




Datenmodellierung verstehen

Datenmodellierung verstehen
In einer Zeit, in der Daten das wertvollste Kapital eines Unternehmens sind, ist die effiziente Erfassung, Speicherung und Verwaltung umfangreicher Daten entscheidend für die Sicherung eines Wettbewerbsvorteils. Doch wie können Unternehmen aus unterschiedlichen Datenquellen einen Sinn schaffen? Woher wissen sie, welche Daten sie sammeln und wie sie sie speichern sollen?
Die Antwort liegt in der effizienten Datenmodellierung - einer Technik, die es Entwicklern ermöglicht, ihr Datenverwaltungssystem zu visualisieren. Sie hilft ihnen zu verstehen, welche Daten sie sammeln müssen und wie sie kritische Beziehungen zwischen verschiedenen Quellen identifizieren können. Dieser Prozess ermöglicht es Entscheidungsträgern, relevante Datensätze für eine effektive Entscheidungsfindung zu identifizieren.
In diesem Beitrag werden die Datenmodellierung, ihre Funktionsweise, Techniken, Prozesse, Vorteile und Herausforderungen sowie die Tools erläutert, die Ihnen bei der Rationalisierung der Modellierungsabläufe helfen können.
Was ist Datenmodellierung?
Bei der Datenmodellierung wird eine Blaupause erstellt, die die Datenstruktur einer Anwendung oder eines Systems darstellt. Das Datenmodell ist ein Diagramm, das die relevanten Dateneinheiten, Objekte, Beziehungen und komplexen Schemata für die Speicherung veranschaulicht.
Das Datenmodell legt auch Datendefinitionen, Glossare und andere wichtige Metadaten fest, damit mehrere Beteiligte aussagekräftige Erkenntnisse für bestimmte Anwendungsfälle gewinnen können. Zu den Beteiligten können Datenanalysten, Entwickler und Administratoren gehören, die Datenquellen analysieren, organisieren und den Zugriff darauf verwalten.
Eine effiziente Datenmodellierung gewährleistet die effektive Nutzung von Datenbeständen in verschiedenen Teams, indem sie ein gemeinsames Verständnis von Daten fördert, Datenredundanzen beseitigt und administrative Hürden minimiert. Sie ermöglicht es Unternehmen außerdem, potenzielle Hindernisse und Designbeschränkungen zu identifizieren und zu beseitigen, um ein skalierbares Datenverwaltungssystem aufzubauen.
Wie funktioniert Datenmodellierung?
Die Techniken zur Erstellung eines Datenmodells können zwar von Fall zu Fall variieren, umfassen aber im Allgemeinen die Entwicklung eines konzeptionellen Entwurfs, eines logischen Rahmens und eines physischen Modells.
Konzeptioneller Entwurf
Der konzeptionelle Entwurf ist eine Abstraktion, die die gesamte Datenstruktur visualisiert. Er identifiziert den Projektumfang und legt die Anforderungen für die Erstellung des Systems auf hoher Ebene fest.
Das konzeptionelle Modell bildet auch die relevanten Dateneinheiten, Beziehungen, Integrationen und Sicherheitsprotokolle für Business-Analytics-Aufgaben ab. Das folgende Diagramm zeigt zum Beispiel ein einfaches konzeptionelles Modell eines Vertriebsdatenbanksystems.
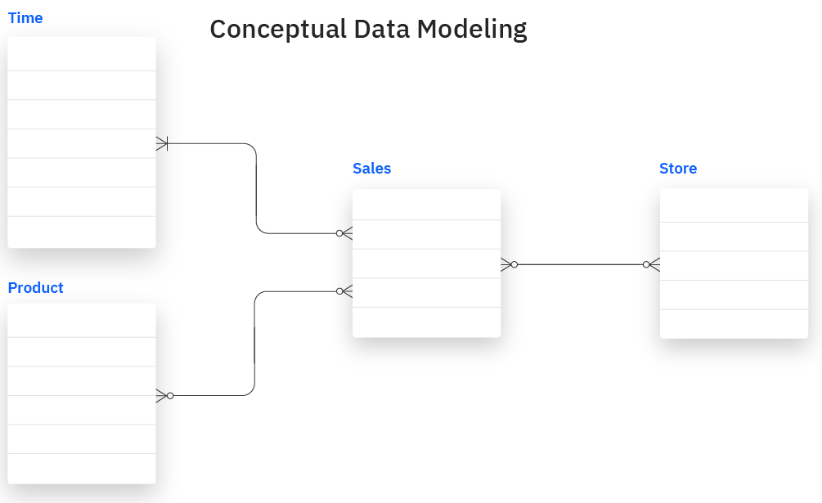 Konzeptuelles Modell.png
Konzeptuelles Modell.png
Ziel ist es, den Datenbedarf von Führungskräften zu decken und ihnen zu helfen, wichtige Datenelemente und -beziehungen zu erkennen, um effektive datengestützte Entscheidungen zu treffen.
