




Machen Sie sich bereit für GPT-4 mit GPTCache & Milvus, sparen Sie viel bei multimodaler KI
Einführung
Da die Welt zunehmend digital wird, steigt die Nachfrage nach Lösungen für künstliche Intelligenz (KI), die riesige Datenmengen verstehen und analysieren können. OpenAI's ChatGPT, das von GPT-3.5 angetrieben wird, hat das Feld der Verarbeitung natürlicher Sprache (NLP) bereits revolutioniert und ein erhebliches Interesse an großen Sprachmodellen (LLMs) geweckt. Während die Einführung von LLMs weiterhin Aufmerksamkeit erregt und in verschiedenen Branchen wächst, steigt auch der Bedarf an fortschrittlicheren großen KI-Modellen, die multimodale Daten verarbeiten können. Die Tech-Welt ist bereits voller Vorfreude auf GPT-4, das verspricht, durch die Ermöglichung visueller Eingaben noch leistungsfähiger und vielseitiger zu sein. Die Zusammenarbeit von GPT-4 mit Bildgenerierungsmodellen birgt ebenfalls enormes Potenzial. Um sich auf diese bevorstehende Revolution vorzubereiten, hat Zilliz GPTCache integriert mit Milvus eingeführt – eine bahnbrechende Lösung, die Unternehmen dabei helfen kann, ein Vermögen bei multimodaler KI zu sparen.
Multimodale KI bezieht sich auf die Integration mehrerer Wahrnehmungs- und Kommunikationsmodi, wie Sprache, Sehen, Sprache und Gestik, um intelligentere und effektivere KI-Systeme zu schaffen. Dieser Ansatz ermöglicht es KI-Modellen, menschliche Interaktionen und Umgebungen besser zu verstehen und zu interpretieren sowie genauere und nuanciertere Antworten zu generieren. Multimodale KI hat Anwendungen in verschiedenen Bereichen, darunter Gesundheitswesen, Bildung, Unterhaltung und Verkehr. Einige Beispiele für multimodale KI-Systeme sind virtuelle Assistenten wie Siri und Alexa, autonome Fahrzeuge und medizinische Diagnosetools, die Bilder und Patientendaten gemeinsam analysieren.
In diesem Artikel werden wir uns mit den Details von GPTCache befassen und untersuchen, wie es in Verbindung mit Milvus funktioniert, um in multimodalen Szenarien eine nahtlosere und leistungsfähigere Benutzererfahrung zu bieten.
Semantischer Cache für multimodale KI
In den meisten Fällen erfordert das Erreichen der gewünschten Ergebnisse in multimodalen KI-Anwendungen den Einsatz großer Modelle. Die Verarbeitung solcher Modelle oder Aufrufe kann jedoch zeitaufwendig und teuer sein. Hier kommt GPTCache ins Spiel – es ermöglicht dem System, zunächst im Cache nach potenziellen Antworten zu suchen, bevor eine Anfrage an ein großes Modell gesendet wird. GPTCache beschleunigt den gesamten Prozess und hilft, die Kosten für den Betrieb großer Modelle zu senken.
Semantischen Cache mit GPTCache erkunden
Ein semantischer Cache speichert und ruft Wissensrepräsentationen von Konzepten ab. Er ist darauf ausgelegt, semantische Informationen oder Wissen strukturiert zu speichern und abzurufen. Dadurch kann ein KI-System Anfragen oder Aufforderungen besser verstehen und darauf reagieren. Die Idee hinter einem semantischen Cache besteht darin, schnelleren Zugriff auf relevante Informationen zu ermöglichen, indem vorberechnete Antworten auf häufig gestellte Fragen oder Anfragen bereitgestellt werden, was dazu beitragen kann, die Leistung und Effizienz von KI-Anwendungen zu verbessern.
GPTCache ist ein Projekt, das entwickelt wurde, um die Antwortzeit zu optimieren und die Kosten für API-Aufrufe im Zusammenhang mit großen Modellen zu senken. Wir haben GPTcache entwickelt, um einen semantischen Cache zu erstellen, der Modellantworten speichert und die Leistungsfähigkeit von Milvus nutzt. Die Technologie basiert auf Milvus und umfasst mehrere wichtige Komponenten, wie den Adapter für große Modelle, den Kontextmanager, den Embedding-Generator, den Cache-Manager, den Ähnlichkeitsbewerter sowie Vor-/Nachprozessoren.
