




Agentic RAG: Intelligentere KI-Abrufsysteme mit autonomen Agenten
Agentic RAG: Intelligentere KI-Abrufsysteme mit autonomen Agenten
Stellen Sie sich einen Forschungsassistenten vor, der nicht einfach nur eine Datenbank durchsucht, wenn Sie eine Frage stellen, sondern intelligent entscheidet, welche Quellen konsultiert werden sollen, die gefundenen Informationen validiert und bei Bedarf sogar Ihre Frage umformuliert, um bessere Ergebnisse zu erzielen. Genau das bringt agentic RAG in Systeme der künstlichen Intelligenz.
Während traditionelle Retrieval-Augmented Generation (RAG)-Systeme die Art und Weise, wie KI-Anwendungen auf externes Wissen zugreifen, erheblich verbessert haben, funktionieren sie wie ein eindimensionales Denken, beschränkt auf eine Wissensquelle und einen einzigen Abrufversuch. Agentic RAG verwandelt diesen linearen Ansatz in ein intelligentes, adaptives System, das über mehrere Informationsquellen hinweg denken, planen und handeln kann, um genauere und umfassendere Antworten zu liefern.
Was ist Agentic RAG?
Agentic RAG ist eine erweiterte Implementierung von Retrieval-Augmented Generation, die KI-Agenten einbezieht, um komplexe Workflows für Informationsabruf und Generierung zu orchestrieren. Im Gegensatz zu traditionellen RAG-Systemen, die einer festen Abfolge von Abruf und Generierung folgen, setzt agentic RAG intelligente Agenten ein, die in der Lage sind, zu schlussfolgern, zu planen und Entscheidungen darüber zu treffen, wie Benutzeranfragen am besten beantwortet werden.
Im Kern nutzt agentic RAG KI-Agenten, um Retrieval-Augmented Generation zu ermöglichen, die RAG-Pipeline mit Anpassungsfähigkeit und Genauigkeit zu verbessern und gleichzeitig großen Sprachmodellen zu ermöglichen, Informationsabruf aus mehreren Quellen durchzuführen und komplexere Workflows zu bewältigen.
Diese Systeme verwandeln LLMs in KI-Agenten und befähigen sie, Tools, Funktionen und externe Wissensquellen zu nutzen, wodurch ein anspruchsvollerer Ansatz zur Informationsverarbeitung entsteht als bei Standard-RAG-Implementierungen.
Hauptmerkmale von Agentic RAG
Multi-Source Intelligence: Das System kann eine Verbindung zu mehreren Datenbanken herstellen, einschließlich Vektordatenbanken wie Milvus und Zilliz Cloud, sowie traditionellen SQL-Datenbanken. Agenten können je nach Anforderungen der Anfrage gleichzeitig auf interne Dokumente, externe APIs, Websuchen und spezialisierte Datenbanken zugreifen.
Adaptive Query Processing: KI-Agenten können auf vorherigen Prozessen iterieren, um Ergebnisse im Laufe der Zeit zu optimieren. Wenn anfängliche Ergebnisse unzureichend sind, können Agenten Anfragen umformulieren, verschiedene Quellen ausprobieren oder komplexe Fragen in überschaubare Teilanfragen aufteilen.
Intelligente Planung und Orchestrierung: Agenten in diesem Ansatz können Aufgaben planen und durchdenken, die mehrere Schritte und logisches Schlussfolgern erfordern. Ein Koordinator-Agent kann spezialisierten Abrufagenten Aufgaben zuweisen, die jeweils für bestimmte Datentypen oder Domänen optimiert sind.
Qualitätsvalidierung: Im Gegensatz zu traditionellen Systemen enthält agentic RAG integrierte Mechanismen zur Bewertung abgerufener Inhalte. KI-Agenten können auf vorherigen Prozessen iterieren, um Ergebnisse im Laufe der Zeit zu optimieren. Diese Validierungsebene reduziert Halluzinationen erheblich und verbessert die Antwortgenauigkeit.
