




LLM-Apps mit 100-mal schnelleren Antworten und drastischer Kostenreduzierung mithilfe von GPTCache
Dieser Artikel wurde ursprünglich auf ODBMS veröffentlicht und wird hier mit Genehmigung erneut veröffentlicht.
Das magische ChatGPT und andere große Sprachmodelle (LLMs) haben fast alle mit ihrer Fähigkeit erstaunt, natürliche Sprache zu verstehen und komplizierte Fragen zu beantworten. Infolgedessen nutzen immer mehr Entwickler LLMs, um intelligente Anwendungen zu erstellen. Wenn Ihre LLM-Anwendung jedoch an Beliebtheit gewinnt und einen Anstieg des Datenverkehrs verzeichnet, werden die Kosten für LLM-API-Aufrufe erheblich steigen. Hohe Antwortlatenz wird ebenfalls frustrierend sein, insbesondere zu Spitzenzeiten für LLMs, und sich direkt auf die Benutzererfahrung auswirken.
In diesem Beitrag stelle ich eine praktische Lösung für Herausforderungen vor, die die Effizienz und Geschwindigkeit von LLM-Anwendungen beeinträchtigen: GPTCache. Dieser semantische Open-Source-Cache kann Ihnen helfen, mindestens 100-mal schnellere Abrufgeschwindigkeiten zu erreichen und Ihre Kosten für die Nutzung von LLM-Diensten auf null zu senken, wenn der Cache getroffen wird.
Zentrale Herausforderungen beim Erstellen LLM-basierter Anwendungen
Bevor wir tief in GPTCache eintauchen, besprechen wir zunächst zwei zentrale Herausforderungen beim Erstellen einer intelligenten Anwendung auf Basis von LLMs.
Steigende Kosten durch unnötige API-Aufrufe
Anwendungen können die leistungsstarken Inferenzfähigkeiten von LLMs nutzen, indem sie die API von LLMs aufrufen. Das Aufrufen der API ist jedoch nicht kostenlos. Wenn Ihre Anwendung für die Produktion bestimmt ist und eine große Nutzerbasis hat, können häufige API-Aufrufe Sie ein Vermögen kosten. Außerdem zahlen Sie möglicherweise am Ende für unnötige API-Aufrufe für semantisch identische Fragen, die das LLM bereits beantwortet hat, wodurch Sie Geld und Ressourcen verschwenden.
Schlechte Leistung und Skalierbarkeit bei hoher Antwortlatenz
Große Sprachmodelle bewältigen normalerweise atemberaubende Arbeitslasten. Nehmen wir ChatGPT als Beispiel. Im Juli 2023 hatte es über 100 Millionen aktive Nutzer und verzeichnete allein im Juni etwa eine Milliarde Besuche. Aufgrund solcher hohen Arbeitslasten verlangsamen LLMs ihre Antworten, insbesondere zu Spitzenzeiten, was dazu führt, dass Anwendungen, die auf sie angewiesen sind, ebenfalls langsamer werden.
Darüber hinaus erzwingen LLM-Dienste Ratenbegrenzungen, die die Anzahl der API-Aufrufe einschränken, die Ihre Anwendungen innerhalb eines bestimmten Zeitraums an den Server senden können. Das Erreichen einer Ratenbegrenzung bedeutet, dass zusätzliche Anfragen blockiert werden, bis ein bestimmter Zeitraum verstrichen ist, was zu einem Dienstausfall führt. Dieser Engpass kann die Benutzererfahrung direkt beeinträchtigen und die Anzahl der Anfragen begrenzen, die Ihre Anwendung verarbeiten kann.
Was ist GPTCache?
GPTCache ist ein semantischer Open-Source-Cache, der entwickelt wurde, um die Effizienz und Geschwindigkeit GPT-basierter Anwendungen zu verbessern, indem die von Sprachmodellen generierten Antworten gespeichert und abgerufen werden. GPTCache ermöglicht es Nutzern, den Cache an ihre spezifischen Anforderungen anzupassen, und bietet eine Reihe von Auswahlmöglichkeiten für Embedding, Ähnlichkeitsbewertung, Speicherort und Verdrängungsrichtlinien. Darüber hinaus unterstützt GPTCache sowohl die OpenAI-ChatGPT-Schnittstelle als auch die Langchain-Schnittstelle, mit Plänen, in den kommenden Monaten weitere Schnittstellen zu unterstützen.
