




Aufbau eines Videoanalysesystems mit der Milvus-Vektordatenbank
When ich am letzten Wochenende Free Guy gesehen habe, hatte ich das Gefühl, den Schauspieler, der Buddy, den Sicherheitsmann, spielt, schon irgendwo gesehen zu haben, konnte mich aber an keines seiner Werke erinnern. Mein Kopf war voll mit „Wer ist dieser Typ?“ Ich war mir sicher, dieses Gesicht schon gesehen zu haben, und versuchte angestrengt, mich an seinen Namen zu erinnern. Ein ähnlicher Fall ist, dass ich einmal den Hauptdarsteller in einem Video sah, in dem er ein Getränk trank, das ich früher sehr mochte, aber am Ende konnte ich mich nicht an den Markennamen erinnern.
Die Antwort lag mir auf der Zunge, aber mein Gehirn fühlte sich völlig blockiert an.
Das Tip-of-the-Tongue-Phänomen (TOT) macht mich beim Filmeschauen wahnsinnig. Wenn es doch nur eine Reverse-Image-Search-Engine für Videos gäbe, die es mir ermöglicht, Videos zu finden und Videoinhalte zu analysieren. Zuvor habe ich eine Reverse-Image-Search-Engine mit Milvus erstellt. Da die Analyse von Videoinhalten der Bildanalyse in gewisser Weise ähnelt, beschloss ich, eine auf Milvus basierende Engine zur Analyse von Videoinhalten zu entwickeln.
Objekterkennung
Überblick
Bevor sie analysiert werden, sollten Objekte in einem Video zuerst erkannt werden. Objekte in einem Video effektiv und präzise zu erkennen, ist die größte Herausforderung der Aufgabe. Es ist auch eine wichtige Aufgabe für Anwendungen wie Autopilot, Wearables und IoT.
Von traditionellen Bildverarbeitungsalgorithmen bis hin zu Deep Neural Networks (DNN) entwickelt, umfassen die heutigen Mainstream-Modelle für die Objekterkennung R-CNN, FRCNN, SSD und YOLO. Das in diesem Thema vorgestellte Milvus-basierte Deep-Learning-Videoanalysesystem kann Objekte intelligent und schnell erkennen.
Implementierung
Um Objekte in einem Video zu erkennen und zu identifizieren, sollte das System zunächst Frames aus einem Video extrahieren und Objekte in den Frame-Bildern mithilfe der Objekterkennung erkennen, anschließend Merkmalsvektoren aus den erkannten Objekten extrahieren und schließlich das Objekt anhand der Merkmalsvektoren analysieren.
- Frame-Extraktion
Die Videoanalyse wird mithilfe der Frame-Extraktion in Bildanalyse umgewandelt. Derzeit ist die Frame-Extraktionstechnologie sehr ausgereift. Programme wie FFmpeg und OpenCV unterstützen das Extrahieren von Frames in festgelegten Intervallen. Dieser Artikel stellt vor, wie man mit OpenCV jede Sekunde Frames aus einem Video extrahiert.
- Objekterkennung
Bei der Objekterkennung geht es darum, Objekte in extrahierten Frames zu finden und Screenshots der Objekte entsprechend ihrer Positionen zu extrahieren. Wie in den folgenden Abbildungen gezeigt, wurden ein Fahrrad, ein Hund und ein Auto erkannt. Dieses Thema stellt vor, wie man Objekte mit YOLOv3 erkennt, das häufig für die Objekterkennung verwendet wird.
