




Wie man einen KI-Chatbot mit Milvus und Towhee erstellt
Milvus, eine Open-Source-Vektordatenbank, ist das perfekte Rückgrat für jede KI-Anwendung, die effiziente und skalierbare Vektorsuchfunktionen benötigt, und damit eine herausragende Wahl für das Datenmanagement Ihres Chatbots. Towhee ist ein aufstrebendes Framework für Machine-Learning-Workflows, das den Prozess der Implementierung und Orchestrierung komplexer ML-Modelle vereinfacht. Außerdem macht es die Entwicklung Ihrer Anwendung überschaubar und leicht verständlich.
In diesem Tutorial erfahren Sie, wie Sie mit Python unter Verwendung von Milvus und Towhee einen einfachen KI-Chatbot erstellen. Sie konzentrieren sich darauf, wie Sie unstrukturierte Daten aufnehmen, analysieren, mit Embeddings speichern und Abfragen verarbeiten.
Einrichten Ihrer Umgebung
Erstellen Sie zunächst eine virtuelle Python-Umgebung, um Ihren Chatbot auszuführen.
Hier ist eine Shell-Sitzung von Linux. Sie erstellt die Umgebung, aktiviert sie und aktualisiert pip auf die neueste Version.
[egoebelbecker@ares milvus_chatbot]$ python -m venv ./chatbot_venv
[egoebelbecker@ares milvus_chatbot]$ source chatbot_venv/bin/activate
(chatbot_venv) [egoebelbecker@ares milvus_chatbot]$ pip install --upgrade pip
Requirement already satisfied: pip in ./chatbot_venv/lib64/python3.11/site-packages (22.2.2)
Collecting pip
Using cached pip-23.1.2-py3-none-any.whl (2.1 MB)
Installing collected packages: pip
Attempting uninstall: pip
Found existing installation: pip 22.2.2
Uninstalling pip-22.2.2:
Successfully uninstalled pip-22.2.2
Successfully installed pip-23.1.2
Installieren Sie als Nächstes die Pakete, die Sie zum Ausführen des Codes benötigen: pandas, jupyter, langchain, towhee, unstructured, milvus, pymilvus, sentence_transformers und gradio.
(chatbot_venv) [egoebelbecker@ares milvus_chatbot]$ pip install pandas jupyter langchain towhee unstructured milvus pymilvus sentence_transformers gradio
Sammle pandas
Beziehe Abhängigkeitsinformationen für pandas von https://files.pythonhosted.org/packages/d0/28/88b81881c056376254618fad622a5e94b5126db8c61157ea1910cd1c040a/pandas-2.0.3-cp311-cp311-manylinux_2_17_x86_64.manylinux2014_x86_64.whl.metadata
Verwende zwischengespeicherte pandas-2.0.3-cp311-cp311-manylinux_2_17_x86_64.manylinux2014_x86_64.whl.metadata (18 kB)
Sammle jupyter
Verwende zwischengespeicherte jupyter-1.0.0-py2.py3-none-any.whl (2.7 kB)
(ausgelassen)
Installiere gesammelte Pakete: webencodings, wcwidth, pytz, pure-eval, ptyprocess, pickleshare, json5, ipython-genutils, filetype, fastjsonschema, executing, backcall, zipp, XlsxWriter, xlrd, widgetsnbextension, websocket-client, webcolors, urllib3, uri-template, tzdata, typing-extensions, traitlets, tqdm, tornado, tinycss2, tenacity, tabulate, soupsieve, sniffio, six, send2trash, rpds-py, rfc3986-validator, rfc3986, regex, pyzmq, PyYAML, python-magic, python-json-logger, pypandoc, pygments, pycparser, psutil, prompt-toolkit, prometheus-client, platformdirs, pkginfo, pillow, pexpect, parso, pandocfilters, packaging, overrides, olefile, numpy, nest-asyncio, mypy-extensions, multidict, more-itertools, mistune, mdurl, markupsafe, markdown, lxml, jupyterlab-widgets, jupyterlab-pygments, jsonpointer, joblib, jeepney, idna, greenlet, frozenlist, fqdn, et-xmlfile, docutils, defusedxml, decorator, debugpy, click, charset-normalizer, chardet, certifi, babel, attrs, async-timeout, async-lru, yarl, typing-inspect, terminado, SQLAlchemy, rfc3339-validator, requests, referencing, qtpy, python-pptx, python-docx, python-dateutil, pydantic, pdf2image, openpyxl, numexpr, nltk, msg-parser, matplotlib-inline, marshmallow, markdown-it-py, jupyter-core, jinja2, jedi, jaraco.classes, importlib-metadata, comm, cffi, bleach, beautifulsoup4, asttokens, anyio, aiosignal, stack-data, rich, requests-toolbelt, readme-renderer, pandas, openapi-schema-pydantic, langsmith, jupyter-server-terminals, jupyter-client, jsonschema-specifications, dataclasses-json, cryptography, arrow, argon2-cffi-bindings, aiohttp, SecretStorage, pdfminer.six, langchain, jsonschema, isoduration, ipython, argon2-cffi, unstructured, nbformat, keyring, ipykernel, twine, qtconsole, nbclient, jupyter-events, jupyter-console, ipywidgets, towhee, nbconvert, jupyter-server, notebook-shim, jupyterlab-server, jupyter-lsp, jupyterlab, notebook, jupyter
Erfolgreich installiert: PyYAML-6.0.1 SQLAlchemy-2.0.19 SecretStorage-3.3.3 XlsxWriter-3.1.2 aiohttp-3.8.5 aiosignal-1.3.1 anyio-3.7.1 argon2-cffi-21.3.0 argon2-cffi-bindings-21.2.0 arrow-1.2.3 asttokens-2.2.1 async-lru-2.0.4 async-timeout-4.0.2 attrs-23.1.0 babel-2.12.1 backcall-0.2.0 beautifulsoup4-4.12.2 bleach-6.0.0 certifi-2023.7.22 cffi-1.15.1 chardet-5.1.0 charset-normalizer-3.2.0 click-8.1.6 comm-0.1.3 cryptography-41.0.2 dataclasses-json-0.5.14 debugpy-1.6.7 decorator-5.1.1 defusedxml-0.7.1 docutils-0.20.1 et-xmlfile-1.1.0 executing-1.2.0 fastjsonschema-2.18.0 filetype-1.2.0 fqdn-1.5.1 frozenlist-1.4.0 greenlet-2.0.2 idna-3.4 importlib-metadata-6.8.0 ipykernel-6.25.0 ipython-8.14.0 ipython-genutils-0.2.0 ipywidgets-8.0.7 isoduration-20.11.0 jaraco.classes-3.3.0 jedi-0.19.0 jeepney-0.8.0 jinja2-3.1.2 joblib-1.3.1 json5-0.9.14 jsonpointer-2.4 jsonschema-4.18.4 jsonschema-specifications-2023.7.1 jupyter-1.0.0 jupyter-client-8.3.0 jupyter-console-6.6.3 jupyter-core-5.3.1 jupyter-events-0.7.0 jupyter-lsp-2.2.0 jupyter-server-2.7.0 jupyter-server-terminals-0.4.4 jupyterlab-4.0.3 jupyterlab-pygments-0.2.2 jupyterlab-server-2.24.0 jupyterlab-widgets-3.0.8 keyring-24.2.0 langchain-0.0.248 langsmith-0.0.15 lxml-4.9.3 markdown-3.4.4 markdown-it-py-3.0.0 markupsafe-2.1.3 marshmallow-3.20.1 matplotlib-inline-0.1.6 mdurl-0.1.2 mistune-3.0.1 more-itertools-10.0.0 msg-parser-1.2.0 multidict-6.0.4 mypy-extensions-1.0.0 nbclient-0.8.0 nbconvert-7.7.3 nbformat-5.9.2 nest-asyncio-1.5.7 nltk-3.8.1 notebook-7.0.1 notebook-shim-0.2.3 numexpr-2.8.4 numpy-1.25.2 olefile-0.46 openapi-schema-pydantic-1.2.4 openpyxl-3.1.2 overrides-7.3.1 packaging-23.1 pandas-2.0.3 pandocfilters-1.5.0 parso-0.8.3 pdf2image-1.16.3 pdfminer.six-20221105 pexpect-4.8.0 pickleshare-0.7.5 pillow-10.0.0 pkginfo-1.9.6 platformdirs-3.10.0 prometheus-client-0.17.1 prompt-toolkit-3.0.39 psutil-5.9.5 ptyprocess-0.7.0 pure-eval-0.2.2 pycparser-2.21 pydantic-1.10.12 pygments-2.15.1 pypandoc-1.11 python-dateutil-2.8.2 python-docx-0.8.11 python-json-logger-2.0.7 python-magic-0.4.27 python-pptx-0.6.21 pytz-2023.3 pyzmq-25.1.0 qtconsole-5.4.3 qtpy-2.3.1 readme-renderer-40.0 referencing-0.30.0 regex-2023.6.3 requests-2.31.0 requests-toolbelt-1.0.0 rfc3339-validator-0.1.4 rfc3986-2.0.0 rfc3986-validator-0.1.1 rich-13.5.1 rpds-py-0.9.2 send2trash-1.8.2 six-1.16.0 sniffio-1.3.0 soupsieve-2.4.1 stack-data-0.6.2 tabulate-0.9.0 tenacity-8.2.2 terminado-0.17.1 tinycss2-1.2.1 tornado-6.3.2 towhee-1.1.1 tqdm-4.65.0 traitlets-5.9.0 twine-4.0.2 typing-extensions-4.7.1 typing-inspect-0.9.0 tzdata-2023.3 unstructured-0.8.7 uri-template-1.3.0 urllib3-2.0.4 wcwidth-0.2.6 webcolors-1.13 webencodings-0.5.1 websocket-client-1.6.1 widgetsnbextension-4.0.8 xlrd-2.0.1 yarl-1.9.2 zipp-3.16.2
