




Beschleunigung der Entdeckung neuer Arzneimittel
Einführung
Die Wirkstoffentdeckung ist als Quelle medizinischer Innovation ein wichtiger Bestandteil der Forschung und Entwicklung neuer Medikamente. Die Wirkstoffentdeckung wird durch Zielauswahl und -bestätigung umgesetzt. Wenn Fragmente oder Leitverbindungen entdeckt werden, werden ähnliche Verbindungen in der Regel in internen oder kommerziellen Verbindungsbibliotheken gesucht, um die Struktur-Wirkungs-Beziehung (SAR) und die Verfügbarkeit von Verbindungen zu ermitteln und so das Potenzial der Leitverbindungen zur Optimierung zu Kandidatenverbindungen zu bewerten.
Um verfügbare Verbindungen im Fragmentraum aus Verbindungsbibliotheken im Milliardenmaßstab zu entdecken, wird der chemische Fingerabdruck üblicherweise für Substruktursuche und Ähnlichkeitssuche abgerufen. Die traditionelle Lösung ist jedoch zeitaufwendig und fehleranfällig, wenn es um hochdimensionale chemische Fingerabdrücke im Milliardenmaßstab geht. Einige potenzielle Verbindungen können dabei ebenfalls verloren gehen. Dieser Artikel erläutert die Verwendung von Milvus, einer Ähnlichkeitssuchmaschine für Vektoren im massiven Maßstab, zusammen mit RDKit zum Aufbau eines Systems für die leistungsstarke Ähnlichkeitssuche chemischer Strukturen.
Im Vergleich zu traditionellen Methoden bietet Milvus eine schnellere Suchgeschwindigkeit und eine breitere Abdeckung. Durch die Verarbeitung chemischer Fingerabdrücke kann Milvus Substruktursuche, Ähnlichkeitssuche und exakte Suche in Bibliotheken chemischer Strukturen durchführen, um potenziell verfügbare Medikamente zu entdecken.
Systemübersicht
Das System verwendet RDKit zur Erzeugung chemischer Fingerabdrücke und Milvus zur Durchführung der Ähnlichkeitssuche chemischer Strukturen. Weitere Informationen zum System finden Sie unter https://github.com/milvus-io/bootcamp/blob/master/EN_solutions/mols_search/README.md.
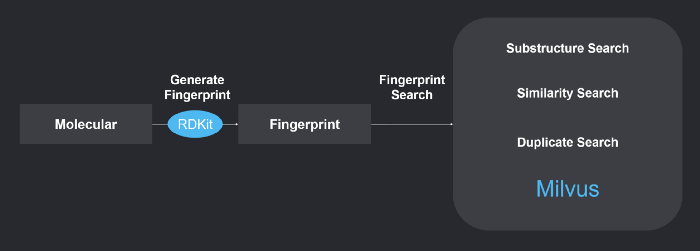 Systemübersicht
Systemübersicht
1. Erzeugen chemischer Fingerabdrücke
Chemische Fingerabdrücke werden üblicherweise für Substruktursuche und Ähnlichkeitssuche verwendet. Das folgende Bild zeigt eine durch Bits dargestellte sequenzielle Liste. Jede Ziffer steht für ein Element, ein Atompaar oder funktionelle Gruppen. Die chemische Struktur ist C1C(=O)NCO1.
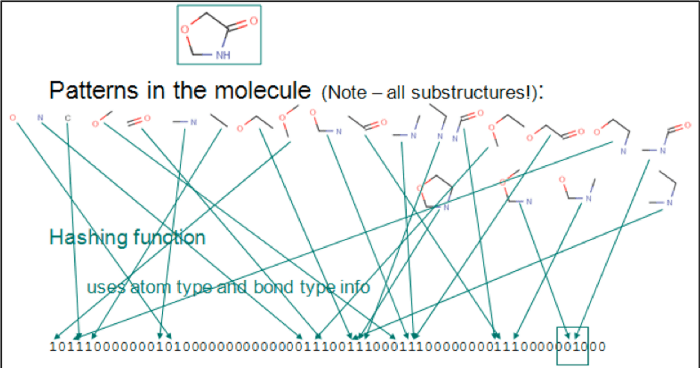 Identifizierung von Molekülmustern.