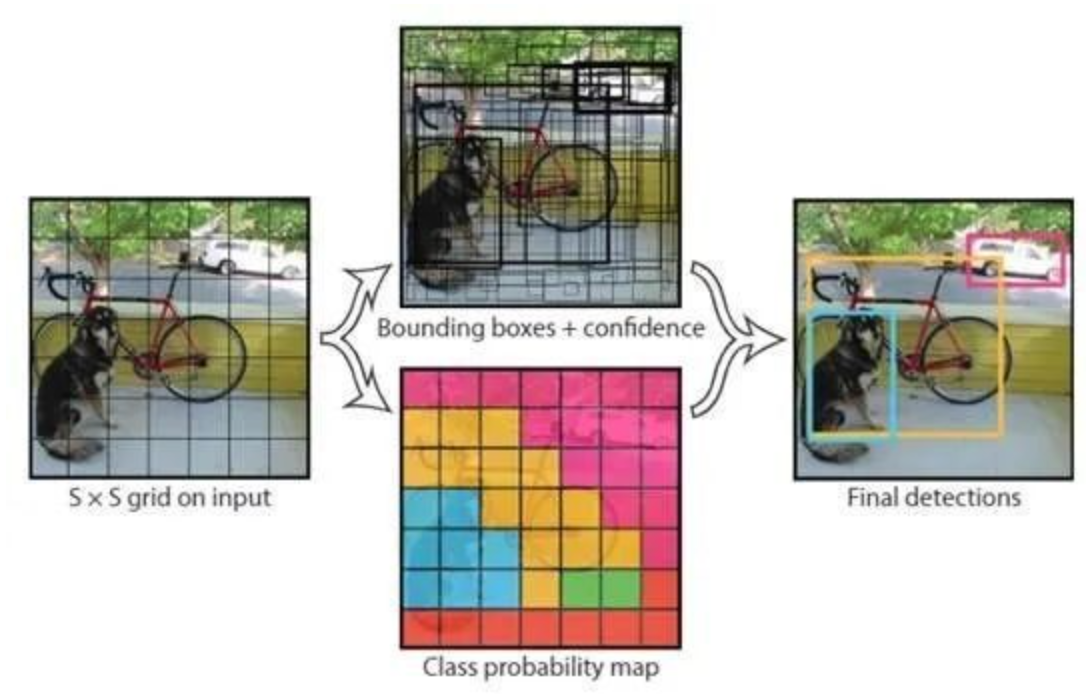 Abbildung 1.
Abbildung 1.
- Merkmalsextraktion
Merkmalsextraktion bezeichnet die Umwandlung unstrukturierter Daten, die für Maschinen schwer zu erkennen sind, in Merkmalsvektoren. Beispielsweise können Bilder mithilfe von Deep-Learning-Modellen in mehrdimensionale Merkmalsvektoren umgewandelt werden. Derzeit gehören VGG, GNN und ResNet zu den beliebtesten KI-Modellen für die Bilderkennung. Dieses Thema stellt vor, wie man mithilfe von ResNet-50 Merkmale aus erkannten Objekten extrahiert.
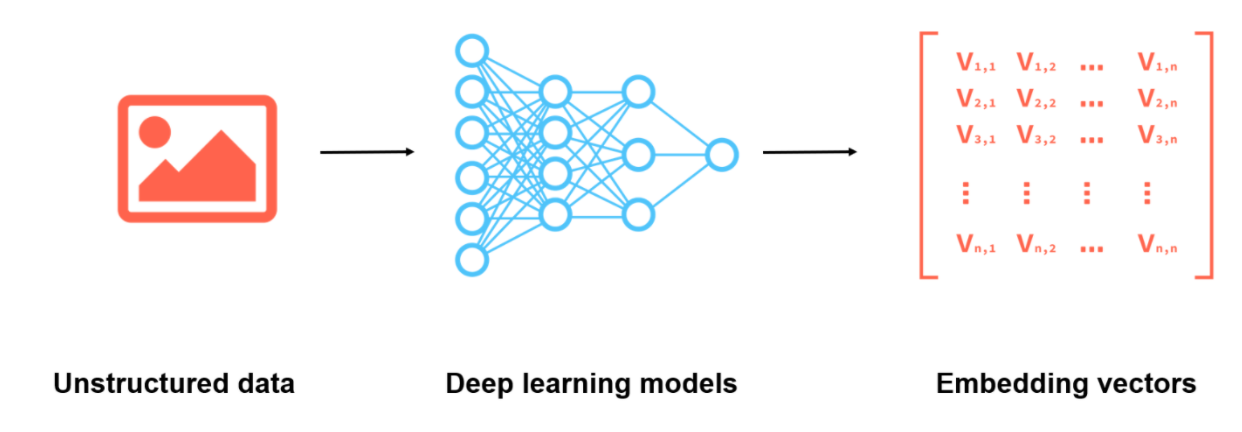 Abbildung 2.
Abbildung 2.
- Vektoranalyse
Extrahierte Merkmalsvektoren werden mit Bibliotheksvektoren verglichen, und die entsprechenden Informationen zu den ähnlichsten Vektoren werden zurückgegeben. Bei groß angelegten Merkmalsvektor-Datensätzen ist die Berechnung eine enorme Herausforderung. Dieses Thema stellt vor, wie man Merkmalsvektoren mit Milvus analysiert.
