




Wie wir semantische Suche genutzt haben, um unsere Suche 10-mal intelligenter zu machen
Bei Tokopedia wissen wir, dass der Wert unseres Produktkorpus erst dann erschlossen wird, wenn unsere Käufer Produkte finden können, die für sie relevant sind. Deshalb bemühen wir uns, die Relevanz der Suchergebnisse zu verbessern.
Um diese Bemühungen weiter voranzutreiben, führen wir die Ähnlichkeitssuche auf Tokopedia ein. Wenn Sie auf Mobilgeräten zur Suchergebnisseite gehen, finden Sie eine „…“-Schaltfläche, die ein Menü öffnet, das Ihnen die Möglichkeit gibt, nach Produkten zu suchen, die dem Produkt ähnlich sind.
Keyword-basierte Suche
Die Tokopedia-Suche verwendet Elasticsearch für die Suche und das Ranking von Produkten. Bei jeder Suchanfrage fragen wir zunächst Elasticsearch ab, das Produkte entsprechend der Suchanfrage einstuft. ElasticSearch speichert jedes Wort als eine Zahlenfolge, die ASCII- (oder UTF-)Codes für jeden Buchstaben darstellt. Es erstellt einen invertierten Index, um schnell herauszufinden, welche Dokumente Wörter aus der Benutzeranfrage enthalten, und findet dann mithilfe verschiedener Scoring-Algorithmen die beste Übereinstimmung unter ihnen. Diese Scoring-Algorithmen achten kaum darauf, was die Wörter bedeuten, sondern vielmehr darauf, wie häufig sie im Dokument vorkommen, wie nahe sie beieinander liegen usw. Die ASCII-Darstellung enthält offensichtlich genug Informationen, um die Semantik zu vermitteln (schließlich können wir Menschen sie verstehen). Leider gibt es keinen guten Algorithmus, mit dem der Computer ASCII-codierte Wörter nach ihrer Bedeutung vergleichen kann.
Vektordarstellung
Eine Lösung hierfür wäre, eine alternative Darstellung zu entwickeln, die uns nicht nur etwas über die im Wort enthaltenen Buchstaben sagt, sondern auch etwas über seine Bedeutung. Beispielsweise könnten wir codieren, mit welchen anderen Wörtern unser Wort häufig zusammen verwendet wird (dargestellt durch den wahrscheinlichen Kontext). Wir würden dann annehmen, dass ähnliche Kontexte ähnliche Dinge darstellen, und versuchen, sie mit mathematischen Methoden zu vergleichen. Wir könnten sogar einen Weg finden, ganze Sätze nach ihrer Bedeutung zu codieren.
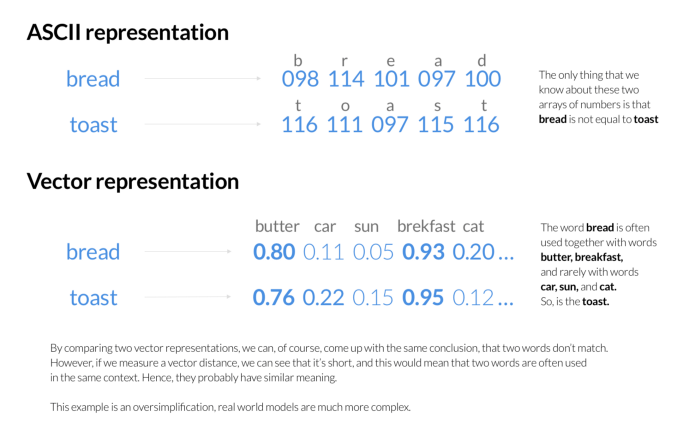 Die Vektordarstellung offenbart im Vergleich zur ASCII-Darstellung auch die Bedeutung von Wörtern.
Die Vektordarstellung offenbart im Vergleich zur ASCII-Darstellung auch die Bedeutung von Wörtern.
Auswahl einer Suchmaschine für Embedding-Ähnlichkeitssuche
Da wir nun Feature-Vektoren haben, bleibt die Frage, wie wir aus der großen Menge an Vektoren diejenigen abrufen, die dem Zielvektor ähnlich sind. Was die Embeddings-Suchmaschine betrifft, haben wir POCs mit mehreren auf Github verfügbaren Engines ausprobiert; einige davon sind FAISS, Vearch, Milvus.
