




Wie eine weltweit führende GPU- und KI-Plattform Milvus nutzt, um multimodales Data Mining für ihr autonomes Fahrsystem zu skalieren

-30% Kosten
Reduzierter Arbeitsspeicher- und Speicherplatzbedarf durch festplattenbasierte Primärschlüssel und optimiertes Segmentlayout in Milvus 2.5.
10× skalieren
Nachgewiesener Spielraum, um ohne Neugestaltung oder Kostenüberraschungen um eine weitere Größenordnung zu skalieren.y ohne architektonische Änderungen oder unerwartete Kosten.
Enterprise-Zuverlässigkeit
Kontinuierliche Produktion in massivem Umfang ohne größere Zwischenfälle.
Hybride Suche
Vereinheitlichte Vektorsuche und Metadatenfilterung zur Unterstützung komplexer Abfragen.
From a system stability perspective, it's really quite good. Over the year-plus that we've been using it—from version 2.4.3 to now 2.5.8—I honestly haven't encountered many issues. The system can just run there for months, with new data being written every day and users searching every day, without any problems. I don't need to worry about it.
Team Lead
Über das Unternehmen
Der Kunde ist ein weltweit führendes Unternehmen im Bereich beschleunigtes Computing und künstliche Intelligenz, mit jahrzehntelanger Erfahrung im Aufbau von GPUs und Softwareplattformen, die in Gaming, Robotik, Rechenzentren und Automobilanwendungen eingesetzt werden. Eine seiner Flaggschiffinitiativen ist eine End-to-End-Plattform für fortschrittliche Fahrerassistenzsysteme und autonomes Fahren. Diese Plattform unterstützt den gesamten Lebenszyklus der Entwicklung selbstfahrender Systeme – von der groß angelegten Datenerfassung und dem Training von KI-Modellen bis hin zur Inferenz im Fahrzeug und zur Entscheidungsfindung in Echtzeit.
Hinter dieser Plattform steht die Autonomous Vehicle (AV) Data Engineering-Organisation des Unternehmens, die für die Dateninfrastruktur verantwortlich ist, die seine Technologie für selbstfahrende Fahrzeuge antreibt. Jede Stunde realer Fahrten erzeugt Terabytes an multimodalen Sensordaten, darunter synchronisierte Kamerastreams, LiDAR-Punktwolken, Radarmessungen, hochpräzise Lokalisierungsdaten und detaillierte Metadaten zum Fahrzeugzustand. Die Mission des Teams besteht darin, diesen riesigen und ständig wachsenden Datensatz für Hunderte von Ingenieuren durchsuchbar, auffindbar und operativ nutzbar zu machen, die Long-Tail-Szenarien aufdecken, seltene Grenzfälle identifizieren und das Modellverhalten unter realen Bedingungen validieren müssen.
Um diese Anforderungen zu erfüllen, entwickelte das Team ein multimodales Data-Mining-System, das Dutzende Milliarden indizierter Sensordatenpunkte durchsuchen kann, die aus Testflotten gesammelt wurden. Das System wandelt rohe Sensordaten in Vektoreinbettungen um, sodass Ingenieure tiefgehende, kontextbewusste Abfragen ausführen können – zum Beispiel: „Fahrzeuge, die bei starkem Regen von rechts einfädeln“, „Fußgänger, die bei Dämmerung an unmarkierten Kreuzungen überqueren“, oder „zweispurige Kreisverkehre mit verdeckter Sicht“.
Das System lief zunächst auf FAISS, doch als Datenvolumen und operative Anforderungen zunahmen, migrierte das Team zu Milvus, um höhere Skalierbarkeit, geringeren Wartungsaufwand und stärkere Produktionszuverlässigkeit zu erreichen. Milvus bot einen klaren Weg, um eine Größenordnung mehr Daten zu unterstützen, den operativen Aufwand zu reduzieren und Clustering-, Indexierungs- und Speichereffizienz zu verbessern, während die Flotte autonomer Fahrzeuge weiter wuchs.