Logischer Rahmen
Das logische Framework bietet mehr Details, indem es Datentypen, eindeutige Bezeichner und Definitionen enthält. Er verwendet formale Datennotationen zur Kennzeichnung von Entitätsbeziehungen und ermöglicht es den Benutzern, Datenattribute und Beziehungen klarer zu visualisieren.
Das logische Gerüst für eine Vertriebsdatenbank kann beispielsweise die Primärschlüssel enthalten, die die Produkt- und Vertriebstabellen miteinander verbinden.
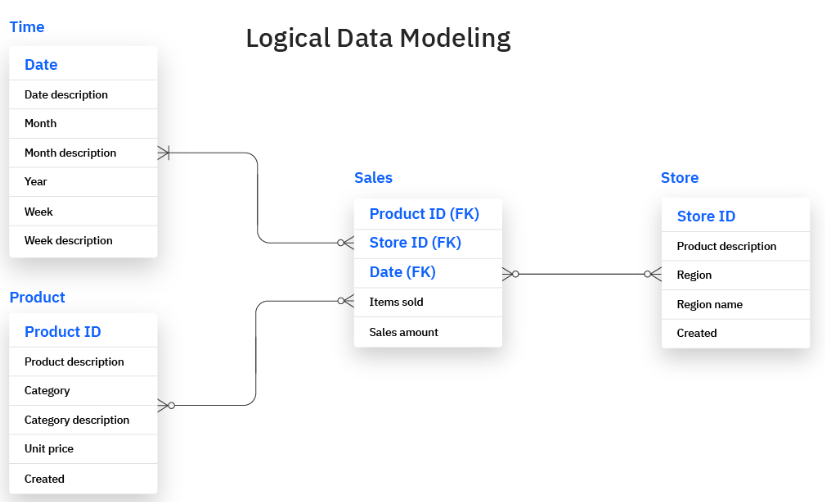 Logisches Gerüst.png
Logisches Gerüst.png
Das logische Modell hilft den Benutzern auch dabei, die Art der in jeder Dateneinheit benötigten Informationen und die Regeln für die Implementierung der Datenstrukturen zu bestimmen.
Physisches Datenmodell
Das physische Datenmodell ist die letzte und detaillierteste Darstellung eines datengesteuerten Systems. Es enthält ein detailliertes Schema, das beschreibt, wie das System die Datenbestände speichern wird.
So besteht das physische Datenmodell in einem relationalen Datenbanksystem aus den Namen der einzelnen Tabellen, Spalten und den entsprechenden Datentypen.
 Physisches Datenmodell.png
Physisches Datenmodell.png
Physikalische Modelle sind systemspezifisch und ändern sich je nach Art des Modells, das Sie zu erstellen versuchen. Im folgenden Abschnitt werden die verschiedenen Datenmodelltypen näher erläutert.
Arten von Datenmodellen
Im Laufe der Zeit sind mit den wachsenden Datenmengen immer komplexere Datenbankmanagementsysteme (DBMS) entstanden. Die Vielfalt der DBMS-Architekturen hat zu einer Vielzahl von Datenmodellen geführt, die Unternehmen dabei helfen, ihre Verwaltungssysteme effizienter zu gestalten.
Während sich die Modelltypen immer noch weiterentwickeln, gehören zu den beliebtesten Typen hierarchische, relationale, Entity-Relationship-, objektorientierte und dimensionale Datenmodelle.