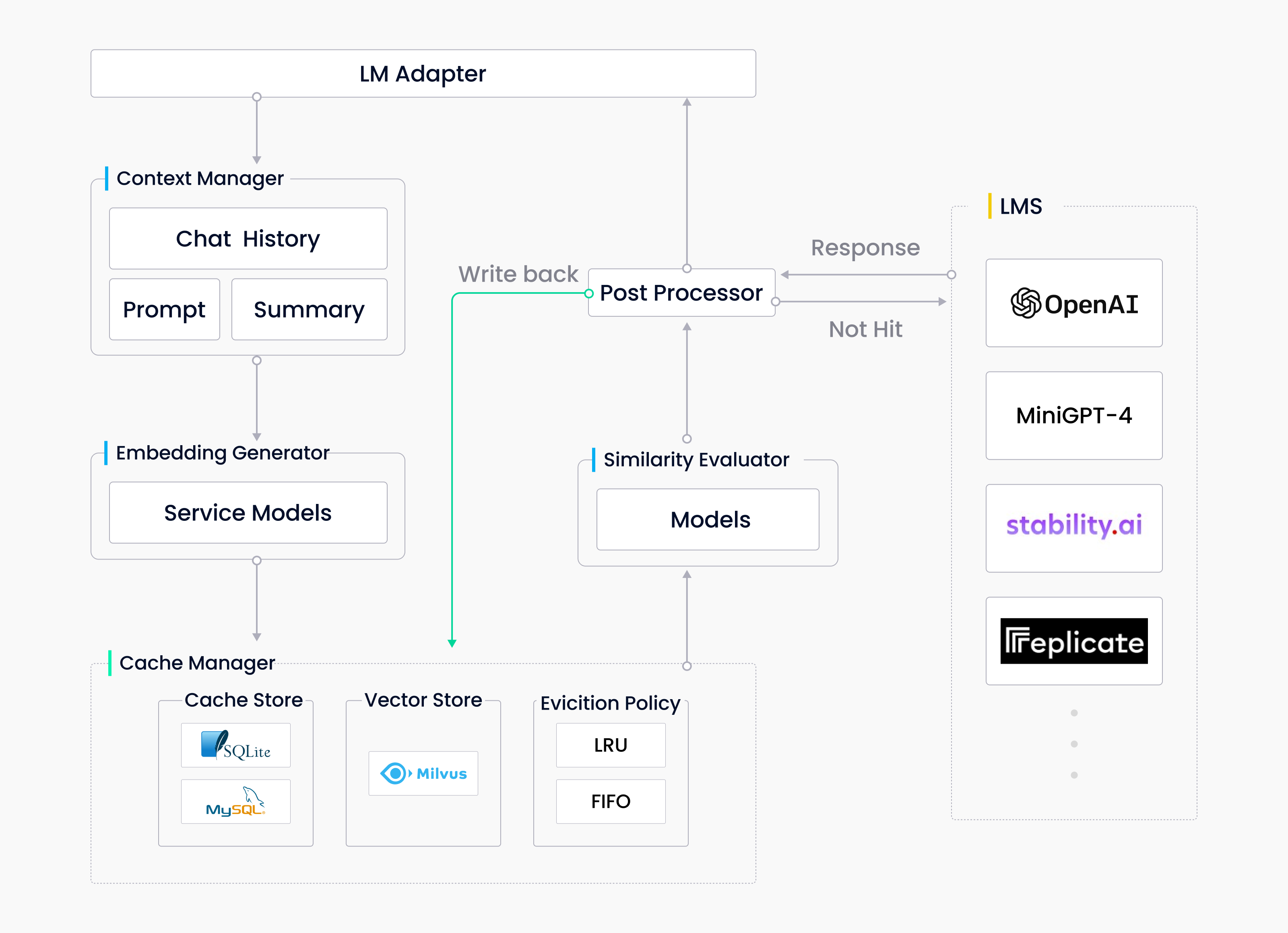 GPTCache-Architektur
GPTCache-Architektur
Der Adapter stellt sicher, dass GPTCache nahtlos mit jedem großen Modell funktioniert. Der Kontextmanager ermöglicht mehr Flexibilität, sodass das System verschiedene Daten in unterschiedlichen Phasen verarbeiten kann. Der Embedding-Generator konvertiert Daten in Embeddings für die Vektorspeicherung und semantische Suche. Alle Vektoren und andere wertvolle Daten werden im Cache gespeichert. Milvus unterstützt nicht nur die Speicherung großer Datenmengen, sondern hilft auch dabei, die Ähnlichkeitssuche zu beschleunigen und ihre Leistung zu verbessern. Schließlich ist der Evaluator dafür verantwortlich zu bewerten, ob potenzielle Antworten, die aus dem Cache abgerufen wurden, gut genug für die Bedürfnisse der Benutzer sind. Das folgende Code-Snippet zeigt, wie man einen Cache mit verschiedenen Modulen in GPTCache initialisiert.
