




Aufbau eines Milvus-Clusters auf Basis von JuiceFS
Zusammenarbeit zwischen Open-Source-Communitys ist etwas Magisches. Leidenschaftliche, intelligente und kreative Freiwillige halten nicht nur Open-Source-Lösungen innovativ, sondern arbeiten auch daran, verschiedene Tools auf interessante und nützliche Weise zusammenzubringen. Milvus, die weltweit beliebteste Vektordatenbank, und JuiceFS, ein gemeinsam genutztes Dateisystem, das für cloud-native Umgebungen entwickelt wurde, wurden in diesem Geist von ihren jeweiligen Open-Source-Communitys vereint. Dieser Artikel erklärt, was JuiceFS ist, wie man einen Milvus-Cluster auf Basis von gemeinsam genutztem JuiceFS-Dateispeicher erstellt und welche Leistung Benutzer bei der Verwendung dieser Lösung erwarten können.
Was ist JuiceFS?
JuiceFS ist ein leistungsstarkes, verteiltes Open-Source-POSIX-Dateisystem, das auf Redis und S3 aufgebaut werden kann. Es wurde für cloud-native Umgebungen entwickelt und unterstützt das Verwalten, Analysieren, Archivieren und Sichern von Daten jeglicher Art. JuiceFS wird häufig verwendet, um Big-Data-Herausforderungen zu lösen, Anwendungen für künstliche Intelligenz (KI) zu erstellen und Protokolle zu sammeln. Das System unterstützt außerdem die gemeinsame Nutzung von Daten über mehrere Clients hinweg und kann direkt als gemeinsam genutzter Speicher in Milvus verwendet werden.