Wie funktioniert GPTCache?
Einfach ausgedrückt speichert GPTCache die Antworten von LLMs im Cache. Wenn Nutzer daher ähnliche Abfragen stellen, auf die LLMs zuvor geantwortet hatten, sucht GPTCache nach den Ergebnissen und gibt sie an die Nutzer zurück, ohne dass das LLM erneut aufgerufen werden muss. Im Gegensatz zu traditionellen Cache-Systemen wie Redis verwendet GPTCache semantisches Caching, das Daten über Embeddings speichert und abruft. Es nutzt Embedding-Algorithmen, um die Nutzerabfragen und Antworten von LLMs in Embeddings umzuwandeln, und führt Ähnlichkeitssuchen auf diesen Embeddings unter Verwendung eines Vektorspeichers wie Milvus durch.
GPTCache umfasst sechs Kernmodule: LLM-Adapter, Pre-processor (Context Manager), Embedding Generator, Cache Manager, Similarity Evaluator und Post-processor.
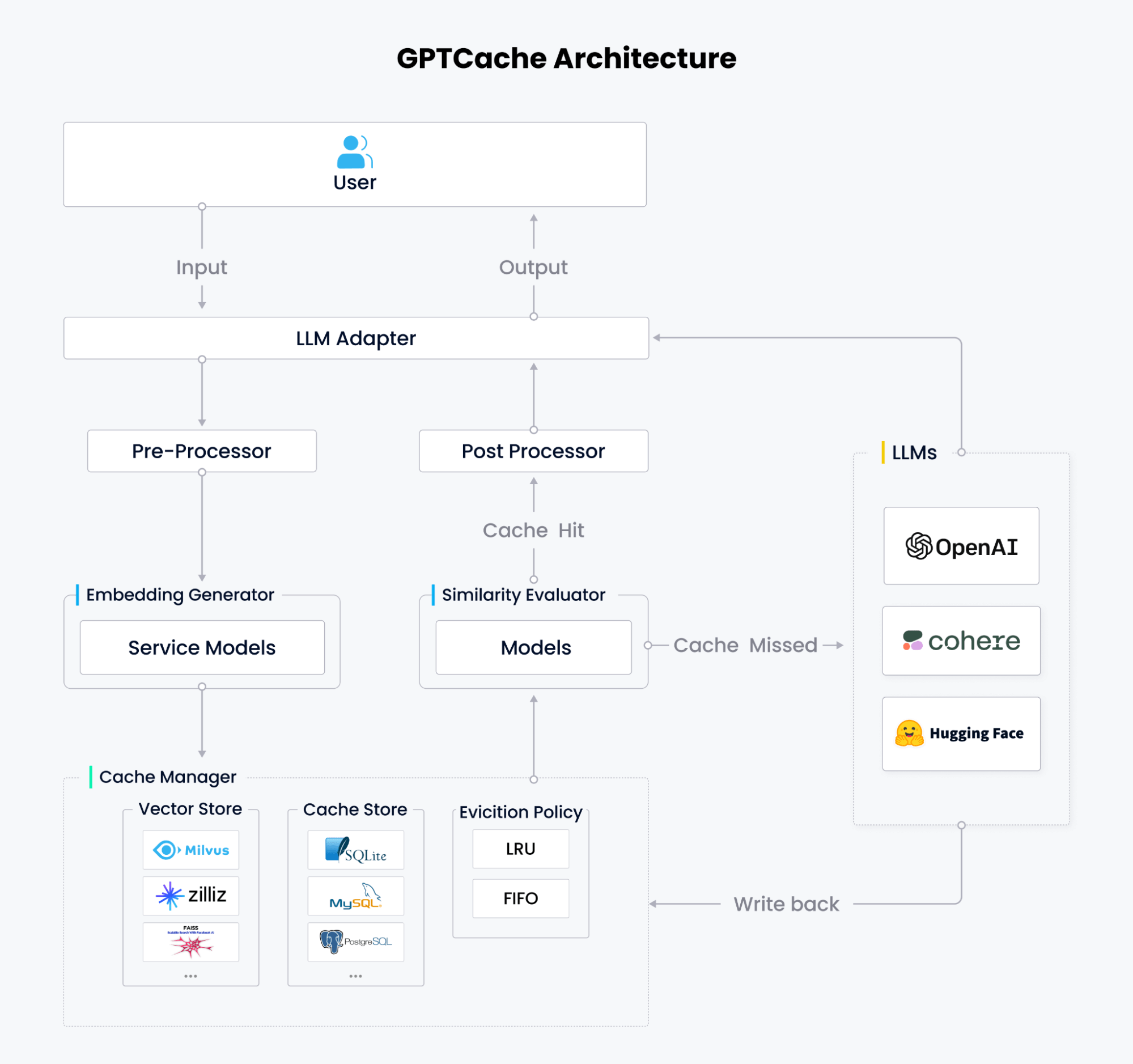
LLM-Adapter
Der LLM-Adapter dient als GPTCaches Schnittstelle für externe Interaktionen. Er wandelt Anfragen in Cache-Protokolle um, steuert den Caching-Workflow und transformiert Cache-Ergebnisse in LLM-Antworten. Mit dem LLM-Adapter wird das Experimentieren und Testen verschiedener Sprachmodelle einfacher, da Sie zwischen ihnen wechseln können, ohne Ihren Code neu zu schreiben oder eine neue API zu erlernen.