Identifizierung von Molekülmustern.
Wir können RDKit verwenden, um Morgan-Fingerabdrücke zu erzeugen, wobei ein Radius von einem bestimmten Atom definiert und die Anzahl der chemischen Strukturen innerhalb des Radiusbereichs berechnet wird, um einen chemischen Fingerabdruck zu erzeugen. Geben Sie unterschiedliche Werte für Radius und Bits an, um die chemischen Fingerabdrücke verschiedener chemischer Strukturen zu erhalten. Die chemischen Strukturen werden im SMILES-Format dargestellt.
from rdkit import Chem
mols = Chem.MolFromSmiles(smiles)
mbfp = AllChem.GetMorganFingerprintAsBitVect(mols, radius=2, bits=512)
mvec = DataStructs.BitVectToFPSText(mbfp)
2. Suchen chemischer Strukturen
Anschließend können wir die Morgan-Fingerabdrücke in Milvus importieren, um eine Datenbank chemischer Strukturen aufzubauen. Mit unterschiedlichen chemischen Fingerabdrücken kann Milvus Substruktursuche, Ähnlichkeitssuche und exakte Suche durchführen.
from milvus import Milvus
Milvus.add_vectors(table_name=MILVUS_TABLE, records=mvecs)
Milvus.search_vectors(table_name=MILVUS_TABLE, query_records=query_mvec, top_k=topk)
Substruktursuche
Prüft, ob eine chemische Struktur eine andere chemische Struktur enthält.
Ähnlichkeitssuche
Sucht nach ähnlichen chemischen Strukturen. Die Tanimoto-Distanz wird standardmäßig als Metrik verwendet.
Exakte Suche
Prüft, ob eine angegebene chemische Struktur existiert. Diese Art der Suche erfordert eine exakte Übereinstimmung.
Berechnung chemischer Fingerabdrücke
Die Tanimoto-Distanz wird häufig als Metrik für chemische Fingerabdrücke verwendet. In Milvus entspricht die Jaccard-Distanz der Tanimoto-Distanz.
 Tabelle zur Berechnung chemischer Fingerabdrücke-1.
Tabelle zur Berechnung chemischer Fingerabdrücke-1.
Basierend auf den vorherigen Parametern kann die Berechnung chemischer Fingerabdrücke wie folgt beschrieben werden:
 Tabelle zur Berechnung chemischer Fingerabdrücke-2.
Tabelle zur Berechnung chemischer Fingerabdrücke-2.
Wir können sehen, dass 1- Jaccard = Tanimoto. Hier verwenden wir Jaccard in Milvus, um den chemischen Fingerabdruck zu berechnen, was tatsächlich mit der Tanimoto-Distanz übereinstimmt.
Systemdemo
Um besser zu demonstrieren, wie das System funktioniert, haben wir eine Demo erstellt, die Milvus verwendet, um mehr als 90 Millionen chemische Fingerabdrücke zu durchsuchen. Die verwendeten Daten stammen von ftp://ftp.ncbi.nlm.nih.gov/pubchem/Compound/CURRENT-Full/SDF. Die anfängliche Oberfläche sieht wie folgt aus:
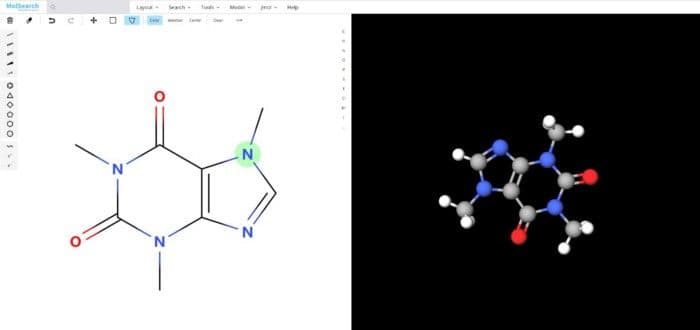 Systemdemo 1.