Hierarchische Datenmodelle
Das hierarchische Datenmodell organisiert Daten in einer eins-zu-viele-Baumstruktur mit einem einzigen übergeordneten Datensatz, der mit mehreren untergeordneten Datensätzen verbunden ist.
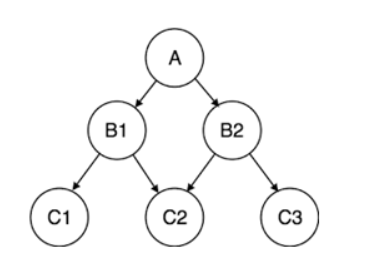 Hierarchisches Modell.png
Hierarchisches Modell.png
Das IBM Information Management System (IMS) war das erste System, das die 1966 eingeführte hierarchische Struktur verwendete. Obwohl das Modell heute selten ist, wird es immer noch für die Organisation von Daten in Extensible Markup Language (XML)-Dateien und geografischen Informationssystemen (GIS) verwendet.
Relationale Datenmodelle
Relationale Datenmodelle, die 1970 von dem IBM-Forscher Edgar F. Codd eingeführt wurden, sind vielseitiger als hierarchische Strukturen. Sie organisieren Daten in Tabellen mit Zeilen und Spalten, was die Erkennung mehrerer Datenelemente und Beziehungen erleichtert.
| ID | Name | Adresse |
| 125 | Name 1 | Adresse 1 |
| 236 | Name 2 | Adresse 2 |
Tabelle: Relationales Modell
Relationale Modelle ermöglichen es Benutzern, mehrere Tabellen auf der Grundlage von Primärschlüsseln zu verbinden und die Datenkomplexität zu verringern. Die strukturierte Abfragesprache (SQL) wird hauptsächlich zur Bearbeitung und Analyse von Daten in relationalen Datenbanken verwendet.
Entity-Relationship-Datenmodelle
Entity-Relationship (ER)-Modelle ordnen Datenattribute nach Entitäten und bilden Beziehungen zwischen mehreren Entitäten ab.