Die Herausforderung: FAISS konnte nicht skalieren
Der Engpass im Datenmanagement
Das frühe Design dieses Data-Mining-Systems war bewusst einfach gehalten. Jede autonome Fahrsitzung – typischerweise eine einstündige Fahrt – wurde in Frames verarbeitet, durch die proprietären Modelle des Unternehmens in Vektoreinbettungen umgewandelt und in FAISS-Indexdateien gruppiert, normalerweise eine pro Tag.
Während diese Struktur anfangs gut funktionierte, ließ sie sich nicht skalieren. Als der Datensatz stark anwuchs, wuchs auch die Anzahl der Indexdateien – schließlich auf Hunderttausende. Jede stellte eine kleine, isolierte Informationsinsel dar. Die Suche über sie hinweg führte zu erheblicher Komplexität: Tagesindizes enthielten häufig überlappende Daten, was komplexe Logik zum Filtern und Zusammenführen von Metadaten erforderte. In der Praxis bedeutete dies, dass die Suche innerhalb eines einzelnen Tages zwar gut funktionierte, die meisten Nutzer jedoch breitere Bedingungen abfragen wollten – etwa spezifische Fahrszenarien über mehrere Tage oder Regionen hinweg. Diese Suchen mussten gleichzeitig auf viele separate Indexdateien zugreifen, was rechenintensiv war. Ingenieure mussten ihren Umfang oft manuell eingrenzen und raten, welche Dateien die relevanten Daten enthalten könnten, bevor sie eine Abfrage ausführten. Dieses Rätselraten machte den Suchprozess langsam und unzuverlässig.
Die Flexibilitätslücke
FAISS ist keine Datenbank – es ist eine Bibliothek. Es eignet sich gut, um die nächsten Nachbarn für einen gegebenen Vektor zu finden, aber produktionsreife Suchsysteme erfordern weit mehr als nur schnellen Ähnlichkeitsabgleich.
In der Praxis wollten Ingenieure nicht den gesamten Korpus auf einmal durchsuchen. Sie benötigten kontextbezogene Filterung—um zum Beispiel „Frames der nach vorn gerichteten Kamera, die bei leichtem Regen auf städtischen Straßen aufgenommen wurden“, oder „Nachtfahrten auf kalifornischen Highways“ zu finden. Um dieses Maß an Präzision zu erreichen, musste die Vektorsuche mit Metadatenfiltern wie Kameratyp, Zeit, Standort, Wetter und Modellversion kombiniert werden. FAISS stellte diese Funktionen jedoch nicht standardmäßig bereit. Um diese Lücke zu schließen, musste das Team einen komplexen Stack aus benutzerdefinierter Logik aufbauen: separate Metadatendatenbanken, maßgeschneiderte Query Planner, die entschieden, welche FAISS-Indizes durchsucht werden sollten, und manuelles Nachfiltern der Ergebnisse nach dem Abruf.
Mit der Zeit führten diese Anpassungen zu einem erheblichen Skalierungsproblem. Unterschiedliche Kamerawinkel, mehrere Embedding-Modelle und versionierte Vorverarbeitungspipelines erforderten jeweils eigene Verwaltungsstrategien. Es gab kein integriertes Konzept von Collections, Partitionen oder logischer Datengruppierung—nur Indexdateien. Jede Organisationsebene, von der Datenversionierung bis zur Abfragefilterung, musste in benutzerdefiniertem Code geschrieben und gepflegt werden. Das System funktionierte—aber auf Kosten von Flexibilität, Wartbarkeit und langfristiger Skalierbarkeit.
Das Skalierbarkeitsproblem
Das System war bereits durch Milliarden von Vektoren stark belastet, und die Testfahrzeuge des Unternehmens generierten täglich neue Daten. Gleichzeitig führten Forschungsteams neue Embedding-Modelle ein, die jeweils eine groß angelegte Neuindizierung historischer Daten erforderten. Es war nur eine Frage der Zeit, bis die Workloads um das Zehnfache wachsen würden, doch das dateibasierte FAISS-Setup bot keine praktikable Möglichkeit, auf dieses Niveau zu skalieren.
