




WhyHow
Build more controlled retrieval workflows within your RAG pipeline with WhyHow and Milvus or Zilliz Cloud
Verwenden Sie diese Integration kostenlosWas ist WhyHow?
WhyHow ist eine Plattform, die Entwicklern die Bausteine zur Verfügung stellt, um unstrukturierte Daten zu organisieren, zu kontextualisieren und zuverlässig abzurufen, um komplexe Retrieval Augmented Generation (RAG) durchzuführen. Das Rule-based Retrieval Package ist ein von WhyHow entwickeltes Python-Paket, das Entwicklern hilft, genauere Retrieval-Workflows innerhalb von RAG zu erstellen, indem es erweiterte Filterfunktionen hinzufügt. Dieses Paket ist mit OpenAI für die Texterstellung und Milvus und Zilliz Cloud (vollständig verwaltetes Milvus) für effiziente Vektorspeicherung und Ähnlichkeitssuche integriert.
Warum die Integration von WhyHow und Milvus/Zilliz?
Retrieval Augmented Generation (RAG) ist eine fortschrittliche Technologie, die große Sprachmodelle (LLMs) durch die Bereitstellung von kontextbezogenen Abfrageinformationen für genauere Antworten erweitert. Bei einer einfachen RAG-Pipeline kann es jedoch vorkommen, dass nicht immer die richtigen Datenpakete abgerufen werden. Dieses Problem kann auf die Blackbox-Natur des Abrufs und der LLM-Antwortengenerierung zurückzuführen sein, auf schlecht formulierte Benutzeranfragen, die suboptimale Ergebnisse aus einer Vektordatenbank liefern, oder auf die Notwendigkeit, kontextuell relevante, aber semantisch unähnliche Daten in die Antworten aufzunehmen.
Um diese Herausforderungen zu meistern, brauchen wir eine bessere Kontrolle über die Abfrage von Rohdaten. Durch die Integration von WhyHow und Milvus/Zilliz können wir eine regelbasierte Abfragelösung aufbauen. Mit diesem Ansatz können Sie vor der Durchführung einer [Ähnlichkeitssuche] (https://zilliz.com/learn/vector-similarity-search) spezifische Regeln für relevante Datenchunks definieren und zuordnen und so die Kontrolle über den Abrufworkflow verbessern. Durch die Implementierung dieser Regeln wird der Umfang der Abfragen auf eine gezieltere Gruppe von Chunks eingegrenzt, wodurch sich die Wahrscheinlichkeit erhöht, dass relevante Daten für die Erstellung präziser Antworten abgerufen werden. Durch weitere Eingabeaufforderungen und Abfrageoptimierungen kann die Ausgabequalität kontinuierlich verbessert werden.
Wie die Integration von WhyHow und Milvus/Zilliz funktioniert
Die regelbasierte Retrieval-Lösung, die mit WhyHow und Milvus/Zilliz entwickelt wurde, erfüllt die folgenden Aufgaben:
Erstellung eines Vektorspeichers: Diese Integration erstellt eine Milvus-Sammlung zur Speicherung der Chunk-Einbettungen.
Splitting, Chunking und Einbettung: Wenn Sie Ihre Dokumente hochladen, teilt die Integration die Dokumente automatisch auf, chunked sie und erstellt Einbettungen, bevor sie in Milvus oder Zilliz Cloud aufgenommen werden. Dieses regelbasierte Abrufpaket unterstützt derzeit [PyPDFLoader] (https://python.langchain.com/v0.1/docs/modules/data_connection/document_loaders/pdf/) und [RecursiveCharacterTextSplitter] (https://python.langchain.com/docs/modules/data_connection/document_transformers/recursive_text_splitter) von LangChain für die PDF-Verarbeitung, die Extraktion von Metadaten und das Chunking. Für die Einbettung unterstützt es das OpenAI text-embedding-3-small model.
Dateneinfügung: Lädt die Einbettungen und die Metadaten in Milvus oder Zilliz Cloud hoch.
Automatische Filterung: Anhand benutzerdefinierter Regeln erstellt die Integration automatisch einen Metadatenfilter, um die Abfrage gegen den Vektorspeicher einzugrenzen.