Wir bevorzugen Milvus gegenüber anderen Engines basierend auf den Ergebnissen von Lasttests. Einerseits haben wir FAISS bereits zuvor in anderen Teams verwendet und möchten daher etwas Neues ausprobieren. Im Vergleich zu Milvus ist FAISS eher eine zugrunde liegende Bibliothek und daher nicht besonders bequem zu verwenden. Als wir mehr über Milvus erfuhren, entschieden wir uns schließlich für Milvus wegen seiner zwei Hauptmerkmale:
Milvus ist sehr einfach zu verwenden. Alles, was Sie tun müssen, ist, das Docker-Image zu pullen und die Parameter entsprechend Ihrem eigenen Szenario zu aktualisieren.
Es unterstützt mehr Indizes und verfügt über eine ausführliche unterstützende Dokumentation.
Kurz gesagt: Milvus ist sehr benutzerfreundlich, und die Dokumentation ist ziemlich detailliert. Wenn Sie auf ein Problem stoßen, finden Sie in der Regel Lösungen in der Dokumentation; andernfalls können Sie jederzeit Unterstützung von der Milvus-Community erhalten.
Milvus-Cluster-Service
Nachdem wir beschlossen hatten, Milvus als Suchmaschine für Feature-Vektoren zu verwenden, entschieden wir uns, Milvus für einen unserer Ads-Service-Anwendungsfälle einzusetzen, bei dem wir Keywords mit niedriger Fill Rate mit Keywords mit hoher Fill Rate abgleichen wollten. Wir konfigurierten einen Standalone-Knoten in einer Entwicklungsumgebung (DEV) und nahmen den Dienst in Betrieb. Er lief einige Tage lang gut und lieferte uns verbesserte CTR/CVR-Kennzahlen. Wenn ein Standalone-Knoten in der Produktion abstürzte, würde der gesamte Dienst nicht mehr verfügbar sein. Daher müssen wir einen hochverfügbaren Suchdienst bereitstellen.
Milvus bietet sowohl Mishards, eine Cluster-Sharding-Middleware, als auch Milvus-Helm für die Konfiguration. Bei Tokopedia verwenden wir Ansible-Playbooks für die Einrichtung der Infrastruktur, daher haben wir ein Playbook für die Infra-Orchestrierung erstellt. Das Diagramm unten aus der Dokumentation von Milvus zeigt, wie Mishards funktioniert:
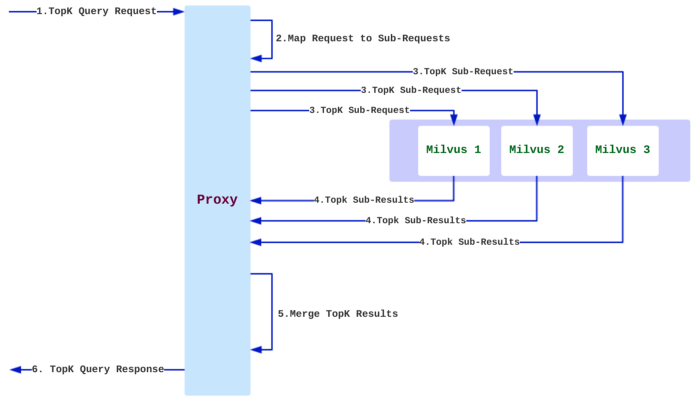 So funktioniert Mishards.
So funktioniert Mishards.
Mishards leitet eine Anfrage von upstream hinunter an seine Submodule weiter, teilt die upstream-Anfrage auf und sammelt dann die Ergebnisse der Subdienste und gibt sie an upstream zurück. Die Gesamtarchitektur der Mishards-basierten Cluster-Lösung ist unten dargestellt:
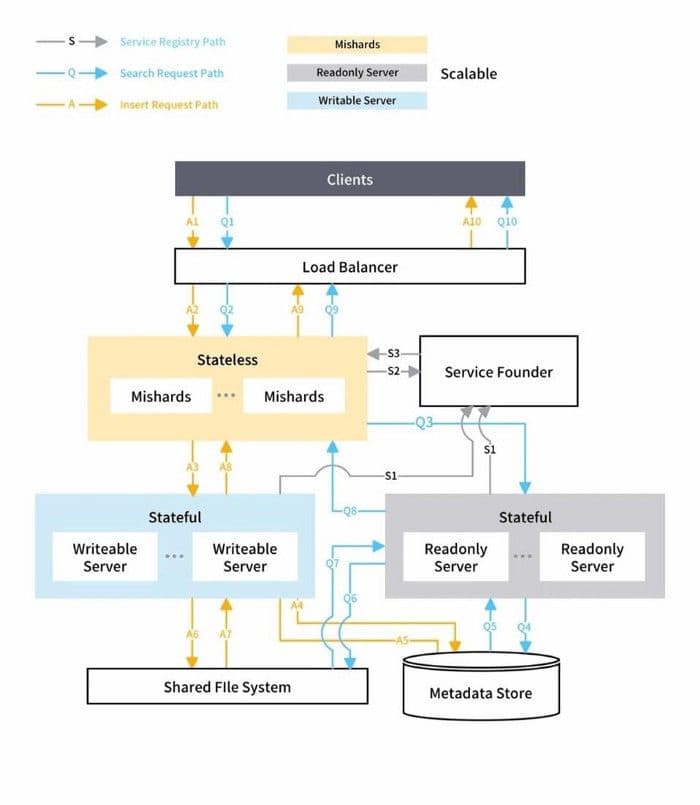 Gesamtarchitektur von Mishards.
