




Aufbau eines graphbasierten Empfehlungssystems mit Milvus, PinSage, DGL und MovieLens-Datensätzen
Empfehlungssysteme werden von Algorithmen angetrieben, die bescheidene Anfänge hatten und Menschen dabei halfen, unerwünschte E-Mails auszusortieren. Im Jahr 1990 verwendete der Erfinder Doug Terry einen Collaborative-Filtering-Algorithmus, um erwünschte E-Mails von Junk-Mails zu trennen. Indem Nutzer eine E-Mail einfach „likten“ oder „hassten“ und dabei mit anderen zusammenarbeiteten, die dasselbe mit ähnlichen Mail-Inhalten taten, konnten sie Computer schnell darauf trainieren, zu bestimmen, was in den Posteingang eines Nutzers weitergeleitet werden sollte – und was in den Junk-Mail-Ordner verschoben werden sollte.
Im Allgemeinen sind Empfehlungssysteme Algorithmen, die Nutzern relevante Vorschläge machen. Vorschläge können Filme zum Anschauen, Bücher zum Lesen, Produkte zum Kaufen oder je nach Szenario oder Branche alles Mögliche sein. Diese Algorithmen sind überall um uns herum und beeinflussen die Inhalte, die wir konsumieren, sowie die Produkte, die wir bei großen Technologieunternehmen wie Youtube, Amazon, Netflix und vielen anderen kaufen.
Gut konzipierte Empfehlungssysteme können wesentliche Umsatztreiber, Kostensenker und Wettbewerbsvorteile sein. Dank Open-Source-Technologie und sinkender Rechenkosten waren maßgeschneiderte Empfehlungssysteme noch nie so zugänglich. Dieser Artikel erklärt, wie man Milvus, eine Open-Source-Vektordatenbank; PinSage, ein graph convolutional neural network (GCN); deep graph library (DGL), ein skalierbares Python-Paket für Deep Learning auf Graphen; und MovieLens-Datensätze verwendet, um ein graphbasiertes Empfehlungssystem zu erstellen.
Direkt zu:
- Wie funktionieren Empfehlungssysteme?
- Tools zum Aufbau eines Empfehlungssystems
- Aufbau eines graphbasierten Empfehlungssystems mit Milvus
Wie funktionieren Empfehlungssysteme?
Es gibt zwei gängige Ansätze zum Aufbau von Empfehlungssystemen: kollaboratives Filtern und inhaltsbasiertes Filtern. Die meisten Entwickler verwenden eine oder beide Methoden, und obwohl Empfehlungssysteme in Komplexität und Aufbau variieren können, enthalten sie typischerweise drei Kernelemente:
- Nutzermodell: Empfehlungssysteme erfordern die Modellierung von Nutzermerkmalen, Präferenzen und Bedürfnissen. Viele Empfehlungssysteme stützen ihre Vorschläge auf implizite oder explizite Eingaben von Nutzern auf Artikelebene.
- Objektmodell: Empfehlungssysteme modellieren auch Artikel, um auf Basis von Nutzerprofilen Artikelempfehlungen auszusprechen.
- Empfehlungsalgorithmus: Die Kernkomponente jedes Empfehlungssystems ist der Algorithmus, der seine Empfehlungen antreibt. Häufig verwendete Algorithmen umfassen kollaboratives Filtern, implizite semantische Modellierung, graphbasierte Modellierung, kombinierte Empfehlung und mehr.
Auf hoher Ebene erstellen Empfehlungssysteme, die auf kollaborativem Filtern basieren, ein Modell aus früherem Nutzerverhalten (einschließlich Verhaltenseingaben ähnlicher Nutzer), um vorherzusagen, woran ein Nutzer interessiert sein könnte. Systeme, die auf inhaltsbasiertem Filtern basieren, verwenden diskrete, vordefinierte Tags auf Grundlage von Artikelmerkmalen, um ähnliche Artikel zu empfehlen.
Ein Beispiel für kollaboratives Filtern wäre ein personalisierter Radiosender auf Spotify, der auf dem Hörverlauf, den Interessen, der Musikbibliothek eines Nutzers und mehr basiert. Der Sender spielt Musik, die der Nutzer nicht gespeichert oder an der er anderweitig Interesse bekundet hat, die aber andere Nutzer mit ähnlichem Geschmack häufig hören. Ein Beispiel für inhaltsbasiertes Filtern wäre ein Radiosender, der auf einem bestimmten Song oder Künstler basiert und Attribute der Eingabe verwendet, um ähnliche Musik zu empfehlen.