(chatbot_venv) [egoebelbecker@ares milvus_chatbot]$
Du findest ein Jupyter Notebook mit dem Code für dieses Tutorial hier. Lade es herunter, starte Jupyter und lade das Notebook:
chatbot_venv) [egoebelbecker@ares milvus_chatbot]$ jupyter notebook milvus_chatbot.ipynb
[I 2023-07-31 11:29:01.748 ServerApp] Package notebook took 0.0000s to import
[I 2023-07-31 11:29:01.759 ServerApp] Package jupyter_lsp took 0.0108s to import
[W 2023-07-31 11:29:01.759 ServerApp] A `_jupyter_server_extension_points` function was not found in jupyter_lsp. Instead, a `_jupyter_server_extension_paths` function was found and will be used for now. This function name will be deprecated in future releases of Jupyter Server.
[I 2023-07-31 11:29:01.764 ServerApp] Package jupyter_server_terminals took 0.0045s to import
[I 2023-07-31 11:29:01.765 ServerApp] Package jupyterlab took 0.0000s to import
[I 2023-07-31 11:29:02.124 ServerApp] Package notebook_shim took 0.0000s to import
Einen Chatbot erstellen
Jetzt machen wir uns an die Arbeit am Chatbot.
Dokumentenspeicher
Der Bot muss Dokument-Chunks und die Embeddings speichern, die Towhee daraus extrahiert. Dafür verwendest du Milvus. Du hast Milvus Lite, eine leichtgewichtige Version von Milvus, oben bereits mit der milvus-Bibliothek installiert.
Du kannst einen Server über die Befehlszeile ausführen:
(chatbot_venv) [egoebelbecker@ares milvus_chatbot]$ milvus-server
__ _________ _ ____ ______
/ |/ / _/ /| | / / / / / __/
/ /|_/ // // /_| |/ / /_/ /\ \
/_/ /_/___/____/___/\____/___/ {Lite}
Welcome to use Milvus!
Version: v2.2.12-lite
Process: 139309
Started: 2023-07-31 12:43:43
Config: /home/egoebelbecker/.milvus.io/milvus-server/2.2.12/configs/milvus.yaml
Logs: /home/egoebelbecker/.milvus.io/milvus-server/2.2.12/logs
Ctrl+C to exit …
Oder als Teil deines Anwendungscodes, wie im Notebook gezeigt:
from milvus import default_server
# Start Milvus service
default_server.start()
# # Stop Milvus service
# default_server.stop()
Anwendungsvariablen festlegen und OpenAI API Key abrufen
Lege als Nächstes einige Variablen fest und bereinige alle verbleibenden SQLite-Dateien. Wir verwenden unten SQLite für den Chatverlauf.
- MILVUS_URI - die Verbindungsinformationen für die Milvus-Server. In Host und Port geparst.
- MILVUS_HOST - der Host, auf dem Milvus läuft.
- MILVUS_PORT - der Port, auf dem der Server lauscht.
- DROP_EXIST - vorhandene Milvus-Sammlungen beim Start löschen.
- EMBED_MODEL - das sentence_transformers-Modell, das der Code zum Erstellen von Embeddings verwendet
- COLLECTION_NAME - Name der Milvus-Sammlung für Daten und Embeddings
- DIM - die Dimension der Embeddings, die das Modell für jedes Textstück erstellt
- OPENAI_API_KEY - Schlüssel für die LLM-API
import getpass
import os
MILVUS_URI = 'http://localhost:19530'
[MILVUS_HOST, MILVUS_PORT] = MILVUS_URI.split('://')[1].split(':')
DROP_EXIST = True
EMBED_MODEL = 'all-mpnet-base-v2'
COLLECTION_NAME = 'chatbot_demo'
DIM = 768
OPENAI_API_KEY = getpass.getpass('Enter your OpenAI API key: ')
if os.path.exists('./sqlite.db'):
os.remove('./sqlite.db')
Führe diesen Code aus, um die Variablen zu definieren, und beantworte die Eingabeaufforderung für den API-Schlüssel.
