




Audio-Retrieval basierend auf Milvus
Ton ist ein informationsdichter Datentyp. Auch wenn er im Zeitalter von Videoinhalten antiquiert erscheinen mag, bleibt Audio für viele Menschen eine primäre Informationsquelle. Trotz eines langfristigen Rückgangs der Hörer hörten 83 % der Amerikaner ab 12 Jahren in einer bestimmten Woche im Jahr 2020 terrestrisches (AM/FM-)Radio (gegenüber 89 % im Jahr 2019). Umgekehrt verzeichnet Online-Audio in den letzten zwei Jahrzehnten einen stetigen Anstieg der Hörer, wobei laut derselben Studie des Pew Research Center Berichten zufolge 62 % der Amerikaner wöchentlich irgendeine Form davon hören.
Als Welle umfasst Schall vier Eigenschaften: Frequenz, Amplitude, Wellenform und Dauer. In der musikalischen Terminologie werden diese Tonhöhe, Dynamik, Klangfarbe und Dauer genannt. Klänge helfen Menschen und anderen Tieren außerdem dabei, unsere Umgebung wahrzunehmen und zu verstehen, indem sie kontextuelle Hinweise auf den Standort und die Bewegung von Objekten in unserer Umgebung liefern.
Als Informationsträger kann Audio in drei Kategorien eingeteilt werden:
- Sprache: Ein Kommunikationsmedium, das aus Wörtern und Grammatik besteht. Mit Spracherkennungsalgorithmen kann Sprache in Text umgewandelt werden.
- Musik: Vokale und/oder instrumentale Klänge, die kombiniert werden, um eine Komposition zu erzeugen, die aus Melodie, Harmonie, Rhythmus und Klangfarbe besteht. Musik kann durch eine Partitur dargestellt werden.
- Wellenform: Ein digitales Audiosignal, das durch die Digitalisierung analoger Klänge gewonnen wird. Wellenformen können Sprache, Musik sowie natürliche oder synthetisierte Klänge darstellen.
Audio-Retrieval kann verwendet werden, um Online-Medien in Echtzeit zu durchsuchen und zu überwachen, um Verletzungen geistiger Eigentumsrechte zu bekämpfen. Es nimmt außerdem eine wichtige Rolle bei der Klassifizierung und statistischen Analyse von Audiodaten ein.
Verarbeitungstechnologien
Sprache, Musik und andere generische Klänge weisen jeweils einzigartige Eigenschaften auf und erfordern unterschiedliche Verarbeitungsmethoden. Typischerweise wird Audio in Gruppen unterteilt, die Sprache enthalten, und Gruppen, die keine Sprache enthalten:
- Sprach-Audio wird durch automatische Spracherkennung verarbeitet.
- Nicht-sprachliches Audio, einschließlich musikalischem Audio, Soundeffekten und digitalisierten Sprachsignalen, wird mithilfe von Audio-Retrieval-Systemen verarbeitet.
Dieser Artikel konzentriert sich darauf, wie ein Audio-Retrieval-System verwendet wird, um nicht-sprachliche Audiodaten zu verarbeiten. Spracherkennung wird in diesem Artikel nicht behandelt
Extraktion von Audio-Merkmalen
Die Merkmalsextraktion ist die wichtigste Technologie in Audio-Retrieval-Systemen, da sie die Suche nach Audio-Ähnlichkeit ermöglicht. Methoden zur Extraktion von Audio-Merkmalen werden in zwei Kategorien unterteilt:
- Traditionelle Modelle zur Extraktion von Audio-Merkmalen wie Gaußsche Mischmodelle (GMMs) und Hidden-Markov-Modelle (HMMs);
- Auf Deep Learning basierende Modelle zur Extraktion von Audio-Merkmalen wie rekurrente neuronale Netze (RNNs), Long-Short-Term-Memory-Netze (LSTM), Encoding-Decoding-Frameworks, Attention-Mechanismen usw.
Auf Deep Learning basierende Modelle weisen eine Fehlerrate auf, die um eine Größenordnung niedriger ist als die traditioneller Modelle, und gewinnen daher als Kerntechnologie im Bereich der Audiosignalverarbeitung an Bedeutung.