Nachdem Daten und die entsprechenden Metadaten jeweils im Objektspeicher und in Redis persistiert wurden, dient JuiceFS als zustandslose Middleware. Die gemeinsame Datennutzung wird ermöglicht, indem verschiedene Anwendungen über eine standardmäßige Dateisystemschnittstelle nahtlos miteinander verbunden werden. JuiceFS stützt sich für die Metadatenspeicherung auf Redis, einen Open-Source-In-Memory-Datenspeicher. Redis wird verwendet, weil es Atomizität garantiert und hochleistungsfähige Metadatenoperationen bietet. Alle Daten werden über den JuiceFS-Client im Objektspeicher gespeichert. Das Architekturdiagramm sieht wie folgt aus:
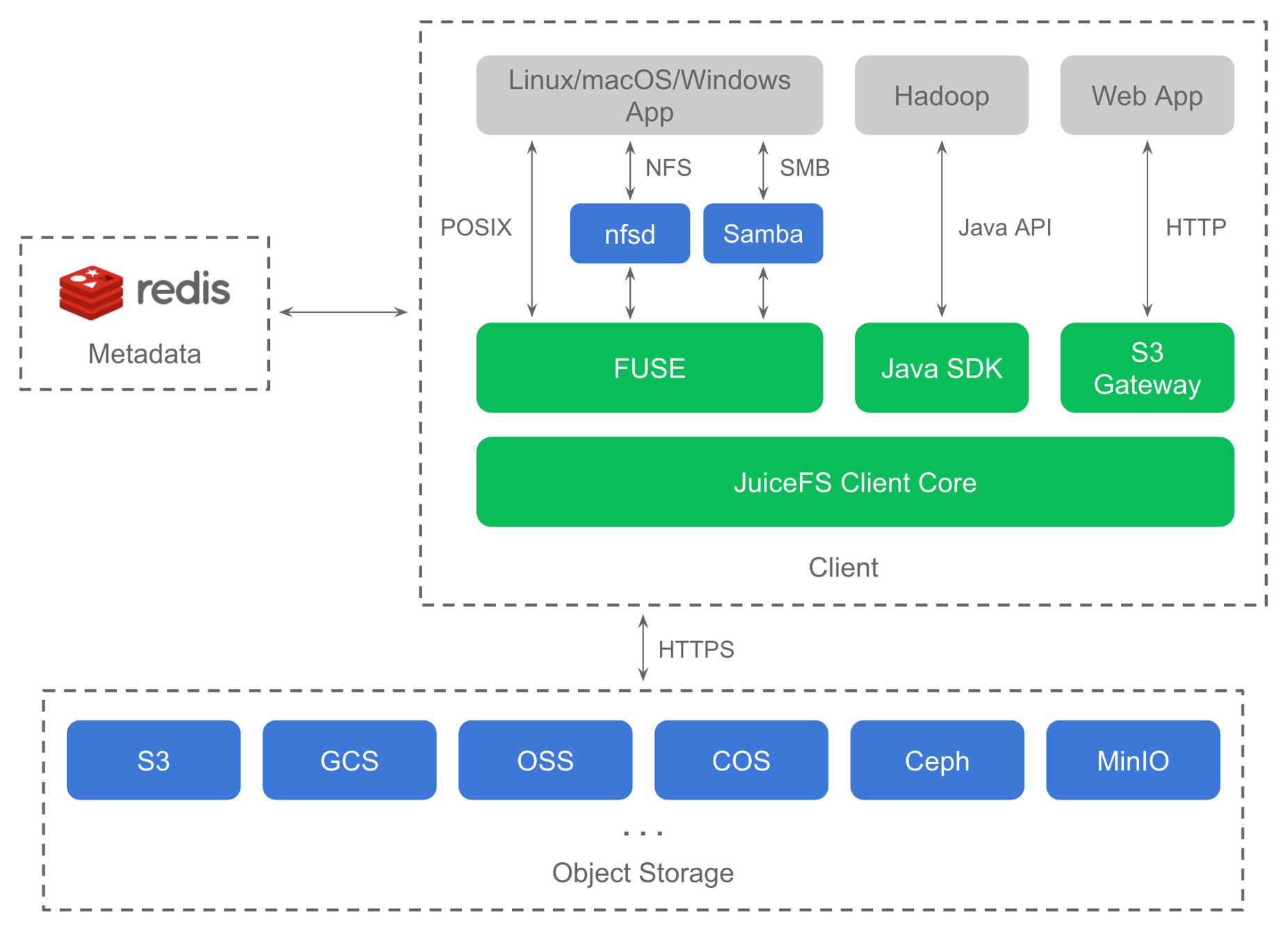 Gesamtarchitektur von JuiceFS.
Gesamtarchitektur von JuiceFS.
Einen Milvus-Cluster auf Basis von JuiceFS erstellen
Ein mit JuiceFS erstellter Milvus-Cluster (siehe Architekturdiagramm unten) funktioniert, indem Upstream-Anfragen mithilfe von Mishards, einer Cluster-Sharding-Middleware, aufgeteilt werden, um die Anfragen an seine Submodule weiterzureichen. Beim Einfügen von Daten weist Mishards Upstream-Anfragen dem Milvus-Schreibknoten zu, der neu eingefügte Daten in JuiceFS speichert. Beim Lesen von Daten lädt Mishards die Daten über einen Milvus-Leseknoten aus JuiceFS zur Verarbeitung in den Speicher, sammelt anschließend Ergebnisse aus Subservices und gibt sie upstream zurück.