Beispiel-Pipeline
Als Nächstes ist es an der Zeit, einige Daten herunterzuladen und in Milvus zu speichern. Doch bevor du das tust, sehen wir uns eine Beispiel-Pipeline zum Herunterladen und Verarbeiten unstrukturierter Daten an.
Für dieses Beispiel verwendest du die Towhee-Dokumentationsseiten. Du kannst verschiedene Websites ausprobieren, um zu sehen, wie der Code unterschiedliche Datensätze verarbeitet.
Dieser Code verwendet Towhee-Pipelines:
- input - beginnt eine neue Pipeline mit der an sie übergebenen Quelle
- map - verwendet ops.text_loader(), um die URL abzurufen und sie auf 'doc' abzubilden
- flat_map - verwendet ops.text_splitter(), um das Dokument zur Speicherung in „Chunks“ zu verarbeiten
- output - schließt die Pipeline und bereitet sie für die Verwendung vor
Übergib diese Pipeline an DataCollection, um zu sehen, wie sie funktioniert.
from towhee import pipe, ops, DataCollection
pipe_load = (
pipe.input('source')
.map('source', 'doc', ops.text_loader())
.flat_map('doc', 'doc_chunks', ops.text_splitter(chunk_size=300))
.output('source', 'doc_chunks')
)
DataCollection(pipe_load('https://towhee.io')).show()
Hier ist die Ausgabe von show():

Die Pipeline hat fünf Chunks aus dem Dokument erstellt.
Beispiel-Embedding-Pipeline
Die Pipeline hat die Daten abgerufen und Chunks erstellt. Du musst auch Embeddings erstellen. Schauen wir uns eine weitere Beispiel-Pipeline an.
Diese verwendet map(), um ops.sentence_embedding.sbert() für jeden Chunk auszuführen. In diesem Beispiel übergeben wir einen einzelnen Textblock.
pipe_embed = (
pipe.input('doc_chunk')
.map('doc_chunk', 'vec', ops.sentence_embedding.sbert(model_name=EMBED_MODEL))
.map('vec', 'vec', ops.np_normalize())
.output('doc_chunk', 'vec')
)
text = '''SOTA Models
We provide 700+ pre-trained embedding models spanning 5 fields (CV, NLP, Multimodal, Audio, Medical), 15 tasks, and 140+ model architectures.
These include BERT, CLIP, ViT, SwinTransformer, data2vec, etc.
'''
DataCollection(pipe_embed(text)).show()
Führe diesen Code aus, um zu sehen, wie die Pipeline den einzelnen Textblock verarbeitet.

Milvus vorbereiten
Jetzt benötigst du eine Collection, um die Daten zu speichern. Dieser Block definiert create_collection(), das MILVUS_HOST und MILVUS_PORT verwendet, um eine Verbindung zu Milvus herzustellen, alle vorhandenen Collections mit dem angegebenen Namen zu löschen und eine neue mit diesem Schema zu erstellen:
- id - eine ganzzahlige Kennung
- embedding - ein Vektor aus Floats für die Embeddings
- text - der entsprechende Text für die Embeddings
from pymilvus import (
connections, utility, Collection,
CollectionSchema, FieldSchema, DataType
)
def create_collection(collection_name):
connections.connect(host=MILVUS_HOST, port=MILVUS_PORT)
has_collection = utility.has_collection(collection_name)
if has_collection:
collection = Collection(collection_name)
if DROP_EXIST:
collection.drop()
else:
return collection
# Create collection
fields = [
FieldSchema(name='id', dtype=DataType.INT64, is_primary=True, auto_id=True),
FieldSchema(name='embedding', dtype=DataType.FLOAT_VECTOR, dim=DIM),
FieldSchema(name='text', dtype=DataType.VARCHAR, max_length=500)
]
schema = CollectionSchema(
fields=fields,
description="Towhee demo",
enable_dynamic_field=True
)
collection = Collection(name=collection_name, schema=schema)
index_params = {
'metric_type': 'IP',
'index_type': 'IVF_FLAT',
'params': {'nlist': 1024}
}
collection.create_index(
field_name='embedding',
index_params=index_params
)
return collection
Einfüge-Pipeline
Es ist Zeit, deinen Eingabetext zu verarbeiten und ihn in Milvus einzufügen. Beginnen wir mit einer Pipeline, die das zusammenfasst, was du oben gelernt hast.
