




Cómo detectar y corregir las falacias lógicas de los modelos GenAI
Introducción
Los Large language models (LLMs) han transformado el campo de la IA, especialmente en la IA conversacional, la generación de textos, etc. Los LLM se entrenan en cantidades masivas de datos con miles de millones de parámetros para generar texto como los humanos. Muchas empresas esperan desarrollar chatbots basados en LLM para gestionar las consultas de los clientes, recibir opiniones, resolver quejas, etc. A medida que crece el uso y la adopción de LLM, necesitamos abordar un problema crítico: Falacias lógicas en los resultados de los LLM. Es crucial abordar este reto y hacer que los sistemas de IA sean más responsables y fiables.
Jon Bennion, ingeniero de IA con amplia experiencia en ML aplicado, seguridad y evaluación de IA, habló recientemente sobre un enfoque interesante para abordar las falacias lógicas en el Unstructured Data Meetup organizado por Zilliz. Jon es un destacado colaborador de LangChain, donde aplica nuevos enfoques para abordar las falacias en los resultados.
Vea la repetición de la charla de Jon_**
Durante su presentación, Jon explica los errores más comunes en el razonamiento de modelos que pueden conducir a falacias lógicas. También habla de estrategias para identificar y corregir estas falacias, haciendo hincapié en la importancia de alinear los resultados de los modelos con un razonamiento lógico y humano.
¿Qué son las falacias lógicas?
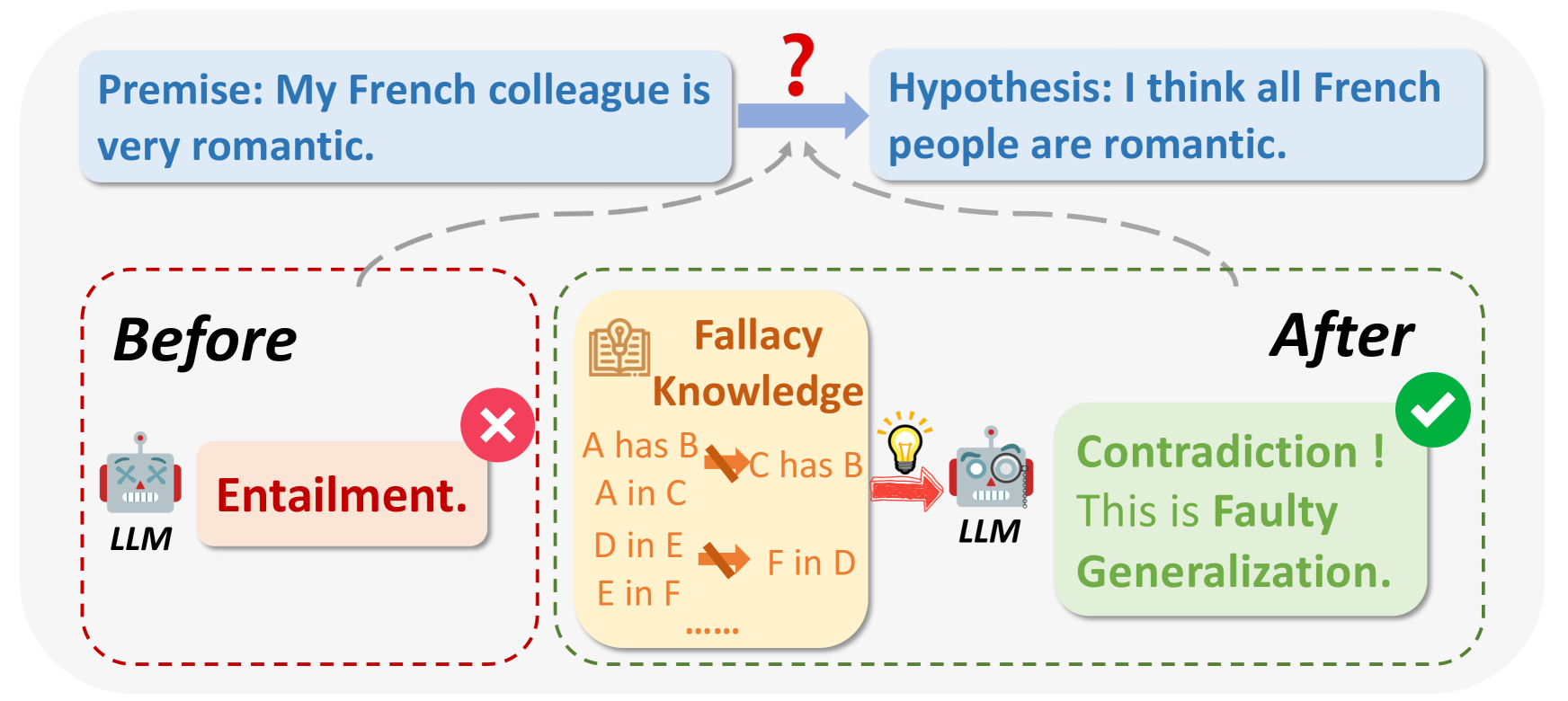
¿Qué son las falacias lógicas?.png](https://assets.zilliz.com/What_are_logical_fallacies_0d774794f8.png)
Fig 1: ¿Qué son las falacias lógicas?