Audiodaten werden in der Regel durch die extrahierten Audio-Merkmale dargestellt. Der Retrieval-Prozess durchsucht und vergleicht diese Merkmale und Attribute statt der Audiodaten selbst. Daher hängt die Effektivität des Audio-Ähnlichkeits-Retrievals weitgehend von der Qualität der Merkmalsextraktion ab.
In diesem Artikel werden groß angelegte vortrainierte neuronale Audio-Netzwerke zur Audio-Mustererkennung (PANNs) verwendet, um Merkmalsvektoren aufgrund ihrer mittleren durchschnittlichen Genauigkeit (mAP) von 0,439 (Hershey et al., 2017) zu extrahieren.
Nach der Extraktion der Merkmalsvektoren der Audiodaten können wir mit Milvus eine leistungsstarke Analyse von Merkmalsvektoren implementieren.
Vektorähnlichkeitssuche
Milvus ist eine cloudnative Open-Source-Vektordatenbank, die zur Verwaltung von Einbettungsvektoren entwickelt wurde, die von Machine-Learning-Modellen und neuronalen Netzen generiert werden. Sie wird häufig in Szenarien wie Computer Vision, Verarbeitung natürlicher Sprache, Computerchemie, personalisierten Empfehlungssystemen und mehr eingesetzt.
Das folgende Diagramm zeigt den allgemeinen Ähnlichkeitssuchprozess mit Milvus:
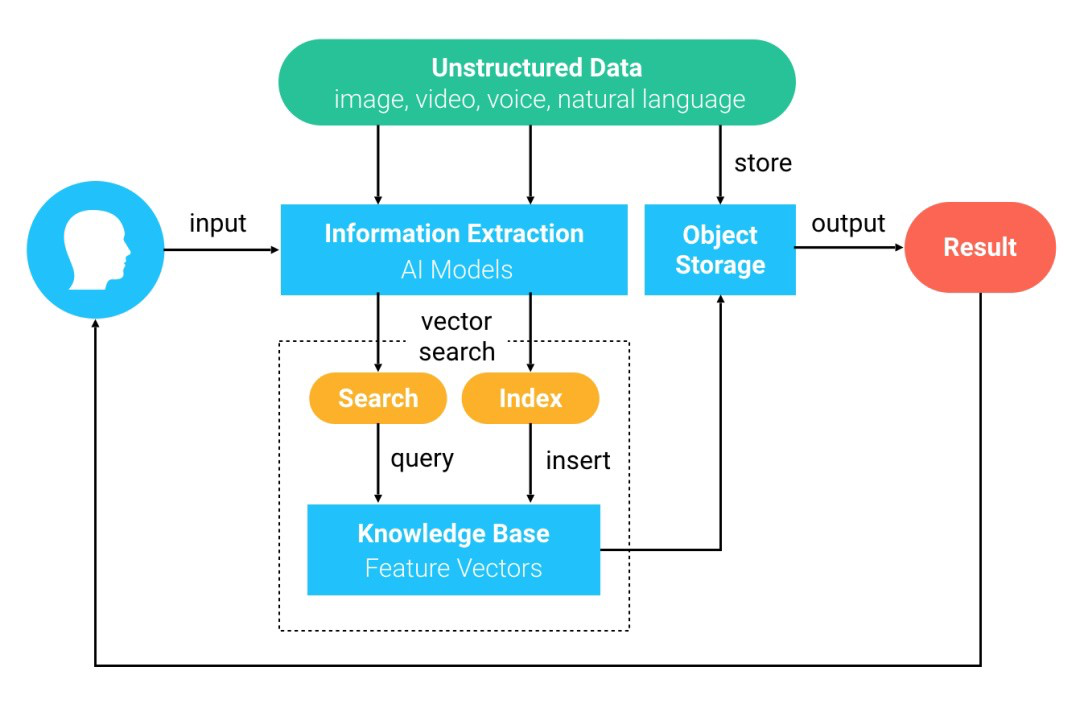 Milvus' Vektorähnlichkeitssuchprozess.