Noch schlimmer war, dass jeder neue Datensatz mehr Indexdateien und mehr manuelle Aktualisierungen des Metadatenspeichers bedeutete. Es gab kein automatisches Sharding, kein integriertes Load Balancing und keine Möglichkeit, Kapazität bei Bedarf hinzuzufügen. Die Architektur war veraltet geworden —statisch, arbeitsintensiv und wachstumsresistent.
Die versteckten Engineering-Kosten
Neben den Cloud-Kosten bestand die größte Herausforderung im versteckten Engineering-Aufwand für die Wartung von FAISS. Ingenieure mussten komplexe Metadatensysteme verwalten, benutzerdefinierte Logik zur Verteilung von Daten entwerfen und Millionen von Indexdateien manuell aktualisieren. Mit der Zeit verlangsamte dieser Aufwand die Innovation: Die Suchleistung verschlechterte sich, Entwicklungszyklen wurden länger, und neue Ideen kamen nie über das Whiteboard hinaus. Während die Datenmengen weiter zunahmen, wurde das System zunehmend starr und fragil. Es war klar, dass der Versuch, das Legacy-Setup zu modernisieren, nicht mehr nachhaltig war.
Die Lösung: Neuarchitektur für Skalierung mit Milvus
Um diese Herausforderungen zu bewältigen, benötigte das AV-Datenteam ein System, das heute Zehnmilliarden von Vektoren verarbeiten kann, mit einem klaren Weg zu 10× Wachstum und darüber hinaus. Es musste robuste Filterung, operative Einfachheit und—vor allem—Produktionszuverlässigkeit mit minimalem Wartungsaufwand bieten.
Der Evaluierungsprozess
Statt einen breiten Vergleichstest über jede aufkommende Vektordatenbank hinweg durchzuführen, konzentrierte sich das Team auf die beliebte Milvus Vector Database und führte einen Proof of Concept mit 400–500 Millionen Vektoren durch—groß genug, um reale Engpässe offenzulegen. Während der Tests replizierten die Ingenieure ihren vollständigen Datenworkflow: Sie indizierten Datensätze mit verschiedenen Indextypen, um Kompromisse zu vergleichen, maßen die Indizierungszeit, um tägliche Batch-Updates abzuschätzen, und benchmarkten die Latenz unter realistischen Filterkombinationen und Abfragemustern. Sie trieben Milvus bewusst an seine Grenzen, führten komplexe Suchen mit mehreren Bedingungen aus und skalierten Datenmengen, um die Stabilität zu testen.
Warum Milvus?
Die Ergebnisse des Proof of Concept machten Milvus zur klaren Wahl für das AV-Datenteam.
Akzeptable Abfrageleistung: Milvus lieferte konstant Abfragelatenzen im Sekundenbereich selbst für die komplexesten, filterintensiven Suchen—deutlich innerhalb der Anforderungen für interne Data-Mining-Workloads.
Native Filterung und flexible Abfragen: Ingenieure konnten nun Vektorähnlichkeitssuche mit Metadatenfiltern in einer einzigen Abfrage kombinieren—Fähigkeiten, die zuvor umfangreichen benutzerdefinierten Code in FAISS erforderten.
Organisierte Datenstruktur: Vektor-Embeddings aus verschiedenen Modellen wurden in separaten Collections gespeichert, die jeweils nach Attributen wie Erfassungsdatum oder Region partitioniert waren. Milvus verwaltete automatisch die Datenverteilung über Segmente hinweg und beseitigte so die Belastung durch manuelle Dateiverwaltung.
Nahtlose Skalierbarkeit: Als die Datenmenge wuchs, fügte das Team weitere Nodes hinzu, um die Kapazität zu erweitern. Die verteilte Architektur von Milvus skalierte linear, ohne Systemneugestaltungen zu erfordern.
Aktive Open-Source-Community: Während der Tests erhielten die AV-Data-Ingenieure prompte, praxisnahe Unterstützung vom Milvus-Team und von Community-Mitwirkenden, wodurch starkes Vertrauen in Milvus als vertrauenswürdiges, produktionsreifes Ökosystem entstand.