GPTCache unterstützt bereits die OpenAI ChatGPT API, LangChain API, MiniGPT4 API und Llamacpp API. Unsere Roadmap umfasst die Hinzufügung weiterer APIs, wie Hugging Face Hub, Bard und Anthropic.
Pre-processor
Der Pre-processor verwaltet, analysiert und formatiert die an LLMs gesendeten Anfragen, einschließlich des Entfernens redundanter Informationen aus Eingaben, des Komprimierens von Eingabeinformationen, des Kürzens langer Texte und der Durchführung anderer verwandter Aufgaben.
Embedding Generator
Der Embedding Generator wandelt Benutzeranfragen mithilfe Ihrer bevorzugten Embedding-Modelle in Embedding-Vektoren um. GPTCache unterstützt lokale Modelle von HuggingFace und GitHub sowie Cloud-Embedding-Dienste zur Generierung von Embeddings. Dazu gehören die OpenAI embedding API, ONNX mit dem GPTCache/paraphrase-albert-onnx-Modell, Hugging Face embedding API, Cohere embedding API, fastText embedding API und die SentenceTransformers embedding API sowie Timm-Modelle für Bild-Embeddings.
Cache Manager
Der Cache Manager ist das Kernmodul von GPTCache. Er speichert die Anfragen der Benutzer und die Antworten der LLMs und besteht aus drei Komponenten:
Ein Vektorspeicher für die Speicherung von Embedding-Vektoren und Ähnlichkeitssuchen
Ein Cache-Speicher zum Speichern von Benutzeranfragen und entsprechenden LLM-Antworten
Eine Räumungsrichtlinie zur Steuerung der Cache-Kapazität gemäß der Least Recently Used (LRU)- oder First In, First Out (FIFO)-Räumungsrichtlinie.
Derzeit unterstützt GPTCache SQLite, PostgreSQL, MySQL, MariaDB, SQL Server und Oracle für die Cache-Speicherung sowie Milvus, Zilliz Cloud und Weaviate für Vektorspeicherung und -abruf. Benutzer können ihren bevorzugten Vektorspeicher, Cache-Speicher und ihre bevorzugte Räumungsrichtlinie wählen, um ihre Anforderungen zu erfüllen und Leistung, Skalierbarkeit und Kosten auszubalancieren.
Similarity Evaluator
Similarity Evaluator bestimmt, ob die zwischengespeicherte Antwort zur Eingabeanfrage passt. GPTCache bietet eine standardisierte Schnittstelle, die mehrere Ähnlichkeitsstrategien kombiniert und es Benutzern ermöglicht, Cache-Treffer entsprechend ihren spezifischen Anforderungen und Anwendungsfällen anzupassen.
Post-Processor
Post-processor bereitet die endgültige Antwort vor, die bei einem Cache-Treffer an den Benutzer zurückgegeben wird. Wenn die Antwort nicht im Cache ist, fordert der LLM Adapter Antworten vom LLM an und schreibt sie zurück in den Cache Manager.
GPTCache-Vorteile
Drastische Kostensenkung bei LLM-API-Aufrufen
LLMs berechnen jeden API-Aufruf. GPTCache hilft Entwicklern, LLM-Antworten semantisch für ähnliche und wiederholt gestellte Fragen zwischenzuspeichern, wodurch API-Kosten auf null reduziert werden, wenn der Cache getroffen wird. GPTCache reduziert die Gesamtzahl der API-Aufrufe und senkt die Kosten drastisch. Dies ist besonders vorteilhaft für Anwendungen mit extrem hohem Traffic.