In einem DBMS für den Vertrieb ist ein Kunde beispielsweise eine Entität, deren Attribute den Namen, die Adresse, die Kontaktdaten und andere Merkmale des Kunden umfassen können. Die Entität "Kunde" kann über die Artikel, die ein bestimmter Kunde gekauft hat, mit der Entität "Produkt" in Beziehung stehen.
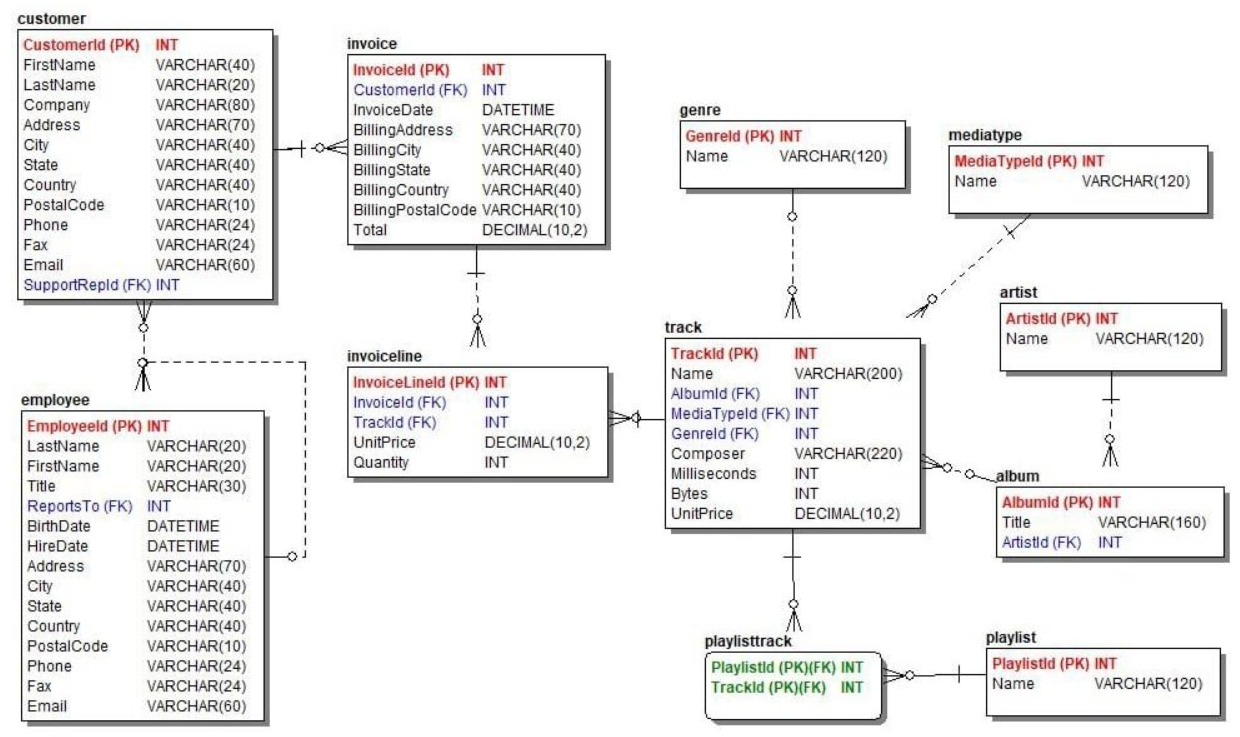 ER Model.png
ER Model.png
Die Struktur ist dynamischer als relationale Modelle, da sie dabei hilft, transaktionsbasierte Daten effizienter zu erfassen und zu analysieren.
Objektorientierte Datenmodelle
Objektorientierte Datenmodelle sind mit der objektorientierten Programmierung populär geworden, bei der Datenobjekte nach ihren Attributen organisiert werden.
Datenobjekte mit ähnlichen Attributen werden in Klassen gruppiert. Programmierer können neue Klassen erstellen, die die Attribute früherer Klassen erben können.
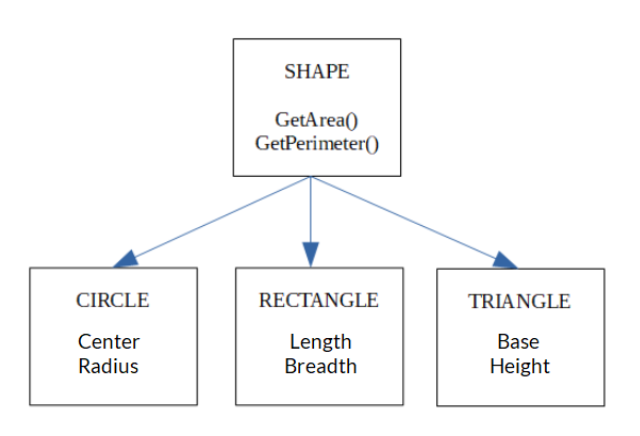 Objektorientiertes Datenmodell- .png
Objektorientiertes Datenmodell- .png
Objektorientiertes Datenmodell: Die Objekte CIRCLE, RECTANGLE und TRIANGLE erben vom SHAPE __Objekt. Jede Form hat ihre Attribute.
In einem objektorientierten Datenmodell können beispielsweise Kunden- und Mitarbeiterdaten zur selben Klasse gehören, da sie identische Attribute wie Name, Adresse und Kontaktinformationen haben. Dies unterscheidet sich von ER-Modellen, bei denen Kunden und Mitarbeiter getrennte Entitäten sind.
Dimensionale Datenmodelle
In dimensionalen Datenmodellen werden Dateneinheiten als Dimensionen organisiert, die mit Factsheets verbunden sind und die Analyse in Data Warehouses und Marts verbessern. Ein Factsheet enthält Daten zu Ereignissen, während Dimensionen Informationen zu den Entitäten enthalten, die in diesen Ereignissen vorkommen.