Tool-Integration: Abrufagenten mit Zugriff auf verschiedene Retriever-Tools, wie zum Beispiel: Vektorsuchmaschine (auch Query Engine genannt), die eine Vektorsuche über einen Vektorindex durchführt (wie in typischen RAG-Pipelines), Websuche, Rechner, jede API für den programmgesteuerten Zugriff auf Software, wie E-Mail- oder Chatprogramme, ermöglichen eine umfassende Informationsbeschaffung über den einfachen Dokumentenabruf hinaus.
Wie funktioniert Agentic RAG
Agentic RAG arbeitet über eine ausgeklügelte Architektur, die mehrere KI-Agenten mit fortgeschrittenen Schlussfolgerungsfähigkeiten kombiniert. So verarbeitet das System Anfragen von Anfang bis Ende:
Schritt-für-Schritt-Workflow
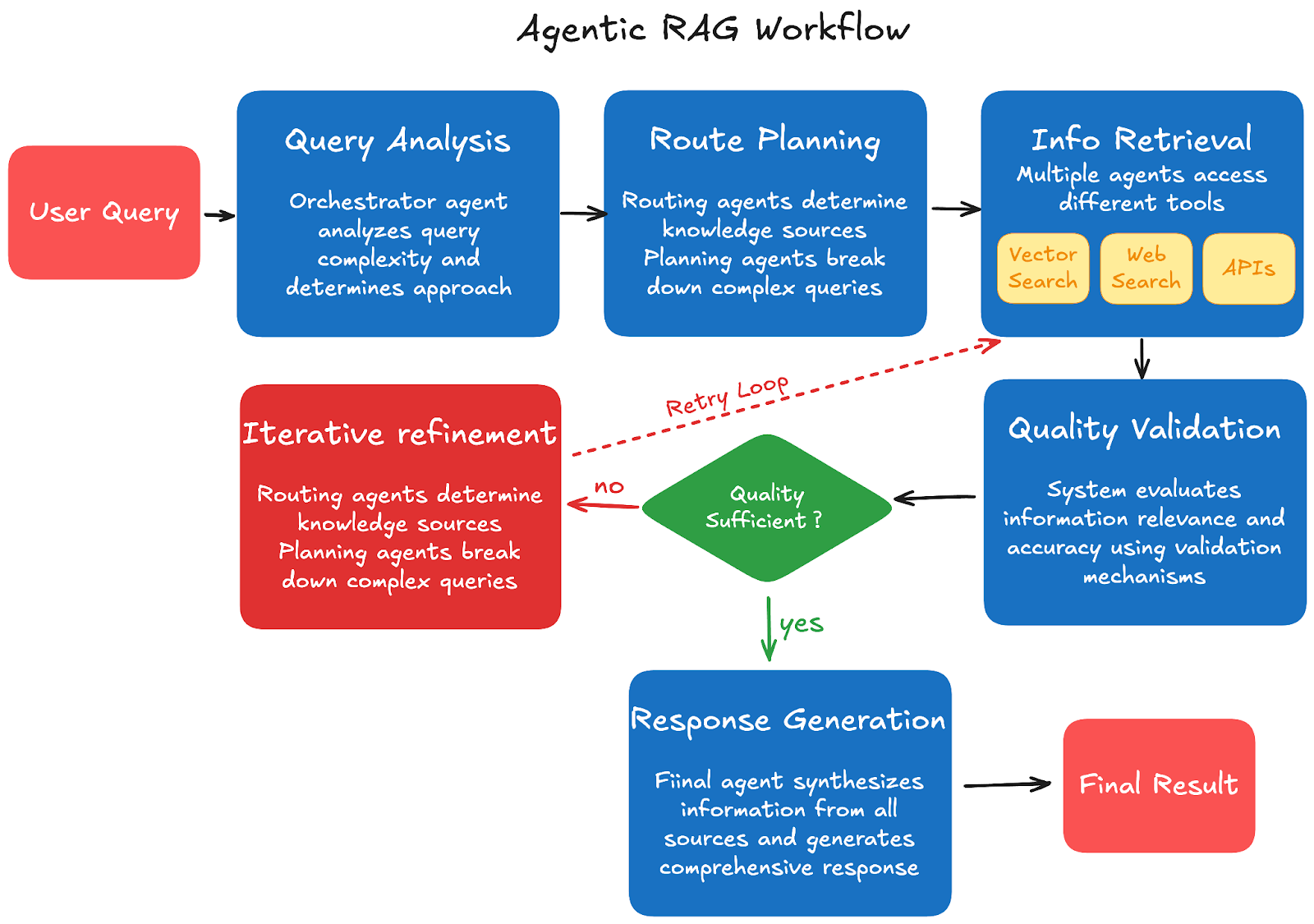
Schritt 1: Anfrageanalyse: Der Benutzer übermittelt eine Anfrage an den primären Orchestrator-Agenten, der die Komplexität der Anfrage analysiert und den erforderlichen Ansatz bestimmt. Das System entscheidet anhand des Umfangs und der Komplexität der Anfrage, ob ein einzelner oder mehrere Abrufschritte erforderlich sind.
