




Cómo Tokopedia logró una experiencia de búsqueda 10 veces más inteligente utilizando Milvus
10 veces más inteligente
experiencia de búsqueda
Mejorado
experiencia del usuario
Mejorado
escalabilidad y fiabilidad
Our search system has been much more intelligent, stable, and reliable using Milvus.
Rahul Yadav
Acerca de Tokopedia
Tokopedia es la mayor plataforma de comercio electrónico de Indonesia, con 90 millones de usuarios activos mensuales y una impresionante red de 8,6 millones de comerciantes. Con un alcance que se extiende al 98% de las regiones administrativas de Indonesia, Tokopedia se ha convertido en el destino preferido del país para las compras en línea.
Tokopedia reconoce que el valor de su amplio catálogo de productos reside en garantizar que los compradores puedan descubrir sin esfuerzo productos adaptados a sus preferencias. En su inquebrantable compromiso por mejorar la relevancia de los resultados de búsqueda, han introducido una búsqueda por similitud en Tokopedia.
Cuando el usuario navega a la página de resultados de búsqueda en su dispositivo móvil, observará un discreto botón "...". Al hacer clic en este botón, el usuario puede acceder a un menú que le ofrece la interesante oportunidad de explorar productos que se asemejan mucho al que está viendo.
Desafíos de la búsqueda basada en palabras clave
En el pasado, Tokopedia Search utilizaba Elasticsearch como motor principal para la búsqueda y clasificación de productos. Cada solicitud de búsqueda iniciaba una consulta a Elasticsearch, que clasificaba los productos en función de la palabra clave buscada por el usuario. Elasticsearch almacena las palabras clave como secuencias de valores numéricos, que representan códigos ASCII o UTF para letras individuales. Construye un índice invertido para la rápida identificación de los documentos que contienen palabras de la consulta del usuario y, posteriormente, determina las mejores coincidencias utilizando una serie de algoritmos de puntuación.
Sin embargo, estos algoritmos de puntuación no suelen tener en cuenta la semántica de las palabras clave buscadas. En su lugar, se centran en factores como la frecuencia con la que las palabras aparecen en los documentos, la proximidad entre ellas y otra información estadística. Aunque los humanos pueden entender el significado que se esconde tras la representación ASCII de las palabras, los ordenadores necesitan un algoritmo fiable para comparar la semántica de las palabras codificadas en ASCII.
Representación vectorial
Una de las soluciones al problema que encontró el equipo de Tokopedia fue crear una nueva forma de representar las palabras clave, que muestra las letras de una palabra y da información sobre su significado. Por ejemplo, podrían codificar las palabras más utilizadas con la palabra clave de búsqueda para proporcionar un contexto probable. A partir de ahí, pueden suponer que contextos similares indican conceptos parecidos y compararlos mediante técnicas matemáticas. Incluso es posible codificar frases enteras en función de su significado.