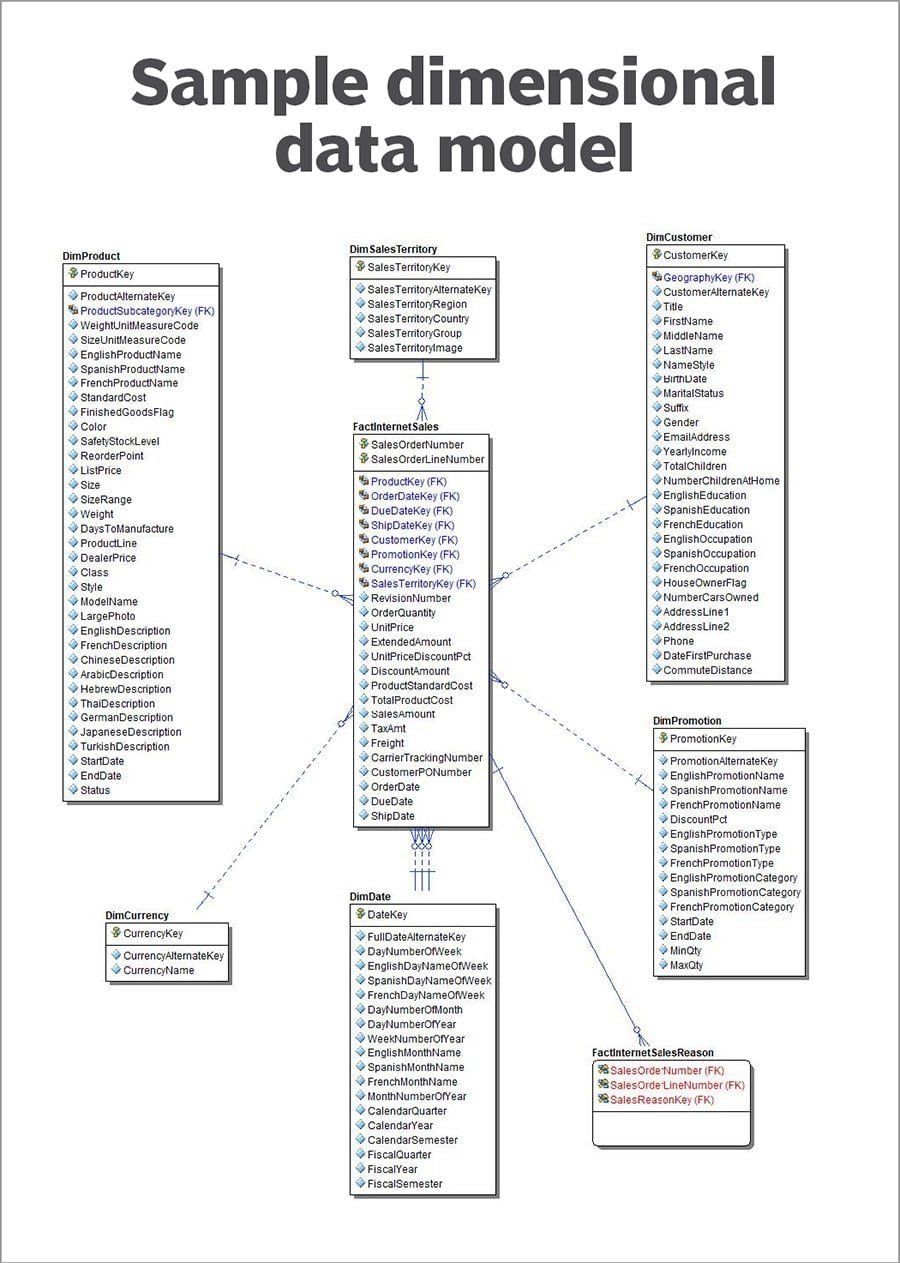 Dimensionales Datenmodell- .jpg
Dimensionales Datenmodell- .jpg
Dimensionales Datenmodell_: Das Absatzdatenblatt bezieht sich auf mehrere Dimensionen von Entitäten, die in ihm vorkommen.
Ein Informationsblatt kann beispielsweise eine Tabelle sein, in der die täglichen Transaktionen mehrerer Kunden aufgezeichnet werden. Die Benutzer können jedoch weitere Informationen zu jedem Kunden oder Produkt in Dimensionstabellen finden, in denen kundenbezogene oder Produktdaten gespeichert sind.
Das Sternschema ist eine bekannte dimensionale Datenstruktur, bei der ein einzelnes Factsheet mit mehreren Dimensionen verbunden ist. Eine komplexere Variante ist die Schneeflockenstruktur, bei der zahlreiche Dimensionstabellen mit verschiedenen Datenblättern verbunden sind.
Vergleich mit Datenbankdesign und Data Engineering
Obwohl Datenbankdesign und Data Engineering ähnliche Konzepte sind, unterscheiden sie sich in einigen Punkten von der Datenmodellierung.