Tools zum Aufbau eines Empfehlungssystems
In diesem Beispiel hängt der Aufbau eines graphbasierten Empfehlungssystems von Grund auf von den folgenden Tools ab:
Pinsage: Ein graph convolutional network
PinSage ist ein Random-Walk-Graph-Convolutional-Network, das Embeddings für Knoten in Web-Scale-Graphen mit Milliarden von Objekten lernen kann. Das Netzwerk wurde von Pinterest, einem Online-Pinnwand-Unternehmen, entwickelt, um seinen Nutzern thematische visuelle Empfehlungen anzubieten.
Pinterest-Nutzer können Inhalte, die sie interessieren, an "Pinnwände" "pinnen", bei denen es sich um Sammlungen gepinnter Inhalte handelt. Mit über 478 Millionen monatlich aktiven Nutzern (MAU) und über 240 Milliarden gespeicherten Objekten verfügt das Unternehmen über eine enorme Menge an Nutzerdaten, mit denen es Schritt halten muss, indem es neue Technologien entwickelt.
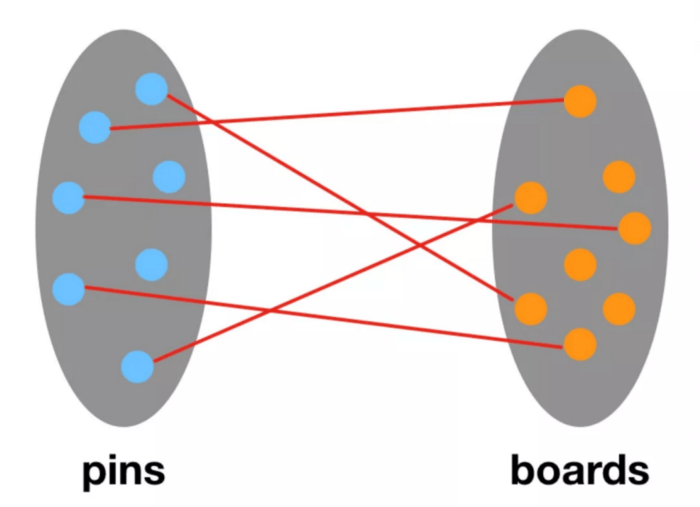 Bipartiter Pins-Pinnwände-Graph.
Bipartiter Pins-Pinnwände-Graph.
PinSage verwendet bipartite Pins-Pinnwände-Graphen, um hochwertige Embeddings aus Pins zu generieren, die verwendet werden, um Nutzern visuell ähnliche Inhalte zu empfehlen. Im Gegensatz zu traditionellen GCN-Algorithmen, die Faltungen auf den Feature-Matrizen und dem vollständigen Graphen durchführen, sampelt PinSage die nahegelegenen Knoten/Pins und führt effizientere lokale Faltungen durch die dynamische Konstruktion von Berechnungsgraphen durch.
Das Durchführen von Faltungen auf der gesamten Nachbarschaft eines Knotens führt zu einem massiven Berechnungsgraphen. Um den Ressourcenbedarf zu reduzieren, aktualisieren traditionelle GCN-Algorithmen die Repräsentation eines Knotens, indem sie Informationen aus seiner k-Hop-Nachbarschaft aggregieren. PinSage simuliert Random-Walk, um häufig besuchte Inhalte als die zentrale Nachbarschaft festzulegen, und konstruiert anschließend darauf basierend eine Faltung.
Da es in k-Hop-Nachbarschaften häufig Überschneidungen gibt, führt lokale Faltung auf Knoten zu wiederholter Berechnung. Um dies zu vermeiden, bildet PinSage in jedem Aggregationsschritt alle Knoten ohne wiederholte Berechnung ab, verknüpft sie dann mit den entsprechenden Knoten der oberen Ebene und ruft schließlich die Embeddings der Knoten der oberen Ebene ab.
Deep Graph Library: Ein skalierbares Python-Paket für Deep Learning auf Graphen
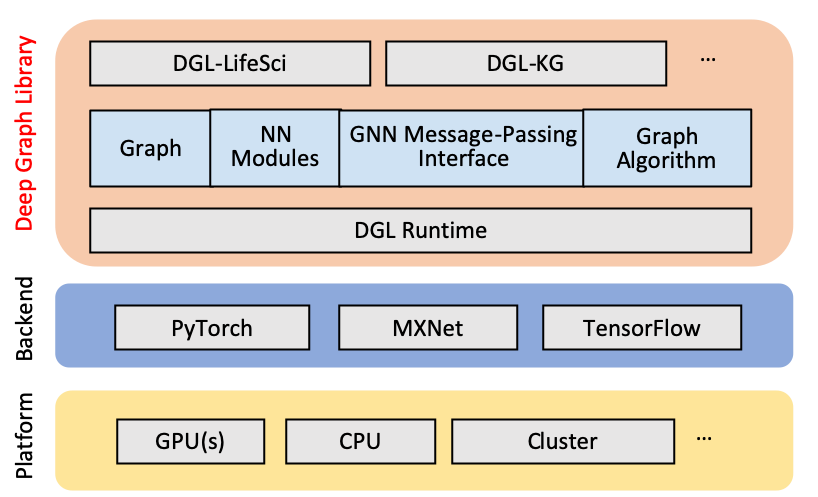 DGL-Framework.