Schritt 2: Routenplanung: Routing-Agenten bestimmen, welche externen Wissensquellen und Tools verwendet werden sollen, während Query-Planning-Agenten komplexe Anfragen in handhabbare Teilaufgaben zerlegen. Das System erstellt auf Grundlage verfügbarer Ressourcen und des effizientesten Wegs zur Sammlung umfassender Informationen einen Ausführungsplan.
Schritt 3: Informationsabruf: Retrieval-Agenten greifen basierend auf dem Ausführungsplan auf verschiedene Tools zu, darunter Vektorsuchmaschinen für Dokumentdatenbanken, Websuche für aktuelle Informationen, APIs für spezifische Software- oder Servicedaten und Rechner für rechnerische Aufgaben. Mehrere Agenten können gleichzeitig über verschiedene Quellen hinweg arbeiten, um Effizienz und Abdeckung zu maximieren.
Schritt 4: Qualitätsvalidierung: Das System bewertet abgerufene Informationen mithilfe integrierter Validierungsmechanismen auf Relevanz und Genauigkeit. Wenn Inhalte unzureichend oder irrelevant sind, formulieren Agenten Anfragen neu, und Validierungsmechanismen prüfen die Konsistenz über mehrere Quellen hinweg, um eine zuverlässige Informationsqualität sicherzustellen.
Schritt 5: Iterative Verfeinerung: Das System bestimmt anhand der Qualität und Vollständigkeit der gesammelten Informationen, ob zusätzlicher Abruf erforderlich ist. Agenten können mit verfeinerten Suchbegriffen erneut Abfragen durchführen, und dieser Prozess wiederholt sich, bis Informationen von ausreichender Qualität gesammelt wurden, um eine umfassende Antwort zu liefern.
Schritt 6: Antwortgenerierung: Der abschließende Agent synthetisiert Informationen aus allen Quellen zu einer kohärenten Antwort. Er generiert umfassende Antworten unter Verwendung validierten Kontexts und stellt, sofern zutreffend, Zitationen und Quellenangaben bereit, um Transparenz und Glaubwürdigkeit zu wahren.
Agententypen und Rollen
Routing-Agenten: Bestimmen, welche externen Wissensquellen und Tools verwendet werden, um Nutzeranfragen zu beantworten
Query-Planning-Agenten: Verarbeiten komplexe Anfragen und zerlegen sie in schrittweise Prozesse
ReAct-Agenten: Kombinieren Denk- und Handlungsfähigkeiten für eine dynamische Anpassung des Workflows
Plan-and-Execute-Agenten: Bearbeiten mehrstufige Workflows unabhängig, ohne ständige Koordination
 Agentic RAG workflow.png
Agentic RAG workflow.png
Vorteile und Herausforderungen von Agentic RAG
Agentic RAG bietet gegenüber traditionellen Ansätzen erhebliche Vorteile, bringt jedoch einige betriebliche Überlegungen mit sich.
