




Computación bajo demanda de Zilliz Cloud: paga solo por lo que usas
El trimestre pasado trabajamos en un caso de facturación con un cliente de conducción autónoma. Su equipo de analítica necesitaba búsqueda vectorial en una colección de 1B de filas. Lo dimensionamos en un clúster Dedicated: $7,000/mes. Probamos Serverless: $10,800. El trabajo real de analítica era de unas pocas horas al mes.
Ambas facturas eran correctas. Ambos productos hacían exactamente aquello para lo que fueron diseñados. El problema era que la carga de trabajo de este cliente — analítica esporádica que compartía un dataset con otras dos cargas de trabajo de producción — no encajaba con aquello para lo que cualquiera de los dos productos fue diseñado.
Ese caso es la razón por la que creamos Zilliz Cloud On-Demand Search — una de las nuevas capacidades que lanzamos con el lanzamiento de Zilliz Vector Lakebase. Misma carga de trabajo, por menos de $500/mes. A continuación se explica qué no encajaba, qué cambiamos, dónde On-Demand es la herramienta equivocada y cómo vuelve a encajar en Vector Lakebase al final.
El caso del cliente
La colección — alrededor de 1 mil millones de registros — ya estaba siendo utilizada por dos cargas de trabajo de producción:
- Un servicio de recuperación online que atiende tráfico en tiempo real.
- Un pipeline de entrenamiento de modelos que extrae datos de escenarios para trabajos de regresión (ejecutado por un equipo separado).
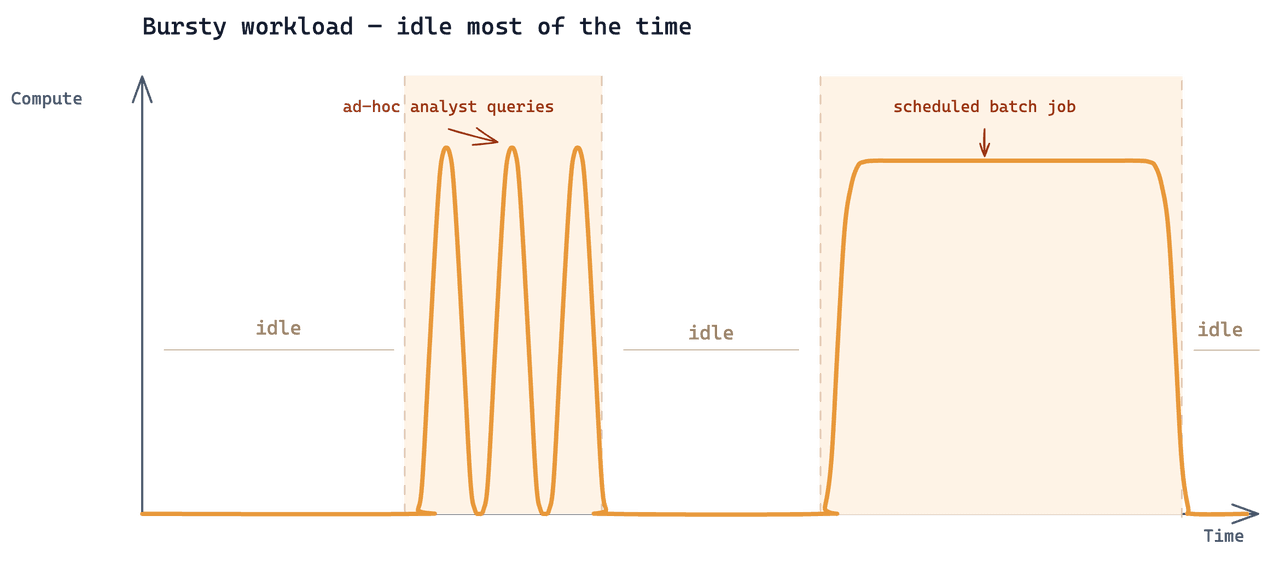
Analítica era una tercera carga de trabajo que se añadía sobre los mismos datos. El patrón de acceso: los analistas solo ejecutaban búsquedas cuando tenían una pregunta específica, en ráfagas iterativas cortas impulsadas por la investigación en curso. El resto del tiempo, no llegaban consultas analíticas al clúster.