from gptcache import cache
from gptcache.manager import get_data_manager, CacheBase, VectorBase, ObjectBase
from gptcache.processor.pre import get_prompt
from gptcache.processor.post import temperature_softmax
from gptcache.embedding import Onnx
from gptcache.similarity_evaluation.distance import SearchDistanceEvaluation
onnx = Onnx()
cache_base = CacheBase('sqlite')
vector_base = VectorBase(
'milvus',
host='localhost',
port='19530',
dimension=onnx.dimension
)
object_base = ObjectBase('local', path='./objects')
data_manager = get_data_manager(cache_base, vector_base, object_base)
cache.init(
pre_embedding_func=get_prompt, # Vorverarbeitung
embedding_func=onnx.to_embeddings, # Embedding-Generator
data_manager=data_manager, # Cache-Manager
similarity_evaluation=SearchDistanceEvaluation() # Evaluator
post_process_messages_func=temperature_softmax # Nachverarbeitung
)
Semantische Daten in einer Vektordatenbank cachen
Einer der Eckpfeiler eines semantischen Caches wie GPTCache ist die Vektordatenbank. Konkret konvertiert der Embedding-Generator von GPTCache Daten in Embeddings für die Vektorspeicherung und semantische Suche. Das Speichern von Vektoren in einer Vektordatenbank wie Milvus unterstützt nicht nur die Speicherung großer Datenmengen, sondern hilft auch dabei, die Ähnlichkeitssuche zu beschleunigen und ihre Leistung zu verbessern. Dies ermöglicht ein effizienteres Abrufen potenzieller Antworten aus dem Cache.
Ein vortrainiertes multimodales Modell lernt einen Vektorraum, um verschiedene Arten von Eingaben darzustellen. Dadurch kann es ergänzende Informationen erfassen, die von anderen Modalitäten bereitgestellt werden. Dieses Paradigma ermöglicht es dem System, Daten mit unterschiedlichen Modalitäten auf einheitliche Weise zu interpretieren, wodurch eine genauere und effizientere Verarbeitung über semantische Suche ermöglicht wird. Vektordatenbanken ermöglichen die semantische Suche für multimodale Eingaben über Vektorähnlichkeitsalgorithmen. Im Gegensatz zu herkömmlichen Datenbanken, die Daten in Zeilen und Spalten speichern, speichern und rufen Vektordatenbanken unstrukturierte Daten als Vektoren ab. Vektordatenbanken verwalten hochdimensionale Daten, die in multimodalen KI-Anwendungen, die verschiedene Datentypen als Vektoren verarbeiten, weit verbreitet sind.
Vorteile der Verwendung von Milvus
Das Milvus-Ökosystem bietet hilfreiche Werkzeuge für Datenbanküberwachung, Datenmigration und Datengrößenschätzung. Für eine unkompliziertere Implementierung und Wartung von Milvus gibt es einen cloudnativen Dienst Zilliz Cloud. Die Kombination von Milvus mit GPTCache bietet eine leistungsstarke Lösung zur Verbesserung der Funktionalität und Leistung multimodaler KI-Anwendungen. Ob Sie mit großen Datenmengen, komplexen Modellen oder vielfältigen Datentypen arbeiten, dieser Ansatz kann dazu beitragen, die Datenverarbeitung zu optimieren und die Genauigkeit und Geschwindigkeit der Ergebnisse zu verbessern. Die Integration von Milvus mit GPTCache in multimodaler KI kann mehrere leistungsstarke Vorteile bieten. Hier sind einige der bemerkenswertesten:
- Effiziente Speicherung und Abfrage von Daten
Milvus wurde speziell für das Speichern und Abrufen groß angelegter Vektordaten entwickelt. Darüber hinaus ist ein Vektor die „allgemeine Sprache“, die von Deep-Learning-Modellen gesprochen wird. Milvus kann Vektoren problemlos verarbeiten und bietet schnellen und effizienten Zugriff auf multimodale Daten. Die Verwendung von Milvus kann zu schnelleren Antwortzeiten und einer besseren Benutzererfahrung führen.
- Verbesserte Flexibilität und Skalierbarkeit
Mit dem Wachstum der von KI-Anwendungen verarbeiteten Datenmenge steigt auch der Bedarf an einer skalierbaren Lösung. Durch die Einbindung von Milvus kann das System nahtlos skaliert werden, um wachsenden Anforderungen gerecht zu werden. Darüber hinaus bietet Milvus eine breite Palette von Funktionen, die die allgemeine Flexibilität und Funktionalität multimodaler KI verbessern können.
- Erhöhte Genauigkeit und Leistung
Dank der von Milvus bereitgestellten einheitlichen Speicherung und Abfrage von Daten können multimodale KI-Anwendungen Eingaben aus verschiedenen Datentypen schneller und genauer verarbeiten. Dies kann zu genaueren Ergebnissen und einer verbesserten Gesamtleistung des Systems führen.
