




Item-basiertes kollaboratives Filtern für ein Musik-Empfehlungssystem
Die Wanyin App ist eine KI-basierte Community zum Teilen von Musik mit dem Ziel, das Teilen von Musik zu fördern und die Musikkomposition für Musikbegeisterte zu erleichtern.
Die Bibliothek von Wanyin enthält eine enorme Menge an Musik, die von Nutzern hochgeladen wurde. Die Hauptaufgabe besteht darin, basierend auf dem bisherigen Verhalten der Nutzer die Musik herauszufiltern, die von Interesse ist. Wir haben zwei klassische Modelle evaluiert: nutzerbasiertes kollaboratives Filtern (User-based CF) und elementbasiertes kollaboratives Filtern (Item-based CF) als potenzielle Modelle für das Empfehlungssystem.
- User-based CF verwendet Ähnlichkeitsstatistiken, um benachbarte Nutzer mit ähnlichen Präferenzen oder Interessen zu ermitteln. Mit der abgerufenen Menge der nächsten Nachbarn kann das System das Interesse des Zielnutzers vorhersagen und Empfehlungen generieren.
- Item-based CF, oder Item-to-Item (I2I) CF, wurde von Amazon eingeführt und ist ein bekanntes kollaboratives Filtermodell für Empfehlungssysteme. Es berechnet Ähnlichkeiten zwischen Elementen statt zwischen Nutzern, basierend auf der Annahme, dass interessante Elemente den Elementen mit hohen Bewertungen ähnlich sein müssen.
User-based CF kann zu unvertretbar längeren Berechnungszeiten führen, wenn die Nutzerzahl einen bestimmten Punkt überschreitet. Unter Berücksichtigung der Eigenschaften unseres Produkts haben wir uns entschieden, I2I CF zur Implementierung des Musikempfehlungssystems zu verwenden. Da wir nicht über viele Metadaten zu den Songs verfügen, müssen wir uns mit den Songs selbst befassen und Feature-Vektoren (Embeddings) aus ihnen extrahieren. Unser Ansatz besteht darin, diese Songs in Mel-Frequenz-Cepstrum (MFC) umzuwandeln, ein Convolutional Neural Network (CNN) zu entwerfen, um die Feature-Embeddings der Songs zu extrahieren, und anschließend Musikempfehlungen über eine Ähnlichkeitssuche der Embeddings auszusprechen.
🔎 Auswahl einer Suchmaschine für Embedding-Ähnlichkeiten
Da wir nun Feature-Vektoren haben, bleibt die Frage, wie aus dem großen Volumen an Vektoren diejenigen abgerufen werden können, die dem Zielvektor ähnlich sind. Bei der Suchmaschine für Embeddings haben wir zwischen Faiss und Milvus abgewogen. Mir fiel Milvus auf, als ich im November 2019 die Trending Repositories von GitHub durchging. Ich habe mir das Projekt angesehen, und es gefiel mir aufgrund seiner abstrakten APIs. (Damals war es auf v0.5.x und inzwischen auf v0.10.2.)
Wir bevorzugen Milvus gegenüber Faiss. Einerseits haben wir Faiss bereits zuvor verwendet und würden daher gerne etwas Neues ausprobieren. Andererseits ist Faiss im Vergleich zu Milvus eher eine zugrunde liegende Bibliothek und daher nicht ganz so bequem zu verwenden. Als wir mehr über Milvus erfuhren, entschieden wir uns schließlich aufgrund seiner zwei Hauptmerkmale für Milvus:
- Milvus ist sehr einfach zu verwenden. Alles, was Sie tun müssen, ist, das Docker-Image zu pullen und die Parameter basierend auf Ihrem eigenen Szenario zu aktualisieren.
- Es unterstützt mehr Indizes und verfügt über ausführliche unterstützende Dokumentation.
Kurz gesagt: Milvus ist sehr benutzerfreundlich und die Dokumentation ist recht detailliert. Wenn Sie auf ein Problem stoßen, finden Sie in der Regel Lösungen in der Dokumentation; andernfalls können Sie jederzeit Unterstützung von der Milvus-Community erhalten.
