




Optimierung der konversationellen KI bei FARFETCH

15x
schnellere Indizierungszeit
5x
schnellere Abfragezeit
Gesteigerte Konversion
durch mehr relevante Produktempfehlungen
Mehrere metrische Typen
zur Unterstützung verschiedener Anwendungsfälle
Milvus consistently outperformed Weaviate, emphasizing the indexing time for scenario S9, closely resembling the FARFETCH product catalog's dimensions.
PEDRO MOREIRA COSTA
Über FARFETCH
FARFETCH, ein führendes Unternehmen im Online-Modehandel, erweitert mit seiner neuesten Innovation iFetch die Grenzen des digitalen Einkaufs. Dieses konversationelle KI-System wurde entwickelt, um den personalisierten, hochwertigen Service, der typischerweise in physischen Luxusgeschäften zu finden ist, in die digitale Welt zu bringen. FARFETCH Chat R&D entwickelt im Rahmen dieser Initiative ein spezielles konversationelles Empfehlungssystem. Dieser Chatbot, der in iFetch integriert ist, ermöglicht es Benutzern, mit dem FARFETCH-Produktkatalog über natürliche Sprache und Bilder zu interagieren. So kann ein Nutzer beispielsweise ein Bild einer Jacke hochladen, die ihm gefällt, und der Chatbot antwortet mit einer kuratierten Auswahl ähnlicher Jacken. Durch die nahtlose Verschmelzung fortschrittlicher KI-Technologien mit dem Fokus auf Benutzerfreundlichkeit will FARFETCH neu definieren, was Kunden vom Online-Shopping erwarten können.
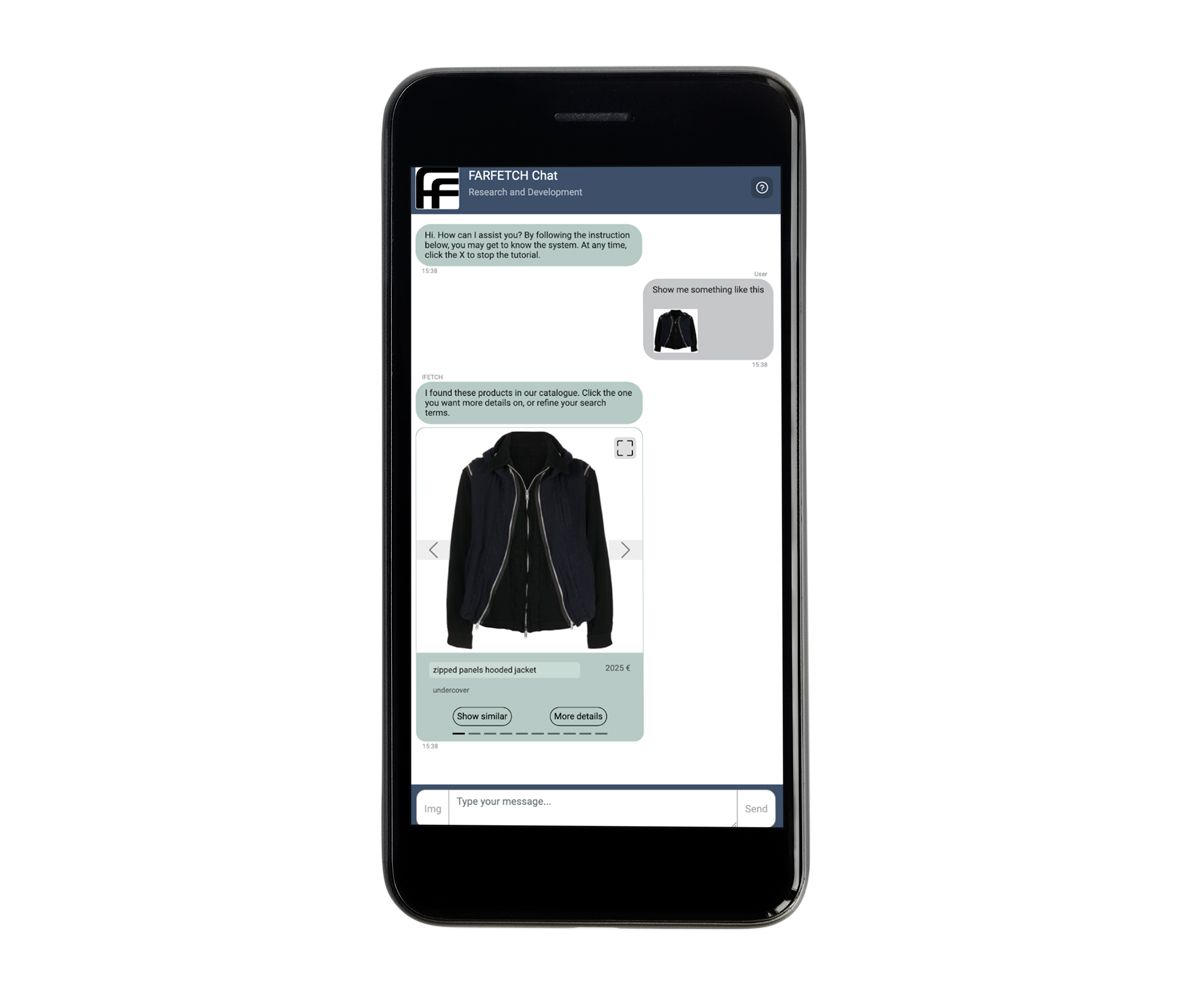 FARFETCH Chat zeigt ein ähnliches Schaufenster
FARFETCH Chat zeigt ein ähnliches Schaufenster
Das Unternehmen sah sich jedoch mit einer großen Herausforderung konfrontiert: Herkömmliche Produktkataloge hatten aufgrund ihrer begrenzten Metadaten Schwierigkeiten, die komplexen Beziehungen und differenzierten Eigenschaften der umfangreichen Produktpalette zu erfassen. Um dieses Problem zu