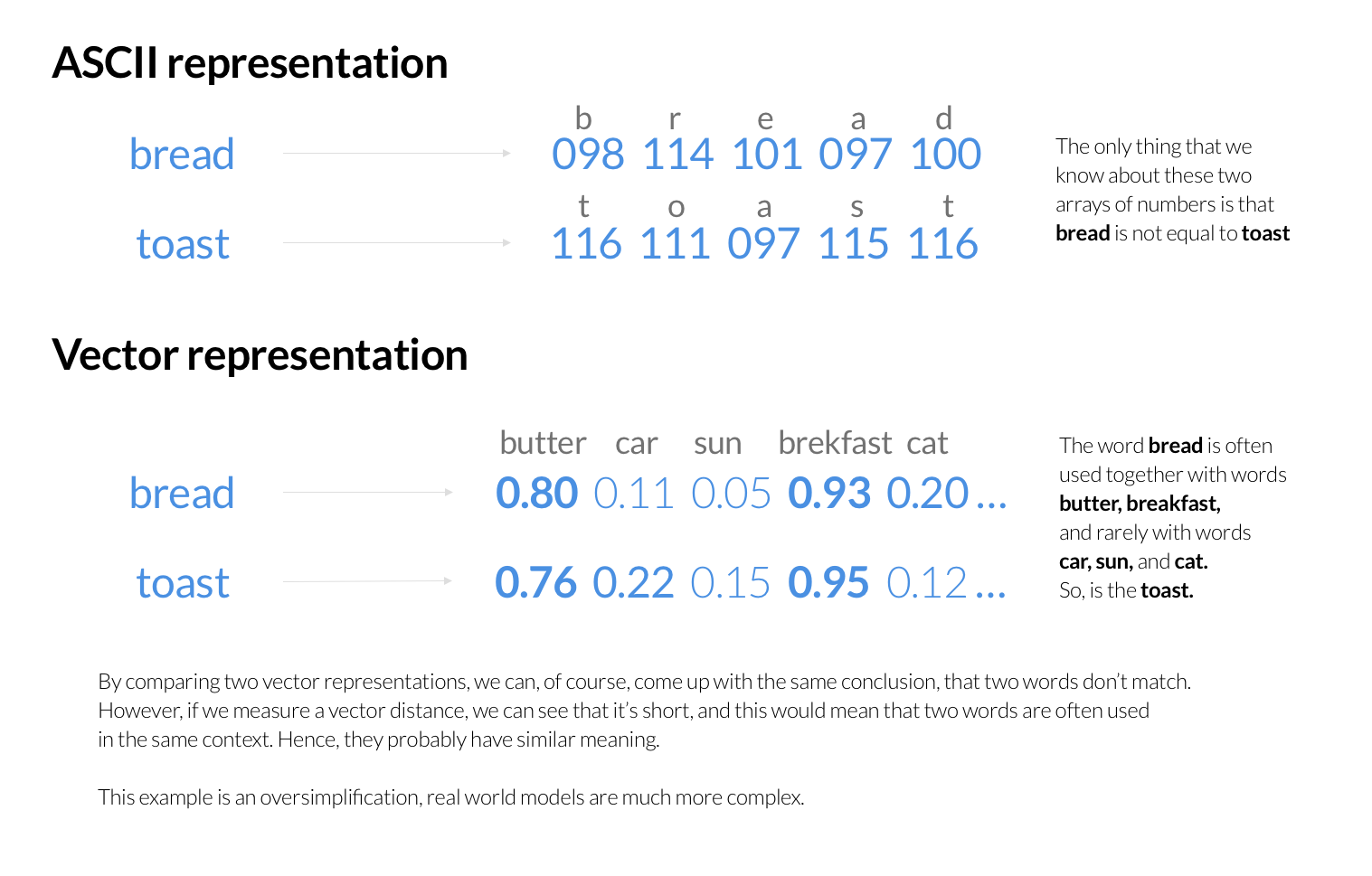
Selección de Milvus como motor de búsqueda de similitud vectorial
Ahora que Tokopedia posee vectores de características, el reto restante consiste en recuperar de forma eficiente vectores del extenso conjunto de datos que coincidan estrechamente con el vector objetivo. Para explorar los motores de búsqueda de vectores, realizamos evaluaciones de prueba de concepto (POC) en varias pilas de búsqueda de vectores disponibles en GitHub, incluidas FAISS, Vearch y Milvus.
Nuestra preferencia se inclina hacia Milvus basándonos en los resultados de nuestras pruebas de carga. En comparación con Milvus, FAISS funciona más como una biblioteca subyacente y, en consecuencia, es menos fácil de usar. Al profundizar en Milvus, lo adoptamos por las siguientes razones:
- Milvus demostró ser notablemente fácil de usar. Descubrieron que sólo es necesario extraer su imagen Docker y ajustar los parámetros para que se adapten a sus casos de uso específicos.