Vorteile
Erhöhte Genauigkeit: Multi-Source-Validierung und Querverweise reduzieren Halluzinationen erheblich und verbessern die Zuverlässigkeit der Antworten. Die Fähigkeit des Systems, Informationen über mehrere Wissensdatenbanken hinweg zu verifizieren, schafft einen robusten Fact-Checking-Mechanismus, den traditionelles RAG nicht erreichen kann.
Multi-Source-Integration: Der Zugriff auf vielfältige Wissensdatenbanken, APIs und externe Tools ermöglicht eine umfassende Informationssammlung aus strukturierten Datenbanken, Websuchen, Rechnern und spezialisierter Software. Diese Vielseitigkeit ermöglicht es dem System, komplexe Anfragen zu bearbeiten, die Informationen aus mehreren Domänen erfordern.
Iterative Verfeinerung: Die kontinuierliche Verbesserung der Antwortqualität durch mehrere Abruf- und Validierungszyklen stellt sicher, dass suboptimale Anfangsergebnisse verbessert werden können. Das System lernt aus jeder Iteration, formuliert Anfragen neu und verbessert Suchstrategien, bis eine zufriedenstellende Informationsqualität erreicht ist.
Adaptive Problemlösung: Proaktiver Ansatz für komplexe Anfragen mit intelligentem Routing und dynamischer Workflow-Anpassung. Das System kann autonom die beste Abrufstrategie bestimmen, sich an veränderte Kontexte anpassen und unerwartete Szenarien bewältigen, ohne manuelle Eingriffe oder umfangreiches Prompt Engineering zu erfordern.
Herausforderungen
Höhere Kosten: Mehr Agenten und iterative Prozesse erfordern größere Rechenressourcen und Token-Nutzung, wodurch die Betriebskosten im Vergleich zu traditionellem RAG potenziell um das 2- bis 3-Fache steigen. Die Multi-Agenten-Architektur erfordert mehr API-Aufrufe, längere Verarbeitungszeiten und zusätzliche Infrastruktur zur Unterstützung komplexer Workflows.
Erhöhte Latenz: Mehrere Agenteninteraktionen, Validierungsschritte und potenzielle Iterationszyklen können die Antwortzeiten erheblich verlangsamen. Komplexe Abfragen können mehrere Runden der Abfrage und Verfeinerung erfordern, wodurch das System weniger geeignet für Echtzeitanwendungen ist, die sofortige Antworten verlangen.
Zuverlässigkeitsprobleme: Agenten können Schwierigkeiten haben oder daran scheitern, komplexe Aufgaben abzuschließen, wodurch Fehlerpunkte im Workflow entstehen. Die Koordination zwischen mehreren Agenten kann instabil werden und zu unvollständigen Antworten, Endlosschleifen oder widersprüchlichen Entscheidungen führen, die ausgefeilte Mechanismen zur Fehlerbehandlung erfordern.
Integrationskomplexität: Die Verbindung unterschiedlicher Tools, Wissensquellen und die Verwaltung der Multi-Agenten-Koordination erfordern eine ausgefeilte Orchestrierung und umfangreiche Tests. Die Systemarchitektur wird deutlich komplexer als bei traditionellem RAG und erfordert spezialisiertes Fachwissen für Bereitstellung, Wartung und Fehlerbehebung.