DGL-Framework.
Deep Graph Library (DGL) ist ein Python-Paket, das für den Aufbau graphbasierter neuronaler Netzwerkmodelle auf bestehenden Deep-Learning-Frameworks (z. B. PyTorch, MXNet, Gluon und mehr) entwickelt wurde. DGL umfasst eine benutzerfreundliche Backend-Schnittstelle, wodurch es leicht in Frameworks zu integrieren ist, die auf Tensoren basieren und automatische Generierung unterstützen. Der oben erwähnte PinSage-Algorithmus ist für die Verwendung mit DGL und PyTorch optimiert.
Milvus: Eine Open-Source-Vektordatenbank für KI und Ähnlichkeitssuche
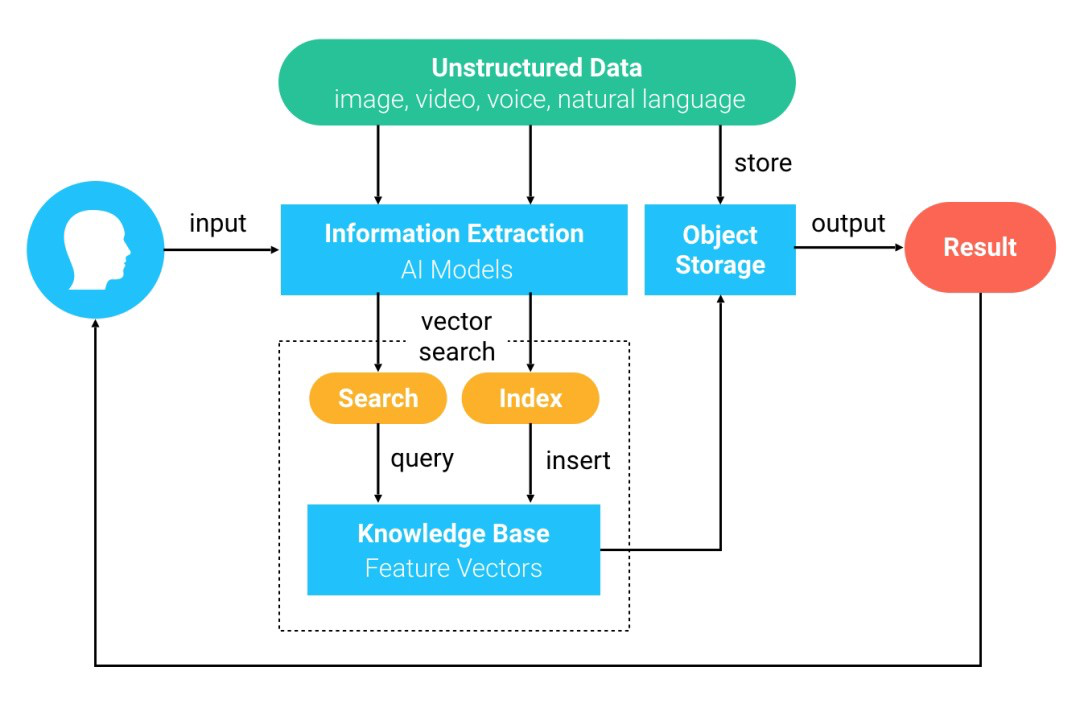 Wie funktioniert Ähnlichkeitssuche in Milvus?
Wie funktioniert Ähnlichkeitssuche in Milvus?
Milvus ist eine Open-Source-Vektordatenbank, die entwickelt wurde, um Vektorähnlichkeitssuche und Anwendungen der künstlichen Intelligenz (KI) zu unterstützen. Auf einer hohen Ebene funktioniert die Verwendung von Milvus für die Ähnlichkeitssuche wie folgt:
- Deep-Learning-Modelle werden verwendet, um unstrukturierte Daten in Feature-Vektoren umzuwandeln, die in Milvus importiert werden.