lösen, setzten sie Algorithmen des maschinellen Lernens ein, um Produkteinbettungen zu entwickeln - hochdimensionale Datenpunkte, die als robuste Sprache für ihr KI-System dienen. Auf diese Weise kann der Chatbot Produkte mit bisher unerreichter Genauigkeit verstehen und empfehlen. Das Speichern und Abrufen dieser Einbettungen in Echtzeit stellte jedoch eine weitere Hürde dar und erforderte eine spezielle Speicherlösung, die hochdimensionale Daten effizient verarbeiten kann.
Die Bedeutung von Vektordatenbanken
Vektordatenbanken, auch bekannt als Vector Similarity Engines (VSE), sind spezialisierte Datenbanken, die für die Verarbeitung komplexer, hochdimensionaler Daten, so genannter Vektoreinbettungen, entwickelt wurden. Diese Datenbanken verwenden Algorithmen der approximierten nächsten Nachbarn (ANN), die für eine schnelle und genaue Datenabfrage unerlässlich sind. Diese Eigenschaft ist besonders wichtig für iFetch, das Kundeninteraktionen in Echtzeit erfordert, um sofortige Produktempfehlungen zu geben und ihre Anfragen zu beantworten. Die Wahl einer Vektordatenbank ist nicht nur eine technische Angelegenheit, sondern eine strategische Entscheidung, die sich direkt auf die Leistung, Robustheit und Effizienz von iFetch auswirkt. Das Unternehmen führte eine umfassende Benchmarking-Studie durch, um sicherzustellen, dass es die am besten geeignete VSE auswählt. Bei diesem Benchmarking wurden verschiedene Datenbanken, darunter Vespa, Milvus, Qdrant, Weaviate, Vald und Pinecone, anhand verschiedener Kriterien wie Indizierungsgeschwindigkeit, Abfragegeschwindigkeit und Skalierbarkeit bewertet. Das Benchmarking umfasste auch Stresstests, um die Leistung der einzelnen VSE bei Spitzenbelastungen sowie Failover- und Wiederherstellungsszenarien zur Beurteilung der Ausfallsicherheit zu bewerten.