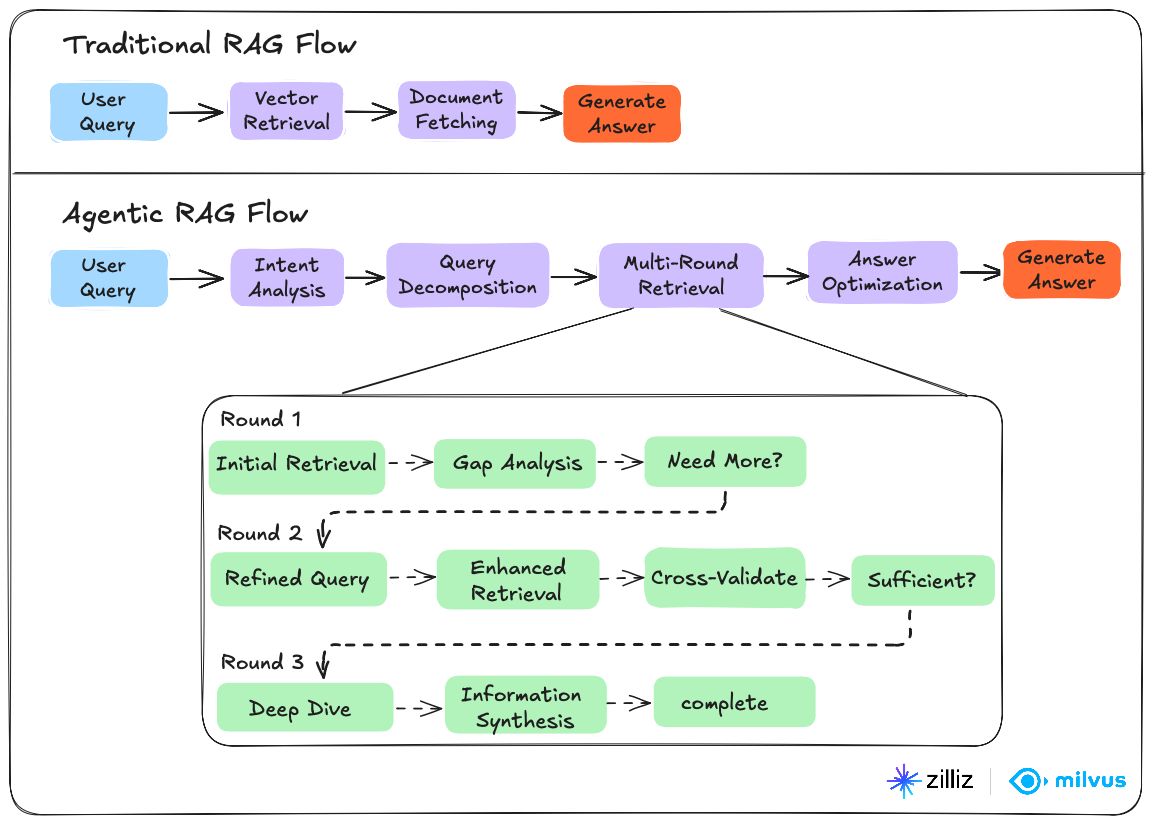
Vergleich von Agentic RAG mit traditionellem RAG
 Agentic RAG vs Traditional RAG.jpg
Agentic RAG vs Traditional RAG.jpg
| Funktion | Traditionelles RAG | Agentic RAG |
|---|---|---|
| Datenquellen | Einzelne Wissensdatenbank | Mehrere Quellen und externe Tools |
| Abfrageverarbeitung | Einmalige Abfrage | Mehrstufiger, iterativer Ansatz |
| Validierung | Keine integrierte Validierung | Automatisierte Qualitätsbewertung |
| Anpassungsfähigkeit | Statisch, regelbasiert | Dynamische, intelligente Entscheidungsfindung |
| Tool-Zugriff | Auf Vektordatenbank beschränkt | APIs, Websuche, Rechner, externe Dienste |
| Planungsfähigkeit | Einfaches Abrufen und Generieren | Komplexes Schlussfolgern und Aufgabenzerlegung |
| Fehlerbehandlung | Manueller Eingriff erforderlich | Selbstkorrektur- und Wiederholungsmechanismen |
| Skalierbarkeit | Durch einzelne Quelle begrenzt | Skaliert mit zusätzlichen Agenten und Quellen |
| Kosten | Geringere Token-Nutzung | Höherer Rechenaufwand |
| Antwortgeschwindigkeit | Schnellere erste Antwort | Variabel, abhängig von der Komplexität |
Anwendungsfälle von Agentic RAG
Enterprise Knowledge Management: Agentengestützte RAG-Systeme eignen sich hervorragend dazu, Informationen aus heterogenen Unternehmensdaten zu betrachten und abzurufen. Unternehmen können Systeme einsetzen, die automatisch interne Dokumente, Datenbanken, E-Mails und externe Marktinformationen durchsuchen, um komplexe Geschäftsfragen zu beantworten.