- Benutzerfreundlichkeit
Milvus bietet verschiedene Optionen für die lokale Bereitstellung, einschließlich eines Schnellstarts mit pip. Es stellt außerdem einen Cloud-Service über Zilliz Cloud bereit, der es Benutzern ermöglicht, ihre Milvus-Instanzen schnell zu starten und zu skalieren. Milvus unterstützt außerdem mehrere Sprach-SDKs, darunter Python, Java und Go (weitere in Entwicklung), wodurch es sich leicht in bestehende Anwendungen integrieren lässt. Darüber hinaus stellt Milvus eine Restful API für die einfache Interaktion mit dem Server bereit.
- Popularität und Zuverlässigkeit
Milvus hat aufgrund seiner hohen Skalierbarkeit und Leistung enorme Popularität erlangt. Mit über 1.000 Unternehmenskunden und einer aktiven Open-Source-Community hat sich Milvus als zuverlässige Lösung für die Verwaltung großer Mengen strukturierter und unstrukturierter Daten positioniert. Als Absolventenprojekt der LF AI & Data Foundation profitiert Milvus zudem von institutioneller Unterstützung, was seine Position als bevorzugte Datenbank für Organisationen, die effiziente und zuverlässige Datenverwaltungslösungen suchen, weiter festigt.
Überwindung von Cache-Beschränkungen für erhöhte Ausgabevielfalt
Eine multimodale KI, die vielfältige Ausgaben erzeugen kann, ist unerlässlich, um eine umfassende und effektive Lösung bereitzustellen, die den Bedürfnissen einer breiten Palette von Benutzern gerecht werden kann. Die Vielfalt der Ausgaben trägt dazu bei, die Benutzererfahrung zu verbessern und die Gesamtfunktionalität des KI-Systems zu steigern. Darüber hinaus ist Ausgabevielfalt entscheidend für Anwendungen, die eine breite Palette von Ausgabetypen erfordern, wie virtuelle Assistenten, Chatbots und Spracherkennungssysteme.
Während der semantische Cache eine effiziente Möglichkeit zum Abrufen von Daten ist, kann er die Vielfalt der Benutzerantworten einschränken. Er priorisiert zwischengespeicherte Antworten gegenüber der Generierung neuer Antworten aus einem großen Modell. Das bedeutet, dass das System möglicherweise weiterhin dieselben oder ähnliche Ausgaben erzeugt und sich stark auf zuvor zwischengespeicherte Informationen stützt. Infolgedessen kann die Ausgabe repetitiv werden und an Neuheit mangeln, was in Kontexten problematisch sein kann, in denen vielfältige und kreative Antworten benötigt werden.
Um dieses Problem anzugehen, ist die Temperatur im maschinellen Lernen zu einem wertvollen Werkzeug geworden. Die Temperatur bestimmt die Zufälligkeit oder Vielfalt des Antwortinhalts, wobei ein höherer Temperaturwert eine stärkere Erkundung von Möglichkeiten jenseits der wahrscheinlichsten Ausgabe erlaubt. Dies kann zu kreativen und unerwarteten Ausgaben führen und eine breitere Palette von Präferenzen und Stilen berücksichtigen. Andererseits erzeugt ein niedrigerer Temperaturwert fokussiertere und deterministischere Antworten und liefert präzise und kohärente Ergebnisse. Durch die Überwindung von Cache-Beschränkungen mittels Temperaturanpassung können multimodale KI-Anwendungen umfassendere und effektivere Lösungen hervorbringen, die den Bedürfnissen einer breiteren Benutzergruppe gerecht werden.
Temperatur in GPTCache
Die Wahl eines geeigneten Temperaturwerts ist in multimodaler KI entscheidend, um Zufälligkeit und Kohärenz auszubalancieren und sie an die spezifischen Bedürfnisse und Präferenzen des Benutzers oder der Anwendung anzupassen. Die Temperatur in GPTCache behält hauptsächlich das allgemeine Konzept der Temperatur im maschinellen Lernen bei. Sie wird durch 3 Optionen im Workflow umgesetzt:
- Nach der Auswertung auswählen
Softmax-Aktivierung auf Modell-Logits ist eine gängige Technik, die Temperatur im Deep Learning einbezieht. GPTCache verwendet in ähnlicher Weise eine Softmax-Funktion, um die Ähnlichkeitswerte von Kandidatenantworten in eine Liste von Wahrscheinlichkeiten umzuwandeln. Je höher der Wert, desto wahrscheinlicher ist es, dass sie als endgültige Antwort ausgewählt wird. Die Temperatur steuert die Schärfe der Wahrscheinlichkeitsverteilung. Das bedeutet, dass eine Antwort mit einem höheren Wert eher ausgewählt wird. Der Postprozessor temperature_softmax in GPTCache folgt diesem Algorithmus, um ein Element aus einer Liste von Kandidaten anhand ihrer Werte oder Konfidenzniveaus auszuwählen.