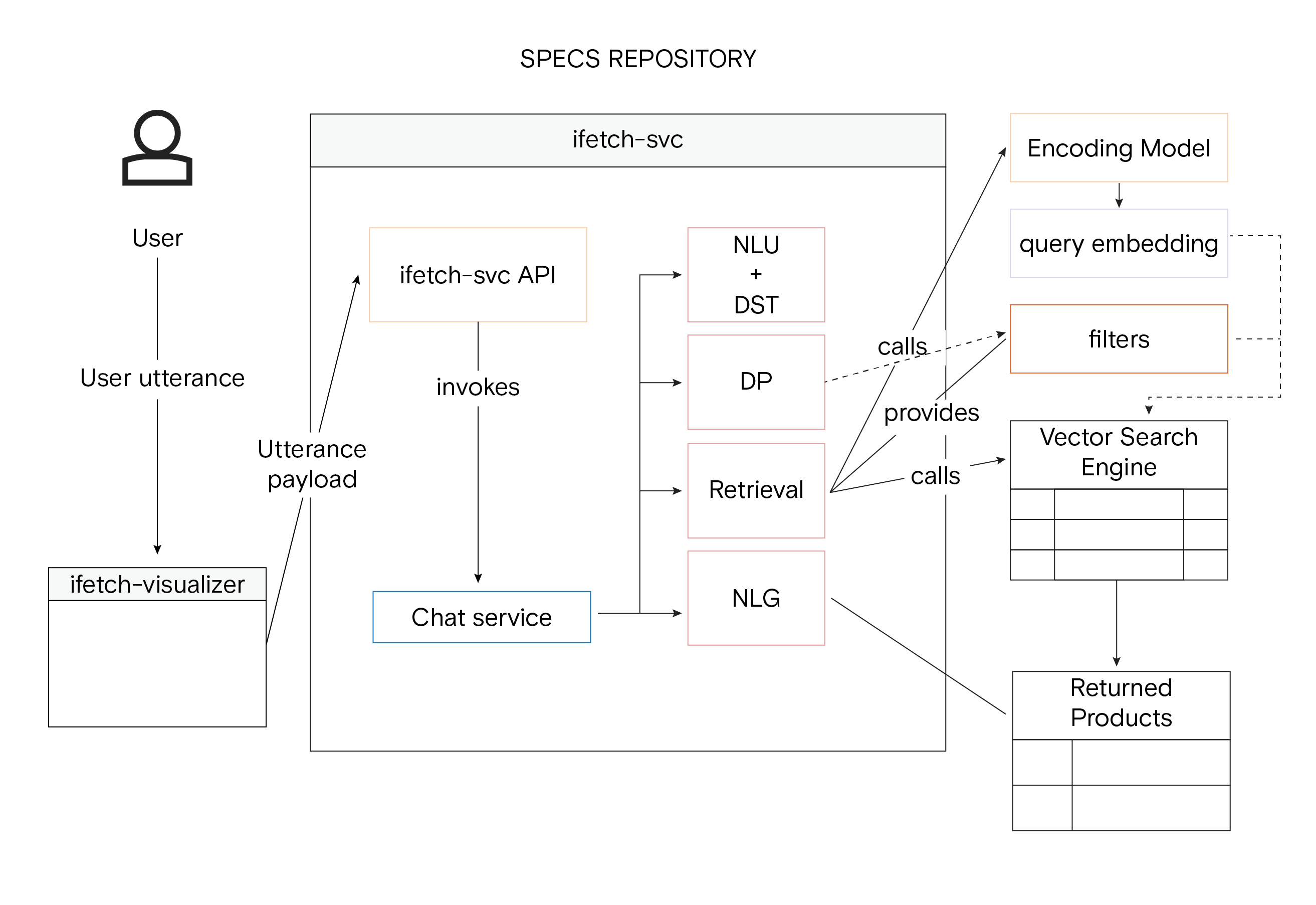 Ganzheitliche Darstellung der iFetch-Systemarchitektur mit Vector Similarity Searc
Ganzheitliche Darstellung der iFetch-Systemarchitektur mit Vector Similarity Searc
Benchmark-Kriterien und Auswahl
Das vom Farfetch-Team durchgeführte Benchmarking-Verfahren war umfassend und methodisch und deckte eine breite Palette von Faktoren ab, die für den langfristigen Erfolg von iFetch entscheidend sind. Dazu gehörten die Vielfalt der Indextypen, die Art der Metriken, die Möglichkeiten der Modellpflege und die Akzeptanz in der Community. Sie berücksichtigten auch die Qualität der Dokumentation und die Verfügbarkeit des Supports, da sich diese Faktoren auf die Einfachheit der Implementierung und die laufende Wartung auswirken würden.