Diese Funktion:
- Erstellt die neue Collection
- Ruft die Daten ab
- Teilt sie in Chunks auf
- Erstellt Embeddings mit EMBED_MODEL
- Fügt den Text und die Embeddings in Milvus ein
load_data = (
pipe.input('collection_name', 'source')
.map('collection_name', 'collection', create_collection)
.map('source', 'doc', ops.text_loader())
.flat_map('doc', 'doc_chunk', ops.text_splitter(chunk_size=300))
.map('doc_chunk', 'vec', ops.sentence_embedding.sbert(model_name=EMBED_MODEL))
.map('vec', 'vec', ops.np_normalize())
.map(('collection_name', 'vec', 'doc_chunk'), 'mr',
ops.ann_insert.osschat_milvus(host=MILVUS_HOST, port=MILVUS_PORT))
.output('mr')
)
Hier ist sie in Aktion. Führe sie gegen die Wikipedia-Seite für Frodo Baggins aus.
project_name = 'towhee_demo'
data_source = 'https://en.wikipedia.org/wiki/Frodo_Baggins'
mr = load_data(COLLECTION_NAME, data_source)
print('Doc chunks inserted:', len(mr.to_list()))
Es fügt 408 Chunks mit Embeddings ein:
2023-07-31 16:50:53,369 - 139993906521792 - node.py-node:167 - INFO: Begin to run Node-_input
2023-07-31 16:50:53,371 - 139993906521792 - node.py-node:167 - INFO: Begin to run Node-create_collection-0
2023-07-31 16:50:53,373 - 139993881343680 - node.py-node:167 - INFO: Begin to run Node-text-loader-1
2023-07-31 16:50:53,374 - 139993898129088 - node.py-node:167 - INFO: Begin to run Node-text-splitter-2
2023-07-31 16:50:53,376 - 139993872950976 - node.py-node:167 - INFO: Begin to run Node-sentence-embedding/sbert-3
2023-07-31 16:50:53,377 - 139993385268928 - node.py-node:167 - INFO: Begin to run Node-np-normalize-4
2023-07-31 16:50:53,378 - 139993376876224 - node.py-node:167 - INFO: Begin to run Node-ann-insert/osschat-milvus-5
2023-07-31 16:50:53,379 - 139993368483520 - node.py-node:167 - INFO: Begin to run Node-_output
(snip)
Categories:
2023-07-31 18:07:53,530 - 140552729257664 - logger.py-logger:14 - DETAIL: Skipping sentence because does not exceed 5 word tokens
Categories
2023-07-31 18:07:53,532 - 140552729257664 - logger.py-logger:14 - DETAIL: Skipping sentence because does not exceed 3 word tokens
Hidden categories
2023-07-31 18:07:53,533 - 140552729257664 - logger.py-logger:14 - DETAIL: Skipping sentence because does not exceed 3 word tokens
Hidden categories
2023-07-31 18:07:53,533 - 140552729257664 - logger.py-logger:14 - DETAIL: Not narrative. Text does not contain a verb:
Hidden categories:
2023-07-31 18:07:53,534 - 140552729257664 - logger.py-logger:14 - DETAIL: Skipping sentence because does not exceed 5 word tokens
Hidden categories
Doc chunks inserted: 408
Wissensdatenbank durchsuchen
Jetzt, da die Embeddings und der Text in Milvus gespeichert sind, kannst du sie durchsuchen.
Diese Funktion erstellt eine Abfrage-Pipeline. Der wichtigste Schritt ist dieser:
ops.ann_search.osschat_milvus(host=MILVUS_HOST, port=MILVUS_PORT,
**{'metric_type': 'IP', 'limit': 3, 'output_fields': ['text']}))
osschat_milvus durchsucht die Embeddings nach Übereinstimmungen mit dem übermittelten Text.