from gptcache.processor.post import temperature_softmax
messages = ["message 1", "message 2", "message 3"]
scores = [0.9, 0.5, 0.1]
answer = temperature_softmax(messages, scores, temperature=0.5)
- Modell ohne Cache aufrufen
Wir wenden die Möglichkeit an, große Modelle direkt aufzurufen, ohne den Cache zu durchsuchen. Diese Möglichkeit wird von der Temperatur beeinflusst. Eine höhere Temperatur bedeutet, dass die Cache-Suche eher übersprungen wird, während eine niedrigere Temperatur die Wahrscheinlichkeit verringert, die Cache-Suche zu überspringen. Hier ist ein Beispiel, das temperatuer_softmax verwendet, um die Entscheidung, den Cache zu überspringen oder zu prüfen, durch die Temperatur zu steuern.
from gptcache.processor.post import temperature_softmax
def skip_cache(temperature):
if 0 < temperature < 2:
cache_skip_options = [True, False]
prob_cache_skip = [0, 1]
cache_skip = temperature_softmax(
messages=cache_skip_options,
scores=prob_cache_skip,
temperature=temperature)
)
elif temperature >= 2:
cache_skip = True
else: # temperature <= 0
cache_skip = False
return cache_skip
- Ergebnis aus dem Cache bearbeiten
Bei Verwendung eines kleinen Modells oder einiger Tools zur Bearbeitung der Antwort erfordert diese Option einen Editor mit der Fähigkeit, den Datentyp der Ausgabe zu konvertieren.
Multimodale Anwendungen
Immer mehr Personen suchen Unterstützung bei GPT-4, anstatt sich mit ChatGPT zufriedenzugeben und sich ausschließlich auf GPT-3.5 zu verlassen. Darüber hinaus verlagert sich der aktuelle Trend von reinem LLM hin zu multimodalen Anwendungen. Multimodale KI interagiert hauptsächlich mit mehreren Datenmodalitäten, darunter Text, visuelle Inhalte und Audio. Mit der Weiterentwicklung von KI-Technologien stellen GPTCache und Milvus einen spannenden und innovativen Ansatz zum Aufbau intelligenter multimodaler Systeme dar. Die folgenden Beispiele zeigen, wie GPTCache und Milvus in multimodalen Situationen implementiert wurden.
1. Text-zu-Bild: Bilderzeugung
Bilderzeugung durch KI ist in den letzten Jahren ein heiß diskutiertes Thema. Sie bezieht sich auf die Generierung von Bildern auf Grundlage textueller Beschreibungen oder Anweisungen mithilfe eines vortrainierten multimodalen Text-Bild-Modells. Diese Technologie hat in den letzten Jahren große Fortschritte gemacht. Wir haben unglaubliche Fortschritte bei Modellen und Anwendungen zur Bilderzeugung gesehen, die überzeugende Bilder erzeugen können, die oft schwer von von Menschen aufgenommenen Fotografien zu unterscheiden sind.
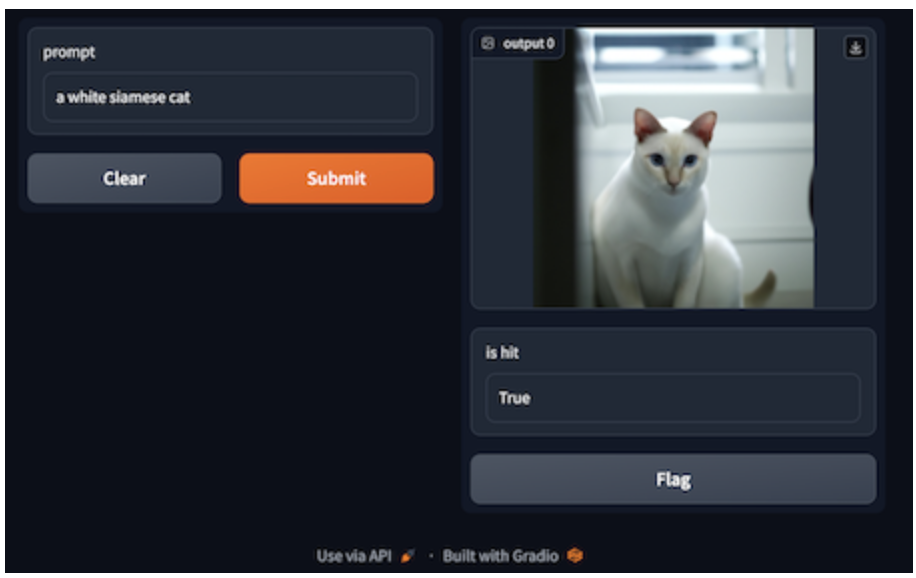 Prompt | eine weiße Siamkatze
Prompt | eine weiße Siamkatze
Der Prozess der Bilderzeugung umfasst die Verwendung textueller Prompts als Eingabe. Mit GPTCache wird die Bilderzeugung durch die semantische Suchfunktion für Prompts erleichtert. Das System verwendet Milvus, um Text-Embeddings zu vergleichen und ähnliche Prompts zu erkennen, die im Cache gespeichert sind. Anschließend ruft es die entsprechenden Bilder aus dem Cache ab. Wenn der Cache keine zufriedenstellenden Ergebnisse liefert, ruft GPTCache das Bilderzeugungsmodell auf. Die Bild- und Textausgaben des Modells werden von GPTCache gespeichert, wodurch seine Datenbank erweitert wird. Der Embedding-Generator wandelt jeden Text-Prompt in einen Vektor um und speichert ihn dann in Milvus, um Speicherung und Abruf zu erleichtern.