Gesamtarchitektur von Mishards.
Die offizielle Dokumentation bietet eine klare Einführung in Mishards. Sie können Mishards ansehen, wenn Sie interessiert sind.
In unserem Keyword-to-Keyword-Dienst haben wir mit Milvus ansible einen beschreibbaren Knoten, zwei schreibgeschützte Knoten und eine Mishards-Middleware-Instanz in GCP bereitgestellt. Bisher läuft dies stabil. Ein wesentlicher Bestandteil dessen, was es ermöglicht, die Millionen-, Milliarden- oder sogar Billionen-Vektor-Datensätze, auf die Similarity-Search-Engines angewiesen sind, effizient abzufragen, ist Indexierung, ein Prozess der Datenorganisation, der die Suche in Big Data drastisch beschleunigt.
Wie beschleunigt Vektorindexierung die Ähnlichkeitssuche?
Similarity-Search-Engines arbeiten, indem sie Eingaben mit einer Datenbank vergleichen, um Objekte zu finden, die der Eingabe am ähnlichsten sind. Indexierung ist der Prozess der effizienten Organisation von Daten, und sie spielt eine wichtige Rolle dabei, die Ähnlichkeitssuche nützlich zu machen, indem sie zeitaufwendige Abfragen in großen Datensätzen drastisch beschleunigt. Nachdem ein massiver Vektordatensatz indexiert wurde, können Abfragen an Cluster oder Teilmengen von Daten weitergeleitet werden, die mit hoher Wahrscheinlichkeit Vektoren enthalten, die einer Eingabeabfrage ähnlich sind. In der Praxis bedeutet dies, dass ein gewisser Grad an Genauigkeit geopfert wird, um Abfragen auf wirklich großen Vektordaten zu beschleunigen.
Eine Analogie lässt sich zu einem Wörterbuch ziehen, in dem Wörter alphabetisch sortiert sind. Wenn man ein Wort nachschlägt, kann man schnell zu einem Abschnitt navigieren, der nur Wörter mit demselben Anfangsbuchstaben enthält — was die Suche nach der Definition des Eingabeworts drastisch beschleunigt.
Was kommt als Nächstes, fragen Sie?
 Blog_How we used semantic search to make our search 10x smarter_5.jpeg
Blog_How we used semantic search to make our search 10x smarter_5.jpeg
Wie oben gezeigt, gibt es keine Lösung, die für alles passt; wir möchten stets die Leistung des Modells verbessern, das zur Gewinnung der Embeddings verwendet wird.
Außerdem möchten wir aus technischer Sicht mehrere Lernmodelle gleichzeitig ausführen und die Ergebnisse der verschiedenen Experimente vergleichen. Bleiben Sie dran für weitere Informationen zu unseren Experimenten wie Bildsuche und Videosuche.
Referenzen:
- Mishards-Dokumentation:https://milvus.io/docs/v0.10.2/mishards.md
- Mishards: https://github.com/milvus-io/milvus/tree/master/shards
- Milvus-Helm: https://github.com/milvus-io/milvus-helm/tree/master/charts/milvus
Dieser Blogartikel wurde erneut veröffentlicht von: https://medium.com/tokopedia-engineering/how-we-used-semantic-search-to-make-our-search-10x-smarter-bd9c7f601821
Lesen Sie weitere Anwenderberichte, um mehr darüber zu erfahren, wie man mit Milvus Dinge entwickelt.
Weiterlesen

AI Agents Are Quietly Transforming E-Commerce — Here’s How
Discover how AI agents transform e-commerce with autonomous decision-making, enhanced product discovery, and vector search capabilities for today's retailers.
Milvus/Zilliz + Surveillance: How Vector Databases Transform Multi-Camera Tracking
See how Milvus vector database enhances multi-camera tracking with similarity-based matching for better surveillance in retail, warehouses and transport hubs.

Proactive Monitoring for Vector Database: Zilliz Cloud Integrates with Datadog
we're excited to announce Zilliz Cloud's integration with Datadog, enabling comprehensive monitoring and observability for your vectorDB deployments.