Hier ist die gesamte Pipeline:
pipe_search = (
pipe.input('collection_name', 'query')
.map('query', 'query_vec', ops.sentence_embedding.sbert(model_name=EMBED_MODEL))
.map('query_vec', 'query_vec', ops.np_normalize())
.map(('collection_name', 'query_vec'), 'search_res',
ops.ann_search.osschat_milvus(host=MILVUS_HOST, port=MILVUS_PORT,
**{'metric_type': 'IP', 'limit': 3, 'output_fields': ['text']}))
.flat_map('search_res', ('id', 'score', 'text'), lambda x: (x[0], x[1], x[2]))
.output('query', 'text', 'score')
)
Probiere es aus:
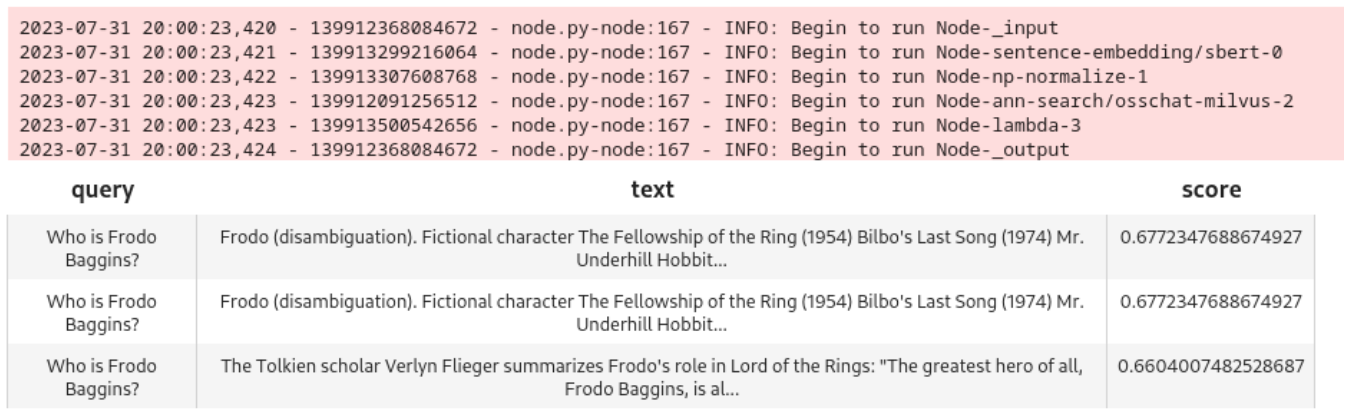
query = 'Who is Frodo Baggins?'
DataCollection(pipe_search(project_name, query)).show()
Das Modell leistet gute Arbeit und ruft drei eng passende Knoten ab:
Ein LLM hinzufügen
Jetzt ist es an der Zeit, ein Large Language Model (LLM) hinzuzufügen, damit Benutzer eine Unterhaltung mit dem Chatbot führen können. Für dieses Beispiel verwenden wir ChatGPT und die OpenAI API.
Chatverlauf
Um bessere Ergebnisse vom LLM zu erhalten, musst du den Chatverlauf speichern und ihn zusammen mit Abfragen bereitstellen. Für diesen Schritt verwendest du SQLite.
Hier ist eine Funktion zum Abrufen des Verlaufs:
pipe_get_history = (
pipe.input('collection_name', 'session')
.map(('collection_name', 'session'), 'history', ops.chat_message_histories.sql(method='get'))
.output('collection_name', 'session', 'history')
)
Hier ist die zum Speichern:
pipe_add_history = (
pipe.input('collection_name', 'session', 'question', 'answer')
.map(('collection_name', 'session', 'question', 'answer'), 'history', ops.chat_message_histories.sql(method='add'))
.output('history')
)
LLM-Abfragepipeline
Jetzt benötigen wir eine Pipeline, um Abfragen an ChatGPT zu senden.
Diese Pipeline:
- durchsucht Milvus mithilfe der Abfrage des Benutzers
- sammelt den aktuellen Chatverlauf
- sendet die Abfrage, die Milvus-Suche und den Chatverlauf an ChatGPT
- Fügt das ChatGPT-Ergebnis dem Chatverlauf hinzu
- Gibt das Ergebnis an den Aufrufer zurück
chat = (
pipe.input('collection_name', 'query', 'session')