| Feature | Qdrant | Milvus | Weaviate | Vespa | Vald | Pinecone | ||
|---|---|---|---|---|---|---|---|---|
| Konsistenzmodell | N/A | Starke Konsistenz | Eventuelle Konsistenz | Eventuelle Konsistenz | N/A | Eventuelle Konsistenz | ||
| Unterstützung für GraphQL | N/A | N/A | Ja | N/A | N/A | N/A | ||
| Sharding | Nein (Datum unbekannt) | Ja | Ja | Ja | Ja | N/A | N/A | N/A |
| Pagination | N/A | Nein (Erwartet in Version 2.2 in 2022.3) | Ja | Ja | N/A | N/A | ||
| Metrische Typen | Inneres Produkt Cosinus-Ähnlichkeit Euklidisch (L2) | L2 Inneres Produkt Hamming Jaccard Tanimoto Superstruktur Substruktur | Cosinus | Euklidisch Winkel Inneres Produkt Geo Grad Hamming | L1 L2 Winkel Hamming Cosinus Normailisierter Winkel Normalisierter Cosinus Jaccard | Euklidisch Cosinus Inneres Produkt | ||
| Max vector dim | N/A | N/A | 32 768 | N/A | max.MaxInt64 | N/A | ||
| Max. Indexgröße | N/A | N/A | Unbegrenzt | N/A | N/A | N/A | ||
| Indexarten | HNSW | ANNOY HNSW IVF_PQ IVF_SQ8 IVF_FLAT FLAT IVF_SQ8_H RNSG | NHSW | HNSW BM25 | N/A | Proprietär | ||
| Model Serving | N/A | N/A | text2vec-contextionary Weaviate's eigener Sprachvektorisierer; Weighted Mean of Word Embeddings (WMOWE) Vektorisierermodul, das mit populären Modellen wie fastText und GloVe arbeitet. Das neueste text2vec - contextionary wird mit fastText auf Wiki und CommonCrawl Daten trainiert. text2vec- transformers Transfomer-Modelle unterscheiden sich vom Contextionary, da sie es Ihnen ermöglichen, ein vortrainiertes NLP-Modul speziell für Ihren Anwendungsfall einzubauen. Das bedeutet, dass Modelle wie BERT, DilstBERT, RoBERTa, DilstilROBERTa usw. sofort mit Weaviate verwendet werden können. Benutzerdefinierte Modelle | N/A | N/A | N/A |
Nach einer gründlichen Analyse wurden zwei VSEs - Milvus und Weaviate - für ein eingehendes Benchmarking ausgewählt. Diese Plattformen entsprachen genau ihren strengen Anforderungen an Robustheit, Effizienz und Skalierbarkeit. Auch die Roadmaps der Plattformen beeinflussten die endgültige Auswahl, da das Unternehmen eine Lösung benötigte, die sich ständig weiterentwickeln und an seine wachsenden Anforderungen anpassen lässt.
Versuchsaufbau
Um eine faire und umfassende Bewertung zu gewährleisten, wurde ein standardisiertes Hardware- und Software-Setup verwendet.
- Hardware: Intel Xeon E5-2690 v4 CPU, 112 GB RAM, 1024 GB HDD
- Software: Linux 16.04-LTS, Anaconda 4.8.3 mit Python 3.8.12
- Datensatz: Das Farfetch-Team verwendete einen öffentlichen Datensatz von startups-list.com, der 40.474 Datensätze umfasst. Der Datensatz enthielt vorberechnete Einbettungen für Unternehmensbeschreibungen.
Szenarien und Indexierungsalgorithmus
Sie entwarfen mehrere Testszenarien, um die Leistung dieser VSEs unter verschiedenen Bedingungen zu bewerten. Diese Szenarien variierten die Anzahl der Datensätze und die Anzahl der Kodierungen pro Entität. Für die Indexierung wurde der Algorithmus Hierarchical Navigable Small World (HNSW) verwendet, der für seine Effizienz in hochdimensionalen Datenräumen bekannt ist.
Die endgültige Liste der Szenarien ist unten aufgeführt.
| Szenario | Anzahl der Entitäten | Anzahl der Kodierungen pro Entität |
|---|---|---|
| Szenario #1 (S1) | 1.000 | 1 |
| Szenario #2 (S2) | 10.000 | 1 |
| Szenario #3 (S3) | 40.474 | 1 |
| Szenario #4 (S4) | 1.000 | 2 |
| Szenario #5 (S5) | 10.000 | 2 |
| Szenario Nr. 6 (S6) | 40.474 | 2 |
| Szenario 7 (S7) | 1,000 | 5 |
| Szenario #8 (S8) | 10.000 | 5 |
| Szenario Nr. 9 (S9) | 40.474 | 5 |
Leistungsanalyse
Indizierung
Weaviate: Ermöglicht die explizite Deklaration von Indexparametern bei der Erstellung von Klassenschemata. Allerdings schränkt es die Benennung von Klassen ein, z. B. sind keine Zahlen oder Sonderzeichen erlaubt.
Milvus: Bietet ein breiteres Spektrum an Indizierungsalgorithmen und metrischen Typen. Es erlaubt auch die Definition von Indexdateigrößen, was Batch-Operationen optimieren kann.
Ergebnis: Milvus war bei den durchschnittlichen Indizierungszeiten in allen Szenarien im Vorteil. Im ressourcenintensivsten Szenario, S9, war es besonders schnell.