- Milvus ofrece una gama más amplia de índices compatibles. Además de FAISS, HSNW, DISK_ANN y ScaNN, hay 11 índices entre los que elegir.
- Milvus proporciona documentación completa para ayudar a los usuarios en su implementación.
En pocas palabras, Milvus es fácil de usar, con una documentación clara y un soporte fiable de la comunidad para cualquier problema que pueda surgir.
Milvus en producción
Después de implementar Milvus como su motor de búsqueda de vectores de características, lo utilizaron para su servicio de anuncios para emparejar palabras clave de bajo índice de relleno con palabras clave de alto índice de relleno. Configuraron y ejecutaron un nodo independiente en un entorno de desarrollo (DEV), que funcionó sin problemas y proporcionó una impresionante tasa de clics (CTR) y una tasa de conversión (CVR) 10 veces superiores.
Sin embargo, surgió un problema potencial. Si un nodo independiente se bloqueaba, todo el servicio quedaría inaccesible. Por lo tanto, el equipo de Tokopedia cambió a una implementación HA de Milvus.
Milvus ofrece dos herramientas: Mishards, un middleware de fragmentación de clústeres, y Milvus-Helm para una configuración simplificada. En Tokopedia, utilizan los playbooks de Ansible para la configuración de la infraestructura, lo que les lleva a crear un playbook para orquestar la infraestructura. El siguiente diagrama muestra cómo funciona Mishards.