Der folgende Beispielcode ruft den mit GPTCache angepassten OpenAI-Dienst auf, um anhand des Textes "a whilte siamese cat." ein Bild zu erzeugen. Die Anfrage reguliert die Vielfalt der erzeugten Bilder bei jeder Gelegenheit über den Wert temperature und top_k. Durch Ändern der Temperatur von ihrem Standardwert 0.0 auf einen höheren Wert von 0.8 ist es wahrscheinlicher, dass die Anfrage bei demselben Text jedes Mal ein anderes Bild erhält.
from gptcache.adapter import openai
cache.set_openai_key()
response = openai.Image.create(
prompt="a white siamese cat",
temperature=0.8, # optional, defaults to 0.0.
top_k=10 # optional, defaults to 5 if temperature>0.0 else 1.
)
GPTCache verfügt derzeit über integrierte Adapter für die meisten beliebten Bilderzeugungsmodelle oder -dienste, darunter OpenAI Image Creation, Stability.AI API, Stable Diffusions at HuggingFace. Das Bootcamp bietet ein Tutorial zur Bilderzeugung mit OpenAI.
2. Bild-zu-Text: Bildbeschriftung
Bildbeschriftung erzeugt eine textuelle Beschreibung für ein Bild, typischerweise unter Verwendung eines vortrainierten multimodalen Bild-Text-Modells. Diese Technologie ermöglicht es Computern, den Inhalt von Bildern zu verstehen und ihn in natürlicher Sprache zu beschreiben, damit Menschen ihn interpretieren können. Bildbeschriftung kann auch eine deutlich robustere Lösung bieten, indem sie in einen Chatbot integriert wird. Sie ermöglicht einen nahtlosen Übergang zwischen den visuellen und konversationellen Aspekten eines Produkts und verbessert so das gesamte Benutzererlebnis.
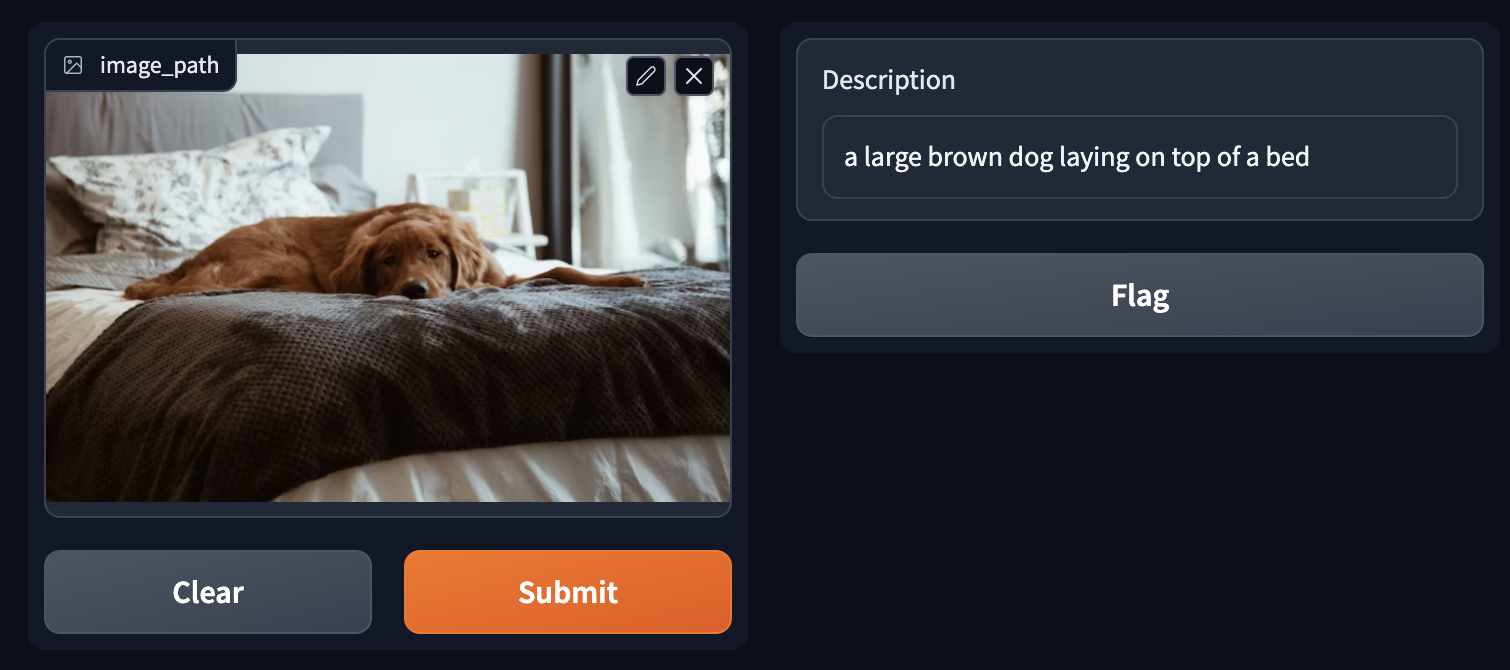 Ein großer brauner Hund liegt auf einem Bett
Ein großer brauner Hund liegt auf einem Bett