Este es un caso de uso de Zilliz bastante común a una escala de datos bastante común. Lo que lo hacía difícil era que las tres cargas de trabajo necesitaban leer de la misma colección subyacente, y cada una tenía una cadencia muy diferente.
Por qué el clúster Dedicated no encajaba
La configuración existente era un clúster Tiered de Zilliz Cloud con 24 CU. Añadirle la carga de trabajo de analítica se valoraba en ~$7,000/mes. El clúster factura por cada hora que existe: 24 × 30 = 720 horas/mes. El trabajo real de analítica consumía 2–3 horas. Las 717 horas restantes se facturaban por estar inactivo — el 99.6% del gasto total iba a capacidad que nadie utilizaba.
Puedes detener un clúster Dedicated entre sesiones para evitar las horas inactivas. Lo consideramos. No funciona, por dos razones.
Primero, el arranque en frío en Dedicated tarda más de 10 minutos para consultas analíticas en frío sobre un dataset de este tamaño. El modelo mental de Dedicated es que todos los datos requeridos deben estar en memoria local antes de que se ejecuten las consultas, por lo que precarga todo el conjunto de trabajo — normalmente decenas a cientos de veces los datos que una sola consulta en frío realmente toca. La misma carga también tiene que levantar estado para trabajo no relacionado con consultas que el clúster admite, como DDL y eliminaciones. Esa sobrecarga existe tanto si la siguiente consulta la necesita como si no.
Segundo, la facturación se redondea a la hora. Así que incluso si el analista estuviera dispuesto a esperar más de 10 minutos a que el clúster se calentara, la factura por una sola consulta sigue siendo una hora más la carga. Con analistas trabajando en ráfagas iterativas cortas, el coste por consulta útil sigue siendo alto sin importar lo diligente que sea la disciplina de iniciar/detener.
Por qué el clúster Serverless no encajaba
Serverless fue la siguiente opción que probamos. Sobre el papel tiene la forma adecuada para este patrón de acceso: sin estado, pago por consulta, sin cómputo inactivo. Para la carga de trabajo de analítica por sí sola, podría haber funcionado.
El problema es que Serverless en este dataset no valora la carga de trabajo de analítica de forma aislada. Valora todo lo que toca la colección. Una vez que incluimos las cargas de trabajo existentes, tres partidas rompieron las cuentas:
- Consultas: ~$6,000/mes. La mayor parte provenía de los trabajos de regresión quincenales del equipo de entrenamiento de modelos: 100 QPS durante 3 horas, cada dos semanas. Los precios unitarios de Serverless incorporan una prima por consulta en frío que se paga en cada consulta, incluso cuando la consulta es caliente. Una vez que el volumen de consultas deja de ser trivialmente bajo, las cuentas dejan de cerrar.
- Almacenamiento: $1,700/mes. Se mide por separado porque Serverless no tiene una tarifa por hora de cómputo en la que incorporar el almacenamiento.
- Escrituras: $3,000/mes. La misma razón: no hay hora de cómputo en la que incorporarlas.
Total: $10,784/mes, más alto que el clúster Dedicated del que intentábamos escapar.
Cada una de esas primas tiene una razón estructural detrás.
Las consultas llevan una prima por consulta en frío. Desde el lado del usuario, Serverless es sin estado. Desde el lado de la plataforma, los datos aún tienen que cargarse en máquinas específicas para ejecutarse. Las consultas se dividen en calientes (los datos ya están en la máquina) y frías (primero hay que recuperarlos del almacenamiento de objetos). Las consultas calientes son baratas; las frías son caras. La plataforma no puede predecir qué consultas serán frías para un usuario determinado, así que distribuye el costo de las consultas en frío en el precio unitario de cada consulta. Las cargas de trabajo con consultas mayoritariamente calientes terminan pagando por las consultas frías de todos.
