




Erkundung der Wunder von Knowhere 2.0
Druckfrisch ist Milvus 2.3 mit vielen bahnbrechenden Updates erschienen. An vorderster Front dieser Verbesserungen steht Knowhere 2.0, ein transformatives Upgrade, das verspricht, Milvus auf ein neues Niveau zu heben.
Begleiten Sie uns in diesem Blogbeitrag, während wir tief in Knowhere 2.0 eintauchen und seine bahnbrechenden Funktionen, Leistungsoptimierungen und Designprinzipien erkunden, die es zu einer herausragenden Kraft in Vektordatenbanken machen.
Was ist Knowhere?
Knowhere ist die zentrale Vektorsuchmaschine für Milvus. Stellen Sie sich die Vektordatenbank als das riesige Marvel-Universum vor; Knowhere ist ihr ultimatives Hauptquartier. Die Hauptaufgabe von Knowhere besteht darin, Approximate-Nearest-Neighbor-Suchen (ANNS) durch den Aufbau von Indizes mit geringer Latenz durchzuführen.
Knowhere 2.0 und seine neuen Fähigkeiten
Wir arbeiten seit Juli 2022 an der Umstrukturierung und Aufrüstung von Knowhere. Nach unermüdlichen Diskussionen, Design, Entwicklung und Tests debütierte Knowhere 2.0 Ende August 2023 mit Milvus 2.3. Diese neue Version bringt viele Verbesserungen mit sich, darunter Unterstützung für den GPU-Index, Kosinus-Ähnlichkeit, ScaNN-Index und Arm-Architektur. Das aktualisierte Knowhere kommt Nutzern und Entwicklern zugute und macht es zu einem Kraftpaket in Milvus. Als Nächstes betrachten wir seine wichtigsten Funktionen.
Unterstützung für GPU-Indizes
Nvidia hat die Indizes GPU_FLAT und GPU_IVFPQ aus seiner Vektorsuchbibliothek RAFT zu Knowhere 2.0 beigetragen. Diese Ergänzung beschleunigt Indexsuchen erheblich, wobei Milvus auf Nvidia A100 bemerkenswerte Durchsatzverbesserungen erzielt, nahezu das 70-Fache für SIFT1M.
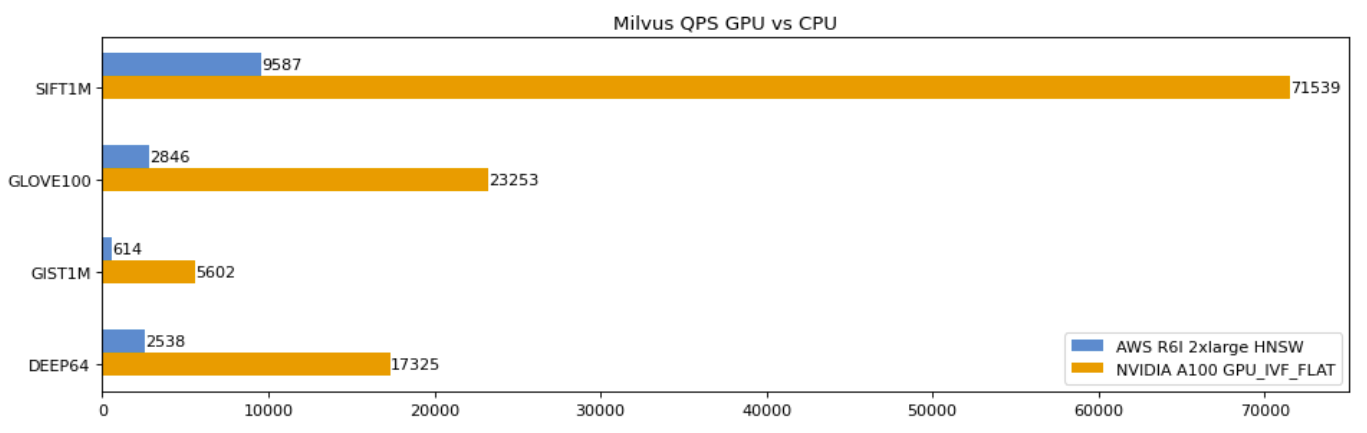 Milvus QPS GPU vs. CPU
Milvus QPS GPU vs. CPU
Weitere Informationen zum GPU-Index finden Sie in der Milvus-Dokumentation.
Unterstützung für Kosinus-Ähnlichkeit
In früheren Versionen von Knowhere mussten Nutzer das innere Produkt verwenden und Vektoren vor dem Einfügen der Vektoren normalisieren, um die Kosinus-Ähnlichkeit zu nutzen. Dieser Prozess war sehr kostspielig, schwer zugänglich und erforderte ein höheres theoretisches Wissen von den Nutzern.
Knowhere 2.0 unterstützt die Kosinus-Distanz nativ, normalisiert eingehende Vektoren automatisch innerhalb der Bibliothek und gleicht entsprechende Indextypen ab, wodurch die Benutzererfahrung erheblich verbessert wird.
Unterstützung für den ScaNN-Index
ScaNN, oder FastScan, ist ein Open-Source-Approximate-Nearest-Neighbor (ANN)-Index, der von FAISS implementiert wurde. Er verwendet kleinere PQ-Kodierung und entsprechende Befehlssätze, um auf CPU-Register zuzugreifen, was zu hervorragender Indexierungsleistung führt.
Knowhere 2.0 unterstützt den ScaNN-Index nun nativ. Mit Knowhere 2.0 erreicht Milvus 2.3 das Siebenfache der QPS von IVF_FLAT und das 1,2-Fache von HNSW, mit einer Recall-Rate von etwa 95 % auf den Cohere-Datensätzen.
Unterstützung für ARM-Architektur
Die ARM-Architektur ist im Vergleich zur x86-Architektur für ihre Kosteneffizienz bekannt. Obwohl weniger leistungsstark, verfügt ARM über ein einfacheres Design und einfachere Befehlssätze, was sie zunehmend beliebt macht. Beispielsweise sind ARM-Instanzen mit denselben CPU-Spezifikationen (z. B. 1 vCPU und 16GB RAM) auf der AWS-Plattform etwa 15 % günstiger als x86-Instanzen.