Milvus' Vektorähnlichkeitssuchprozess.
- Unstrukturierte Daten werden durch Deep-Learning-Modelle in Merkmalsvektoren umgewandelt und in Milvus eingefügt.
- Milvus speichert und indiziert diese Merkmalsvektoren.
- Auf Anfrage sucht Milvus nach den Vektoren, die dem Abfragevektor am ähnlichsten sind, und gibt sie zurück.
Systemübersicht
Das Audio-Retrieval-System besteht hauptsächlich aus zwei Teilen: Einfügen (schwarze Linie) und Suche (rote Linie).
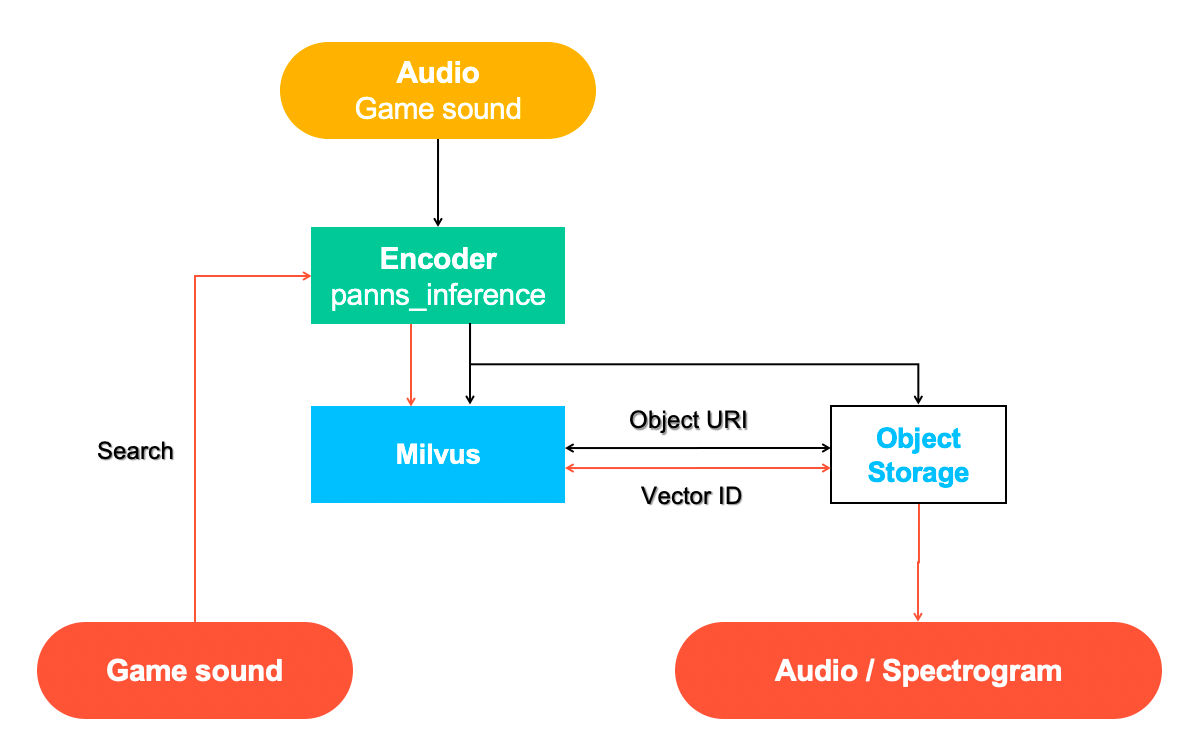 Audio-Retrieval-System powered by Milvus.
Audio-Retrieval-System powered by Milvus.
Der in diesem Projekt verwendete Beispieldatensatz enthält Open-Source-Spielesounds, und der Code ist im Milvus bootcamp ausführlich beschrieben.
Schritt 1: Daten einfügen
Nachfolgend finden Sie den Beispielcode zur Generierung von Audio-Einbettungen mit dem vortrainierten PANNs-inference-Modell und zum Einfügen in Milvus, das jeder Vektoreinbettung eine eindeutige ID zuweist.