Fuente de la imagen:_ https://arxiv.org/html/2404.04293v1/x1.png
Al consultar los LLM, en algunos casos, el resultado puede ser erróneo por razones lógicas o irrelevante para la pregunta. Las falacias lógicas incluyen Ad Hominem, razonamiento circular, Apelación a la Autoridad, etc. Suelen hacer amplias generalizaciones basadas en muestras de pequeño tamaño, por ejemplo: "Mi amigo de Francia es maleducado, así que todos los franceses deben ser maleducados".
En algunos casos, puede suponer que algo es cierto o correcto porque es popular.
Ejemplo_: "Todo el mundo usa esta nueva aplicación, así que debe ser la mejor". A veces, a los LLM les resulta difícil recordar los detalles de la conversión anterior y no pueden dar una respuesta precisa.
¿Por qué se producen las falacias lógicas?
Hay múltiples razones por las que las falacias lógicas pueden ocurrir estando en la cima. Como todos sabemos, los LLM no están perfectamente entrenados para enfrentarse a todas las situaciones de la misma manera que nuestro cerebro las comprendería.
Datos de entrenamiento imperfectos
Los datos de entrenamiento que proporcionamos proceden de diversas fuentes de Internet y no son perfectos. Contienen muchos sesgos humanos, incoherencias e incluso información errónea en casos extremos. Durante el entrenamiento, el LLM se ve expuesto a razonamientos erróneos e incoherentes, y también los aprende. Si los datos de entrenamiento contienen argumentos erróneos, recogerá estos patrones y los imitará en las respuestas.
Pequeña ventana de contexto
En la charla, Jon menciona: "Una ventana de contexto pequeña puede causar problemas en la respuesta. Muchos equipos luchan por optimizar la ventana de contexto para los requisitos de memoria y el rendimiento".
La ventana de contexto se refiere a la cantidad de información que un LLM puede considerar a la vez, y es fija. Cuando la ventana de contexto es pequeña, el modelo puede pasar por alto detalles importantes y no puede formar una respuesta coherente. Esto puede dar lugar a falacias como generalizaciones precipitadas o falsas dicotomías.
Naturaleza probabilística
Los LLM generan texto basándose en qué palabra es altamente probable en la secuencia. No pueden comprender el verdadero significado de las palabras como hacen los humanos. Entrenamos a los modelos para que logren una coherencia local proporcionada por el contexto. A veces, esto puede dar lugar a falacias lógicas, ya que se puede pasar por alto el contexto más amplio.
¿Cómo combatir las falacias lógicas?
Es crucial detectar y evitar que el LLM produzca respuestas con falacias lógicas para que los usuarios puedan confiar en él. Jon discute brevemente las prácticas comunes usadas para abordar este problema, como la retroalimentación humana, el aprendizaje por refuerzo, la ingeniería de avisos y más.
En esta charla, Jon presenta un enfoque interesante para detectar y corregir falacias lógicas, "RLAIF". La idea aquí es utilizar la IA para arreglarse a sí misma.