Mit der Unterstützung für die ARM-Architektur in Knowhere 2.0 können Nutzer nun Dienste der oberen Schicht auf dieser Architektur ausführen und aufbauen.
Unterstützung für Bereichssuche
Es gibt zwei Methoden zur Suche nach den nächsten Nachbarn: K Nearest Neighbor (KNN) und Range Search. KNN findet die „k“ nächsten Vektoren zu einem Abfragevektor „q“ innerhalb einer Sammlung von Vektoren „X“. Range Search hingegen hat kein festgelegtes „k“; stattdessen gibt sie alle Vektoren innerhalb einer bestimmten Entfernung (Radius) vom Abfragevektor „q“ innerhalb der Vektorsammlung „X“ zurück.
Knowhere 2.0 unterstützt Range Search für mehrere Indizes in der Bibliothek, wie HNSW-, DiskANN- und IVF-Indizes. Diese Funktion ermöglicht es Benutzern, während einer Abfrage die Entfernung zwischen dem Eingabevektor und den in Milvus gespeicherten Vektoren anzugeben.
Optimierte Filterabfragen
Bei gemischten Skalar- und Vektorabfragen können Sie einige Vektoren herausfiltern. Knowhere 2.0 hat Filter-Vektorabfragen für HNSW erheblich verbessert, was zu Leistungssteigerungen um das 6- bis 80-Fache im Vergleich zu früheren Versionen führt.
Verbesserungen an Codestruktur und Kompilierung
Knowhere 2.0 vereinfacht die Vererbung von C++-Klassen, verwendet Proxy-Muster für die Integration neuer Indizes, überarbeitet das Config-Modul, nutzt Conan als Paketmanager für eine optimierte Kompilierung und setzt Follys Thread-Pool für eine präzise Thread-Steuerung ein. All diese Verbesserungen machen die Nutzung von Milvus unkomplizierter.
MMap-Unterstützung
In der Vergangenheit waren einige Benutzer aufgrund ihrer großen Datensätze mit Einschränkungen beim Speicherplatz konfrontiert, was sich auf die Indizes auswirkte, die sie speichern konnten. Mit der Einführung von Knowhere 2.0 unterstützt Milvus nun jedoch Memory Mapping (MMap), wodurch große Dateien automatisch in den Speicher gemappt werden können. Diese neue Funktion ermöglicht Benutzern den Zugriff auf umfangreiche Indexdaten trotz unzureichendem Arbeitsspeicher.
Unterstützung für das Abrufen ursprünglicher Vektoren
Nach Abschluss einer Suche benötigen Benutzer möglicherweise Zugriff auf die ursprünglichen Vektoren auf Basis der zurückgegebenen IDs für weitere benutzerdefinierte Berechnungen oder Filterungen. Mit Knowhere 2.0 können Benutzer ursprüngliche Vektoren direkt aus dem Index abrufen, wodurch die Latenz im Vergleich zum Abrufen aus Remote-Speicher wie S3 reduziert wird.
Weitere Details zu den Funktionen und Verbesserungen von Knowhere 2.0 finden Sie in den Knowhere 2.0 Release Notes.
Tragen Sie gerne zu Knowhere bei!
Knowhere entwickelt sich kontinuierlich weiter, und Ihr Feedback ist wichtig. Wenn Sie wertvolle Vorschläge oder Ideen haben, zögern Sie bitte nicht, zum Repository Knowhere beizutragen.

Weiterlesen

The Real Bottlenecks in Autonomous Driving — And How AI Infrastructure Can Solve Them
Autonomous driving faces a data bottleneck. Learn how AI-native vector databases like Zilliz solve scale, cost, and insight challenges across AV pipelines.

1 Table = 1000 Words? Foundation Models for Tabular Data
TableGPT2 automates tabular data insights, overcoming schema variability, while Milvus accelerates vector search for efficient, scalable decision-making.

Zilliz Cloud BYOC Upgrades: Bring Enterprise-Grade Security, Networking Isolation, and More
Discover how Zilliz Cloud BYOC brings enterprise-grade security, networking isolation, and infrastructure automation to vector database deployments in AWS