




ChatGPT+ Vektordatenbank + Prompt-as-Code - Der CVP-Stack
Ich freue mich, eine Demo-Anwendung vorzustellen, an der wir hier bei Zilliz gearbeitet haben. Wir nennen sie OSS Chat, einen Chatbot, mit dem du technisches Wissen über deine bevorzugten Open-Source-Projekte erhalten kannst. Diese erste Version unterstützt nur Hugging Face, Pytorch und Milvus, aber wir planen, sie auf mehrere deiner bevorzugten Open-Source-Projekte auszuweiten. Wir haben OSS Chat mit OpenAIs ChatGPT und einer Vektordatenbank, Zilliz, entwickelt! Wir bieten ihn als kostenlosen Service für alle an, die ihn nutzen. Wenn du möchtest, dass dein Open-Source-Projekt aufgeführt wird, lass es uns wissen.
Hintergrund dazu, warum wir OSS Chat entwickelt haben
ChatGPT hat aufgrund seiner begrenzten Wissensbasis Einschränkungen, was manchmal zu halluzinierten Antworten führt, wenn es zu unbekannten Themen befragt wird. Wir führen den neuen KI-Stack ChatGPT+Vektordatenbank+Prompt-as-Code, oder den CVP Stack, ein, um diese Einschränkung zu überwinden.
ChatGPT ist außergewöhnlich gut darin, Anfragen in natürlicher Sprache zu beantworten. In Kombination mit einem Prompt, der die Anfrage des Nutzers und den abgerufenen Text verknüpft, generiert ChatGPT eine relevante und genaue Antwort. Dieser Ansatz kann verhindern, dass ChatGPT „halluzinierte Antworten“ liefert.
Wir haben OSS Chat als funktionierende Demonstration des CVP Stacks entwickelt. OSS Chat nutzt verschiedene GitHub-Repositories von Open-Source-Projekten und deren zugehörige Dokumentationsseiten als verlässliche Quelle. Wir wandeln diese Daten in Embeddings um und speichern die Embeddings in Zilliz und die zugehörigen Inhalte in einem separaten Datenspeicher. Wenn der Nutzer mit OSS Chat interagiert, indem er Fragen zu einem beliebigen Open-Source-Projekt stellt, lösen wir eine Ähnlichkeitssuche in Zilliz aus, um eine relevante Übereinstimmung zu finden. Die abgerufenen Daten werden in ChatGPT eingespeist, um eine präzise und genaue Antwort zu generieren.
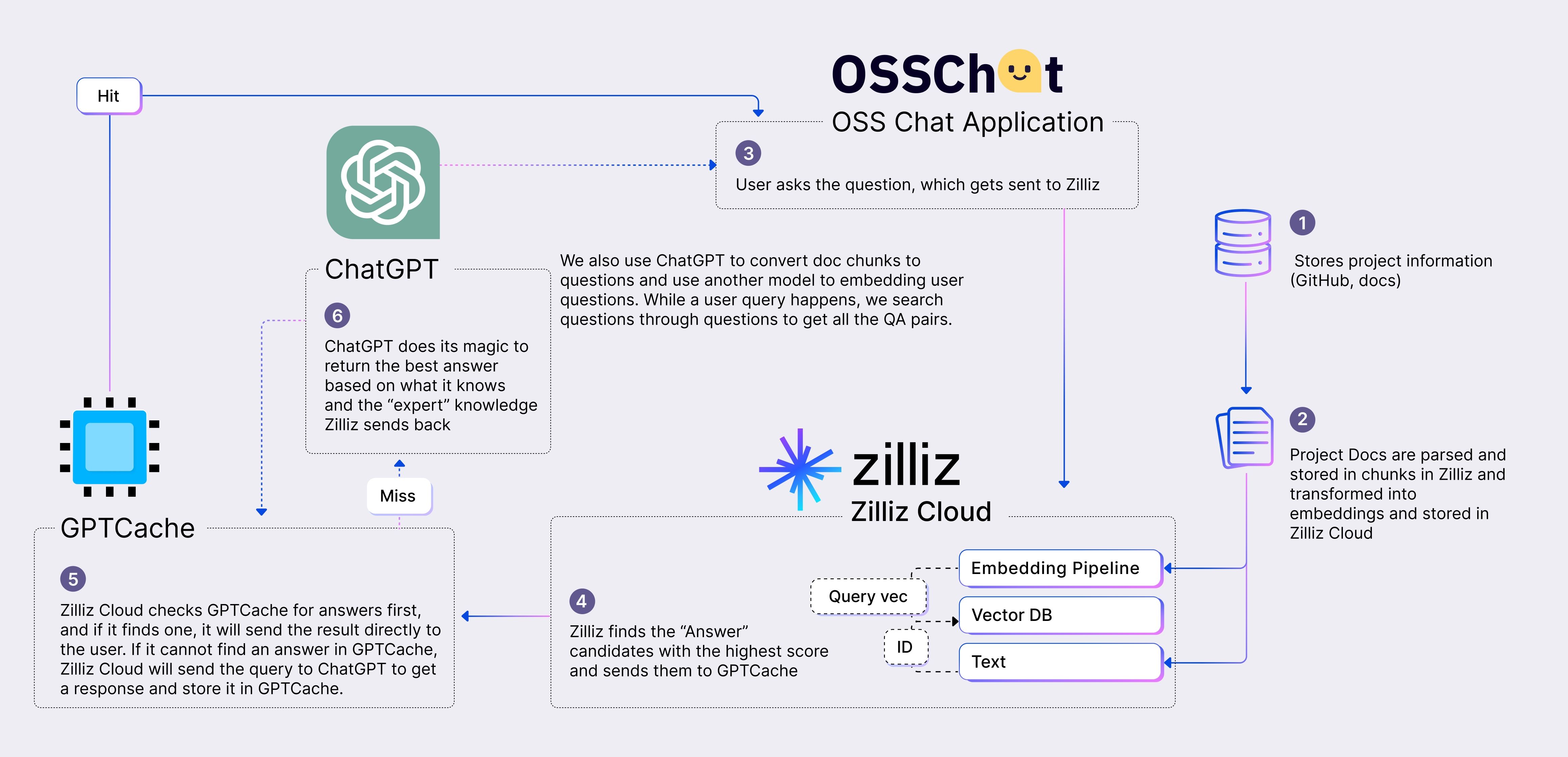 OSS Chat Architecture
OSS Chat Architecture
Die Antwort halluzinieren
Ich möchte dir ein paar Q&A-Beispiele mit ChatGPT und OSS Chat zeigen, um zu demonstrieren, wie du einige falsche Antworten entfernen kannst.
Q1 Unterstützt Hugging Face OpenAI Whisper
Als wir ChatGPT diese Frage stellten, gab es seine Einschränkung zu und lieferte uns eine genaue Antwort (es hatte die Daten nicht), was nicht nützlich war.
Nach meinem Wissensstand von September 2021 hat Hugging Face keine Unterstützung für OpenAI Whisper angekündigt. Es ist jedoch immer möglich, dass sie in Zukunft Unterstützung hinzufügen. OpenAI Whisper ist ein neues Sprachmodell von OpenAI, und es kann einige Zeit dauern, bis andere Unternehmen und Entwickler es in ihre Plattformen und Produkte integrieren.
Mit OSS Chat können wir, da wir die Daten von der Huggingface-Dokumentationsseite abrufen, eine genaue Antwort erhalten. Ja, Hugging Face unterstützt OpenAI Whisper. Die Klasse FlaxWhisperModel ist in der transformers-Bibliothek verfügbar, die ein Wrapper um das OpenAI Whisper-Modell ist. Du kannst diese Klasse verwenden, um das vortrainierte OpenAI Whisper-Modell zu laden und es für verschiedene Aufgaben der Verarbeitung natürlicher Sprache wie Textklassifizierung, Beantwortung von Fragen und Textgenerierung zu verwenden.