Milvus-Cluster-Service ☸️ ⏩
Nachdem wir beschlossen hatten, Milvus als Suchmaschine für Feature-Vektoren zu verwenden, konfigurierten wir einen eigenständigen Knoten in einer Entwicklungsumgebung (DEV). Er lief einige Tage lang gut, daher planten wir, Tests in einer Factory-Acceptance-Test-Umgebung (FAT) durchzuführen. Wenn ein eigenständiger Knoten in der Produktion abstürzte, wäre der gesamte Dienst nicht mehr verfügbar. Daher müssen wir einen hochverfügbaren Suchdienst bereitstellen.
Milvus stellt sowohl Mishards, eine Cluster-Sharding-Middleware, als auch Milvus-Helm für die Konfiguration bereit. Der Prozess der Bereitstellung eines Milvus-Cluster-Services ist einfach. Wir müssen nur einige Parameter aktualisieren und sie für die Bereitstellung in Kubernetes paketieren. Das folgende Diagramm aus der Dokumentation von Milvus zeigt, wie Mishards funktioniert:
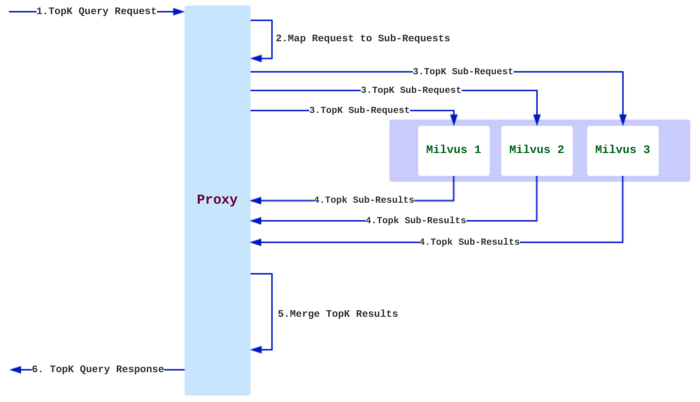 Ein Diagramm des Funktionsmechanismus von Mishards.
Ein Diagramm des Funktionsmechanismus von Mishards.
Mishards leitet eine Anfrage von upstream an seine Submodule weiter, indem es die Upstream-Anfrage aufteilt, und sammelt anschließend die Ergebnisse der Sub-Services und gibt sie an upstream zurück. Die Gesamtarchitektur der Mishards-basierten Cluster-Lösung ist unten dargestellt:
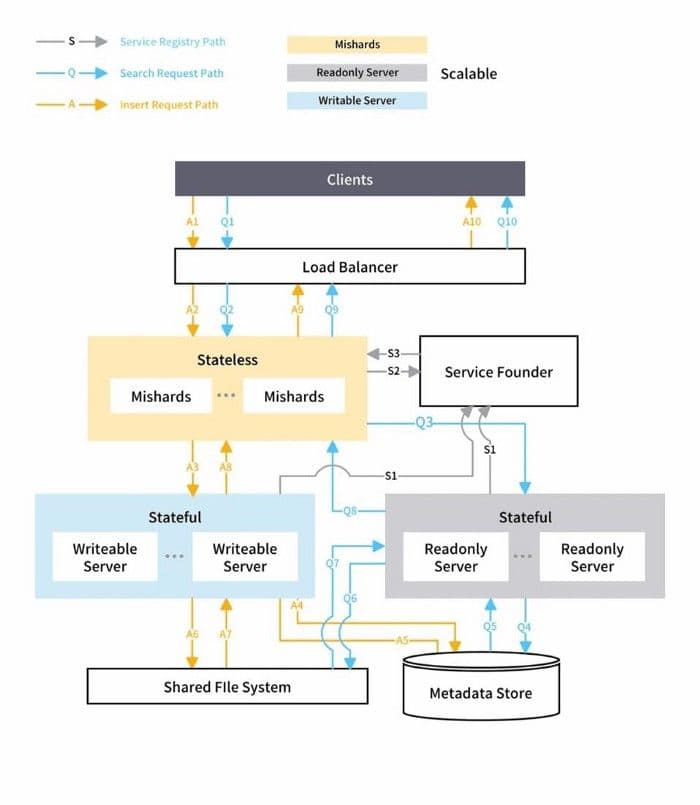 Gesamtarchitektur von Mishards.
Gesamtarchitektur von Mishards.
Die offizielle Dokumentation bietet eine klare Einführung in Mishards. Sie können Mishards lesen, wenn Sie interessiert sind.
