistemas distribuidos: Recuperar datos de varios nodos en bases de datos distribuidas provoca un rendimiento retardado. La desnormalización coloca datos duplicados cerca de sus principales puntos de acceso. Esto reduce la necesidad de recuperación de datos de nodo a nodo. La técnica resulta valiosa para sistemas basados en la nube, así como para arquitecturas escaladas horizontalmente.
Mayor eficiencia en el almacenamiento de datos: Los almacenes de datos requieren un manejo eficiente de tareas analíticas que ejecutan cálculos complejos y procedimientos de agregación. La desnormalización beneficia el rendimiento de lectura al almacenar datos previamente unidos o previamente agregados, eliminando la necesidad de transformaciones de datos en tiempo real.
Facilita el análisis en tiempo real: Las aplicaciones que realizan análisis necesitan acceso inmediato a los datos para obtener información rápidamente. La desnormalización reduce el requisito de cálculos complejos en tiempo real al almacenar valores precalculados con datos redundantes.
Informes optimizados: Las bases de datos desnormalizadas mantienen datos preprocesados para la creación instantánea de informes y minimizan la necesidad de operaciones de transformación de datos. Este enfoque beneficia sustancialmente a las aplicaciones de inteligencia empresarial y los paneles ejecutivos.
Desafíos
Anomalías de datos: La duplicación de datos crea un mayor riesgo de inconsistencia de datos porque las actualizaciones podrían no propagarse correctamente entre todas las instancias del sistema. La validación de datos y las comprobaciones de consistencia son importantes en los sistemas desnormalizados para reducir el riesgo de anomalías.
Mayores costos de almacenamiento: Los datos redundantes requieren espacio de almacenamiento adicional, lo que aumenta el tamaño total de la base de datos. Las bases de datos basadas en la nube que usan modelos de precios basados en el uso podrían experimentar costos más altos debido a los requisitos de almacenamiento.
Complejidad en la sincronización de datos: La sincronización de datos requiere que cada operación de actualización modifique todas las copias de datos simultáneamente, lo que genera limitaciones de rendimiento. Una mala ejecución de la sincronización de datos produce registros que contienen imprecisiones o información obsoleta.
Posibilidad de problemas de integridad de datos: La ejecución incorrecta de actualizaciones en varias instancias produce datos inconsistentes. Esto degrada la calidad operativa y la precisión de los informes. Los sistemas de alta transacción requieren recursos adicionales y sistemas de validación estrictos para mantener la integridad de los datos.
Flexibilidad reducida: Los entornos con múltiples tablas hacen que las modificaciones del esquema sean más difíciles. Esto conduce a ciclos de desarrollo más lentos y dificulta que las organizaciones se adapten a nuevos requisitos empresariales.
Se necesita una gestión adecuada para implementar la desnormalización con el fin de prevenir anomalías de datos, problemas de integridad y gastos de almacenamiento. Las organizaciones deben implementar la desnormalización en función de los requisitos de rendimiento identificados que coincidan con las necesidades de su sistema.
Casos de uso
Los beneficios de la desnormalización se hacen evidentes en casos de uso particulares, pero las organizaciones deben comprender sus implicaciones en diferentes situaciones. Estos son algunos de los principales casos de uso:
Almacenamiento de datos y sistemas OLAP: Los sistemas de almacenamiento de datos y OLAP utilizan métodos de desnormalización para hacer que las consultas y agregaciones complejas sean más eficientes. El uso de esquemas desnormalizados resulta en una recuperación de datos más rápida porque elimina el requisito de múltiples uniones de tablas. Esto es esencial para aplicaciones de inteligencia empresarial y cargas de trabajo analíticas.
Aplicaciones de baja latencia: La desnormalización beneficia a las aplicaciones de baja latencia al acortar el tiempo necesario para recuperar y procesar datos en entornos críticos como las plataformas de negociación financiera.
Aplicaciones con muchas lecturas: Las aplicaciones que realizan más operaciones de lectura que de escritura pueden lograr un mejor rendimiento mediante el uso de la desnormalización. Sistemas como herramientas de gestión de contenido y generación de informes pueden lograr un mejor rendimiento de las solicitudes de lectura al añadir datos duplicados.
Análisis en tiempo real: Las aplicaciones que necesitan información instantánea pueden beneficiarse de la desnormalización al acceder a datos preagregados. Esto reduce el tiempo de procesamiento de las consultas, lo que permite tomar decisiones rápidas usando información actualizada.
Preguntas frecuentes
¿La desnormalización de bases de datos siempre es mejor para el rendimiento?
La desnormalización en sistemas con muchas escrituras crea problemas de inconsistencia de datos porque mantener datos redundantes presenta desafíos significativos. Debes evaluar los patrones de lectura y escritura de tu aplicación antes de decidir sobre la desnormalización de la base de datos.
¿La desnormalización reemplaza a la normalización?
La desnormalización funciona como un paso adicional después de la normalización para mejorar los problemas de rendimiento. El proceso de normalización estructura los datos para eliminar la duplicación y mantener la integridad de los datos, pero la desnormalización reintroduce duplicados de datos para mejorar la velocidad de lectura.
¿Cuáles son los riesgos de la desnormalización?
Implementar la desnormalización crea tres riesgos principales: redundancia de datos, mayores requisitos de almacenamiento e inconsistencias. El aumento de la redundancia de datos crea posibles anomalías cuando se gestiona incorrectamente, mientras que el tamaño ampliado de los datos requiere mayores gastos de almacenamiento.
¿Puedo desnormalizar solo parte de mi base de datos?
Sí, la desnormalización de bases de datos funciona dirigiéndose a secciones específicas de la base de datos para optimizar el rendimiento. La implementación dirigida permite una mejor eficiencia de lectura en áreas específicas sin afectar la manejabilidad ni la integridad de la base de datos.
¿Cómo mantengo la consistencia de los datos en una base de datos desnormalizada?
Una base de datos desnormalizada requiere disparadores de base de datos, restricciones y lógica de aplicación para mantener los datos redundantes consistentes durante las actualizaciones. Implementar estos mecanismos mantiene la sincronización de datos en todas las copias de datos.
Recursos relacionados
- ¿Qué es la desnormalización de bases de datos?
- Cómo funciona
- Comparación: desnormalización vs. normalización
- Beneficios y desafíos
- Casos de uso
- Preguntas frecuentes
- Recursos relacionados
Contenido
Comienza Gratis, Escala Fácilmente
Prueba la base de datos vectorial completamente gestionada construida para tus aplicaciones GenAI.
Prueba Zilliz Cloud Gratis