Datenmodellierung versus Datenbankdesign: Die Datenmodellierung ist die erste Phase beim Aufbau einer Datenbank. Das Datenbankdesign ist ein weniger abstrakter Prozess, der die Anforderungen für die Implementierung des Datenmodells festlegt. Die Entwickler überlegen, welche Datenbankstruktur am besten geeignet ist, um Skalierbarkeit und Datenintegrität zu verbessern. Dies kann z. B. die Wahl von Primärschlüsseln, Indexierungstechniken und Schemadesign umfassen.
Datenmodellierung versus Data Engineering: Data Engineering ist ein breiteres Konzept, das die Entwicklung automatisierter Datenpipelines zur Verarbeitung, Umwandlung und Verschiebung von Daten zwischen verschiedenen Plattformen umfasst. Ein effizientes Datenmodell kann beim Aufbau eines robusten Datenbankdesigns helfen und die Entwickler bei der Rationalisierung von Data-Engineering-Workflows unterstützen.
Datenmodellierungsprozess
Der Entwurf eines Datenmodells erfordert den Beitrag mehrerer Beteiligter, um den Umfang, die Ziele und die Ressourcenbeschränkungen des Datenbanksystems zu verstehen.
Datenexperten müssen den geeigneten Datenmodelltyp auswählen, um die für einen bestimmten Anwendungsfall erforderliche Datenstruktur darzustellen. Sie müssen auch die relevanten Symbole und Notationskonventionen für die Konstruktion des Modells festlegen.
Obwohl die Arbeitsabläufe bei der Datenmodellierung je nach Geschäftsanforderungen und Art der Daten unterschiedlich sein können, bietet die folgende Liste einige Schritte für den Entwurf eines Modells.
Entitätsidentifizierung: Der erste Schritt ist die Identifizierung der relevanten Entitäten, die die Daten enthalten müssen. Die Entitäten müssen sich gegenseitig ausschließen und sollten die Grundlage für den konzeptionellen Entwurf des Modells bilden.
Attribut-Identifikation: Die Entwickler müssen die eindeutigen Attribute für jede Entität identifizieren. In einer Datenbank mit Bankdaten von Kunden kann z. B. "Bankkonten" eine separate Entität mit eindeutigen Attributen wie Art des Kontos, Kontonummer, Erstellungsdatum, ursprünglicher Einzahlungsbetrag usw. sein.
Beziehung zwischen Entitäten: Bilden Sie die Beziehungen zwischen mehreren Entitäten ab. Zum Beispiel kann die Entität "Bankkonto" mit der Entität "Kunde" in Beziehung stehen, wobei jeder Kunde ein weiteres Konto hat.
Zuweisung von Primärschlüsseln: Die Entwickler müssen den Entitäten eindeutige Schlüssel zuweisen, um ihre Beziehungen formal darzustellen. So kann beispielsweise die Kontonummer ein Primärschlüssel sein, der die Entität "Kunden" mit der Entität "Bankkonten" verknüpft.
Erstellung und Fertigstellung des Datenmodells: Nachdem alle relevanten Entitäten, Attribute und Beziehungen mit Primärschlüsseln identifiziert wurden, können die Entwickler das geeignete Datenmodell bestimmen und das Design fertigstellen, das die Datenanforderungen des Unternehmens am besten erfüllt.
Vorteile der Datenmodellierung
Ein Datenmodell ist das Rückgrat eines effektiven Datenmanagementsystems. Es ermöglicht mehreren Beteiligten, Datenbestände zu nutzen, um wertvolle Erkenntnisse für die strategische Entscheidungsfindung zu gewinnen.
In der folgenden Liste sind einige Vorteile eines effektiven Datenmodells aufgeführt.
Bessere Kommunikation: Ein Datenmodell hilft dabei, den Datenfluss und die Konzepte den relevanten Interessengruppen leichter zu vermitteln.
Konsistente Dokumentation: Da das Datenmodell eine standardisierte Visualisierung der gesamten Datenstruktur bietet, ist die Dokumentation konsistenter und ermöglicht einen robusteren Systementwurf.
Verbesserte teamübergreifende Zusammenarbeit: Mit einem gemeinsamen Datenverständnis können Teams aus verschiedenen Bereichen effektiver an Projekten zusammenarbeiten.