Implementierung der neuen Architektur mit Milvus
Im Kern ist die Architektur dieses multimodalen Data-Mining-Systems einfach—doch ihre Umsetzung in massivem Maßstab erfordert sorgfältiges Engineering und Präzision. Rohvideodaten aus Fahrten autonomer Fahrzeuge—stundenlanges kontinuierliches Filmmaterial von mehreren Kameras—fließen in eine Verarbeitungspipeline, die einzelne Frames oder kurze Clips extrahiert, typischerweise von wenigen Sekunden Länge.
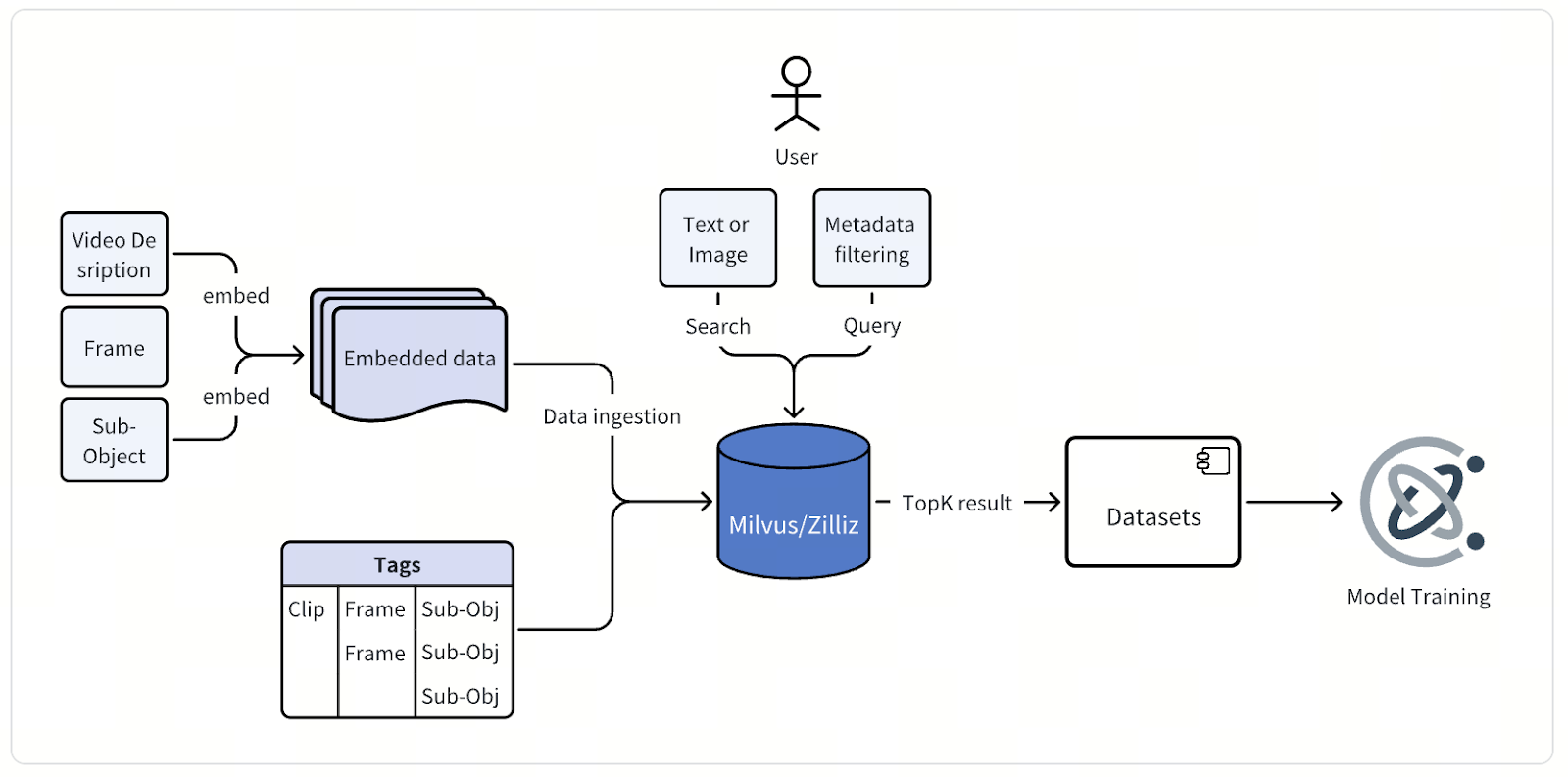
Jeder Frame oder Clip durchläuft anschließend die proprietären Embedding-Modelle des Unternehmens, die speziell für autonomes Fahren entwickelt wurden. Für Bilddaten verwendet das Team Modelle, die von der CLIP-Architektur abgeleitet sind und angepasst sowie feinabgestimmt wurden, um straßenspezifische Semantik zu erfassen. Für Videodaten stützen sie sich auf ihre eigenen hausgemachten Modelle, eine Familie von Foundation Models für Physical-AI-Anwendungen. Gemeinsam wandeln diese Modelle visuelle Daten in hochdimensionale Vektor-Embeddings um, die reichhaltige kontextuelle Bedeutung kodieren.