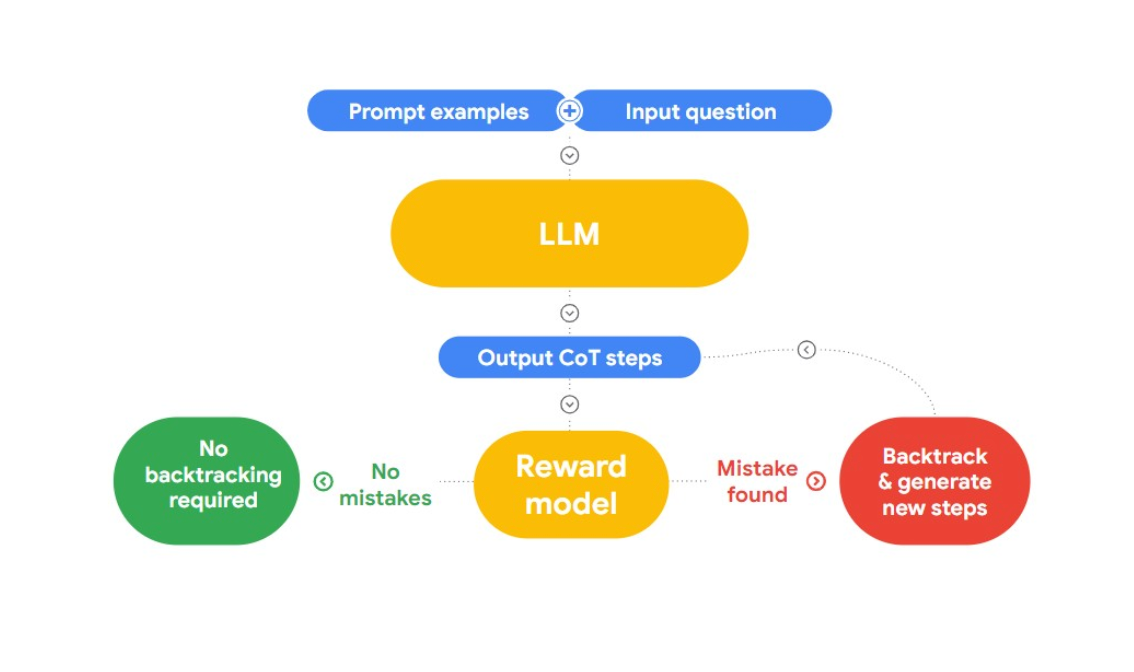
Fig 2: ¿Cómo funciona RLAIF?
Hace referencia al trabajo de investigación "Case-based Reasoning with Language Models for Classification of Logical Policies", que es útil para nuestro problema. El documento introduce Case-Based Reasoning (CBR), para clasificar las falacias lógicas. Funciona en tres etapas:
Recuperación: Proporcionamos a CBR una colección de datos de texto (base de casos) que tiene falacias lógicas e identidad por humanos. Cuando se proporciona un nuevo texto, CBR busca en la base de casos para encontrar un caso similar.
Adaptación: Los casos recuperados se adaptan entonces al contexto específico del nuevo argumento, considerando factores como objetivos, explicaciones y contraargumentos.
- Clasificación: Basándose en la información disponible, el CBR identifica y clasifica las falacias lógicas.
Jon ha tomado este enfoque, lo ha desarrollado más y ha implementado una función de detección de falacias en LangChain.
Prevenir falacias lógicas usando la cadena de falacias de LangChain
Jon demuestra un ejemplo pidiendo al modelo que proporcione salidas con falacias lógicas. El siguiente ejemplo muestra una salida que sufre de "Apelación a la Autoridad" y es lógicamente errónea.
# Ejemplo de una salida del modelo que se devuelve con una falacia lógica
misleading_prompt = PromptTemplate(
template="""Tiene que responder utilizando únicamente falacias lógicas inherentes a las explicaciones de sus respuestas.
Pregunta: {pregunta}
Mala respuesta:""",
input_variables=["pregunta"],
)
llm = OpenAI(temperatura=0)
cadena_engañosa = LLMChain(llm=llm, pregunta=pregunta_engañosa)
misleading_chain.run(question="¿Cómo sé que la Tierra es redonda?")
La salida:
'La tierra es redonda porque mi profesor dice que lo es, y todo el mundo cree a mi profesor'
Es un método de ingeniería inversa en el que localizamos las falacias que el modelo ha aprendido y luego le impedimos que las utilice.
Jon explicó cómo podemos utilizar el módulo FallacyChain de LangChain para hacer correcciones. En primer lugar, inicializamos una LangChain con la indicación engañosa para resaltar las falacias inherentes presentes.
falacias = FallacyChain.get_fallacies(["corrección"])
cadena_falacia = FallacyChain.from_llm(
cadena=cadena_engañosa,
falacias_logicas=falacias,
llm=llm,
verbose=Verdadero,
)
fallacy_chain.run(question="¿Cómo sé que la tierra es redonda?")