In Bezug auf Bildbeschriftung beginnt GPTCache damit, seinen Cache nach Bildern zu durchsuchen, die dem Eingabebild ähneln, gemessen anhand von Bild-Embeddings. Um anschließend die Qualität der zurückgegebenen Beschriftungen sicherzustellen, führt ein Evaluator eine zusätzliche Bewertung der Relevanz oder Ähnlichkeit zwischen dem Eingabebild und den aus dem Cache abgerufenen Bildern oder Beschriftungen durch. Beispielsweise können vortrainierte visuelle Modelle wie ResNets oder ViTs die Bildähnlichkeit bewerten. Zusätzlich kann ein Text-Bild-Modell wie CLIP angewendet werden, um die Ähnlichkeit zwischen Bild und Text zu messen. Wenn es keine Übereinstimmung im Cache gibt, nutzt das System ein multimodales Modell, um Beschriftungen für das gegebene Bild zu erzeugen. Anschließend speichert GPTCache sowohl das Bild als auch die zugehörigen Beschriftungen, wobei Bilder und Beschriftungen als Vektoren in Milvus gespeichert werden.
GPTCache hat bereits beliebte Bildbeschriftungsdienste wie Replicate BLIP und miniGPT-4 angepasst. Es plant, weitere Bild-zu-Text-Dienste und lokal gehostete multimodale Modelle zu unterstützen.
3. Audio-zu-Text: Sprachtranskription
Audio-zu-Text, auch bekannt als Sprachtranskription, wandelt Audioinhalte wie aufgezeichnete Gespräche, Meetings oder Vorlesungen in geschriebenen Text um. Diese Technologie ermöglicht es Personen, die möglicherweise Schwierigkeiten beim Hören haben oder Inhalte lieber lesen als anhören, leichter auf die Informationen zuzugreifen und sie zu verstehen. Zusätzlich zur Weitergabe von Transkriptionen an einen Chatbot wie ChatGPT können Nutzer die Transkriptionen verwenden, um mehr zu erkunden.