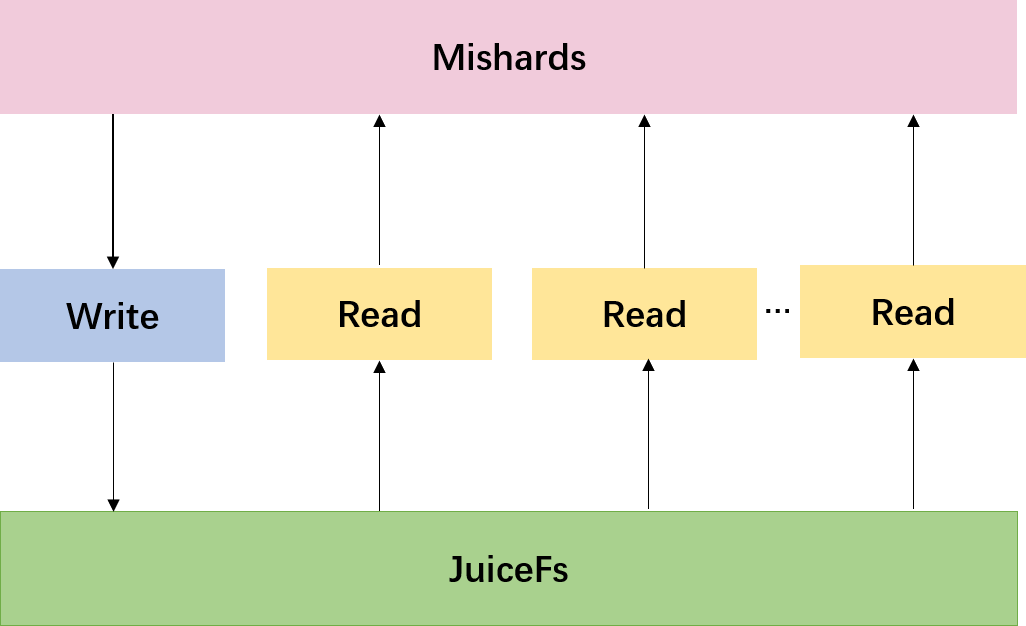 Architektur eines mit JuiceFS erstellten Milvus-Clusters.
Architektur eines mit JuiceFS erstellten Milvus-Clusters.
Schritt 1: MySQL-Dienst starten
Starten Sie den MySQL-Dienst auf einem beliebigen Knoten im Cluster. Details finden Sie unter Metadaten mit MySQL verwalten.
Schritt 2: Ein JuiceFS-Dateisystem erstellen
Zu Demonstrationszwecken wird das vorkompilierte binäre JuiceFS-Programm verwendet. Laden Sie das passende Installationspaket für Ihr System herunter und folgen Sie dem JuiceFS-Quick Start Guide für detaillierte Installationsanweisungen. Um ein JuiceFS-Dateisystem zu erstellen, richten Sie zunächst eine Redis-Datenbank für die Metadatenspeicherung ein. Es wird empfohlen, bei Public-Cloud-Bereitstellungen den Redis-Dienst in derselben Cloud wie die Anwendung zu hosten. Richten Sie zusätzlich Objektspeicher für JuiceFS ein. In diesem Beispiel wird Azure Blob Storage verwendet; JuiceFS unterstützt jedoch nahezu alle Objektdienste. Wählen Sie den Objektspeicherdienst aus, der den Anforderungen Ihres Szenarios am besten entspricht.
Nachdem Sie den Redis-Dienst und den Objektspeicher konfiguriert haben, formatieren Sie ein neues Dateisystem und mounten Sie JuiceFS in das lokale Verzeichnis:
1 $ export AZURE_STORAGE_CONNECTION_STRING="DefaultEndpointsProtocol=https;AccountName=XXX;AccountKey=XXX;EndpointSuffix=core.windows.net"
2 $ ./juicefs format \
3 --storage wasb \
4 --bucket https://<container> \
5 ... \
6 localhost test #format
7 $ ./juicefs mount -d localhost ~/jfs #mount
8
Wenn der Redis-Server nicht lokal ausgeführt wird, ersetzen Sie localhost durch die folgende Adresse:
redis://<user:password>@host:6379/1.
Wenn die Installation erfolgreich ist, gibt JuiceFS die Seite für den gemeinsam genutzten Speicher /root/jfs zurück.
 Erfolgreiche Installation.
Erfolgreiche Installation.
Schritt 3: Milvus starten
Auf allen Knoten im Cluster sollte Milvus installiert sein, und jeder Milvus-Knoten sollte mit Lese- oder Schreibberechtigung konfiguriert sein. Nur ein Milvus-Knoten kann als Schreibknoten konfiguriert werden, und die übrigen müssen Leseknoten sein. Legen Sie zunächst die Parameter der Abschnitte cluster und general in der Milvus-Systemkonfigurationsdatei server_config.yaml fest:
Abschnitt cluster
| Parameter | Beschreibung | Konfiguration |
|---|---|---|
enable | Ob der Clustermodus aktiviert werden soll | true |
role | Milvus-Bereitstellungsrolle | rw/ro |
Abschnitt general
# meta_uri is the URI for metadata storage, using MySQL (for Milvus Cluster). Format: mysql://<username:password>@host:port/database
general:
timezone: UTC+8
meta_uri: mysql://root:milvusroot@host:3306/milvus
Während der Installation wird der konfigurierte JuiceFS-Pfad für gemeinsam genutzten Speicher als /root/jfs/milvus/db festgelegt.