Schlüsseltechnologien
OpenCV
Open Source Computer Vision Library (OpenCV) ist eine plattformübergreifende Computer-Vision-Bibliothek, die viele universelle Algorithmen für Bildverarbeitung und Computer Vision bereitstellt. OpenCV wird häufig im Bereich Computer Vision eingesetzt.
Das folgende Beispiel zeigt, wie man mit OpenCV und Python Videoframes in festgelegten Intervallen erfasst und als Bilder speichert.
import cv2
cap = cv2.VideoCapture(file_path)
framerate = cap.get(cv2.CAP_PROP_FPS)
allframes = int(cv2.VideoCapture.get(cap, int(cv2.CAP_PROP_FRAME_COUNT)))
success, image = cap.read()
cv2.imwrite(file_name, image)
YOLOv3
You Only Look Once, Version 3 (YOLOv3 [5]) ist ein einstufiger Objekterkennungsalgorithmus, der in den letzten Jahren vorgeschlagen wurde. Im Vergleich zu traditionellen Objekterkennungsalgorithmen mit derselben Genauigkeit ist YOLOv3 doppelt so schnell. Das in diesem Thema erwähnte YOLOv3 ist die erweiterte Version von PaddlePaddle [6]. Es verwendet mehrere Optimierungsmethoden mit einer höheren Inferenzgeschwindigkeit.
ResNet-50
ResNet [7] ist aufgrund seiner Einfachheit und Praxistauglichkeit der Gewinner der ILSVRC 2015 in der Bildklassifizierung. Als Grundlage vieler Bildanalysemethoden erweist sich ResNet als beliebtes Modell, das auf Bilderkennung, Segmentierung und Erkennung spezialisiert ist.
Milvus
Milvus ist eine cloud-native Open-Source-Vektordatenbank, die entwickelt wurde, um von Machine-Learning-Modellen und neuronalen Netzwerken generierte Embedding-Vektoren zu verwalten. Sie wird häufig in Szenarien wie Computer Vision, Verarbeitung natürlicher Sprache, Computerchemie, personalisierten Empfehlungssystemen und mehr eingesetzt.
Die folgenden Verfahren beschreiben, wie Milvus funktioniert.
- Unstrukturierte Daten werden mithilfe von Deep-Learning-Modellen in Merkmalsvektoren umgewandelt und in Milvus importiert.
- Milvus speichert und indiziert die Merkmalsvektoren.
- Milvus gibt die Vektoren zurück, die dem von Benutzern abgefragten Vektor am ähnlichsten sind.
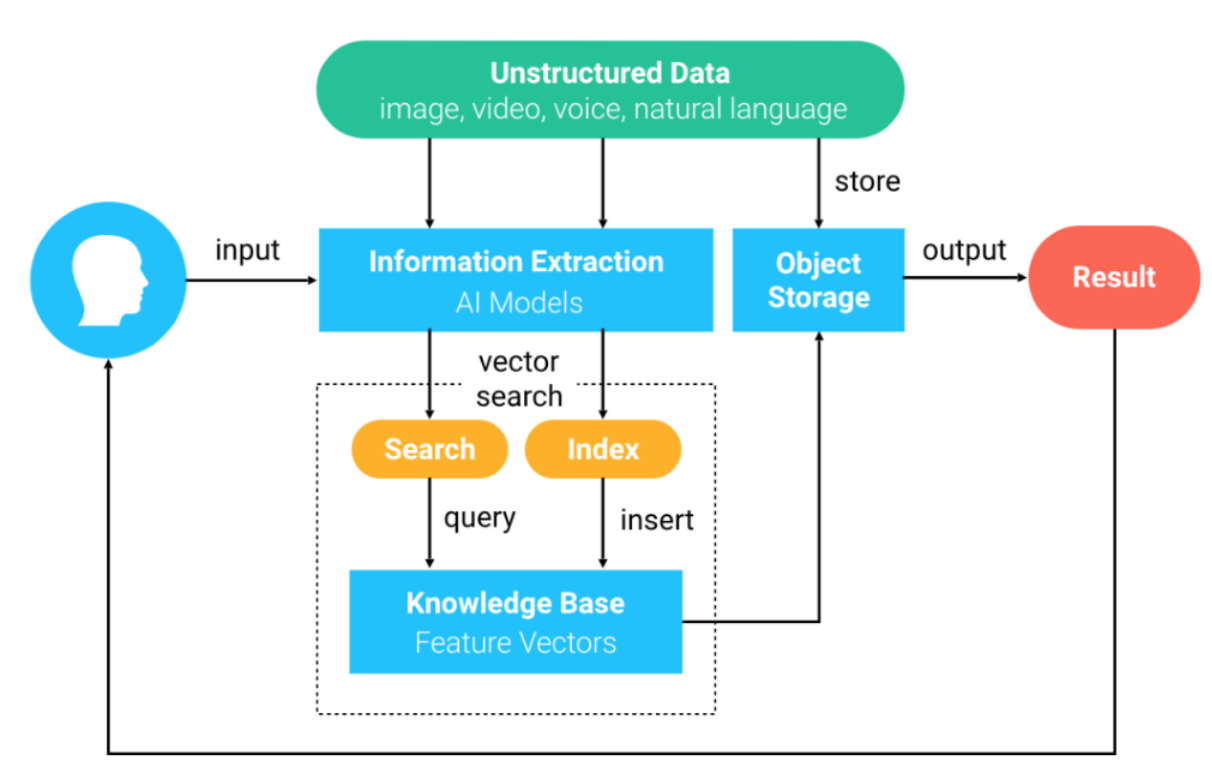 Abbildung 3.