Nach ihrer Erzeugung werden diese Vektor-Embeddings—zusammen mit detaillierten Metadaten—in der Milvus Vector Database gespeichert und indexiert. Jeder Datenpunkt trägt Attribute, die unter anderem die Fahrsitzung, Kameraposition, den Zeitstempel, Fahrzeugzustand, Standort und die Wetterbedingungen beschreiben. Diese Metadaten werden ebenfalls indexiert, um schnelle und präzise gefilterte Suchen über massive Datensätze hinweg zu ermöglichen.
Über eine einheitliche Abfrageschnittstelle können Ingenieure die Daten auf verschiedene Weise durchsuchen. Sie können eine Textbeschreibung eingeben, ein Referenzbild oder -video hochladen oder Vektorsuche mit Metadatenfiltern kombinieren, um genau das zu finden, was sie benötigen. Eine einzelne Abfrage könnte beispielsweise nach „urban intersections at night with pedestrians crossing“ fragen, und Milvus liefert die relevantesten Frames oder Clips zur Überprüfung, Analyse und Modellverbesserung zurück.
Die Vorteile: Kosteneffizienz, Stabilität und Skalierung
Nach mehr als einem Jahr im Dauerbetrieb hat sich Milvus nicht nur als technisch solide, sondern auch als operativ transformativ erwiesen. Die folgenden Ergebnisse zeigen, wie seine Architektur und sein Ökosystem in reale Effizienz im großen Maßstab umgesetzt wurden.
Einfacherer Betrieb, weniger Aufwand und schnellere Entwicklung
Die Migration von Hunderttausenden FAISS-Dateien zu Milvus entfernte eine ganze Ebene operativer Mehrarbeit. Es gibt keine manuelle Verwaltung von Indexdateien mehr, keine Ad-hoc-Skripte und keine benutzerdefinierte Abfragelogik. Datenverteilung, Segmentverwaltung und Abfrage-Routing erfolgen nun automatisch. Upgrades sind unkompliziert, das Monitoring ist vereinheitlicht, und Metriken erzählen eine klare Geschichte. Das Ergebnis ist weniger Zeit für die Wartung von Systemen und mehr Zeit für das Mining von Daten nach Erkenntnissen.
Geringerer Engineering-Aufwand plus 30% zusätzliche Kostenreduktion nach dem Upgrade auf Milvus 2.5
Die Einführung von Milvus reduzierte sofort sowohl Infrastruktur- als auch Engineering-Kosten. Die Abkehr vom dateibasierten System von FAISS beseitigte die manuelle Dateiverwaltung und komplexe Metadatenverfolgung, wodurch erhebliche Entwicklerzeit und betrieblicher Aufwand eingespart wurden. Das Upgrade von Milvus 2.4 auf Milvus 2.5 brachte anschließend eine zusätzliche Senkung der Infrastrukturkosten um 30%, dank intelligenterem Memory Mapping, festplattenbasierter Speicherung von Primärschlüsseln und effizienterem Segmentmanagement.