1 sudo docker run -d --name milvus_gpu_1.0.0 --gpus all \
2 -p 19530:19530 \
3 -p 19121:19121 \
4 -v /root/jfs/milvus/db:/var/lib/milvus/db \ #/root/jfs/milvus/db is the shared storage path
5 -v /home/$USER/milvus/conf:/var/lib/milvus/conf \
6 -v /home/$USER/milvus/logs:/var/lib/milvus/logs \
7 -v /home/$USER/milvus/wal:/var/lib/milvus/wal \
8 milvusdb/milvus:1.0.0-gpu-d030521-1ea92e
9
Nach Abschluss der Installation starten Sie Milvus und bestätigen Sie, dass es ordnungsgemäß gestartet wurde. Starten Sie abschließend den Mishards-Dienst auf einem beliebigen der Knoten im Cluster. Das folgende Bild zeigt einen erfolgreichen Start von Mishards. Weitere Informationen finden Sie im GitHub-Tutorial.
 Erfolgreicher Start von Mishards.
Erfolgreicher Start von Mishards.
Performance-Benchmarks
Lösungen für gemeinsam genutzten Speicher werden in der Regel durch Network-Attached-Storage-Systeme (NAS) implementiert. Zu den häufig verwendeten NAS-Systemtypen gehören Network File System (NFS) und Server Message Block (SMB). Public-Cloud-Plattformen bieten im Allgemeinen verwaltete Speicherdienste an, die mit diesen Protokollen kompatibel sind, wie etwa Amazon Elastic File System (EFS).
Im Gegensatz zu herkömmlichen NAS-Systemen wird JuiceFS auf Basis von Filesystem in Userspace (FUSE) implementiert, wobei sämtliches Lesen und Schreiben von Daten direkt auf der Anwendungsseite erfolgt, wodurch die Zugriffslatenz weiter reduziert wird. Außerdem gibt es Funktionen, die für JuiceFS einzigartig sind und in anderen NAS-Systemen nicht zu finden sind, wie Datenkomprimierung und Caching.
Benchmark-Tests zeigen, dass JuiceFS erhebliche Vorteile gegenüber EFS bietet. Im Metadaten-Benchmark (Abbildung 1) erreicht JuiceFS bis zu zehnmal höhere I/O-Operationen pro Sekunde (IOPS) als EFS. Darüber hinaus zeigt der I/O-Durchsatz-Benchmark (Abbildung 2), dass JuiceFS EFS sowohl in Einzel- als auch in Mehrfach-Job-Szenarien übertrifft.
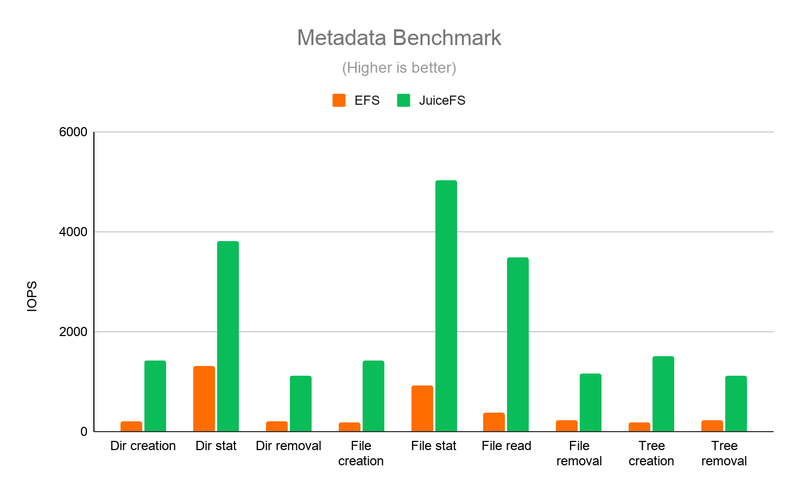 Abbildung 1. Metadaten-Benchmark.