Q2 Was macht die torch.compile API?
Wir stellten ChatGPT eine Frage zu einer PyTorch-API und erhielten eine lange Antwort darüber, was sie ist (was wir nicht gefragt hatten), sowie eine Antwort, die besagte, dass PyTorch keine torch.compile API hat.
Nach meinem Wissensstand von September 2021 gibt es keine torch.compile API in PyTorch, einer beliebten Open-Source-Bibliothek für maschinelles Lernen, die von Facebook AI Research entwickelt wurde.
PyTorch bietet jedoch verschiedene APIs zum Kompilieren und Optimieren neuronaler Netzwerkmodelle, wie z. B. torch.nn.Module, eine Basisklasse für alle neuronalen Netzwerkmodule in PyTorch. torch.nn.Module bietet verschiedene Methoden und Hooks zum Definieren und Optimieren neuronaler Netzwerkmodelle.
Zusätzlich bietet PyTorch eine Schnittstelle zur Integration mit Just-In-Time-(JIT)-Compilern, wie dem TorchScript-JIT-Compiler, der verwendet werden kann, um PyTorch-Modelle für eine effiziente Ausführung auf verschiedenen Hardwareplattformen zu optimieren und zu kompilieren. Der JIT-Compiler kann verwendet werden, um PyTorch-Modelle in eine eigenständige, serialisierte Darstellung umzuwandeln, die in anderen Umgebungen oder Sprachen geladen und ausgeführt werden kann. Zusammenfassend lässt sich sagen: Obwohl PyTorch keine torch.compile-API hat, bietet es verschiedene APIs und Tools zur Optimierung und Kompilierung neuronaler Netzwerkmodelle.
Hier ist, was OSSChat uns gesagt hat:
Der Zweck der torch.compile-API besteht darin, PyTorch-Code zu beschleunigen, indem er im Voraus kompiliert wird. Sie kann beliebigen Python-Code mit minimalen Änderungen am bestehenden Code verarbeiten und datenabhängige Kontrollflüsse handhaben. Sie ist außerdem in der Lage, Nicht-PyTorch-Funktionsaufrufe zu verarbeiten, die TorchScript-Tracing als Konstanten behandelt und die zu falschen Ergebnissen führen können.
Q3 Was ist TTL in Milvus und wie stelle ich es ein
Für diese letzte Frage haben wir ChatGPT gefragt, und es lieferte uns eine vernünftige Antwort (sie enthielt sogar Code-Snippets!), aber es war keine Antwort auf die Frage. Stattdessen war es eine dieser „Halluzinationen“, bei denen es die Antwort wohl zusammengestellt haben muss.
In Milvus ist TTL (Time To Live) eine Funktion, mit der Sie eine Ablaufzeit für Ihre Daten festlegen können. Wenn Sie eine TTL für eine Collection oder Partition in Milvus festlegen, löscht Milvus automatisch alle Daten, die die angegebene TTL überschritten haben. Um TTL für eine Collection oder Partition in Milvus festzulegen, können Sie die set_collection_ttl- bzw. set_partition_ttl-API verwenden. Hier ist ein Beispiel:
pythonCopy code
import datetime
from milvus import Milvus, DataType
milvus = Milvus()
# create a collection
collection_param = {
'collection_name': 'my_collection',
'dimension': 128,
'index_file_size': 1024,
'metric_type': DataType.FLOAT_VECTOR,
}
milvus.create_collection(collection_param)