Der Arbeitsablauf dieser Integration ist wie folgt:
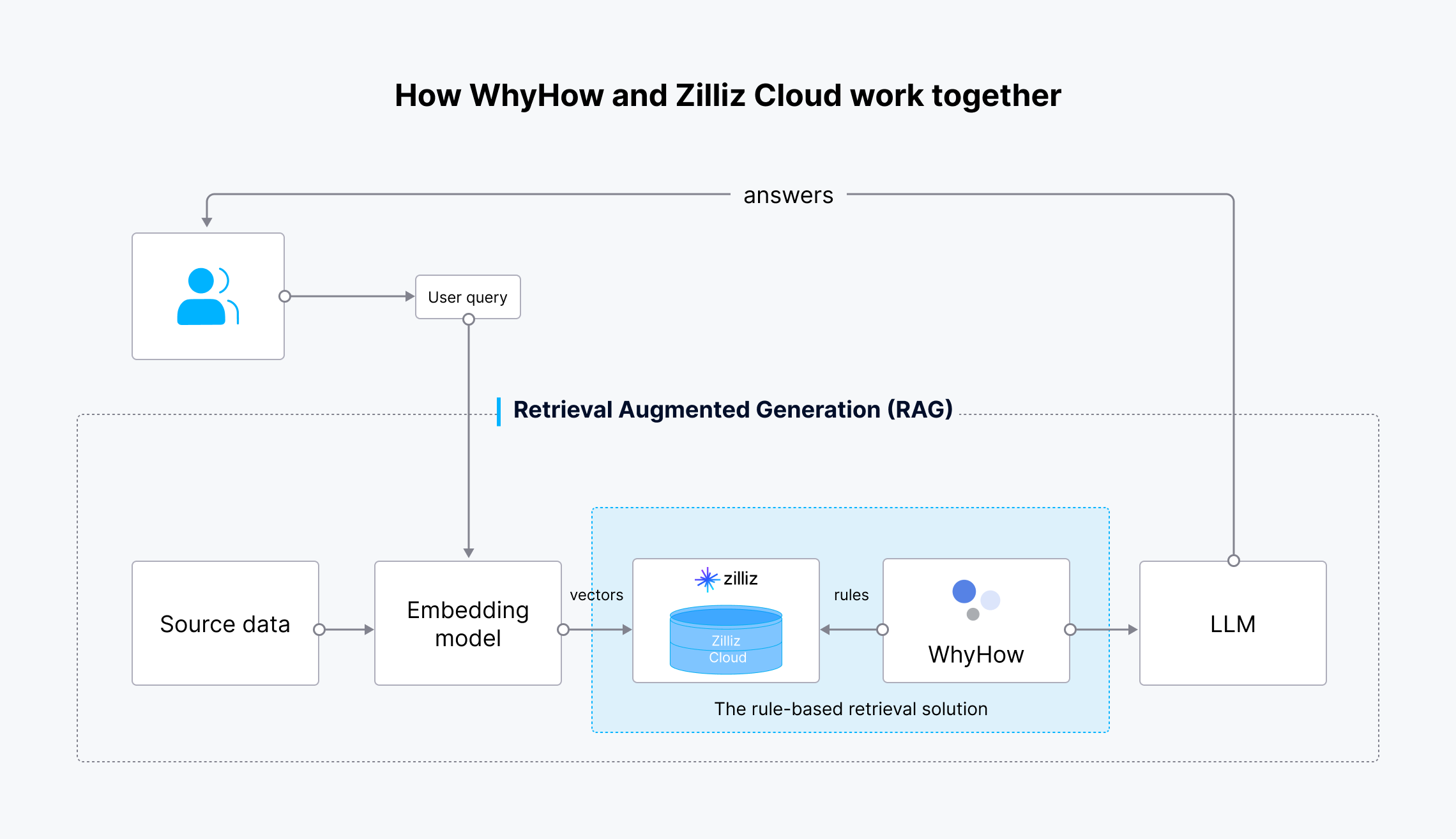 Wie WhyHow und Zilliz Cloud zusammenarbeiten.png
Wie WhyHow und Zilliz Cloud zusammenarbeiten.png
- Die Quelldaten werden mithilfe des Einbettungsmodells von OpenAI in Vektoreinbettungen umgewandelt.
- Die Vektoreinbettungen werden zur Speicherung und zum Abruf in Milvus oder Zilliz Cloud aufgenommen.
- Die Benutzeranfrage wird ebenfalls in Vektoreinbettungen umgewandelt und an Milvus oder Zilliz Cloud gesendet, um nach den relevantesten Ergebnissen zu suchen.
- WhyHow legt Regeln fest und fügt der Vektorsuche Filter hinzu.
- Die abgerufenen Ergebnisse und die ursprüngliche Benutzeranfrage werden an den LLM gesendet.
- Der LLM generiert genauere Ergebnisse und sendet sie an den Nutzer.
Wie man WhyHow und Milvus/Zilliz Cloud verwendet