Abbildung 1. Metadaten-Benchmark.
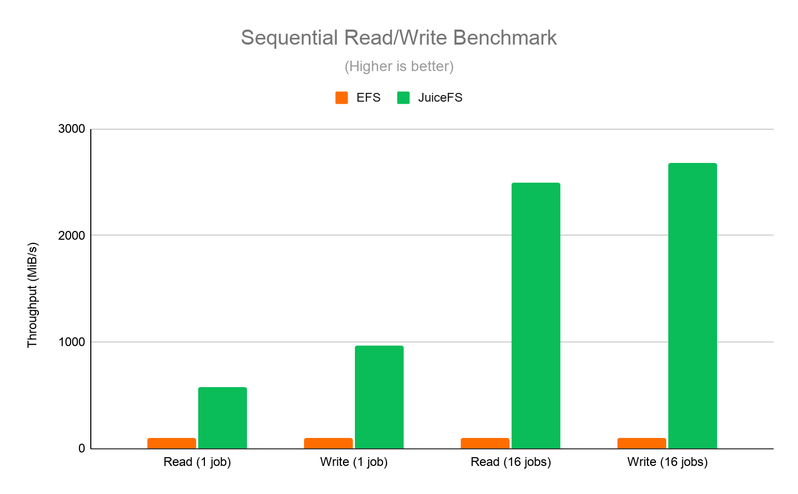 Abbildung 2. Benchmark für sequenzielles Lesen/Schreiben.
Abbildung 2. Benchmark für sequenzielles Lesen/Schreiben.
Darüber hinaus zeigen Benchmark-Tests, dass die Abrufzeit der ersten Abfrage, also die Zeit zum Laden neu eingefügter Daten von der Festplatte in den Arbeitsspeicher, für den JuiceFS-basierten Milvus-Cluster im Durchschnitt nur 0,032 Sekunden beträgt. Dies zeigt, dass Daten nahezu augenblicklich von der Festplatte in den Arbeitsspeicher geladen werden. Für diesen Test wird die Abrufzeit der ersten Abfrage anhand von einer Million Zeilen 128-dimensionaler Vektordaten gemessen, die in Batches von 100k in Intervallen von 1 bis 8 Sekunden eingefügt werden.
JuiceFS ist ein stabiles und zuverlässiges gemeinsames Dateispeichersystem, und der auf JuiceFS aufgebaute Milvus-Cluster bietet sowohl hohe Leistung als auch flexible Speicherkapazität.
Erfahren Sie mehr über Milvus
Milvus ist ein leistungsstarkes Tool, das eine Vielzahl von Anwendungen für künstliche Intelligenz und Vektorähnlichkeitssuche unterstützen kann. Um mehr über das Projekt zu erfahren, sehen Sie sich die folgenden Ressourcen an:
- Lesen Sie unseren Blog.
- Tauschen Sie sich mit unserer Open-Source-Community auf Slack aus.
- Nutzen Sie die weltweit beliebteste Vektordatenbank auf GitHub oder tragen Sie zu ihr bei.
- Testen und implementieren Sie KI-Anwendungen schnell mit unserem neuen Bootcamp.
 Biografie von Changjian Gao.
Biografie von Changjian Gao.
 Biografie von Jingjing Jia.
Biografie von Jingjing Jia.
Weiterlesen

A Few Notes from Databricks Data + AI Summit 2026: Why the Data Layer Matters Again
James Luan shares notes from Databricks Data + AI Summit 2026 on why production AI is pushing the data layer back to the center of infrastructure.

Milvus WebUI: A Visual Management Tool for Your Vector Database
Explore Milvus WebUI to monitor, manage, and optimize your vector database with real-time insights, performance tracking, and system health monitoring.

DeepSeek Always Busy? Deploy It Locally with Milvus in Just 10 Minutes—No More Waiting!
Learn how to set up DeepSeek-R1 on your local machine using Ollama, AnythingLLM, and Milvus in just 10 minutes. Bypass busy servers and enhance AI responses with custom data.