El almacenamiento tiene un precio por encima del costo marginal. En Dedicated, los costos de almacenamiento y escritura van incorporados de forma invisible en la tarifa por hora de cómputo. Serverless no tiene una tarifa por hora de cómputo detrás de la cual ocultar esos costos, así que el almacenamiento se cobra explícitamente. Ese precio explícito tiene que cubrir datos que están almacenados pero nunca se consultan: la plataforma no puede enviarlos a un almacenamiento profundamente frío porque los datos deben permanecer listos para consulta en cualquier momento. Mantener esa disponibilidad requiere estado adicional, y su costo termina amortizado sobre el tamaño del almacenamiento, que en realidad no se corresponde con el consumo real.
Las escrituras también tienen un precio por encima del costo marginal. Las escrituras se miden por separado para evitar que los usuarios emitan actualizaciones de alta frecuencia que generen mucho costo de escritura sin hacer crecer el conjunto de datos (lo que, de otro modo, dejaría a la plataforma absorbiendo el costo). La misma dinámica que con el almacenamiento: el costo del estado de disponibilidad se traslada al precio unitario por escritura.
El problema más profundo es que Serverless oculta la abstracción de "recurso de cómputo" al usuario. El usuario ve una interfaz sin estado; la plataforma aún tiene que pagar por patrones de acceso impredecibles detrás de ella: datos calientes/fríos, tráfico con ráfagas, almacenamiento inactivo que debe permanecer listo para consulta. Esos costos no pueden atribuirse con precisión a usuarios específicos, así que se amortizan en los precios unitarios de consultas, almacenamiento y escrituras. Cada acción facturable termina un punto por encima de su costo marginal real.
Este es un modelo de "riesgo compartido": cada partida lleva un recargo para cubrir las consultas frías, las ráfagas o el almacenamiento inactivo de otra persona. Las cargas de trabajo menos responsables de esa variación —consultas calientes estables, de alta frecuencia y predecibles— pagan la mayor parte de la prima. Cuanto más estable es tu carga de trabajo, más terminas subsidiando.
Lo que el cliente realmente necesitaba
Dando un paso atrás, lo que pedía el cliente no era exótico. Un conjunto de datos, múltiples cadencias de acceso, con la factura siguiendo solo el cómputo que cada cadencia realmente usaba.
- Recuperación en línea: continua, de baja latencia, predecible. Dedicated es adecuado para esto.
- Entrenamiento de modelos: con ráfagas pero predecible: 3 horas cada dos semanas.
- Analítica: esporádica e impredecible: unos pocos minutos cada vez, con largos intervalos.
Dedicated no podía ofrecer eso. Cobra por capacidad aprovisionada, no por consumo. Serverless tampoco podía: su precio unitario por consulta tiene que subsidiar consultas frías, almacenamiento inactivo y margen para ráfagas de todos los usuarios de la plataforma, así que las cargas de trabajo estables terminan pagando por una variación que no generan.
Lo que necesitábamos era un tercer modelo de cómputo: uno que pudiera conectarse a los mismos datos que Dedicated, iniciarse lo suficientemente rápido como para hacer realista la facturación por consulta y cobrar solo cuando estuviera realmente en ejecución.
Lo que cambiamos
On-Demand es un modelo de cómputo separado en Zilliz Cloud que convive con Dedicated y Serverless. Cambia tres cosas en comparación con cualquiera de los dos:
- Arranque en frío. Carga solo los fragmentos que toca la consulta actual, no todo el conjunto de trabajo. Baja de más de 10 minutos a segundos.
- Facturación. Por minuto de tiempo de actividad real de cómputo. Escrituras también. Sin hora mínima, sin prima por consulta fría/caliente.
- Aislamiento. Cada carga de trabajo se conecta a una colección a través de su propio grupo de recursos de cómputo. Los mismos datos, sin contención.
Las siguientes tres secciones explican cada uno.
Cargar menos datos, más rápido
El arranque en frío de 10 minutos en Dedicated existe porque el clúster tiene que cargar todo el conjunto de trabajo en memoria local antes de atender consultas. En una colección de 1B de filas, eso equivale a decenas o cientos de veces más datos de los que realmente necesita cualquier consulta individual. Comprimir el arranque en frío a segundos significa abandonar esa suposición: cargar solo lo que toca la consulta actual.