In unserem Musikempfehlungssystem haben wir mit Milvus-Helm einen beschreibbaren Knoten, zwei schreibgeschützte Knoten und eine Mishards-Middleware-Instanz in Kubernetes bereitgestellt. Nachdem der Service eine Zeit lang stabil in einer FAT-Umgebung gelaufen war, haben wir ihn in der Produktion bereitgestellt. Bisher läuft er stabil.
🎧 I2I-Musikempfehlung 🎶
Wie oben erwähnt, haben wir Wanyins I2I-Musikempfehlungssystem mithilfe der extrahierten Embeddings der vorhandenen Songs aufgebaut. Zuerst haben wir den Gesang und die BGM (Spurtrennung) eines neuen, vom Benutzer hochgeladenen Songs getrennt und die BGM-Embeddings als Merkmalsrepräsentation des Songs extrahiert. Dies hilft auch dabei, Coverversionen von Originalsongs zu identifizieren. Anschließend haben wir diese Embeddings in Milvus gespeichert, anhand der Songs, die der Benutzer gehört hat, nach ähnlichen Songs gesucht und die abgerufenen Songs dann sortiert und neu angeordnet, um Musikempfehlungen zu generieren. Der Implementierungsprozess ist unten dargestellt:
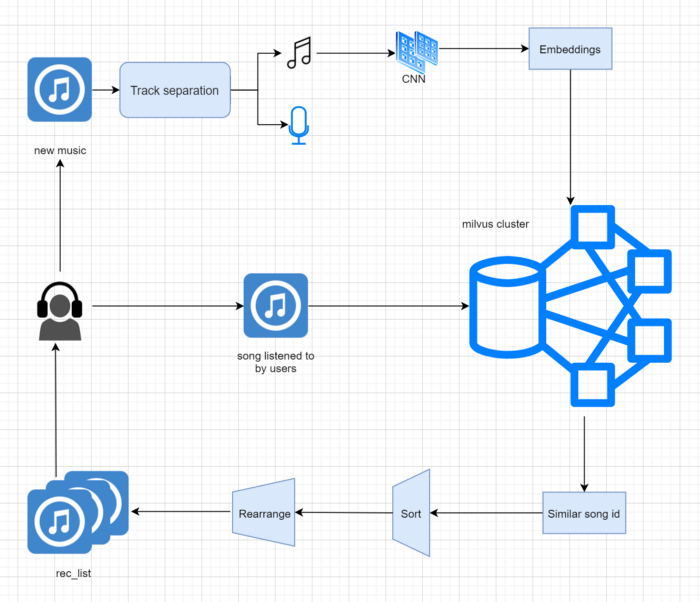 Implementierung von Wanyins I2I-Musikempfehlungssystem.
Implementierung von Wanyins I2I-Musikempfehlungssystem.
🚫 Filter für doppelte Songs
Ein weiteres Szenario, in dem wir Milvus verwenden, ist das Filtern doppelter Songs. Einige Benutzer laden denselben Song oder Clip mehrmals hoch, und diese doppelten Songs können in ihrer Empfehlungsliste erscheinen. Das bedeutet, dass es die Benutzererfahrung beeinträchtigen würde, Empfehlungen ohne Vorverarbeitung zu generieren. Daher müssen wir die doppelten Songs herausfinden und durch Vorverarbeitung sicherstellen, dass sie nicht in derselben Liste erscheinen.
Ein weiteres Szenario, in dem wir Milvus verwenden, ist das Filtern doppelter Songs. Einige Benutzer laden denselben Song oder Clip mehrmals hoch, und diese doppelten Songs können in ihrer Empfehlungsliste erscheinen. Das bedeutet, dass es die Benutzererfahrung beeinträchtigen würde, Empfehlungen ohne Vorverarbeitung zu generieren. Daher müssen wir die doppelten Songs herausfinden und durch Vorverarbeitung sicherstellen, dass sie nicht in derselben Liste erscheinen.
Wie im vorherigen Szenario haben wir das Filtern doppelter Songs durch die Suche nach ähnlichen Merkmalsvektoren implementiert. Zuerst haben wir den Gesang und die BGM getrennt und mit Milvus eine Anzahl ähnlicher Songs abgerufen. Um doppelte Songs genau zu filtern, haben wir die Audio-Fingerprints des Ziel-Songs und der ähnlichen Songs extrahiert (mit Technologien wie Echoprint, Chromaprint usw.) und die Ähnlichkeit zwischen dem Audio-Fingerprint des Ziel-Songs und den Fingerprints der einzelnen ähnlichen Songs berechnet. Wenn die Ähnlichkeit den Schwellenwert überschreitet, definieren wir einen Song als Duplikat des Ziel-Songs. Der Prozess des Audio-Fingerprint-Abgleichs macht das Filtern doppelter Songs genauer, ist aber auch zeitaufwendig. Daher verwenden wir, wenn es darum geht, Songs in einer riesigen Musikbibliothek zu filtern, Milvus als ersten Schritt, um unsere Kandidaten für doppelte Songs vorzufiltern.
