




So wählen Sie Indexparameter für den IVF-Index aus
In Best Practices for Milvus Configuration wurden einige Best Practices für die Konfiguration von Milvus 0.6.0 vorgestellt. In diesem Artikel stellen wir außerdem einige Best Practices für das Festlegen wichtiger Parameter in Milvus-Clients für Vorgänge wie das Erstellen einer Tabelle, das Erstellen von Indizes und die Suche vor. Diese Parameter können die Suchleistung beeinflussen.
1. index_file_size
Beim Erstellen einer Tabelle wird der Parameter index_file_size verwendet, um die Größe einer einzelnen Datei für die Datenspeicherung in MB anzugeben. Der Standardwert ist 1024. Wenn Vektordaten importiert werden, kombiniert Milvus Daten schrittweise zu Dateien. Wenn die Dateigröße index_file_size erreicht, nimmt diese Datei keine neuen Daten mehr an, und Milvus speichert neue Daten in einer anderen Datei. Dies sind alles Rohdatendateien. Wenn ein Index erstellt wird, generiert Milvus für jede Rohdatendatei eine Indexdatei. Für den Indextyp IVFLAT entspricht die Größe der Indexdatei ungefähr der Größe der entsprechenden Rohdatendatei. Beim SQ8-Index beträgt die Größe einer Indexdatei ungefähr 30 Prozent der entsprechenden Rohdatendatei.
Während einer Suche durchsucht Milvus jede Indexdatei nacheinander. Unserer Erfahrung nach verbessert sich die Suchleistung um 30 Prozent bis 50 Prozent, wenn index_file_size von 1024 auf 2048 geändert wird. Wenn der Wert jedoch zu groß ist, können große Dateien möglicherweise nicht in den GPU-Speicher (oder sogar CPU-Speicher) geladen werden. Wenn der GPU-Speicher beispielsweise 2 GB beträgt und index_file_size 3 GB ist, kann die Indexdatei nicht in den GPU-Speicher geladen werden. Üblicherweise setzen wir index_file_size auf 1024 MB oder 2048 MB.
Die folgende Tabelle zeigt einen Test mit sift50m für index_file_size. Der Indextyp ist SQ8.
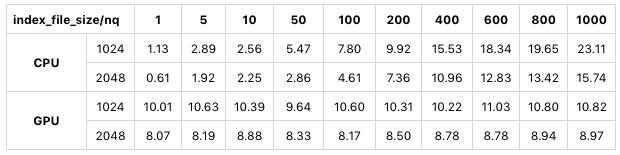 1-sift50m-test-results-milvus.
1-sift50m-test-results-milvus.
Wir können sehen, dass sich die Suchleistung im CPU-Modus und GPU-Modus deutlich verbessert, wenn index_file_size 2048 MB statt 1024 MB beträgt.
2. nlist und nprobe
Der Parameter nlist wird für die Indexerstellung verwendet, und der Parameter nprobe wird für die Suche verwendet. IVFLAT und SQ8 verwenden beide Clustering-Algorithmen, um eine große Anzahl von Vektoren in Cluster oder Buckets aufzuteilen. nlist ist die Anzahl der Buckets während des Clusterings.
Bei der Suche mithilfe von Indizes besteht der erste Schritt darin, eine bestimmte Anzahl von Buckets zu finden, die dem Zielvektor am nächsten liegen, und der zweite Schritt besteht darin, die ähnlichsten k Vektoren aus den Buckets anhand der Vektordistanz zu finden. nprobe ist die Anzahl der Buckets in Schritt eins.
Im Allgemeinen führt eine Erhöhung von nlist zu mehr Buckets und weniger Vektoren in einem Bucket während des Clusterings. Dadurch sinkt die Rechenlast und die Suchleistung verbessert sich. Bei weniger Vektoren für den Ähnlichkeitsvergleich kann jedoch das korrekte Ergebnis verpasst werden.
Eine Erhöhung von nprobe führt dazu, dass mehr Buckets durchsucht werden. Dadurch steigt die Rechenlast und die Suchleistung verschlechtert sich, aber die Suchpräzision verbessert sich. Die Situation kann je nach Datensätzen mit unterschiedlichen Verteilungen variieren. Sie sollten beim Festlegen von nlist und nprobe auch die Größe des Datensatzes berücksichtigen. Im Allgemeinen wird empfohlen, dass nlist 4 * sqrt(n) sein kann, wobei n die Gesamtzahl der Vektoren ist. Bei nprobe müssen Sie einen Kompromiss zwischen Präzision und Effizienz eingehen, und der beste Weg besteht darin, den Wert durch Versuch und Irrtum zu bestimmen.
Die folgende Tabelle zeigt einen Test mit sift50m für nlist und nprobe. Der Indextyp ist SQ8.
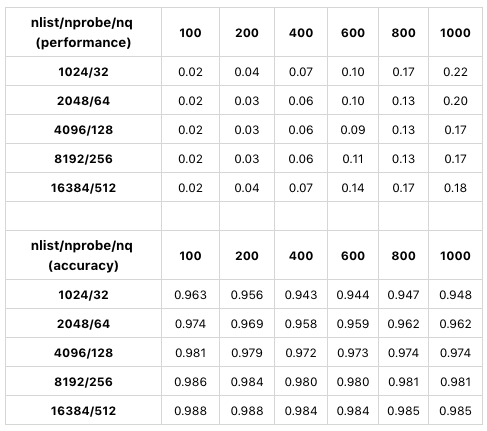 sq8-index-test-sift50m.
sq8-index-test-sift50m.
Die Tabelle vergleicht die Suchleistung und Präzision bei Verwendung verschiedener Werte von nlist/nprobe. Es werden nur GPU-Ergebnisse angezeigt, da CPU- und GPU-Tests ähnliche Ergebnisse liefern. In diesem Test steigt die Suchpräzision ebenfalls, wenn die Werte von nlist/nprobe um denselben Prozentsatz erhöht werden. Wenn nlist = 4096 und nprobe 128 ist, hat Milvus die beste Suchleistung. Zusammenfassend gilt: Bei der Bestimmung der Werte für nlist und nprobe müssen Sie unter Berücksichtigung verschiedener Datensätze und Anforderungen einen Kompromiss zwischen Leistung und Präzision eingehen.
Zusammenfassung
index_file_size: Wenn die Datengröße größer als index_file_size ist, gilt: Je größer der Wert von index_file_size, desto besser ist die Suchleistung.
nlist und nprobe:Sie müssen einen Kompromiss zwischen Leistung und Präzision eingehen.
Weiterlesen

Expanding Our Global Reach: Zilliz Cloud Launches in Azure Central India
Zilliz Cloud expands to Azure Central India. This new region helps customers meet compliance, reduce latency, and optimize cloud costs when building AI applications.
Milvus/Zilliz + Surveillance: How Vector Databases Transform Multi-Camera Tracking
See how Milvus vector database enhances multi-camera tracking with similarity-based matching for better surveillance in retail, warehouses and transport hubs.

DeepSeek-VL2: Mixture-of-Experts Vision-Language Models for Advanced Multimodal Understanding
Explore DeepSeek-VL2, the open-source MoE vision-language model. Discover its architecture, efficient training pipeline, and top-tier performance.