- Milvus speichert und indiziert die Feature-Vektoren.
- Auf Anfrage sucht Milvus nach Vektoren, die einem Eingabevektor am ähnlichsten sind, und gibt sie zurück.
Aufbau eines graphbasierten Empfehlungssystems mit Milvus
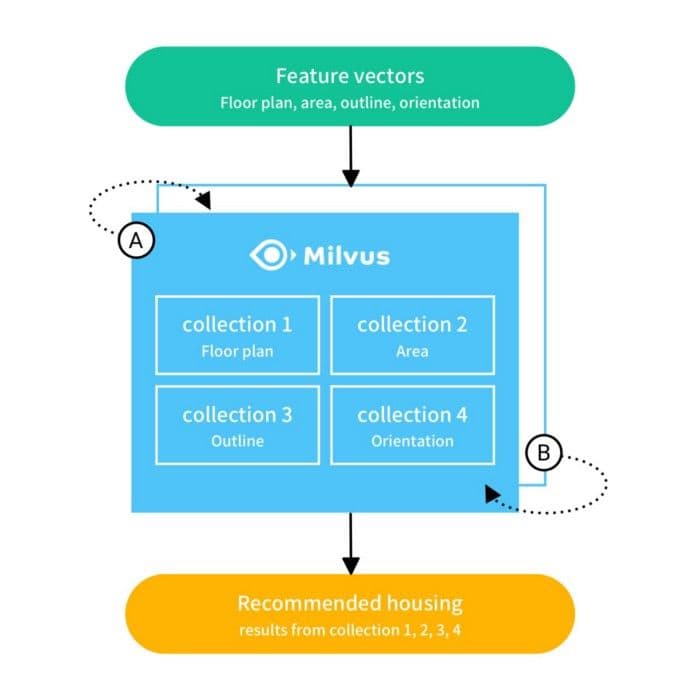 Grundlegender Workflow eines graphbasierten Empfehlungssystems in Milvus.
Grundlegender Workflow eines graphbasierten Empfehlungssystems in Milvus.
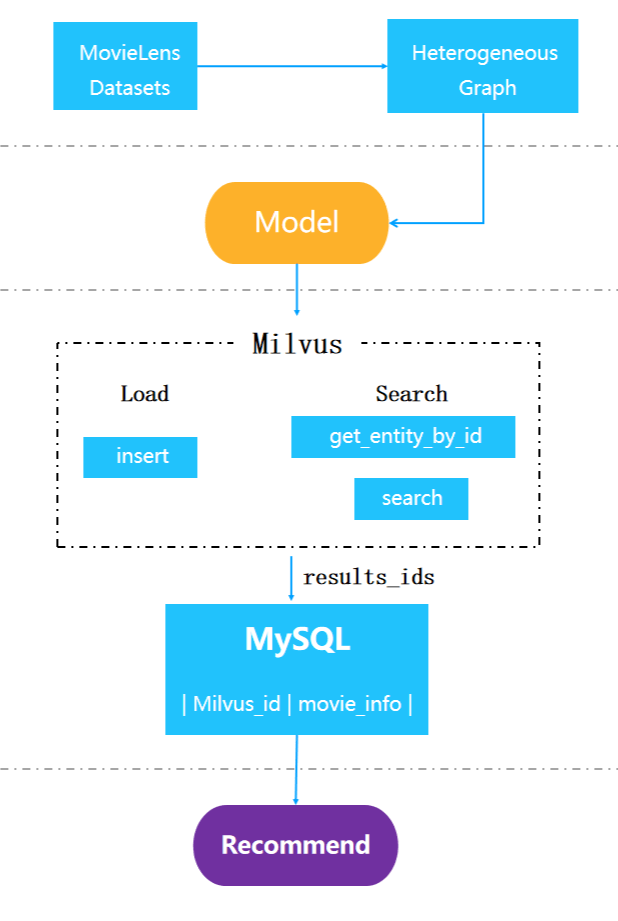 Grundlegender Workflow eines graphbasierten Empfehlungssystems in Milvus.
Grundlegender Workflow eines graphbasierten Empfehlungssystems in Milvus.
Der Aufbau eines graphbasierten Empfehlungssystems mit Milvus umfasst die folgenden Schritte:
Schritt 1: Daten vorverarbeiten
Bei der Datenvorverarbeitung werden Rohdaten in ein leichter verständliches Format umgewandelt. Dieses Beispiel verwendet die offenen Datensätze MovieLens[5] (m1–1m), die 1.000.000 Bewertungen von 4.000 Filmen enthalten, die von 6.000 Nutzern beigesteuert wurden. Diese Daten wurden von GroupLens gesammelt und umfassen Filmbeschreibungen, Filmbewertungen und Nutzereigenschaften.