.map('query', 'query_vec', ops.sentence_embedding.sbert(model_name=EMBED_MODEL))
.map('query_vec', 'query_vec', ops.np_normalize())
.map(('collection_name', 'query_vec'), 'search_res',
ops.ann_search.osschat_milvus(host=MILVUS_HOST,
port=MILVUS_PORT,
**{'metric_type': 'IP', 'limit': 3, 'output_fields': ['text']}))
.map('search_res', 'knowledge', lambda y: [x[2] for x in y])
.map(('collection_name', 'session'), 'history', ops.chat_message_histories.sql(method='get'))
.map(('query', 'knowledge', 'history'), 'messages', ops.prompt.question_answer())
.map('messages', 'answer', ops.LLM.OpenAI(api_key=OPENAI_API_KEY,
model_name='gpt-3.5-turbo',
temperature=0.8))
.map(('collection_name', 'session', 'query', 'answer'), 'new_history', ops.chat_message_histories.sql(method='add'))
.output('query', 'history', 'answer', )
)
Testen wir diese Pipeline, bevor wir sie mit einer GUI verbinden:
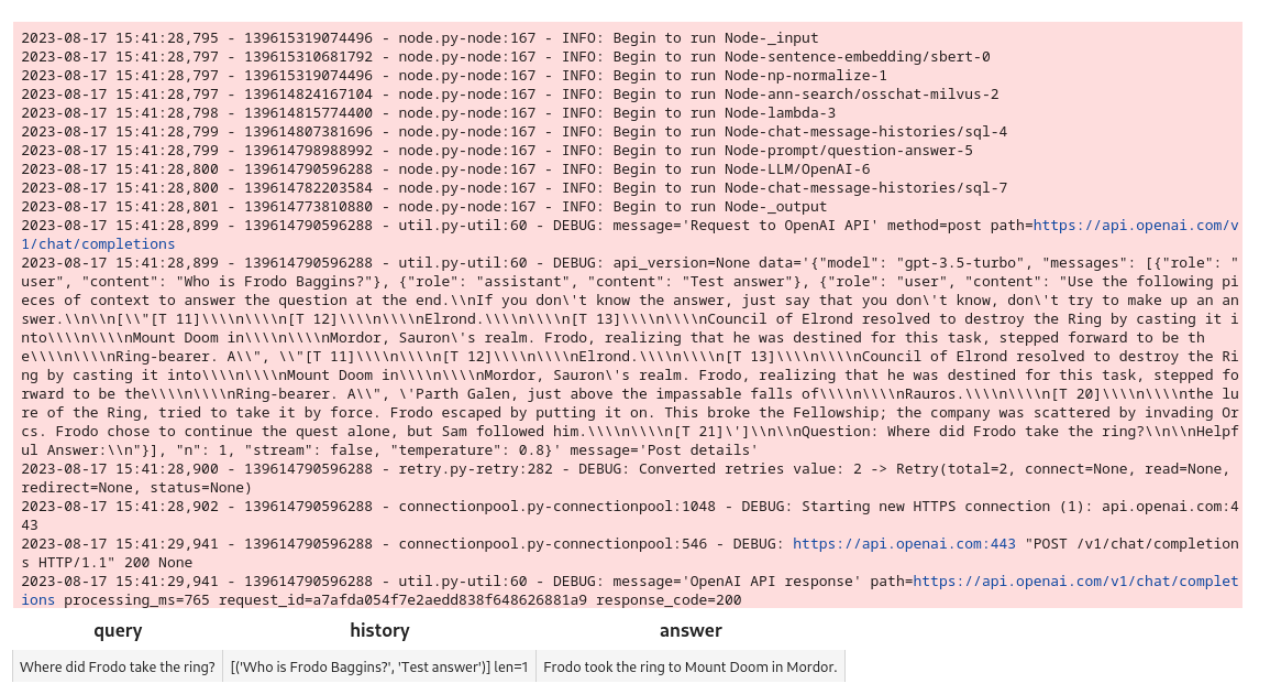
new_query = 'Where did Frodo take the ring?'
DataCollection(chat(COLLECTION_NAME, new_query, session_id)).show()
Hier sind die Ausgabe und Ergebnisse im Notebook:
Die Pipeline funktioniert. Stellen wir eine Gradio-Oberfläche zusammen.
Gradio-GUI
Zuerst benötigen Sie Funktionen, um eine Sitzungskennung zu erstellen und auf Abfragen aus der Oberfläche zu antworten.
Diese Funktionen erstellen eine Sitzungs-ID mithilfe einer UUID und akzeptieren eine Sitzung und eine Abfrage für die Abfragepipeline.
import uuid
import io
def create_session_id():
uid = str(uuid.uuid4())
suid = ''.join(uid.split('-'))
return 'sess_' + suid
def respond(session, query):
res = chat(COLLECTION_NAME, query, session).get_dict()
answer = res['answer']
response = res['history']
response.append((query, answer))
return response
Als Nächstes verwendet die Gradio-Oberfläche diese Funktionen, um einen Chatbot zu erstellen.
Sie verwendet die Blocks API, um eine ChatBot-Oberfläche zu erstellen. Die Schaltfläche Send Message verwendet die Funktion respond, um Anfragen an ChatGPT zu senden.