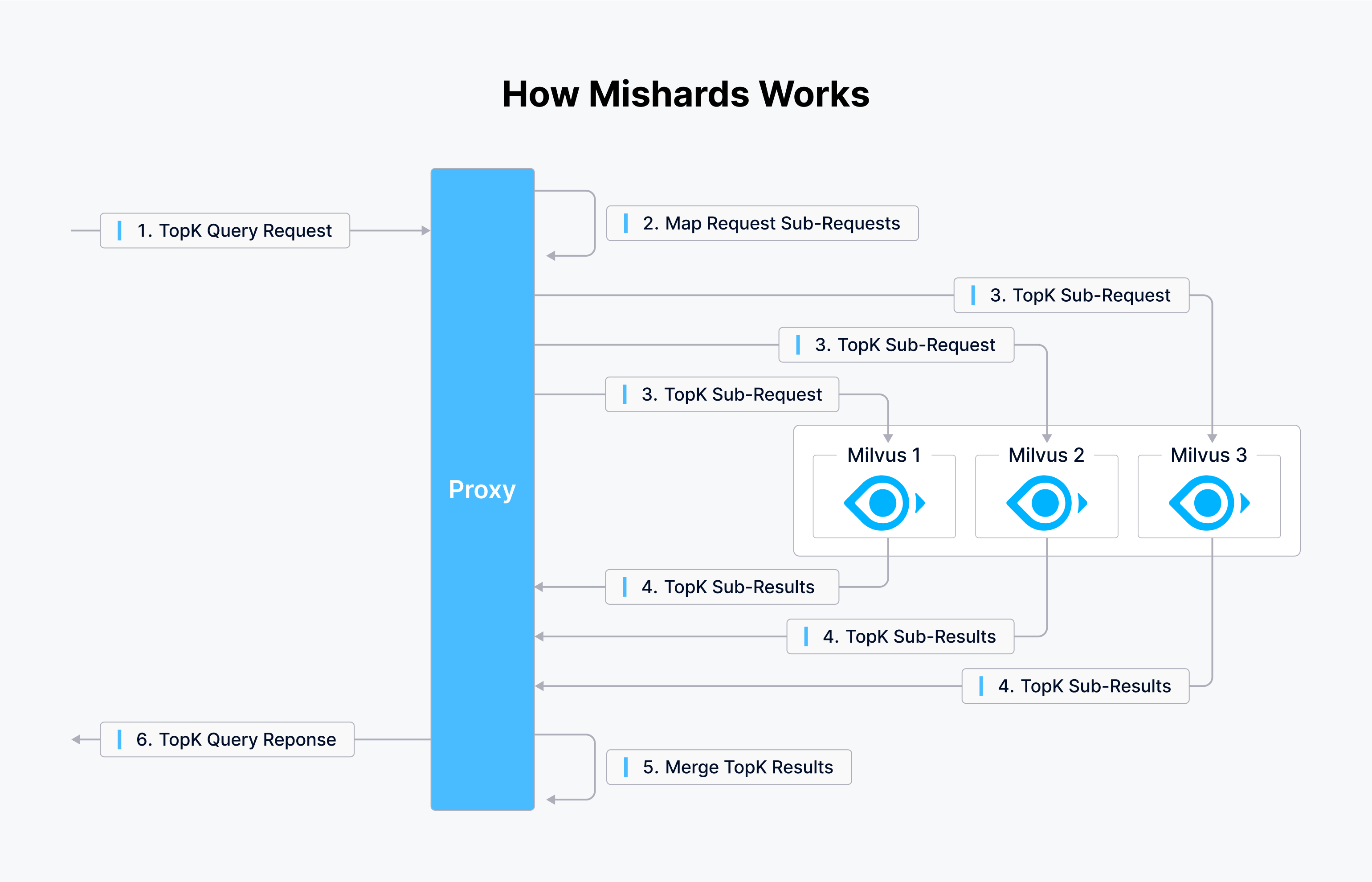
Mishards facilita el flujo continuo de solicitudes desde el origen hasta el destino, dividiendo las solicitudes del origen en submódulos, recopilando resultados de los subservicios y devolviendo posteriormente estos resultados a la fuente del origen.
A continuación se muestra la arquitectura de la solución de clúster basada en Mishards.
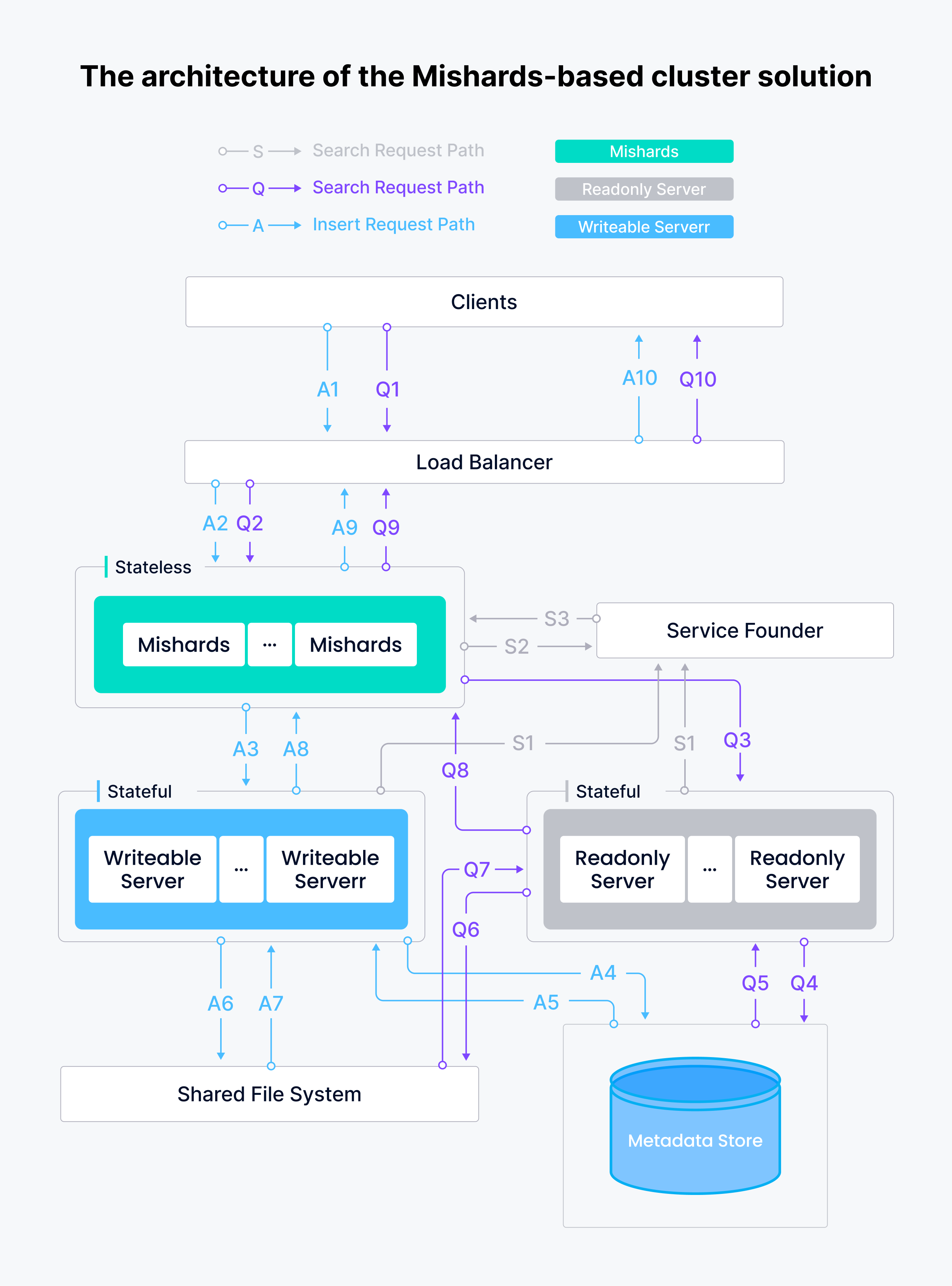
El sistema de servicio de búsqueda semántica Tokopedia incluye un nodo de escritura, dos nodos de sólo lectura y una instancia de middleware Mishards, todo ello desplegado en GCP utilizando Milvus Ansible. El sistema ha sido considerablemente más inteligente, estable y fiable.
¿Cómo acelera la indexación vectorial la búsqueda de similitudes?
La consulta eficiente de grandes conjuntos de datos vectoriales en motores de búsqueda de similitud requiere una indexación adecuada. Este proceso organiza los datos y acelera el proceso de búsqueda, por lo que resulta esencial para manejar conjuntos de datos con millones, miles de millones o incluso billones de vectores. Una vez indexado un conjunto de datos vectoriales masivo, se pueden dirigir las consultas a los clusters o subconjuntos de datos con