Eso suena como una sola frase; en la práctica requirió rediseñar tres capas: qué leer, dónde ponerlo y cómo ponerlo en marcha.
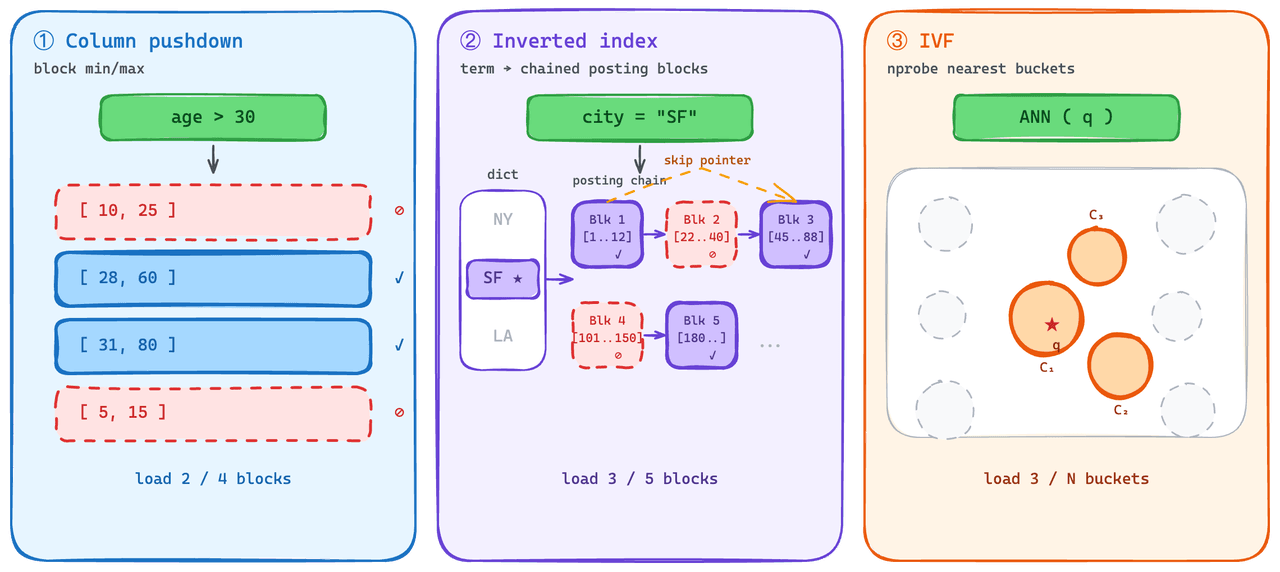
Índices que se cargan parcialmente.
En el lado escalar, el predicate pushdown es una práctica estándar. El motor elimina bloques que no pueden coincidir con el predicado y evita obtenerlos. Usamos esto en índices invertidos: cada lista de postings se carga como un bloque, y cada lista lleva estadísticas de mínimo/máximo que el motor puede comprobar antes de obtenerla.
La parte más difícil fue darle al lado vectorial una capacidad comparable de "leer un subconjunto". Los índices de grafos —la opción de mayor rendimiento para QPS en estado estable— no se degradan de forma elegante con la carga parcial: la estructura tiene que cargarse por completo para ser útil, por lo que el coste de carga en frío es alto.
On-Demand usa la familia IVF en su lugar. IVF agrupa los vectores en buckets en el momento de indexación, y en el momento de la consulta solo se obtienen los buckets más cercanos a la consulta. Eso le da al lado vectorial algo parecido a la semántica de predicate-pushdown: las consultas en frío extraen una pequeña fracción del índice, no todo.
Esto es una compensación deliberada. Perdemos el rendimiento en estado estable de los índices de grafos, que es la razón principal por la que On-Demand no es adecuado para serving de alto QPS (más sobre eso abajo). Para cargas de trabajo dispersas y con ráfagas, la compensación vale la pena.
Una ruta de datos de tres niveles.