Bessere Datenqualität: Ein gut konzipiertes Modell gewährleistet die Datenintegrität über verschiedene Datenquellen hinweg und ermöglicht den Benutzern die Entwicklung schneller und effizienter Datenanalyse-Workflows.
Herausforderungen bei der Datenmodellierung
Die Datenmodellierung bietet zwar zahlreiche Vorteile, birgt aber auch einige Herausforderungen bei der Implementierung. Wenn Sie diese Hürden verstehen und wissen, wie Sie sie überwinden können, können Unternehmen die Vorteile der Datenmodellierung schneller nutzen.
Nachfolgend sind einige Herausforderungen aufgeführt, mit denen Entwickler beim Entwurf eines Datenmodells konfrontiert werden können.
Ansteigende Datenkomplexität: Moderne DBMS müssen dynamisch sein und den sich ändernden Geschäftsanforderungen sowie der zunehmenden Datenvielfalt gerecht werden. Die Vorhersage künftiger Änderungen ist jedoch komplex und erfordert erhebliche Spekulationen. Die Zerlegung von Modellen in kleinere Komponenten und die Verwendung von Industriestandards können dazu beitragen, solche Probleme zu entschärfen.
Einbindung des Führungsteams: Das Führungsteam von den Vorteilen eines Datenmodells zu überzeugen, kann mühsam sein. Die Diskussion kann für Geschäftsanwender zu abstrakt werden. Um Unterstützung zu erhalten, müssen Datenteams mit klaren Zielen und Vorgaben an die Unternehmensleitung herantreten, die sich an der allgemeinen Mission und Vision des Unternehmens orientieren.
Ändernde Anforderungen: Die Entwicklung eines Datenmodells ist ein iterativer Prozess, der Änderungen des Umfangs und der Ziele erfordern kann. Häufige Änderungen können jedoch dazu führen, dass der Entwurf aus der Bahn gerät und die Entwicklungskosten steigen. Die Identifizierung und Einbeziehung relevanter Interessengruppen von Anfang an und die Einholung regelmäßiger Rückmeldungen können helfen, diese Probleme zu überwinden.
Tools für die Datenmodellierung
Entwickler können Datenmodellierungstools verwenden, um schnell effizientere Entwürfe zu erstellen. Es gibt zwar mehrere Anbieter von Datenmodellierungslösungen, aber die Auswahl der für Ihr Unternehmen am besten geeigneten Lösung erfordert Zeit und Mühe. In der folgenden Liste sind einige beliebte Tools aufgeführt, die Ihnen die Suche erleichtern können.
Erwin Data Modeler: Hilft bei der Erstellung detaillierter Schemata und Designvisualisierungen, die mehrere Datenbanksysteme unterstützen. Es verfügt über ein Versionskontrollsystem und ermöglicht es den Benutzern, Datenmodelle aus bestehenden Datenstrukturen umzukehren.
DbSchema: Verfügt über eine intuitive Benutzeroberfläche, die es Benutzern ermöglicht, mit Datenmodellen zu interagieren und Abfragen visuell zu erstellen, ohne Code zu verwenden.
ER/Studio: Unterstützt mehrere Datenbanksysteme, einschließlich relationaler und dimensionaler Strukturen. Bietet Tools für die Zusammenarbeit, die es Teams ermöglichen, Daten durch Aktivitäts- und Diskussionsströme besser zu verstehen.
FAQs zur Datenmodellierung
- Was ist der Unterschied zwischen Datenmodellierung und Datenbankdesign?
Die Datenmodellierung bezieht sich auf die Identifizierung von Dateneinheiten, Attributen und Beziehungen zwischen verschiedenen Einheiten. Sie hilft bei der Erstellung der Gesamtstruktur, wie eine Datenbank diese Entitäten speichern wird und wie Benutzer die Beziehungen zur Durchführung von Analysen nutzen können.
Das Datenbankdesign kommt nach der Fertigstellung des Datenmodells und beinhaltet die Implementierung des Datenmodells in einem Datenbankmanagementsystem (DBMS). Dazu gehören Indexierungstechniken, Schemanamen und Speicherstrukturen.
- Was ist Normalisierung in der Datenmodellierung?