más probabilidades de contener vectores similares a la consulta de entrada. Sin embargo, este enfoque puede sacrificar la precisión para conseguir consultas más rápidas en grandes datos vectoriales.
Para entenderlo mejor, piense en la indexación como una ordenación alfabética de palabras en un diccionario. Al buscar una palabra clave, se puede navegar rápidamente a una sección que contenga sólo palabras con la misma letra inicial, lo que acelera drásticamente la búsqueda de la definición de la palabra de entrada.
Resumen
La búsqueda de Tokopedia de una funcionalidad de búsqueda superior les llevó a Milvus, un cambio de juego en la búsqueda semántica. Con Milvus, desbloquearon el poder de la representación vectorial y construyeron un sistema de búsqueda 10 veces más inteligente que ha mejorado drásticamente la experiencia del usuario. Además, su servicio de búsqueda está altamente disponible, lo que garantiza un funcionamiento sin interrupciones. Este viaje con Milvus ha transformado la búsqueda de Tokopedia, prometiendo un futuro de resultados de búsqueda personalizados y significativos. Con Milvus, están revolucionando el comercio electrónico en Indonesia y más allá.
*Este artículo ha sido escrito por Rahul Yadav, ingeniero de software de Tokopedia. Se ha editado y publicado aquí con permiso. *