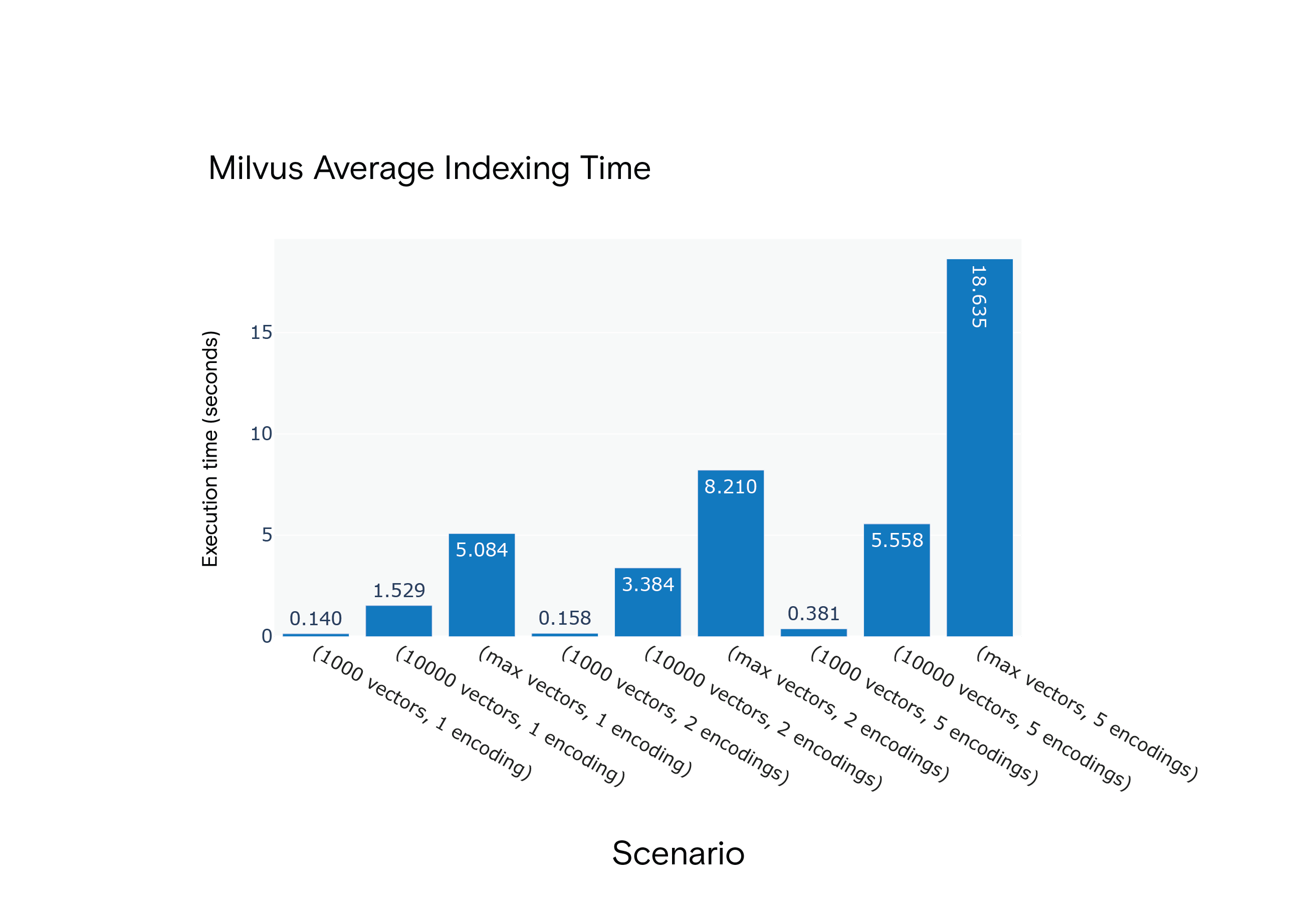 Milvus 1.1.1 Durchschnittliche Indizierungszeit für die Szenarien S1 bis S9
Milvus 1.1.1 Durchschnittliche Indizierungszeit für die Szenarien S1 bis S9
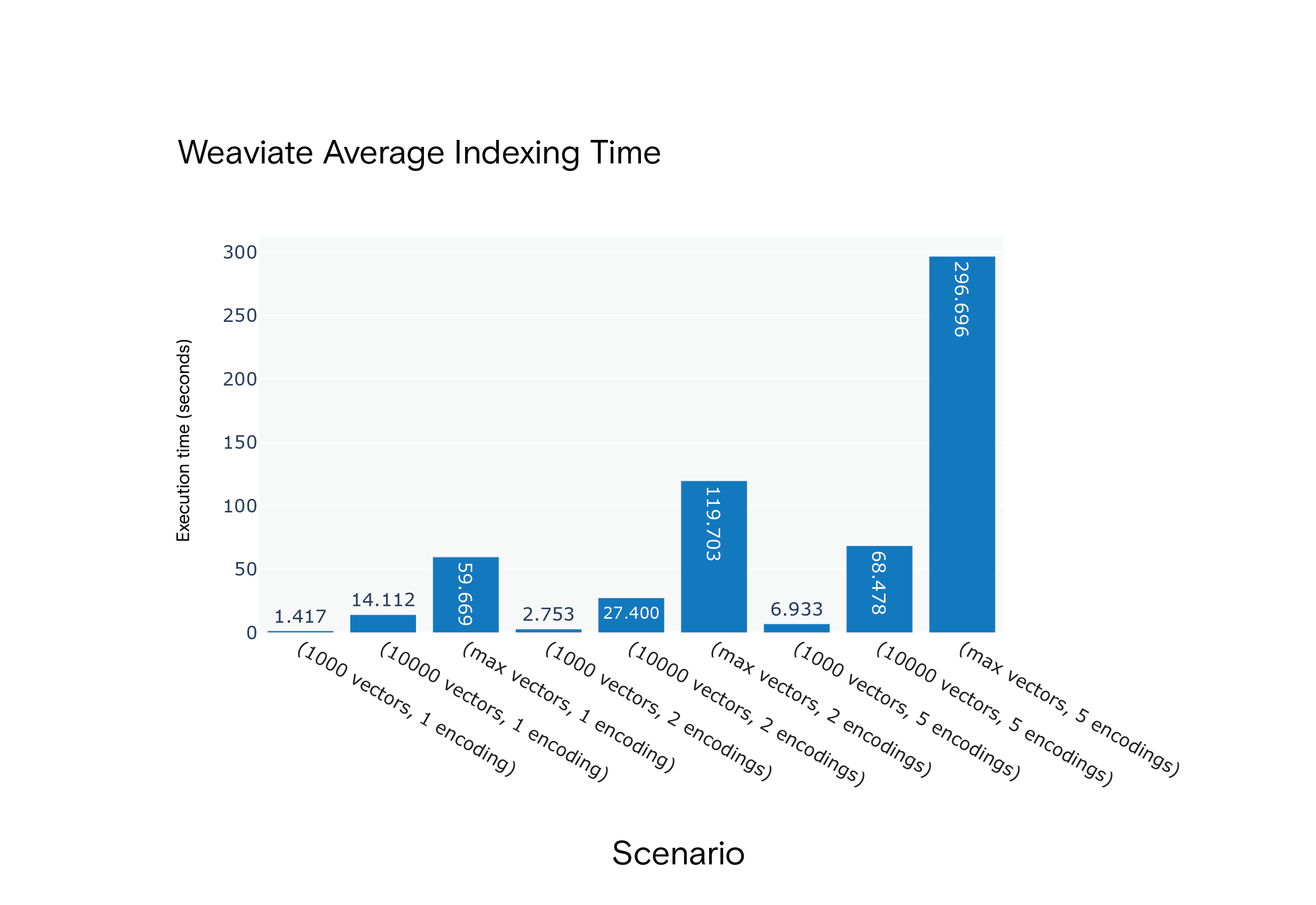 Weaviate Durchschnittliche Indizierungszeit für die Szenarien S1 bis S9
Weaviate Durchschnittliche Indizierungszeit für die Szenarien S1 bis S9
Abfrage
Weaviate: Der Python-Client unterstützt die Vektorsuche, allerdings nur für jeweils einen einzelnen Vektor.
Milvus: Bietet eine flexiblere Suchmethode, die eine Liste von Vektoren verarbeiten kann, was die Abfrage mehrerer Vektoren erleichtert.
Ergebnis: Milvus zeigte in allen Szenarien kürzere durchschnittliche Abfragezeiten, obwohl es eine "Aufwärmphase" benötigte, um eine optimale Leistung zu erreichen.