Zusammen ermöglichen diese Verbesserungen dem AV-Data-Team, dieselben Workloads auf kleineren AWS-Instanzen auszuführen—oder deutlich mehr Daten zu indexieren—ohne die Ausgaben oder den Wartungsaufwand zu erhöhen. Ermutigt durch diese Ergebnisse plant das Team, Milvus 2.6 zu testen, das neue Indextypen wie RaBitQ und weitere Optimierungen einführt, die sowohl Performance als auch Kosteneffizienz voraussichtlich noch weiter steigern werden. Für große Offline-Batch-Workloads bleibt die Geschwindigkeit des Indexaufbaus eine zentrale Herausforderung. Dank Beiträgen des NVIDIA-cuVS-Teams unterstützt Milvus nun GPU-beschleunigte Indexaufbauten mit CPU-basiertem Serving (GPU-build, CPU-serve). Dieser Ansatz beschleunigt die Indexerstellung erheblich und erhält gleichzeitig die Kosteneffizienz — und wird voraussichtlich den Preis-Leistungs-Vorteil von Milvus bei Workloads für autonomes Fahren weiter stärken.
Integrierte Skalierbarkeit, in der Praxis bewährt
Die Plattform indexiert nun zig Milliarden Vektoren und nimmt täglich neue Daten reibungslos auf. Interne Modellierungen bestätigen, dass sie ohne Neudesign oder Kostenüberraschungen um das 10-Fache weiter skalieren kann—wodurch aus einer früheren Kapazitätsbeschränkung ein langfristiger strategischer Vorteil wird. Mit diesem Spielraum kann das Team von der Indexierung der Fahrdaten der letzten zwei Jahre auf die Abdeckung des gesamten historischen Archivs erweitern und so die Suche über jede jemals aufgezeichnete Fahrsitzung hinweg ermöglichen. Außerdem können mehrere Embedding-Modelle parallel ausgeführt werden, um das Retrieval für verschiedene Abfragetypen zu optimieren, und Daten sogar unbegrenzt aufbewahrt werden, statt sie auslaufen zu lassen. Skalierbarkeit bedeutet hier nicht nur, mehr Daten zu verarbeiten, sondern kontinuierliches Lernen zu ermöglichen und schnellere Fortschritte hin zu sichererem autonomem Fahren zu erzielen.
Enterprise-Zuverlässigkeit in massivem Maßstab
In mehr als einem Jahr ununterbrochenem Produktivbetrieb hat Milvus still und zuverlässig zig Milliarden Vektoren mit täglicher Aufnahme und Abfrage verarbeitet—ohne einen einzigen größeren Vorfall. Das System läuft stabil im Hintergrund und erfordert nur minimale Überwachung. Keine Wochenendausfälle, keine Notfall-Patches—nur konsistente, vorhersehbare Performance. Diese Art von Zuverlässigkeit in diesem Maßstab bedeutet weniger betriebliche Risiken, weniger Feuerwehreinsätze und mehr Fokus darauf, Mehrwert zu schaffen, statt Infrastruktur zu verwalten.
Umfangreichere Suche, intelligentere Workflows
Milvus kombiniert Vektorsuche mit Metadatenfilterung und eröffnet den Ingenieuren des Unternehmens neue Möglichkeiten, komplexe Fahrdaten zu analysieren. Sie können zum Beispiel alle Bilder von Baustellenbereichen finden, die bei Tageslicht von nach vorn gerichteten Kameras aufgenommen wurden, oder nach Zeit und Ort filtern, um das Modellverhalten über Updates und Regionen hinweg zu vergleichen. Verschiedene Collections enthalten Embeddings aus unterschiedlichen Modellen, sodass Teams neue Architekturen testen können, ohne die Produktion zu beeinträchtigen. Diese Fähigkeiten beschleunigen Experimente und decken Erkenntnisse auf, die zuvor umfangreiches Custom Engineering erforderten.
Eine starke Community, die die Wirkung vervielfacht
Über die Technologie hinaus war die Milvus-Open-Source-Community ein wesentlicher Bestandteil des Unternehmenserfolgs. Während Tests und Bereitstellung erhielten die Ingenieure schnelle Unterstützung direkt von Milvus-Beitragenden und -Maintainers. Diese Reaktionsfähigkeit reduzierte Ausfallzeiten, beschleunigte das Debugging und hielt den Fortschritt auf Kurs. Im Laufe der Zeit hat die aktive Community weiterhin Mehrwert geschaffen, indem sie half, neue Ideen zu validieren, Upgrades reibungsloser zu gestalten und Best Practices zu teilen. Für diesen Kunden ist Milvus nicht nur zuverlässige Software – es ist ein kollaboratives Ökosystem, das die Plattform stärkt und langfristige Effizienz liefert.