A continuación, inicializamos una cadena de falacias, proporcionando la cadena de falacias como entrada y el modelo LLM. Detectará el tipo de falacia presente y actualizará la respuesta eliminándola.
> Introduciendo nueva cadena FallacyChain...
Respuesta inicial: La tierra es redonda porque mi profesor dijo que lo es, y todo el mundo cree a mi profesor.
Aplicando corrección...
Crítica a la falacia: La respuesta del modelo utiliza una apelación a la autoridad y ad populum (todo el mundo cree al profesor). Crítica de falacia necesaria.
Respuesta actualizada: Puedes encontrar evidencia de una tierra redonda debido a evidencia empírica como fotos desde el espacio, observaciones de barcos desapareciendo sobre el horizonte, ver la sombra curva en la luna, o la habilidad de circunnavegar el globo.
> Cadena terminada.
Puedes encontrar evidencia de una tierra redonda debido a evidencia empírica como fotos del espacio, observaciones de barcos desapareciendo en el horizonte, viendo la sombra curva en la luna, o la habilidad de circunnavegar el globo.'
Jon se sumerge en el funcionamiento del módulo Fallacy Chain, que incorporó a LangChain. La arquitectura de la Cadena de Falacias tiene dos componentes principales: La Cadena de Crítica y la Cadena de Revisión. En ambas cadenas se aprovecha la ingeniería de prompts para detectar y modificar las falacias en la respuesta. Un vistazo rápido a cómo funciona:
Cuando proporcionamos la entrada, el LLM la procesa y genera una respuesta inicial.
El siguiente paso es la detección de falacias. La cadena de Crítica identifica y clasifica cualquier falacia presente basándose en los patrones identificados. Jon menciona el aprovechamiento de la lista de falacias que se extrajeron y utilizaron del trabajo de investigación mencionado anteriormente.
La cadena de revisión se codifica con ingeniería de avisos para volver a generar una respuesta revisada que evite las falacias detectadas. Esto puede implicar reformular, añadir contexto o alterar la estructura del argumento.
Aplicación de demostración
Jon también demostró una aplicación para extraer falacias lógicas de artículos de noticias. En esta demostración, mostró cómo los nuevos artículos de diferentes regiones pueden tener un sesgo político y de autoridad. También mostró una aplicación creada con Open AI para extraer nuevos artículos sobre un tema determinado e identificar sus principales falacias. Con esta aplicación, buscó nuevos artículos relacionados con "China" como palabra clave, y el resultado se muestra a continuación.

Los artículos explican cómo la Cadena de Falacias ha identificado y explicado el problema de la "Apelación a la Autoridad". Jon habla de cómo herramientas como ésta pueden limpiar nuestros datos de entrenamiento de falacias lógicas, proporcionando un aprendizaje sin fallos al modelo. FallacyChain puede mejorar considerablemente la fiabilidad de los resultados del LLM y aumentar la confianza de los usuarios. También proporciona transparencia al explicar los cambios y sus razones, ayudando a los usuarios a entender cómo se logró la coherencia lógica.
Para más información sobre esta demostración, ver la repetición de la charla de Jon en el meetup.
Conclusión
La FallacyChain en LangChain es un poderoso enfoque para mejorar la integridad lógica del texto generado por LLMs. Puede aumentar la confianza entre los usuarios y facilitar la implementación de los LLM conforme a la normativa. Aunque las ventajas son asombrosas, es necesario evaluar los costes para implantarlo a escala. Es un espacio apasionante, y se están realizando nuevos experimentos para mejorarlo utilizando métodos de aprendizaje automático para la clasificación de falacias, etc.

{kind=link}
{kind=link}
Sigue leyendo

DeepSeek-OCR Explained: Optical Compression for Scalable Long-Context and RAG Systems
Discover how DeepSeek-OCR uses visual tokens and Contexts Optical Compression to boost long-context LLM efficiency and reshape RAG performance.

Why Context Engineering Is Becoming the Full Stack of AI Agents
Discover how context engineering unifies prompts, RAG, and tools to build smarter, production-ready AI agents powered by Milvus.

OpenAI o1: What Developers Need to Know
In this article, we will talk about the o1 series from a developer's perspective, exploring how these models can be implemented for sophisticated use cases.