100x schnellere Antworten
GPTCache kann die Antwortzeit für LLM-Anwendungen erheblich reduzieren. Während der Spitzenzeiten von ChatGPT können Antworten bis zu mehrere Sekunden dauern. Mit GPTCache können Anwendungen jedoch zuvor angeforderte Antworten in weniger als 100 Millisekunden abrufen, was mindestens 100-mal schneller ist.
Verbesserte Skalierbarkeit
Das Zwischenspeichern von LLM-Antworten reduziert die Last auf den LLM-Dienst, verbessert die Skalierbarkeit Ihrer App und verhindert Engpässe bei der Verarbeitung wachsender Anfragen.
Bessere Verfügbarkeit
LLM-Dienste legen häufig Ratenbegrenzungen fest, die einschränken, wie oft Ihre App innerhalb eines bestimmten Zeitraums auf den Server zugreifen kann. GPTCache reduziert die Gesamtzahl der API-Aufrufe und ermöglicht es Ihrer App, schnell zu skalieren, um ein zunehmendes Anfragevolumen zu bewältigen. Dieser Ansatz gewährleistet eine konsistente Leistung, während die Nutzerbasis Ihrer Anwendung wächst.
Weitere Details dazu, wie Sie von GPTCache profitieren können, finden Sie auf der Seite What is GPTCache.
OSS Chat, ein KI-Chatbot, der GPTCache und den CVP-Stack nutzt
GPTCache ist vorteilhaft für Retrieval-Augmented Generation (RAG), bei der Anwendungen einen CVP-Stack (ChatGPT/LLMs+Vektordatenbank+Prompt as Code) implementieren, um genauere Ergebnisse zu erzielen. OSS Chat, ein KI-Chatbot, der Fragen zu GitHub-Projekten beantworten kann, ist das beste Beispiel dafür, wie GPTCache und der CVP-Stack im RAG-Szenario funktionieren.
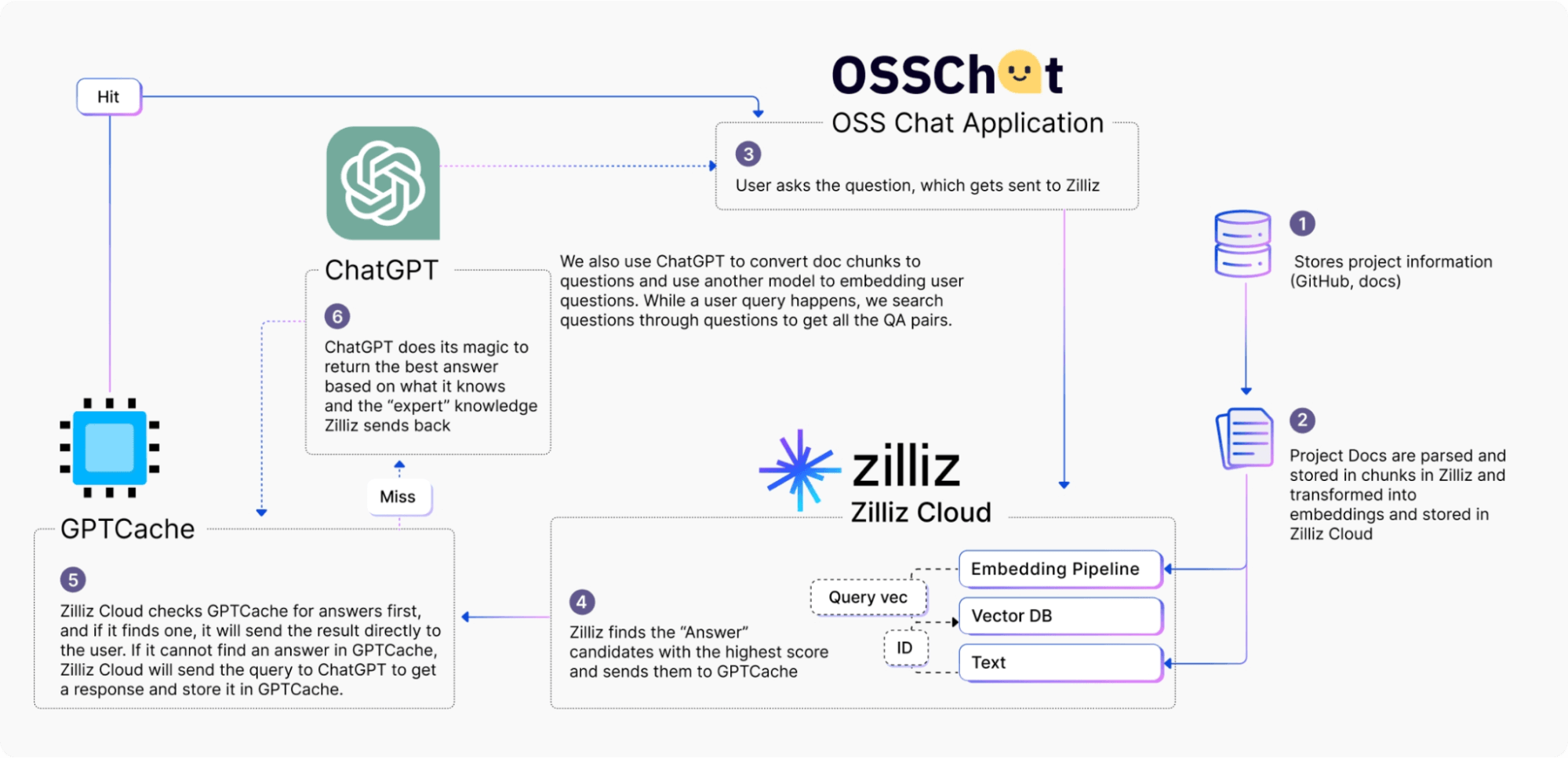 Architektur von OSS Chat
Architektur von OSS Chat
OSS Chat nutzt Towhee, eine Machine-Learning-Pipeline, um Informationen und zugehörige Dokumentationsseiten von GitHub-Projekten in Embeddings umzuwandeln. Anschließend speichert es die Embeddings in Zilliz Cloud, einem vollständig verwalteten Vektordatenbankdienst. Wenn ein Nutzer über OSS Chat eine Frage stellt, sucht Zilliz Cloud nach den Top-k-Ergebnissen, die für diese Anfrage am relevantesten sind. Diese Ergebnisse werden dann mit der ursprünglichen Frage kombiniert, um einen Prompt mit einem breiteren Kontext zu erstellen.