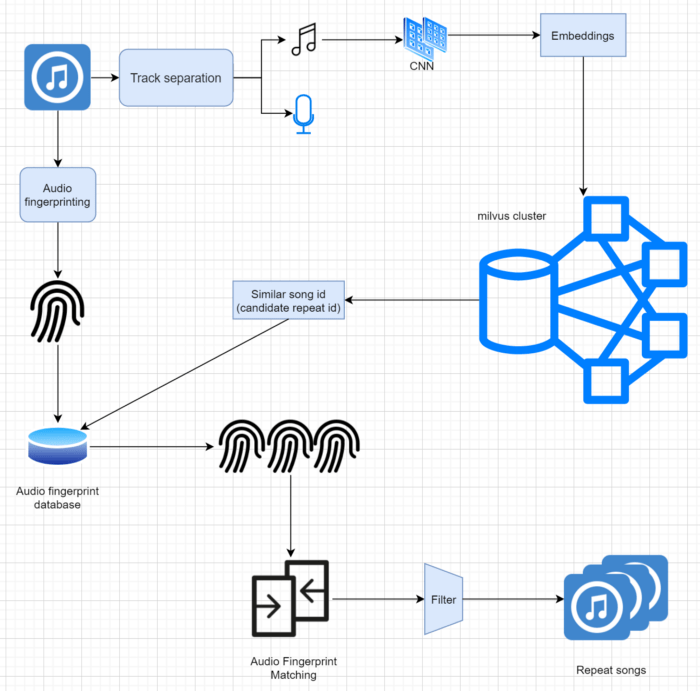 Milvus verwenden, um das Filtern doppelter Songs zu ermöglichen.
Milvus verwenden, um das Filtern doppelter Songs zu ermöglichen.
Um das I2I-Empfehlungssystem für Wanyins riesige Musikbibliothek zu implementieren, besteht unser Ansatz darin, die Embeddings von Songs als deren Merkmal zu extrahieren, ähnliche Embeddings zum Embedding des Ziel-Songs abzurufen und die Ergebnisse anschließend zu sortieren und neu anzuordnen, um Empfehlungslisten für den Benutzer zu erstellen. Um Echtzeit-Empfehlungen zu ermöglichen, wählen wir Milvus anstelle von Faiss als Suchmaschine für die Ähnlichkeit von Merkmalsvektoren, da Milvus sich als benutzerfreundlicher und ausgereifter erweist. Aus demselben Grund haben wir Milvus auch auf unseren Filter für doppelte Songs angewendet, was die Benutzererfahrung und Effizienz verbessert.
Du kannst die Wanyin App 🎶 herunterladen und ausprobieren. (Hinweis: möglicherweise nicht in allen App Stores verfügbar.)
📝 Autoren:
Jason, Algorithmus-Ingenieur bei Stepbeats Shiyu Chen, Dateningenieur bei Zilliz
📚 Referenzen:
Mishards Docs: https://milvus.io/docs/v0.10.2/mishards.md Mishards: https://github.com/milvus-io/milvus/tree/master/shards Milvus-Helm: https://github.com/milvus-io/milvus-helm/tree/master/charts/milvus
🤗 Sei kein Fremder, folge uns auf Twitter oder tritt uns auf Slack!👇🏻
Weiterlesen

Introducing Zilliz MCP Server: Natural Language Access to Your Vector Database
Developers can easily manage and query vector databases with natural language via Zilliz MCP Server in AI-native environments.

Balancing Precision and Performance: How Zilliz Cloud's New Parameters Help You Optimize Vector Search
Optimize vector search with Zilliz Cloud’s level and recall features to tune accuracy, balance performance, and power AI applications.

1 Table = 1000 Words? Foundation Models for Tabular Data
TableGPT2 automates tabular data insights, overcoming schema variability, while Milvus accelerates vector search for efficient, scalable decision-making.