1 wav_name, vectors_audio = get_audio_embedding(audio_path)
2 if vectors_audio:
3 embeddings.append(vectors_audio)
4 wav_names.append(wav_name)
5 ids_milvus = insert_vectors(milvus_client, table_name, embeddings)
6
Anschließend werden die zurückgegebenen ids_milvus zusammen mit anderen relevanten Informationen (z. B. wav_name) für die in einer MySQL-Datenbank gespeicherten Audiodaten zur nachfolgenden Verarbeitung gespeichert.
1 get_ids_correlation(ids_milvus, wav_name)
2 load_data_to_mysql(conn, cursor, table_name)
3
Schritt 2: Audiosuche
Milvus berechnet die Inner-Product-Distanz zwischen den vorab gespeicherten Merkmalsvektoren und den Eingabemerkmalsvektoren, die mithilfe des PANNs-inference-Modells aus den Abfrage-Audiodaten extrahiert werden, und gibt die ids_milvus ähnlicher Merkmalsvektoren zurück, die den gesuchten Audiodaten entsprechen.
1 _, vectors_audio = get_audio_embedding(audio_filename)
2 results = search_vectors(milvus_client, table_name, [vectors_audio], METRIC_TYPE, TOP_K)
3 ids_milvus = [x.id for x in results[0]]
4 audio_name = search_by_milvus_ids(conn, cursor, ids_milvus, table_name)
5
API-Referenz und Demo
API
Dieses Audio-Retrieval-System basiert auf Open-Source-Code. Seine Hauptfunktionen sind das Einfügen und Löschen von Audiodaten. Alle APIs können angezeigt werden, indem Sie 127.0.0.1:
Demo
Wir hosten online eine Live-Demo des Milvus-basierten Audio-Retrieval-Systems, die Sie mit Ihren eigenen Audiodaten ausprobieren können.
 Audio-Suchdemo powered by Milvus.
Audio-Suchdemo powered by Milvus.
Fazit
Im Zeitalter von Big Data stellen Menschen fest, dass ihr Leben von allen Arten von Informationen erfüllt ist. Um diese besser zu verstehen, reicht herkömmliches Text-Retrieval nicht mehr aus. Die heutige Information-Retrieval-Technologie benötigt dringend das Retrieval verschiedener unstrukturierter Datentypen wie Videos, Bilder und Audio.
Unstrukturierte Daten, die für Computer schwer zu verarbeiten sind, können mithilfe von Deep-Learning-Modellen in Merkmalsvektoren umgewandelt werden. Diese umgewandelten Daten können von Maschinen leicht verarbeitet werden, sodass wir unstrukturierte Daten auf eine Weise analysieren können, wie es unseren Vorgängern nie möglich war. Milvus, eine Open-Source-Vektordatenbank, kann die von KI-Modellen extrahierten Merkmalsvektoren effizient verarbeiten und bietet eine Vielzahl gängiger Vektorähnlichkeitsberechnungen.
Referenzen
Hershey, S., Chaudhuri, S., Ellis, D.P., Gemmeke, J.F., Jansen, A., Moore, R.C., Plakal, M., Platt, D., Saurous, R.A., Seybold, B. und Slaney, M., 2017, März. CNN-Architekturen für groß angelegte Audioklassifizierung. In 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), S. 131-135, 2017
Bleib in Kontakt

Weiterlesen

Zilliz Cloud Now Available in AWS Asia Pacific (Seoul)
Zilliz Cloud is now available in AWS Seoul — low-latency vector search, in-country data residency, and one-step migration for Korean AI teams. 31 regions across 5 clouds.

Introducing Zilliz Cloud Global Cluster: Region-Level Resilience for Mission-Critical AI
Zilliz Cloud Global Cluster delivers multi-region resilience, automatic failover, and fast global AI search with built-in security and compliance.
Milvus/Zilliz + Surveillance: How Vector Databases Transform Multi-Camera Tracking
See how Milvus vector database enhances multi-camera tracking with similarity-based matching for better surveillance in retail, warehouses and transport hubs.