Erkenntnisse aus der Produktion
Den richtigen Index wählen: Skalierung, Kosten und Genauigkeit ausbalancieren
Die Wahl eines Index ist eine der wichtigsten praktischen Entscheidungen beim Aufbau eines Vektorsuchsystems. Milvus unterstützt viele Indextypen, jeder mit eigenen Kompromissen bei Geschwindigkeit, Speichernutzung und Genauigkeit. Für das AV-Data-Team bestand das Ziel darin, ein Gleichgewicht zwischen Datenskalierung, Infrastrukturkosten und Suchgenauigkeit zu finden – nicht einfach nur die schnellste Option zu wählen.
Nachdem sie mehrere Konfigurationen getestet hatten, entschieden sie sich für IVF_FLAT, das Vektoren in Cluster gruppiert und innerhalb der relevanten Cluster eine exakte Suche durchführt. Es ist nicht die schnellste oder kompakteste Option, aber für Dutzende Milliarden von Vektoren und moderate Latenzanforderungen lieferte es die richtige Mischung aus Leistung und Genauigkeit, während es effizient blieb.
Das Team stellte fest, dass es selten notwendig ist, zu etwas Neuerem zu wechseln, sobald ein Index gut zur Arbeitslast passt. In der Praxis spart ein gut abgestimmter Index mehr Zeit und Ressourcen, als kleinen Leistungsgewinnen hinterherzujagen. Für großskalige Systeme ist eine stabile und vorhersehbare Leistung das, was den Betrieb reibungslos hält.
Memory Mapping: Latenz gegen Kosten im großen Maßstab abwägen
Eine der effektivsten technischen Entscheidungen des Teams war die Nutzung von Memory Mapping (Mmap), um Infrastrukturkosten zu kontrollieren. In traditionellen Setups würde das Vorhalten aller Vektordaten im RAM massive, kostenintensive Instanzen erfordern. Mit Memory Mapping in Milvus verbleiben die meisten Daten auf der Festplatte, während das Betriebssystem häufig abgerufene Teile automatisch im Speicher hält. Dieses Design führt zu einer gewissen Latenz – Festplattenzugriffe sind langsamer als RAM –, bewahrt jedoch vorhersehbare Leistung und effiziente Ressourcennutzung. Für die Arbeitslast des Unternehmens ergab dieser Kompromiss vollkommen Sinn. Ihre Nutzer sind Ingenieure, die analytische Abfragen ausführen, nicht Endnutzer, die sofortige Antworten erwarten, und die Nebenläufigkeit bleibt gering.
Löschvorgänge: Wenn kleine Annahmen im großen Maßstab brechen
Eine der größten Erkenntnisse des Teams entstand aus etwas, das einfach erschien: Daten löschen. In der Append-only-Architektur von Milvus werden gelöschte Vektoren nicht sofort entfernt – sie werden zur Löschung markiert und später durch Hintergrund-Compaction bereinigt. Während der Tests löschte das Entfernen von Millionen von Vektoren unerwartet die Neuindizierung von Milliarden aus, da Bloom-Filter über Tausende von Segmenten hinweg False Positives erzeugten. Was wie eine routinemäßige Bereinigung wirkte, führte schließlich dazu, dass Data Nodes überlastet wurden und Jobs ins Stocken gerieten.
Die Lösung ergab sich daraus, zu verstehen, wie Milvus Daten verwaltet, und den Workflow entsprechend anzupassen – Bloom-Filter zu tunen, Partition Keys zu verwenden, um Löschvorgänge präzise auszurichten, und auf insert-only Bulk Loading umzusteigen. Die Quintessenz: Im großen Maßstab können selbst einfache Vorgänge sich anders verhalten, und das Verständnis der Systeminternas ist entscheidend, um die Leistung vorhersehbar zu halten.