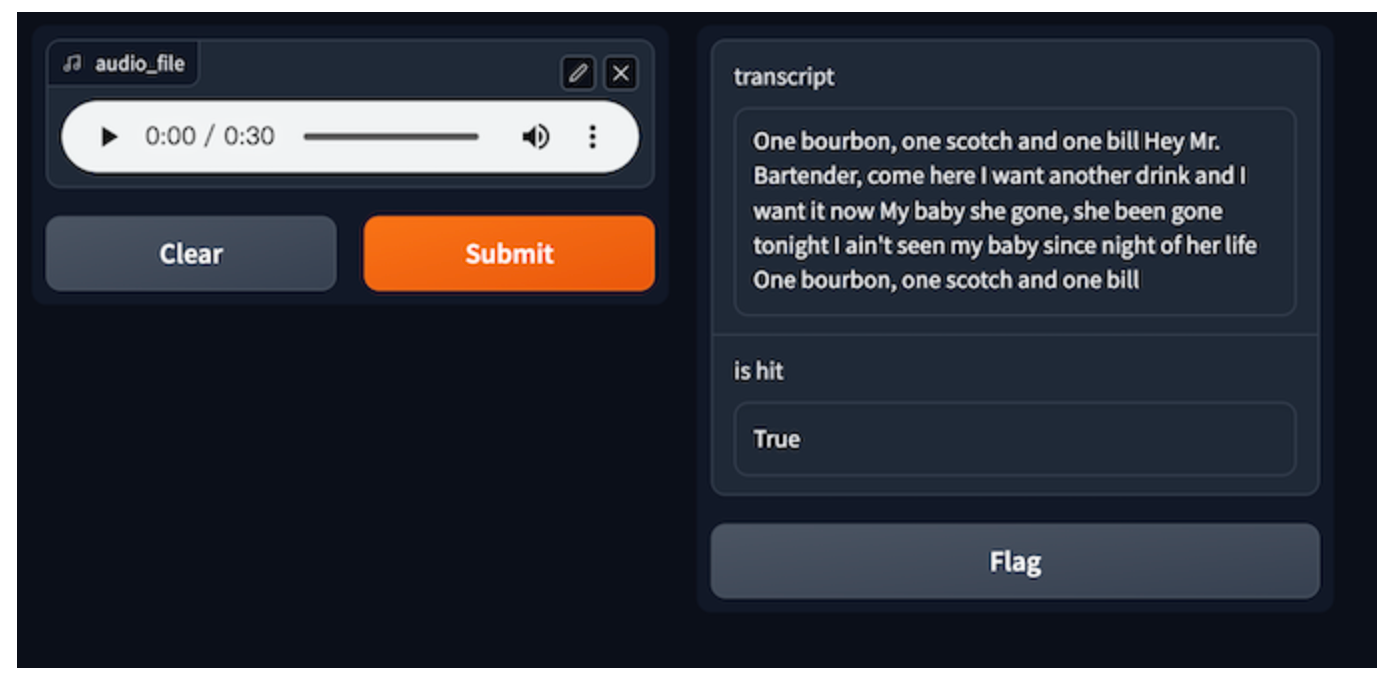 Audiodatei | One bourbon, one scotch, one bill
Audiodatei | One bourbon, one scotch, one bill
Eine Audiodatei dient typischerweise als anfängliche Eingabe für die Sprachtranskription. Durch die Aktivierung von GPTCache besteht der erste Schritt darin, für jede Eingabe ein Audio-Embedding zu erstellen. Das System nutzt dann Milvus für die Ähnlichkeitssuche und ruft potenzielle Transkriptionen aus dem Cache ab. Schließlich wird ein Modell oder Dienst für automatische Spracherkennung (ASR) aufgerufen, wenn nach der Auswertung keine entsprechenden Antworten gefunden werden. Alle vom ASR-Modell generierten Paare aus Audio und Transkriptionen werden im Cache gespeichert. Die Verwendung von Milvus zur Speicherung von Audiodaten als Vektoren stellt sicher, dass ein Abgleich ähnlicher Audiodaten aus dem Cache möglich ist. Sie ermöglicht außerdem Skalierbarkeit, wenn die Menge der Audiodaten zunimmt.
GPTCache und Milvus reduzieren den Bedarf an mehrfachen ASR-Aufrufen erheblich und verbessern so Geschwindigkeit und Effizienz. Das GPTCache-Bootcamp zu Speech to Text bietet ein Beispiel-Tutorial zur Aktivierung von GPTCache und zur Anwendung von Milvus für die OpenAI Transcriptions.
Fazit
Die Nutzung multimodaler KI-Modelle gewinnt an Popularität und ermöglicht eine umfassendere Analyse und ein besseres Verständnis komplexer Daten. Mit seiner Unterstützung für unstrukturierte Daten ist Milvus eine ideale Lösung für den Aufbau und die Skalierung multimodaler Anwendungen. Darüber hinaus erweitert das Hinzufügen weiterer Funktionen in GPTCache, wie Sitzungsverwaltung, Kontextbewusstsein und Serverunterstützung, die Fähigkeiten multimodaler KI zusätzlich. Mit diesen Fortschritten haben multimodale KI-Modelle mehr potenzielle Einsatzmöglichkeiten und Szenarien. Bleiben Sie beim GPTCache Bootcamp auf dem Laufenden, um weitere Einblicke in multimodale KI-Anwendungen zu erhalten.

Weiterlesen

Notion's Vector Search Is Excellent. Their Next Problem Is Harder.
Notion solved vector search scaling in two years. The next bottleneck — offline context engineering, unified data, and the real-time/offline gap — is harder.

How to Choose the Best Embedding Model for RAG in 2026: 10 Models Benchmarked
We benchmarked 10 embedding models on cross-modal, cross-lingual, long-document, and dimension compression tasks. See which one fits your RAG pipeline.
Milvus/Zilliz + Surveillance: How Vector Databases Transform Multi-Camera Tracking
See how Milvus vector database enhances multi-camera tracking with similarity-based matching for better surveillance in retail, warehouses and transport hubs.