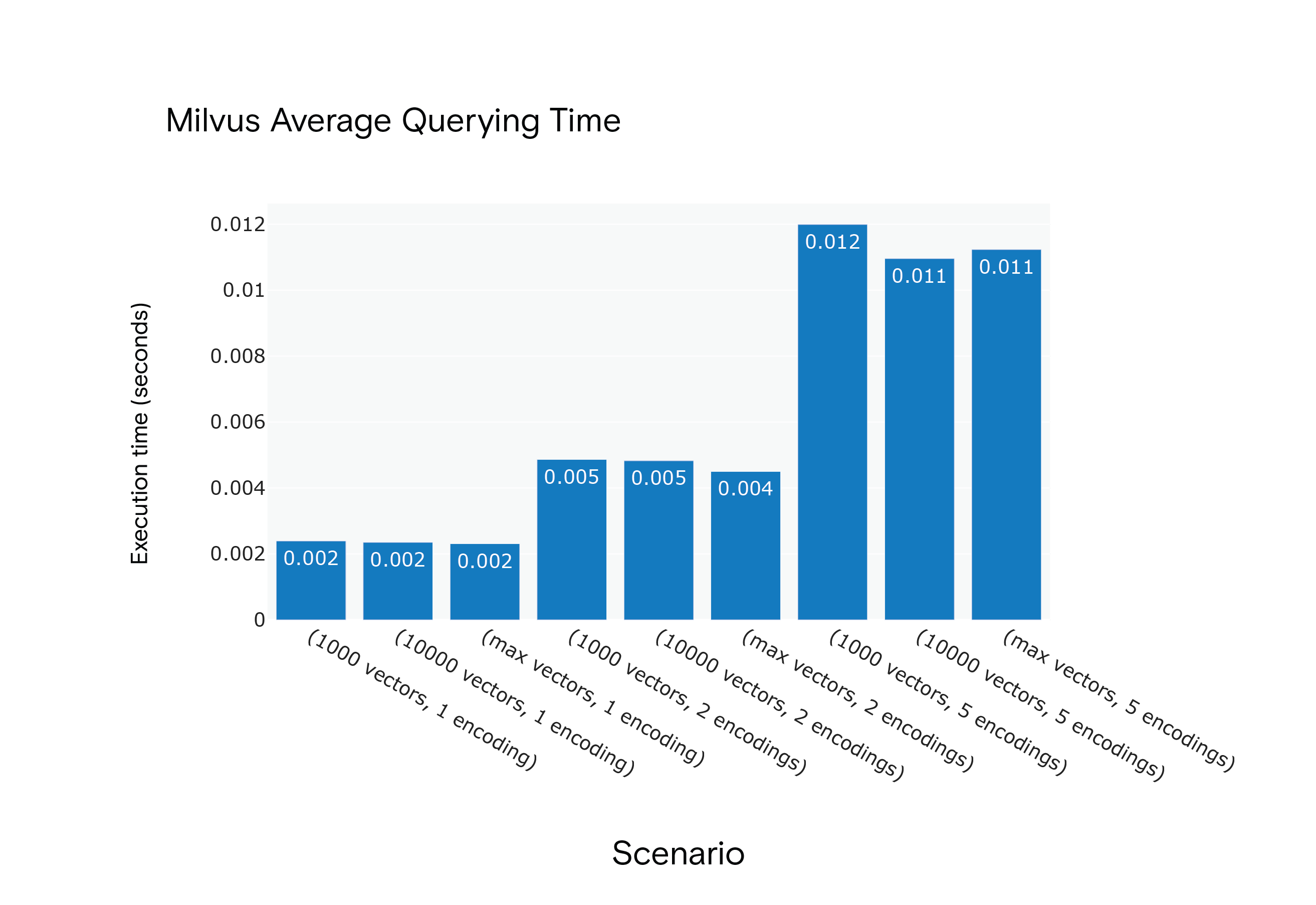 Milvus 1.1.1 Durchschnittliche Abfragezeit für die Szenarien S1 bis S9
Milvus 1.1.1 Durchschnittliche Abfragezeit für die Szenarien S1 bis S9
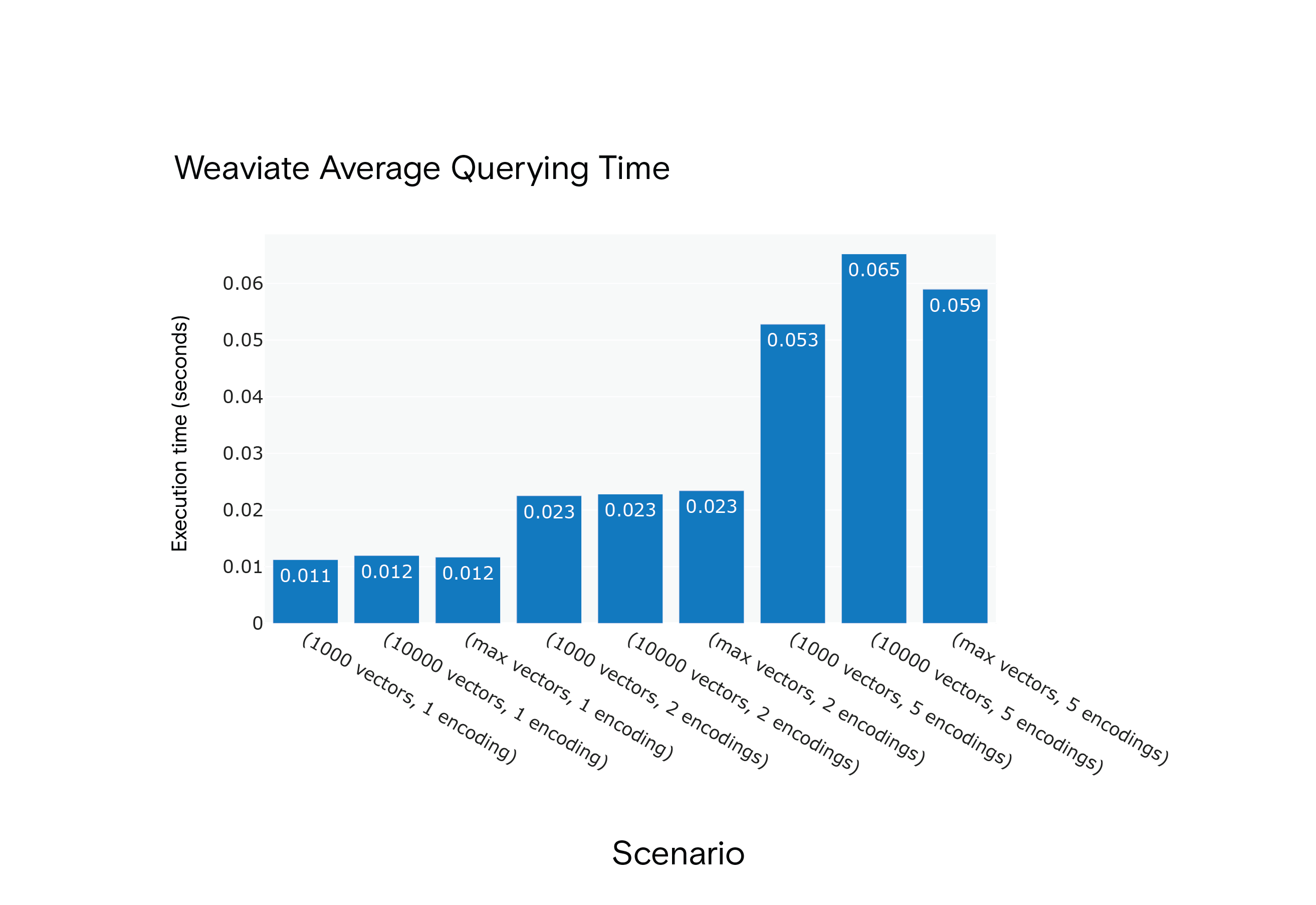 Weaviate Durchschnittliche Abfragezeit für die Szenarien S1 bis S9
Weaviate Durchschnittliche Abfragezeit für die Szenarien S1 bis S9
Das Farfetch-Team ist der Meinung, dass Milvus und Weaviate vielversprechend sind, sich aber noch weiterentwickeln. Funktionen wie horizontale Skalierung, Sharding und GPU-Unterstützung stehen auf der Roadmap. Für FARFETCH, das einen Produktkatalog mit 300.000 bis 5 Millionen Produkten verwalten will, sollte die ideale VSE folgende Funktionen bieten:
- Hochwertige, genaue Ergebnisse
- Effiziente Indizierungsfunktionen
- Schnelle Abfrageausführung
- Skalierbarkeitsfunktionen wie Lastausgleich und Datenreplikation
Die Experimente ergaben, dass Milvus bei den Indizierungs- und Abfragezeiten durchweg besser abschnitt als Weaviate. Es sei jedoch darauf hingewiesen, dass beide Plattformen bestimmte