Systemdemo 1.
Wir können im System nach angegebenen chemischen Strukturen suchen und ähnliche chemische Strukturen zurückgeben:
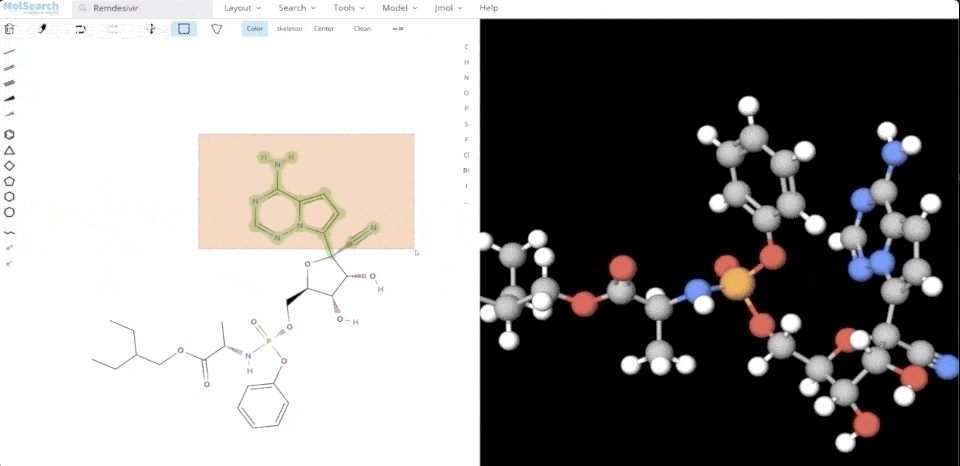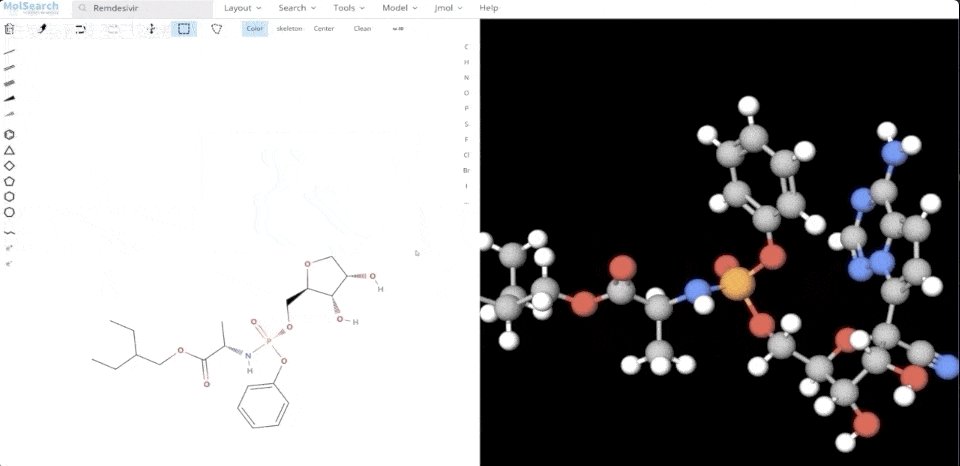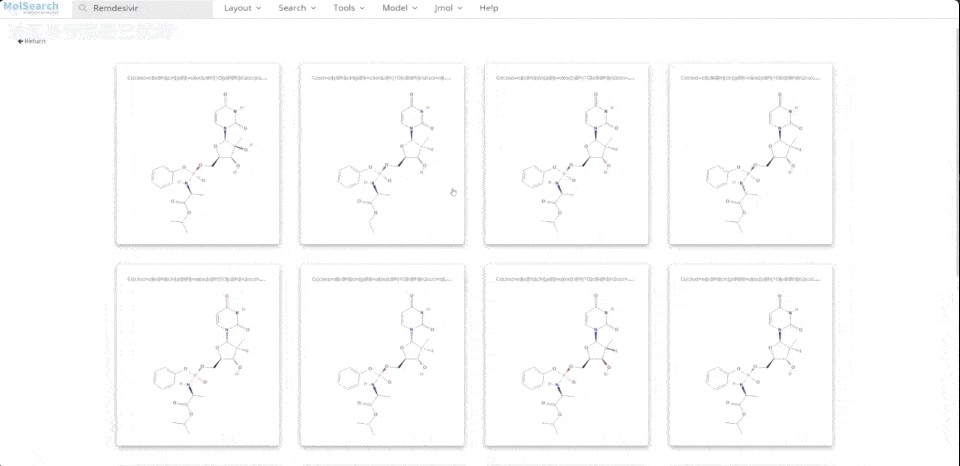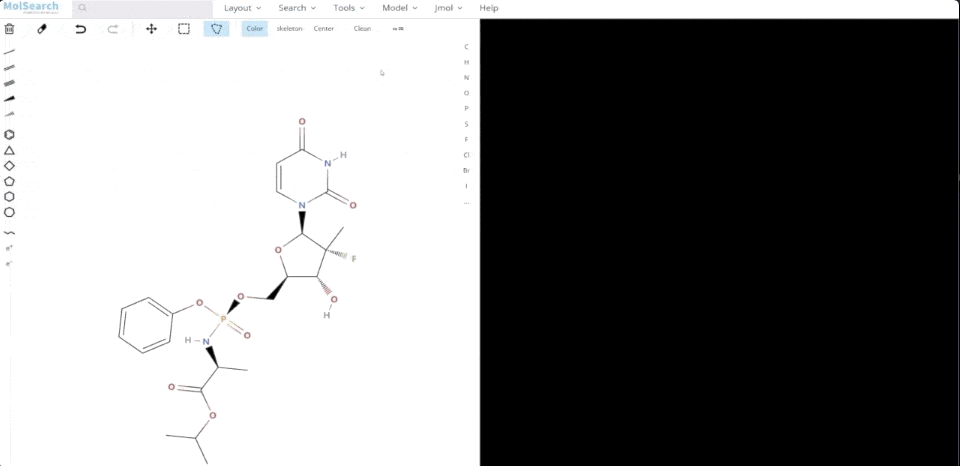 Systemdemo 2.
Systemdemo 2.
Fazit
Ähnlichkeitssuche ist in einer Reihe von Bereichen unverzichtbar, etwa bei Bildern und Videos. In der Wirkstoffforschung kann die Ähnlichkeitssuche auf Datenbanken chemischer Strukturen angewendet werden, um potenziell verfügbare Verbindungen zu entdecken, die anschließend in Ausgangsstoffe für die praktische Synthese und Point-of-Care-Tests umgewandelt werden. Milvus ist eine Open-Source-Ähnlichkeitssuchmaschine für Feature-Vektoren im großen Maßstab und basiert auf einer heterogenen Computing-Architektur für die beste Kosteneffizienz. Suchen über Vektoren im Milliardenmaßstab dauern mit minimalen Rechenressourcen nur Millisekunden. Somit kann Milvus dazu beitragen, eine präzise und schnelle Suche nach chemischen Strukturen in Bereichen wie Biologie und Chemie umzusetzen.
Sie können auf die Demo zugreifen, indem Sie http://40.117.75.127:8002/ besuchen, und vergessen Sie nicht, auch unser GitHub https://github.com/milvus-io/milvus zu besuchen, um mehr zu erfahren!
Weiterlesen

From Vector Database to Vector Lakebase
Zilliz offers a fully managed Vector Lakebase powered by Milvus, unifying real-time vector search, lake-scale discovery, and Al data operations.

Zilliz Cloud Now Available in Azure North Europe: Bringing AI-Powered Vector Search Closer to European Customers
The addition of the Azure North Europe (Ireland) region further expands our global footprint to better serve our European customers.

Balancing Precision and Performance: How Zilliz Cloud's New Parameters Help You Optimize Vector Search
Optimize vector search with Zilliz Cloud’s level and recall features to tune accuracy, balance performance, and power AI applications.