# set TTL for the collection
now = datetime.datetime.now()
delta = datetime.timedelta(days=7) # TTL of 7 days
expiry_time = now + delta
milvus.set_collection_ttl('my_collection', expiry_time.timestamp())
# create a partition
partition_param = {
'collection_name': 'my_collection',
'partition_name': 'my_partition',
}
milvus.create_partition(partition_param)
# set TTL for the partition
milvus.set_partition_ttl('my_collection', 'my_partition', expiry_time.timestamp())
In diesem Beispiel erstellen wir eine Collection und eine Partition in Milvus. Anschließend legen wir mithilfe der set_collection_ttl- bzw. set_partition_ttl-APIs eine TTL von 7 Tagen sowohl für die Collection als auch für die Partition fest. Die TTL wird als Unix-Zeitstempel angegeben, also die Anzahl der Sekunden seit dem 1. Januar 1970. Wir berechnen die Ablaufzeit, indem wir die TTL mithilfe des datetime-Moduls zur aktuellen Zeit addieren.
Beachten Sie, dass Sie die TTL-Funktion aktivieren müssen, wenn Sie Milvus starten. Dies kann durch Festlegen des Parameters TTL_CHECK_INTERVAL in der Milvus-Konfigurationsdatei erfolgen. Der Standardwert beträgt 60 Sekunden.
OSSchat hingegen gab uns die richtige Antwort: eine einzelne Codezeile, um die gewünschten Sekunden in der Collection-Set-Property festzulegen.
TTL steht in Milvus für „Time to Live“. Es ist eine Funktion, mit der Sie eine Ablaufzeit für Daten in einer Collection festlegen können. Wenn Daten in einer Collection ablaufen, werden sie automatisch bereinigt und nicht in Suchen oder Abfragen einbezogen.
Um den TTL-Wert für eine Collection in Milvus festzulegen, können Sie die Methode collection.set_properties() in Python verwenden. Um beispielsweise den TTL-Wert auf 1800 Sekunden (30 Minuten) festzulegen, können Sie den folgenden Code verwenden:
collection.set_properties(properties={"collection.ttl.seconds": 1800})
Sie können den TTL-Wert auch beim Erstellen einer Collection festlegen, indem Sie die Eigenschaft collection.ttl.seconds in den Eigenschaften der Collection angeben. Der Wert sollte in Sekunden angegeben werden und 0 oder größer sein. Ein Wert von 0 bedeutet, dass TTL deaktiviert ist.
Jetzt loslegen
In den kommenden Tagen werden wir OSS Chat um weitere Funktionen erweitern und begleitende Blogs verfassen, um euch zu zeigen, wie wir es entwickeln. Probiert in der Zwischenzeit OSS Chat aus und teilt uns mit, welche Funktionen ihr gerne sehen würdet, oder wenn ihr ein Open-Source-Projekt hinzufügen möchtet, lasst es uns wissen!

Weiterlesen

We spent 8 years making vector databases faster. Then we stopped.
Rarely queried embeddings still need to stay searchable. See how Vector Lakebase enables on-demand vector search without always-on compute costs.

Why Teams Are Migrating from Weaviate to Zilliz Cloud — and How to Do It Seamlessly
Explore how Milvus scales for large datasets and complex queries with advanced features, and discover how to migrate from Weaviate to Zilliz Cloud.

Introducing DeepSearcher: A Local Open Source Deep Research
In contrast to OpenAI’s Deep Research, this example ran locally, using only open-source models and tools like Milvus and LangChain.