Abbildung 3.
Bereitstellung
Nun haben Sie ein gewisses Verständnis von Milvus-basierten Videoanalysesystemen. Das System besteht hauptsächlich aus zwei Teilen, wie in der folgenden Abbildung dargestellt.
Die roten Pfeile zeigen den Datenimportprozess an. Verwenden Sie ResNet-50, um Merkmalsvektoren aus dem Bilddatensatz zu extrahieren und die Merkmalsvektoren in Milvus zu importieren.
Die schwarzen Pfeile zeigen den Videoanalyseprozess an. Extrahieren Sie zuerst Frames aus einem Video und speichern Sie die Frames als Bilder. Erkennen und extrahieren Sie anschließend Objekte in den Bildern mithilfe von YOLOv3. Verwenden Sie dann ResNet-50, um Merkmalsvektoren aus den Bildern zu extrahieren. Zuletzt sucht Milvus nach den Informationen der Objekte mit den entsprechenden Merkmalsvektoren und gibt sie zurück.
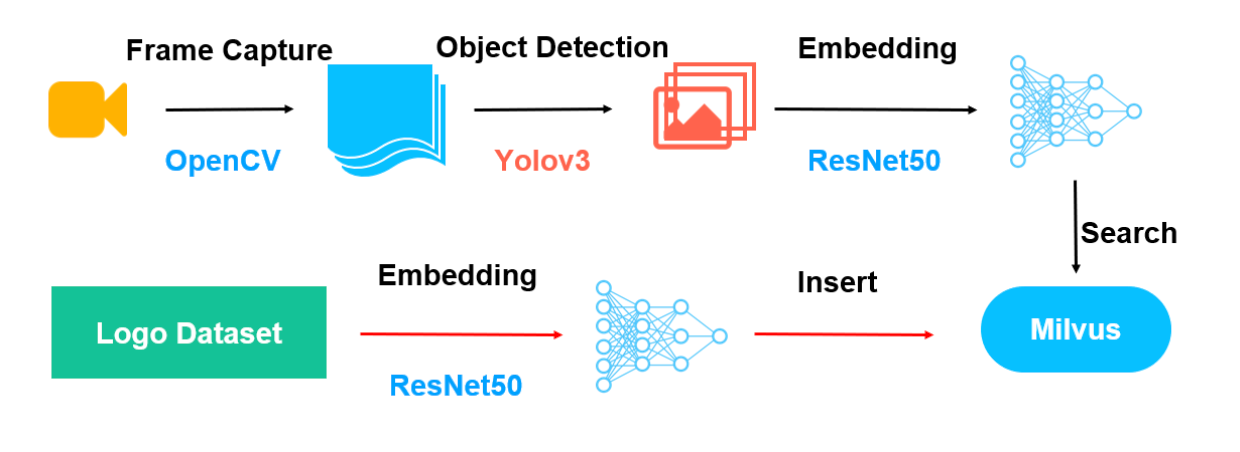 Abbildung 4.
Abbildung 4.
Weitere Informationen finden Sie unter Milvus Bootcamp: Video Object Detection System.