Una vez que sabemos qué leer, la siguiente pregunta es dónde conservarlo. Los fragmentos fluyen libremente entre S3, el disco local y la memoria, y el ciclo de vida de la caché se gestiona por fragmento entre consultas: los fragmentos que necesita la consulta actual se suben; los fragmentos que permanecen inactivos el tiempo suficiente se expulsan. El mismo dataset puede consultarse a cadencias muy diferentes, y ninguno paga el coste de cargar datos que no toca.
Cada nivel tiene su propio diseño y granularidad de datos, adaptados a las características de IO del medio: la alineación que funciona para el almacenamiento de objetos no es la alineación que funciona para el disco local, y ninguna de las dos coincide con lo que el motor ejecuta en memoria.
IO asíncrona de extremo a extremo.
La cadena de IO es totalmente asíncrona. El cómputo y la IO se canalizan durante todo el proceso, de modo que la CPU no se queda esperando una obtención y el ancho de banda de IO no se queda esperando al cómputo.
En conjunto, fragmentado + por niveles + asíncrono reduce la carga útil de una consulta en frío a menos del 1–2% del dataset completo y la ruta en frío de extremo a extremo a segundos.
Facturación por minuto
Con el arranque en frío al nivel de segundos, "poner en marcha cómputo cuando llega una consulta, liberarlo cuando termina" funciona como un mecanismo de producto real, no solo como una aspiración de diseño. Dos piezas del plano de control hacen el trabajo pesado.
Un pool de nodos en espera. Las descargas de imágenes añaden latencia al levantar un nodo nuevo. Mantenemos un pequeño pool de nodos con imágenes ya descargadas listo, de modo que el arranque toma nodos del pool en lugar de empezar desde cero.
Liberación basada en TTL. Cada sesión tiene un tiempo de espera por inactividad configurable. Los recursos de cómputo se liberan automáticamente cuando se agota el tiempo de espera, finaliza la carga de trabajo de consultas o se cierra la sesión. Todo el ciclo de vida está programado por la plataforma: no hay modo "olvidé detener mi clúster", ni operaciones manuales.
Como el ciclo de vida es granular, la granularidad de facturación baja para coincidir. El cómputo se factura por minuto de tiempo de actividad real: sin hora mínima, sin cargo mínimo por consulta. Las escrituras se miden de la misma manera: uso real de recursos, por minuto.
La precisión en la atribución de costos es lo que permite que On-Demand evite la prima de almacenamiento que Serverless tiene que cobrar. Serverless cobra el almacenamiento por encima del costo marginal porque su capa de cómputo no tiene forma de absorber costos no atribuidos: cada dólar que gasta la plataforma tiene que aparecer en alguna parte de la factura, por lo que el almacenamiento y las escrituras se convierten en el vertedero de lo que no puede atribuirse en otro lugar. Cuando On-Demand factura cada minuto de cómputo a una sesión específica, no hay un fondo no atribuido. El almacenamiento en On-Demand sigue los precios de Zilliz Cloud a tarifas Dedicated: alrededor de 1/10 del almacenamiento Serverless típico.
Aislamiento de cargas de trabajo sobre datos compartidos
El tercer cambio es hacer explícita la capa de cómputo. En Dedicated, la capa de cómputo es el clúster: invisible para el usuario excepto como un único parámetro de dimensionamiento. En Serverless, la capa de cómputo está completamente oculta. On-Demand la expone.
Cada carga de trabajo se conecta a una colección a través de un grupo de recursos de cómputo. Los nuevos grupos se ponen en marcha —o se reutilizan los existentes— mediante sesiones. Los diferentes grupos están aislados entre sí, y la factura de cada grupo refleja solo su propio consumo.
Para el caso de conducción autónoma, así es como la carga de trabajo de analítica obtiene su propia conexión a los datos: un grupo de recursos On-Demand que se inicia para consultas ad hoc y se libera al quedar inactivo, ejecutándose sobre la misma colección de Milvus, los mismos índices y los mismos metadatos que las cargas de trabajo existentes de recuperación en línea y entrenamiento de modelos. La separación almacenamiento-cómputo significa que ninguno de ellos tiene que copiar ni sincronizar datos para usarlos. Sin subsidios cruzados, sin contención de planificación, sin coordinación operativa entre equipos sobre la forma del clúster.