Bei der Normalisierung werden Daten in Gruppen organisiert, um Redundanzen zu beseitigen und die Datenkonsistenz zu verbessern. Betrachten Sie zum Beispiel die folgende Tabelle in einem relationalen DBMS:
| Kunde | Gekaufter Artikel | Preis |
| A | Telefon | $200 |
| B | Computer | $1500 |
| C | Ladegerät | $50 |
| D | Telefon | $200 |
Hier wird der Benutzer den Preis eines Artikels entfernen, wenn er den Datensatz eines bestimmten Kunden löschen möchte. Die Normalisierung trennt Kundendaten von Preisinformationen, indem sie zwei Tabellen erstellt.
Durch diesen Prozess wird sichergestellt, dass die Daten konsistent bleiben und der Benutzer die Daten flexibler bearbeiten kann, ohne die Gesamtstruktur der Informationen zu verändern.
- Wie werden Datenmodelle für unstrukturierte Daten entworfen?
Zu den [unstrukturierten Daten] (https://zilliz.com/glossary/unstructured-data) gehören Bild-, Video- und Textdaten. Modelle für unstrukturierte Datensätze erfordern andere Techniken, da ihre Darstellung komplexer ist als bei herkömmlichen Schemata.
Entwickler können Vektordatenbanken verwenden, um Datenmodelle für unstrukturierte Datensätze zu speichern und zu entwickeln. Die Datenbanken verwenden Algorithmen der künstlichen Intelligenz (KI), um Datenproben in Einbettungen, vektorisierte Darstellungen jedes Datenpunkts, umzuwandeln. Jedes Element des Vektors entspricht einem bestimmten Attribut der Datenprobe.
Sobald die Stichproben in Vektorform vorliegen, können Benutzer Ähnlichkeitsmetriken berechnen, um die Ähnlichkeit zwischen verschiedenen Datenpunkten zu bewerten. Anhand der Ähnlichkeitswerte können sie die Daten in Gruppen einteilen und Modelle entwickeln, die die Beziehungen zwischen ihnen darstellen.
- Welche häufigen Fehler sind bei der Datenmodellierung zu vermeiden?
Die Entwickler verkomplizieren das Modell oft zu sehr und versäumen es, die relevanten Interessengruppen in der Entwurfsphase einzubeziehen. Auch die Aufnahme unnötiger Dateneinheiten und die Nichtberücksichtigung von Leistungsbeschränkungen sind häufige Fehler, die die Effizienz des Datenmodells beeinträchtigen.
- Wie wählt man das richtige Datenmodellierungstool aus?
Bei der Investition in eine Datenmodellierungslösung müssen Sie die folgenden Faktoren berücksichtigen:
Benutzerfreundlichkeit
Unterstützte Datenbanksysteme
Visualisierungsfunktionen
Werkzeuge für die Zusammenarbeit
Skalierbarkeit
Preis
Verwandte Ressourcen
Weitere Informationen über die Verwaltung unstrukturierter Daten und Modellierungstechniken finden Sie in den folgenden Artikeln.
Einführung in unstrukturierte Daten](https://zilliz.com/learn/introduction-to-unstructured-data)
Was ist eine Vektordatenbank, und wie funktioniert sie?](https://zilliz.com/learn/what-is-vector-database)
Verständnis von Vektordatenbanken](https://zilliz.com/learn/comparing-vector-database-vector-search-library-and-vector-search-plugin)
Datenmodellierungstechniken für Vektordatenbanken](https://zilliz.com/learn/data-modeling-techniques-optimized-for-vector-databases)
- Was ist Datenmodellierung?
- Wie funktioniert Datenmodellierung?
- Arten von Datenmodellen
- Dimensionale Datenmodelle
- Vergleich mit Datenbankdesign und Data Engineering
- Datenmodellierungsprozess
- Vorteile der Datenmodellierung
- Herausforderungen bei der Datenmodellierung
- Tools für die Datenmodellierung
- FAQs zur Datenmodellierung
- Verwandte Ressourcen
Inhalte
Kostenlos starten, einfach skalieren
Testen Sie die vollständig verwaltete Vektordatenbank, die für Ihre GenAI-Anwendungen entwickelt wurde.
Zilliz Cloud kostenlos ausprobieren