Automatisierung des Kundensupports: Unternehmen, die ihre Kundensupport-Services optimieren möchten, können automatisierte RAG-Systeme verwenden, um einfachere Kundenanfragen zu bearbeiten. Das agentische RAG-System kann anspruchsvollere Supportanfragen an menschliches Personal eskalieren. Das System kann auf Produkthandbücher, FAQ-Datenbanken, Kundenhistorie und Echtzeitstatusinformationen zugreifen, um umfassenden Support zu bieten.
Gesundheitsinformationssysteme: Medizinisches Fachpersonal kann agentisches RAG verwenden, um gleichzeitig auf Patientenakten, medizinische Literatur, Arzneimitteldatenbanken und klinische Leitlinien zuzugreifen, was eine fundiertere Entscheidungsfindung ermöglicht und gleichzeitig Datenschutz- und Compliance-Standards einhält.
Unterstützung finanzieller Entscheidungen: Mehrere RAG-Agenten können Berechnungen durchführen, Wetterinformationen finden, Aktien- und Markttrends empfehlen, Daten analysieren und mehr. Finanzanalysten können Systeme abfragen, die interne Portfoliodaten mit externen Marktinformationen, aufsichtsrechtlichen Einreichungen und Wirtschaftsindikatoren kombinieren.
FAQs
F: Kann agentisches RAG gleichzeitig auf mehrere Dokumente zugreifen?
A: Ein RAG-Agent kann auf Daten in mehreren bereitgestellten Dokumenten zugreifen, sie abrufen und vergleichen. Das System ist besonders leistungsfähig darin, Informationen aus unterschiedlichen Quellen in einer einzigen Antwort zu synthetisieren.
Q: Wie unterscheidet sich agentisches RAG von standardmäßigem RAG?
A: Ein klassisches RAG kann Informationen aus einer einzigen Quelle abrufen, während ein agentisches RAG mehrere Agenten nutzt, um auf Daten aus unterschiedlichen Quellen zuzugreifen und sie zu orchestrieren. Traditionelles RAG ist reaktiv, während agentisches RAG proaktiv und intelligent ist.
Q: Welche Frameworks können zum Erstellen agentischer RAG-Anwendungen verwendet werden?
A: Es sind mehrere Python-Frameworks mit einsatzbereiten Komponenten und Tools für Analysen und Monitoring von RAG-Agenten verfügbar. Zu diesen Frameworks gehören Phidata, LangGraph, Swarm, Microsoft Autogen usw.
Q: Ist agentisches RAG immer besser als traditionelles RAG?
A: Nicht unbedingt. Während agentisches RAG Ergebnisse durch Function Calling, mehrstufiges Schlussfolgern und Multiagentensysteme optimiert, ist es nicht immer die bessere Wahl. Für einfache Abfragen aus einer einzigen Quelle kann traditionelles RAG effizienter und kostengünstiger sein.
Q: Kann agentisches RAG mit verschiedenen Datentypen arbeiten?
A: Ja, moderne agentische RAG-Systeme unterstützen multimodale Verarbeitung und verarbeiten Text, Bilder, Audio sowie andere strukturierte und unstrukturierte Datenformate.
- Was ist Agentic RAG?
- Hauptmerkmale von Agentic RAG
- Wie funktioniert Agentic RAG
- Vorteile und Herausforderungen von Agentic RAG
- Vergleich von Agentic RAG mit traditionellem RAG
- Anwendungsfälle von Agentic RAG
- FAQs
Inhalte
Kostenlos starten, einfach skalieren
Testen Sie die vollständig verwaltete Vektordatenbank, die für Ihre GenAI-Anwendungen entwickelt wurde.
Zilliz Cloud kostenlos ausprobieren