Este es el mismo patrón arquitectónico que un data lake, aplicado a la búsqueda vectorial: el almacenamiento es el sustrato compartido, y el cómputo se conecta con la forma que cada carga de trabajo necesite.
La factura, después
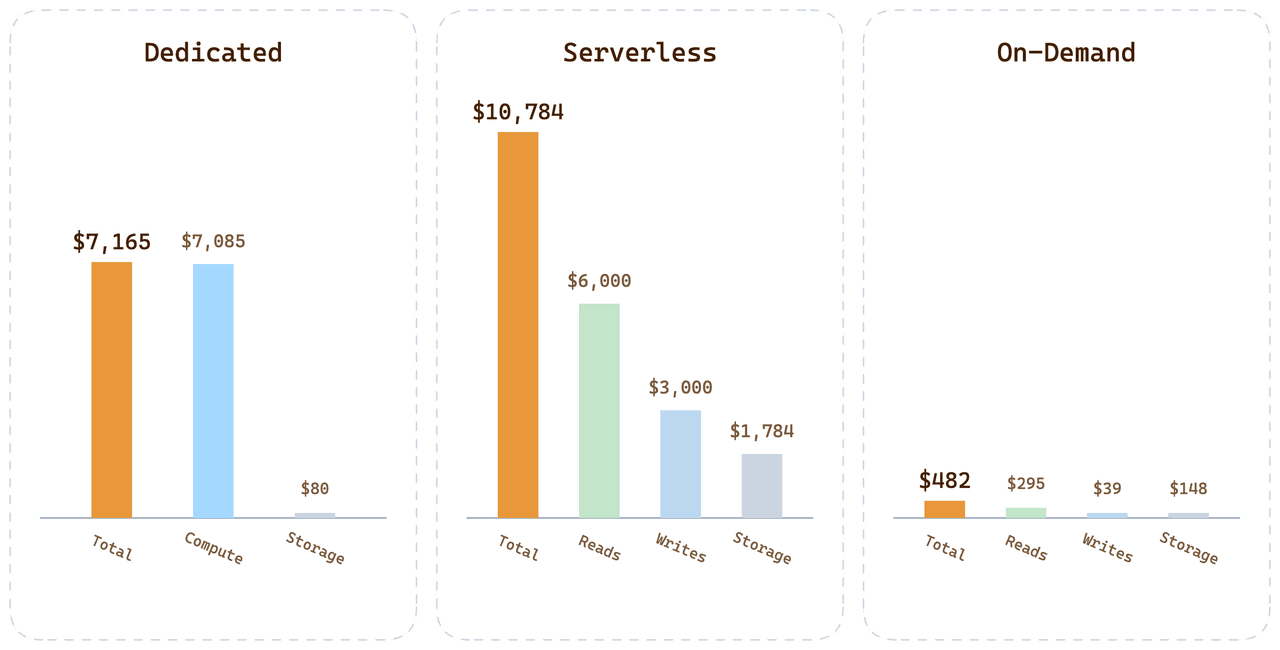
Para la misma carga de trabajo del cliente en las tres opciones:
| Opción | Factura mensual | A dónde va el dinero |
|---|---|---|
| Dedicated (24 CU Tiered) | $7,165 | 99.6% del cómputo pagado pero inactivo |
| Serverless | $10,784 | Prima por consultas + $1,700 de almacenamiento + $3,000 de escrituras |
| On-Demand | < $500 | Cómputo por minuto + almacenamiento a tarifa Dedicated |
On-Demand para esta carga de trabajo queda por debajo de 1/20 de la factura Serverless. La diferencia no es un truco de precios; es la consecuencia directa de atribuir el costo al consumo real en lugar de amortizar la variabilidad de otros usuarios en cada precio unitario.