Ausblick
Das Team bereitet sich darauf vor, Milvus 2.6 kurz nach der Veröffentlichung einzuführen, überzeugt davon, dass neue Indextypen und architektonische Optimierungen einen weiteren Effizienzsprung bringen werden. Frühe Gespräche mit dem Milvus-Engineering-Team deuten auf weitere Kostensenkungen und eine verbesserte Ressourcennutzung hin, die das Unternehmen durch Benchmarks im vollen Maßstab validieren möchte.
Mit Blick auf die weitere Zukunft sieht das Team spannende Möglichkeiten, Funktionalität und Skalierung auszubauen. Funktionen wie die hybride Suche, die Text- und Vektorabfragen kombiniert, könnten neue Wege zur Exploration multimodaler Daten eröffnen, während erweiterte datenbankähnliche Filter komplexe Workflows vereinfachen werden. Das kommende Milvus-3.0-Release verspricht zudem gestufte Architekturen, die es dem Unternehmen ermöglichen, schnellen Zugriff auf aktuelle Daten beizubehalten und gleichzeitig sein vollständiges historisches Archiv effizient zu speichern. Zusammen werden diese Fortschritte dem Unternehmen eine Datenplattform bieten, die mühelos skaliert, tiefere Suchfunktionen unterstützt und effizienter wächst.
Darüber hinaus wird erwartet, dass die Einführung und Weiterentwicklung von NVIDIA cuVS-gestützten GPU-beschleunigten Index-Builds mit CPU-basiertem Serving (GPU-build, CPU-serve) in Milvus eine sprunghafte Verbesserung der Offline-Indexierungsleistung ermöglicht. Durch die Nutzung von NVIDIA-GPUs und den hochoptimierten cuVS-Bibliotheken kann Milvus großskalige Vektorindizes deutlich schneller erstellen als reine CPU-Pipelines, während Abfragen weiterhin kosteneffizient auf der CPU bedient werden. Dies verkürzt die Zeit von Daten bis zur Abfrage erheblich, ermöglicht häufigere Index-Aktualisierungszyklen und verstärkt den Preis-Leistungs-Vorteil von Milvus für autonomes Fahren und andere großskalige multimodale Workloads weiter, bei denen schnelle Iteration und aktuelle Daten entscheidend sind.
Fazit
Das AV-Data-Team des Kunden hat eine leistungsstarke Data-Mining-Plattform aufgebaut, die die Entwicklung des autonomen Fahrens beschleunigt, indem sie riesige Mengen multimodaler Daten durchsuchbar und nutzbar macht. Die Migration von FAISS zu Milvus löste kritische Herausforderungen in Bezug auf Skalierbarkeit, Flexibilität und betriebliche Komplexität – und erzielte zugleich messbare Kosteneinsparungen und bemerkenswerte Produktionsstabilität.
Nach mehr als einem Jahr kontinuierlichen Betriebs und Dutzenden Milliarden indexierter Vektoren hat die Plattform bewiesen, dass Milvus als produktionsreife Grundlage für großskalige, domänenspezifische Vektorsuche dienen kann. Das System nimmt täglich neue Daten auf, unterstützt Ingenieure in den Programmen des Unternehmens für autonomes Fahren und bietet einen klaren Weg, ohne Re-Architektur um das 10-Fache weiter zu skalieren.
Für Organisationen, die Vektorsuchsysteme mit enormer Datenskalierung aufbauen, ist Kosteneffizienz entscheidend, und Stabilität wiegt schwerer als Latenzen im Sub-Millisekundenbereich. Die Erfahrung des Unternehmens ist aufschlussreich. Milvus zeigt, dass eine Open-Source-Vektordatenbank nicht nur die Anforderungen des Produktivbetriebs erfüllen kann, sondern sich im Laufe der Zeit weiter verbessert – und ein zuverlässiges, skalierbares und zukunftssicheres Rückgrat für reale KI-Infrastrukturen liefert.
- Über das Unternehmen
- Die Herausforderung: FAISS konnte nicht skalieren
- Die Lösung: Neuarchitektur für Skalierung mit Milvus
- Die Vorteile: Kosteneffizienz, Stabilität und Skalierung
- Erkenntnisse aus der Produktion
- Ausblick
- Fazit
Inhalte
Anwendungsfall
Branche
Automobilindustrie
Verwendete Technologie