import gradio as gr
with gr.Blocks() as demo:
session_id = gr.State(create_session_id)
with gr.Row():
with gr.Column(scale=2):
gr.Markdown('''## Chat''')
conversation = gr.Chatbot(label='conversation').style(height=300)
question = gr.Textbox(label='question', value=None)
send_btn = gr.Button('Send Message')
send_btn.click(
fn=respond,
inputs=[
session_id,
question
],
outputs=conversation,
)
demo.launch(server_name='127.0.0.1', server_port=8902)
Hier ist sie:
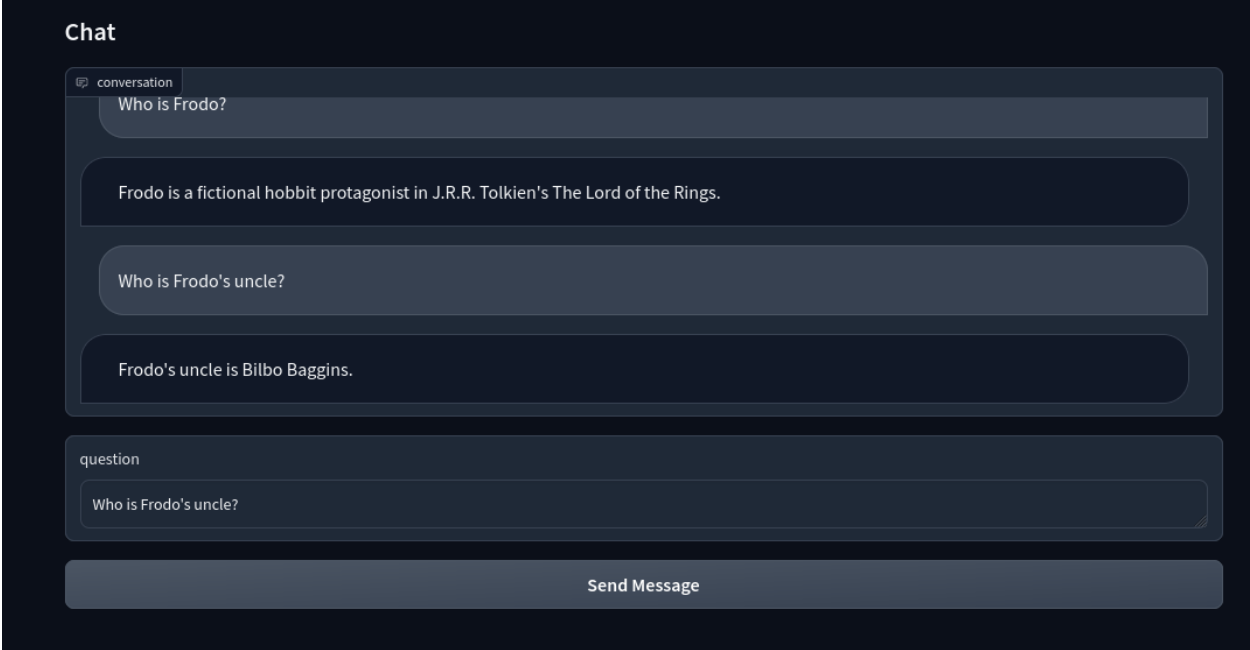
Jetzt haben Sie einen LLM-basierten intelligenten Chatbot mit Milvus!
Zusammenfassung
In diesem Beitrag haben wir Towhee-Pipelines erstellt, um unstrukturierte Daten aufzunehmen, sie für Embeddings zu verarbeiten und diese Embeddings in Milvus zu speichern. Anschließend haben wir eine Abfragepipeline für die Chatfunktion erstellt und den Chatbot mit einem LLM verbunden. Schließlich erhielten wir einen intelligenten Chatbot.
Dieses Tutorial zeigt, wie einfach es ist, Anwendungen mit Milvus zu erstellen. Milvus bietet zahlreiche Vorteile, wenn es in Anwendungen integriert wird, insbesondere in solchen, die auf maschinellem Lernen und künstlicher Intelligenz basieren. Es bietet hocheffiziente, skalierbare und zuverlässige Funktionen für die Vektorähnlichkeitssuche und -analyse, die in Anwendungen wie Chatbots, Empfehlungssystemen sowie Bild- oder Texterkennung entscheidend sind.
Dieser Beitrag wurde von Eric Goebelbecker verfasst. Eric arbeitet seit 25 Jahren in den Finanzmärkten in New York City und entwickelt Infrastruktur für Marktdaten- und Financial Information Exchange (FIX)-Protokollnetzwerke. Er spricht gerne darüber, was Teams effektiv (oder nicht so effektiv!) macht.

Weiterlesen

Notion's Vector Search Is Excellent. Their Next Problem Is Harder.
Notion solved vector search scaling in two years. The next bottleneck — offline context engineering, unified data, and the real-time/offline gap — is harder.

Zilliz Cloud Now Available in Azure North Europe: Bringing AI-Powered Vector Search Closer to European Customers
The addition of the Azure North Europe (Ireland) region further expands our global footprint to better serve our European customers.

Creating Collections in Zilliz Cloud Just Got Way Easier
We've enhanced the entire collection creation experience to bring advanced capabilities directly into the interface, making it faster and easier to build production-ready schemas without switching tools.