Dónde On-Demand no es la herramienta adecuada
On-Demand no es un reemplazo universal de Dedicated o Serverless. Las mismas decisiones de diseño que lo hacen barato para cargas de trabajo escasas y con ráfagas lo hacen inadecuado para otras. El gráfico siguiente traza el costo mensual frente a la presión de consultas para la carga de trabajo de este cliente en las tres opciones.
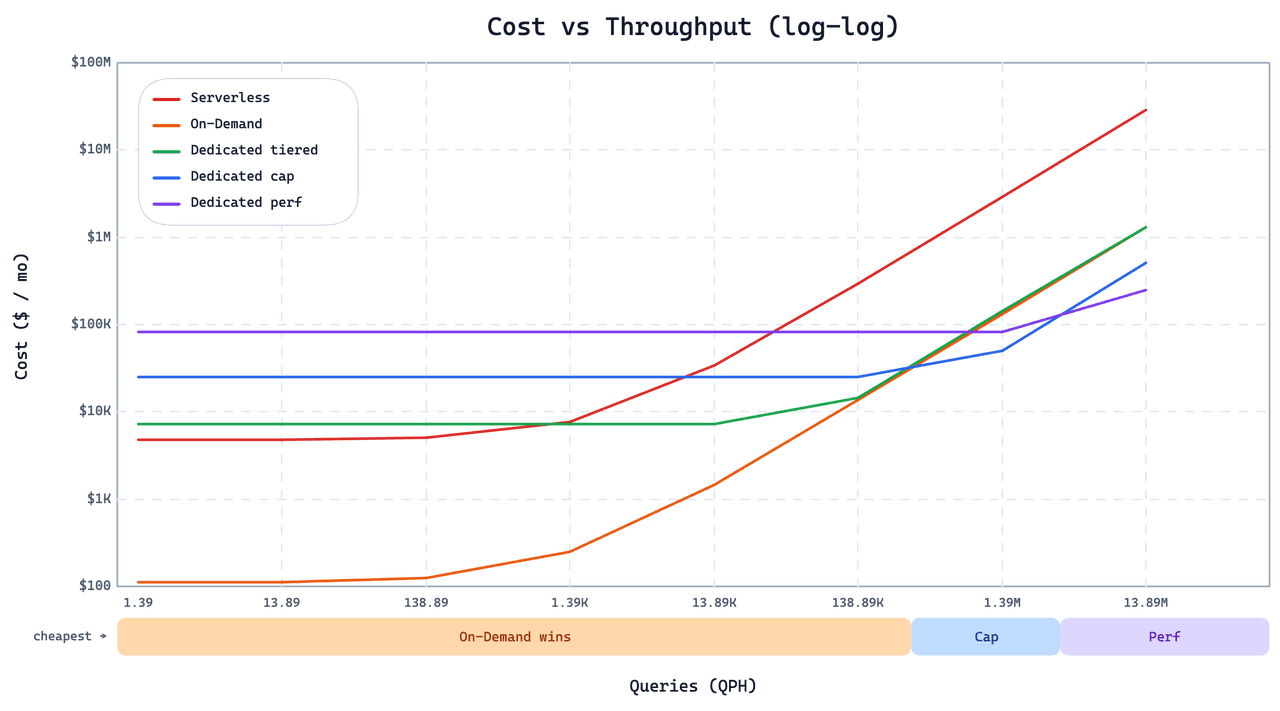
Por debajo del punto de cruce, On-Demand es significativamente más barato. Una vez que el QPS entra en las decenas, las instancias Dedicated Cap o Perf se vuelven tanto más baratas como más rápidas. Dos decisiones de diseño explican el punto de cruce:
Sin índice de grafo. Para mantener barata la carga de consultas en frío, On-Demand usa IVF en lugar de índices de grafo. Los índices de grafo ofrecen un QPS sostenido más alto a escala, pero su coste de carga en frío es alto. Por encima de unas pocas decenas de QPS, la ventaja en estado estable gana de forma decisiva. Para serving de alto QPS, usa Dedicated.