Datenimport
Der Datenimportprozess ist einfach. Konvertieren Sie die Daten in 2.048-dimensionale Vektoren und importieren Sie die Vektoren in Milvus.
vector = image_encoder.execute(filename)
entities = [vector]
collection.insert(data=entities)
Videoanalyse
Wie oben eingeführt, umfasst der Videoanalyseprozess das Erfassen von Videoframes, das Erkennen von Objekten in jedem Frame, das Extrahieren von Vektoren aus den Objekten, das Berechnen der Vektorähnlichkeit mit Metriken der euklidischen Distanz (L2) und das Suchen nach Ergebnissen mithilfe von Milvus.
images = extract_frame(filename, 1, prefix)
detector = Detector()
run(detector, DATA_PATH)
vectors = get_object_vector(image_encoder, DATA_PATH)
search_params = {"metric_type": "L2", "params": {"nprobe": 10}}
results = collection.search(vectors, param=search_params, limit=10)
Fazit
Derzeit sind mehr als 80 % der Daten unstrukturiert. Mit der rasanten Entwicklung der KI wurde eine zunehmende Anzahl von Deep-Learning-Modellen zur Analyse unstrukturierter Daten entwickelt. Technologien wie Objekterkennung und Bildverarbeitung haben sowohl in der Wissenschaft als auch in der Industrie große Durchbrüche erzielt. Gestützt durch diese Technologien haben immer mehr KI-Plattformen praktische Anforderungen erfüllt.
Das in diesem Thema behandelte Videoanalysesystem ist mit Milvus aufgebaut und kann Videoinhalte schnell analysieren.
Als Open-Source-Vektordatenbank unterstützt Milvus Feature-Vektoren, die mit verschiedenen Deep-Learning-Modellen extrahiert wurden. Integriert mit Bibliotheken wie Faiss, NMSLIB und Annoy bietet Milvus eine Reihe intuitiver APIs und unterstützt das Wechseln von Indextypen je nach Szenario. Darüber hinaus unterstützt Milvus skalare Filterung, was die Recall-Rate und die Suchflexibilität erhöht. Milvus wurde in vielen Bereichen eingesetzt, darunter Bildverarbeitung, Computer Vision, Verarbeitung natürlicher Sprache, Spracherkennung, Empfehlungssysteme und die Entdeckung neuer Medikamente.
Referenzen
[1] A. D. Bagdanov, L. Ballan, M. Bertini, A. Del Bimbo. “Trademark matching and retrieval in sports video databases.” Proceedings of the international workshop on Workshop on multimedia information retrieval, ACM, 2007. https://www.researchgate.net/publication/210113141_Trademark_matching_and_retrieval_in_sports_video_databases
[2] J. Kleban, X. Xie, W.-Y. Ma. “Spatial pyramid mining for logo detection in natural scenes.” IEEE International Conference, 2008. https://ieeexplore.ieee.org/document/4607625
[3] R. Boia, C. Florea, L. Florea, R. Dogaru. “Logo localization and recognition in natural images using homographic class graphs.” Machine Vision and Applications 27 (2), 2016. https://link.springer.com/article/10.1007/s00138-015-0741-7
[4] R. Boia, C. Florea, L. Florea. “Elliptical asift agglomeration in class prototype for logo detection.” BMVC, 2015. http://citeseerx.ist.psu.edu/viewdoc/download;jsessionid=5C87F52DE38AB0C90F8340DFEBB841F7?doi=10.1.1.707.9371&rep=rep1&type=pdf
[5] https://arxiv.org/abs/1804.02767
[6] https://paddlepaddle.org.cn/modelbasedetail/yolov3
[7] https://arxiv.org/abs/1512.03385

Weiterlesen

Announcing VDBBench 1.0: Open-Source VectorDB Benchmarking with Your Real-World Production Workloads
Discover VDBBench 1.0, an open-source tool for benchmarking vector databases with real-world production data, streaming ingestion, and concurrent workloads.

Zilliz Cloud Introduces Advanced BYOC-I Solution for Ultimate Enterprise Data Sovereignty
Explore Zilliz Cloud BYOC-I, the solution that balances AI innovation with data control, enabling secure deployments in finance, healthcare, and education sectors.

DeepSeek-VL2: Mixture-of-Experts Vision-Language Models for Advanced Multimodal Understanding
Explore DeepSeek-VL2, the open-source MoE vision-language model. Discover its architecture, efficient training pipeline, and top-tier performance.