Beachten Sie, dass die in diesem Beispiel verwendeten MovieLens-Datensätze nur minimale Datenbereinigung oder Organisation erfordern. Wenn Sie jedoch andere Datensätze verwenden, kann der Aufwand variieren.
Um mit dem Aufbau eines Empfehlungssystems zu beginnen, erstellen Sie mithilfe historischer Nutzer-Film-Daten aus dem MovieLens-Datensatz einen bipartiten Nutzer-Film-Graphen für Klassifizierungszwecke.
graph_builder = PandasGraphBuilder()
graph_builder.add_entities(users, 'user_id', 'user')
graph_builder.add_entities(movies_categorical, 'movie_id', 'movie')
graph_builder.add_binary_relations(ratings, 'user_id', 'movie_id', 'watched')
graph_builder.add_binary_relations(ratings, 'movie_id', 'user_id', 'watched-by')
g = graph_builder.build()
Schritt 2: Modell mit PinSage trainieren
Einbettungsvektoren von Pins, die mit dem PinSage-Modell generiert werden, sind Merkmalsvektoren der erfassten Filminformationen. Erstellen Sie ein PinSage-Modell auf Basis des bipartiten Graphen g und der angepassten Dimensionen der Film-Merkmalsvektoren (standardmäßig 256-d). Trainieren Sie anschließend das Modell mit PyTorch, um die h_item-Einbettungen von 4.000 Filmen zu erhalten.
# Define the model
model = PinSAGEModel(g, item_ntype, textset, args.hidden_dims, args.num_layers).to(device)
opt = torch.optim.Adam(model.parameters(), lr=args.lr)
# Get the item embeddings
for blocks in dataloader_test:
for i in range(len(blocks)):
blocks[i] = blocks[i].to(device)
h_item_batches.append(model.get_repr(blocks))
h_item = torch.cat(h_item_batches, 0)
Schritt 3: Daten laden
Laden Sie die vom PinSage-Modell generierten Filmeinbettungen h_item in Milvus, das die entsprechenden IDs zurückgibt. Importieren Sie die IDs und die entsprechenden Filminformationen in MySQL.
# Load data to Milvus and MySQL
status, ids = milvus.insert(milvus_table, h_item)
load_movies_to_mysql(milvus_table, ids_info)
Schritt 4: Vektorähnlichkeitssuche durchführen
Rufen Sie die entsprechenden Einbettungen in Milvus anhand der Film-IDs ab und verwenden Sie anschließend Milvus, um mit diesen Einbettungen eine Ähnlichkeitssuche durchzuführen. Ermitteln Sie danach die entsprechenden Filminformationen in einer MySQL-Datenbank.
# Get embeddings that users like
_, user_like_vectors = milvus.get_entity_by_id(milvus_table, ids)
# Get the information with similar movies
_, ids = milvus.search(param = {milvus_table, user_like_vectors, top_k})
sql = "select * from " + movies_table + " where milvus_id=" + ids + ";"
results = cursor.execute(sql).fetchall()
Schritt 5: Empfehlungen erhalten
Das System empfiehlt nun Filme, die den Suchanfragen der Nutzer am ähnlichsten sind. Dies ist der allgemeine Workflow zum Aufbau eines Empfehlungssystems. Um Empfehlungssysteme und andere KI-Anwendungen schnell zu testen und bereitzustellen, probieren Sie das Milvus bootcamp aus.
Milvus kann mehr als nur Empfehlungssysteme betreiben
Milvus ist ein leistungsstarkes Tool, das eine Vielzahl von Anwendungen für künstliche Intelligenz und Vektorähnlichkeitssuche ermöglichen kann. Um mehr über das Projekt zu erfahren, sehen Sie sich die folgenden Ressourcen an:
Weiterlesen

Cosmos World Foundation Model Platform for Physical AI
NVIDIA's Cosmos platform enables safe, digital twin training of GenAI models for physical applications, overcoming data scarcity and safety challenges.

DeepSeek Always Busy? Deploy It Locally with Milvus in Just 10 Minutes—No More Waiting!
Learn how to set up DeepSeek-R1 on your local machine using Ollama, AnythingLLM, and Milvus in just 10 minutes. Bypass busy servers and enhance AI responses with custom data.

AI Integration in Video Surveillance Tools: Transforming the Industry with Vector Databases
Discover how AI and vector databases are revolutionizing video surveillance with real-time analysis, faster threat detection, and intelligent search capabilities for enhanced security.