Mayor latencia de cola en consultas en frío. On-Demand no precarga datos, por lo que una consulta en frío paga una recuperación adicional antes de poder ejecutarse. Las consultas en caliente son rápidas; las consultas en frío son notablemente más lentas, y la distribución de la latencia de cola es más amplia que en Dedicated o Serverless. Si tu aplicación no puede tolerar respuestas ocasionales a nivel de segundos (o peor, a nivel de minutos), On-Demand no es lo adecuado. Para esas cargas de trabajo, Smart Autoscaling on Dedicated reduce la capacidad ociosa sin sacrificar la latencia en estado caliente.
Donde On-Demand sí es la herramienta adecuada: acceso disperso, iteración analítica y minería por lotes en grandes conjuntos de datos — cargas de trabajo en las que la alta concurrencia y una consistencia estricta de latencia no son los requisitos principales.
Dónde encaja esto en Zilliz Vector Lakebase
El caso de cliente de esta publicación es una parte de un patrón más amplio: el mismo conjunto de datos, accedido con diferentes cadencias por diferentes cargas de trabajo, dimensionado correctamente solo cuando cada carga de trabajo obtiene la forma de cómputo que realmente necesita. On-Demand es una de las formas de cómputo. Zilliz Vector Lakebase es la arquitectura que hace posible el resto.
Una Vector Lakebase es una plataforma de datos nativa de lake para cargas de trabajo de IA. Los datos residen en S3, los índices están desacoplados del cómputo, y diferentes formas de cómputo se conectan a la misma colección mediante acceso zero-copy. Maneja tres modos de carga de trabajo como capacidades de primer nivel — recuperación en tiempo real, descubrimiento iterativo y análisis por lotes — cada uno servido por la forma de cómputo que se ajusta a su patrón de acceso. La recuperación vectorial siempre ha sido una carga de trabajo de primer nivel en Zilliz Cloud; con el lanzamiento de Vector Lakebase, las formas de cómputo de descubrimiento iterativo y análisis por lotes se unen a ella sobre la misma base de datos.
On-Demand es la forma de cómputo creada para cargas de trabajo analíticas y con picos. Las otras cuatro capacidades cubren el resto de los modos:
- Tiered Serving Solutions para recuperación en tiempo real — Performance-Optimized (1000+ QPS, latencia de ms de un solo dígito, todo en memoria), Capacity-Optimized (100–500 QPS con latencia inferior a 100 ms en memoria + NVMe local) y Tiered-Storage (10–50 QPS con latencia de ~100 ms entre memoria, NVMe y almacén de objetos). Diferentes puntos en la curva de rendimiento/coste, el mismo modo de serving.
- External Data Lake Search para indexar y buscar datos que ya están en Lance, Iceberg u otros formatos de lake — sin copiarlos a un almacén separado.
- Full-Spectrum Search para vectores, texto, JSON y geoespacial en un único plano de consulta, con recuperación híbrida, filtrado y reranking sobre un modelo de datos de tabla ancha.
- Unified Lake-Native Storage construido sobre Vortex, un formato columnar abierto de próxima generación con lecturas aleatorias más rápidas que Lance o Parquet, además de flexibilidad de formato por columna.
Zilliz Vector Lakebase está ahora en vista previa pública en Zilliz Cloud. Para la arquitectura completa y el resto de las capacidades, el análisis en profundidad de Vector Lakebase es la lectura de referencia.
Para probar On-Demand en tu propia carga de trabajo, regístrate en Zilliz Cloud y crea un clúster On-Demand desde la consola o la CLI. Si las cifras de esta publicación se corresponden con algo que estás ejecutando, el equipo de Zilliz estará encantado de revisar tu carga de trabajo antes de que empieces a construir.

Sigue leyendo

Zilliz Cloud Audit Logs Goes GA: Security, Compliance, and Transparency at Scale
Zilliz Cloud Audit Logs are now GA, giving enterprises real-time visibility, compliance-ready trails, and stronger security across AWS, GCP, and Azure.

Introducing Zilliz MCP Server: Natural Language Access to Your Vector Database
Developers can easily manage and query vector databases with natural language via Zilliz MCP Server in AI-native environments.

Demystifying the Milvus Sizing Tool
Explore how to use the Sizing Tool to select the optimal configuration for your Milvus deployment.