Einschränkungen aufweisen, wie z. B. die fehlende Unterstützung für mehrere Kodierungen. In ihrer zukünftigen Arbeit werden sie die Entwicklung dieser Plattformen genau beobachten und sie möglicherweise neu bewerten, wenn sie neue Funktionen einführen.
Diese Fallstudie ist eine gekürzte Version eines ausführlichen Benchmarking-Blogs über Vektordatenbanken, der ursprünglich von PEDRO MOREIRA COSTA von Farfetch veröffentlicht wurde. Detailliertere Analysen und Einblicke finden Sie in den Original-Blogbeiträgen: [POWERING AI WITH VECTOR DATABASES: A BENCHMARK - PART I] (https://www.farfetchtechblog.com/en/blog/post/powering-ai-with-vector-databases-a-benchmark-part-i/) und [POWERING AI WITH VECTOR DATABASES: A BENCHMARK - PART II] (https://www.farfetchtechblog.com/en/blog/post/powering-ai-with-vector-databases-a-benchmark-part-ii/).
- Über FARFETCH
- Die Bedeutung von Vektordatenbanken
- Benchmark-Kriterien und Auswahl
- Versuchsaufbau
- Szenarien und Indexierungsalgorithmus
- Leistungsanalyse
Inhalte
Anwendungsfall
Branche
Elektronischer Geschäftsverkehr