Bevor der Prompt an ChatGPT gesendet wird, prüft Zilliz Cloud zunächst GPTCache auf Antworten; bei einem Cache-Treffer gibt GPTCache die Antwort direkt an den Nutzer zurück. Bei einem Cache-Fehltreffer sendet GPTCache den ursprünglichen Prompt an ChatGPT, um Antworten zu erhalten, und speichert ihn für die zukünftige Nutzung wieder im Cache. GPTCache ermöglicht es OSS Chat, eine hervorragende Nutzererfahrung mit niedrigeren Kosten, geringerer Antwortlatenz und weniger Entwicklungsaufwand zu bieten.
Zusammenfassung
Das Erstellen von Anwendungen auf Basis von LLMs ist ein wachsender Trend, von dem alle im Ökosystem profitieren. App-Entwickler stehen jedoch vor zwei zentralen Herausforderungen: den hohen Kosten von API-Aufrufen und der hohen Antwortlatenz. GPTCache ist eine perfekte Open-Source-Lösung, die diese Herausforderungen angeht und viele weitere Vorteile bietet, darunter reduzierte Netzwerklatenz, verbesserte Verfügbarkeit und bessere Skalierbarkeit.
Ein praxisnahes Tutorial zum Einstieg in GPTCache finden Sie in der GPTCache-Dokumentation. Sie können während unserer Community Office Hours Fragen stellen oder Ihre Ideen teilen. Sie sind außerdem herzlich eingeladen, zu GPTCache beizutragen.

Weiterlesen

What Is a Vector Lakebase?
A Vector Lakebase is a unified, lake-native data architecture for AI that combines vector-database-grade serving with open lake storage, reusable lake-level indexes, and a shared semantic layer.

Vector Databases vs. Object-Relational Databases
Use a vector database for AI-powered similarity search; use an object-relational database for complex data modeling with both relational integrity and object-oriented features.

Selecting the Right ETL Tools for Unstructured Data to Prepare for AI
Learn the right ETL tools for unstructured data to power AI. Explore key challenges, tool comparisons, and integrations with Milvus for vector search.